一. 准备工作
1.1简单复习Scrapy知识
1.1.1 创建爬虫项目
scrapy startproject 项目的名称
1.1.2 项目组成
#项目组成:
# spiders
# __init__.py
# 自定义的爬虫文件.py ‐‐‐》由我们自己创建,是实现爬虫核心功能的文件
# __init__.py
# items.py ‐‐‐》定义数据结构的地方,是一个继承自scrapy.Item的类
# middlewares.py ‐‐‐》中间件 代理
# pipelines.py ‐‐‐》管道文件,里面只有一个类,用于处理下载数据的后续处理
# 默认是300优先级,值越小优先级越高(1‐1000)
# settings.py ‐‐‐》配置文件 比如:是否遵守robots协议,User‐Agent定义等
1.1.3 创建爬虫文件
-
要在spiders文件夹中去创建爬虫文件
-
cd 项目的名字\项目的名字\spiders
-
创建爬虫文件
scrapy genspider 爬虫文件的名字 要爬取的网页的地址
爬虫文件的基本组成:
#继承scrapy.Spider类
# name = 'baidu' ‐‐‐》 运行爬虫文件时使用的名字
# allowed_domains ‐‐‐》 爬虫允许的域名,在爬取的时候,如果不是此域名之下的
# url,会被过滤掉
# start_urls ‐‐‐》 声明了爬虫的起始地址,可以写多个url,一般是一个
# parse(self, response) ‐‐‐》解析数据的回调函数
# response.text ‐‐‐》响应的是字符串
# response.body ‐‐‐》响应的是二进制文件
# response.xpath() --‐》xpath方法的返回值类型是selector列表
# extract() ‐‐‐》提取的是selector对象的是data
# extract_first() ‐‐‐》提取的是selector列表中的第一个数据
#爬虫的名字,用于爬虫的时候使用的值
#允许访问的域名
#起始的url地址 指的是第一次要访问的域名
#是执行了start_urls之后执行的方法,方法中的response就是返回的那个对象
#相当于response = urllib.request.urlopen()
# response = requests.get()
1.1.4 运行爬虫代码
scrapy crawl 爬虫名称
注意:应在spiders文件夹内执行
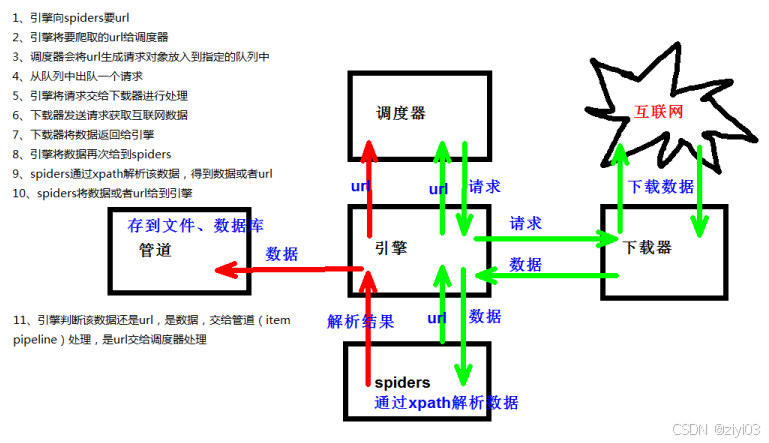
1.1.5 Scrapy架构组成
