若在阅读过程中有些知识点存在盲区,可以回到如何优雅的谈论大模型重新阅读。另外斯坦福2024人工智能报告解读为通识性读物。若对于如果构建生成级别的AI架构则可以关注AI架构设计。技术宅麻烦死磕LLM背后的基础模型。
序列模型的效率与有效性之间的权衡取决于状态编码(压缩)的程度:追求高效性一定要求具有较小的状态,追求有效性一定要求状态包含更多的上下文信息。而在Mamba中的指导思想是选择性:或者重点关注,或者过滤掉无关的输入从而具备较强的的上下文感知能力。

Mamba
若读者仔细的将前面的六个部分进行仔细的推敲和阅读,那么在这篇终章理解Mamba就轻松多。
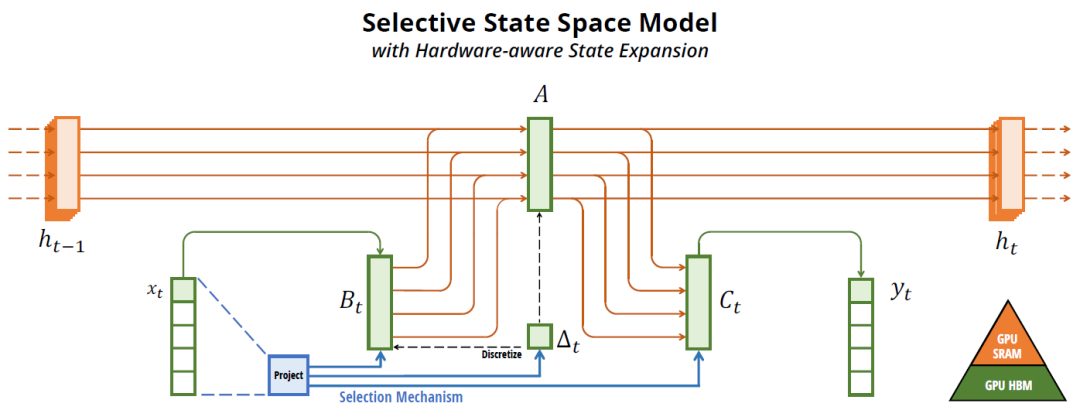
先来看看这幅经典的图,从图中可以看到在常规的状态空间模型SSM中,矩阵A、B和C都是固定,而在Mamba中加入了选择机制,矩阵B和C不再是固定矩阵,随着输入x而变化(某种程度而言,BC跟随时间或者步长的变化而变化)。因此Mamba不再是时不变系统了,而是时变系统。
图中有个离散化的参数∆t,它其实是离散化的一个参数。大白话的理解就是要是想忽略掉某次的输入那么∆t会比较小,要是想要稍微记久一点,那么∆t会相对大。∆t也是根据输入x进行变化的。另外从图上可以看出来状态都存储在GPU的高速SRAM中,而矩阵参数都存放在HBM中。
