搭建参考,可以参考这个文章:实战篇:使用rook在k8s上搭建ceph集群
一、概述
下面对在K8S集群中使用Rook来创建Ceph集群的步骤做一个概述:
-
部署Rook Operator 在Kubernetes集群中部署Rook Operator,可以通过使用Helm Chart或kubectl命令来实现。Rook Operator是一个控制器,它可以在Kubernetes集群中管理Ceph集群的创建和配置。
-
创建Ceph Cluster 创建一个名为ceph-cluster.yaml的清单文件,其中包含有关Ceph集群的配置信息,例如Ceph mon、Ceph OSD、Ceph MGR和Ceph RGW的数量、存储池配置等等。清单文件的格式应符合Kubernetes YAML格式。
-
创建存储类 在Kubernetes集群中创建一个存储类,该存储类使用Ceph集群提供的存储。可以通过创建一个名为ceph-storageclass.yaml的清单文件,其中包含关于存储类的配置信息,例如存储池、存储类名称等等。清单文件的格式应符合Kubernetes YAML格式。
-
创建块存储 使用存储类创建一个块存储,以供Pod使用。可以通过在Pod的卷声明中指定存储类来创建块存储。在使用块存储之前,需要先将其格式化并挂载到Pod中。
通过这些步骤,可以使用Rook在Kubernetes集群中创建一个Ceph集群,并将其作为Kubernetes存储类提供给Pod使用。Rook提供了许多其他的功能和配置选项,可以根据需要进行修改和扩展。
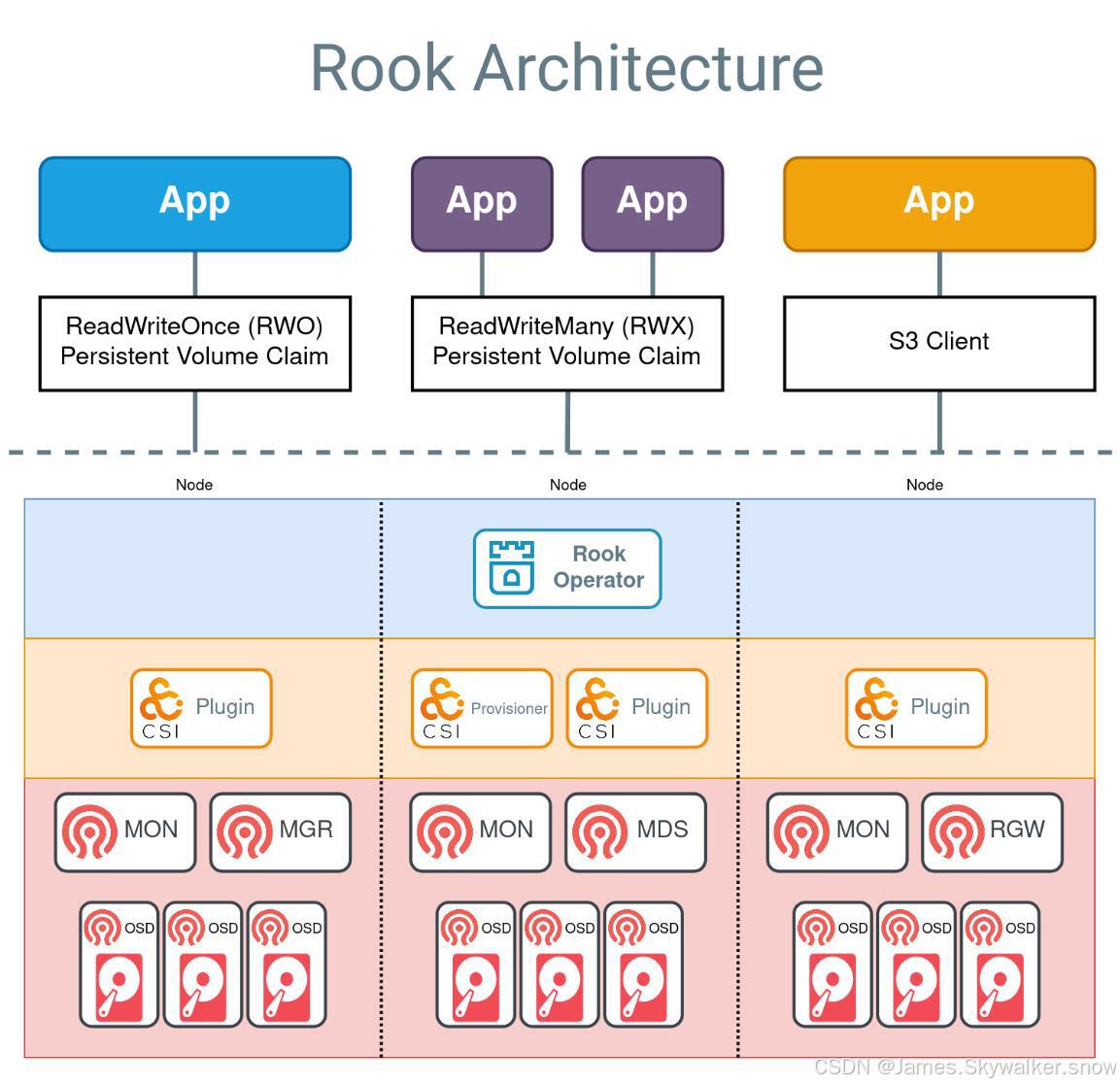
二、搭建步骤
此处只为概述
拉取镜像
拉取rook-ceph相关镜像,需要愚昧上网。
创建crd&common
获取rook部署yaml文件,此处可以自由选择版本,当然有人建议根据K8s的版本选择一个合适的rook版本。
#v1.12稳定版
git clone --single-branch --branch v1.12.11 https://github.com/rook/rook.git
git clone --single-branch --branch v1.13.8 https://github.com/rook/rook.git部署资源文件
cd rookv1.13.8
kubectl create -f crds.yaml -f common.yaml
#删除
kubectl delete -f crds.yaml -f common.yaml 部署operator
一般来说不用修改。operator(操作器)是rook部署的核心,rook的操作都需要operator(操作器)进行。
kubectl create -f operator.yaml
#删除部署
kubectl delete -f operator.yaml
#查看状态,比如保证operator处于running状态
kubectl get pod -n rook-ceph
NAME READY STATUS RESTARTS AGE
rook-ceph-operator-9f688fcc5-cg689 1/1 Running 0 3s部署cluster
使用磁盘序列号进行绑定,避免重启后nvme硬盘识别号发生变化。一般来说不存在这个问题,但是某些超微主板在添加同型号SSD后,硬盘位置为发生变化, 所以可以执行磁盘序列号绑定。
udevadm info --query=all --name=/dev/nvme1n1
P: /devices/pci0000:00/0000:00:03.3/0000:01:00.0/nvme/nvme1/nvme1n1
N: nvme1n1
L: 0
S: disk/by-id/nvme-eui.5cd2e4259141745f
S: disk/by-id/nvme-INTEL_SSDPEKKF010T8L_PHHH838101SW1P0E_1
S: disk/by-id/nvme-INTEL_SSDPEKKF010T8L_PHHH838101SW1P0E
部署
kubectl create -f cluster.yaml
#删除
kubectl delete -f cluster.yamlcluster.yaml存储了使用的硬盘信息。下面是一个复杂的设置:配置了两种型号的硬盘SSD和HDD,其中为HDD配置SSD缓存。深入理解,可以参考rook给出的deviceClass的说明。
