声明
-
本精要由珠海科技学院学生自行从课本教材和课堂笔记整理,用于珠海科技学院大数据技术期末复习,不作商业用途。
-
本精要的参考教材是由人民邮电出版社出版的厦门大学林子雨老师的《大数据技术原理与应用(第三版) 》,同时也是珠海科技学院大数据技术的课堂教材(2024—2025学年)。精要中标注的页码均为该书页码。
-
本精要只摘录课堂重点及可能的考试重点,遵循的原则是“多一个字不多,少一个字不少”,对细节部分和考纲无关内容不会过多阐述,只用于巩固复习和考前备战,如需系统学习大数据技术请参考相关书籍和课程。
-
对于本精要的超重点部分会用高亮提示,关键词部分会用加粗提示。
-
在每章节末尾附有配套习题与答案,做到了以学促练,以练督学,学练一体。亦可根据自身的需要,通过目录跳转到想复习的部分进行针对性地学习和练习。
-
更新版本:已完结。
第一章大数据概述
1.1大数据时代
(1)三次信息化浪潮、每次解决的问题、技术 P3
| 信息化浪潮 | 发生时间 | 标志 | 解决的问题 | 代表企业 |
|---|---|---|---|---|
| 第一次信息化浪潮 | 1980 年前后 | 个人计算机 | 信息处理 | Intel、AMD、IBM、苹果、微软、联想、戴尔、惠普等 |
| 第二次信息化浪潮 | 1995 年前后 | 互联网 | 信息传输 | 雅虎、谷歌、阿里巴巴、百度、腾讯等 |
| 第三次信息化浪潮 | 2010 年前后 | 大数据、云计算和物联网 | 信息爆炸 | 亚马逊、谷歌、IBM、VMware、Palantir、Hortonworks、Cloudera、阿里云等 |
(2)大数据技术支撑-三个方面 P3-P5
- 存储设备容量不断增加
- CPU 处理能力大幅提升
- 网络带宽不断增加
(3)数据产生方式变革-三个阶段 P5-P6
| 阶段 | 时间 | 内容 |
|---|---|---|
| 第一阶段:萌芽期 | 20世纪90年代 ∼ \sim ∼ 21世纪初 | 随着数据挖掘理论和数据库技术的逐步成熟,一批商业智能工具和知识管理技术开始被应用,如数据仓库、专家系统、知识管理系统等 |
| 第二阶段:成熟期 | 21世纪前10年 | Web 2.0应用迅猛发展,非结构化数据大量产生,传统处理方法难以应对,带动了大数据技术的快速突破,大数据解决方案逐渐走向成熟,形成了并行计算与分布式系统两大核心技术,谷歌的GFS和MapReduce等大数据技术受到追捧,Hadoop平台开始盛行 |
| 第三阶段:大规模应用期 | 2010年以后 | 大数据应用渗透各行各业,数据驱动决策,信息社会智能化程度大幅提高 |
1.2大数据概念-4V特点 P8-P10
大数据的 4 个“V”,或者说是大数据的 4 个特点,包含 4 个层面:数据量大(Volume)、数据类型繁多(Variety)、处理速度快(Velocity)和价值密度低(Value)。
1.3大数据的影响-5个方面的影响 P10-P14
大数据对科学研究、思维方式、社会发展、就业市场和人才培养都具有重要而深远的影响。
-
科学研究方面,大数据使人类科学研究在经历了实验科学、理论科学、计算科学 3 种范式之后,迎来了第 4 种范式—数据密集型科学;
-
在思维方式方面,大数据具有“全样而非抽样、效率而非精确、相关而非因果”三大显著特征,完全颠覆了传统的思维方式;
-
在社会发展方面,大数据决策逐渐成为一种新的决策方式,大数据应用有力促进了信息技术与各行业的深度融合,大数据开发大大推动了新技术和新应用不断涌现;
-
在就业方面,大数据的兴起使得数据科学家成为热门人才;
-
在人才培养方面,大数据的兴起将在很大程度上改变我国高校信息技术相关专业的现有教学和科研体制。
1.4大数据的应用 P15(结合第四篇的大数据应用理解)
大数据无处不在,包括制造、金融、汽车、互联网、餐饮、电信、能源、物流、城市管理、生物医学、体育和娱乐等在内的社会各个行业/领域都已经融入了大数据。
| 行业/领域 | 大数据的应用 |
|---|---|
| 制造 | 利用工业大数据提升制造业水平,包括产品故障诊断与预测、分析工艺流程、改进生产工艺、优化生产过程能耗、工业供应链分析与优化、生产计划与排程 |
| 金融 | 大数据在高频交易、社交情绪分析和信贷风险分析三大金融创新领域发挥重要作用 |
| 汽车 | 利用大数据和物联网技术实现的无人驾驶汽车,在不远的未来将走入我们的日常生活 |
| 互联网 | 借助大数据技术,可以分析客户行为,进行商品推荐和有针对性地广告投放 |
| 餐饮 | 利用大数据实现餐饮O20模式,彻底改变传统餐饮经营方式 |
| 电信 | 利用大数据技术实现客户离网分析,及时掌握客户离网倾向,出台客户挽留措施 |
| 能源 | 随着智能电网的发展,电力公司可以掌握海量的用户用电信息,利用大数据技术分析用户用电模式,可以改进电网运行,合理地设计电力需求响应系统,确保电网运行安全 |
| 物流 | 利用大数据优化物流网络,提高物流效率,降低物流成本 |
| 城市管理 | 可以利用大数据实现智能交通、环保监测、城市规划和智能安防 |
| 生物医学 | 大数据可以帮助我们实现流行病预测、智慧医疗、健康管理,还可以帮助我们解读DNA,了解更多的生命奥秘 |
| 体育和娱乐 | 大数据可以帮助我们训练球队,预测比赛结果,以及决定投拍哪种题材的影视作品 |
| 安全领域 | 政府可以利用大数据技术构建起强大的国家安全保障体系,企业可以利用大数据抵御网络攻击,警察可以借助大数据来预防犯罪 |
| 个人生活 | 大数据还可以应用于个人生活,利用与每个人相关联的“个人大数据”,分析个人生活行为习惯,为其提供更加周到的个性化服务 |
1.5大数据的关键技术 P16页表格的四个技术层面及功能
当人们谈到大数据时,往往并非仅指数据本身,而是数据和大数据技术这二者的综合。所谓大数据技术,是指伴随着大数据的采集、存储、分析和结果呈现的相关技术,是使用非传统的工具来对大量的结构化、半结构化和非结构化数据进行处理,从而获得分析和预测结果的一系列数据处理和分析技术。
| 大数据技术层面 | 功能 |
|---|---|
| 数据采集与预处理 | 利用ETL工具将分布在异构数据源中的数据,如关系数据、平面数据文件等,抽取到临时中间层后进行清洗、转换、集成,最后加载到数据仓库或数据集市中,成为联机分析处理、数据挖掘的基础;也可以利用日志采集工具(如Flume、Kafka等)把实时采集的数据作为流计算系统的输入,进行实时处理分析 |
| 数据存储和管理 | 利用分布式文件系统、数据仓库、关系数据库、NoSQL数据库、云数据库等,实现对结构化、半结构化和非结构化海量数据的存储和管理 |
| 数据处理与分析 | 利用分布式并行编程模型和计算框架,结合机器学习和数据挖掘算法,实现对海量数据的处理和分析;对分析结果进行可视化呈现,帮助人们更好地理解数据、分析数据 |
| 数据安全和隐私保护 | 在从大数据中挖掘潜在的巨大商业价值和学术价值的同时,构建数据安全体系和隐私数据保护体系,有效保护数据安全和个人隐私 |
1.6大数据计算模式 -典型模式+针对的问题/数据+代表框架 P17-P18
| 大数据计算模式 | 解决问题 | 代表产品 |
|---|---|---|
| 批处理计算 | 针对大规模数据的批量处理 | MapReduce、Spark等 |
| 流计算 | 针对流数据的实时计算 | Flink、Storm、S4、Flume、Streams、Puma、DStream、Super Mario、银河流数据处理平台等 |
| 图计算 | 针对大规模图结构数据的处理 | Pregel、GraphX、Giraph、PowerGraph、Hama、Golden Orb等 |
| 查询分析计算 | 大规模数据的存储管理和查询分析 | Dremel、Hive、Cassandra、Impala等 |
1.7大数据产业 P18-19页的表格
大数据产业是指一切与支撑大数据组织管理和价值发现相关的企业经济活动的集合。大数据产业包括 IT 基础设施层、数据源层、数据管理层、数据分析层、数据平台层和数据应用层。
| 产业层次 | 包含内容 |
|---|---|
| IT基础设施层 | 包括提供硬件、软件、网络等基础设施以及提供咨询、规划和系统集成服务的企业,比如提供数据中心解决方案的IBM、惠普和戴尔等,提供存储解决方案的EMC, 提供虚拟化管理软件的微软、思杰、SUN、Red Hat等 |
| 数据源层 | 大数据生态圈里的数据提供者,是生物(生物信息学领域的各类研究机构)大数据、交通(交通主管部门)大数据、医疗(各大医院、体检机构)大数据、政务(政府部门)大数据、电商(淘宝、天猫、苏宁云商、京东等电商)大数据、社交网络(微博、微信等)大数据、搜索引擎(百度、谷歌等)大数据等各种数据的来源 |
| 数据管理层 | 包括数据抽取、转换、存储和管理等服务的各类企业或产品,如分布式文件系统(如Hadoop的HDFS和谷歌的GFS)、ETL工具(Informatica、Datastage、Kettle等)、数据库和数据仓库 (Oracle、MySQL、SQL Server、HBase、GreenPlum等) |
| 数据分析层 | 包括提供分布式计算、数据挖掘、统计分析等服务的各类企业或产品,如分布式计算框架 MapReduce、统计分析软件SPSS和SAS、数据挖掘工具Weka、数据可视化工具Tableau、BI 工具(MicroStrategy、Cognos、BO)等 |
| 数据平台层 | 包括提供数据分享平台、数据分析平台、数据租售平台等服务的企业或产品,如阿里巴巴、谷歌、中国电信、百度等 |
| 数据应用层 | 提供智能交通、智慧医疗、智能物流、智能电网等行业应用的企业、机构或政府部门,如交通主管部门、各大医疗机构、菜鸟网络、国家电网等 |
1.8大数据与云计算、物联网
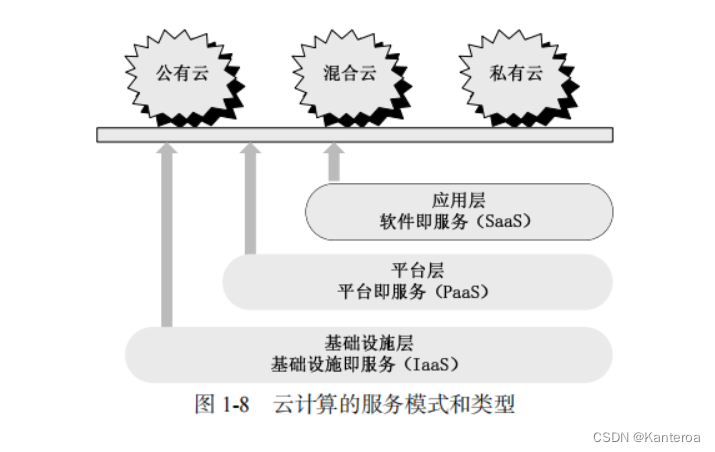
(1)云计算的概念及三种服务模式 P19-P20
- 云计算的概念
云计算实现了通过网络提供可伸缩的、廉价的分布式计算能力,用户只需要在具备网络接入条件的地方,就可以随时随地获得所需的各种 IT 资源。云计算代表了以虚拟化技术为核心、以低成本为目标的、动态可扩展的网络应用基础设施,是近年来最有代表性的网络计算技术与模式。
- 云计算的3 种服务模式
云计算包括 3 种典型的服务模式(见图 1-8),即基础设施即服务(Infrastructure as a Service,IaaS)、平台即服务(Platform as a Service,PaaS)和软件即服务(Software as a Service,SaaS)。IaaS 将基础设施(计算资源和存储)作为服务出租,PaaS 把平台作为服务出租,SaaS 把软件作为服务出租。
(2)物联网的概念 P23
物联网是物物相连的互联网,是互联网的延伸,它利用局部网络或互联网等通信技术把传感器、控制器、计算机、人员和物等通过新的方式连在一起,形成人与物、物与物相连,实现信息化和远程管理控制。
(3)物联网的应用形式 P25
物联网已经广泛应用于智能交通、智慧医疗、智能家居、环保监测、智能安防、智能物流、智能电网、智慧农业、智能工业等领域,对国民经济与社会发展起到了重要的推动作用
(4)大数据、云计算、物联网三者关系 P27
第一,大数据、云计算和物联网的区别。大数据侧重于对海量数据的存储、处理与分析,从海量数据中发现价值,服务于生产和生活;云计算旨在整合和优化各种 IT 资源,并通过网络以服务的方式廉价地提供给用户;物联网的发展目标是实现“物物相连”,应用创新是物联网发展的核心。
第二,大数据、云计算和物联网的联系。从整体上看,大数据、云计算和物联网这三者是相辅相成的。大数据根植于云计算,大数据分析的很多技术都来自云计算,云计算的分布式数据存储和管理系统(包括分布式文件系统和分布式数据库系统)提供了海量数据的存储和管理能力,分布式并行处理框架 MapReduce 提供了海量数据分析能力。没有这些云计算技术作为支撑,大数据分析就无从谈起。反之,大数据为云计算提供了“用武之地”,没有大数据这个“练兵场”,云计算技术再先进,也不能发挥它的应用价值。物联网的传感器源源不断产生的大量数据,构成了大数据的重要数据来源,没有物联网的飞速发展,就不会带来数据产生方式的变革,即由人工产生阶段转向自动产生阶段,大数据时代也不会这么快就到来。同时,物联网需要借助云计算和大数据技术,实现物联网大数据的存储、分析和处理。
可以说,云计算、大数据和物联网三者已经彼此渗透、相互融合,在很多应用场合都可以同时看到三者的身影。在未来,三者会继续相互促进、相互影响,更好地服务于社会生产和生活的各个领域。
习题
单选题
- 第一次信息化浪潮主要解决什么问题?(B)
A、信息传输 B、信息处理 C、信息爆炸 D、信息转换
- 下面哪个选项属于大数据技术的“数据存储和管理”技术层面的功能?(A)
A、利用分布式文件系统、数据仓库、关系数据库等实现对结构化、半结构化和非结构化海量数据的存储和管理。
B、利用分布式并行编程模型和计算框架,结合机器学习和数据挖掘算法,实现对海量数据的处理和分析
C、构建隐私数据保护体系和数据安全体系,有效保护个人隐私和数据安全
D、把实时采集的数据作为流计算系统的输入,进行实时处理分析
- 在大数据的计算模式中,流计算解决的是什么问题?(D)
A、针对大规模数据的批量处理
B、针对大规模图结构数据的处理
C、大规模数据的存储管理和查询分析
D、针对流数据的实时计算
- 大数据产业指什么?(A)
A、一切与支撑大数据组织管理和价值发现相关的企业经济活动的集合
B、提供智能交通、智慧医疗、智能物流、智能电网等行业应用的企业
C、提供数据分享平台、数据分析平台、数据租售平台等服务的企业
D、提供分布式计算、数据挖掘、统计分析等服务的各类企业
- 下列哪一个不属于大数据产业的产业链环节?(A)
A、数据循环层
B、数据源层
C、数据分析层
D、数据应用层
- 下列哪一个不属于第三次信息化浪潮中新兴的技术?(A)
A、互联网
B、云计算
C、大数据
D、物联网
- 云计算平台层(PaaS)指的是什么?(A)
A、操作系统和围绕特定应用的必需的服务
B、将基础设施(计算资源和存储)作为服务出租
C、从一个集中的系统部署软件,使之在一台本地计算机上(或从云中远程地)运行的一个模型
D、提供硬件、软件、网络等基础设施以及提供咨询、规划和系统集成服务
- 下面关于云计算数据中心的描述正确的是:(A)
A、数据中心是云计算的重要载体,为各种平台和应用提供运行支撑环境
B、数据中心就是放在企业内部的一台中心服务器
C、每个企业都需要建设一个云计算数据中心
D、数据中心不需要网络带宽的支撑
- 下列哪个不属于物联网的应用?(D)
A、智能物流
B、智能安防
C、环保监测
D、数据清洗
- 下列哪项不属于大数据的发展历程?(D)
A、成熟期
B、萌芽期
C、大规模应用期
D、迷茫期
多选题
-
第三次信息化浪潮的标志是哪些技术的兴起?(BCD)
A、个人计算机
B、物联网
C、云计算
D、大数据
-
信息科技为大数据时代提供哪些技术支撑?(ABC)
A、存储设备容量不断增加
B、网络带宽不断增加
C、CPU 处理能力大幅提升
D、数据量不断增大
-
大数据具有哪些特点?(ABCD)
A、数据的“大量化”
B、数据的“快速化”
C、数据的“多样化”
D、数据的“价值密度比较低”
-
下面哪个属于大数据的应用领域?(ABCD)
A、智能医疗研发
B、监控身体情况
C、实时掌握交通状况
D、金融交易
-
大数据的两个核心技术是什么?(AC)
A、分布式存储
B、分布式应用
C、分布式处理
D、集中式存储
-
云计算关键技术包括什么?(ABCD)
A、分布式存储
B、虚拟化
C、分布式计算
D、多租户
-
云计算的服务模式和类型主要包括哪三类?(ABC)
A、软件即服务(SaaS)
B、平台即服务(PaaS)
C、基础设施即服务(IaaS)
D、数据采集即服务(DaaS)
-
物联网主要由下列哪些部分组成的?(ABCD)
A、应用层
B、处理层
C、感知层
D、网络层
-
物联网的关键技术包括哪些?(AB)
A、识别和感知技术
B、网络与通信技术
C、数据挖掘与融合技术
D、信息处理一体化技术
-
大数据对社会发展的影响有哪些?(ABC)
A、大数据成为一种新的决策方式
B、大数据应用促进信息技术与各行业的深度融合
C、大数据开发推动新技术和新应用的不断涌现
D、大数据对社会发展没有产生积极影响
简答题
- 试述信息技术发展史上的3次信息化浪潮及其具体内容。
第一次信息化浪潮 1980年前后个人计算机开始普及,计算机走入企业和千家万户。代表企业:Intel,AMD,IBM,苹果,微软,联想,戴尔,惠普等。
第二次信息化浪潮 1995年前后进入互联网时代。代表企业:雅虎,谷歌阿里巴巴,百度,腾讯。
第三次信息浪潮 2010年前后,云计算大数据,物联网快速发展,即将涌现一批新的市场标杆企业。
- 试述数据产生方式经历的几个阶段。
经历了三个阶段:
运营式系统阶段 数据伴随一定的运营活动而产生并记录在数据库。
用户原创内容阶段 Web2.0时代。
感知式系统阶段 物联网中的设备每时每刻自动产生大量数据。
- 试述大数据的4个基本特征。
数据量大(Volume)
据类型繁多(Variety)
处理速度快(Velocity)
价值密度低(Value)
- 试述大数据时代的“数据爆炸”特性。
大数据摩尔定律:人类社会产生的数据一直都在以每年50%的速度增长,即每两年就增加一倍。
- 科学研究经历了那四个阶段?
实验 比萨斜塔实验
理论 采用各种数学,几何,物理等理论,构建问题模型和解决方案。例如:牛一,牛二,牛三定律。
计算 设计算法并编写相应程序输入计算机运行。
数据 以数据为中心,从数据中发现问题解决问题。
- 试述大数据对思维方式的重要影响。
全样而非抽样
效率而非精确
相关而非因果
- 大数据决策与传统的基于数据仓库的决策有什么区别?
数据仓库以关系数据库为基础,在数据类型和数据量方面存在较大限制。
大数据决策面向类型繁多的,非结构化的海量数据进行决策分析。
- 举例说明大数据的具体应用。
汽车行业 大数据和物联网技术 无人汽车
互联网行业 分析客户行为,进行商品推介和有针对性的广告投放。
城市管理 智能交通 环保检测 城市规划和智能安防
生物医学 流行病预测 智慧医疗 健康管理 解读DNA
个人生活 分析个人生活行为习惯,提供周到的个性化服务
- 举例说明大数据的关键技术
数据采集
数据存储和管理
数据处理分析
数据安全与隐私保护
- 大数据产业包含哪些层面?
IT基础设施层
数据源层
数据管理层
数据分析层
数据平台层
数据应用层
- 定义并解释一下术语:云计算,物联网。
云计算实现了通过网络提供可伸缩的廉价的分布式计算力,用户只需要在具备网络接入条件的地方,就可以随时随地获得所需的各种IT资源。
物联网: 物物相连的互联网,利用局部网络或者互联网等通信技术把传感器,控制器,机器,人员和物等通过新的方式连在一起,形成人与物,物与物相连,实现信息化和远程管理控制。
- 详细阐述大数据,云计算和物联网三者之间的区别和联系。
大数据、云计算和物联网的区别
大数据侧重于海量数据的存储、处理与分析,从海量数据中发现价值,服务于生产和生活;云计算本质上旨在整合和优化各种IT资源,并通过网络以服务的方式廉价提供给用户;
物联网的发展目标是实现物物相连,应用创新是物联网发展的核心。
大数据、云计算和物联网的联系
从整体上看,大数据、云计算和物联网这三者是相辅相成的。大数据根植于云计算,大数据分析的很多技术都来自于云计算,云计算的分布式和数据存储和管理系统(包括分布式文件系统和分布式数据库系统)提供了海量数据的存储和管理能力,分布式并行处理框架MapReduce提供了海量数据分析能力,没有这些云计算技术作为支撑,大数据分析就无从谈起。反之,大数据为云计算提供了“用武之地”,没有大数据这个“练兵场”,云计算技术再先进,也不能发挥它的应用价值。
物联网的传感器源源不断产生的大量数据,构成了大数据的重要来源,没有物联网的飞速发展,就不会带来数据产生方式的变革,即由人工产生阶段向自动产生阶段,大数据时代也不会这么快就到来。同时,物联网需要借助于云计算和大数据技术、实现物联网大数据的存储、分析和处理。
云计算、大数据和物联网,三者会继续相互促进、相互影响,更好地服务于社会生产和生活的各个领域。
第二章大数据处理架构Hadoop
2.1 Hadoop概述
(1)Hadoop的特征 P30
Hadoop 是一个能够对大量数据进行分布式处理的软件框架,并且是以一种可靠、高效、可伸缩的方式进行处理的,它具有以下几个方面的特性。
-
高可靠性。采用冗余数据存储方式,即使一个副本发生故障,其他副本也可以保证正常对外提供服务。
-
高效性。作为并行分布式计算平台,Hadoop 采用分布式存储和分布式处理两大核心技术,能够高效地处理 PB 级数据。
-
高可扩展性。Hadoop 的设计目标是可以高效稳定地运行在廉价的计算机集群上,可以扩展到数以千计的计算机节点上。
-
高容错性。采用冗余数据存储方式,自动保存数据的多个副本,并且能够自动将失败的任务进行重新分配。
-
成本低。Hadoop 采用廉价的计算机集群,成本比较低,普通用户也很容易用自己的 PC搭建 Hadoop 运行环境。
-
运行在 Linux 操作系统上。Hadoop 是基于 Java 开发的,可以较好地运行在 Linux 操作系统上。
-
支持多种编程语言。Hadoop 上的应用程序也可以使用其他语言编写,如 C++。
(2)Hadoop集群遵从主从结构的理解(结合hadoop各个组件的主从结构理解)
Hadoop集群的主从结构是分布式计算系统的一个核心概念,它主要包括以下几个关键组件,每个组件都有明确的主从角色分工:
HDFS(Hadoop Distributed File System)
-
NameNode(主节点):
- NameNode 是HDFS的主节点,负责管理文件系统的元数据(如文件的路径、块的位置等)。它知道所有的文件和块的分布信息。
- NameNode 不存储实际的数据,而是存储文件目录结构和文件块的位置信息。
-
DataNode(从节点):
- DataNode 是HDFS的从节点,负责存储实际的数据块。
- DataNode 定期向 NameNode 发送心跳信号和块报告,确保 NameNode 知道每个 DataNode 的状态以及数据块的情况。
YARN(Yet Another Resource Negotiator)
-
ResourceManager(主节点):
- ResourceManager 是YARN的主节点,负责管理集群资源和调度应用程序的执行。
- ResourceManager 接收来自客户端的应用程序提交请求,并分配合适的资源容器(Container)来执行任务。
-
NodeManager(从节点):
- NodeManager 是YARN的从节点,负责管理每个节点上的资源(CPU、内存等)和容器的生命周期。
- NodeManager 向 ResourceManager 报告资源使用情况,并负责启动、监控和终止容器。
MapReduce
-
JobTracker(主节点,在YARN之前使用):
- JobTracker 是旧版 Hadoop 中 MapReduce 的主节点,负责任务调度和监控。
- JobTracker 将 Map 和 Reduce 任务分配给集群中的 TaskTracker。
-
TaskTracker(从节点,在YARN之前使用):
- TaskTracker 是旧版 Hadoop 中的从节点,负责执行分配给它的 Map 和 Reduce 任务。
- TaskTracker 定期向 JobTracker 报告任务执行状态。
在 YARN 引入后,MapReduce 作业的调度和资源管理被 ResourceManager 和 NodeManager 接管。
Hadoop集群的工作流程:
-
数据存储:
- 客户端将数据写入 HDFS,数据被分块并分布存储在不同的 DataNode 上。
- NameNode 记录这些数据块的元数据。
-
作业提交:
- 客户端提交 MapReduce 作业给 ResourceManager。
- ResourceManager 根据资源情况分配 Container 并启动 ApplicationMaster(应用主进程)。
-
任务执行:
- ApplicationMaster 协调作业的执行,向 ResourceManager 请求更多的资源。
- NodeManager 在分配的 Container 内执行 Map 和 Reduce 任务,处理数据并产生结果。
-
结果汇总:
- Map 任务处理后,将中间结果存储在本地,Reduce 任务读取这些中间结果并进行汇总计算,最终生成结果存储在 HDFS 中。
通过这种主从结构,Hadoop 能够高效地管理和处理大规模的数据集,实现分布式存储和并行计算。
2.2 Hadoop生态系统
(1)生态系统10个组件的定义(需要明确知道它们都是定义为什么。比如HDFS是分布式文件系统、HBase是列式数据库… P32-P34)
- HDFS
Hadoop 分布式文件系统是 Hadoop 项目的两大核心之一,是针对谷歌文件系统的开源实现。HDFS 具有处理超大数据、流式处理、可以运行在廉价商用服务器上等优点。HDFS 在设计之初就是要运行在廉价的大型服务器集群上,因此在设计上就把硬件故障作为一种常态来考虑,实现在部分硬件发生故障的情况下仍然能够保证文件系统的整体可用性和可靠性。HDFS 放宽了一部分可移植操作系统接口(Portable Operating System Interface,POSIX)约束,从而实现以流的形式访问文件系统中的数据。HDFS 在访问应用程序数据时,可以具有很高的吞吐率,因此对于超大数据集的应用程序而言,选择 HDFS 作为底层数据存储系统是较好的选择。
- HBase
HBase 是一个提供高可靠性、高性能、可伸缩、实时读写、分布式的列式数据库,一般采用HDFS 作为其底层数据存储系统。HBase 是针对谷歌 BigTable 的开源实现,二者都采用了相同的数据模型,具有强大的非结构化数据存储能力。HBase 与传统关系数据库的一个重要区别是,前者采用基于列的存储,后者采用基于行的存储。HBase 具有良好的横向扩展能力,可以通过不断增加廉价的商用服务器来提高存储能力。
- MapReduce
Hadoop MapReduce 是针对谷歌 MapReduce 的开源实现。MapReduce 是一种编程模型,用于大规模数据集(大于 1 TB)的并行运算,它将复杂的、运行于大规模集群上的并行计算过程高度地抽象为两个函数—Map 和 Reduce,并且允许用户在不了解分布式系统底层细节的情况下开发并行应用程序,并将其运行于廉价的计算机集群上,完成海量数据的处理。通俗地说,MapReduce 的核心思想就是“分而治之”,它把输入的数据集切分为若干独立的数据块,分发给一个主节点管理下的各个分节点来共同并行完成;最后,通过整合各个节点的中间结果得到最终结果。
- Hive
Hive 是一个基于 Hadoop 的数据仓库工具,可以用于对 Hadoop 文件中的数据集进行数据整理、特殊查询和分析存储。Hive 的学习门槛较低,因为它提供了类似于关系数据库 SQL 的查询语言—HiveQL,可以通过 HiveQL 语句快速实现简单的 MapReduce 任务,Hive 自身可以将HiveQL 语句转换为 MapReduce 任务运行,而不必开发专门的 MapReduce 应用,因而十分适合数据仓库的统计分析。
- Pig
Pig 是一种数据流语言和运行环境,适合于使用 Hadoop 和 MapReduce 平台来查询大型半结构化数据集。虽然编写 MapReduce 应用程序不是十分复杂,但毕竟也是需要一定的开发经验的。Pig 的出现大大简化了 Hadoop 常见的工作任务,它在 MapReduce 的基础上创建了更简单抽象的过程语言,为 Hadoop 应用程序提供了一种更加接近结构查询语言的接口。Pig 是一种相对简单的语言,它可以执行语句,因此当我们需要从大型数据集中搜索满足某个给定搜索条件的记录时,采用 Pig 要比 MapReduce 具有明显的优势,前者只需要编写一个简单的脚本在集群中自动并行处理与分发,后者则需要编写一个单独的 MapReduce 应用程序。
- Mahout
Mahout 是 Apache 软件基金会旗下的一个开源项目,提供一些可扩展的机器学习领域经典算法的实现,旨在帮助开发人员更加方便快捷地创建智能应用程序。Mahout 包含许多实现,如聚类、分类、推荐过滤、频繁子项挖掘等。此外,通过使用 Apache Hadoop 库,Mahout 可以有效地扩展到云中。
- ZooKeeper
ZooKeeper 是针对谷歌 Chubby 的一个开源实现,是高效和可靠的协同工作系统,提供分布式锁之类的基本服务(如统一命名服务、状态同步服务、集群管理、分布式应用配置项的管理等),用于构建分布式应用,减轻分布式应用程序所承担的协调任务。ZooKeeper 使用 Java 编写,很容易编程接入,它使用了一个和文件树结构相似的数据模型,可以使用 Java 或者 C 来进行编程接入。
- Flume
Flume 是 Cloudera 提供的一个高可用的、高可靠的、分布式的海量日志采集、聚合和传输的系统。Flume 支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume 提供对数据进行简单处理并写到各种数据接收方的能力。
- Sqoop
Sqoop 是 SQL-to-Hadoop 的缩写,主要用来在 Hadoop 和关系数据库之间交换数据,可以改进数据的互操作性。通过 Sqoop 可以方便地将数据从 MySQL、Oracle、PostgreSQL 等关系数据库中导入 Hadoop(可以导入 HDFS、HBase 或 Hive),或者将数据从 Hadoop 导出到关系数据库,使传统关系数据库和 Hadoop 之间的数据迁移变得非常方便。Sqoop 主要通过 Java 数据库连接(Java DataBase Connectivity,JDBC)和关系数据库进行交互,理论上,支持 JDBC 的关系数据库都可以使 Sqoop 和 Hadoop 进行数据交互。Sqoop 是专门为大数据集设计的,支持增量更新,可以将新记录添加到最近一次导出的数据源上,或者指定上次修改的时间戳。
- Ambari
Apache Ambari 是一种基于 Web 的工具,支持 Apache Hadoop 集群的安装、部署、配置和管理。Ambari 目前已支持大多数 Hadoop 组件,包括 HDFS、MapReduce、Hive、Pig、HBase、ZooKeeper、Sqoop 等。
2.3 Hadoop的安装与使用
(1)Hadoop的三种安装模式 单机模式、伪分布模式、分布式模式
单机模式:在采用单机模式时,Hadoop 只在一台机器上运行,存储采用本地文件系统,没有采用分布式文件系统 HDFS。
分布式安装:在分布式安装时,Hadoop 存储采用分布式文件系统 HDFS,而且,HDFS 的名称节点和数据节点位于集群的不同机器上。
伪分布式安装:伪分布式安装是指在一台机器上模拟一个小的集群,但是集群中只有一个节点。在采用伪分布式模式时,Hadoop 的存储采用分布式文件系统 HDFS,但是,HDFS的名称节点和数据节点都在同一台机器上。
需要说明的是,在一台机器上也是可以实现完全分布式安装的(而不是伪分布式)。只要在一台机器上安装多个 Linux 虚拟机,使每个 Linux 虚拟机成为一个节点,就可以实现 Hadoop 的完全分布式安装。
习题
单选题
-
下列哪个不属于Hadoop的特性?(A)
A、成本高
B、高可靠性
C、高容错性
D、运行在 Linux 平台上
-
Hadoop框架中最核心的设计是什么?(A)
A、为海量数据提供存储的HDFS和对数据进行计算的MapReduce
B、提供整个HDFS文件系统的NameSpace(命名空间)管理、块管理等所有服务
C、Hadoop不仅可以运行在企业内部的集群中,也可以运行在云计算环境中
D、Hadoop被视为事实上的大数据处理标准
-
在一个基本的Hadoop集群中,DataNode主要负责什么?(D)
A、负责执行由JobTracker指派的任务
B、协调数据计算任务
C、负责协调集群中的数据存储
D、存储被拆分的数据块
-
Hadoop最初是由谁创建的?(B)
A、Lucene
B、Doug Cutting
C、Apache
D、MapReduce
-
下列哪一个不属于Hadoop的大数据层的功能?(C)
A、数据挖掘
B、离线分析
C、实时计算
D、BI分析
-
在一个基本的Hadoop集群中,SecondaryNameNode主要负责什么?(A)
A、帮助 NameNode 收集文件系统运行的状态信息
B、负责执行由 JobTracker 指派的任务
C、协调数据计算任务
D、负责协调集群中的数据存储
-
下面哪一项不是Hadoop的特性?(B)
A、可扩展性高
B、只支持少数几种编程语言
C、成本低
D、能在linux上运行
-
在Hadoop项目结构中,HDFS指的是什么?(A)
A、分布式文件系统
B、分布式并行编程模型
C、资源管理和调度器
D、Hadoop上的数据仓库
-
在Hadoop项目结构中,MapReduce指的是什么?(A)
A、分布式并行编程模型
B、流计算框架
C、Hadoop上的工作流管理系统
D、提供分布式协调一致性服务
-
下面哪个不是Hadoop1.0的组件:(C)
A、HDFS
B、MapReduce
C、YARN
D、NameNode 和 DataNode
多选题
-
Hadoop的特性包括哪些?(ABCD)
A、高可扩展性
B、支持多种编程语言
C、成本低
D、运行在Linux平台上
-
下面哪个是Hadoop2.0的组件?(AD)
A、ResourceManager
B、JobTracker
C、TaskTracker
D、NodeManager
-
一个基本的Hadoop集群中的节点主要包括什么?(ABCD)
A、DataNode:存储被拆分的数据块
B、JobTracker:协调数据计算任务
C、TaskTracker:负责执行由JobTracker指派的任务
D、SecondaryNameNode:帮助NameNode收集文件系统运行的状态信息
-
下列关于Hadoop的描述,哪些是正确的?(ABCD)
A、为用户提供了系统底层细节透明的分布式基础架构
B、具有很好的跨平台特性
C、可以部署在廉价的计算机集群中
D、曾经被公认为行业大数据标准开源软件
-
Hadoop集群的整体性能主要受到什么因素影响?(ABCD)
A、CPU性能
B、内存
C、网络
D、存储容量
-
下列关于Hadoop的描述,哪些是错误的?(AB)
A、只能支持一种编程语言
B、具有较差的跨平台特性
C、可以部署在廉价的计算机集群中
D、曾经被公认为行业大数据标准开源软件
-
下列哪些项不属于Hadoop的特性?(AB)
A、较低可扩展性
B、只支持java语言
C、成本低
D、运行在Linux平台上
简答题
- 试述Hadoop和谷歌的MapReduce、GFS等技术之间的关系。
Hadoop是Apache软件基金会旗下的一-个开源分布式计算平台,为用户提供了系统底层细节透明的分布式基础架构。
① Hadoop 的核心是分布式文件系统( Hadoop Ditributed File System,HDFS )和MapReduce。
② HDFS是对谷歌文件系统( Google File System, GFS )的开源实现,是面向普通硬件环境的分布式文件系统,具有较高的读写速度、很好的容错性和可伸缩性,支持大规模数据的分布式存储,其冗余数据存储的方式很好地保证了数据的安全性。
③ MapReduce 是针对谷歌MapReduce的开源实现,允许用户在不了解分布式系统底层细节的情况下开发并行应用程序,采用MapReduce 来整合分布式文件系统上的数据,可保证分析和处理数据的高效性。
- 试述Hadoop具有哪些特性。
Hadoop是一个能够对大量数据进行分布式处理的软件框架,并且是以一种可靠、高效、可伸缩的方式进行处理的,它具有以下几个方面的特性。
① 高可靠性。采用冗余数据存储方式,即使一个副本发生故障, 其他副本也可以保证正常对外提供服务。
② 高效性。 作为并行分布式计算平台,Hadoop采用分布式存储和分布式处理两大核心技术,能够高效地处理PB级数据。
③ 高可扩展性。 Hadoop的设计目标是可以高效稳定地运行在廉价的计算机集群上,可以扩展到数以千计的计算机节点。
④ 高容错性。 采用冗余数据存储方式,自动保存数据的多个副本,并且能够自动将失败的任务进行重新分配。
⑤ 成本低。 Hadoop采用廉价的计算机集群,成本比较低,普通用户也很容易用自己的PC搭建Hadoop运行环境。
⑥ 运行在 Linux平台上。Hadoop是基于Java语言开发的,可以较好地运行在Linux平台上。
⑦ 支持多种编程语言。 Hadoop 上的应用程序也可以使用其他语言编写,如C++。
- 试述Hadoop在各个领域的应用情况。
互联网领域是Hadoop应用的主要阵地。
① 雅虎将Hadoop主要用于支持广告系统与网页搜索。
② Facebook主要将Hadoop平台用于日志处理、推荐系统和数据仓库等方面。
③ 淘宝Hadoop集群服务于阿里巴巴集团各部门,数据来源于各部门产品的线上数据库( Oracle、MySQL)备份、系统日志以及爬虫数据,每天在Hadoop集群运行各种MapReduce任务,如数据魔方、量子统计、推荐系统、排行榜等。
④ 百度选择Hadoop主要用于日志的存储和统计、网页数据的分析和挖掘、商业分析、在线数据反馈、网页聚类等。
- 试述Hadoop的项目结构以及每个部分的具体功能。
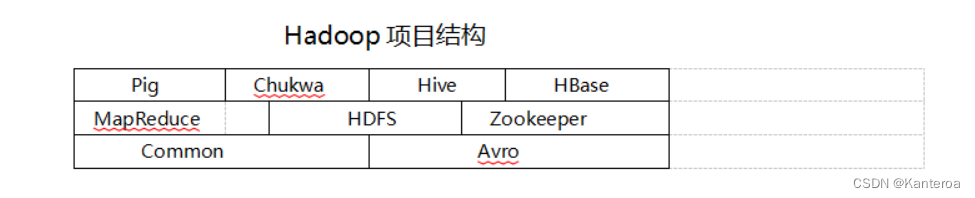
各部分具体功能:
① Common。Common为Hadoop其他子项目提供支持的常用工具,主要包括文件系统、RPC(Remote Procedure Call)和串行化库。
② Avro。Avro Avro是Hadoop的一一个子项目,也是Apache中的一个独立项目。Avro是一个用于数据序列化的系统,提供了丰富的数据结构类型、快速可压缩的二进制数据格式、存储持久性数据的文件集、远程调用( Remote Procedure Call, RPC )的功能和简单的动态语言集成功能。Avro 可以将数据结构或对象转化成便于存储和传输的格式,节约数据存储空间和网络传输带宽, Hadoop的其他子项目(如HBase和Hive )的客户端与服务端之间的数据传输都采用了Avro。
③ HDFS。HDFS是针对GFS的开源实现。具有处理强大数据、流式处理、可以运行在廉价的商用服务器上等优点。
④ HBase。HBase是针对谷歌的BigTable的开源实现。一般采用HDFS作为其底层数据存储,基于列的存储,具有强大的非结构化数据存储能力。具有良好的横向扩展能力。
⑤ MapReduce。MapReduce是一种编程模型,用于大规模数据集(大于1TB)的并行运算。允许用户在不了解分布式系统底层细节的情况下开发并行应用程序,并将其运行于廉价计算机集群上,完成海量数据的处理。
⑥ Zookeeper。Zookeeper是针对谷歌Chubby的-一个开源实现,是高效和可靠的协同工作系统,提供分布式锁之类的基本服务( 如统一命名服务、 状态同步服务、集群管理、分布式应用配置项的管理等),用于构建分布式应用,减轻分布式应用程序所承担的协调任务。
⑦ Hive。Hive是一个基于Hadoop的数据仓库工具,可以用于对Hadoop文件中的数据集进行数据整理、特殊查询和分析存储,十分适合数据仓库的统计分析。
⑧ Pig。Pig是一种数据流语言和运行环境,适合于使用Hadoop和MapReduce平台来查询大型半结构化数据集。Pig大大简化了Hadoop常见的工作任务,它在MapReduce的基础上创建了更简单的过程语言抽象,为Hadoop应用程序提供了一种更加接近结构化查询语言(SQL)的接口。
⑨ Sqoop。Sqoop可以改进数据的互操作性,主要用来在Hadoop 和关系数据库之间交换数据。通过Sqoop,可以方便地将数据从MySQL、Oracle 、PostgreSQL 等关系数据库中导人Hadoop (可以导人HDFS、HBase或Hive),或者将数据从Hadoop导出到关系数据库,使得传统关系数据库和Hadoop之间的数据迁移变得非常方便。
⑩ Chukwa。Chukwa是一个开源的、用于监控大型分布式系统的数据收集系统,可以将各种类型的数据收集成适合Hadoop处理的文件,并保存在HDFS中供Hadoop进行各种MapReduce操作。
- 路径JAVA_ HOME是在哪一个配置文件中进行设置的?