先来看看它的算法,不用害怕里面横七竖八的数学符号,左侧为S4的算法,右侧为Mamba的算法,Mamba有个另外的别名S6。

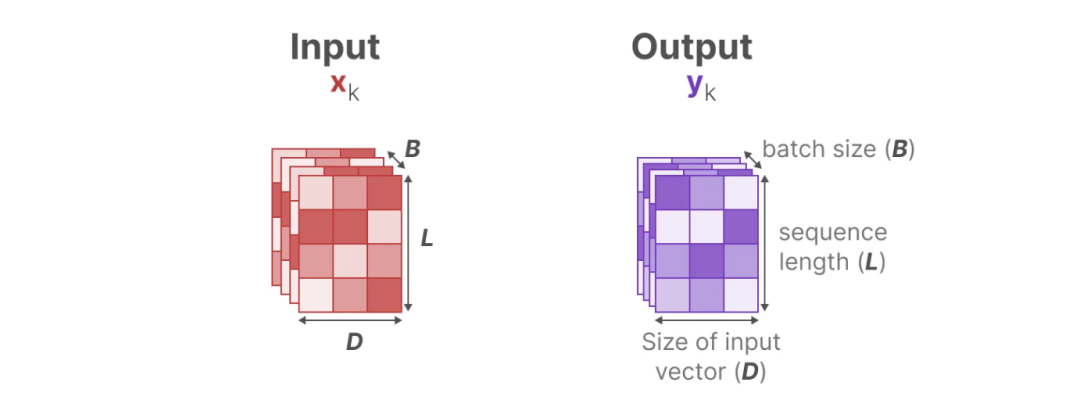
B: Batch Size(训练的批次大小)
L: Sequence Length (每句序列长度)
D: Size of the input vector (每个Token的向量长度,类似d_model)
N: Size of the hidden state h.(隐含层的长度)
| | |
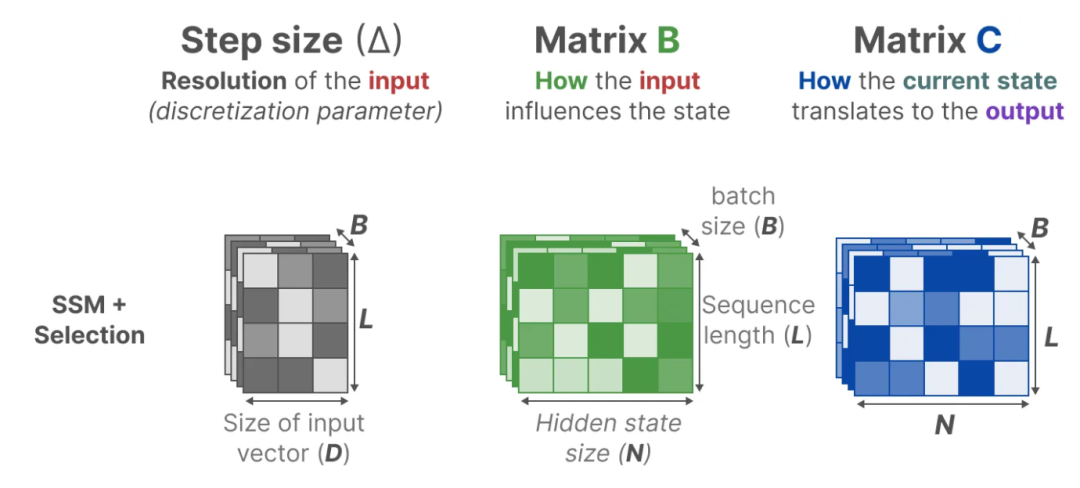
相对于S4而言,S6扩展了矩阵B/C/∆的维度,而且它们和输入x相关,同时这三者在运算过程中会作为参数离散化为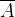
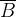

理解选择性
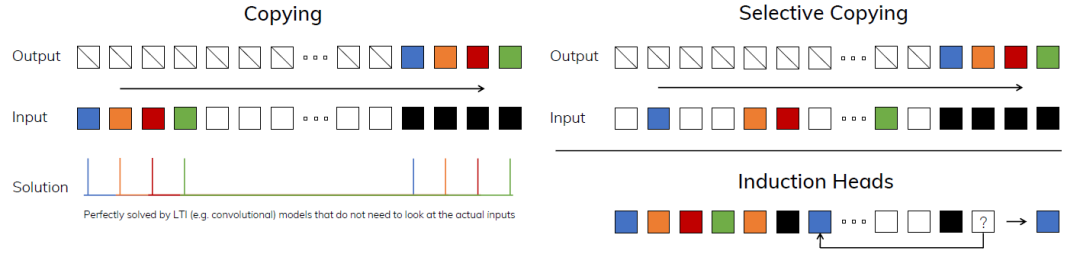
先来看看选择性机制的效果,传统SSM可以利用卷积核选择性将固定间隔的记忆内容输出(左图),而Mamba可以将不固定间隔的上下文内容输出,同时能够根据场景决定什么时候重置状态,这其实更加符合大语言模型的需求场景。
RNN的经典门控机制是Mamba选择机制的一个实例。RNN门控和连续时间系统离散化很早就有研究人员将他们建立联系。更广泛地说,∆在SSM的作用可以看成RNN门控机制。 换句话说,SSM的离散化是智能门控机制的原则基础。<是不是看到这里脑袋一片空白……>