-
deviceClass:用于此选择的存储设备的CRUSH 设备类。 (默认情况下,如果尚未设置设备的类别,OSD 将根据 Linux 内核公开的硬件属性自动将设备的类别设置为hdd、ssd或。)然后可以使用这些存储类别来选择支持的设备通过将它们指定为池规范字段的nvme值来创建存储池。deviceClass.。来源:https://rook.io/docs/rook/latest-release/CRDs/Cluster/ceph-cluster-crd/#storage-class-device-sets
storage: # cluster level storage configuration and selection
useAllNodes: false
useAllDevices: false
config: {}
nodes:
- name: "k8s-w32-ip31-7513"
devices:
- name: "/dev/disk/by-id/nvme-WUS4BB076D7P3E3_A05E1AB6"
config:
osdsPerDevice: "4"
- name: "/dev/disk/by-id/nvme-WUS4BB076D7P3E3_A0614749"
config:
osdsPerDevice: "4"
- name: "sda"
config:
metadataDevice: "/dev/disk/by-id/nvme-Micron_7450_MTFDKBG960TFR_22263B92A0F1"
- name: "sdb"
config:
metadataDevice: "/dev/disk/by-id/nvme-Micron_7450_MTFDKBG960TFR_22263B92A0F1"
- name: "sdc"
config:
metadataDevice: "/dev/disk/by-id/nvme-Micron_7450_MTFDKBG960TFR_22263B92A0F1"
- name: "sdd"
config:
metadataDevice: "/dev/disk/by-id/nvme-Micron_7450_MTFDKBG960TFR_22263B92A0F1"
- name: "sde"
config:
metadataDevice: "/dev/disk/by-id/nvme-Micron_7450_MTFDKBG960TFR_22263B92A0F1"
- name: "sdf"
config:
metadataDevice: "/dev/disk/by-id/nvme-Micron_7450_MTFDKBG960TFR_22263B92A0F1"
- name: "sdg"
config:
metadataDevice: "/dev/disk/by-id/nvme-Micron_7450_MTFDKBG960TFR_22263B92A0F1"
- name: "sdh"
config:
metadataDevice: "/dev/disk/by-id/nvme-Micron_7450_MTFDKBG960TFR_22263B92A0F1"
- name: "sdi"
config:
metadataDevice: "/dev/disk/by-id/nvme-Micron_7450_MTFDKBG960TFR_22263B92A0F1"安装ceph客户端工具
#创建toolbox
kubectl create -f toolbox.yaml -n rook-ceph
kubectl delete -f toolbox.yaml -n rook-ceph
# 查看pod
kubectl get pod -n rook-ceph -l app=rook-ceph-tools
#直接执行命令
kubectl -n rook-ceph exec -it deploy/rook-ceph-tools -- ceph status
kubectl -n rook-ceph exec -it deploy/rook-ceph-tools -- ceph osd lspools
#进入pod