在安装Hadoop的文件夹下的“conf”目录下配置。
- 所有节点的HDFS路径是通过fs.default.name来设置的,请问它是在哪个配置文件中设置的?
在安装目录下的HDFS core-site.xml 配置文件中配置。
fs.default.name是文件系统的名字。通常是NameNode的hostname与port, 需要在每一个需要访问集群的机器上指定,包括集群中的节点
- 试列举单机模式和伪分布模式的异同点。
相同点:运行机器数相同。单机模式与伪分布式都是在一台单机上运行。
不同点:
① 运行模式不同:单机模式是Hadoop的默认模式,即在一台单机上运行,没有分布式文件系统,直接读写本地操作系统的文件系统。伪分布模式但用不同的Java进程模仿分布式运行中的各类结点。
② 启动进程不同:单机模式下,Hadoop不会启动NameNode、DataNode、JobTracker、TaskTracker等守护进程,Map()和Reduce()任务作为同一个进程的不同部分来执行的。伪分布式模式下,Hadoop启动NameNode、DataNode、JobTracker、TaskTracker这些守护进程都在同一台机器上运行,是相互独立的Java进程。
③ 配置文件处理方式不同:单机模式下,不对配置文件进行修改。伪分布式模式下,修改3个配置文件:core-site.xml(Hadoop集群的特性,作用于全部进程及客户端)、hdfs-site.xml(配置HDFS集群的工作属性)、mapred-site.xml(配置MapReduce集群的属性)。
④ 节点交互不同:单机模式因为不需要与其他节点交互,单机模式就不使用HDFS,也不加载任何Hadoop的守护进程。该模式主要用于开发调试MapReduce程序的应用逻辑。伪分布模式在单机模式之上增加了代码调试功能,允许你检查内存使用情况,HDFS输入输出,以及其他的守护进程交互。
- Hadoop伪分布式运行启动后所具有的进程都有哪些?
Hadoop伪分布式运行启动后所具有的进程有:NameNode、DataNode、JobTracker、TaskTracker。
- 如果具备集群实验条件,请尝试按照Hadoop官方文档搭建全分布式的Hadoop集群环境。
略。
第三章分布式文件系统HDFS
3.1分布式文件系统
(1)分布式文件系统结构 P46
相对于传统的本地文件系统而言,分布式文件系统(Distributed File System)是一种通过网络实现文件在多台主机上进行分布式存储的文件系统。分布式文件系统的设计一般采用“客户机/服务器”(Client/Server)模式,客户端以特定的通信协议通过网络与服务器建立连接,提出文件访问请求,客户端和服务器可以通过设置访问权来限制请求方对底层数据存储块的访问。
目前,已得到广泛应用的分布式文件系统主要包括 GFS 和 HDFS 等,后者是针对前者的开源实现。
(2)Client、NameNode和DataNode的理解 P47
在我们所熟悉的Windows、Linux等操作系统中,文件系统一般会把磁盘空间划分为每512Byte一组,称为“磁盘块”,它是文件系统进行读写操作的最小单位,文件系统的块(Block)通常是磁盘块的整数倍,即每次读写的数据量必须是磁盘块大小的整数倍。
与普通文件系统类似,分布式文件系统也采用了块的概念,文件被分成若干个块进行存储,块是数据读写的基本单元,只不过分布式文件系统的块要比操作系统中的块大很多。比如 HDFS默认的一个块的大小是 64 MB。与普通文件不同的是,在分布式文件系统中,如果一个文件小于一个数据块的大小,它并不占用整个数据块的存储空间。
分布式文件系统在物理结构上是由计算机集群中的多个节点构成的,如图 3-2 所示。这些节点分为两类:一类叫“主节点”(Master Node),或者被称为“名称节点”(NameNode);另一类叫“从节点”(Slave Node),或者被称为“数据节点”(DataNode)。名称节点负责文件和目录的创建、删除和重命名等,同时管理着数据节点和文件块的映射关系,因此客户端只有访问名称节点才能找到请求的文件块所在的位置,进而到相应位置读取所需文件块。数据节点负责数据的存储和读取,在存储时,由名称节点分配存储位置,然后由客户端把数据直接写入相应数据节点;在读取时,客户端从名称节点获得数据节点和文件块的映射关系,然后就可以到相应位置访问文件块。数据节点也要根据名称节点的命令创建、删除和复制数据块。
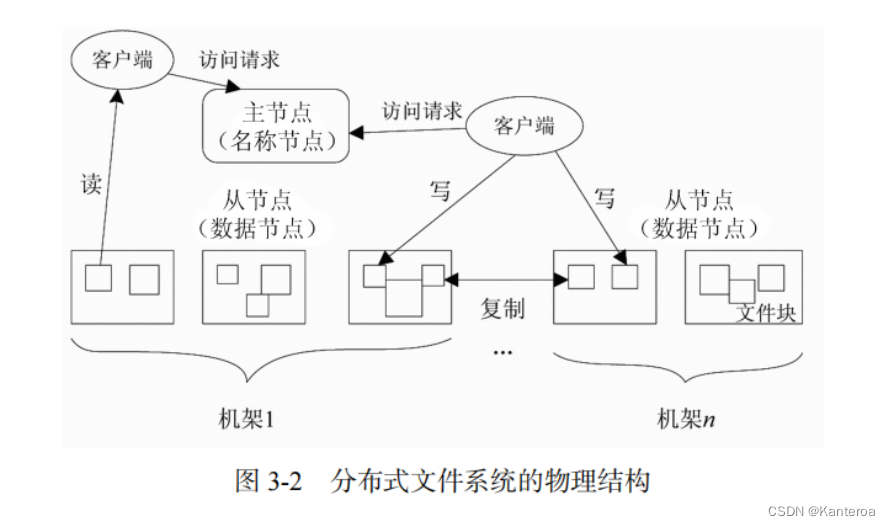
计算机集群中的节点可能发生故障,因此为了保证数据的完整性,分布式文件系统通常采用多副本存储。文件块会被复制为多个副本,存储在不同的节点上,而且存储同一文件块的不同副本的各个节点会分布在不同的机架上。这样,在单个节点出现故障时,就可以快速调用副本重启单个节点上的计算过程,而不用重启整个计算过程,整个机架出现故障时也不会丢失所有文件块。文件块的大小和副本个数通常可以由用户指定。
分布式文件系统是针对大规模数据存储而设计的,主要用于处理大规模文件,如 TB 级文件。处理规模过小的文件不仅无法充分发挥其优势,而且会严重影响系统的扩展和性能。
3.2 HDFS简介
(1)HDFS的目标和局限性 P49
HDFS 开源实现了 GFS 的基本思想。HDFS 原来是 Apache Nutch 搜索引擎的一部分,后来独立出来作为一个 Apache 子项目,并和 MapReduce 一起成为 Hadoop 的核心组成部分。HDFS 支持流数据读取和处理超大规模文件,并能够运行在由廉价的普通机器组成的集群上,这主要得益于HDFS 在设计之初就充分考虑了实际应用环境的特点,那就是,**硬件出错在普通服务器集群中是一种常态,而不是异常。**因此,HDFS 在设计上采取了多种机制保证在硬件出错的环境中实现数据的完整性。
总体而言,HDFS 要实现以下目标
-
兼容廉价的硬件设备。在成百上千台廉价服务器中存储数据,常会出现节点失效的情况,因此 HDFS 设计了快速检测硬件故障和进行自动恢复的机制,可以实现持续监视、错误检查、容错处理和自动恢复,从而在硬件出错的情况下也能实现数据的完整性。
-
流数据读写。普通文件系统主要用于随机读写以及与用户进行交互,HDFS 则是为了满足批量数据处理的要求而设计的,因此为了提高数据吞吐率,HDFS 放松了一些 POSIX 的要求,从而能够以流式方式来访问文件系统数据。
-
大数据集。HDFS 中的文件通常可以达到 GB 甚至 TB 级别,一个数百台机器组成的集群可以支持千万级别这样的文件。
-
简单的文件模型。HDFS 采用了“一次写入、多次读取”的简单文件模型,文件一旦完成写入,关闭后就无法再次写入,只能被读取。
-
强大的跨平台兼容性。HDFS 是采用 Java 语言实现的,具有很好的跨平台兼容性,支持Java 虚拟机(Java Virtual Machine,JVM)的机器都可以运行 HDFS。
HDFS 特殊的设计,在实现上述优良特性的同时,也使自身具有一些应用局限性。
-
不适合低延迟数据访问。HDFS 主要是面向大规模数据批量处理而设计的,采用流式数据读取,具有很高的数据吞吐率,但是,这也意味着较高的延迟。因此,HDFS 不适合用在需要较低延迟(如数十毫秒)的应用场合。对于低延时要求的应用程序而言,HBase 是一个更好的选择。
-
无法高效存储大量小文件。小文件是指文件大小小于一个块的文件。HDFS 无法高效存储和处理大量小文件,过多小文件会给系统扩展性和性能带来诸多问题。首先,HDFS 采用名称节点来管理文件系统的元数据,这些元数据被保存在内存中,从而使客户端可以快速获取文件实际存储位置。通常,每个文件、目录和块大约占 150Byte,如果有 1000 万个文件,每个文件对应一个块,那么,名称节点至少要消耗 3 GB 的内存来保存这些元数据信息。很显然,这时元数据检索的效率就比较低了,需要花费较多的时间找到一个文件的实际存储位置。而且,如果继续扩展到数十亿个文件,名称节点保存元数据所需要的内存空间就会大大增加,以现有的硬件水平,是无法在内存中保存如此大量的元数据的。其次,用 MapReduce 处理大量小文件时,会产生过多的Map 任务,进程管理开销会大大增加,因此处理大量小文件的速度远远低于处理同等规模的大文件的速度。再次,访问大量小文件的速度远远低于访问几个大文件的速度,因为访问大量小文件,需要不断从一个数据节点跳到另一个数据节点,严重影响性能。
-
不支持多用户写入及任意修改文件。HDFS 只允许一个文件有一个写入者,不允许多个用户对同一个文件执行写操作,而且只允许对文件执行追加操作,不能执行随机写操作。
3.3 HDFS相关概念※
(1)块 :概念、存储单位、默认大小 P50
在传统的文件系统中,为了提高磁盘读写效率,一般以数据块为单位,而不是以字节为单位。比如机械式硬盘(磁盘的一种)包含了磁头和转动部件,在读取数据时有一个寻道的过程,通过转动盘片和移动磁头的位置,找到数据在机械式硬盘中的存储位置,才能进行读写。在 I/O 开销中,机械式硬盘的寻址时间是最耗时的部分,一旦找到第一条记录,剩下的顺序读取效率是非常高的。因此,以块为单位读写数据,可以把磁盘寻道时间分摊到大量数据中。
HDFS 也同样采用了块的概念,默认的一个块大小是 64 MB。在 HDFS 中的文件会被拆分成多个块,每个块作为独立的单元进行存储。我们所熟悉的普通文件系统的块一般只有几千字节,
可以看出,HDFS 在块的大小的设计上明显要大于普通文件系统。HDFS 这么做,是为了最小化寻址开销。HDFS 寻址开销不仅包括磁盘寻道开销,还包括数据块的定位开销。当客户端需要访问一个文件时,首先从名称节点获得组成这个文件的数据块的位置列表,然后根据位置列表获取实际存储各个数据块的数据节点的位置,最后数据节点根据数据块信息在本地 Linux 文件系统中找到对应的文件,并把数据返回给客户端。设计一个比较大的块,可以把上述寻址开销分摊到较多的数据中,降低了单位数据的寻址开销。因此,HDFS 在文件块大小设置上要远远大于普通文件系统,以期在处理大规模文件时能够获得更好的性能。当然,块的大小也不宜设置过大,因为通常 MapReduce 中的 Map 任务一次只处理一个块中的数据,如果启动的任务太少,就会降低作业并行处理速度。
HDFS 采用抽象的块概念可以带来以下几个明显的好处。
- 支持大规模文件存储。文件以块为单位进行存储,一个大规模文件可以被拆分成若干个文
件块,不同的文件块可以被分发到不同的节点上,因此一个文件的大小不会受到单个节点的存储
容量的限制,可以远远大于网络中任意节点的存储容量。
- 简化系统设计。首先,HDFS 采用块概念大大简化了存储管理,因为文件块大小是固定的,
这样就可以很容易计算出一个节点可以存储多少文件块;其次,这方便了元数据的管理,元数据
不需要和文件块一起存储,可以由其他系统负责管理元数据。
- 适合数据备份。每个文件块都可以冗余存储到多个节点上,大大提高了系统的容错性和可
用性。
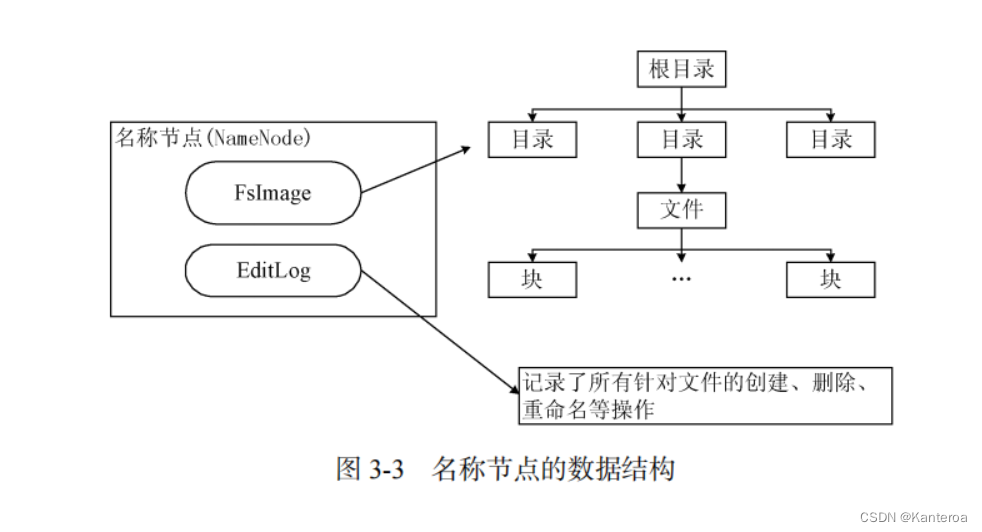
(2)名称节点:功能、两大核心数据结构功能及存储位置 P50-P51
在 HDFS 中,名称节点负责管理分布式文件系统的命名空间(Namespace),保存了两个核心的数据结构(见图 3-3),即 FsImage 和 EditLog。FsImage 用于维护文件系统树以及文件树中所有的文件和文件夹的元数据,操作日志文件 EditLog 中记录了所有针对文件的创建、删除、重命名等操作。名称节点记录了每个文件中各个块所在的数据节点的位置信息,但是并不持久化地存储这些信息,而是在系统每次启动时扫描所有数据节点并重构,得到这些信息。名称节点在启动时,会将 FsImage 的内容加载到内存当中,然后执行 EditLog 文件中的各项操作,使内存中的元数据保持最新。这个操作完成以后,就会创建一个新的 FsImage 文件和一个空的 EditLog 文件。名称节点启动成功并进入正常运行状态以后,HDFS 中的更新操作都会被写入 EditLog,而不是直接被写入 FsImage。这是因为对于分布式文件系统而言,FsImage 文件通常都很庞大(一般都是 GB 级别以上),如果所有的更新操作都直接在 FsImage 文件中进行,那么系统的运行速度会变得非常缓慢。相对而言,EditLog 通常都要远远小于 FsImage,更新操作写入EditLog 是非常高效的。名称节点在启动的过程中处于“安全模式”,只能对外提供读操作,无法提供写操作。启动过程结束后,系统就会退出安全模式,进入正常运行状态,对外提供读写操作。
数据节点(DataNode)是分布式文件系统 HDFS 的工作节点,负责数据的存储和读取,会根据客户端或者名称节点的调度来进行数据的存储和检索,并且向名称节点定期发送自己所存储的块的列表信息。每个数据节点中的数据会被保存在各自节点的本地 Linux 文件系统中。
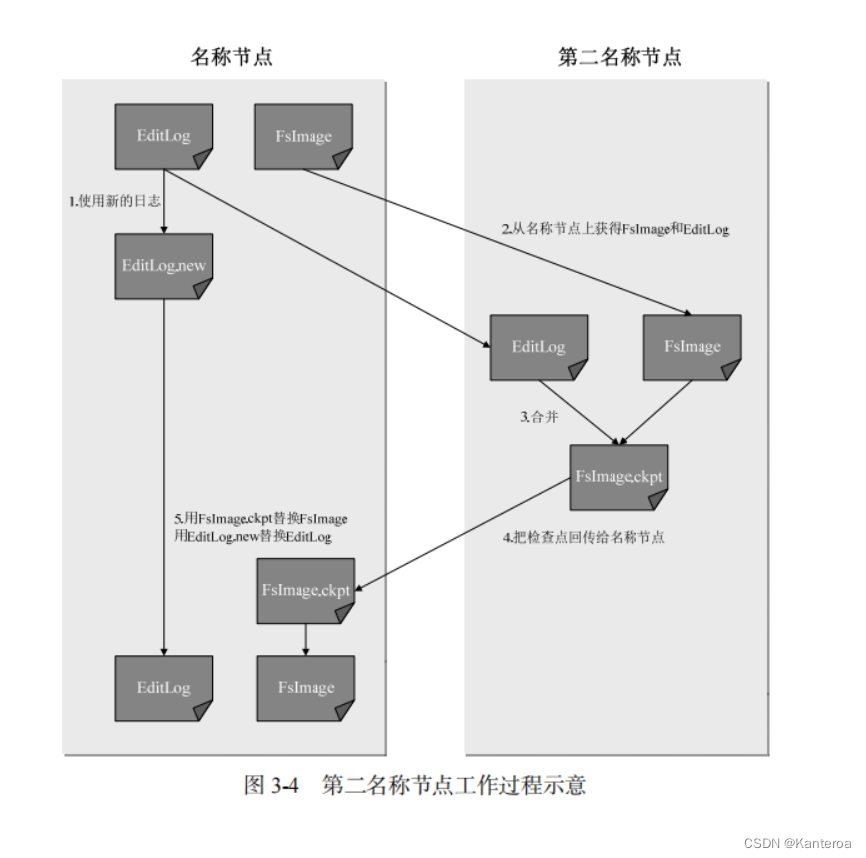
(3)第二名称节点:解决的问题、冷备份、运行原理 P51
在名称节点运行期间,HDFS 会不断产生更新操作,这些更新操作直接被写入 EditLog 文件,因此 EditLog 文件也会逐渐变大。在名称节点运行期间,不断变大的 EditLog 文件通常对于系统性能不会产生显著影响,但是当名称节点重启时,需要将 FsImage 加载到内存中,然后逐条执行EditLog 中的记录,使 FsImage 保持最新。可想而知,如果 EditLog 很大,就会导致整个过程变得非常缓慢,使名称节点在启动过程中长期处于“安全模式”,无法正常对外提供写操作,影响用户的使用。
为了有效解决 EditLog 逐渐变大带来的问题,HDFS 在设计中采用了第二名称节点(Secondary NameNode)。第二名称节点是 HDFS 架构的一个重要组成部分,具有两个方面的功能:首先,它可以完成 EditLog 与 FsImage 的合并操作,减小 EditLog 文件大小,缩短名称节点重启时间;其次,它可以作为名称节点的“检查点”,保存名称节点中的元数据信息。具体如下。
(1)EditLog 与 FsImage 的合并操作。每隔一段时间,第二名称节点会和名称节点通信,请求其停止使用 EditLog 文件(这里假设这个时刻为 t1),如图 3-4 所示,暂时将新到达的写操作添加到一个新的文件 EditLog.new 中。然后,第二名称节点把名称节点中的 FsImage 文件和 EditLog文件拉回本地,再加载到内存中;对二者执行合并操作,即在内存中逐条执行 EditLog 中的操作,使 FsImage 保持最新。合并结束后,第二名称节点会把合并后得到的最新的 FsImage.ckpt 文件发送到名称节点。名称节点收到后,会用最新的 FsImage.ckpt 文件去替换旧的 FsImage 文件,同时用 EditLog.new 文件去替换 EditLog 文件(这里假设这个时刻为 t2),从而减小了 EditLog 文件的大小。
(2)作为名称节点的“检查点”。从上面的合并过程可以看出,第二名称节点会定期和名称节点通信,从名称节点获取 FsImage 文件和 EditLog 文件,执行合并操作得到新的 FsImage.ckpt 文件。从这个角度来讲,第二名称节点相当于为名称节点设置了一个“检查点”,周期性地备份名称节点中的元数据信息,当名称节点发生故障时,就可以用第二名称节点中记录的元数据信息进行系统恢复。但是,在第二名称节点上合并操作得到的新的 FsImage 文件是合并操作发生时(即 t1时刻)HDFS 记录的元数据信息,并没有包含 t1时刻和 t2时刻期间发生的更新操作。如果名称节点在 t1时刻和 t2时刻期间发生故障,系统就会丢失部分元数据信息,在 HDFS 的设计中,也并不支持把系统直接切换到第二名称节点。因此从这个角度来讲,第二名称节点只是起到了名称节点的“检查点”作用,并不能起到“热备份”作用。即使有了第二名称节点的存在,当名称节点发生故障时,系统还是有可能会丢失部分元数据信息的。
3.4 HDFS体系结构
(1)HDFS 局限性 P54
HDFS 只设置唯一一个名称节点,这样做虽然大大简化了系统设计,但也带来了一些明显的局限性,具体如下。
-
命名空间的限制。名称节点是保存在内存中的,因此名称节点能够容纳对象(文件、块)的个数会受到内存空间大小的限制。
-
性能的瓶颈。整个分布式文件系统的吞吐量受限于单个名称节点的吞吐量。
-
隔离问题。由于集群中只有一个名称节点,只有一个命名空间,因此无法对不同应用程序进行隔离。
-
集群的可用性。一旦这个唯一的名称节点发生故障,会导致整个集群变得不可用。
3.5 HDFS存储原理※
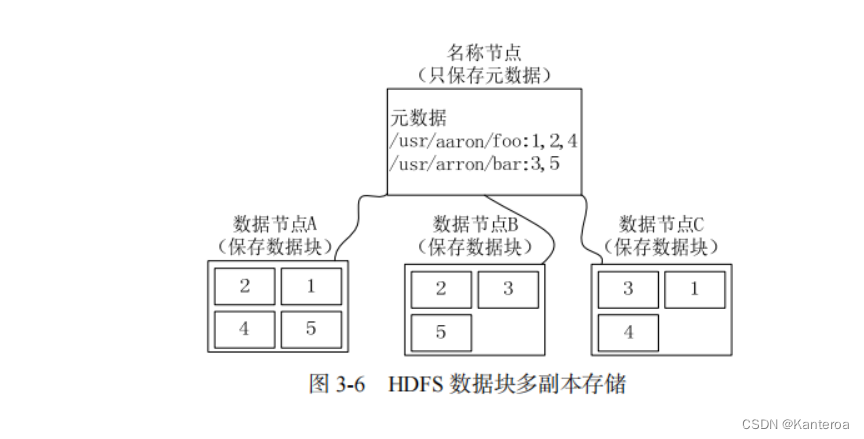
(1)冗余存储的方式和优点 P55
作为一个分布式文件系统,为了保证系统的容错性和可用性,HDFS 采用了多副本方式对数据进行冗余存储,通常一个数据块的多个副本会被分布到不同的数据节点上。如图 3-6 所示,数据块 1 被分别存放到数据节点 A 和 C 上,数据块 2 被存放在数据节点 A 和 B 上等。
这种多副本方式具有以下 3 个优点。
-
加快数据传输速度。当多个客户端需要同时访问同一个文件时,可以让各个客户端分别从不同的数据块副本中读取数据,这就大大加快了数据传输速度。
-
容易检查数据错误。HDFS 的数据节点之间通过网络传输数据,采用多个副本可以很容易判断数据传输是否出错。
-
保证数据的可靠性。即使某个数据节点出现故障失效,也不会造成数据丢失。
(2)数据存储策略 P55-P56
数据存取策略包括数据存放、数据读取和数据复制等方面,它在很大程度上会影响到整个分布式文件系统的读写性能,是分布式文件系统的核心内容。
数据存放
为了提高数据的可靠性与系统的可用性,以及充分利用网络带宽,HDFS 采用了以机架(Rack)为基础的数据存放策略。一个 HDFS 集群通常包含多个机架,不同机架之间的数据通信需要经过交换机或者路由器,同一个机架中不同机器之间的通信则不需要经过交换机和路由器,这意味着同一个机架中不同机器之间的通信要比不同机架之间机器的通信带宽大。
HDFS 默认每个数据节点都在不同的机架上,这种方法会存在一个缺点,那就是写入数据的时候不能充分利用同一机架内部机器之间的带宽。但是,与这个缺点相比,这种方法也带来了更多很显著的优点:首先,可以获得很高的数据可靠性,即使一个机架发生故障,位于其他机架上的数据副本仍然是可用的;其次,可以在多个机架上并行读取数据,大大提高数据读取速度;最后,可以更容易地实现系统内部负载均衡和错误处理。
HDFS 默认的冗余复制因子是 3,每一个文件块会被同时保存到 3 个地方,其中,有两个副本放在同一个机架的不同机器上面,第 3 个副本放在不同机架的机器上面,这样既可以保证机架发生异常时的数据恢复,也可以提高数据读写性能。一般而言,HDFS 副本的放置策略如下(见图 3-7)。
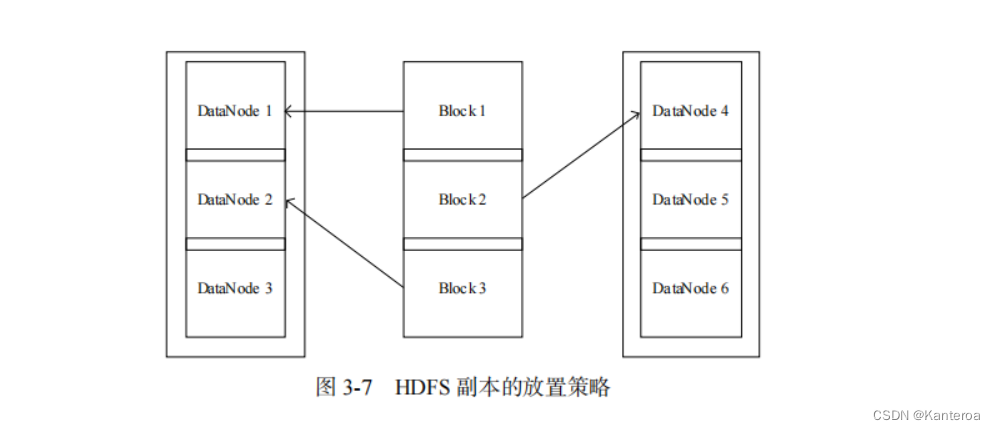
-
如果是在集群内发起写操作请求,则把第 1 个副本放置在发起写操作请求的数据节点上,实现就近写入数据。如果是在集群外发起写操作请求,则从集群内部挑选一台磁盘空间较为充足、CPU 不太忙的数据节点,作为第 1 个副本的存放地。
-
第 2 个副本会被放置在与第 1 个副本不同的机架的数据节点上。
-
第 3 个副本会被放置在与第 1 个副本相同的机架的其他节点上。
-
如果还有更多的副本,则继续从集群中随机选择数据节点进行存放。
数据读取
HDFS 提供了一个 API 可以确定一个数据节点所属的机架 ID,客户端也可以调用 API 获取自己所属的机架 ID。当客户端读取数据时,从名称节点获得数据块不同副本的存放位置列表,列表中包含了副本所在的数据节点,可以调用 API 来确定客户端和这些数据节点所属的机架 ID。当发现某个数据块副本对应的机架 ID 和客户端对应的机架 ID 相同时,就优先选择该副本读取数据,如果没有发现,就随机选择一个副本读取数据。
数据复制
HDFS 的数据复制采用了流水线复制的策略,大大提高了数据复制过程的效率。当客户端要往 HDFS 中写入一个文件时,这个文件会首先被写入本地,并被切分成若干个块,每个块的大小是由 HDFS 的设定值来决定的。每个块都向 HDFS 集群中的名称节点发起写请求,名称节点会根据系统中各个数据节点的使用情况,选择一个数据节点列表返回给客户端,然后客户端就把数据首先写入列表中的第 1 个数据节点,同时把列表传给第 1 个数据节点,当第 1 个数据节点接收到4 KB 数据的时候,写入本地,并且向列表中的第 2 个数据节点发起连接请求,把自己已经接收到的 4 KB 数据和列表传给第 2 个数据节点。当第 2 个数据节点接收到 4 KB 数据的时候,写入本地,并且向列表中的第 3 个数据节点发起连接请求,依此类推,列表中的多个数据节点形成一条数据复制的流水线。最后,当文件写完的时候,数据复制也同时完成。
3.6 HDFS数据读写过程※ 理解如何读和如何写 P57-P58
在介绍 HDFS 的数据读写过程之前,需要简单介绍一下相关的类。FileSystem 是一个通用文件系统的抽象基类,可以被分布式文件系统继承,所有可能使用 Hadoop 文件系统的代码都要使用到这个类。Hadoop 为 FileSystem 这个抽象类提供了多种具体的实现,DistributedFileSystem 就是 FileSystem 在 HDFS 中的实现。FileSystem 的 open()方法返回的是一个输入流 FSDataInputStream对象,在 HDFS 中具体的输入流就是 DFSInputStream;FileSystem 中的 create()方法返回的是一个输出流 FSDataOutputStream 对象,在 HDFS 中具体的输出流就是 DFSOutputStream。
读数据的过程
客户端连续调用 open()、read()、close()读取数据时,HDFS 内部的执行过程如下(见图 3-8)。
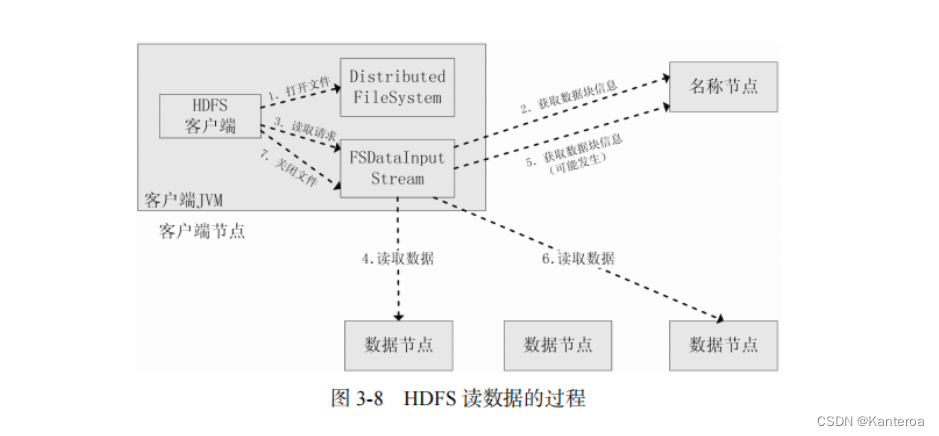
-
客户端通过 FileSystem.open()打开文件,相应地,在 HDFS 中 DistributedFileSystem 具体实现了 FileSystem。因此,调用 open()方法后,DistributedFileSystem 会创建输入流 FSData InputStream,对于HDFS 而言,具体的输入流就是 DFSInputStream。
-
在 DFSInputStream 的构造函数中,输入流通过 ClientProtocal.getBlockLocations()远程调用名称节点,获得文件开始部分数据块的保存位置。对于该数据块,名称节点返回保存该数据块的所有数据节点的地址,同时根据距离客户端的远近对数据节点进行排序;然后,DistributedFileSystem 会利用 DFSInputStream 来实例化 FSDataInputStream,并返回给客户端,同时返回数据块的数据节点地址。
-
获得输入流 FSDataInputStream 后,客户端调用 read()方法开始读取数据。输入流根据前面的排序结果,选择距离客户端最近的数据节点建立连接并读取数据。
-
数据从该数据节点读到客户端;当该数据块读取完毕时,FSDataInputStream 关闭和该数据节点的连接。
-
输入流通过 getBlockLocations()方法查找下一个数据块(如果客户端缓存中已经包含了该数据块的位置信息,就不需要调用该方法)。
写数据的过程
客户端向 HDFS 写数据是一个复杂的过程,这里介绍一下在不发生任何异常的情况下,客户端连续调用 create()、write()和 close()时,HDFS 内部的执行过程(见图 3-9)。
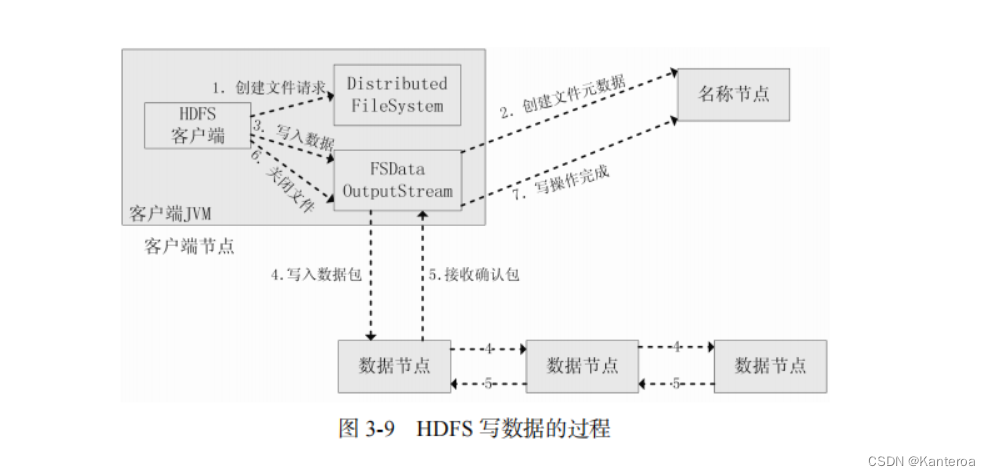
-
客户端通过 FileSystem.create()创建文件,相应地,在 HDFS 中 Distributed FileSystem 具体实现了 FileSystem。因此,调用 create ()方法后,DistributedFileSystem 会创建输出流 FSDataOutputStream,对于 HDFS 而言,具体的输出流就是 DFSOutputStream。
-
然后,DistributedFileSystem 通过 RPC 远程调用名称节点,在文件系统的命名空间中创建一个新的文件。名称节点会执行一些检查,比如文件是否已经存在,客户端是否有权限创建文件等。检查通过之后,名称节点会构造一个新文件,并添加文件信息。远程方法调用结束后,DistributedFileSystem会利用 DFSOutputStream 来实例化 FSDataOutputStream,并返回给客户端,客户端使用这个输出流写入数据。
-
获得输出流 FSDataOutputStream 以后,客户端调用输出流的 write()方法向 HDFS 中对应的文件写入数据。
-
客户端向输出流 FSDataOutputStream 中写入的数据会首先被分成一个个的分包,这些分包被放入 DFSOutputStream 对象的内部队列。输出流 FSDataOutputStream 会向名称节点申请保存文件和副本数据块的若干个数据节点,这些数据节点形成一个数据流管道。队列中的分包最后被打包成数据包,发往数据流管道中的第 1 个数据节点,第 1 个数据节点将数据包发送给第 2 个数据节点,第 2 个数据节点将数据包发送给第 3 个数据节点,这样,数据包会流经管道上的各个数据节点(即 3.5.2 节介绍的流水线复制策略)。
-
因为各个数据节点位于不同的机器上,数据需要通过网络发送。因此,为了保证所有数据节点的数据都是准确的,接收到数据的数据节点要向发送者发送“确认包”(ACK Packet)。确认包沿着数据流管道逆流而上,从数据流管道依次经过各个数据节点并最终发往客户端,当客户端收到应答时,它将对应的分包从内部队列移除。不断执行(3)~(5)步,直到数据全部写完。
-
客户端调用 close()方法关闭输出流,此时开始,客户端不会再向输出流中写入数据,所以,当 DFSOutputStream 对象内部队列中的分包都收到应答以后,就可以使用 ClientProtocol. complete()方法通知名称节点关闭文件,完成一次正常的写文件过程。
3.7 HDFS编程实践
(1)HDFS Shell的基本操作 P59-P60 -同时复习头歌平台HDFS操作命令
在 Linux 终端窗口,我们可以利用 Shell 命令对 Hadoop 进行操作。利用这些命令可以完成HDFS 中文档的上传、下载、复制、查看文件信息、格式化名称节点等操作。关于 HDFS 的 Shell命令有一个统一的格式:
hadoop command [genericOptions] [commandOptions]
HDFS 有很多命令,其中 fs 命令可以说是 HDFS 最常用的命令,利用 fs 命令可以查看 HDFS的目录结构、上传和下载数据、创建文件等。该命令的用法如下:
hadoop fs [genericOptions] [commandOptions]
具体如下。
-
hadoop fs -ls <path>。显示指定的文件的详细信息。 -
hadoop fs -ls -R <path>。ls 命令的递归版本。 -
hadoop fs -cat <path>。将指定的文件的内容输出到标准输出(stdout)。 -