# (1)引擎 ‐‐‐》自动运行,无需关注,会自动组织所有的请求对象,分发给下载器
# (2)下载器 ‐‐‐》从引擎处获取到请求对象后,请求数据
# (3)spiders ‐‐‐》Spider类定义了如何爬取某个(或某些)网站。包括了爬取的动作(例
#如:是否跟进链接)以及如何从网页的内容中提取结构化数据(爬取item)。 换句话说,Spider就是您定义爬取的动作及
#分析某个网页(或者是有些网页)的地方。
# (4)调度器 ‐‐‐》有自己的调度规则,无需关注
# (5)管道(Item pipeline) ‐‐‐》最终处理数据的管道,会预留接口供我们处理数据
#当Item在Spider中被收集之后,它将会被传递到Item Pipeline,一些组件会按照一定的顺序执行对Item的处理。
#每个item pipeline组件(有时称之为“Item Pipeline”)是实现了简单方法的Python类。他们接收到Item并通过它执#行
#一些行为,同时也决定此Item是否继续通过pipeline,或是被丢弃而不再进行处理。
# 以下是item pipeline的一些典型应用:
# 1. 清理HTML数据
# 2. 验证爬取的数据(检查item包含某些字段)
# 3. 查重(并丢弃)
# 4. 将爬取结果保存到数据库中
1.2 目标确定
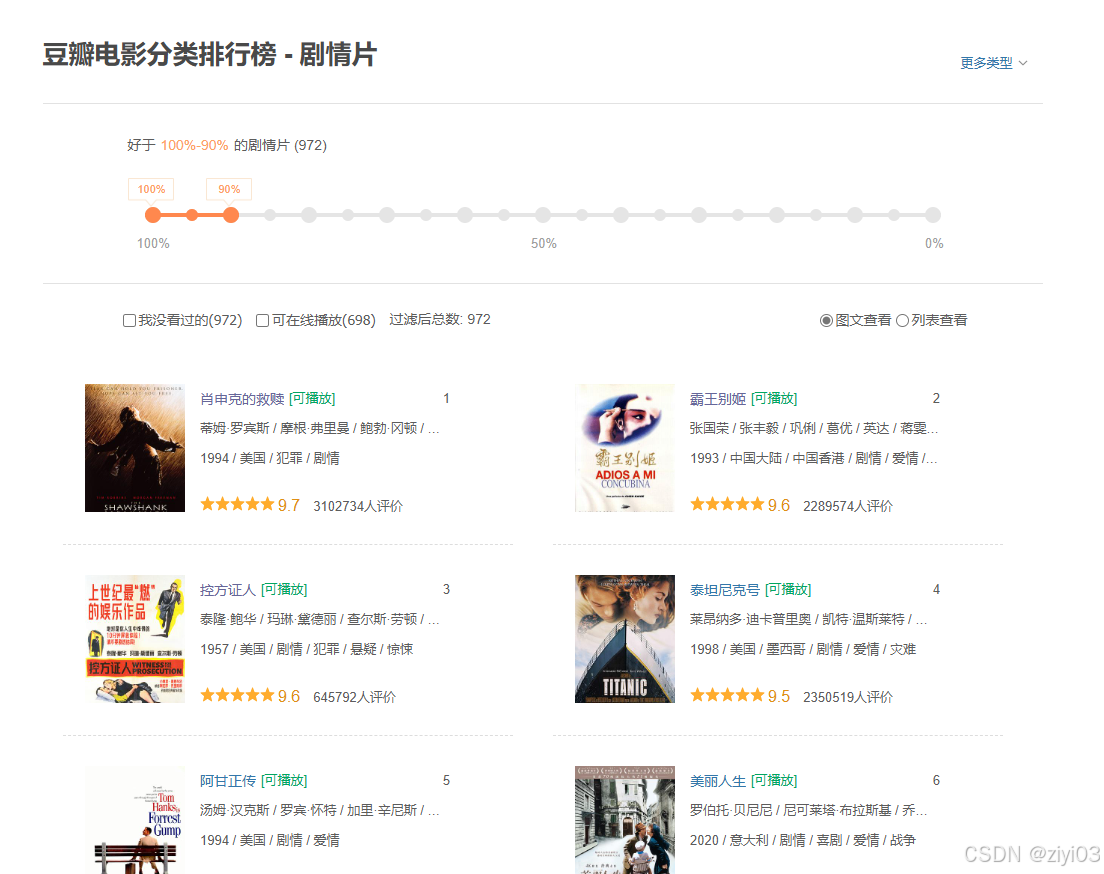
-
按排名爬取图片以及电影名和制片地区/国家,上映年
如:

综上所述,我们需要按顺序爬取电影图片,电影名字,制片地区/国家。
1.3 文档建立
-
找到适合自己的位置,创建项目名,我这里是在F盘下创建
scrapy_project文件夹,用于存储整个项目文件; -
在
scrapy_project中创建images文件夹,用于存放爬取的电影图片,每一张被爬取的电影名字为(电影名字+上映年); -
创建
豆瓣网剧情片排行榜.xlsx文件,其中存放电影名字,制片地区/国家。
二. 编写程序
2.1 创建Scrapy项目
-
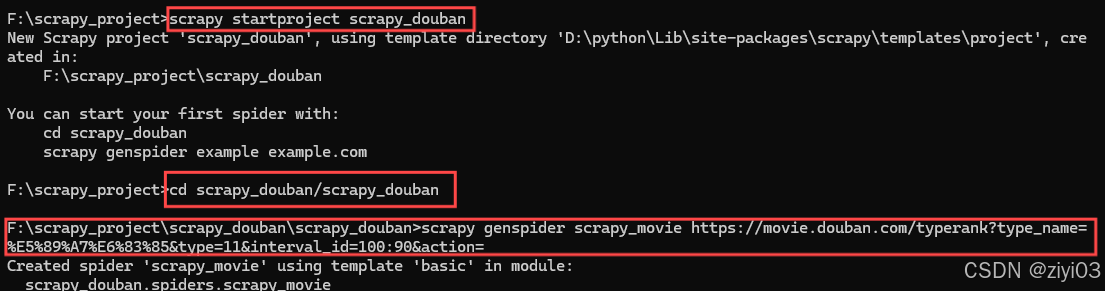
进入scrapy_project文件夹中,点击地址栏,输入cmd,进入控制台,在控制台中输入:
scrapy strproject scrapy_douban -
cd 项目的名字\项目的名字\spiders,进入spiders文件夹下:
cd scrapy_douban\scrapy_douban\scrapy_douban -
创建爬虫文件(
scrapy genspider 爬虫文件的名字 要爬取的网页的地址):scrapy genspider scrapy_movie https://movie.douban.com/typerank?type_name=%E5%89%A7%E6%83%85&type=11&interval_id=100:90&action=