不着急,看来那么先来看看下面的图片,Mamba块的输入x先经过两个线性变换,然后经过σ的激活函数在输送给SSM。还记得RNN中的激活函数没有,激活函数输出[0,1]之间。通过和输入x相乘决定让多少的信息通过,这就是门控。
那么回过来看看下面的定理:
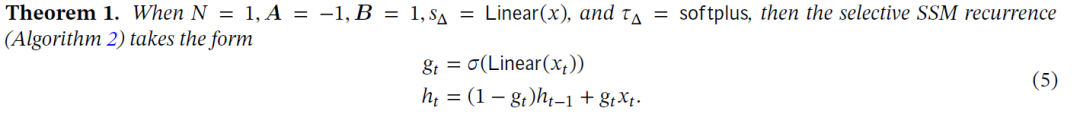
符号∆控制着“关注”或者“忽略”当前输入xt的平衡。它摇身一变,泛化为RNN的门(例如上面定理的
按照这种方式理解,直觉上是∆->∞ 代表系统更长时间地关注当前输入(因此“选择”它且忘记当前状态),而∆->0 表示被忽略的瞬态输入。

其他的特点
选择性机制:线性 RNN 在长距离竞技场基准测试中确实表现出色,但这并不意味着它们是很好的语言模型。对于语言建模,线性RNN的性能比 Transformer 差得多。正如Mamba论文中所指出的,其原因是线性 RNN 无法选择性地忘记输出向量中的信息。如果权重接近 0,则每次输入后输出向量将设置为 0,实际上模型将始终立即忘记当前输入之前的任何内容。 如果循环权重接近1,则输出向量在与权重相乘时不会改变。而大模型最重要的是根据看到的输入来决定何时存储信息以及何时忘记信息。