hadoop fs -chgrp [-R] group <path>。将指定的文件所属的组改为 group,使用-R 对 指定的文件夹内的文件进行递归操作。这个命令只适用于超级用户。 -
hadoop fs -chown [-R] [owner] [: [group]] <path>。改变指定的文件所有者,-R 用于递归改变文件夹内的文件所有者。这个命令只适用于超级用户。 -
hadoop fs -chmod [-R] <mode> <path>。将指定的文件的权限更改为。这个命令只适用于超级用户和文件所有者。 -
hadoop fs -tail [-f] <path>。将指定的文件最后 1KB 的内容输出到标准输出(stdout)上,-f 选项用于持续检测新添加到文件中的内容。 -
hadoop fs -stat [format] <path>。以指定的格式返回指定的文件的相关信息。当不指定 format 的时候,返回文件 的创建日期。 -
hadoop fs -touchz <path>。创建一个指定的空文件。 -
hadoop fs -mkdir [-p] <paths>。创建指定的一个或多个文件夹,-p 选项用于递归创建子文件夹。 -
hadoop fs -copyFromLocal <localsrc> <dst>。将本地源文件复制到路径指定的文件或文件夹中。 -
hadoop fs -copyToLocal [-ignorecrc] [-crc] <target> <localdst>。将目标文件复制到本地文件或文件夹中,可用-ignorecrc 选项复制 CRC 校验失败的文件,使用-crc 选项复制文件以及 CRC 信息。 -
hadoop fs -cp <src> <dst>。将文件从源路径复制到目标路径。 -
hadoop fs -du <path>。显示指定的文件或文件夹中所有文件的大小。 -
hadoop fs -expunge。清空回收站,请参考 HDFS 官方文档以获取更多关于回收站特性的信息。 -
hadoop fs -get [-ignorecrc] [-crc] <src> <localdst>。复制指定的文件到本地文件系统指定的文件或文件夹,可用-ignorecrc 选项复制 CRC 校验失败的文件,使用-crc 选项复制文件以及 CRC 信息。 -
hadoop fs -getmerge [-nl] <src> <localdst>。对指定的源目录中的所有文件进行合并,写入指定的本地文件。-nl 是可选的,用于指定在每个文件结尾添加一个换行符。 -
hadoop fs -put <localsrc> <dst>。从本地文件系统中复制指定的单个或多个源文件到指定的目标文件系统中,也支持从标准输入(stdin)中读取输入并写入目标文件系统。 -
hadoop fs -moveFromLocal <localsrc> <dst>。与 put 命令功能相同,但是文件上传结束后会从本地文件系统中删除指定的文件。 -
hadoop fs -mv <src> <dest>。将文件从源路径移动到目标路径。 -
hadoop fs -rm <path>。删除指定的文件,只删除非空目录和文件。 -
hadoop fs -rm -r <path>。删除指定的文件夹及其下的所有文件,-r 选项表示递归删除子目录。 -
hadoop fs -setrep [-R] <path>。改变指定的文件的副本系数,-R 选项用于递归改变目录下所有文件的副本系数。 -
hadoop fs -test -[ezd] <path>。检查指定的文件或文件夹的相关信息。不同选项的作用如下。 -
-e 检查文件是否存在,如果存在则返回 0,否则返回 1。
-
-z 检查文件是否是 0 字节,如果是则返回 0,否则返回 1。
-
-d 如果路径是个目录,则返回 1,否则返回 0。
-
-
hadoop fs -text <path>。将指定的文件输出为文本格式,文件的格式也允许是 zip 和TextRecordInputStream 等。
习题
单选题
-
分布式文件系统指的是什么?(A)
A、把文件分布存储到多个计算机节点上,成千上万的计算机节点构成计算机集群
B、用于在 Hadoop 与传统数据库之间进行数据传递
C、一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统
D、一种高吞吐量的分布式发布订阅消息系统,可以处理消费者规模的网站中的所有动作流数据
-
下面哪一项不属于计算机集群中的节点?(B)
A、主节点(Master Node)
B、源节点(SourceNode)
C、名称结点(NameNode)
D、从节点(Slave Node)
-
在HDFS中,默认一个块多大?(A)
A、64MB
B、32KB
C、128KB
D、16KB
-
下列哪一项不属于HDFS采用抽象的块概念带来的好处?(C)
A、简化系统设计
B、支持大规模文件存储
C、强大的跨平台兼容性
D、适合数据备份
-
在HDFS中,NameNode的主要功能是什么?(D)
A、维护了block id 到datanode本地文件的映射关系
B、存储文件内容
C、文件内存保存在磁盘中
D、存储元数据
-
下面对FsImage的描述,哪个是错误的?(D)
A、FsImage文件没有记录每个块存储在哪个数据节点
B、FsImage文件包含文件系统中所有目录和文件inode的序列化形式
C、FsImage用于维护文件系统树以及文件树中所有的文件和文件夹的元数据
D、FsImage文件记录了每个块具体被存储在哪个数据节点
-
下面对SecondaryNameNode第二名称节点的描述,哪个是错误的?(A)
A、SecondaryNameNode一般是并行运行在多台机器上
B、它是用来保存名称节点中对HDFS元数据信息的备份,并减少名称节点重启的时间
C、SecondaryNameNode通过HTTP GET方式从NameNode上获取到FsImage和EditLog文件,并下载到本地的相应目录下
D、SecondaryNameNode是HDFS架构中的一个组成部分
-
HDFS采用了什么模型?(B)
A、分层模型
B、主从结构模型
C、管道-过滤器模型
D、点对点模型
-
Hadoop项目结构中,HDFS指的是什么?(A)
A、分布式文件系统
B、流数据读写
C、资源管理和调度器
D、Hadoop上的数据仓库
-
下列关于HDFS的描述,哪个不正确?(D)
A、HDFS还采用了相应的数据存放、数据读取和数据复制策略,来提升系统整体读写响应性能
B、HDFS采用了主从(Master/Slave)结构模型
C、HDFS采用了冗余数据存储,增强了数据可靠性
D、HDFS采用块的概念,使得系统的设计变得更加复杂
多选题
- HDFS要实现以下哪几个目标?(ABC)
A、兼容廉价的硬件设备
B、流数据读写
C、大数据集
D、复杂的文件模型
-
HDFS特殊的设计,在实现优良特性的同时,也使得自身具有一些应用局限性,主要包括以下哪几个方面?(BCD)
A、较差的跨平台兼容性
B、无法高效存储大量小文件
C、不支持多用户写入及任意修改文件
D、不适合低延迟数据访问
-
HDFS采用抽象的块概念可以带来以下哪几个明显的好处?(ACD)
A、支持大规模文件存储
B、支持小规模文件存储
C、适合数据备份
D、简化系统设计
-
在HDFS中,名称节点(NameNode)主要保存了哪些核心的数据结构?(AD)
A、FsImage
B、DN8
C、Block
D、EditLog
-
数据节点(DataNode)的主要功能包括哪些?(ABC)
A、负责数据的存储和读取
B、根据客户端或者是名称节点的调度来进行数据的存储和检索
C、向名称节点定期发送自己所存储的块的列表
D、用来保存名称节点中对HDFS元数据信息的备份,并减少名称节点重启的时间
-
HDFS的命名空间包含什么?(BCD)
A、磁盘
B、文件
C、块
D、目录
-
下列对于客服端的描述,哪些是正确的?(ABCD)
A、客户端是用户操作HDFS最常用的方式,HDFS在部署时都提供了客户端
B、HDFS客户端是一个库,暴露了HDFS文件系统接口
C、严格来说,客户端并不算是HDFS的一部分
D、客户端可以支持打开、读取、写入等常见的操作
-
HDFS只设置唯一一个名称节点,这样做虽然大大简化了系统设计,但也带来了哪些明显的局限性?(ABCD)
A、命名空间的限制
B、性能的瓶颈
C、隔离问题
D、集群的可用性
-
HDFS数据块多副本存储具备以下哪些优点?(ABC)
A、加快数据传输速度
B、容易检查数据错误
C、保证数据可靠性
D、适合多平台上运行
-
HDFS具有较高的容错性,设计了哪些相应的机制检测数据错误和进行自动恢复?(BCD)
A、数据源太大
B、数据节点出错
C、数据出错
D、名称节点出错
简答题
- 试述分布式文件系统设计的需求。
| 序号 | 特性 | 描述 | HDFS支持情况 |
|---|---|---|---|
| 1 | 透明性 | 包括访问透明性、位置透明性、性能和伸缩透明性;访问透明性:用户不需要专门区分哪些是本地文件,哪些是远程文件。用户能够通过相同的操作来访问本地和远程文件资源;位置透明性:不改变路径名的前提下,不管文件副本数量和实际存储位置发生何种变化,对用户而言都是透明的;性能和伸缩透明性:系统中节点的增加和减少以及性能的变化对用户而言是透明的,用户感觉不到什么时候节点加入或退出; | HDFS只能提供一定程度的访问透明性,完全的位置透明性、性能和伸缩透明性。 |
| 2 | 并发性 | 客户端对于文件的读写不应该影响其他客户端对同一文件的读写; | HDFS机制非常简单,任何时候只允许有一个程序写入某个文件。 |
| 3 | 文件复制 | 一个文件可以拥有不同位置的多个副本 | HDFS采用多副本机制。 |
| 4 | 硬件和操作系统异构性 | 可以在不同的操作系统和计算机上实现同样的客户端和服务器端程序; | HDFS采用JAVA,具有很好的跨平台性。 |
| 5 | 可伸缩性 | 支持节点的动态加入和退出; | HDFS建立在大规模廉价机器上的分布式文件系统集群,具有良好的可伸缩性。 |
| 6 | 容错 | 保证文件服务器在客户端或服务器出现问题的时候能正常使用; | HDFS具有多副本机制和故障自动检测恢复机制。 |
| 7 | 安全 | 保障系统的安全性; | HDFS安全性较弱。 |
- 分布式文件系统是如何实现较高水平的扩展的?
分布式文件系统把文件分布存储到多个计算机节点上,成千上万的计算机节点构成计算机集群。
- 试述HDFS中的块和普通文件系统中的块的区别。
HDFS中的块比普通文件系统中的块大很多。且在HDFS中如果一个文件小于数据块的大小,它并不占用整个数据存储块的空间。
- 试述HDFS中的名称节点和数据节点的具体功能。
名称节点:负责文件和目录的创建删除和重命名等,管理数据节点和文件块的映射关系。
数据节点:负责数据的存储和读取。
- 在分布式文件系统中,中心节点的设计至关重要,请阐述HDFS是如何减轻中心节点的负担的。
名称节点不参与数据的传输。
- HDFS只设置唯一一个名称节点,在简化系统的同时也带来了一些明显的局限性,请阐述局限性具体表现在哪些方面。
1)命名空间的限制:
名称节点是保存在内存中,因此名称节点能够容纳对象(文件,块)的个数受到内存空间大小的限制
2)性能的瓶颈
整个分布式文件系统的吞吐量受限于单个名称节点的吞吐量
3)隔离问题
由于集群中只有一个名称节点,只有一个命名空间,因此无法为不同应用程序进行隔离
4)集群的可用性
一旦唯一的名称节点发生故障,会导致整个集群不可用
- 试述HDFS的冗余数据保存策略。
HDFS采用多副本方式对数据进行冗余存储,通常一个数据块的多个副本会被分不到不同的数据节点上。
- 数据复制主要是在数据写入和数据恢复的时候发生,HDFS数据复制是使用流水线复制的策略,请阐述该策略的细节。
这个文件首先被写入本地,被切分成若干个块,每个块向HDFS集群中名称节点发起写请求,名称节点会将各个数据节点的使用情况,选择一个数据节点列表返回给客户端,当第一个数据节点接收块的时候,写入本地,并且向第二数据节点发起连接请求,把自己的接收的块传给第二个数据节点,依次类推,列表中的对个数据节点形成一条数据复制的流水线。最后数据写完后,数据复制同时完成。
- 试述HDFS是如何探测错误发生以及如何进行恢复的。
(1)名称节点出错:
1)把名称节点的元数据信息同步存储到其他文件系统;
2)可以把第二名称节点作为不就措施
一般会把两者结合使用,其他文件系统的元数据信息放到第二名称节点进行恢复,并把第二名称节点作为名称节点使用(这样做仍然会有一部分数据丢失)
(2)数据节点出错:
数据节点定期向名称节点发送心跳信息,向名称节点报告状态,如果名称节点没有收到某些数据节点时,这时名称节点将这些数据节点标记为宕机,由于这些数据节点不可用导致一些数据块的副本数据量小于冗余因子时,就会启动数据冗余复制,生成新的副本
(3)数据出错:
网络传输和磁盘错误等因数都会造成数据的错误,客户端读取数据后,会采用md5对数据块进行校验,以正确读取到正确的数据。如果校验出错,客户端就会请求到另外一个数据节点读取该文件块,并向名称节点报告这个文件错误,名称节点会定期检查并重新复制这个块
- 请阐述HDFS在不发生故障的情况下读文件的过程。
1) 使用HDFS提供供的客户端Client, 向远程的Namenode发起RPC请求;
2) Namenode会视情况返回文件的部分或者全部block列表, 对于每个block, Namenode都会返回有该block拷贝的DataNode地址;
3) 客户端Client会选取离客户端最近的DataNode来读取block; 如果客户端本身就是DataNode,那么将从本地直接获取数据;
4) 读取完当前block的数据后, 关闭当前的DataNode链接, 并为读取下一个block寻找最佳的DataNode;
5)当读完列表block后, 且文件读取还没有结束, 客户端会继续向Namenode获取下一批的block列表;
6) 读取完一个block都会进行checksum验证, 如果读取datanode时出现错误, 客户端会通知Namenode, 然后再从下一个拥有该block拷贝的datanode继续读。
- 请阐述HDFS在不发生故障的情况下写文件的过程。
1) 使用HDFS提供的客户端Client, 向远程的Namenode发起RPC请求
2) Namenode会检查要创建的文件是否已经存在, 创建者是否有权限进行操作, 成功则会为文件创建一个记录, 否则会让客户端抛出异常;
3) 当客户端开始写入文件的时候, 客户端会将文件切分成多个packets, 并在内部以数据队列“data queue( 数据队列) ”的形式管理这些packets, 并向Namenode申请blocks, 获取用来存储replicas的合适的datanode列表, 列表的大小根据Namenode中replication的设定而定;
4) 开始以pipeline( 管道) 的形式将packet写入所有的replicas中。 开发库把packet以流的方式写入第一个datanode, 该datanode把该packet存储之后, 再将其传递给在此pipeline中的下一个datanode, 直到最后一个datanode, 这种写数据的方式呈流水线的形式。
5) 最后一个datanode成功存储之后会返回一个ack packet( 确认队列) , 在pipeline里传递至客户端, 在客户端的开发库内部维护着”ack queue”, 成功收到datanode返回的ack packet后会从”ack queue”移除相应的packet。
6) 如果传输过程中, 有某个datanode出现了故障, 那么当前的pipeline会被关闭, 出现故障的datanode会从当前的pipeline中移除, 剩余的block会继续剩下的datanode中继续以pipeline的形式传输, 同时Namenode会分配一个新的datanode, 保持replicas设定的数量。
7) 客户端完成数据的写入后, 会对数据流调用close()方法, 关闭数据流;
8) 只要写入了dfs.replication.min的复本数( 默认为1),写操作就会成功, 并且这个块可以在集群中异步复制, 直到达到其目标复本数( dfs. replication的默认值为3),因为namenode已经知道文件由哪些块组成, 所以它在返回成功前只需要等待数据块进行最小量的复制。
第四章分布式数据库HBase
4.1 HBase概述
(1)HBase和BigTable的关系 P67
图 4-1 描述了 Hadoop 生态系统中 HBase 与其他部分的关系。
HBase 利用 Hadoop MapReduce来处理 HBase 中的海量数据,实现高性能计算;
利用 ZooKeeper 作为协同服务,实现稳定服务和失败恢复;
使用 HDFS 作为高可靠的底层存储,利用廉价集群提供海量数据存储能力。当然,HBase也可以直接使用本地文件系统而不用 HDFS 作为底层数据存储方式。不过,为了提高数据可靠性和系统的健壮性,发挥 HBase 处理大数据量等功能,一般都使用 HDFS 作为 HBase 的底层数据存储系统。
此外,为了方便在 HBase 上进行数据处理,Sqoop 为 HBase 提供了高效、便捷的关系数据库管理系统(Relational DataBase Management System,RDBMS)数据导入功能,Pig 和 Hive为 HBase 提供了高层语言支持。
HBase 是 BigTable 的开源实现,HBase 和 BigTable 的底层技术对应关系见表 4-1。
| 项目 | BigTable | HBase |
|---|---|---|
| 文件存储系统 | GFS | HDFS |
| 海量数据处理 | MapReduce | Hadoop MapReduce |
| 协同服务管理 | Chubby | ZooKeeper |
4.2 HBase访问接口 P69页表格
HBase 提供了 Native Java API、HBase Shell、Thrift Gateway、REST Gateway、Pig、Hive 等多种访问方式,表 4-2 给出了 HBase 访问接口的类型、特点和使用场合。
| 类型 | 特点 | 使用场合 |
|---|---|---|
| Native Java API | 常规和高效的访问方式 | 适合Hadoop MapReduce作业并行批处理HBase表数据 |
| HBase Shell | HBase的命令行工具,最简单的接口 | 适合HBase管理 |
| Thrift Gateway | 利用Thrift序列化技术,支持C++、PHP、Python等多种语言 | 适合其他异构系统在线访问HBase表数据 |
| REST Gateway | 解除语言限制 | 支持REST风格的HTTPAPI访问HBase |
| Pig | 使用 Pig Latin 流式编程语言来处理 HBase中的数据 | 适合做数据统计 |
| Hive | 简单 | 当需要以类似 SQL 的方式来访问 HBase 的时候 |
4.3 HBase数据模型※
(1)数据模型相关概念-6个 P70-P71
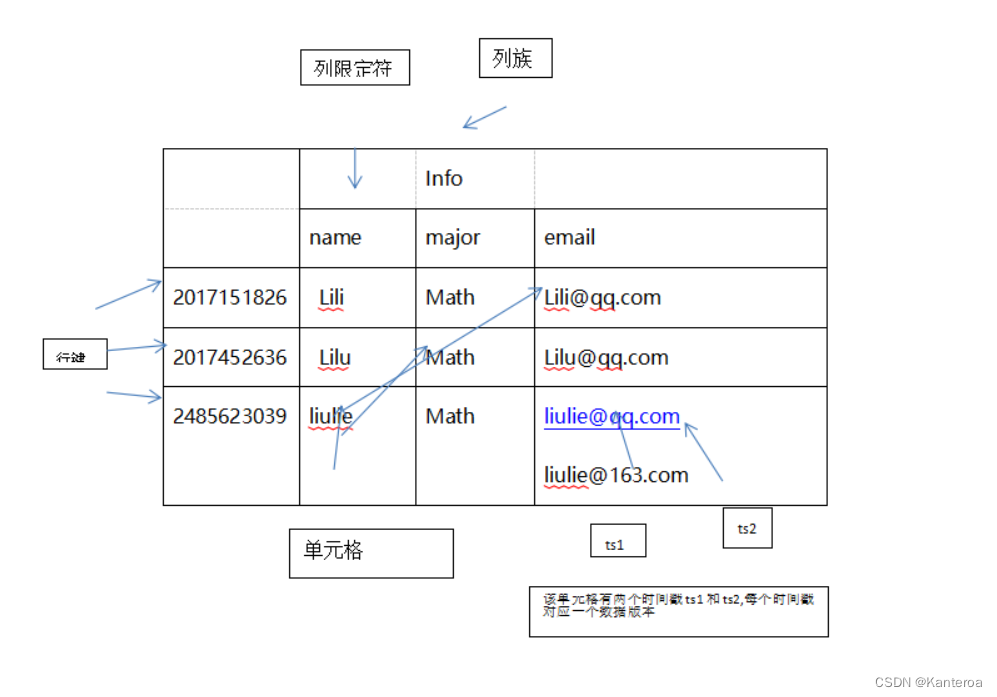
HBase 实际上就是一个稀疏、多维、持久化存储的映射表,它采用行键(Row Key)、列族(Column Family)、列限定符(Column Qualifier)和时间戳(Timestamp)进行索引,每个值都是未经解释的字节数组 byte[]。下面具体介绍 HBase 数据模型的相关概念。
1.表
HBase 采用表来组织数据,表由行和列组成,列划分为若干个列族。
2.行键
每个 HBase 表都由若干行组成,每个行由行键(Row Key)来标识。访问表中的行只有 3 种方式:通过单个行键访问;通过一个行键的区间来访问;全表扫描。行键可以是任意字符串(最大长度是 64 KB,实际应用中长度一般为 10~100 Byte)。在 HBase 内部,行键保存为字节数组。存储时,数据按照行键的字典序存储。在设计行键时,要充分考虑这个特性,将经常一起读取的行存储在一起。
3.列族
一个 HBase 表被分组成许多“列族”的集合,它是基本的访问控制单元。列族需要在表创建时就定义好,数量不能太多(HBase 的一些缺陷使得列族的数量只限于几十个),而且不能频繁修改。存储在一个列族当中的所有数据,通常都属于同一种数据类型,这通常意味着数据具有较高的压缩率。表中的每个列都归属于某个列族,数据可以被存放到列族的某个列下面,但是在把数据存放到这个列族的某个列下面之前,必须首先创建这个列族。在创建完列族以后,就可以使用同一个列族当中的列。列名都以列族作为前缀。例如,courses:history 和 courses:math 这两个列都属于 courses 这个列族。在 HBase 中,访问控制、磁盘和内存的使用统计都是在列族层面进行的。
实际应用中,我们可以借助列族上的控制权限帮助实现特定的目的。比如,我们可以允许一些应用能够向表中添加新的数据,而另一些应用只被允许浏览数据。HBase 列族还可以被配置成支持不同类型的访问模式。比如,一个列族也可以被设置成放入内存当中,以消耗内存为代价,从而换取更好的响应性能。
4.列限定符
列族里的数据通过列限定符(或列)来定位。列限定符不用事先定义,也不需要在不同行之间保持一致。列限定符没有数据类型,总被视为字节数组 byte[]。
5.单元格
在 HBase 表中,通过行键、列族和列限定符确定一个“单元格”(Cell)。单元格中存储的数据没有数据类型,总被视为字节数组 byte[]。每个单元格中可以保存一个数据的多个版本,每个版本对应一个不同的时间戳。
6.时间戳
每个单元格都保存着同一份数据的多个版本,这些版本采用时间戳进行索引。每次对一个单元格执行操作(新建、修改、删除)时,HBase 都会隐式地自动生成并存储一个时间戳。时间戳一般是 64 位整型数据,可以由用户自己赋值(自己生成唯一时间戳可以避免应用程序中出现数据版本冲突),也可以由 HBase 在数据写入时自动赋值。一个单元格的不同版本根据时间戳降序存储,这样,最新的版本可以被最先读取。
下面以一个实例来阐释 HBase 的数据模型。图 4-2 是一张用来存储学生信息的 HBase 表,学号作为行键来唯一标识每个学生,表中设计了列族 Info 来保存学生相关信息,列族 Info 中包含 3个列—name、major 和 email,分别用来保存学生的姓名、专业和电子邮件信息。学号为“201505003”的学生存在两个版本的电子邮件地址,时间戳分别为 ts1=1174184619081 和ts2=1174184620720,时间戳较大的版本的数据是最新的数据。
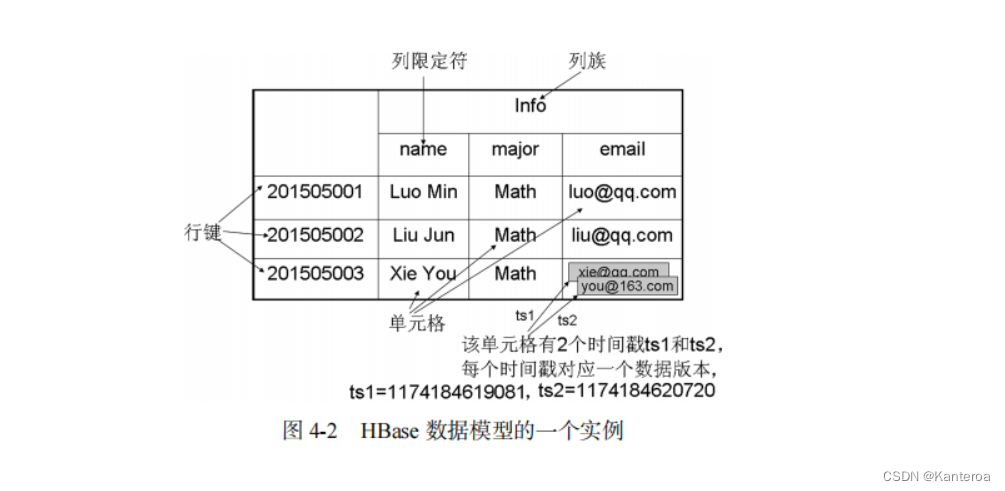
(2)四维坐标是什么 P71-P72
HBase 使用坐标来定位表中的数据,也就是说,每个值都通过坐标来访问。对于我们熟悉的关系数据库而言,数据定位可以理解为采用“二维坐标”,即根据行和列就可以确定表中一个具体的值。但是,HBase 中需要根据行键、列族、列限定符和时间戳来确定一个单元格,因此可以视为一个“四维坐标”,即["行键", "列族", "列限定符", "时间戳"]。
例如,在图 4-2 中,由行键“201505003”、列族“Info”、列限定符“email”和时间戳“ 1174184619081 ”( ts1 ) 这 4 个坐标值确定的单元格 [“201505003”, “Info”, “email”, “1174184619081”],里面存储的值是“[email protected]”;由行键“201505003”、列族“Info”、列限定符“email”和时间戳“1174184620720”(ts2)这 4 个坐标值确定的单元格[“201505003”, “Info”, “email”, “1174184620720”],里面存储的值是“[email protected]”。
如果把所有坐标看成一个整体,视为“键”,把四维坐标对应的单元格中的数据视为“值”,那么,HBase 可以看成一个键值数据库。
| 键 | 值 |
|---|---|
| [“20150003”,“Info”,“email”,“1174184619081”] | “[email protected]” |
| [“201505003”,“Info”,“email”,“1174184620720”] | “[email protected]” |
(3)面向列的存储的理解 P73
通过前面的论述,我们已经知道 HBase 是面向列的存储,也就是说,HBase 是一个“列式数据库”。而传统的关系数据库采用的是面向行的存储,被称为“行式数据库”。为了加深对这个问题的认识,下面我们对面向行的存储(行式数据库)和面向列的存储(列式数据库)做一个简单介绍。
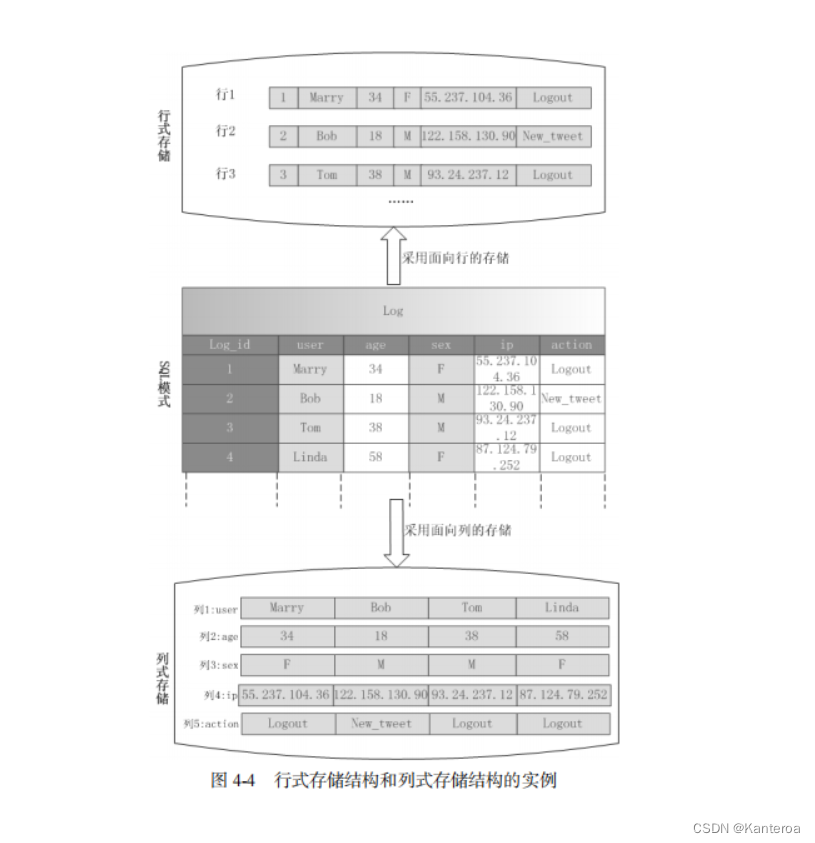
简单地说,行式数据库使用行存储模型(N-ary Storage Model,NSM),一个元组(或行)会被连续地存储在磁盘页中,如图 4-3 所示。也就是说,数据是一行一行被存储的,第一行写入磁盘页后,再继续写入第二行,以此类推。在从磁盘中读取数据时,需要从磁盘中顺序扫描每个元组的完整内容,然后从每个元组中筛选出查询所需要的属性。如果每个元组只有少量属性的值对于查询是有用的,那么 NSM 就会浪费许多磁盘空间和内存带宽。
列式数据库采用列存储模型(Decomposition Storage Model,DSM),它是在 1985 年提出来的,目的是最小化无用的 I/O。DSM 采用了不同于 NSM 的思路,对于采用 DSM 的关系数据库,DSM会对关系进行垂直分解,并为每个属性分配一个子关系。因此,一个具有 n 个属性的关系会被分解成 n 个子关系,每个子关系单独存储,每个子关系只有当其相应的属性被请求时才会被访问。也就是说,DSM 以关系数据库中的属性或列为单位进行存储,关系中多个元组的同一属性值(或同一列值)会被存储在一起,而一个元组中不同属性值通常会被分别存放于不同的磁盘页中。
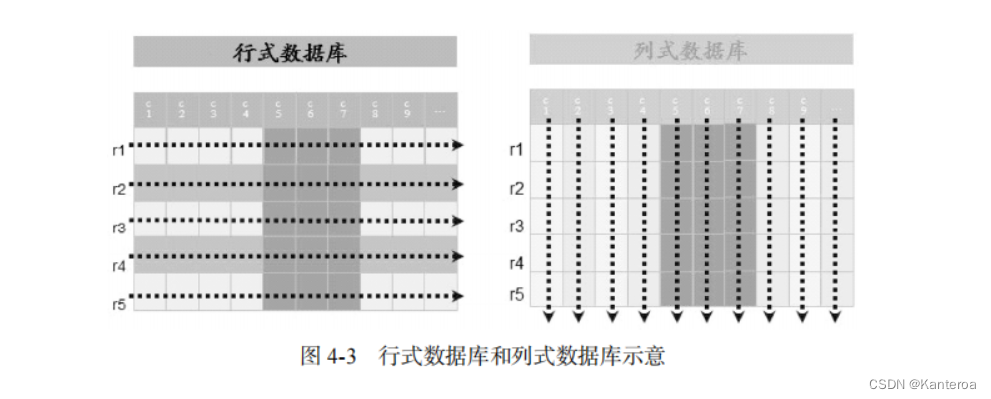
图 4-4 是一个关于行式存储结构和列式存储结构的实例,从中可以看出两种存储方式的具体差别。
行式数据库主要适合小批量的数据处理,如联机事务型数据处理,我们平时熟悉的 Oracle 和MySQL 等关系数据库都属于行式数据库。列式数据库主要适合批量数据处理和即席查询(Ad-Hoc Query)。列式数据库的优点是:可以降低 I/O 开销,支持大量并发用户查询,其数据处理速度比传统方法快 100 倍,因为仅需要处理可以回答这些查询的列,而不是分类整理与特定查询无关的数据行;具有较高的数据压缩比,较传统的行式数据库更加有效,甚至能达到比其高 5 倍的效果。
列式数据库主要用于数据挖掘、决策支持和地理信息系统等查询密集型系统中。因为采用列式数据库一次查询就可以得出结果,而不必每次都要遍历所有的数据库,所以,列式数据库大多应用在人口统计调查、医疗分析等情况中,这种情况需要处理大量的数据,假如采用行式数据库,势必导致消耗的时间被无限延长。