kubectl -n rook-ceph exec -it deploy/rook-ceph-tools -- bash
#查看集群状态
ceph status暴露Dashboard
Dashboard可以让我们查看Ceph集群的状态,包括整体的运行状况、mon仲裁状态、mgr、osd 和其他Ceph守护程序的状态、查看池和PG状态、显示守护程序的日志等。关于Dashboard的更多配置,请参考:https://rook.io/docs/rook/v1.11/Storage-Configuration/Monitoring/ceph-dashboard/
查看dashboard的svc,Rook将启用端口 8443 以进行 https 访问:
kubectl get svc -n rook-ceph
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
rook-ceph-mgr ClusterIP 10.140.249.105 <none> 9283/TCP 12m
rook-ceph-mgr-dashboard ClusterIP 10.140.217.133 <none> 8443/TCP 12m
rook-ceph-mon-a ClusterIP 10.140.21.78 <none> 6789/TCP,3300/TCP 13m
rook-ceph-mon-b ClusterIP 10.140.36.54 <none> 6789/TCP,3300/TCP 13m
rook-ceph-mon-c ClusterIP 10.140.9.120 <none> 6789/TCP,3300/TCP 13m
-
rook-ceph-mgr:是 Ceph 的管理进程(Manager),负责集群的监控、状态报告、数据分析、调度等功能,它默认监听 9283 端口,并提供了 Prometheus 格式的监控指标,可以被 Prometheus 拉取并用于集群监控。
-
rook-ceph-mgr-dashboard:是 Rook 提供的一个 Web 界面,用于方便地查看 Ceph 集群的监控信息、状态、性能指标等。
-
rook-ceph-mon:是 Ceph Monitor 进程的 Kubernetes 服务。Ceph Monitor 是 Ceph 集群的核心组件之一,负责维护 Ceph 集群的状态、拓扑结构、数据分布等信息,是 Ceph 集群的管理节点。
查看默认账号admin的密码
kubectl -n rook-ceph get secret rook-ceph-dashboard-password -o jsonpath="{['data']['password']}" | base64 --decode && echo使用 NodePort 类型的Service暴露dashboard dashboard-external-https.yaml
kubectl create -f dashboard-external-https.yaml
#删除部署
kubectl delete -f dashboard-external-https.yaml
清除rook-ceph
删除 Ceph 集群,按照建立顺序反向删除,crd.yaml不用删除
#查看已经建立的pv、pvc
kubectl get pv,pvc
kubectl delete pvc pvc名称
kubectl delete pv pv名称
#删除storage
kubectl get storageclass -A
kubectl delete storageclass rook-ceph-es-sc
#删除文件系统
ceph fs fail nvmefs
ceph fs rm nvmefs --yes-i-really-mean-it
#删除存储池
kubectl -n rook-ceph exec -it deploy/rook-ceph-tools -- ceph osd lspools
kubectl -n rook-ceph exec -it deploy/rook-ceph-tools -- ceph osd pool delete replicapool replicapool --yes-i-really-really-mean-it