2.2 检查是否有反爬
-
通过pycharm打开scrapy_project文件夹,点击scrapy_douban文件夹下的scrapy_douban文件夹,打开spiders文件夹,进入
scrapy_moive.py文件,在parse函数中输入:print("检查是否有反爬")
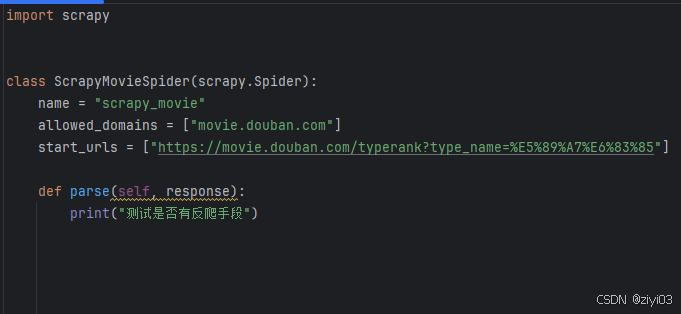
-
进入spiders文件中,在地址栏输入cmd,在弹出的对话框中输入
scrapy crawl 爬虫名称运行爬虫项目scrapy crawl scrapy_movie -
结果中并没有打印输出
检查是否有反爬,并且结果中出现下图说明了:
- 豆瓣网站使用
robots.txt文件来限制爬虫访问某些页面 - 需要使用User-Agent模拟浏览器行为,避免被网站识别为爬虫
- 豆瓣网站使用
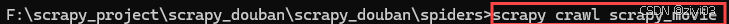

2.3 绕过反爬手段
打开settings.py文件中:
-
禁用
robots.txt规则(20行)注释掉
ROBOTSTXT_OBEY = True -
设置
User-Agent(43行)取消对
DEFAULT_REQUEST_HEADERS的注释,并添加'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/131.0.0.0 Safari/537.36 Edg/131.0.0.0',


2.4 运行爬虫代码
进入spiders文件夹,进入控制台输入(scrapy crawl 爬虫名称)
scrapy crawl scrapy_movie
结果中出现检查是否有反爬,说明已经绕过反爬虫手段

2.3 爬取电影图片,电影名称,制片地区/国家,上映年
2.3.1找出网页结构
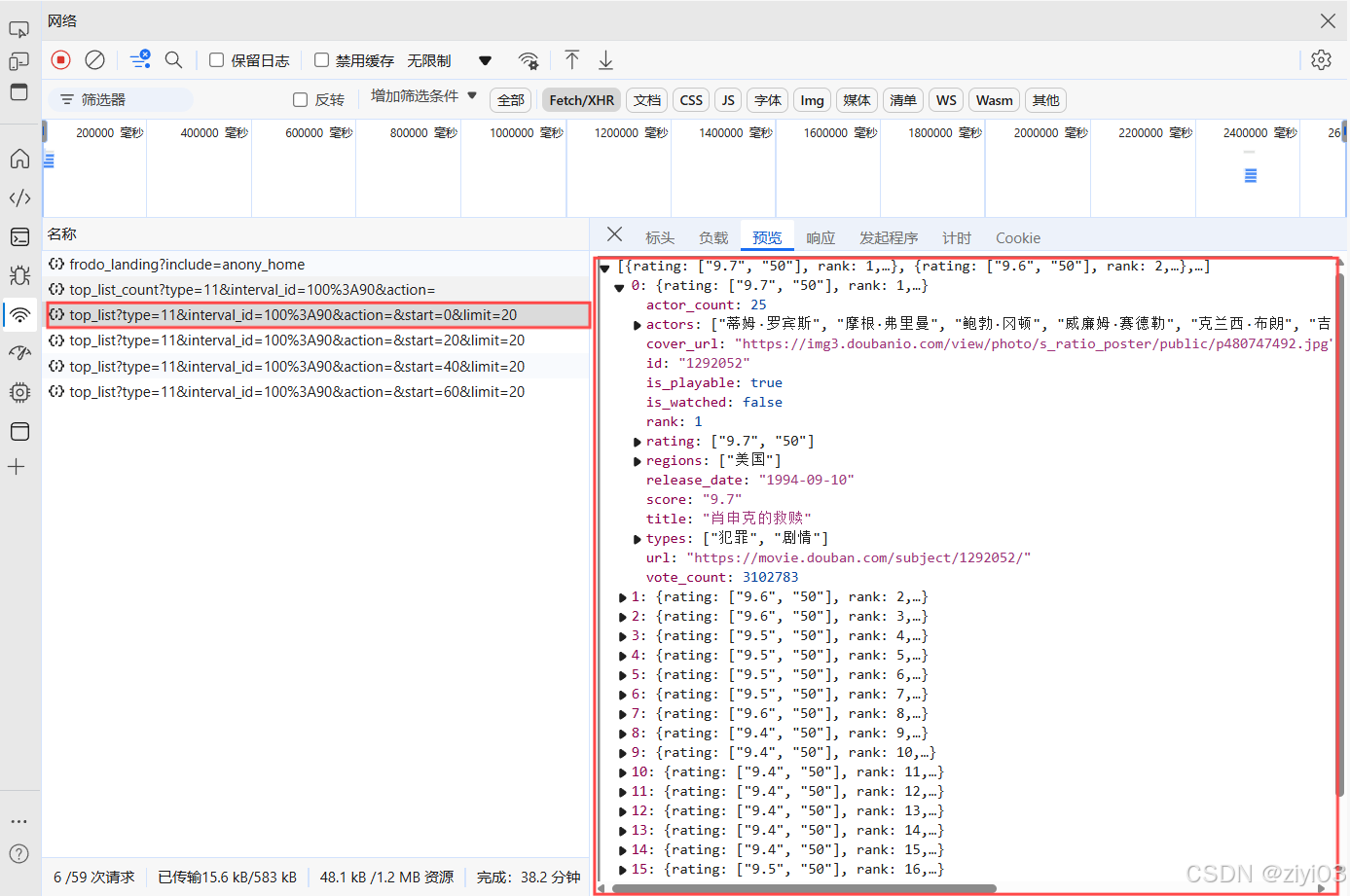
进入豆瓣电影分类排行榜-剧情片,按下F12,打开开发者模式,点击网页,选择Fetch/XHR,发现:
-
不断向下滑,发现随着网页的不管更新变多,但整个网页并没有刷新,并且网页的网址并没有发生改变,所以该网页采用了Ajax技术;
-
随着不断向下滑,发现开发者控制台内容不断增多,点击每条数据,选择
预览,发现json数据中记录了网页中记录了电影图片,电影名称,制片地区/国家,上映年,详情页等数据; -
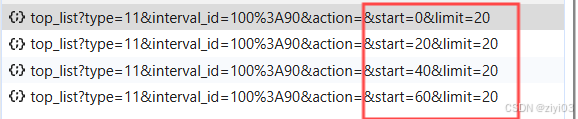
随着网页的不断更新,网页的每次增多会出现20条数据,我将每次增多的20条数据成为一页,并且发现规律:
#page 1 2 3 4 #start 0 20 40 60 #推出 start = (page-1) * 20我们注意到start这一项,第一页的startt为0,第二页为20,依次推列。在程序中这一项用于控制抓取第一页,但是也要给一个范围,不可能无限大,否则会报错,可以去看看一共有多少页视频,也可以写一个异常捕获机制,捕捉到请求出错则退出。我这里图片仅仅是示范,所以需要500条数据时,start为480,此时的page为25。
-
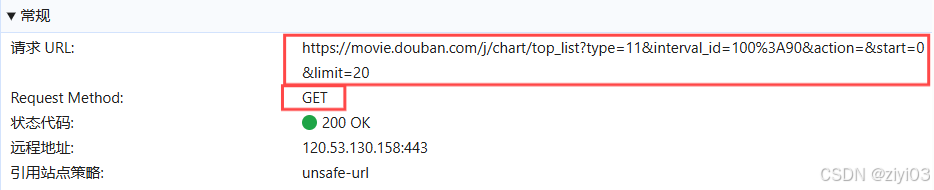
查看
标头,获取url的请求方式
2.4 获取前500条电影的json数据
通过pycharm文件打开spiders文件夹下的scrapy_movie文件
def parse(self, response):
#每一页含有20条电影数据,因此需要25页数据
for page in range(1, 26):
#获取每一页的json数据
source = self.get_json_request(page)
def get_json_request(self, page):
#每页含有共同的地址部分
base_url = 'https://movie.douban.com/j/chart/top_listtype=11&interval_id=100%3A90&action=&'
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/131.0.0.0 Safari/537.36 Edg/131.0.0.0',
}
#定制每页特有的地址部分
data = {
'start': (page - 1) * 20,
'limit': 20
}
#data编码
data = urllib.parse.urlencode(data)
#每页的请求url
url = base_url + data
#定制请求对象
request = urllib.request.Request(url=url, headers=headers)
#获取响应数据
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
source = json.loads(content)
#返回每一页的json数据
return source
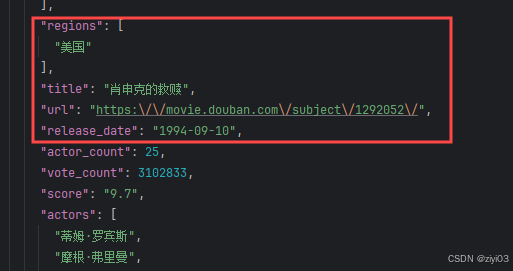
下载一页json数据,发现:
-
电影名,上映日期,详情页地址是字符串形式,而制片地区/国家是数组形式
2.5 将电影名字,制片地区/国家,上映年写入到xlsx文件中
#用于记录当前下一次数据所在的行数
num = 2
workbook = load_workbook(filename='F:/scrapy_project/豆瓣网剧情片排行榜.xlsx')