DSM 的缺陷是:执行连接操作时需要昂贵的元组重构代价。因为一个元组的不同属性被分散到不同磁盘页中存储,当需要一个完整的元组时,就要从多个磁盘页中读取相应字段的值来重新组合得到原来的一个元组。对于联机事务型数据而言,处理这些数据需要频繁对一些元组进行修改(如百货商场售出一件衣服后要立即修改库存数据),如果采用 DSM,就会带来高昂的开销。在过去的很多年里,数据库主要应用于联机事务型数据处理。因此,在很长一段时间里,主流商业数据库大都采用了 NSM 而不是 DSM。但是,随着市场需求的变化,分析型应用开始发挥着越来越重要的作用,企业需要分析各种经营数据帮助企业制定决策,而对于分析型应用而言,一般数据被存储后不会发生修改(如数据仓库),因此不会涉及昂贵的元组重构代价。所以,近些年DSM 开始受到青睐,并且出现了一些采用 DSM 的商业产品和学术研究原型系统,如 Sybase IQ、ParAccel、Sand/DNA Analytics、Vertica、InfiniDB、INFOBright、MonetDB 和 LucidDB 等。类似Sybase IQ 和 Vertica 这些商业化的列式数据库,已经可以很好地满足数据仓库等分析型应用的需求,并且可以获得较高的性能。鉴于 DSM 的许多优良特性,HBase 等非关系数据库(或称为 NoSQL数据库)也借鉴了这种面向列的存储格式。
可以看出,如果严格从关系数据库的角度来看,HBase 并不是一个列式存储的数据库,毕竟HBase 是以列族为单位进行分解的(列族当中可以包含多个列),而不是每个列都单独存储,但是HBase 借鉴和利用了磁盘上的这种列存储格式,所以,从这个角度来说,HBase 可以被视为列式数据库。
4.4 HBase的实现原理※
(1)HBase功能组件 P75
HBase 的实现包括 3 个主要的功能组件:库函数,链接到每个客户端;一个 Master 主服务器(也称为 Master);许多个 Region 服务器。Region 服务器负责存储和维护分配给自己的 Region,处理来自客户端的读写请求。Master 主服务器负责管理和维护 HBase 表的分区信息,比如一个表被分成了哪些 Region,每个 Region 被存放在哪台 Region 服务器上,同时也负责维护 Region 服务器列表。因此,如果 Master 主服务器死机,那么整个系统都会无效。Master 会实时监测集群中的 Region 服务器,把特定的 Region 分配到可用的 Region 服务器上,并确保整个集群内部不同 Region 服务器之间的负载均衡。当某个 Region 服务器因出现故障而失效时,Master 会把该故障服务器上存储的 Region 重新分配给其他可用的 Region 服务器。除此以外,Master 还处理模式变化,如表和列族的创建。
客户端并不是直接从 Master 主服务器上读取数据,而是在获得 Region 的存储位置信息后,直接从 Region 服务器上读取数据。尤其需要指出的是,HBase 客户端并不依赖于 Master 而是借助于 ZooKeeper 来获得 Region 的位置信息的,所以大多数客户端从来不和 Master 主服务器通信,这种设计方式使 Master 的负载很小。
(2)Region的定义、和表的关系、Region定位方式 P76-P78
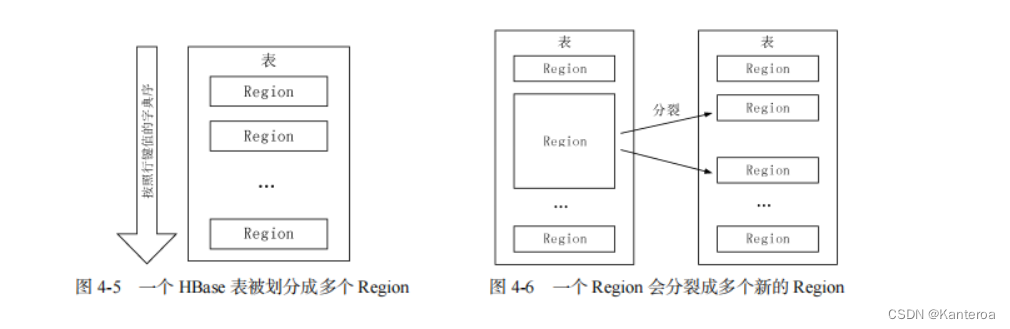
在一个 HBase 中,存储了许多表。对于每个 HBase 表而言,表中的行是根据行键的值的字典序进行维护的,表中包含的行的数量可能非常庞大,无法存储在一台机器上,需要分布存储到多台机器上。因此,需要根据行键的值对表中的行进行分区(见图 4-5)。每个行区间构成一个分区,被称为“Region”。Region 包含了位于某个值域区间内的所有数据,是负载均衡和数据分发的基本单位。这些 Region 会被分发到不同的 Region 服务器上。
初始时,每个表只包含一个 Region,随着数据的不断插入,Region 会持续增大。当一个 Region中包含的行数量达到一个阈值时,就会被自动等分成两个新的 Region(见图 4-6),随着表中行的数量继续增加,就会分裂出越来越多的 Region。
每个 Region 的默认大小是 100~200 MB,是 HBase中负载均衡和数据分发的基本单位。Master主服务器会把不同的 Region 分配到不同的 Region 服务器上(见图 4-7),但是同一个 Region 不会被拆分到多个 Region 服务器上。每个 Region 服务器负责管理一个 Region 集合,通常在每个 Region服务器上会放置 10~1000 个 Region。
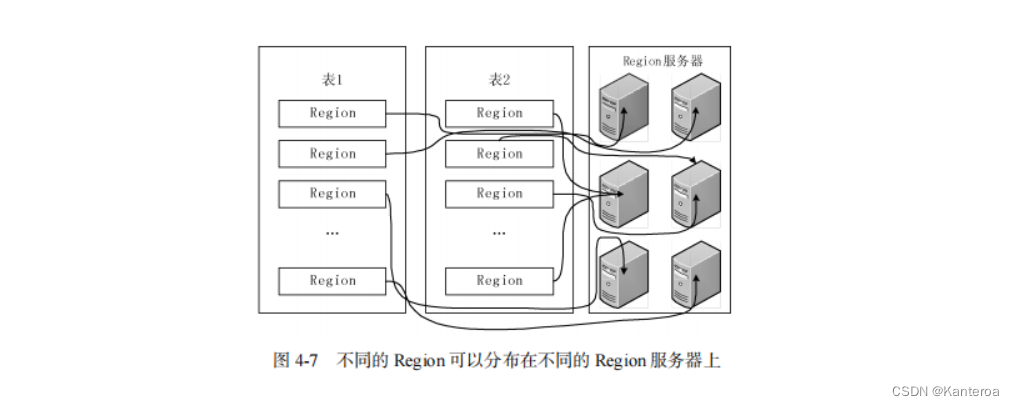
一个 HBase 的表可能非常庞大,会被分裂成很多个 Region,这些 Region 可被分发到不同的Region 服务器上。因此,必须设计相应的 Region 定位机制,保证客户端知道到可以在哪里找到自己所需要的数据。
每个 Region 都有一个 RegionID 来标识它的唯一性,这样,一个 Region 标识符就可以表示成“表名+开始主键+RegionID”。
有了 Region 标识符,就可以唯一地标识每个 Region。为了定位每个 Region 所在的位置,可以构建一张映射表。映射表的每个条目(或每行)包含两项内容,一个是 Region 标识符,另一个是 Region 服务器标识。这个条目表示 Region 和 Region 服务器之间的对应关系,从而可以知道某个 Region 被保存在哪个 Region 服务器中。这个映射表包含了关于 Region 的元数据(即 Region和 Region 服务器之间的对应关系),因此也被称为“元数据表”,又名“.META.表”。
当一个 HBase 表中的 Region 数量非常庞大的时候,.META.表的条目就会非常多,一个服务器保存不下,也需要分区存储到不同的服务器上,因此.META.表也会被分裂成多个 Region。这时,为了定位这些 Region,就需要构建一个新的映射表,记录所有元数据的具体位置,这个新的映射表就是“根数据表”,又名“-ROOT-表”。-ROOT-表是不能被分割的,永远只存在一个 Region 用于存放-ROOT-表。因此这个用来存放-ROOT-表的唯一一个 Region,它的名字是在程序中被“写死”的,Master 主服务器永远知道它的位置。
综上所述,HBase 使用类似 B+树的三层结构来保存 Region 位置信息(见图 4-8)。下表给出了 HBase 三层结构中各层次的名称和作用。
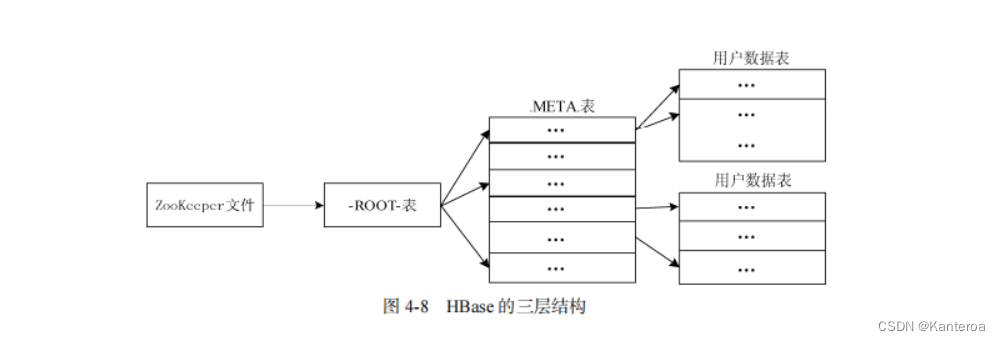
| 层次 | 名称 | 作用 |
|---|---|---|
| 第一层 | ZooKeeper 文件 | 记录了-ROOT-表的位置信息,保证集群内各个组件的同步 |
| 第二层 | -ROOT-表 | 记录了.META.表的Region位置信息,-ROOT-表只能有一个Region。通过-ROOT-表就可以访问.META.表中的数据 |
| 第三层 | .META.表 | 记录了用户数据表的Region位置信息,.META.表可以有多个Region, 保存了HBase中所有用户数据表的Region位置信息 |
为了加快访问速度,.META.表的全部 Region 都会被保存在内存中。假设.META.表的每行(一个映射条目)在内存中大约占用 1 KB,并且每个 Region 限制为 128 MB,那么,上面的三层结构可以保存的用户数据表的 Region 数目的计算方法是:(-ROOT-表能够寻址的.META.表的 Region个数)×(每个.META.表的 Region 可以寻址的用户数据表的 Region 个数)。一个-ROOT-表最多只能有一个 Region,也就是最多只能有 128 MB,按照每行(一个映射条目)占用 1 KB 内存计算,128 MB 空间可以容纳 128 MB/1 KB=217行,也就是说,一个-ROOT-表可以寻址 217个.META.表的 Region。同理,每个.META.表的 Region 可以寻址的用户数据表的 Region 数目是 128 MB/1 KB=217。最终,三层结构可以保存的 Region 数目是(128 MB/1 KB)×(128 MB/1 KB) = 234个 Region。
4.5 HBase运行机制
(1)系统架构+四个系统组件功能 P78-P79
HBase 的系统架构如图 4-9 所示,包括客户端、ZooKeeper 服务器、Master 主服务器、Region服务器。需要说明的是,HBase 一般采用 HDFS 作为底层数据存储系统,因此图 4-9 中加入了 HDFS和 Hadoop。
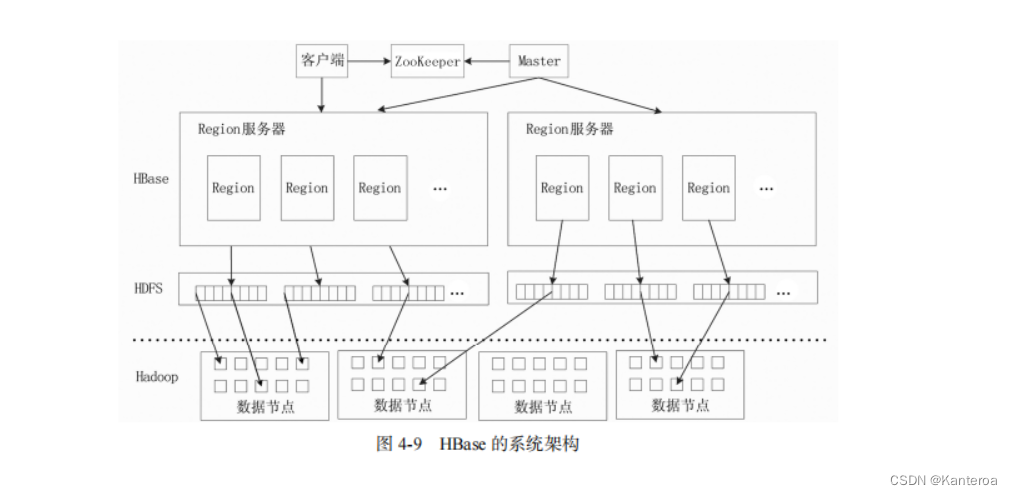
1.客户端
客户端包含访问 HBase 的接口,同时在缓存中维护着已经访问过的 Region 位置信息,用来加快后续数据访问过程。HBase 客户端使用 HBase 的 RPC 机制与 Master 和 Region 服务器进行通信。其中,对于管理类操作,客户端与 Master 进行 RPC;而对于数据读写类操作,客户端会与Region 服务器进行 RPC。
2.ZooKeeper 服务器
ZooKeeper 服务器并非一台单一的机器,可能是由多台机器构成的集群来提供稳定可靠的协同服务。ZooKeeper 服务器能够很容易地实现集群管理的功能,如果有多台服务器组成一个服务器集群,那么必须有一个“总管”知道当前集群中每台机器的服务状态,一旦某台机器不能提供服务,集群中其他机器必须知道,从而做出调整、重新分配服务策略。同样,当增加集群的服务能力时,就会增加一台或多台服务器,此时也必须让“总管”知道。
在 HBase 服务器集群中,包含了一个 Master 主服务器和多个 Region 服务器。Master 就是这个 HBase 集群的“总管”,它必须知道 Region 服务器的状态。ZooKeeper 服务器就可以轻松做到这一点,每个 Region 服务器都需要到 ZooKeeper 服务器中进行注册,ZooKeeper 服务器会实时监控每个 Region 服务器的状态并通知 Master 主服务器,这样,Master 主服务器就可以通过 ZooKeeper服务器随时感知到各个 Region 服务器的工作状态。
ZooKeeper 服务器不仅能够帮助维护当前的集群中机器的服务状态,而且能够帮助选出一个“总管”,让这个总管来管理集群。HBase 中可以启动多个 Master,但是 ZooKeeper 服务器可以帮助选举出一个 Master 主服务器作为集群的总管,并保证在任何时刻总有唯一一个 Master 主服务器在运行,这就避免了 Master 主服务器的“单点失效”问题。
ZooKeeper 服务器中保存了-ROOT-表的地址和 Master 主服务器的地址,客户端可以通过访问ZooKeeper 服务器获得-ROOT-表的地址,并最终通过“三级寻址”找到所需的数据。ZooKeeper服务器中还存储了 HBase 的模式,包括 Hbase 里有哪些表,每个表有哪些列族。
3.Master 主服务器
Master 主服务器主要负责表和 Region 的管理工作。
- 管理用户对表的增加、删除、修改、查询等操作。
- 实现不同 Region 服务器之间的负载均衡。
- 在 Region 分裂或合并后,负责重新调整 Region 的分布。
- 对发生故障失效的 Region 服务器上的 Region 进行迁移。
客户端访问 HBase 上数据的过程并不需要 Master 主服务器的参与,客户端可以访问ZooKeeper 服务器获取-ROOT-表的地址,并最终到相应的 Region 服务器进行数据读写,Master主服务器仅维护着表和 Region 的元数据信息,因此负载很低。任何时刻,一个 Region 只能分配给一个 Region 服务器。Master 主服务器维护了当前可用的Region 服务器列表,以及确定当前哪些 Region 分配给哪些 Region 服务器,哪些 Region 还未被分配。当存在未被分配的 Region,并且有一个 Region 服务器上有可用空间时,Master 主服务器就给这个 Region 服务器发送一个请求,把该 Region 分配给它。Region 服务器接收请求并完成数据加载后,就开始负责管理该 Region 对象,并对外提供服务。
4.Region 服务器
Region 服务器是 HBase 中最核心的模块,负责维护分配给自己的 Region,并响应用户的读写请求。HBase 一般采用 HDFS 作为底层存储的文件系统(见图 4-9),因此 Region 服务器需要向HDFS 中读写数据。采用 HDFS 作为底层存储系统,可以为 HBase 提供可靠稳定的数据存储,HBase自身并不具备数据复制和维护数据副本的功能,而HDFS可以为HBase提供这些支持。当然,HBase也可以不采用 HDFS,而是使用其他任何支持 Hadoop 接口的文件系统作为底层存储文件系统,比如本地文件系统或云计算环境中的 Amazon S3(Simple Storage Service)。
(2)HBase工作原理 P80-P81
Region 服务器的工作原理
Region 服务器是 HBase 中最核心的模块,图 4-10 描述了 Region 服务器向 HDFS 中读写数据的基本原理。从图中可以看出,Region 服务器内部管理了一系列 Region 对象和一个 HLog 文件。其中 HLog 是磁盘上面的记录文件,它记录着所有的更新操作。每个 Region 对象由多个 Store 组成,每个 Store 对应表中的一个列族的存储。每个 Store 又包含一个 MemStore 和若干个 StoreFile。
其中,MemStore 是在内存中的缓存,保存最近更新的数据;StoreFile 是磁盘中的文件,这些文件都是 B 树结构的,方便快速读取。在底层,StoreFile 通过 HDFS 的 HFile 实现,HFile 的数据块通常采用压缩方式存储,压缩之后可以大大减少网络 I/O 和磁盘 I/O。
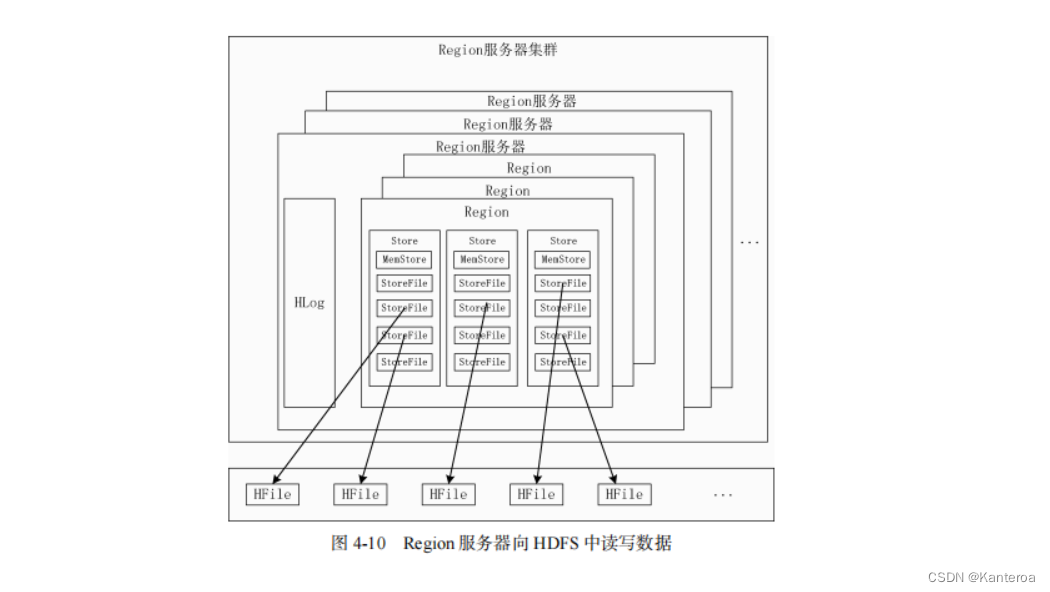
1.用户读写数据的过程
当用户写入数据时,会被分配到相应的 Region 服务器去执行操作。用户数据首先被写入MemStore 和 HLog 中,当操作写入 HLog 之后,commit()调用才会将其返回给客户端。
当用户读取数据时,Region 服务器会首先访问 MemStore 缓存,如果数据不在缓存中,才会到磁盘上面的 StoreFile 中去寻找。
2.缓存的刷新
MemStore 缓存的容量有限,系统会周期性地调用 Region.flushcache()把 MemStore 缓存里面的内容写到磁盘的 StoreFile 文件中,清空缓存,并在 HLog 文件中写入一个标记,用来表示缓存中的内容已经被写入 StoreFile 文件中。每次缓存刷新操作都会在磁盘上生成一个新的 StoreFile 文件,因此每个 Store 会包含多个 StoreFile 文件。
每个 Region 服务器都有一个自己的 HLog 文件。在启动的时候,每个 Region 服务器都会检查自己的 HLog 文件,确认最近一次执行缓存刷新操作之后是否发生新的写入操作。如果没有更新,说明所有数据已经被永久保存到磁盘的 StoreFile 文件中;如果发现更新,就先把这些更新写入 MemStore,然后刷新缓存,写入磁盘的 StoreFile 文件中。最后,删除旧的 HLog 文件,并开始为用户提供数据访问服务。
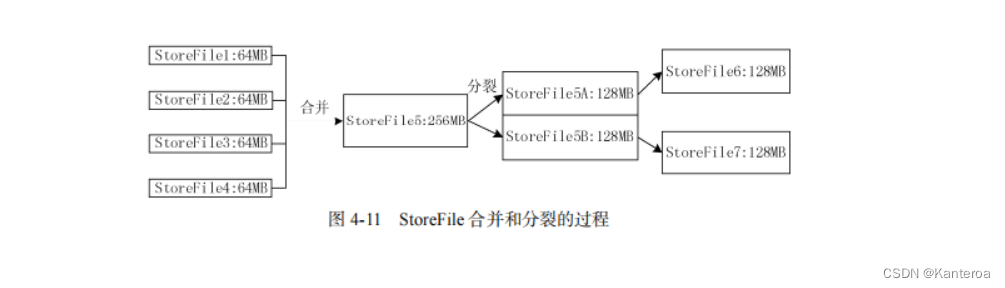
3.StoreFile 的合并
每次 MemStore 缓存的刷新操作都会在磁盘上生成一个新的 StoreFile 文件,这样,系统中的每个 Store 就会存在多个 StoreFile 文件。当需要访问某个 Store 中的某个值时,就必须查找所有StoreFile 文件,非常耗费时间。因此,为了减少查找时间,系统一般会调用 Store.compact()把多个 StoreFile 文件合并成一个大文件。由于合并操作比较耗费资源,因此只会在 StoreFile 文件的数量达到一个阈值的时候才会触发合并操作。
Store 的工作原理
Region 服务器是 HBase 的核心模块,而 Store 是 Region 服务器的核心。每个 Store 对应了表中的一个列族的存储。每个 Store 包含一个 MemStore 缓存和若干个 StoreFile 文件。MemStore 是排序的内存缓冲区,当用户写入数据时,系统首先把数据放入 MemStore 缓存,当 MemStore 缓存满时,就会刷新到磁盘中的一个 StoreFile 文件中。随着 StoreFile 文件数量的不断增加,当达到事先设定的数量时,就会触发文件合并操作,多个 StoreFile 文件会被合并成一个大的 StoreFile 文件。当多个 StoreFile 文件合并后,会逐步形成越来越大的 StoreFile 文件,当单个StoreFile 文件大小超过一定阈值时,就会触发文件分裂操作。同时,当前的一个父 Region 会被分裂成两个子 Region,父 Region 会下线,新分裂出的两个子 Region 会被 Master 主服务器分配到相应的 Region 服务器上。StoreFile 合并和分裂的过程如图 4-11 所示。
HLog 的工作原理
在分布式环境下,必须考虑到系统出错的情形,比如当 Region 服务器发生故障时,MemStore缓存中的数据(还没有被写入文件)会全部丢失。因此,HBase 采用 HLog 来保证系统发生故障时能够恢复到正确的状态。
HBase 系统为每个 Region 服务器配置了一个 HLog 文件,它是一种预写式日志(Write Ahead Log),也就是说,用户更新数据必须首先被记入日志才能写入 MemStore 缓存,并且直到 MemStore缓存内容对应的日志已经被写入磁盘之后,该缓存内容才会被刷新写入磁盘。
ZooKeeper 服务器会实时监测每个 Region 服务器的状态,当某个 Region 服务器发生故障时,ZooKeeper 服务器会通知 Master 主服务器。Master 主服务器首先会处理该故障 Region 服务器上面遗留的 HLog 文件,由于一个 Region 服务器上面可能会维护多个 Region 对象,这些 Region 对象共用一个 HLog 文件,因此这个遗留的 HLog 文件中包含了来自多个 Region 对象的日志记录。系统会根据每条日志记录所属的 Region 对象对 HLog 数据进行拆分,分别放到相应 Region 对象的目录下,然后将失效的 Region 重新分配到可用的 Region 服务器中,并把与该 Region 对象相关的HLog 日志记录也发送给相应的 Region 服务器。Region 服务器领取分配给自己的 Region 对象以及与之相关的 HLog 日志记录以后,会重新做一遍日志记录中的各种操作,把日志记录中的数据写入 MemStore 缓存,然后刷新到磁盘的 StoreFile 文件中,完成数据恢复。
需要特别指出的是,HBase 系统中,每个 Region 服务器只需要维护一个 HLog 文件,所有Region 对象共用一个 HLog,而不是每个 Region 对象使用一个 HLog。在这种 Region 对象共用一个 HLog 的方式中,多个 Region 对象的更新操作所发生的日志修改,只需要不断把日志记录追加到单个日志文件中,而不需要同时打开、写入多个日志文件中,因此可以减少磁盘寻址次数,提高对表的写操作性能。这种方式的缺点是,如果一个 Region 服务器发生故障,为了恢复其上的Region 对象,需要将 Region 服务器上的 HLog 按照其所属的 Region 对象进行拆分,然后分发到其他 Region 服务器上执行恢复操作。
习题
单选题
-
下列关于BigTable的描述,哪个是错误的?(A)
A、爬虫持续不断地抓取新页面,这些页面每隔一段时间地存储到BigTable里
B、BigTable是一个分布式存储系统
C、BigTable起初用于解决典型的互联网搜索问题
D、网络搜索应用查询建立好的索引,从BigTable得到网页
-
下列选项中,关于HBase和BigTable的底层技术对应关系,哪个是错误的?(B)
A、GFS与HDFS相对应
B、GFS与Zookeeper相对应
C、MapReduce与Hadoop MapReduce相对应
D、Chubby与Zookeeper相对应
-
在HBase中,关于数据操作的描述,下列哪一项是错误的?(C)
A、HBase采用了更加简单的数据模型,它把数据存储为未经解释的字符串
B、HBase操作不存在复杂的表与表之间的关系
C、HBase不支持修改操作
D、HBase在设计上就避免了复杂的表和表之间的关系
-
在HBase访问接口中,Pig主要用在哪个场合?(D)
A、适合Hadoop MapReduce作业并行批处理HBase表数据
B、适合HBase管理使用
C、适合其他异构系统在线访问HBase表数据
D、适合做数据统计
-
HBase中需要根据某些因素来确定一个单元格,这些因素可以视为一个“四维坐标”,下面哪个不属于“四维坐标”?(B)
A、行键
B、关键字
C、列族
D、时间戳
-
关于HBase的三层结构中各层次的名称和作用的说法,哪个是错误的?(A)
A、Zookeeper文件记录了用户数据表的Region位置信息
B、-ROOT-表记录了.META.表的Region位置信息
C、.META.表保存了HBase中所有用户数据表的Region位置信息
D、Zookeeper文件记录了-ROOT-表的位置信息
-
下面关于主服务器Master主要负责表和Region的管理工作的描述,哪个是错误的?(D)
A、在Region分裂或合并后,负责重新调整Region的分布
B、对发生故障失效的Region服务器上的Region进行迁移
C、管理用户对表的增加、删除、修改、查询等操作
D、不支持不同Region服务器之间的负载均衡
-
HBase只有一个针对行健的索引,如果要访问HBase表中的行,下面哪种方式是不可行的?(B)
A、通过单个行健访问
B、通过时间戳访问
C、通过一个行健的区间来访问
D、全表扫描
-
下面关于Region的说法,哪个是错误的?(C)
A、同一个Region不会被分拆到多个Region服务器
B、为了加快访问速度,.META.表的全部Region都会被保存在内存中
C、一个-ROOT-表可以有多个Region
D、为了加速寻址,客户端会缓存位置信息,同时,需要解决缓存失效问题
多选题
-
关系数据库已经流行很多年,并且Hadoop已经有了HDFS和MapReduce,为什么需要HBase?(ABCD)
A、Hadoop可以很好地解决大规模数据的离线批量处理问题,但是,受限于Hadoop MapReduce编程框架的高延迟数据处理机制,使得Hadoop无法满足大规模数据实时处理应用的需求上
B、HDFS面向批量访问模式,不是随机访问模式
C、传统的通用关系型数据库无法应对在数据规模剧增时导致的系统扩展性和性能问题
D、传统关系数据库在数据结构变化时一般需要停机维护;空列浪费存储空间
-
HBase与传统的关系数据库的区别主要体现在以下哪几个方面?(ABCD)
A、数据类型
B、数据操作
C、存储模式
D、数据维护
-
HBase访问接口类型包括哪些?(ABCD)
A、Native Java API
B、HBase Shell
C、Thrift Gateway
D、REST Gateway
-
下列关于数据模型的描述,哪些是正确的?(ABCD)
A、HBase采用表来组织数据,表由行和列组成,列划分为若干个列族
B、每个HBase表都由若干行组成,每个行由行键(row key)来标识
C、列族里的数据通过列限定符(或列)来定位
D、每个单元格都保存着同一份数据的多个版本,这些版本采用时间戳进行索引
-
HBase的实现包括哪三个主要的功能组件?(ABC)
A、库函数:链接到每个客户端
B、一个Master主服务器
C、许多个Region服务器
D、廉价的计算机集群
-
HBase的三层结构中,三层指的是哪三层?(ABC)
A、Zookeeper文件
B、-ROOT-表
C、.META.表
D、数据类型
-
以下哪些软件可以对HBase进行性能监视?(ABCD)
A、Master-status(自带)
B、Ganglia
C、OpenTSDB
D、Ambari
-
Zookeeper是一个很好的集群管理工具,被大量用于分布式计算,它主要提供什么服务?(ABC)
A、配置维护
B、域名服务
C、分布式同步
D、负载均衡服务
-
下列关于Region服务器工作原理的描述,哪些是正确的?(ABCD)
A、每个Region服务器都有一个自己的HLog 文件
B、每次刷写都生成一个新的StoreFile,数量太多,影响查找速度
C、合并操作比较耗费资源,只有数量达到一个阈值才启动合并
D、Store是Region服务器的核心
-
下列关于HLog工作原理的描述,哪些是正确的?(ABCD)
A、分布式环境必须要考虑系统出错。HBase采用HLog保证
B、HBase系统为每个Region服务器配置了一个HLog文件
C、Zookeeper会实时监测每个Region服务器的状态
D、Master首先会处理该故障Region服务器上面遗留的HLog文件
简答题
- 试述在Hadoop体系架构中HBase与其他组成部分的相互关系。
HBase利用Hadoop MapReduce来处理HBase中的海量数据,实现高性能计算;利用Zookeeper作为协同服务,实现稳定服务和失败恢复;使用HDFS作为高可靠的底层存储,利用廉价集群提供海量数据存储能力; Sqoop为HBase的底层数据导入功能,Pig和Hive为HBase提供了高层语言支持,HBase是BigTable的开源实现。
- 请阐述HBase和BigTable的底层技术的对应关系。
| 项目 | BigTable | HBase |
|---|---|---|
| 文件存储系统 | GFS | HDFS |
| 海量数据处理 | MapReduce | Hadoop MapReduce |
| 协同服务管理 | Chubby | Zookeeper |
-
请阐述HBase和传统关系数据库的区别。
主要体现在6个方面。
| 主要方面 | 关系数据库 | HBase |
|---|---|---|
| 数据类型 | 关系模型 丰富的数据类型和存储方式 | 简单的数据模型 数据存储为未经解释的字符串 |
| 数据操作 | 丰富 插入 删除 更行 查询等 多表连接 | 不存在复杂的表与表之间的关系 仅插入 查询 删除 清空等 |
| 存储模式 | 基于行模式存储 | 基于列存储 |
| 数据索引 | 针对不同列构建复杂的多个索引,提高数据访问性能 | 索引是行键 |
| 数据维护 | 更行操作用最新的当前值替换记录中原来的旧值 | 更新操作不删除数据旧的版本 |
| 可伸缩性 | 难实现横向扩展,纵向扩展的空间有限 | 水平扩展灵活 轻易的通过在集群中增加或者减少硬件数量来实现性能的伸缩 |
- HBase有哪些类型的访问接口?