kubectl -n rook-ceph exec -it deploy/rook-ceph-tools -- ceph osd pool delete ec-pool ec-pool --yes-i-really-really-mean-it
kubectl -n rook-ceph exec -it deploy/rook-ceph-tools -- ceph osd pool delete .mgr .mgr --yes-i-really-really-mean-it
#删除集群。如果不需要更改rook-ceph的命名空间,可以到此为止。
kubectl delete -f cluster.yaml
kubectl delete -f operator.yaml
kubectl delete -f common.yaml验证清理,验证所有资源是否已经被清理干净。
kubectl get all -n rook-ceph
kubectl -n rook-ceph get all,pvc,secret,configmap,cephclusters.ceph.rook.io,cephblockpools.ceph.rook.io,cephfilesystems.ceph.rook卡主的解决方案
查看和删除Finalizers: Kubernetes资源(如CephCluster)可能因为finalizer阻塞而不能被删除。您可以检查并手动移除这些finalizer以解除删除阻塞:
在编辑界面中,找到metadata部分下的finalizers,删除所有列出的finalizer条目,然后保存并退出编辑器。这应该会移除删除阻塞。
kubectl edit cephcluster rook-ceph -n rook-ceph卡主的解决方案2
故障排除,原文链接:https://blog.csdn.net/zh_admini/article/details/124090548
如果清理指令没有按照上面的顺序执行,或者你很难清理集群,这里有一些事情可以尝试。
清理集群最常见的问题是rook-ceph命名空间或集群 CRD 无限期地保持在terminating状态中。命名空间在其所有资源都被删除之前无法被删除,因此请查看哪些资源正在等待终止。
kubectl -n rook-ceph get pod
kubectl -n rook-ceph get cephcluster
for CRD in $(kubectl get crd -n rook-ceph | awk '/ceph.rook.io/ {print $1}'); do
kubectl get -n rook-ceph "$CRD" -o name | \
xargs -I {} kubectl patch -n rook-ceph {} --type merge -p '{"metadata":{"finalizers": [null]}}'
done
kubectl api-resources --verbs=list --namespaced -o name \
| xargs -n 1 kubectl get --show-kind --ignore-not-found -n rook-ceph
kubectl -n rook-ceph patch configmap rook-ceph-mon-endpoints --type merge -p '{"metadata":{"finalizers": [null]}}'
kubectl -n rook-ceph patch secrets rook-ceph-mon --type merge -p '{"metadata":{"finalizers": [null]}}'
清理节点
重新部署之前,必需清理节点
对于每个参与过 Ceph 集群的节点,你可能需要手动清理相关的数据目录和设备。这通常包括删除 OSD 数据、mon 数据和日志文件。
#手动登录到每个节点并清理 Ceph 使用的磁盘和目录
sudo rm -rf /var/lib/rook
sudo rm -rf /var/lib/rook-hdd
#将磁盘置为初始状态
lsblk
sudo wipefs -a /dev/sda
#元数据盘
sudo wipefs -a /dev/nvme3n1
sudo cfdisk