Mamba在此对每个输入向量应用线性函数,为该输入生成单独的权重向量,然后使用这些生成的权重执行循环扫描。这样,某些输入可以生成接近0的权重,从而从输出向量中删除信息。 至于如何使用稳定的配置避免Mamba的梯度消失和爆炸,Mamba原始论文没有提及。
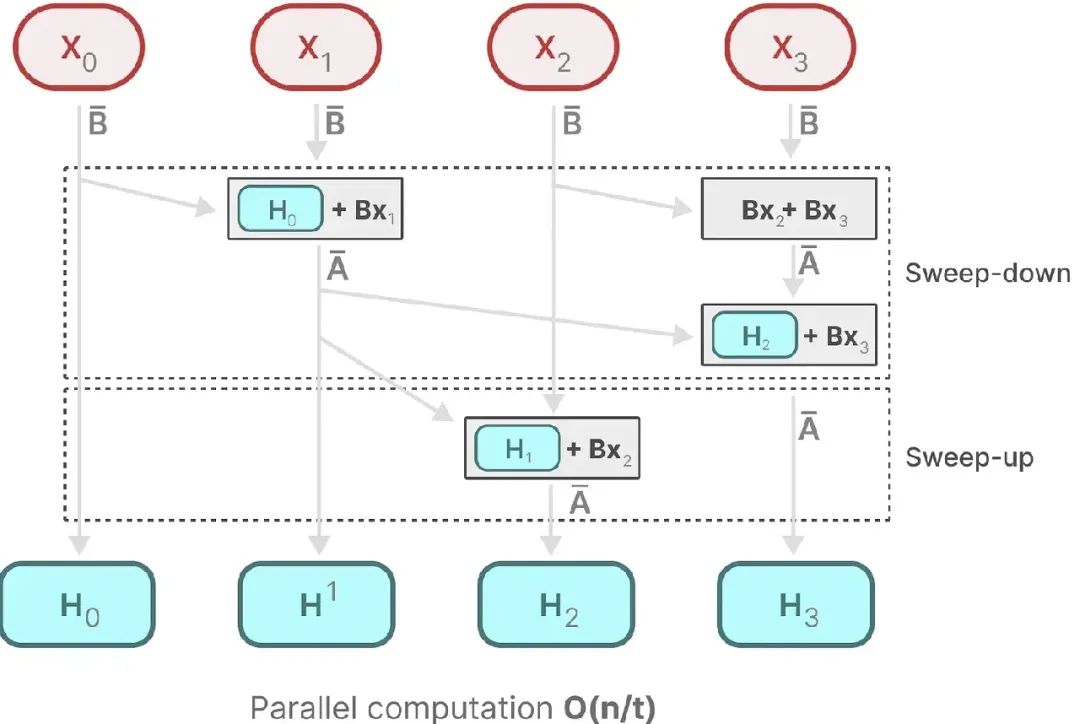
并行扫描:已经在Mamba5解释了原理,大家可以对照图推理。由于 Mamba是时变系统,无法使用卷积进行评估(还记得之前SSM的卷积表达模式没有)。但是它可以采用并行扫描算法进行并行化。
内存分配:Mamba还使用另一种技巧,即增加输出向量的大小。在标准RNN 中,输出向量与输入向量大小相同。Mamba将输出向量的大小扩展了16 倍。这使得它能够存储来自先前输入的更多信息。当然输出向量在传递到下一层之前被投影回原始大小。
通常这会使计算时间增加16倍,但事实证明,在GPU上Mamba层的主要瓶颈是在高性能内存中读取和写入数据所需的时间。GPU有两种类型的内存,SRAM和HBM(不明白的话,请跳转至此)。
GPU包含两种主要类型的内存:HBM (High Bandwidth memory)和SRAM (Static Random-Access memory)。HBM虽然带宽很高,但与更快但更小的SRAM相比,它的访问时间相对较慢。Mamba则使用SRAM在矩阵乘法期间进行快速访问,这是其计算的关键。