HBase提供了Native Java API , HBase Shell , Thrift Gateway , REST GateWay , Pig , Hive 等访问接口。
- 请以实例说明HBase数据模型。
- 分别解释HBase中行键、列键和时间戳的概念。
① 行键标识行。行键可以是任意字符串,行键保存为字节数组。
② 列族。HBase的基本的访问控制单元,需在表创建时就定义好。
③ 时间戳。每个单元格都保存着同一份数据的多个版本,这些版本采用时间戳进行索引。
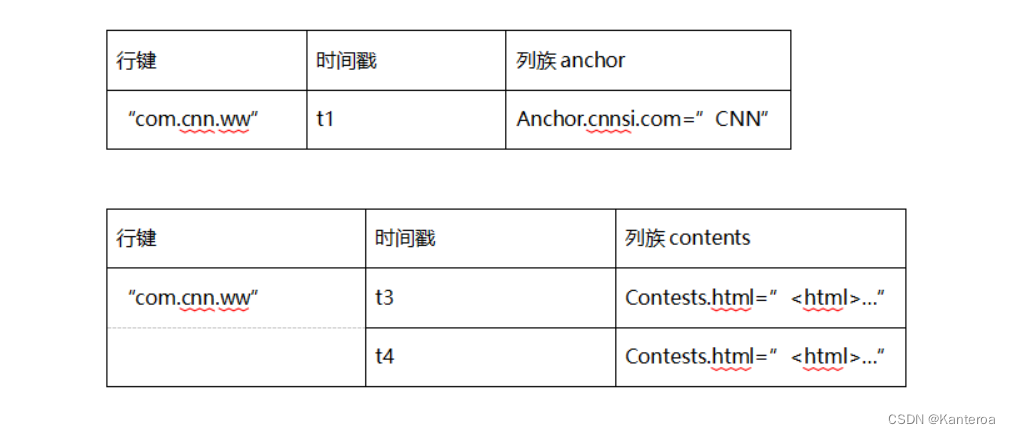
- 请举个实例来阐述HBase的概念视图和物理视图的不同。
数据概念试图
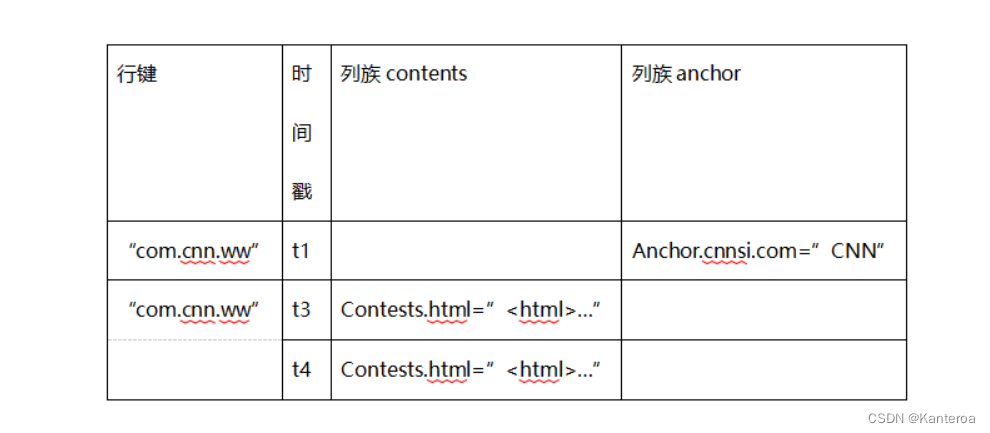
数据物理视图
- 试述HBase各功能组件及其作用。
① 库函数:链接到每个客户端;
② 一个Master主服务器:主服务器Master主要负责表和Region的管理工作;
③ ③许多个Region服务器:Region服务器是HBase中最核心的模块,负责存储和维护分配给自己的Region,并响应用户的读写请求
- 请阐述HBase的数据分区机制。
每个行区间构成一个分区,被称为“Region”,分发到不同的Region服务器上。
- HBase中的分区是如何定位的?
通过构建的映射表的每个条目包含两项内容,一个是Regionde 标识符,另一个是Region服务器标识,这个条目就标识Region和Region服务器之间的对应关系,从而就可以知道某个Region被保存在哪个Region服务器中。
- 试述HBase的三层结构中各层次的名称和作用。
| 层次 | 名称 | 作用 |
|---|---|---|
| 第一层 | Zookeeper文件 | 记录了-ROOT-表的位置信息 |
| 第二层 | -ROOT-表 | 记录了.META.表的Region位置信息,-ROOT-表只能有一个Region。通过-ROOT-表,就可以访问.META.表中的数据 |
| 第三层 | .META.表 | 记录了用户数据表的Region位置信息,.META.表可以有多个Region,保存了HBase中所有请阐述在HBase三层结构下,客户端是如何访问到数据的。 |
- 请阐述HBase的三层结构下,客户端是如何访问到数据的。
首先访问Zookeeper,获取-ROOT表的位置信息,然后访问-Root-表,获得.MATA.表的信息,接着访问.MATA.表,找到所需的Region具体位于哪个Region服务器,最后才会到该Region服务器读取数据。
- 试述HBase系统基本架构以及每个组成部分的作用。
(1)客户端
客户端包含访问HBase的接口,同时在缓存中维护着已经访问过的Region位置信息,用来加快后续数据访问过程
(2)Zookeeper服务器
Zookeeper可以帮助选举出一个Master作为集群的总管,并保证在任何时刻总有唯一一个Master在运行,这就避免了Master的“单点失效”问题
(3)Master
主服务器Master主要负责表和Region的管理工作:管理用户对表的增加、删除、修改、查询等操作;实现不同Region服务器之间的负载均衡;在Region分裂或合并后,负责重新调整Region的分布;对发生故障失效的Region服务器上的Region进行迁移
(4)Region服务器
Region服务器是HBase中最核心的模块,负责维护分配给自己的Region,并响应用户的读写请求
- 请阐述Region服务器向HDFS文件系统中读写数据的基本原理。
Region服务器内部管理一系列Region对象和一个HLog文件,其中,HLog是磁盘上面的记录文件,它记录着所有的更新操作。每个Region对象又是由多个Store组成的,每个Store对象了表中的一个列族的存储。每个Store又包含了MemStore和若干个StoreFile,其中,MemStore是在内存中的缓存。
- 试述HStore的工作原理。
每个Store对应了表中的一个列族的存储。每个Store包括一个MenStore缓存和若干个StoreFile文件。MenStore是排序的内存缓冲区,当用户写入数据时,系统首先把数据放入MenStore缓存,当MemStore缓存满时,就会刷新到磁盘中的一个StoreFile文件中,当单个StoreFile文件大小超过一定阈值时,就会触发文件分裂操作。
- 试述HLog的工作原理。
HBase系统为每个Region服务器配置了一个HLog文件,它是一种预写式日志(Write Ahead Log),用户更新数据必须首先写入日志后,才能写入MemStore缓存,并且,直到MemStore缓存内容对应的日志已经写入磁盘,该缓存内容才能被刷写到磁盘。
- 在HBase中,每个Region服务器维护一个HLog,而不是为每个Region都单独维护一个HLog。请说明这种做法的优点和缺点。
优点: 多个Region对象的更新操作所发生的日志修改,只需要不断把日志记录追加到单个日志文件中,不需要同时打开、写入到多个日志文件中。
缺点:如果一个Region服务器发生故障,为了恢复其上次的Region对象,需要将Region服务器上的对象,需要将Region服务器上的HLog按照其所属的Region对象进行拆分,然后分发到其他Region服务器上执行恢复操作。
- 当一台Region服务器意外终止时,Master如何发现这种意外终止情况?为了恢复这台发生意外的Region服务器上的Region,Master应该做出那些处理(包括如何使用HLog进行恢复)?
Zookeeper会实时监测每个Region服务器的状态,当某个Region服务器发生故障时,Zookeeper会通知Master。
Master首先会处理该故障Region服务器上面遗留的HLog文件,这个遗留的HLog文件中包含了来自多个Region对象的日志记录。
系统会根据每条日志记录所属的Region对象对HLog数据进行拆分,分别放到相应Region对象的目录下,然后,再将失效的Region重新分配到可用的Region服务器中,并把与该Region对象相关的HLog日志记录也发送给相应的Region服务器。
Region服务器领取到分配给自己的Region对象以及与之相关的HLog日志记录以后,会重新做一遍日志记录中的各种操作,把日志记录中的数据写入到MemStore缓存中,然后,刷新到磁盘的StoreFile文件中,完成数据恢复。
第五章NoSQL数据库
5.1 NoSQL简介-NoSQL的三个特点是什么 P98-P99
当应用场合需要简单的数据模型、灵活性的 IT 系统、较高的数据库性能和较低的数据库一致性时,NoSQL 数据库是一个很好的选择。通常 NoSQL 数据库具有以下 3 个特点。
1.灵活的可扩展性
传统的关系数据库由于自身设计的局限性,通常很难实现“横向扩展”。当数据库负载大规模增加时,往往需要通过升级硬件来实现“纵向扩展”。但是,当前的计算机硬件制造工艺已经达到一个限度,性能提升的速度开始趋缓,已经远远赶不上数据库系统负载的增加速度,而且配置高端的高性能服务器价格不菲,因此寄希望于通过“纵向扩展”满足实际业务需求,已经变得越来越不现实。相反,“横向扩展”仅需要非常普通且廉价的标准化刀片服务器,不仅具有较高的性价比,也提供了理论上近乎无限的扩展空间。NoSQL 数据库在设计之初就是为了满足“横向扩展”的需求,因此天生具备良好的横向(水平)扩展能力。
2.灵活的数据模型
关系数据模型是关系数据库的基石,它以完备的关系代数理论为基础,具有规范的定义,遵守各种严格的约束条件。这种做法虽然保证了业务系统对数据一致性的需求,但是过于死板的数据模型,意味着无法满足各种新兴的业务需求。相反,NoSQL 数据库天生就旨在摆脱关系数据库的各种束缚条件,摈弃了流行多年的关系数据模型,转而采用键值、列族等非关系数据模型,允许在一个数据元素里存储不同类型的数据。
3.与云计算紧密融合
云计算具有很好的水平扩展能力,可以根据资源使用情况进行自由伸缩,各种资源可以动态加入或退出。NoSQL 数据库可以凭借自身良好的横向扩展能力,充分利用云计算基础设施,很好地将数据库融入云计算环境中,构建基于 NoSQL 的云数据库服务。
5.2 NoSQL兴起原因
(1)关系型数据库的问题 P99
尽管数据库的事务和查询机制较好地满足了银行、电信等各类商业公司的业务数据管理需求,但是随着 Web 2.0 的兴起和大数据时代的到来,关系数据库已经显得越来越力不从心,暴露出越来越多难以克服的缺陷。于是 NoSQL 数据库应运而生,它很好地满足了 Web 2.0 的需求,得到了市场的青睐。
关系数据库无法满足 Web 2.0 的需求
关系数据库已经无法满足 Web 2.0 的需求,主要表现在以下 3 个方面。
1.无法满足海量数据的管理需求
在 Web 2.0 时代,每个用户都是信息的发布者,用户的购物、社交、搜索等网络行为都会产生大量数据。新浪微博、淘宝、百度等网站,每天生成的数据量十分可观。对于上述网站而言,很快就可以产生超过 10 亿条的记录数据。对于关系数据库来说,在一张有 10 亿条记录数据的表里进行 SQL 查询,效率极其低下,甚至是不可忍受的。
2.无法满足数据高并发的需求
在 Web 1.0 时代,通常采用动态页面静态化技术,事先访问数据库生成静态页面供浏览者访问,从而保证大规模用户访问时,也能够获得较好的实时响应性能。但是,在 Web 2.0 时代,各种用户信息都在不断地发生变化,购物记录、搜索记录、微博粉丝数等信息都需要实时更新,动态页面静态化技术基本没有用武之地,所有信息都需要动态实时生成,这就会导致高并发的
数据库访问,可能产生每秒上万次的读写请求。对于很多关系数据库而言,这都是“难以承受
之重”。
3.无法满足高可扩展性和高可用性的需求
在 Web 2.0 时代,不知名的网站可能一夜爆红,用户迅速增加,已经广为人知的网站也可能因为发布了某些吸引眼球的信息,引来大量用户在短时间内围绕该信息产生大量交流、互动。这些都会导致对数据库读写负荷的急剧增加,需要数据库能够在短时间内迅速提升性能应对突发需求。但遗憾的是,关系数据库通常是难以横向扩展的,没有办法像网页服务器和应用服务器那样简单地通过添加更多的硬件和服务节点来扩展性能和负载能力。
关系数据库的关键特性在 Web 2.0 时代成为“鸡肋”
关系数据库的关键特性包括完善的事务机制和高效的查询机制。关系数据库的事务机制是由1998 年图灵奖获得者、被誉为“数据库事务处理专家”的詹姆斯·格雷提出的。一个事务具有原子性、一致性、隔离性、持续性等“ACID”四性。有了事务机制,数据库中的各种操作可以保证数据的一致性修改。关系数据库还拥有非常高效的查询处理引擎,可以对查询语句进行语法分析和性能优化,保证查询的高效执行。
但是,关系数据库引以为傲的两个关键特性到了 Web 2.0 时代却成了“鸡肋”,主要表现在以下 3 个方面。
1.Web 2.0 网站系统通常不要求严格的数据库事务
对于许多 Web 2.0 网站而言,数据库事务已经不再那么重要。比如对于微博网站而言,如果一个用户发布微博过程出现错误,可以直接丢弃该信息,而不必像关系数据库那样执行复杂的回滚操作,这样并不会给用户造成什么损失。而且,数据库事务通常有一套复杂的实现机制来保证数据库一致性,这需要大量系统开销。对于包含大量频繁实时读写请求的 Web 2.0 网站而言,实现事务的代价是难以承受的。
2.Web 2.0 并不要求严格的读写实时性
对于关系数据库而言,一旦有一条数据记录成功插入数据库中,就可以立即被查询。这对于银行等金融机构而言,是非常重要的。银行用户肯定不希望自己刚刚存入一笔钱,却无法在系统中立即查询到这笔存款记录。但是,对于 Web 2.0 而言,却没有这种实时读写需求,比如用户的微博粉丝数量增加了 10 个,在几分钟后显示更新的粉丝数量,用户可能也不会察觉。
3.Web 2.0 通常不包含大量复杂的 SQL 查询
复杂的 SQL 查询通常包含多表连接操作。在数据库中,多表连接操作代价高昂,因此各类SQL 查询处理引擎都设计了十分巧妙的优化机制—通过调整选择、投影、连接等操作的顺序,达到尽早减少参与连接操作的元组数目的目的,从而降低连接代价,提高连接效率。但是,Web 2.0网站在设计时就已经尽量减少甚至避免这类操作,通常只采用单表的主键查询,因此关系数据库的查询优化机制在 Web 2.0 中难以有所作为。
综上所述,关系数据库凭借自身的独特优势,很好地满足了传统企业的数据管理需求,在数据库这个“江湖”独领风骚 40 余年。但是随着 Web 2.0 时代的到来,各类网站的数据管理需求已经与传统企业大不相同。在这种新的应用背景下,纵使关系数据库使尽浑身解数,也难以满足新时期的要求。于是 NoSQL 数据应运而生,它的出现可以说是 IT 发展的必然。
5.3 NoSQL与关系数据库的比较 P101页的表格
下表给出了 NoSQL 和关系数据库的简单比较,对比指标包括数据库原理、数据规模、数据库模式、查询效率、一致性、数据完整性、扩展性、可用性、标准化、技术支持和可维护性等方面。从表中可以看出,关系数据库的突出优势在于,以完善的关系代数理论作为基础,有严格的标准,支持事务 ACID 四性,借助索引机制可以实现高效的查询,技术成熟,有专业公司的技术支持;其劣势在于,可扩展性较差,无法较好地支持海量数据存储,数据模型过于死板,无法较好地支持 Web 2.0 应用,事务机制影响了系统的整体性能等。NoSQL 数据库的明显优势在于,可以支持超大规模数据存储,其灵活的数据模型可以很好地支持 Web 2.0 应用,具有强大的横向扩展能力等;其劣势在于,缺乏数学理论基础,复杂查询性能不高,一般都不能实现事务强一致性,很难实现数据完整性,技术尚不成熟,缺乏专业团队的技术支持,维护较困难等。
| 对比指标 | NoSQL | 关系数据库 | 备注 |
|---|---|---|---|
| 数据库原理 | 部分支持 | 完全支持 | 关系数据库有关系代数理论作为基础。NoSQL没有统一的理论基础 |
| 数据规模 | 超大 | 大 | 关系数据库很难实现横向扩展,纵向扩展的空间也比较有限,性能会随着数据规模的增大而降低。NoSQL可以很容易通过添加更多设备来支持更大规模的数据 |
| 数据库模式 | 灵活 | 固定 | 关系数据库需要定义数据库模式,严格遵守数据定义和相关约束条件。NoSQL不存在数据库模式,可以自由、灵活地定义并存储各种不同类型的数据 |
| 查询效率 | 可以实现高效的简单查询,但是不具备高度结构化查询等特性,复杂查询的性能不尽如人意 | 快 | 关系数据库借助于索引机制可以实现快速查询(包括记录查询和范围查询)。很多NoSQL数据库没有面向复杂查询的索引,虽然NoSQL可以使用MapReduce来加速查询,但是在复杂查询方面的性能仍然不如关系数据库 |
| 一致性 | 弱一致性 | 强一致性 | 关系数据库严格遵守事务ACID模型,可以保证事务强一致性。很多NoSQL数据库放松了对事务ACID四性的要求,而是遵守BASE模型,只能保证最终一致性 |
| 数据完整性 | 很难实现 | 容易实现 | 任何一个关系数据库都可以很容易实现数据完整性,如通过主键或者非空约束来实现实体完整性,通过主键、外键来实现参照完整性,通过约束或者触发器来实现用户自定义完整性,但是在NoSQL数据库无法实现 |
| 扩展性 | 好 | 一般 | 关系数据库很难实现横向扩展,纵向扩展的空间也比较有限。NoSQL在设计之初就充分考虑了横向扩展的需求,可以很容易通过添加廉价设备实现扩展 |
| 可用性 | 很好 | 好 | 关系数据库在任何时候都以保证数据一致性为优先目标,其次才是优化系统性能。随着数据规模的增大,关系数据库为了保证严格的一致性,只能提供相对较弱的可用性。大多数NoSQL都能提供较高的可用性 |
| 标准化 | 否 | 是 | 关系数据库已经标准化(SQL)。NoSQL还没有行业标准,不同的NoSQL数据库有不同的查询语言,很难规范应用程序接口 |
| 技术支持 | 低 | 高 | 关系数据库经过几十年的发展,已经非常成熟,Oracle等大型厂商都可以提供很好的技术支持。NoSQL在技术支持方面仍然处于起步阶段,还不成熟,缺乏有力的技术支持 |
| 可维护性 | 复杂 | 复杂 | 关系数据库需要专门的数据库管理员(DataBase Administrator, DBA)维护 NoSQL数据库虽然没有关系数据库复杂,但难以维护 |
5.4 NoSQL的四大类型※-四大类型及其相关特点 P102-105
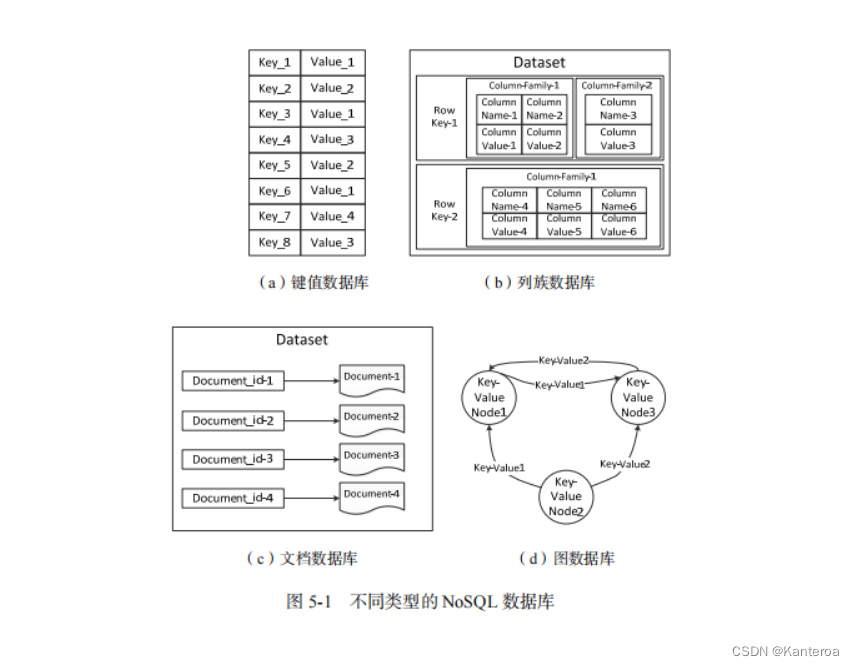
NoSQL 数据库虽然数量众多,但是归结起来,典型的 NoSQL 数据库通常包括键值数据库、列族数据库、文档数据库和图数据库,如图 5-1 所示。
键值数据库
键值数据库(Key-Value Database)会使用一个哈希表,这个表中有一个特定的 Key 和一个指针指向特定的 Value。Key 可以用来定位 Value,即存储和检索具体的 Value。Value 对数据库而言是透明不可见的,不能对 Value 进行索引和查询,只能通过 Key 进行查询。Value 可以用来存储任意类型的数据,包括整型、字符型、数组、对象等。在存在大量写操作的情况下,键值数据库可以比关系数据库取得更好的性能。因为,关系数据库需要建立索引来加速查询,当存在大量写操作时,索引会发生频繁更新,由此会产生高昂的索引维护代价。关系数据库通常很难横向扩展,但是键值数据库天生具有良好的伸缩性,理论上几乎可以实现数据量的无限扩容。键值数据库可以进一步划分为内存键值数据库和持久化(Persistent)键值数据库。内存键值数据库把数据保存在内存中,如 Memcached 和 Redis;持久化键值数据库把数据保存在磁盘,如 BerkeleyDB、Voldmort和 Riak。
当然,键值数据库也有自身的局限性,条件查询就是键值数据库的弱项。因此,如果只对部分值进行查询或更新,效率就会比较低下。在使用键值数据库时,应该尽量避免多表关联查询,可以采用双向冗余存储关系来代替表关联,把操作分解成单表操作。此外,键值数据库在发生故障时不支持回滚操作,因此无法支持事务。键值数据库的相关产品、数据模型、典型应用、优点、缺点和使用者见下表。
| 项目 | 描述 |
|---|---|
| 相关产品 | Redis、Riak、SimpleDB、Chordless、Scalaris、Memcached |
| 数据模型 | 键值对 |
| 典型应用 | 内容缓存,如会话、配置文件、参数、购物车等 |
| 优点 | 扩展性好、灵活性好、大量写操作时性能高 |
| 缺点 | 无法存储结构化信息、条件查询效率较低 |
| 使用者 | 百度云数据库(Redis)、GitHub(Riak)、BestBuy(Riak)、StackOverFlow(Redis)、Instagram (Redis) |
列族数据库
列族数据库一般采用列族数据模型,数据库由多个行构成,每行数据包含多个列族,不同的行可以具有不同数量的列族,属于同一列族的数据会被存放在一起。每行数据通过行键进行定位,与这个行键对应的是一个列族。从这个角度来说,列族数据库也可以被视为一个键值数据库。列族可以被配置成支持不同类型的访问模式,一个列族也可以被设置成放入内存,以消耗内存为代价来换取更好的响应性能。列族数据库的相关产品、数据模型、典型应用、优点、缺点和使用者见下表。
| 项目 | 描述 |
|---|---|
| 相关产品 | BigTable、HBase、Cassandra、HadoopDB、GreenPlum、PNUTS |
| 数据模型 | 列族 |
| 典型应用 | 分布式数据存储与管理 |
| 优点 | 查找速度快、可扩展性强、容易进行分布式扩展、复杂性低 |
| 缺点 | 功能较少,大都不支持强事务一致性 |
| 使用者 | Ebay (Cassandra)、Instagram(Cassandra) |
文档数据库
在文档数据库中,文档是数据库的最小单位。虽然每一种文档数据库的部署有所不同,但是大都假定文档以某种标准化格式封装并对数据进行加密,同时用多种格式进行解码,包括 XML、YAML、JSON 和 BSON 等,或者也可以使用二进制格式进行解码(如 PDF、微软 Office 文档等)。文档数据库通过键来定位一个文档,因此可以看成键值数据库的一个衍生品,而且前者比后者具有更高的查询效率。对于那些可以把输入数据表示成文档的应用而言,文档数据库是非常合适的。一个文档可以包含非常复杂的数据结构,如嵌套对象,并且不需要采用特定的数据模式,每个文档可能具有完全不同的结构。文档数据库既可以根据键(Key)来构建索引,也可以基于文档内容来构建索引。基于文档内容的索引和查询能力,是文档数据库不同于键值数据库的地方。因为在键值数据库中,值(Value)对数据库是透明不可见的,不能根据值来构建索引。文档数据库主要用于存储并检索文档数据,当文档数据需要考虑很多关系和标准化约束,以及需要事务支持时,传统的关系数据库是更好的选择。文档数据库的相关产品、数据模型、典型应用、优点、缺点和使用者见下表。
| 项目 | 描述 |
|---|---|
| 相关产品 | CouchDB、MongoDB、Terrastore、ThnuDB、RavenDB、SisoDB、RaptorDB、CloudKit、Persevere、Jackrabbit |
| 数据模型 | 版本化的文档 |
| 典型应用 | 存储、索引并管理面向文档的数据或者类似的半结构化数据 |
| 优点 | 性能好、灵活性高、复杂性低、数据结构灵活 |
| 缺点 | 缺乏统一的查询语法 |
| 使用者 | 百度云数据库(MongoDB)、SAP(MongoDB)、Codecademy(MongoDB)、Foursquare(MongoDB) |
图数据库
图数据库以图论为基础,一个图是一个数学概念,用来表示一个对象集合,包括顶点以及连接顶点的边。图数据库使用图作为数据模型来存储数据,完全不同于键值、列族和文档数据模型,可以高效地存储不同顶点之间的关系。图数据库专门用于处理具有高度相互关联关系的数据,可以高效地处理实体之间的关系,比较适合于社交网络、模式识别、依赖分析、推荐系统以及路径寻找等问题。有些图数据库(如 Neo4J),完全兼容 ACID。但是,图数据库除了在处理图和关系这些应用领域具有很好的性能以外,在其他领域,其性能不如其他 NoSQL 数据库。图数据库的相关产品、数据模型、典型应用、优点、缺点和使用者见下表 。
| 项目 | 描述 |
|---|---|
| 相关产品 | Neo4J、OrientDB、InfoGrid、Infinite Graph、GraphDB |
| 数据模型 | 图结构 |
| 典型应用 | 应用于大量复杂、互连接、低结构化的图结构场合,如社交网络、推荐系统等 |
| 优点 | 灵活性高、支持复杂的图算法、可用于构建复杂的关系图谱 |