#如果cfdisk 删除分区后,lsblk还存在lvm分区,此时需要重启电脑。
三、创建cephfs文件系统
CephFS,或者称为 Ceph 文件系统,是一种分布式文件系统,允许多个客户端同时连接到一个 Ceph 存储集群来访问文件。与传统的文件系统(如 NTFS、EXT4 等)不同,CephFS 主要设计用于提供高性能、可扩展和高可用性的存储解决方案。然而,关于您提到的“文件格式”,这里有几个相关的概念需要澄清:
-
文件系统类型:CephFS 本身就是一种文件系统类型,就像 EXT4、XFS 或 BTRFS 等 Linux 文件系统。它处理文件的存储方式、元数据管理以及数据冗余和恢复等任务。
-
存储数据格式:CephFS 存储数据在后端的 Ceph 集群中,通常是以 RADOS(Reliable Autonomic Distributed Object Store)块为基础。这些数据块由 Ceph 内部以对象的形式管理,而不是传统的文件系统所使用的连续磁盘块。CephFS 通过其元数据服务器来管理文件系统的层次结构和文件元数据,而实际的文件数据被存储在这些对象中。
-
文件兼容性:对于终端用户来说,CephFS 提供了一个标准的 POSIX 文件系统接口,这意味着用户和应用程序可以像使用任何本地文件系统一样使用 CephFS,而无需担心后端存储的具体实现细节。因此,任何标准的文件类型(如文本文件、图像、视频等)都可以存储在 CephFS 中,而这些文件的格式是由创建它们的应用程序决定的,与 CephFS 无关。
-
访问和交互:CephFS 可以通过多种方式挂载和访问,包括内核模块、FUSE 客户端以及通过网络文件系统协议(如 NFS)。这些方法都提供对 CephFS 的透明访问,让它表现得就像一个普通的文件系统。
总的来说,CephFS 自身并没有所谓的“文件格式”,它提供的是文件系统服务,允许存储和访问各种格式的文件。用户层面看到的文件格式由具体的应用程序决定,CephFS 仅负责安全和效率地存储这些文件。如果您有关于如何在 CephFS 上操作特定类型文件的问题,或者需要进一步的帮助,随时欢迎提问!
创建用的yaml文件,rook给出的示例有问题,可以参考这个,此处不在重复yaml文件以及建立过程。
Rook-CephのCephFSを使ってWordpress環境の構築をする - Qiita
四、创建NFS导出
如果K8s工作集群和rook存储集群是分开的,那么需要创建NFS导出为K8s的工作集群使用。
但是问题是NFS挂载性能不行,因此高性能场景不建议使用NFS挂载。
五、CEPH调优
调整PG和PGP
在Ceph集群中,**放置组(Placement Groups,简称PG)和放置组的副本数量(PGP,Placement Group Placement)**是确保数据存储和检索的效率和一致性的关键概念。了解这两个概念有助于深入理解Ceph的工作原理和如何优化其性能。
PG(放置组)
放置组是Ceph用来组织和管理数据的一个基本单位。当数据存储到Ceph集群时,它们不是直接存储到物理硬盘上,而是先被划分为更小的单位,然后存储到这些放置组中。每个放置组对应一组OSD(对象存储设备),这些OSD负责存储该放置组内的数据。放置组的主要目的包括:
-
负载均衡:通过均匀分配数据到不同的放置组和OSD,Ceph能够确保没有单一的OSD过载,从而优化整个集群的性能和扩展性。
-
数据复制和恢复:在放置组内,Ceph通过复制同一数据到多个OSD来实现数据的高可用和容错。如果一个OSD发生故障,Ceph可以从其他OSD中的副本恢复数据。
PGP(放置组的副本数量)
PGP是指放置组的物理位置或其副本的放置策略。在Ceph的早期版本中,pg_num和pgp_num可以被独立设置,以允许细致控制放置组的数据分布,而不必重新映射整个放置组。这可以用来平滑地调整放置组的分布,而不会引起大规模的数据移动。但在最新的Ceph版本中,通常推荐保持pg_num和pgp_num一致,以简化管理并优化数据分布的一致性。
数据分布与CRUSH算法
Ceph使用CRUSH(Controlled Replication Under Scalable Hashing)算法来计算数据应该存储在哪个放置组以及这些放置组应该分布到哪些OSD上。CRUSH算法使得Ceph能够高效地扩展到数千个硬件节点,同时提供一致的数据分布和快速的数据检索能力。