对于Mamba的递归操作,事实证明传输数据所花费的时间实际上比计算本身所花费的时间要大得多。 因此Mamba将输入向量和模型参数传输到SRAM,然后在单个块中计算整个Mamba操作,包括将输出投影回较小的原始大小,然后将结果写回HBM。这样,只需在高性能内存之间传输原始大小的向量,实际计算时间即便慢了16倍,但计算时间与传输时间相比非常小,不会真正影响总时间。

所有的离散化和计算都在SRAM内完成
重新计算:Mamba不保存大小为(B,L,D,N)的中间状态以避免内存爆炸。 然而中间状态对于向后传递计算新的梯度是必要,所以采用的方式是重新计算这些中间状态。
这么设计的原因是从HBM读取到SRAM的∆、A、B、C 和输出梯度的大小为 O(BLN + DN),并且输入梯度的大小也为O(BLN + DN),重新计算避免了从HBM读取O (BLND)的时间成本,这也意味着相对于读取写入,重新计算中间状态可以加速SSM的梯队传播。
内核融合:GPU复制数据的速度比计算操作的速度相对慢。为了让操作更快,Mamba融合CUDA内核生成自定义的CUDA内核,该内核依次执行操作,无需将中间结果复制到HBM(左图)。
| | |


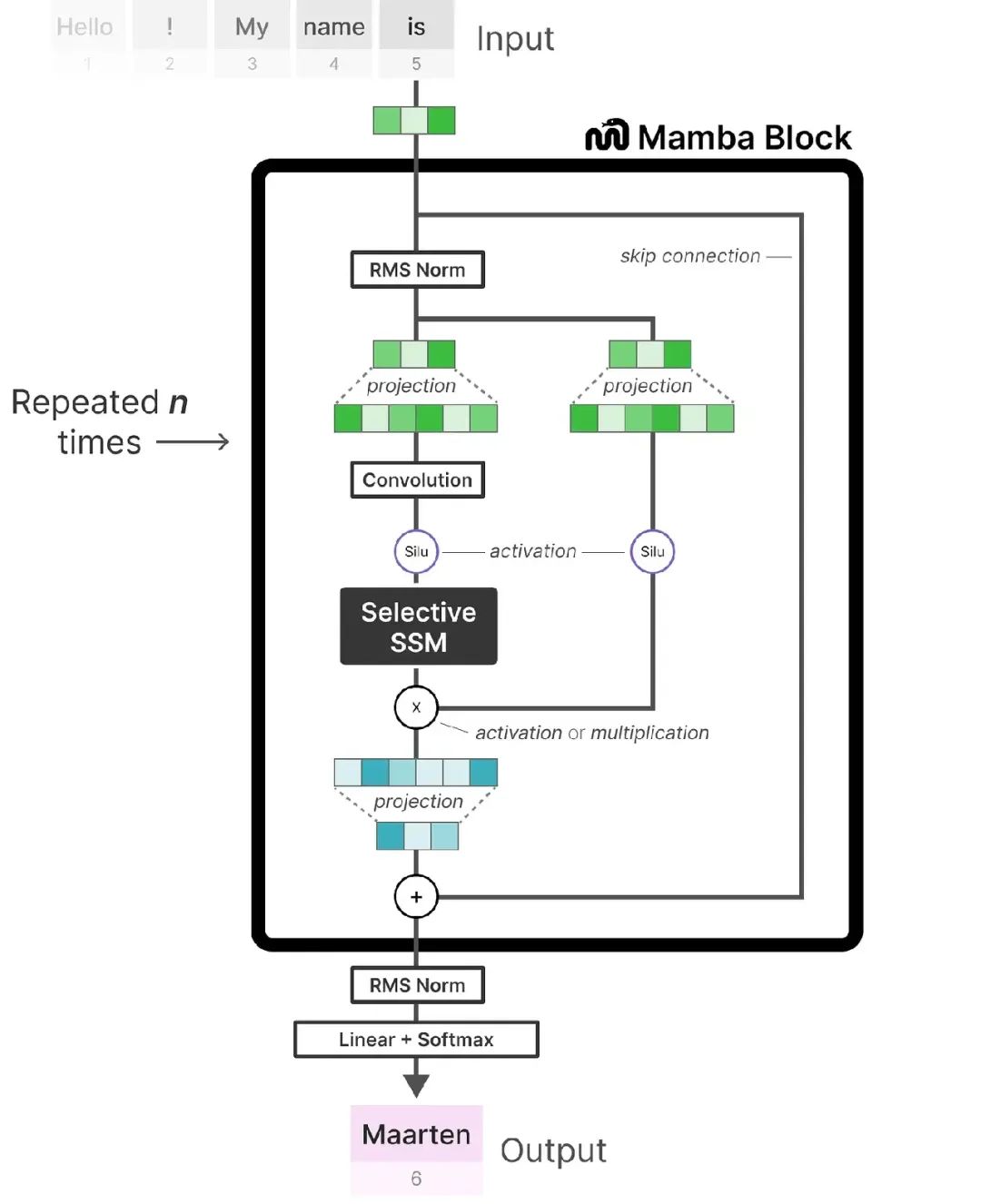
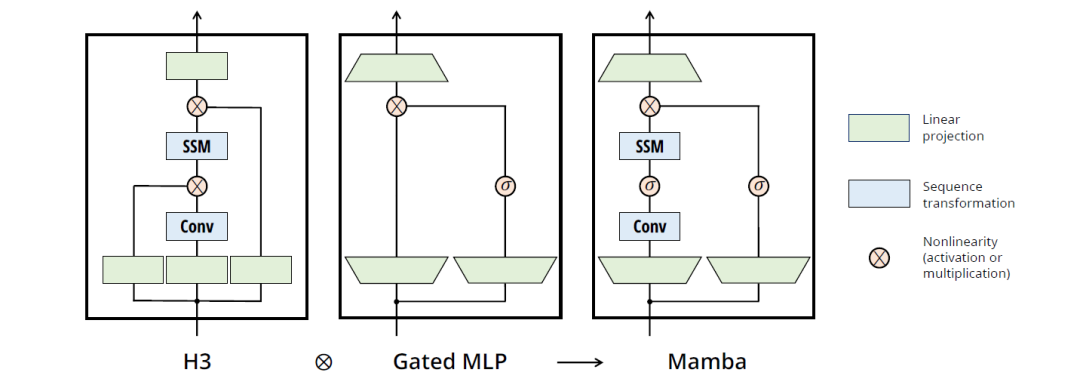
最后以Mamba的架构图进行收官,希望读者看到山顶的太阳,留下的更是难忘的路途风景。