| 缺点 | 复杂性高、只能支持一定的数据规模 |
| 使用者 | Adobe (Neo4J)、Cisco (Neo4J) |
5.5 NoSQL的三大基石※
(1)CAP -怎么理解/每个字母都是什么意思 P105
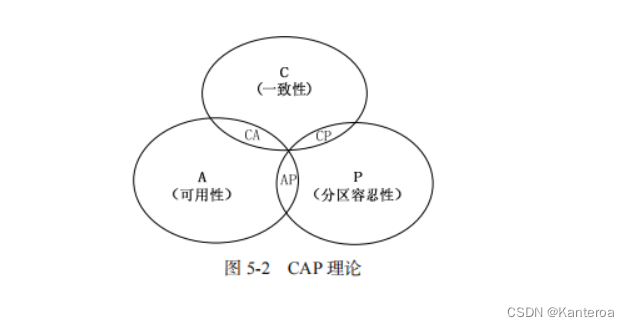
2000 年,美国著名科学家 Eric Brewer 教授指出了著名的 CAP 理论,后来美国麻省理工学院(Massachusetts Institute of Techonlogy,MIT)的两位科学家 Seth Gilbert 和 Nancy lynch 证明了 CAP理论的正确性。CAP 含义如下。
- C(Consistency):一致性。它是指任何一个读操作总是能够读到之前完成的写操作的结果,也就是在分布式环境中,多点的数据是一致的。
- A(Availability):可用性。它是指快速获取数据,且在确定的时间内返回操作结果。
- P(Tolerance of Network Partition):分区容忍性。
它是指当出现网络分区的情况时(即系统中的一部分节点无法和其他节点进行通信),分离的系统也能够正常
运行。
CAP 理论(见图 5-2)告诉我们,一个分布式系统不可能同时满足一致性、可用性和分区容忍性这 3 个特性,最多只能同时满足其中 2 个,正所谓“鱼和熊掌不可兼得”。如果追求一致性,就要牺牲可用性,需要处理因为系统不可用而导致的写操作失败的情况;如果要追求可用性,就要预估到可能发生数据不一致的情况,比如系统的读操作可能不能精确地读取写操作写入的最新值。
(2)ACID -怎么理解/每个字母都是什么意思 P107
说起 BASE(Basically availble、Soft-state、Eventual consistency),不得不谈到 ACID。一个数据库事务具有 ACID 四性。
- A(Atomicity):原子性。它是指事务必须是原子工作单元,对于其数据修改,要么全都执行,要么全都不执行。
- C(Consistency):一致性。它是指事务在完成时,必须使所有的数据都保持一致状态。
- I(Isolation):隔离性。它是指由并发事务所做的修改必须与任何其他并发事务所做的修改隔离。
- D(Durability):持久性。它是指事务完成之后,它对于系统的影响是永久性的,该修改即使出现致命的系统故障也将一直保持。
关系数据库系统中设计了复杂的事务管理机制来保证事务在执行过程中严格满足 ACID 四性要求。关系数据库的事务管理机制较好地满足了银行等领域对数据一致性的要求,因此得到了广泛的商业应用。但是,NoSQL 数据库通常应用于 Web 2.0 网站等场景中,对数据一致性的要求并不是很高,而是强调系统的高可用性,因此为了获得系统的高可用性,可以考虑适当牺牲一致性或分区容忍性。BASE 的基本思想就是在这个基础上发展起来的,它完全不同于 ACID 模型,BASE牺牲了高一致性,从而获得可用性或可靠性,Cassandra 系统就是一个很好的实例。有意思的是,单从名字上就可以看出二者有点“水火不容”,BASE 的英文意义是碱,而 ACID 的英文含义是酸。
(3)BASE -怎么理解/每个字母都是什么意思 P108
BASE 的基本含义是基本可用(Basically Available)、软状态(Soft-state)和最终一致性(Eventual consistency)。
1.基本可用
基本可用是指一个分布式系统的一部分发生问题变得不可用时,其他部分仍然可以正常使用,也就是允许分区失败的情形出现。比如一个分布式数据存储系统由 10 个节点组成,当其中 1 个节点损坏不可用时,其他 9 个节点仍然可以正常提供数据访问,那么,就只有 10%的数据是不可用的,其余 90%的数据都是可用的,这时就可以认为这个分布式数据存储系统“基本可用”。
2.软状态
“软状态”(Soft-state)是与“硬状态(Hard-state)”相对应的一种提法。数据库保存的数据是“硬状态”时,可以保证数据一致性,即保证数据一直是正确的。“软状态”是指状态可以有一段时间不同步,具有一定的滞后性。假设某个银行中的一个用户 A 转移资金给另外一个用户 B,这个操作通过消息队列来实现解耦,即用户 A 向发送队列中放入资金,资金到达接收队列后通知用户 B 取走资金。由于消息传输的延迟,这个过程可能会存在一个短时的不一致性,即用户 A 已经在队列中放入资金,但是资金还没有到达接收队列,用户 B 还没拿到资金,导致出现数据不一致状态,即用户 A 的钱已经减少了,但是用户 B 的钱并没有相应增加。也就是说,在转账的开始和结束状态之间存在一个滞后时间,在这个滞后时间内,两个用户的资金似乎都消失了,出现了短时的不一致状态。虽然这对用户来说有一个滞后,但是这种滞后是用户可以容忍的,甚至用户根本感知不到,因为两边用户实际上都不知道资金何时到达。当经过短暂延迟后,资金到达接收队列时,就可以通知用户 B 取走资金,状态最终一致。
3.最终一致性
一致性的类型包括强一致性和弱一致性,二者的主要区别在于在高并发的数据访问操作下,后续操作是否能够获取最新的数据。对于强一致性而言,当执行完一次更新操作后,后续的其他读操作就可以保证读到更新后的最新数据;反之,如果不能保证后续访问读到的都是更新后的最新数据,那么就是弱一致性。而最终一致性只不过是弱一致性的一种特例,允许后续的访问操作可以暂时读不到更新后的数据,但是经过一段时间之后,用户必须读到更新后的数据。最终一致性也是 ACID 的最终目的,只要最终数据是一致的就可以了,而不是每时每刻都保持实时一致。
(4)最终一致性 P109
讨论一致性的时候,需要从客户端和服务端两个角度来考虑。从服务端来看,一致性是指更新如何复制分布到整个系统,以保证数据最终一致。从客户端来看,一致性主要指的是在高并发的数据访问操作下,后续操作是否能够获取最新的数据。关系数据库通常实现强一致性,也就是一旦一个更新完成,后续的访问操作都可以立即读取更新过的数据。弱一致性则无法保证后续访问都能够读到更新后的数据。
最终一致性的要求更低,只要经过一段时间后能够访问到更新后的数据即可。也就是说,如果一个操作 OP 往分布式存储系统中写入了一个值,遵循最终一致性的系统可以保证,如果后续访问发生之前没有其他写操作去更新这个值,那么,最终所有后续的访问都可以读取操作 OP 写入的最新值。从 OP 操作完成到后续访问可以最终读取 OP 写入的最新值,这之间的时间间隔称为“不一致性窗口”,如果没有发生系统失败,这个窗口的大小依赖于交互延迟、系统负载和副本个数等因素。
最终一致性根据更新数据后各进程访问到数据的时间和方式的不同,又可以进行如下区分。
- 因果一致性。如果进程 A 通知进程 B 它已更新了一个数据项,那么进程 B 的后续访问将获得进程 A 写入的最新值。而与进程 A 无因果关系的进程 C 的访问,仍然遵守一般的最终一致性规则。
- “读己之所写”一致性。这可以视为因果一致性的一个特例。当进程 A 自己执行一个更新操作之后,它自己总是可以访问到更新过的值,绝不会看到旧值。
- 会话一致性。它把访问存储系统的进程放到会话(Session)的上下文中,只要会话还存在,系统就保证“读己之所写”一致性。如果由于某些失败情形令会话终止,就要建立新的会话,而且系统保证不会延续到新的会话。
- 单调读一致性。如果进程已经看到过数据对象的某个值,那么任何后续访问都不会返回在那个值之前的值。
- 单调写一致性。系统保证来自同一个进程的写操作顺序执行。系统必须保证这种程度的一致性,否则编程难以进行。
5.6从NoSQL到NewSQL数据库 P110的图要理解
NoSQL 数据库可以提供良好的扩展性和灵活性,很好地弥补了传统关系数据库的缺陷,较好地满足了 Web 2.0 应用的需求。但是,NoSQL 数据库也存在自己的不足之处。由于 NoSQL 数据库采用非关系数据模型,因此它不具备高度结构化查询等特性,查询效率尤其是复杂查询效率不如关系数据库,而且不支持事务 ACID 四性。
在这个背景下,近几年,NewSQL 数据库逐渐升温。NewSQL 是对各种新的可扩展、高性能数据库的简称,这类数据库不仅具有 NoSQL 对海量数据的存储管理能力,还保持了传统数据库支持 ACID 和 SQL 等特性。不同的 NewSQL 数据库的内部结构差异很大,但是它们有两个显著的共同特点:都支持关系数据模型;都使用 SQL 作为其主要的接口。
目前,具有代表性的 NewSQL 数据库主要包括 Spanner、Clustrix、GenieDB、ScalArc、Schooner、VoltDB、RethinkDB、ScaleDB、Akiban、CodeFutures、ScaleBase、Translattice、NimbusDB、Drizzle、Tokutek、JustOneDB 等。此外,还有一些在云端提供的 NewSQL 数据库(也就是云数据库,在第6 章介绍),包括 Amazon RDS、Microsoft SQL Azure、Xeround 和 FathomDB 等。在众多 NewSQL数据库中,Spanner 备受瞩目。它是一个可扩展、多版本、全球分布式并且支持同步复制的数据库,是 Google 的第一个可以全球扩展并且支持外部一致性的数据库。Spanner 能做到这些,离不开一个用 GPS 和原子钟实现的时间 API。这个 API 能将数据中心之间的时间同步精确到 10 ms 以内。因此,Spanner 有几个良好的特性:无锁读事务、原子模式修改、读历史数据无阻塞。
一些 NewSQL 数据库比传统的关系数据库具有明显的性能优势。比如 VoltDB 系统使用了NewSQL 创新的体系架构,释放了主内存运行的数据库中消耗系统资源的缓冲池,在执行交易时可比传统关系数据库快 45 倍。VoltDB 可扩展服务器数量为 39 个,并可以每秒处理 160 万个交易(300 个 CPU 核心),而具备同样处理能力的 Hadoop 需要更多的服务器。
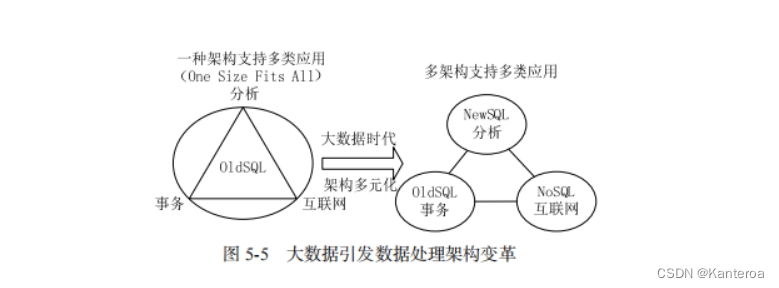
综合来看,大数据时代的到来,引发了数据处理架构的变革,如图 5-5 所示。以前,业界和学术界追求的方向是一种架构支持多类应用(One Size Fits All),包括事务型应用(OLTP 系统)、分析型应用(OLAP、数据仓库)和互联网应用(Web 2.0)。但是,实践证明,这种理想愿景是不可能实现的,不同应用场景的数据管理需求截然不同,一种数据库架构根本无法满足所有场景。因此,到了大数据时代,数据库架构开始向着多元化方向发展,并形成了传统关系数据库(OldSQL)、NoSQL 数据库和 NewSQL 数据库 3 个阵营,三者各有自己的应用场景和发展空间。尤其是传统关系数据库,并没有就此被其他两者完全取代。在基本架构不变的基础上,许多关系数据库产品开始引入内存计算和一体机技术以提升处理性能。在未来一段时间内,3 个阵营共存的局面还将持续,不过有一点是肯定的,那就是传统关系数据库的辉煌时期已经过去了。
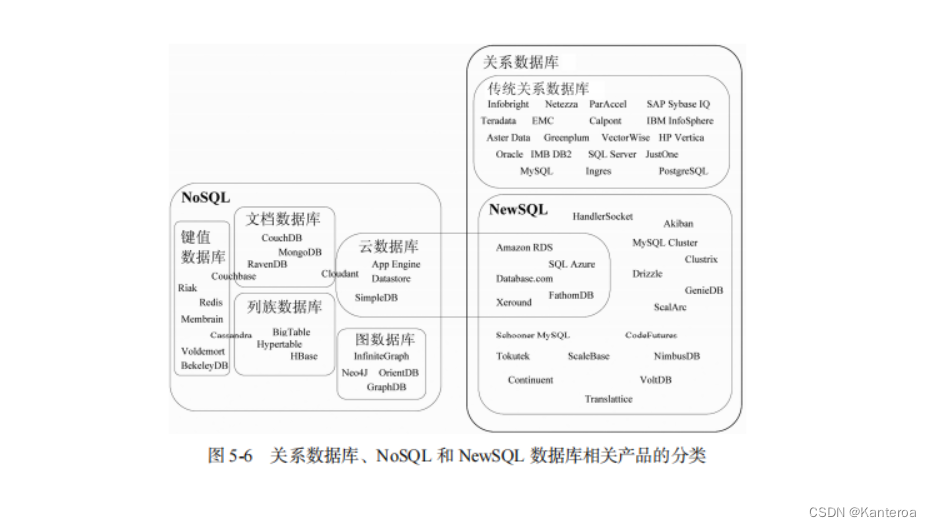
为了更加清晰地认识传统关系数据库、NoSQL 和 NewSQL 数据库的相关产品,图 5-6 给出了3 种数据库相关产品的分类情况。
习题
单选题
-
下列哪个不属于NoSQL数据库的特点?(D)
A、灵活的可扩展性
B、灵活的数据模型
C、与云计算紧密融合
D、数据存储规模有限
-
下面关于NoSQL和关系数据库的简单比较,哪个是错误的?(B)
A、RDBMS有关系代数理论作为基础,NoSQL没有统一的理论基础
B、NoSQL很难实现横向扩展,RDBMS可以很容易通过添加更多设备来支持更大规模的数据
C、RDBMS需要定义数据库模式,严格遵守数据定义,NoSQL一般不存在数据库模式,可以自由灵活定义并存储各种不同类型的数据
D、RDBMS借助于索引机制可以实现快速查询,很多NoSQL数据库没有面向复杂查询的索引
-
下列哪一项不属于NoSQL的四大类型?(D)
A、文档数据库
B、图数据库
C、列族数据库
D、时间戳数据库
-
下列关于键值数据库的描述,哪一项是错误的?(D)
A、扩展性好,灵活性好
B、大量写操作时性能高
C、无法存储结构化信息
D、条件查询效率高
-
下列关于列族数据库的描述,哪一项是错误的?(A)
A、查找速度慢,可扩展性差
B、功能较少,大都不支持强事务一致性
C、容易进行分布式扩展
D、复杂性低
-
下列哪一项不属于数据库事务具有ACID四性?(A)
A、间断性
B、原子性
C、一致性
D、持久性
-
下面关于MongoDB说法,哪一项是正确的?(D)
A、具有较差的水平可扩展性
B、设置个别属性的索引来实现更快的排序
C、提供了一个面向文档存储,操作复杂
D、可以实现替换完成的文档(数据)或者一些指定的数据字段
-
下列关于NoSQL与关系数据库的比较,哪个说法是错误的?(无正确选项)
A、在一致性方面,RDBMS强于NoSQL
B、在数据完整性方面,RDBMS容易实现
C、在扩展性方面,NoSQL比较好
D、在可用性方面,NoSQL优于RDBMS
-
关于文档数据库的说法,下列哪一项是错误的?(A)
A、数据是规则的
B、性能好(高并发)
C、缺乏统一的查询语法
D、复杂性低
多选题
-
下列哪个不属于关系数据库在Web2.0时代面临的挑战?(ABC)
A、无法满足海量数据的管理需求
B、无法满足数据高并发的需求
C、无法满足高可扩展性和高可用性的需求
D、使用难度高
-
下列关于MySQL集群的描述,哪些是正确的?(ABCD)
A、复杂性:部署、管理、配置很复杂
B、数据库复制:MySQL主备之间一般采用复制方式,很多时候是异步复制
C、扩容问题:如果系统压力过大需要增加新的机器,这个过程涉及数据重新划分
D、动态数据迁移问题:如果某个数据库组压力过大,需要将其中部分数据迁移出去
-
关系数据库引以为傲的两个关键特性(完善的事务机制和高效的查询机制),到了Web2.0时代却成了鸡肋,主要表现在以下哪几个方面?(ACD)
A、Web2.0 网站系统通常不要求严格的数据库事务
B、Web2.0 网站系统基本上不用关系数据库来存储数据
C、Web2.0 并不要求严格的读写实时性
D、Web2.0 通常不包含大量复杂的SQL 查询
-
下面关于NoSQL与关系数据库的比较,哪些是正确的?(ABCD)
A、关系数据库以完善的关系代数理论作为基础,有严格的标准
B、关系数据库可扩展性较差,无法较好支持海量数据存储
C、NoSQL可以支持超大规模数据存储
D、NoSQL 数据库缺乏数学理论基础,复杂查询性能不高
-
下列关于文档数据库的描述,哪些是正确的?(AD)
A、性能好(高并发),灵活性高
B、具备统一的查询语法
C、文档数据库支持文档间的事务
D、复杂性低,数据结构灵活
-
下列关于图数据库的描述,哪些是正确的?(ABCD)
A、专门用于处理具有高度相互关联关系的数据
B、比较适合于社交网络、模式识别、依赖分析、推荐系统以及路径寻找等问题
C、灵活性高,支持复杂的图算法
D、复杂性高,只能支持一定的数据规模
-
NoSQL的三大基石?(ABC)
A、CAP
B、最终一致性
C、BASE
D、DN8
-
关于NoSQL的三大基石之一的CAP,下列哪些说法是正确的?(ACD)
A、一致性,是指任何一个读操作总是能够读到之前完成的写操作的结果量
B、一个分布式系统可以同时满足一致性、可用性和分区容忍性这三个需求
C、可用性,是指快速获取数据
D、分区容忍性,是指当出现网络分区的情况时(即系统中的一部分节点无法和其他节点进行通信),分离的系统也能够正常运行
-
当处理CAP的问题时,可以有哪几个明显的选择?(ABC)
A、CA:也就是强调一致性(C)和可用性(A),放弃分区容忍性(P)
B、CP:也就是强调一致性(C)和分区容忍性(P),放弃可用性(A)
C、AP:也就是强调可用性(A)和分区容忍性(P),放弃一致性(C)
D、CAP:也就是同时兼顾可用性(A)、分区容忍性(P)和一致性(C),当时系统性能会下降很多
-
数据库事务具有ACID四性,下面哪几项属于四性?(ABD)
A、原子性
B、持久性
C、间断性
D、一致性
简答题
- 如何准确理解NoSQL的含义?
NoSQL是一种不同于关系数据库的数据库管理系统设计方式,是对非关系型数据库的一类统称,它采用的数据模型并非传统关系数据库的关系模型,而是类似键/值、列族、文档等非关系模型。
- 试述关系数据库在哪些方面无法满足Web 2.0应用的需求。
主要表现在以下几个方面:
(1)无法满足海量数据的管理需求
(2)无法满足数据高并发的需求
(3)无法满足高可扩展性和高可用性的需求
- 为什么说关系数据库的一些关键特性在Web 2.0时代成为“鸡肋”?
(1)Web2.0网站系统通常不要求严格的数据库事务
(2)Web2.0不要求严格的读写实时性
(3) Web2.0通常不包含大量复杂的SQL查询
- 请比较NoSQL数据库和关系数据库的优缺点。
①关系数据库。
优点:以完善得关系理论代数作为基础,有严格得标准,支持事务ACID四性,高校查询,技术成熟,专业公司得技术支持;
缺点:可扩展性较差、无法较好支持海量数据存储、数据模型过于死板、无法较好支持Web2.0应用、事务机制影响系统整体性能。
②NoSQL数据库。
优点:支持超大规模数据存储数据模型灵活支持Web2.0,具有强大得横向扩展能力
缺点:缺乏数学理论基础,复杂查询性能不高。不能实现事务强一致性,很难实现数据完整性,技术尚不成熟,缺乏专业的技术支持,维护较困难。
- 试述NoSQL数据库的四大类型。
答:键值数据库、列族数据库、文档数据库和图数据库
- 试述键值数据库、列族数据库、文档数据库和图形数据库的适用场合和优缺点。
| 数据库 | 适用场合 | 优点 | 缺点 |
|---|---|---|---|
| 键值数据库 | 通过键而是通过值来查的业务 | 扩展性好,灵活性好,大量写操作时性能高 | 无法存储结构化信息,条件查询效率较低 |
| 列族数据库 | 不需要ACID事务支持的情形 | 查找速度快,可扩展性强,容易进行分布式扩展,复杂性低 | 功能较少,大都不支持强事务一致性 |
| 文档数据库 | 只在相同的文档上添加事务 | 性能好(高并发),灵活性高,复杂性低,数据结构灵活;提供嵌入式文档功能,将经常查询的数据存储在同一个文档中;既可以根据键来构建索引,也可以根据内容构建索引 | 缺乏统一的查询语法 |
| 图形数据库 | 具有高度相互关联关系的数据 | 灵活性高,支持复杂的图形算法,可用于构建复杂的关系图谱 | 复杂性高,只能支持一定的数据规模 |
- 试述CAP理论的具体含义。
C(Consistency):一致性,是指任何一个读操作总是能够读到之前完成的写操作的结果,也就是在分布式环境中,多点的数据是一致的,或者说,所有节点在同一时间具有相同的数据
A:(Availability):可用性,是指快速获取数据,可以在确定的时间内返回操作结果,保证每个请求不管成功或者失败都有响应;
P(Tolerance of Network Partition):分区容忍性,是指当出现网络分区的情况时(即系统中的一部分节点无法和其他节点进行通信),分离的系统也能够正常运行,也就是说,系统中任意信息的丢失或失败不会影响系统的继续运作。
- 请举例说明不同产品在设计时是如何运用CAP理论的。
① CA。强调一致性©和可用性(A),放弃分区容忍性§,最简单的做法是把所有与事务相关的内容都放到同一台机器 上。这种做法会严重影响系统的可扩展性。例如传统的关系数据库( MySQL、SQL Server和PostgreSQL ) 。
② CP。强调一致性©和分区容忍性§,放弃可用性(A),当出现网络分区的情况时,受影响的服务需要等待数据一致,因此在等待期间就无法对外提供服务。例如Neo4J、BigTable和HBase等NoSQL数据库。
③ AP。强调可用性(A)和分区容忍性§,放弃-致性©,允许系统返回不一致的数据。这对于许多Web 2.0 网站而言是可行的,这些网站的用户首先关注的是网站服务是否可用,当用户需要发布一条微博时,必须能够立即发布,否则,用户就会放弃使用,但是,这条微博发布后什么时候能够被其他用户读取到,则不是非常重要的问题,不会影响到用户体验。因此,对于Web 2.0 网站而言,可用性与分区容忍性优先级要高于数据-致性,网站一般会尽量朝着AP的方向设计。当然,在采用AP设计时,也可以不完全放弃一致性,转而采用最终一致性。例如Dynamo、Riak 、CouchDB、Cassandra 等NoSQL数据库。
- 试述数据库的ACID四性的含义。
①原子性(Atomicity)
指事务必须是原子工作单元,对于其数据修改,要么全都执行,要么全都不执行。
②一致性(consistency)
指事务在完成时,必须使所有的数据都保持一致状态。
③隔离性(Isolation)
指并发事务所做的修改必须与其他并发事务所做的修改隔离。
④持久性(Durability)
指事务完成之后,它对于系统的影响是永久性的,该修改即使出现致命的系统故障也将一直保持。
- 试述BASE的具体含义。
BASE的基本含义是基本可用(Basically Availble)、软状态(Soft-state)和最终一致性(Eventual consistency)
- 请解释软状态、无状态、硬状态的具体含义。
答:“软状态(soft-state)”是与“硬状态(hard-state)”相对应的一种提法。数据库保存的数据是“硬状态”时,可以保证数据一致性,即保证数据一直是正确的。“软状态”是指状态可以有一段时间不同步,具有一定的滞后性。
- 什么是最终一致性?
最终一致性根据更新数据后各进程访问到数据的时间和方式的不同,又可以区分为:
①会话一致性:它把访问存储系统的进程放到会话(session)的上下文中,只要会话还存在,系统就保证“读己之所写”一致性。如果由于某些失败情形令会话终止,就要建立新的会话,而且系统保证不会延续到新的会话;
②单调写一致性:系统保证来自同一个进程的写操作顺序执行。系统必须保证这种程度的一致性,否则就非常难以编程了
③单调读一致性:如果进程已经看到过数据对象的某个值,那么任何后续访问都不会返回在那个值之前的值
④因果一致性:如果进程A通知进程B它已更新了一个数据项,那么进程B的后续访问将获得A写入的最新值。而与进程A无因果关系的进程C的访问,仍然遵守一般的最终一致性规则
⑤“读己之所写”一致性:可以视为因果一致性的一个特例。当进程A自己执行一个更新操作之后,它自己总是可以访问到更新过的值,绝不会看到旧值。
- 试述不一致性窗口的含义。
所有后续的访问都可以读取到操作OP写入的最新值。从OP操作完成到后续访问可以最终读取到OP写入的最新值,这之间的时间间隔称为“不一致性窗口”。
- 最终一致性根据更新数据后各进程访问到数据的时间和方式的不同,又可以分为哪些不同类型的一致性?
会话一致性、单调写一致性、单调写一致性、因果一致性和“读己之所写”一致性。
- 什么是NewSQL数据库?