def parse(self, response):
sheet = self.workbook.active
sheet["A1"] = "电影名"
sheet["B1"] = "制片地区/国家"
sheet["C1"] = "上映日期"
for page in range(1, 26):
source = self.get_json_request(page)
self.write_xlsx(source)
self.workbook.save(filename='F:/scrapy_project/豆瓣网剧情片排行榜.xlsx')
def write_xlsx(self, source):
count = 0
# 每一页中只有20个电影数据,下表从0开始
while count < 20:
regions = ''
sheet = self.workbook.active
# 将数据写入对应的列下面
sheet[f"A{self.num}"] = source[count]['title']
if (type(source[count]['regions']) == list):
for region in source[count]['regions']:
regions += region + ' '
sheet[f"B{self.num}"] = regions
sheet[f"C{self.num}"] = source[count]['release_date']
self.num += 1 # 递增 num 属性
count += 1
2.6 下载电影图片
在items.py文件中
import scrapy
class ScrapyDoubanItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
# 电影图片
src = scrapy.Field()
# 电影名称
name = scrapy.Field()
# 电影上映年
movie_year = scrapy.Field()
在settings.py文件中,打开管道(67行)
ITEM_PIPELINES = {
"scrapy_project.pipelines.ScrapyProjectPipeline": 300,
}
在scrapy_movie.py文件中
def parse(self, response):
for page in range(1, 26):
source = self.get_json_request(page)
self.write_xlsx(source)
index = 0
while index < 20:
src = source[index]['cover_url']
name = source[index]['title']
movie_year = source[index]['release_date']
movies = ScrapyDoubanItem(src=src, name=name, movie_year=movie_year)
yield movies
index += 1
scrapy_movie.py的全部代码为:
import scrapy
import urllib.request
import urllib.parse
import json
from openpyxl import load_workbook
from scrapy_douban.items import ScrapyDoubanItem
class ScrapyMovieSpider(scrapy.Spider):
name = "scrapy_movie"
allowed_domains = ["movie.douban.com"]
start_urls = ["https://movie.douban.com/typerank?type_name=%E5%89%A7%E6%83%85"]
num = 2
workbook = load_workbook(filename='F:/scrapy_project/豆瓣网剧情片排行榜.xlsx')
def parse(self, response):
sheet = self.workbook.active
sheet["A1"] = "电影名"
sheet["B1"] = "制片地区/国家"
sheet["C1"] = "上映日期"
for page in range(1, 26):
source = self.get_json_request(page)
self.write_xlsx(source)
index = 0
while index < 20:
src = source[index]['cover_url']
name = source[index]['title']
movie_year = source[index]['release_date']
movies = ScrapyDoubanItem(src=src, name=name, movie_year=movie_year)
yield movies
index += 1
self.workbook.save(filename='F:/scrapy_project/豆瓣网剧情片排行榜.xlsx')
def get_json_request(self, page):
