简介:这篇文章已经算比较老的一片文章了,主要就是充分利用了一个目标人物在空间和时间维度上的辨别部分,通过帧间正则化产生了一个二维注意力得分矩阵,以衡量不同帧间空间部分的重要性,达到更优的效果。
可以提前了解一下注意力机制,其实就是权重分配的问题。
STA:大规模视频行人重识别–利用时空注意力
AAAI 2019
论文作者:Yang Fu, Xiaoyang Wang, Yunchao Wei, Thomas Huang
作者单位:贝克曼研究所
paper:https://arxiv.org/abs/1811.04129?context=cs
一、Motivation
- 大多数现有方法(2018之前)将视频的一帧表示为一个特征向量,然后采用跨帧平均或最大池化来获得输入视频的表示。然而,当视频中频繁出现遮挡物时,这种方法通常会失效
- 视频帧间的最大或平均池化等基本操作无法处理帧间人体姿势变化造成的空间错位
- 虽然已经有了关于注意力机制的应用,但是这些现有的(2018)基于注意力的方法只为每个帧分配一个注意力权重,没有利用人体不同不同部分之间的关系,因此缺乏发现视频序列中具有区分性的帧或每个帧中具有区分性的身体部位的能力。由于人体的不同区域对再识别任务的影响应该是不同的,因此,作者的方法旨在发现每一帧中的具有判别性的表征
- 大多数现有的基于注意力的方法中的注意力机制都是参数化的,例如全连接层,这就要求输入视频序列的长度是固定的
二、Contribution
- 提出Spatial-Temporal Attention(STA )模型,该模型为每个空间区域分配注意力得分,从而在不使用任何额外参数的情况下,实现discriminative parts mining and frame selection。
- 引入帧间正则化项来限制不同帧之间的差异
- 设计了一种特征融合策略,将视频序列中的全局信息和具有判别性的信息结合起来,以实现更好的特征聚合。
三、Method
STA 框架不再是简单地通过参数模型对每一帧图像进行池化或权重分配来对图像序列进行编码,而是在不使用任何额外参数的情况下,将包括帧选择、判别部分挖掘和特征聚合在内的多个新颖组件联合在一起
Framework

1、首先从输入的视频 query 中随机采样一定数量的帧,并将其送入backbone network(ResNet50) ,从每一帧中提取特征
2、然后,将获得的feature maps 输入到此处提出的 STA 模型中,生成一个二维注意力评分矩阵,该矩阵为每帧的每个spatial region分配一个注意力权重
3、接下来,我们利用每个frame中对应权值最大的spatial region,和所有注意力权值的加权和,得到两组完整的人体特征图。
4、最后,把它们拼接起来,作为全局表示法和判别表示,并采用全局平均池化和全连接层来表示这个视频query。(最后采用softmax loss和 batch-hard triplet loss来一起作为损失函数 )
STA
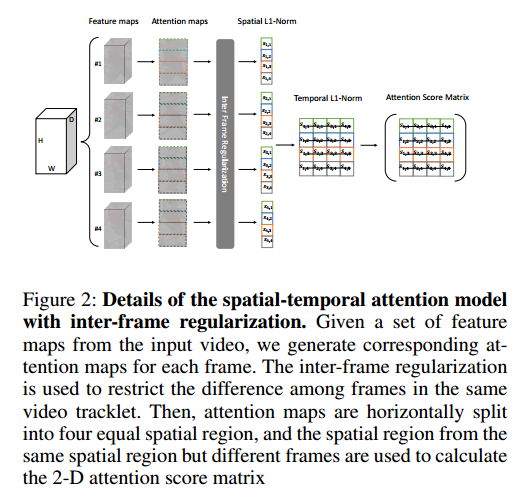
- 给定输入视频的特征图 { f n f_n