NewSQL是对各种新的可扩展、高性能数据库的简称,这类数据库不仅具有NoSQL对海量数据的存储管理能力,还保持了传统数据库支持ACID和SQL特性。
- 试述NewSQL数据库与传统的关系数据库以及NoSQL数据库的区别。
NewSQL数据库不经具有NoSQL对海量数据的存储管理能力,还保持了传统数据库支持ACID和SQL特性。
第六章云数据库
6.1云数据库概述
(1)云数据库发展基础和概念 P115-P116
云计算是云数据库兴起的基础
**云计算是分布式计算、并行计算、效用计算、网络存储、虚拟化、负载均衡等计算机和网络技术发展融合的产物。**云计算是由一系列可以动态升级和被虚拟化的资源组成的,用户无须掌握云计算的技术,只要通过网络就可以访问这些资源。
云计算主要包括 3 种类型,即 IaaS(Infrastructure as a Service)、**PaaS(Platform as a Service)**和 SaaS(Software as a Service)。以 SaaS 为例,它极大地改变了用户使用软件的方式,用户不再需要购买软件安装到本地计算机上,只要通过网络就可以使用各种软件。SaaS 厂商将应用软件统一部署在自己的服务器上,用户可以在线购买、在线使用、按需付费。成立于 1999 年的 Salesforce公司,是 SaaS 厂商的先驱,提供 SaaS 云服务,并提出了“终结软件”的口号。在该公司的带动下,其他 SaaS 厂商如雨后春笋般大量涌现。
云数据库的概念
云数据库是部署在云计算环境中的虚拟化数据库。云数据库是在云计算的大背景下发展起来的一种新兴的共享基础架构的方法,它极大地增强了数据库的存储能力,避免了人员、硬件、软件的重复配置,让软、硬件升级变得更加容易,同时虚拟化了许多后端功能。云数据库具有高可扩展性、高可用性、采用多租形式和支持资源有效分发等特点。
在云数据库中,所有数据库功能都是在云端提供的,客户端可以通过网络远程使用云数据库提供的服务(见图 6-1)。客户端不需要了解云数据库的底层细节,所有的底层硬件都已经被虚拟化,对客户端而言是透明的,客户端就像在使用一个运行在单一服务器上的数据库一样,非常方便、容易,同时可以获得理论上近乎无限的存储和处理能力。
需要指出的是,有人认为数据库属于应用基础设施(即中间件),因此把云数据库列入 PaaS的范畴,也有人认为数据库本身也是一种应用软件,因此把云数据库划入 SaaS。对于这个问题,本书把云数据库划入 SaaS,但同时认为,云数据库到底应该被划入 PaaS 还是 SaaS,这并不是最重要的。实际上,云计算 IaaS、PaaS 和 SaaS 这 3 个层次之间的界限有些时候也不是非常清晰。对于云数据库而言,最重要的就是它允许用户以服务的方式通过网络获得云端的数据库功能。
(2)云数据库的特征 P117
云数据库具有以下特性。
1.动态可扩展
理论上,云数据库具有无限可扩展性,可以满足不断增加的数据存储需求。在面对不断变化的条件时,云数据库可以表现出很好的弹性。例如,对于一个从事产品零售的电子商务公司,会存在季节性或突发性的产品需求变化,或者对于类似 Animoto 的网络社区站点,可能会经历一个指数级的用户增长阶段。这时,它们就可以分配额外的数据库存储资源来处理增加的需求,这个过程只需要几分钟。一旦需求过去以后,它们就可以立即释放这些资源。
2.高可用性
云数据库不存在单点失效问题。如果一个节点失效了,剩余的节点就会接管未完成的事务。而且,在云数据库中,数据通常是冗余存储的,在地理上也是分散的。诸如 Google、Amazon 和IBM 等大型云计算供应商,具有分布在世界范围内的数据中心,通过在不同地理区间内进行数据复制,可以提供高水平的容错能力。例如,Amazon SimpleDB 会在不同的区域内进行数据复制,这样,即使某个区域内的云设施失效,也可以保证数据继续可用。
3.较低的使用代价
云数据库厂商通常采用多租户(Multi-tenancy)的形式,同时为多个用户提供服务,这种共享资源的形式对于用户而言可以节省开销,而且用户采用“按需付费”的方式使用云计算环境中的各种软、硬件资源,不会产生不必要的资源浪费。另外,云数据库底层存储通常采用大量廉价的商业服务器,这大大降低了用户开销。腾讯云数据库官方公布的资料显示,当实现类似的数据库性能时,如果采用自己投资自建 MySQL 的方式,则成本为每台服务器每天 50.6 元,实现双机容灾需要 2 台服务器,即成本为每天 101.2 元,平均存储成本是每吉字节每天 0.25 元,平均 1 元可获得的每秒查询率(Query Per Second,QPS)为每秒 24 次;而如果采用腾讯云数据库产品,企业不需要投入任何初期建设成本,每天成本仅为 72 元,平均存储成本为每吉字节每天 0.18 元,平均 1 元可获得的 QPS 为每秒 83 次,相对于自建,云数据库平均 1 元获得的 QPS 提高为原来的346%,具有极高的性价比。
4.易用性
使用云数据库的用户不必控制运行原始数据库的机器,也不必了解它身在何处。用户只需要一个有效的连接字符串(URL)就可以开始使用云数据库,而且就像使用本地数据库一样。许多基于 MySQL 的云数据库产品(如腾讯云数据库、阿里云 RDS 等),完全兼容 MySQL 协议,用户可通过基于 MySQL 协议的客户端或者 API 访问实例。用户可无缝地将原有 MySQL 应用迁移到云存储平台,无须进行任何代码改造。
5.高性能
云数据库采用大型分布式存储服务集群,支撑海量数据访问,多机房自动冗余备份,自动读写分离。
6.免维护
用户不需要关注后端机器及数据库的稳定性、网络问题、机房灾难、单库压力等各种风险,云数据库服务商提供“7×24h”的专业服务,扩容和迁移对用户透明且不影响服务,并且可以提供全方位、全天候立体式监控,用户无须半夜去处理数据库故障。
7.安全
云数据库提供数据隔离,不同应用的数据会存在于不同的数据库中而不会相互影响;提供安全性检查,可以及时发现并拒绝恶意攻击性访问;提供数据多点备份,确保不会发生数据丢失。以腾讯云数据库为例,开发者可快速在腾讯云中申请云服务器实例资源,通过 IP/PORT 直接访问 MySQL 实例,完全无须再安装 MySQL 实例,可以一键迁移原有 SQL 应用到腾讯云平台,这大大节省了人力成本;同时,该云数据库完全兼容 MySQL 协议,可通过基于 MySQL 协议的客户端或 API 便捷地访问实例。此外,腾讯云数据库还采用了大型分布式存储服务集群,支撑海量数据访问,7×24h 的专业存储服务,可以提供高达 99.99%服务可用性的 MySQL 集群服务,并且数据可靠性超过 99.999%。自建数据库和腾讯云数据库的比较见下表。
| 项目 | 自建数据库 | 腾讯云数据库 |
|---|---|---|
| 数据安全性 | 开发者自行解决,成本较高昂 | 15种类型备份数据,保证数据安全 |
| 服务可用性 | 开发者自行解决,成本较高昂 | 99.99%高可靠性 |
| 数据备份 | 开发者自行解决,成本较高昂 | 零花费,系统自动多时间点数据备份 |
| 维护成本 | 开发者自行解决,成本较高昂 | 零成本,专业团队 7 × 24 h 7\times 24h 7×24h帮助维护 |
| 实例扩容 | 开发者自行解决,成本较高昂 | 一键式直接扩容,安全可靠 |
| 资源利用率 | 开发者自行解决,成本较高昂 | 按需申请,资源利用率高达99.9% |
| 技术支持 | 开发者自行解决,成本较高昂 | 专业团队一对一指导、QQ远程协助开发者 |
6.2云数据库产品
云数据库厂商主要分为三类。
-
传统的数据库厂商,如 Teradata、Oracle、IBM DB2 和 Microsoft SQL Server 等。
-
涉足数据库市场的云数据库厂商,如 Amazon、Google、Yahoo!、阿里、百度、腾讯等。
-
新兴厂商,如 Vertica、LongJump 和 EnterpriseDB 等。
市场上常见的云数据库产品见下表。
| 企业 | 产品 |
|---|---|
| Amazon | DynamoDB、SimpleDB、RDS |
| Google Cloud SQL | |
| Microsoft | Microsoft SQL Azure |
| Oracle | Oracle Cloud |
| Yahoo! | PNUTS |
| Vertica | Analytic Database for the Cloud |
| EnerpriseDB | Postgres Plus in the Cloud |
| 阿里 | 阿里云 RDS |
| 百度 | 百度云数据库 |
| 腾讯 | 腾讯云数据库 |
6.3云数据库系统架构※
(1)UMP系统架构-11个组件及其基本作用 P123
UMP 系统架构如图 6-3 所示,UMP 系统中的角色包括 Controller 服务器、Web 控制台、Proxy服务器、Agent 服务器、日志分析服务器、信息统计服务器、愚公系统;依赖的开源组件包括 Mnesia、RabbitMQ、ZooKeeper 和 LVS。
1.Mnesia
Mnesia 是一个分布式数据库管理系统,适合电信及其他需要持续运行和具备软实时特性的Erlang 应用,是构建电信应用的控制系统平台—开放式电信平台(Open Telecom Platform,OTP)的一部分。Erlang 是一种结构化、动态类型的编程语言,内建并行计算支持,非常适合构建分布式、软实时并行计算系统。使用 Erlang 编写出的应用,在运行时通常由成千上万个轻量级进程组成,并通过消息传递相互通信,Erlang 的进程间上下文切换要比 C 程序高效得多。Mnesia 与 Erlang 编程语言是紧耦合的,其最大的好处是在操作数据时,不会发生由于数据库与编程语言所用的数据格式不同带来阻抗失配问题。Mnesia 支持事务,支持透明的数据分片,利用两阶段锁实现分布式事务,可以线性扩展到至少 50 个节点。Mnesia 的数据库模式(schema)可在运行时动态重配置,表能被迁移或复制到多个节点来改进容错性。Mnesia 的这些特性,使其在开发云数据库时被用来提供分布式数据库服务。
2.RabbitMQ
RabbitMQ 是一个用 Erlang 开发的工业级的消息队列产品(功能类似于 IBM 公司的消息队列产品 IBM WebSphere MQ),作为消息传输中间件来使用,可以实现可靠的消息传送。UMP 集群中各个节点之间的通信,不需要建立专门的连接,都是通过读写队列消息来实现的。
3.ZooKeeper
ZooKeeper 是高效和可靠的协同工作系统,提供分布式锁之类的基本服务(如统一命名服务、状态同步服务、集群管理、分布式应用配置项的管理等),用于构建分布式应用,减轻分布式应用程序所承担的协调任务(关于 ZooKeeper 的工作原理可以参考相关书籍或网络资料)。在 UMP 系统中,ZooKeeper 主要发挥 3 个作用。
-
作为全局的配置服务器。UMP 系统需要运行多台服务器,它们运行的应用系统的某些配置项是相同的,如果要修改这些相同的配置项,就必须同时到多个服务器上去修改,这样做不仅麻烦,而且容易出错。因此,UMP 系统把这类配置信息完全交给 ZooKeeper 来管理,把配置信息保存在 ZooKeeper 的某个目录节点中,然后在所有需要修改的服务器中对这个目录节点设置监听,也就是监控配置信息的状态,一旦配置信息发生变化,每台服务器就会收到 ZooKeeper 的通知,然后从 ZooKeeper 获取新的配置信息。
-
提供分布式锁。UMP 集群中部署了多个 Controller 服务器,为了保证系统的正确运行,对于某些操作,在某一时刻,只能由一个服务器执行,而不能由多台服务器同时执行。例如一个MySQL 实例发生故障后,需要进行主备切换,由另一个正常的服务器来代替当前发生故障的服务器,如果这个时候所有的 Controller 服务器都去跟踪处理并且发起主备切换流程,那么,整个系统就会进入混乱状态。因此,在同一时间,必须从集群的多个 Controller 服务器中选举出一个“总管”,由这个“总管”负责发起各种系统任务。ZooKeeper 的分布式锁功能能够帮助选出一个“总管”,让这个“总管”来管理集群。
-
监控所有 MySQL 实例。集群中运行 MySQL 实例的服务器发生故障时,必须及时被监听到,然后使用其他正常服务器来替代故障服务器。UMP 系统借助于 ZooKeeper 实现对所有MySQL 实例的监控。每个 MySQL 实例在启动时都会在 ZooKeeper 上创建一个临时类型的目录节点,当某个 MySQL 实例挂掉时,这个临时类型的目录节点也随之被删除,后台监听进程可以捕获到这种变化,从而知道这个 MySQL 实例不再可用。
4.LVS
Linux 虚拟服务器(Linux Virtual Server,LVS),是一个虚拟的服务器集群系统。LVS 采用 IP负载均衡技术和基于内容的请求分发技术。调度器是 LVS 集群系统的唯一入口点。调度器具有很好的吞吐率,将请求均衡地转移到不同的服务器上执行,且调度器自动屏蔽服务器的故障,从而将一组服务器构成一个高性能的、高可用的虚拟服务器。整个服务器集群的结构对客户是透明的,而且无须修改客户端和服务器端的程序。UMP 系统借助于 LVS 来实现集群内部的负载均衡。
5.Controller 服务器
**Controller 服务器向 UMP 集群提供各种管理服务,实现集群成员管理、元数据存储、MySQL实例管理、故障恢复、备份、迁移、扩容等功能。**Controller 服务器上运行了一组 Mnesia 分布式数据库服务,其中存储了各种系统元数据,主要包括集群成员、用户的配置和状态信息,以及用户名与后端 MySQL 实例地址的映射关系(或称为“路由表”)等。当其他服务器组件需要获取用户数据时,可以向 Controller 服务器发送获取数据请求。为了避免单点故障,保证系统的高可用性,UMP 系统中部署了多台 Controller 服务器,然后由 ZooKeeper 的分布式锁功能来帮助选出一个“总管”,负责各种系统任务的调度和监控。
6.Web 控制台
Web 控制台向用户提供系统管理页面。
7.Proxy 服务器
**Proxy 服务器向用户提供访问 MySQL 数据库的服务。**它完全实现了 MySQL 协议,用户可以使用已有的 MySQL 客户端连接到 Proxy 服务器,Proxy 服务器通过用户名获取用户的认证信息、资源配额的限制,如 QPS、IOPS、最大连接数等,以及后台 MySQL 实例的地址,然后用户的 SQL查询请求会被转发到相应的 MySQL 实例上。除了数据路由的基本功能外,Proxy 服务器中还实现了很多重要的功能,主要包括屏蔽 MySQL 实例故障、读写分离、分库分表、资源隔离、记录用户访问日志等。
8.Agent 服务器
Agent 服务器部署在运行 MySQL 进程的机器上,用来管理每台物理机上的 MySQL 实例,执行主从切换、创建、删除、备份、迁移等操作,同时还负责收集和分析 MySQL 进程的统计信息、慢查询日志(Slow Query Log)和 bin-log。
9.日志分析服务器
日志分析服务器存储和分析 Proxy 服务器传入的用户访问日志,并支持实时查询一段时间内的慢日志和统计报表。10.信息统计服务器 信息统计服务器定期对采集到的用户的连接数、QPS 数值以及 MySQL 实例的进程状态用RRDtool 进行统计,可以在 Web 页面上可视化展示统计结果,也可以把统计结果作为今后实现弹性的资源分配和自动化的 MySQL 实例迁移的依据。
11.愚公系统
愚公系统是一个进行增量复制的工具,它结合了全量复制和 bin-log 分析,可以实现在不停机的情况下动态扩容、缩容和迁移。
(2)UMP系统功能-需要能够理解7个功能的具体内容 P126-128
UMP 系统构建在一个大的集群之上,通过多个组件的协同作业,整个系统实现了对用户透明的容灾、读写分离、分库分表、资源管理、资源调度、资源隔离和数据安全等功能。
1.容灾
云数据库必须向用户提供一直可用的数据库连接,当 MySQL 实例发生故障时,系统必须自动执行故障恢复,所有故障处理过程对于用户而言是透明的,用户不会感知到后台发生的一切。
为了实现容灾,UMP 系统会为每个用户创建两个 MySQL 实例,一个是主库,一个是从库,而且这两个 MySQL 实例之间互相把对方设置为备份机,任意一个 MySQL 实例上面发生的更新都会复制到对方。同时,Proxy 服务器可以保证只向主库写入数据。
主库和从库的状态是由 ZooKeeper 负责维护的,ZooKeeper 可以实时监听各个 MySQL 实例的状态,一旦主库死机,ZooKeeper 可以立即感知到,并通知 Controller 服务器。Controller 服务器会启动主从切换操作,在路由表中修改用户名与后端 MySQL 实例地址的映射关系,并把主库标记为不可用,同时,借助于消息队列中间件 RabbitMQ 通知所有 Proxy 服务器修改用户名与后端 MySQL 实例地址的映射关系。通过这一系列操作后,主从切换完成,用户名就会被赋予一个新的可以正常使用的 MySQL 实例,而这一切对于用户自己而言是完全透明的。
死机后的主库在进行恢复处理后需要再次上线。在主库死机和故障恢复期间,从库可能已经发生过多次更新。因此,在主库恢复时,会把从库中的这些更新都复制给自己,当主库的数据库状态快要达到和从库一致的状态时,Controller 服务器就会命令从库停止更新,进入不可写状态,禁止用户写入数据,这个时候用户可能感受到短时间的“不可写”。等到主库更新到和从库完全一致的状态时,Controller 服务器就会发起主从切换操作,并在路由表中把主库标记为可用状态,然后通知 Proxy 服务器把写操作切回主库上,用户写操作可以继续执行,再把从库修改为可写状态。
2.读写分离
由于每个用户都有两个 MySQL 实例,即主库和从库,因此 UMP 系统可以充分利用主从库实现用户读写操作的分离,实现负载均衡。UMP 系统实现了对于用户透明的读写分离功能,当整个功能被开启时,负责向用户提供访问 MySQL 数据库服务的 Proxy 服务器,就会对用户发起的 SQL语句进行解析。如果该 SQL 语句属于写操作,就直接发送到主库;如果该 SQL 语句属于读操作,就会被均衡地发送到主库和从库上执行。但是,有一种情况可能发生,那就是,用户刚刚写入数据到主库,数据还没有被复制到从库之前,用户就去从库读这个数据,导致用户要么读不到数据,要么读到数据的旧版本。为了避免这种情况的发生,UMP 系统在每次用户写操作发生后都会开启一个计时器,如果用户在计时器开启的 300 ms 内读数据,不管是读刚写入的这些数据还是其他数据,都会被强行分发到主库上去执行读操作。当然,在实际应用中,UMP 系统允许修改 300 ms这个设定值,但是一般而言,300 ms 已经可以保证数据在写入主库后被复制到从库中。
3.分库分表
UMP 支持对用户透明的分库分表(Shard / Horizontal Partition),但是用户在创建账号的时候需要指定类型为多实例,并且设置实例的个数,系统会根据用户设置来创建多组 MySQL 实例。除此以外,用户还需要自己设定分库分表规则,如需要确定分区字段,也就是确定根据哪个字段进行分库分表,还要确定分区字段里的值如何映射到不同的 MySQL 实例上。
当采用分库分表时,系统处理用户查询的过程如下:首先,Proxy 服务器解析用户 SQL 语句,提取重写和分发 SQL 语句所需要的信息;其次,对 SQL 语句进行重写,得到多个针对相应 MySQL实例的子语句,然后把子语句分发到对应的 MySQL 实例上执行;最后,接收来自各个 MySQL实例的 SQL 语句执行结果,合并得到最终结果。
4.资源管理
UMP 系统采用资源池机制来管理数据库服务器上的 CPU、内存、磁盘等计算资源,所有的计算资源都放在资源池内进行统一分配,资源池是为 MySQL 实例分配资源的基本单位。整个集群中的所有服务器会根据其机型、所在机房等因素被划分为多个资源池,每台服务器会被加入相应的资源池。对于每个具体的 MySQL 实例,管理员会根据应用部署在哪些机房、需要哪些计算资源等因素,为该 MySQL 实例具体指定主库和从库所在的资源池,然后系统的实例管理服务会本着“负载均衡”的原则,从资源池中选择负载较轻的服务器来创建 MySQL 实例。在资源池划分的基础上,UMP 系统还在每台服务器内部采用 Cgroup 将资源进一步地细化,从而限制每个进程组使用资源的上限,同时保证进程组之间相互隔离。
5.资源调度
UMP 系统中有 3 种规模的用户,分别是数据量和流量比较小的用户、中等规模用户,以及需要分库分表的用户。多个小规模用户可以共享同一个 MySQL 实例。对于中等规模的用户,每个用户独占一个 MySQL 实例,用户可以根据自己的需求来调整内存空间和磁盘空间,如果用户需要更多的资源,就可以迁移到资源有空闲或者具有更高配置的服务器上。对于分库分表的用户,会占有多个独立的 MySQL 实例,这些实例既可以共存在同一台物理机上,也可以每个实例独占一台物理机。UMP 系统通过 MySQL 实例的迁移来实现资源调度。借助于阿里巴巴中间件团队开发的愚公系统,UMP 系统可以实现在不停机的情况下动态扩容、缩容和迁移。
6.资源隔离
当多个用户共享同一个 MySQL 实例或者多个 MySQL 实例共存在同一台物理机上时,为了保护用户应用和数据的安全,必须实现资源隔离,否则,某个用户过多消耗系统资源会严重影响到其他用户的操作性能。UMP 系统采用下表所示的两种资源隔离方式。
| 资源隔离方式 | 应用场合 | 实现方式 |
|---|---|---|
| 用Cgroup限制MySQL进程资源 | 适用于多个 MySQL 实例共享同一台物理机的情况 | 可以对用户的 MySQL 进程最大可以使用的 CPU使用率、内存和IOPS等进行限制 |
| 在Proxy服务器端限制QPS | 适用于多个用户共享同一个MySQL实例的情况 | Controller服务器监测用户的MySQL实例的资源消耗情况,如果明显超出配额,就通知Proxy 服务器通过增加延迟的方法去限制用户的 QPS,以减少用户对系统资源的消耗 |
7.数据安全
数据安全是让用户放心使用云数据库产品的关键,尤其是企业用户,数据库中存放了很多业务数据,有些属于商业机密,一旦泄露,就会给企业造成损失。UMP 系统设计了多种机制来保证数据安全。
-
SSL 数据库连接。安全套接字协议(Secure Sockets Layer,SSL)是为网络通信提供安全及数据完整性的一种安全协议,它在传输层对网络连接进行加密。Proxy 服务器实现了完整的MySQL 客户端/服务器协议,可以与客户端之间建立 SSL 数据库连接。
-
数据访问 IP 白名单。UMP 系统可以把允许访问云数据库的 IP 地址放入“白名单”,只有白名单内的 IP 地址才能访问云数据库,其他 IP 地址的访问都会被拒绝,进一步保证账户安全。
-
记录用户操作日志。用户的所有操作都会被记录到日志分析服务器,通过检查用户操作记录,可以发现隐藏的安全漏洞。
-
SQL 拦截。Proxy 服务器可以根据要求拦截多种类型的 SQL 语句,比如全表扫描语句“select *”。
习题
单选题
-
下列哪个不属于云计算的优势?(D)
A、按需服务
B、随时服务
C、通用性
D、价格不菲
-
下列关于云数据库的描述,哪个是错误的?(C)
A、云数据库是部署和虚拟化在云计算环境中的数据库
B、云数据库是在云计算的大背景下发展起来的一种新兴的共享基础架构的方法
C、云数据库价格不菲,维护费用极其昂贵
D、云数据库具有高可扩展性、高可用性、采用多租形式和支持资源有效分发等特点
-
下列哪一个不属于云数据库产品?(A)
A、本地安装MySQL
B、阿里云RDS
C、Oracle Cloud
D、百度云数据库
-
UMP系统是构建在一个大的集群之上的,下列哪一项不属于系统向用户提供的功能?(D)
A、读写分离
B、分库分表
C、数据安全
D、资源合并
-
下列关于UMP系统功能的说法,哪个是错误的?(D)
A、充分利用主从库实现用户读写操作的分离,实现负载均衡
B、UMP系统实现了对于用户透明的读写分离功能
C、UMP采用的两种资源隔离方式(用Cgroup限制MySQL进程资源和在Proxy服务器端限制QPS)
D、UMP系统只设计了一种机制来保证数据安全
-
下列关于阿里云RDS的说法,哪个是错误的?(D)
A、RDS是阿里云提供的关系型数据库服务
B、RDS由专业数据库管理团队维护
C、RDS具有安全稳定、数据可靠、自动备份
D、RDS实例,是用户购买RDS服务的基本单位,在实例中,用户只能创建一个数据库
-
下面哪一项不是云数据库的特性?(B)
A、动态可扩展
B、高成本
C、易用性
D、大规模并行处理
-
下列哪个不是UMP系统中的角色?(D)
A、Controller服务器
B、Proxy服务器
C、愚公系统
D、阿斯隆服务器
-
关于UMP系统架构依赖的开源组件Mnesia,说法错误的是哪一项?(B)
A、Mnesia是一个分布式数据库管理系统
B、Mnesia的数据库模式(schema)只能在未运行前静态重配置
C、Mnesia的这些特性,使其在开发云数据库时被用来提供分布式数据库服务
D、Mnesia支持事务,支持透明的数据分片
-
关于UMP系统架构的Controller服务器,说法错误的是哪一项?(C)
A、Controller服务器向UMP集群提供各种管理服务
B、Controller服务器上运行了一组Mnesia分布式数据库服务
C、当其它服务器组件需要获取用户数据时,不可以向Controller服务器发送请求获取数据
D、为了避免单点故障,保证系统的高可用性,UMP系统中部署了多台Controller服务器
多选题
-
云数据库具有以下哪些特性?(ABCD)
A、动态可扩展
B、高可用性
C、免维护
D、安全
-
下列关于云数据库的描述,哪些是正确的?(ABCD)
A、Amazon是云数据库市场的先行者
B、Google Cloud SQL是谷歌公司推出的基于MySQL的云数据库
C、从数据模型的角度来说,云数据库并非一种全新的数据库技术
D、云数据库并没有专属于自己的数据模型
-
UMP系统架构设计遵循了以下哪些原则?(ABCD)
A、保持单一的系统对外入口,并且为系统内部维护单一的资源池
B、消除单点故障,保证服务的高可用性
C、保证系统具有良好的可伸缩,能够动态地增加、删减计算与存储节点
D、保证分配给用户的资源也是弹性可伸缩的
-
UMP系统架构依赖的哪些开源组件?(ABCD)
A、Mnesia
B、LVS
C、RabbitMQ
D、ZooKeeper
-
下列关于UMP系统架构的描述,哪些是正确的?(ACD)
A、信息统计服务器定期将采集到的用户的连接数
B、Web控制台无法向用户提供系统管理界面
C、LVS(Linux Virtual Server)即Linux虚拟服务器
D、UMP系统借助于LVS来实现集群内部的负载均衡
-
为什么说云数据库是个性化数据存储需求的理想选择?(ABCD)
A、云数据库可以满足大企业的海量数据存储需求
B、云数据库可以满足中小企业的低成本数据存储需求
C、云数据库可以满足企业动态变化的数据存储需求
D、前期零投入、后期免维护的数据库服务,可以很好满足它们的需求
-
下列关于云数据库与其他数据库的关系,哪些是正确的?(ABD)
A、从数据模型的角度来说,云数据库并非一种全新的数据库技术
B、云数据库并没有专属于自己的数据模型,云数据库所采用的数据模型可以是关系数据库所使用的关系模型
C、同一个公司只能提供采用不同数据模型的单个云数据库服务
D、许多公司在开发云数据库时,后端数据库都是直接使用现有的各种关系数据库或NoSQL数据库产品
-
以下哪些是Amazon的云数据库产品?(ABD)
A、Amazon RDS:云中的关系数据库
B、Amazon SimpleDB:云中的键值数据库
C、Amazon DynamoDB:云中的数据仓库
D、Amazon ElastiCache:云中的分布式内存缓存
-
Microsoft的云数据库产品SQL Azure具有以下哪些特性?(ABCD)
A、属于关系型数据库:支持使用TSQL来管理、创建和操作云数据库
B、支持存储过程:它的数据类型、存储过程和传统的SQL Server具有很大的相似性
C、支持大量数据类型
D、支持云中的事务:支持局部事务,但是不支持分布式事务
简答题
- 试述云数据库的概念。
云数据库是部署和虚拟化在云计算环境中的数据库。云数据库是在云计算的大背景下发展起来的一种新兴的共享基础架构的方法,它极大地增强了数据库的存储能力,消除了人员、硬件、软件的重复配置,让软、硬件升级变得更加容易,同时,也虚拟化了许多后端功能。云数据库具有高可扩展性、高可用性、采用多租形式和支持资源有效分发等特点。
- 与传统的软件使用方式相比,云计算这种模式具有哪些明显的优势?
① 可直接购买云计算厂商的软件服务;
② 软件运行在云计算厂商服务器上,用户再有网络的地方就可以使用软件服务。
③ 零成本投入,按需付费,极其廉价;
④ 维护零成本,由云计算厂商负责;
⑤ 获得IT资源的速度:随时可用,购买服务后立即可用;
⑥ 资源可拓展。等
- 云数据库有哪些特性?
① 动态可扩展
② 高可用性
③ 较低的使用代价
④ 易用性
⑤ 高性能
⑥ 免维护
⑦ 安全
- 试述云数据库的影响。
① 云数据库可以满足大企业的海量数据存储需求。
② 云数据库可以满足中小企业的低成本数据存储需求。
③ 云数据库可以满足企业动态变化的数据存储需求。
- 举例说明云数据库厂商及其代表性产品。
云数据库供应商主要分为三类。
① 传统的数据库厂商,如Teradata、Oracle、IBM DB2和Microsoft SQL Server等。
② 涉足数据库市场的云供应商,如Amazon、Google.Yahoo!、阿里、百度、腾讯等。
③ 新兴厂商,如IVertica.LongJump 和EnterpriseDB等。
- 试述Microsoft SQL Azure 的体系架构。
如下图所示,SQL Azure 的体系架构中包含了一个虚拟机簇,可以根据工作负载的变化,动态增加或减少虚拟机的数量。每台虚拟机SQL Server VM ( Virtual Machine )安装了SQL Server2008数据库管理系统,以关系模型存储数据。通常,-一个数据库会被分散存储到3~5台SQL ServerVM中。每台SQL Server VM同时安装了SQL Azure Fabric和SQL Azure管理服务,后者负责数库的数据复写工作,以保障SQL Azure 的基本高可用性要求。不同SQL Server VM内的SQLAzure Fabric和管理服务之间会彼此交换监控信息,以保证整体服务的可监控性。
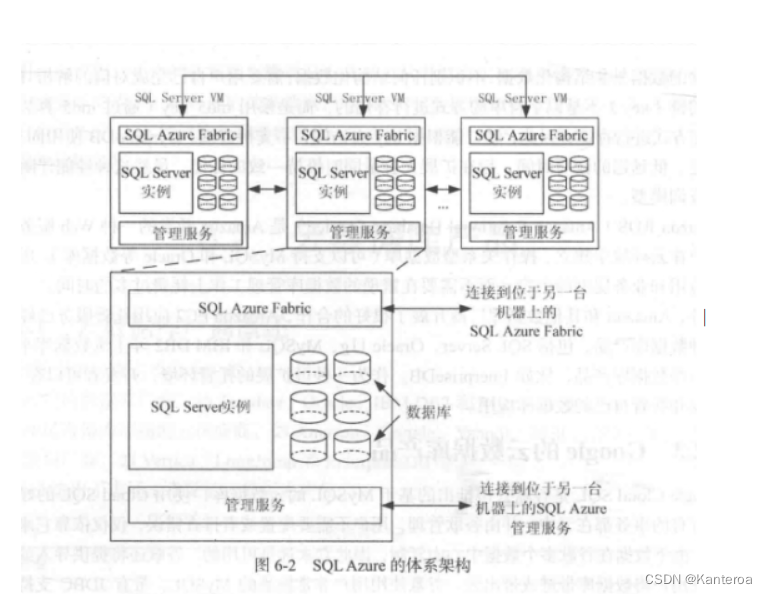
- 试述UMP系统的功能。
UMP系统是构建在一个大的集群之上的,通过多个组件的协同作业,整个系统实现了对用户透明的 容灾、读写分离、分库分表、资源管理、资源调度、资源隔离和数据安全功能。
1.容灾
云数据库必须向用户提供一直可用的数据库连接,当MySQL实例发生故障时,系统必须自动执行故障恢复,所有故障处理过程对于用户而言是透明的,用户不会感知到后台发生的一切。 为了实现容灾,UMP系统会为每个用户创建两个MySQL实例,一个是主库,一个是从库,而且,这两个MySQL 实例之间互相把对方设置为备份机,任意一个MySQL实例上面发生的更新都会复制到对方。同时,Proxy服务器可以保证只向主库写人数据。
2.读写分离
由于每个用户都有两个MySQL实例,即主库和从库,因此,可以充分利用主从库实现用户读写操作的分离,实现负载均衡。UMP系统实现了对于用户透明的读写分离功能,当整个功能被开启时,负责向用户提供访问MySQL数据库服务的Proxy 服务器,就会对用户发起的SQL 语句进行解析,如果属于写操作,就直接发送到主库,如果是读操作,就会被均衡地发送到主库和从库上执行。
3.分库分表
UMP支持对用户透明的分库分表(Shard/Horizontal Partition)。但是,用户在创建账号的时候需要指定类型为多实例,并且设置实例的个数,系统会根据用户设置来创建多组MySQL实例。除此以外,用户还需要自己设定分库分表规则,如需要确定分区字段,也就是根据哪个字段进行分库分表,还要确定分区字段里的值如何映射到不同的MySQL 实例上。
4.资源管理
UMP系统采用资源池机制来管理数据库服务器上的CPU、内存、磁盘等计算资源,所有的计算资源都放在资源池内进行统一分配,资源池是为MySQL 实例分配资源的基本单位。整个集群中的所有服务器会根据其机型、所在机房等因素被划分为多个资源池,每台服务器会被加人到相应的资源池。在资源池划分的基础上,UMP还在每台服务器内部采用Cgroup将资源进一步地细化,从而可以限制每个进程组使用资源的上限,同时保证进程组之间相互隔离。
5.资源调度
UMP系统中有3种规格的用户,分别是数据量和流量比较小的用户、中等规模用户以及需要分库分表的用户。多个小规模用户可以共享同一个MySQL实例。对于中等规模的用户,每个用户独占个MySQL 实例。用户可以根据自己的需求来调整内存空间和磁盘空间,如果用户需要更多的资源,就可以迁移到资源有空闲或者具有更高配置的服务器上对于分库分表的用户,会占有多个独立的MySQL 实例,这些实例既可以共存在同一台物理机上,也可以每个实例独占一台物理机。 UMP通过MySQL实例的迁移来实现资源调度。借助于阿里集团中间件团队开发的愚公系统,UMP 可以实现在不停机的情况下动态扩容、缩容和迁移。
6.资源隔离
当多个用户共享同一个MySQL 实例或者多个MySQL 实例共存在同一个物理机上时,为了保护用户应用和数据的安全,必须实现资源隔离,否则,某个用户过多消耗系统资源会严重影响到其他用户的操作性能。
7.数据安全
数据安全是让用户放心使用云数据库产品的关键,尤其是企业用户,数据库中存放了很多业务数据,有些属于商业机密,一旦泄露,会给企业造成损失。UMP 系统设计了多种机制来保证数据安全。
① SSL 数据库连接。
② 数据访问IP 白名单。
③ 记录用户操作日志。
④ SQL拦截。
- 试述UMP系统的组件及其具体作用。
① Controller服务器:向UMP集群提供各种管理服务,实现集群成员管理、元数据存储、MySQL实例管理、故障恢复、备份、迁移、扩容等功能。
② Web控制台:向用户提供系统管理界面。
③ Proxy服务器:向用户提供访问MySQL数据库的服务;除了数据路由的基本功能外,Proxy服务器中还实现了屏蔽MySQL实例故障、读写分离、分库分表、资源隔离、记录用户访问日志等。
④ Agent服务器:管理每台物理机上的MySQL实例,执行主从切换、创建、删除、备份、迁移等操作,同时还负责收集和分析MySQL进程的统计信息、慢查询日志和bin-log。
⑤ 日志分析服务器:存储和分析Proxy服务器传入的用户访问日志,并支持实时查询一段时间内的慢日志和统计报表。
⑥ 信息统计服务器:定期将采集到的用户的连接数、QPS数值以及MySQL实例的进程状态用RRDtool进行统计。
⑦ 愚公系统:是一个全量复制结合bin-log分析进行增量复制的工具,可以实现在不停机的情况下动态扩容、缩容和迁移。
- 试述UMP系统实现主从备份的方法。
UMP系统会为用户创建两个MySQL实例,一个是主库,一个是从库,且这两个MySQL实例之间相互把对方设置为备份机,任何一个MySQL实例上面发生的更新都会复制到对方。一旦主机宕机,Controller服务器会启动主从切换,修改映射关系;宕机后的主库在恢复处理后会再次上线,并从从库中复制更新,直到更新到完全一致状态的时候,Controller服务器会再次发起主从切换操作。
- 试述UMP系统读写分离的实现方法。
UMP系统实现了对于用户透明的读写分离功能,当整个功能被开启时,负责向用户提供访问MySQL数据库服务的Proxy 服务器,就会对用户发起的SQL 语句进行解析,如果属于写操作,就直接发送到主库,如果是读操作,就会被均衡地发送到主库和从库上执行。
- UMP系统采用哪两种方式实现资源隔离?
① 用Group限制MySQL进程资源;
② 在Proxy服务器端限制QPS。
- 试述UMP系统中的3种规格用户。
系统内部划分为3种规格的用户,分别是数据量和流量比较小的用户、中等规模用户以及需要分库分表的用户。多个小规模用户可以共享同一个MySQL实例,中等规模用户独占一个MySQL实例,需要分库分表的用户的多个MySQL实例共享同一个物理机,通过这些方式实现了资源的虚拟化,降低了整体成本。UMP通过“用Cgroup限制MySQL进程。
- UMP系统是如何保障数据安全的?