base_url = 'https://movie.douban.com/j/chart/top_list?type=11&interval_id=100%3A90&action=&'
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/131.0.0.0 Safari/537.36 Edg/131.0.0.0'
}
data = {
'start': (page-1) * 20,
'limit': 20
}
# data编码
data = urllib.parse.urlencode(data)
url = base_url + data
request = urllib.request.Request(url=url, headers=headers)
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
source = json.loads(content)
return source
def write_xlsx(self, source):
count = 0
while count < 20:
regions = ''
sheet = self.workbook.active
sheet[f"A{self.num}"] = source[count]['title']
if (type(source[count]['regions']) == list):
for region in source[count]['regions']:
regions += region + ' '
sheet[f"B{self.num}"] = regions
sheet[f"C{self.num}"] = source[count]['release_date']
self.num += 1 # 递增 num 属性
count += 1
三.运行代码
进入F:\scrapy_project\scrapy_douban\scrapy_douban\spiders在地址栏中输入cmd打开控制台,输入scrapy crawl scrapy_movie运行程序;
查看images文件夹
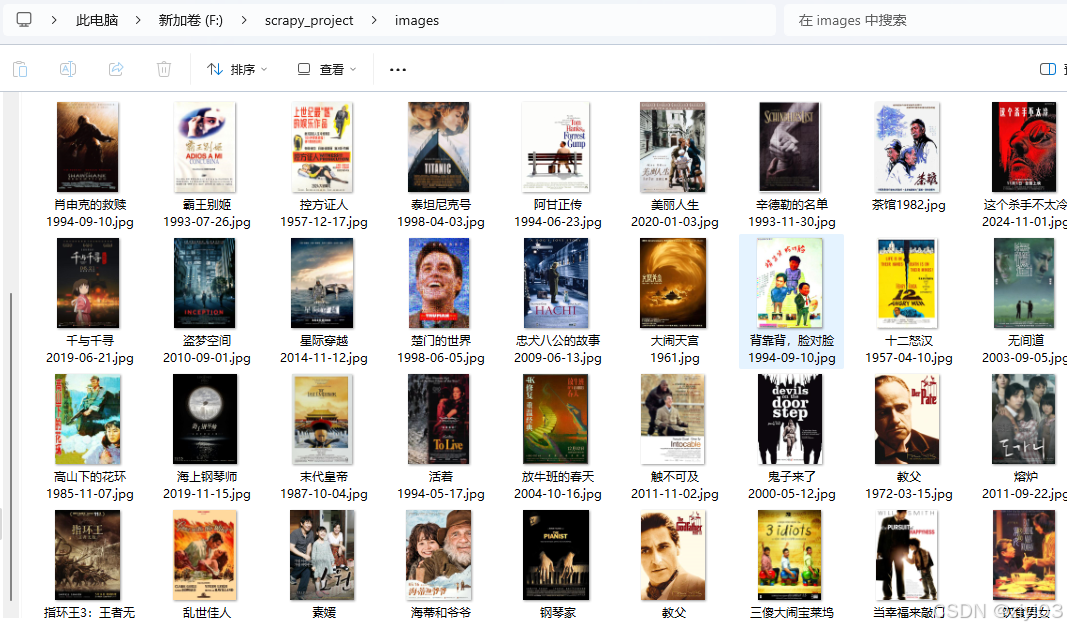
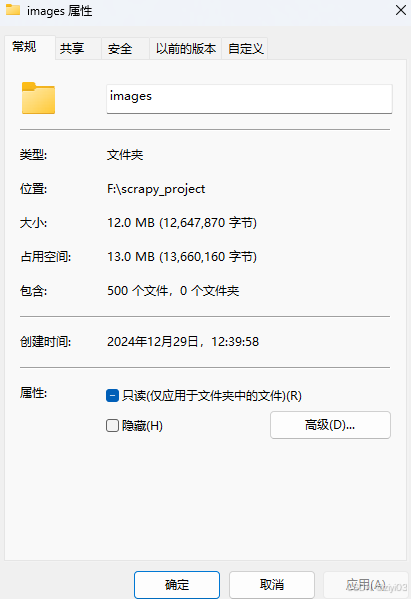
查看所有的文件数量
打开豆瓣网剧情片排行榜.xlsx,检查数量,名称是否正确
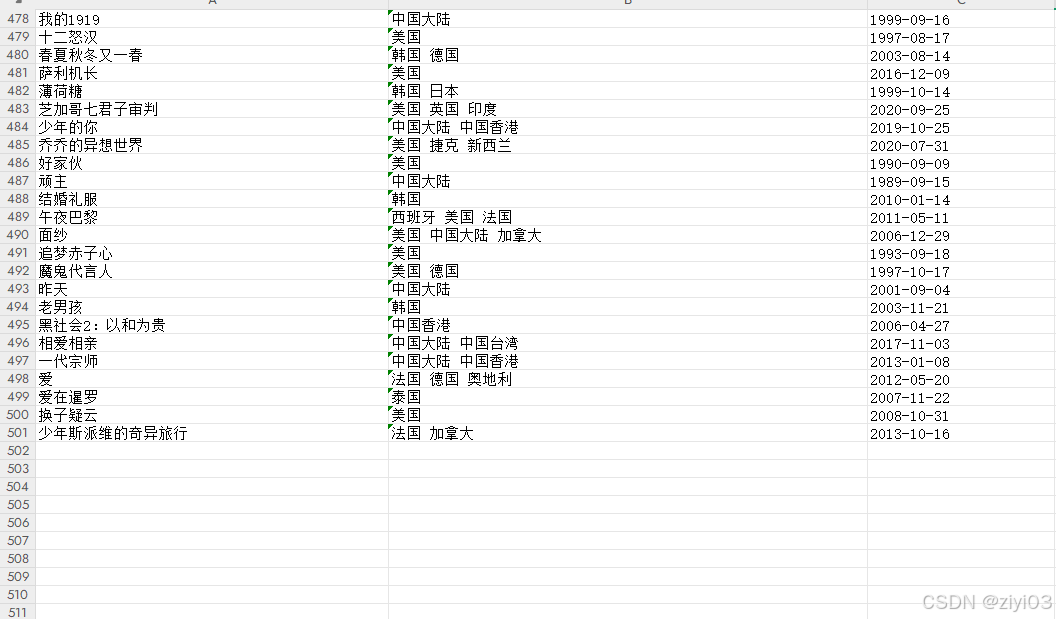
说明爬虫程序成功运行。
最后,该文章部分内容来自尚硅谷爬虫教学视频,如有错误,欢迎大家批评指正。
完整代码(https://gitee.com/jkeremy/python_projects)