调整PG的数量是一个复杂的操作,通常在集群规模变化或性能调优时进行。查看当前的PG数量和建议值,可以使用:
#获取pg和pgp数量
ceph osd pool get <pool-name> pg_num
ceph osd pool get <pool-name> pgp_num
ceph osd pool get nvme-replicapool pg_num
ceph osd pool get nvme-replicapool pgp_num
ceph osd pool get mynfs-metadata pg_num
ceph osd pool get nvme-replicapool pgp_num
ceph osd pool get mynfs-replicated pg_num
如果您有 50 多个 OSD,我们建议每个 OSD 大约 50-100 个 PG,以平衡资源使用量、数据持久性和分布。如果您没有 50 个 OSD,理想的做法是在 PG Count 中选择 Small Clusters。对于单个对象池,您可以使用以下公式来获取基准:
Total PGs = (Total_number_of_OSD * 100) / max_replication_count
其中,池大小 是复制池的副本数量,或者是纠删代码池的 K+M 和(由 ceph osd erasure-code-profile get返回)。
结算的结果往上取靠近2的N次方的值。比如总共OSD数量是160,复制份数3,pool数量也是3,那么按上述公式计算出的结果是1777.7。取跟它接近的2的N次方是2048,那么每个pool分配的PG数量就是2048。
调整pg数,调整pg数的大小,推荐的增长幅度为2的幂
设置命令如下:
ceph osd pool set <poolname> pg_num <new_pg_num>
ceph osd pool set nvme-replicapool pg_num 256
ceph osd pool set nvmefs-replicated pg_num 256
ceph osd pool set nvmefs-metadata pg_num 256
ceph osd pool set hddreplicapool pg_num 1024
ceph osd pool set mynfs-metadata pg_num 1024
ceph osd pool set mynfs-replicated pg_num 1024可以使用ceph -w来查看集群pg分布状态,并等待集群恢复正常(会引起部分pg的分布变化,但不会引起pg内的对象的变动)。
调整pgp,在pg增长之后,通过下面的命令,设置pgp和pg数保持一致,并触发数据平衡。
ceph osd pool set <poolname> pgp_num <new_pgpnum>
ceph osd pool set nvme-replicapool pgp_num 256
ceph osd pool set nvmefs-replicated pgp_num 256
ceph osd pool set nvmefs-metadata pgp_num 256
ceph osd pool set hddreplicapool pgp_num 1024
ceph osd pool set mynfs-metadata pgp_num 1024
ceph osd pool set mynfs-replicated pgp_num 1024参考:
3.3. PG Count Red Hat Ceph Storage 4 | Red Hat Customer Portal
CEPH系列之性能调优:怎样设置PG数量? - 大天使之剑 - twt企业IT交流平台
六、CEPH运维手册
https://lihaijing.gitbooks.io/ceph-handbook/content/Troubleshooting/troubleshooting_pg.html
https://access.redhat.com/documentation/zh-cn/red_hat_ceph_storage/4/html/administration_guide/placement-group-states_admin