① SSL数据库连接。SSL ( Secure Sockets Layer )是为网络通信提供安全及数据完整性的一种安全协议,它在传输层对网络连接进行加密。Proxy服务器实现了完整的MySQL客户端/服务器协议,可以与客户端之间建立SSL数据库连接。
② 数据访问IP白名单。可以把允许访问云数据库的IP地址放入“白名单”,只有白名单内的IP地址才能访问,其他IP地址的访问都会被拒绝,从而进一步保证账户安全。
③ 记录用户操作日志。用户的所有操作记录都会被记录到日志分析服务器,通过检查用户操作记录,可以发现隐藏的安全漏洞。
④ SQL拦截。Proxy服务器可以根据要求拦截多种类型的SQL语句,比如全表扫描语句“select *"。
- 简述阿里云RDS的主要优势。
RDS是阿里云提供的关系型数据库服务,它将直接运行于物理服务器上的数据库实例租给用户,是专业管理、高可靠的云端数据库服务。用户可以通过Web或API的方式,在几分钟内开通完全兼容MySQL或SQL Server的数据库实例。RDS由专业数据库管理团队维护,还可以为用户提供数据备份、数据恢复、扩展升级等管理功能,相对于用户自建数据库而言,RDS具有专业、高可靠、高性能、灵活易用等优点,能够帮助用户解决费时费力的数据库管理任务,让用户将更多的时间聚焦在核心业务上。RDS适用于各行业数据库应用,如SaaS应用、电子商务网站、商家后台应用、社区网站、手机APP以及游戏类应用等。RDS具有安全稳定、数据可靠、自动备份、管理透明、性能卓越,灵活扩容等优点,可以提供专业的数据库管理平台、专业的数据库优化建议以及完善的监控体系。
- 简述RDS中实例与数据库的概念。
① RDS实例
RDS实例或简称“实例”,是用户购买RDS服务的基本单位。在实例中可以创建多个数据库,可以使用常见的数据库客户端连接、管理及使用数据库。可以通过RDS管理控制台或OPEN API来创建、修改和删除数据库。各实例之间相互独立、资源隔离,相互之间不存在CPU、内存、IOPS等抢占问题;但是,同-实例中的不同数据库之间是资源共享的。每个实例拥有其自己的特性,如数据库类型、版本等,系统有相应的参数来控制实例行为。用户所购买RDS实例的性能,取决于购买RDS实例时所选择的配置,可供用户选择的硬件配置项为内存和磁盘容量。
② RDS 数据库
RDS数据库或简称“数据库",是用户在一个实例下创建的逻辑单元,一.个实例可以创建多个数据库,在实例内数据库命名唯-一, 所有数据库都会共享该实例下的资源,如CPU、内存、磁盘容量等。RDS不支持使用标准的SQL语句或客户端工具创建数据库,必须使用OPEN API或RDS管理控制台进行操作。
- 列举连接RDS for MySQL数据库的4种方法。
①方法1:使用客户端MySQL-Front访问。使用客户端MySQL-Front,在连接Host框中输人数据实例链接地址、端口( 默认3306)、 数据库用户名和数据库密码后,单击“确定”按钮即可。
②方法2:使用数据库管理工具Navicat MySQL。Navicat MySQL是一套专为MySQL设计的强大的数据库管理及开发工具,可以在连接输入框中输人数据实例地址、端口(默认3306 )、数据库用户名和数据库密码后,单击“确定"按钮即可。
③方法3:使用MySQL命令登录。用户安装MySQL客户端后,可进人命令行方式连接数据库。命令格式如下。
mysql -u user_ name -h yuqianli .mysq1. rds.aliyuncs.com -P3306 -pxxxx其中,-u指定的是用户名,-h指定的是主机名,-P 指定的是端口,-p指定的是密码。
④方法4:使用阿里云控制台iDB Cloud访问。RDS连接地址以及端口不需要再输入,只需在“用户名”中输人数据库的账号,在“密码”栏中输人数据库账号的密码,便可以登录RDS进行数据操作了。
第七章MapReduce
7.1 MapReduce概述
(1)分布式并行编程 -摩尔定律、与传统程序开发区别 Hadoop MapRedcue和谷歌 MapReduce区别 P131
在过去的很长一段时间里,CPU 的性能都遵循“摩尔定律”,大约每隔 18 个月性能翻一番。这意味着不需要对程序做任何改变,仅通过使用更高级的 CPU,程序就可以“享受”性能提升。但是,大规模集成电路的制作工艺已经达到一个极限,从 2005 年开始摩尔定律逐渐失效。人们想要提高程序的运行性能,就不能再把希望过多地寄托在性能更高的 CPU 身上。于是,人们开始借助于分布式并行编程来提高程序的性能。分布式程序运行在大规模计算机集群上,集群中包括大量廉价服务器,可以并行执行大规模数据处理任务,从而获得海量的计算能力。
分布式并行编程与传统的程序开发方式有很大的区别。传统的程序都以单指令、单数据流的方式顺序执行,虽然这种方式比较符合人类的思维习惯,但是这种程序的性能受到单台机器性能的限制,可扩展性较差。分布式并行程序可以运行在由大量计算机构成的集群上,从而可以充分利用集群的并行处理能力,同时通过向集群中增加新的计算节点,可以很容易地实现集群计算能力的扩充。
谷歌最先提出分布式并行编程模型 MapReduce,Hadoop MapReduce 是它的开源实现。谷歌的 MapReduce 运行在分布式文件系统 GFS 上。与谷歌类似,Hadoop MapReduce 运行在分布式文件系统 HDFS 上。相对而言,Hadoop MapReduce 要比 Google 的 MapReduce 的使用门槛低很多,程序员即使没有任何分布式程序开发经验,也可以很轻松地开发出分布式程序并部署到计算机集群中。
7.2 MapReduce工作流程※
(1)工作流程执行的各个阶段 P134
下面是一个 MapReduce 算法的执行过程。
- MapReduce 框架使用 InputFormat 模块做 Map 前的预处理,比如验证输入的格式是否符合输入定义;然后,将输入文件切分为逻辑上的多个 InputSplit。InputSplit 是 MapReduce 对文件进行处理和运算的输入单位,只是一个逻辑概念,每个 InputSplit 并没有对文件进行实际切分,只是记录了要处理的数据的位置和长度。
- 因为 InputSplit 是逻辑切分而非物理切分,所以还需要通过 RecordReader(RR)根据InputSplit 中的信息来处理 InputSplit 中的具体记录,加载数据并将其转换为适合 Map 任务读取的键值对,输入给 Map 任务。
- Map 任务会根据用户自定义的映射规则,输出一系列的<key,value>作为中间结果。
- 为了让 Reduce 可以并行处理 Map 的结果,需要对 Map 的输出进行一定的分区(Partition)、排序(Sort)、合并(Combine)、归并(Merge)等操作,得到<key,value-list>形式的中间结果,再交给对应的 Reduce 来处理,这个过程称为 Shuffle。从无序的<key,value>到有序的<key,value-list>,这个过程用 Shuffle 来称呼是非常形象的。
- Reduce 以一系列<key,value-list>中间结果作为输入,执行用户定义的逻辑,输出结果交给 OutputFormat 模块。
- OutputFormat 模块会验证输出目录是否已经存在,以及输出结果类型是否符合配置文件中的配置类型,如果都满足,就输出 Reduce 的结果到分布式文件系统。
MapReduce 工作流程中的各个执行阶段,具体如图 7-2 所示。
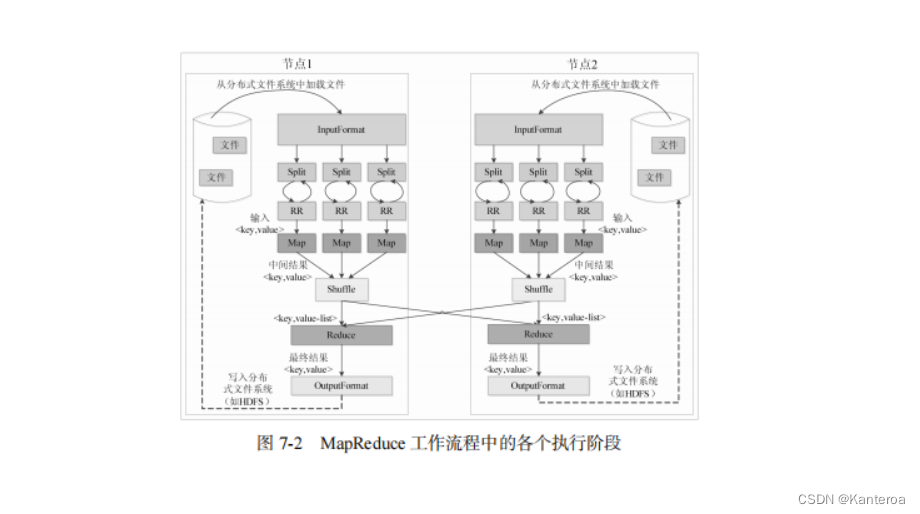
(2)shuffle的过程
Shuffle 过程是 MapReduce 整个工作流程的核心环节,理解 Shuffle 过程的基本原理,对于理解 MapReduce 流程至关重要。
Shuffle 过程简介
Shuffle 是指对 Map 任务输出结果进行分区、排序、合并、归并等处理并交给 Reduce 的过程。
因此,Shuffle 过程分为 Map 端的操作和 Reduce 端的操作,如图 7-3 所示,主要执行以下操作。
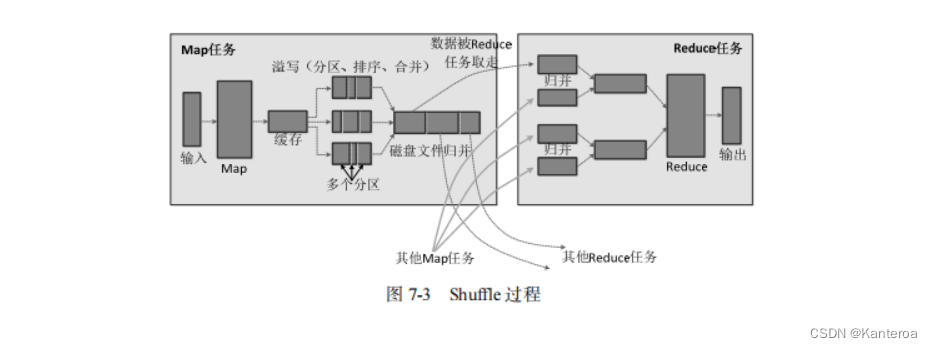
- 在 Map 端的 Shuffle 过程。
Map 任务的输出结果首先被写入缓存,当缓存满时,就启动溢写操作,把缓存中的数据写入磁盘文件,并清空缓存。当启动溢写操作时,首先需要对缓存中的数据进行分区,然后对每个分区的数据进行排序和合并,再写入磁盘文件。每次溢写操作会生成一个新的磁盘文件,随着 Map任务的执行,磁盘中就会生成多个溢写文件。在 Map 任务全部结束之前,这些溢写文件会被归并成一个大的磁盘文件,然后通知相应的 Reduce 任务来“领取”属于自己处理的数据。
- 在 Reduce 端的 Shuffle 过程。
Reduce 任务从 Map 端的不同 Map 机器“领取”属于自己处理的那部分数据,然后对数据进行归并后交给 Reduce 处理。
(3)split的概念和划分
HDFS 以固定大小的block 为基本单位存储数据,而对于MapReduce 而言,其处理单位是split。split 是一个逻辑概念,它只包含一些元数据信息,比如数据起始位置、数据长度、数据所在节点等。它的划分方法完全由用户自己决定。
7.5 MapReduce编程实践※WordCount -代码包含哪几个主要部分 P144
(1)编写 Map 处理逻辑
为了把文档处理成我们希望的效果,首先需要对文档进行切分。通过前面的内容我们可以知道,数据处理的第一个阶段是 Map 阶段,在这个阶段中文本数据被读入并进行基本的分析,然后以特定的键值对的形式进行输出,这个输出将作为中间结果,继续提供给 Reduce 阶段作为输入数据。
(2)编写 Reduce 处理逻辑
在 Map 部分得到中间结果后,接下来进入 Shuffle 阶段。在这个阶段中 Hadoop 自动将 Map的输出结果进行分区、排序、合并,然后分发给对应的 Reduce 任务来处理。
(3)编写 main 方法。
(4)编译打包代码以及运行程序。
习题
单选题
-
下列传统并行计算框架,说法错误的是哪一项?(B)
A、刀片服务器、高速网、SAN,价格贵,扩展性差
B、共享式(共享内存/共享存储),容错性好
C、编程难度高
D、实时、细粒度计算、计算密集型
-
下列关于MapReduce模型的描述,错误的是哪一项?(D)
A、MapReduce采用“分而治之”策略
B、MapReduce设计的一个理念就是“计算向数据靠拢”
C、MapReduce框架采用了Master/Slave架构
D、MapReduce应用程序只能用Java来写
-
MapReduce1.0的体系结构中,JobTracker是主要任务是什么?(A)
A、负责资源监控和作业调度,监控所有TaskTracker与Job的健康状况
B、使用“slot”等量划分本节点上的资源量(CPU、内存等)
C、会周期性地通过“心跳”将本节点上资源的使用情况和任务的运行进度汇报给TaskTracker
D、会跟踪任务的执行进度、资源使用量等信息,并将这些信息告诉任务(Task)
-
下列关于MapReduce工作流程,哪个描述是正确的?(A)
A、所有的数据交换都是通过MapReduce框架自身去实现的
B、不同的Map任务之间会进行通信
C、不同的Reduce任务之间可以发生信息交换
D、用户可以显式地从一台机器向另一台机器发送消息
-
下列关于MapReduce的说法,哪个描述是错误的?(D)
A、MapReduce具有广泛的应用,比如关系代数运算、分组与聚合运算等
B、MapReduce将复杂的、运行于大规模集群上的并行计算过程高度地抽象到了两个函数
C、编程人员在不会分布式并行编程的情况下,也可以很容易将自己的程序运行在分布式系统上,完成海量数据集的计算
D、不同的Map任务之间可以进行通信
-
下列关于Map和Reduce函数的描述,哪个是错误的?(C)
A、Map将小数据集进一步解析成一批<key,value>对,输入Map函数中进行处理
B、Map每一个输入的<k1,v1>会输出一批<k2,v2>。<k2,v2>是计算的中间结果
C、Reduce输入的中间结果<k2,List(v2)>中的List(v2)表示是一批属于不同k2的value
D、Reduce输入的中间结果<k2,List(v2)>中的List(v2)表示是一批属于同一个k2的value
-
下面哪一项不是MapReduce体系结构主要部分?(D)
A、Client
B、JobTracker
C、TaskTracker以及Task
D、Job
-
关于MapReduce1.0的体系结构的描述,下列说法错误的是?(A)
A、Task 分为Map Task 和Reduce Task 两种,分别由JobTracker 和TaskTracker 启动
B、slot 分为Map slot 和Reduce slot 两种,分别供MapTask 和Reduce Task 使用
C、TaskTracker 使用“slot”等量划分本节点上的资源量(CPU、内存等)
D、TaskTracker 会周期性接收JobTracker 发送过来的命令并执行相应的操作(如启动新任务、杀死任务等)
-
下列说法错误的是?(C)
A、Hadoop MapReduce是MapReduce的开源实现,后者比前者使用门槛低很多
B、MapReduce采用非共享式架构,容错性好
C、MapReduce主要用于批处理、实时、计算密集型应用
D、MapReduce采用“分而治之”策略
多选题
-
MapReduce相较于传统的并行计算框架有什么优势?(ABCD)
A、非共享式,容错性好
B、普通PC机,便宜,扩展性好
C、编程简单,只要告诉MapReduce做什么即可
D、批处理、非实时、数据密集型
-
MapReduce体系结构主要由以下那几个部分构成?(ABCD)
A、Client
B、JobTracker
C、TaskTracker
D、Task
-
下列关于MapReduce的体系结构的描述,说法正确的有?(ABD)
A、用户编写的MapReduce程序通过Client提交到JobTracker端
B、JobTracker负责资源监控和作业调度
C、TaskTracker监控所有TaskTracker与Job的健康状况
D、TaskTracker 使用“slot”等量划分本节点上的资源量(CPU、内存等)
-
MapReduce的作业主要包括什么?(AB)
A、从磁盘或从网络读取数据,即IO密集工作
B、计算数据,即CPU密集工作
C、针对不同的工作节点选择合适硬件类型
D、负责协调集群中的数据存储
-
对于MapReduce 而言,其处理单位是split。split 是一个逻辑概念,它包含哪些元数据信息?(AB)
A、数据起始位置
B、数据长度
C、数据所在节点
D、数据大小
-
下列关于Map 端的Shuffle的描述,哪些是正确的?(BC)
A、MapReduce默认为每个Map任务分配1000MB缓存
B、多个溢写文件归并成一个或多个大文件,文件中的键值对是排序的
C、当数据很少时,不需要溢写到磁盘,直接在缓存中归并,然后输出给Reduce
D、每个Map任务分配多个缓存,使得任务运行更有效率
-
MapReduce的具体应用包括哪些?(ABCD)
A、关系代数运算(选择、投影、并、交、差、连接)
B、分组与聚合运算
C、矩阵-向量乘法
D、矩阵乘法
-
MapReduce执行的全过程包括以下哪几个主要阶段?(ABCD)
A、从分布式文件系统读入数据
B、执行Map任务输出中间结果
C、通过 Shuffle阶段把中间结果分区排序整理后发送给Reduce任务
D、执行Reduce任务得到最终结果并写入分布式文件系统
-
下列说法正确的是?(ABCD)
A、MapReduce体系结构主要由四个部分组成,分别是:Client、JobTracker、TaskTracker以及Task
B、Task 分为Map Task 和Reduce Task 两种,均由TaskTracker 启动
C、在MapReduce工作流程中,所有的数据交换都是通过MapReduce框架自身去实现的
D、在MapReduce工作流程中,用户不能显式地从一台机器向另一台机器发送消息
简答题
- 试述MapReduce和Hadoop的关系。
谷歌公司最先提出了分布式并行编程模型MapReduce, Hadoop MapReduce是它的开源实现。谷歌的MapReduce运行在分布式文件系统GFS上,与谷歌类似,HadoopMapReduce运行在分布式文件系统HDFS上。相对而言,HadoopMapReduce 要比谷歌MapReduce 的使用门槛低很多,程序员即使没有任何分布式程序开发经验,也可以很轻松地开发出分布式程序并部署到计算机集群中。
- MapReduce 是处理大数据的有力工具,但不是每个任务都可以使用MapReduce来进行处理。试述适合用MapReduce来处理的任务或者数据集需满足怎样的要求。
适合用MapReduce来处理的数据集,需要满足一个前提条件: 待处理的数据集可以分解成许多小的数据集,而且每一个小数据集都可以完全并行地进行处理。
- MapReduce 模型采用Master(JobTracker)-Slave(TaskTracker)结构, 试描述JobTracker 和TaskTracker的功能。
MapReduce 框架采用了Master/Slave 架构,包括一个Master 和若干个Slave。Master 上运行JobTracker,Slave 上运行TaskTrackero 用户提交的每个计算作业,会被划分成若千个任务。JobTracker 负责作业和任务的调度,监控它们的执行,并重新调度已经失败的任务。TaskTracker负责执行由JobTracker指派的任务。
- TaskTracker 出现故障会有什么影响?该故障是如何处理的?
- MapReduce计算模型的核心是Map函数和Reduce函数,试述这两个函数各自的输人、输出以及处理过程。
Map函数的输人是来自于分布式文件系统的文件块,这些文件块的格式是任意的,可以是文档,也可以是二进制格式。文件块是一系列元素的集合,这些元素是任意类型的,同一个元素不能跨文件块存储。Map函数将输人的元素转换成<key,value形式的键值对,键和值的类型也是任意的,其中,键不同于一般的标志属性,即键没有唯一性,不能作为输出的身份标识,即使是同一输人元素,也可通过一个Map任务生成具有相同键的多个<key,value>。
Reduce函数的任务就是将输人的一-系列具有相同键的键值对以某种方式组合起来,输出处理后的键值对,输出结果会合并成一个文件。用户可以指定Reduce任务的个数(如n个),并通知实现系统,然后主控进程通常会选择一个Hash函数,Map任务输出的每个键都会经过Hash函数计算,并根据哈希结果将该键值对输人相应的Reduce任务来处理。对于处理键为k的Reduce任务的输人形式为<K,<v1,v2,…,vn>>.,输出为<k,V>。
- 试述MapReduce的工作流程(需包括提交任务、Map、Shuffle、 Reduce的过程)。
①MapReduce框架使用InputFormat模块做Map前的预处理,比如,验证输入的格式是否符合输人定义;然后,将输入文件切分为逻辑上的多个InputSplit, InputSplit 是MapReduce对文件进行处理和运算的输人单位,只是一个逻辑概念, 每个InputSplit并没有对文件进行实际切割,只是记录了要处理的数据的位置和长度。
②因为InputSplit 是逻辑切分而非物理切分,所以,还需要通过RecordReader (RR)根据InputSplit中的信息来处理InputSplit中的具体记录,加载数据并转换为适合Map任务读取的键值对,输入给Map任务。
③Map任务会根据用户自定义的映射规则,输出一系列的<key,value>作为中间结果。
④为了让Reduce可以并行处理Map的结果,需要对Map的输出进行-一定的分区、排序(Sort)、合并( Combine)、归并( Merge)等操作,得到形式的中间结果, 再交给对应的Reduce进行处理,这个过程称为Shuffle。
⑤Reduce 以一系列<key,value-list>中间结果作为输入, 执行用户定义的逻辑,输出结果给OutputFormat模块。
⑥OutputFormat 模块会验证输出目录是否已经存在以及输出结果类型是否符合配置文件中的配置类型,如果都满足,就输出Reduce的结果到分布式文件系统。
- Shuffle 过程是MapReduce 工作流程的核心,也被称为奇迹发生的地方,试分析Shuffle过程的作用。
Shufle,是指对Map输出结果进行分区、排序、合并等处理并交给Reduce的过程。Shuffle 过程分为Map端的操作和Reduce端的操作。
① 在Map端的Shuffle过程。Map的输出结果首先被写入缓存,当缓存满时,就启动溢写操作,把缓存中的数据写入磁盘文件,并清空缓存。当启动溢写操作时,首先需要把缓存中的数据进行分区,然后对每个分区的数据进行排序( Sort)和合并( Combine),之后再写入磁盘文件。每次溢写操作会生成-一个新的磁盘文件,随着Map任务的执行,磁盘中就会生成多个溢写文件。在Map任务全部结束之前,这些溢写文件会被归并( Merge)成-一个大的磁盘文件,然后,通知相应的Reduce任务来领取属于自己处理的数据。
② 在Reduce端的Shuffle 过程。Reduce 任务从Map端的不同Map机器领回属于自己处理的那部分数据,然后,对数据进行归并( Merge )后交给Reduce处理。
- 分别描述Map端和Reduce端的Shuffle过程(需包括Spill Sort、 Merge、Fetch 的过程)。
(1)Map端的Shuffle过程:
① 输入数据和执行Map任务。
② 写入缓存
③ 溢写(分区,排序和合并)
④ 文件归并
(2)Reduce端的Shuffle过程:
① “领取”数据
② 归并数据
③ 把数据输入Reduce任务
- MapReduce 中有这样-一个原则:移动计算比移动数据更经济。试述什么是本地计算,并分析为何要采用本地计算。
MapReduce设计的一个理念就是“计算向数据靠拢”,而不是“数据向计算靠拢”,因为移动数据需要大量的网络传输开销,尤其是在大规模数据环境下,这种开销尤为惊人,所以,移动计算要比移动数据更加经济。
本地计算:在一个集群中,只要有可能,MapReduce框架就会将Map程序就近地在HDFS数据所在的节点运行,即将计算节点和存储节点放在一起运行,从而减少了节点间的数据移动开销。
- 试说明一个MapReduce程序在运行期间,所启动的Map任务数量和Reduce任务数量各是由什么因素决定的。
MapReduce的核心思想可以用“分而治之”来描述,一个大的MapReduce作业,首先会被拆分成许多个Map任务在多台机器上并行执行,即Map任务的数量取决于mapReduce作业的大小。
当Map任务结束后,会生成以<key,value>形式表示的许多中间结果。然后,这些中间结果会被分发到多个Reduce任务在多台机器上并行执行,具有相同key的<key,value>会被发送到同一个Reduce任务那里,Reduce任务会对中间结果进行汇总计算得到最后结果,并输出到分布式文件系统中。即reduce的任务数量取决于Map输出结果中key的数量。
- 是否所有的MapReduce程序都需要经过Map和Reduce这两个过程?如果不是,请举例说明。
不是。对于关系的选择运算,只需要Map过程就能实现,对于关系R 中的每个元组t,检测是否是满足条件的所需元组,如果满足条件,则输出键值对<,>,也就是说,键和值都是t。这时的Reduce函数就只是一个恒等式,对输入不做任何变换就直接输出。
- 试分析为何采用Combiner可以减少数据传输量?是否所有的MapReduce程序都可以采用Combiner?为什么?
对于每个分区内的所有键值对,后台线程会根据key 对它们进行内存排序(Sort ),排序是MapReduce 的默认操作。排序结束后,还包含一个可选的合并(Combine )操作。如果用户事先没有定义Combiner 函数,就不用进行合并操作。如果用户事先定义了Combiner 函数,则这个时候会执行合并操作,从而减少需要溢写到磁盘的数据量。
所谓“合并”,是指将那些具有相同key 的<key,value>的value 加起来,比如,有两个键值对<*xmu",1>和<*xmu",1>,经过合并操作以后就可以得到一个键值对<*xmu",2>,减少了键值对的数量。
不过,并非所有场合都可以使用Combiner,因为,Combiner的输出是Reduce任务的输人,Combiner绝不能改变Reduce任务最终的计算结果,一般而言,累加、最大值等场景可以使用合并操作。
- MapReduce 程序的输入文件、输出文件都存储在HDFS中,而在Map任务完成时的中间结果则存储在本地磁盘中。试分析中间结果存储在本地磁盘而不是HDFS上有何优缺点。
因为Map的输出是中间的结果,这个中间结果是由reduce处理后才产生最终输出结果,而且一旦作业完成,map的输出结果就可以删除。如果把它存储在hdfs中就并备份,有些小题大作,如果运行map任务的节点将map中间结果传送给reduce任务之前失败,hadoop将在另一个节点上重新运行这个map任务以在此构建中间结果。
- 早期版本的HDFS,其默认块( Block)大小为64MB,而较新的版本默认为128MB,采用较大的块具有什么影响和优缺点?
优点:块寻址时间变短
- 试画出使用MapReduce来对英语句子“Whatever is worth doing is worth doing well"进行单词统计的过程。
- 在基于MapReduce的单词统计中,MapReduce是如何保证相同的单词数据会划分到同一个reduce上进行处理以保证结果的正确性?
对有相同KEY的Map输出的键值对进行归并,得到新的键值对作为Reduce任务的输入,由Reduce任务计算每个单词出现的次数,以保证结果的正确性。
第八章Hadoop架构再探讨
8.1 Hadoop的优化与发展
(1)Hadoop1.0的局限性-7方面 P155-P156
Hadoop 1.0 的核心组件(仅指 MapReduce 和 HDFS,不包括 Hadoop 生态系统内的 Pig、Hive、HBase 等其他组件)主要存在以下不足。
- 抽象层次低。功能实现需要手工编写代码来完成,有时只是为了实现一个简单的功能,也需要编写大量的代码。
- 表达能力有限。MapReduce 把复杂分布式编程工作高度抽象为两个函数,即 Map 和Reduce,在降低开发人员程序开发复杂度的同时,却也带来了表达能力有限的问题,实际生产环境中的一些应用是无法用简单的 Map 和 Reduce 来完成的。
- 开发者自己管理作业之间的依赖关系。一个作业(Job)只包含 Map 和 Reduce 两个阶段,通常的实际应用问题需要大量的作业进行协作才能顺利解决,这些作业之间往往存在复杂的依赖关系,但是 MapReduce 框架本身并没有提供相关的机制对这些依赖关系进行有效管理,只能由开发者自己管理。
- 难以看到程序整体逻辑。用户的处理逻辑都隐藏在代码细节中,没有更高层次的抽象机制对程序整体逻辑进行设计,这就给代码理解和后期维护带来了障碍。
- 执行迭代操作效率低。对于一些大型的机器学习、数据挖掘任务,往往需要多轮迭代才能得到结果。采用 MapReduce 实现这些算法时,每次迭代都是一次执行 Map、Reduce 任务的过程,这个过程的数据来自分布式文件系统 HDFS,本次迭代的处理结果也被存放到 HDFS 中,继续用于下一次迭代过程。反复读写 HDFS 中的数据,大大降低了迭代操作的效率。
- 资源浪费。在 MapReduce 框架设计中,Reduce 任务需要等待所有 Map 任务都完成后才可以开始,造成了不必要的资源浪费。
- 实时性差。只适用于离线批数据处理,无法支持交互式数据处理、实时数据处理。
(2)对Hadoop的两方面改进措施 P156
针对 Hadoop 1.0 存在的局限和不足,在后续发展过程中,Hadoop 对 MapReduce 和 HDFS 的许多方面做了有针对性的改进提升(见表 8-1),同时在 Hadoop 生态系统中也融入了更多的新成员,使得 Hadoop 功能更加完善,比较有代表性的产品包括 Pig、Oozie、Tez、Kafka 等(见表 8-2)。
1. Hadoop 框架自身的改进:从 1.0 到 2.0
| 组件 | Hadoop 1.0的问题 | Hadoop 2.0的改进 |
|---|---|---|
| HDFS | 单一名称节点,存在单点失效问题 | 设计了HDFSHA,提供名称节点热备份机制 |
| HDFS | 单一命名空间,无法实现资源隔离 | 设计了HDFS联邦,管理多个命名空间 |
| MapReduce | 资源管理效率低 | 设计了新的资源管理框架YARN |
2. 不断完善的 Hadoop 生态系统
| 组件 | 功能 | 解决Hadoop中存在的问题 |
|---|---|---|
| Pig | 处理大规模数据的脚本语言,用户只需要编写几条简单的语句,系统会自动转换为MapReduce作业 | 抽象层次低,需要手工编写大量代码 |
| Oozie | 工作流和协作服务引擎,协调Hadoop上运行的不同任务 | 没有提供作业依赖关系管理机制,需要用户自己处理作业之间的依赖关系 |
| Tez | 支持DAG作业的计算框架,对作业的操作进行重新分解和组合,形成一个大的DAG作业,减少不必要操作 | 不同的MapReduce任务之间存在重复操作,降低了效率 |
| Kafka | 分布式发布订阅消息系统,一般作为企业大数据分析平台的数据交换枢纽,不同类型的分布式系统可以统一接入 Kafka,实现和Hadoop各个组件之间的不同类型数据的实时高效交换 | Hadoop 生态系统中各个组件和其他产品之间缺乏统一的、高效的数据交换中介 |
8.2 HDFS2.0的新特性
(1)HDFS HA 解决了什么问题,怎么实现的 P157
对于分布式文件系统 HDFS 而言,名称节点(NameNode)是系统的核心节点,存储了各类元数据信息,并负责管理文件系统的命名空间和客户端对文件的访问。但是,在 HDFS 1.0 中,只存在一个名称节点,一旦这个唯一的名称节点发生故障,就会导致整个集群变得不可用,这就是常说的“单点故障问题”。虽然 HDFS 1.0 中存在一个第二名称节点(Secondary NameNode),但是第二名称节点并不是名称节点的备用节点,它与名称节点有着不同的职责。第二名称节点的主要功能是周期性地从名称节点获取命名空间镜像文件(FsImage)和修改日志(EditLog),进行合并后发送给名称节点,替换掉原来的 FsImage,以防止日志文件 EditLog 过大,导致名称节点失败恢复时消耗过多时间。合并后的命名空间镜像文件 FsImage 在第二名称节点中也保存一份,当名称节点失效的时候,可以使用第二名称节点中的 FsImage 进行恢复。
由于第二名称节点无法提供“热备份”功能,即在名称节点发生故障的时候,系统无法实时切换到第二名称节点立即对外提供服务,仍然需要进行停机恢复,因此 HDFS 1.0 的设计是存在单点故障问题的。为了解决单点故障问题,HDFS 2.0 采用了高可用(High Availability,HA)架构。在一个典型的 HA 集群中,一般设置两个名称节点,其中一个名称节点处于“活跃”(Active)状态,另一个处于“待命”(Standby)状态,HDFS HA 架构如图 8-1 所示。处于活跃状态的名称节点负责对外处理所有客户端的请求,处于待命状态的名称节点则作为备用节点,保存足够多的系统元数据,当名称节点出现故障时提供快速恢复能力。也就是说,在 HDFS HA 中,处于待命状态的名称节点提供了“热备份”,一旦活跃名称节点出现故障,就可以立即切换到待命名称节点,不会影响到系统的正常对外服务。
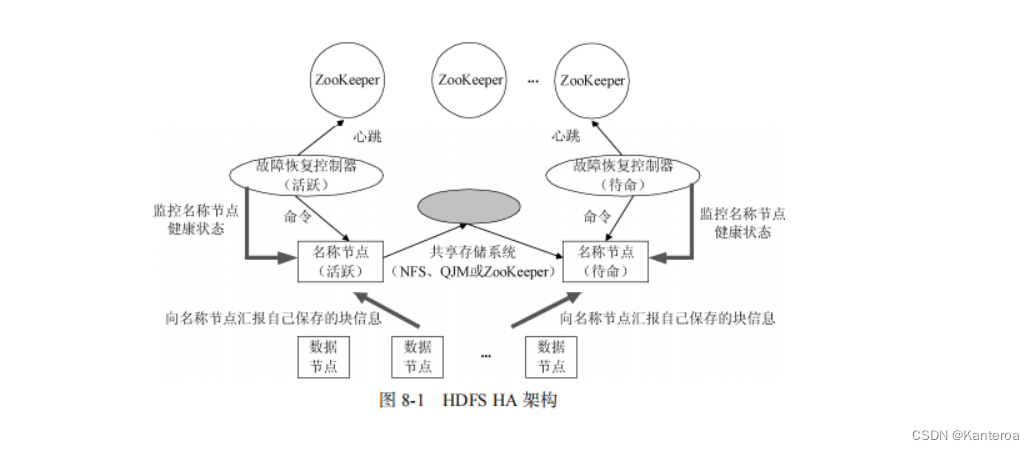
由于待命名称节点是活跃名称节点的“热备份”,因此活跃名称节点的状态信息必须实时同步到待命名称节点。两种名称节点的状态同步,可以借助于一个共享存储系统来实现,比如网络文件系统(Network File System,NFS)、仲裁日志管理器(Quorum Journal Manager,QJM)或者ZooKeeper。活跃名称节点将更新数据写入共享存储系统,待命名称节点会一直监听该系统,一旦发现有新的写入,就立即从公共存储系统中读取这些数据并加载到自己的内存中,从而保证与活跃名称节点状态完全同步。
此外,名称节点中保存了数据块到实际存储位置的映射信息,即每个数据块是由哪个数据节点存储的。当一个数据节点加入 HDFS 集群时,它会把自己所包含的数据块列表报告给名称节点,此后会通过“心跳”的方式定期执行这种告知操作,以确保名称节点的块映射是最新的。因此,为了实现故障时的快速切换,必须保证待命名称节点一直包含最新的集群中各个块的位置信息。为了做到这一点,需要给数据节点配置两个名称节点的地址(即活跃名称节点和待命名称节点),并把块的位置信息和心跳信息同时发送到这两个名称节点。为了防止出现“两个管家”现象,HA还要保证任何时刻都只有一个名称节点处于活跃状态,否则,如果有两个名称节点处于活跃状态,HDFS 集群中出现“两个管家”,就会导致数据丢失或者其他异常。这个任务是由 ZooKeeper 来实现的,ZooKeeper 可以确保任意时刻只有一个名称节点提供对外服务。
(2)HDFS 联邦 -联邦解决了什么问题(优势)、联邦的结构设计、访问方式 P159
采用 HDFS 联邦的设计方式,可解决单名称节点存在的以下 3 个问题:
-
HDFS 集群可扩展性。多个名称节点各自分管一部分目录,使得一个集群可以扩展到更多节点,不再像 HDFS 1.0 中那样由于内存的限制制约文件存储数目。
-
系统整体性能更高。多个名称节点管理不同的数据,且同时对外提供服务,将为用户提供更高的读写吞吐率。
-
良好的隔离性。用户可根据需要将不同业务数据交由不同名称节点管理,这样不同业务之间的影响很小。
需要注意的是,HDFS 联邦并不能解决单点故障问题。也就是说,每个名称节点都存在单点故障问题,需要为每个名称节点部署一个后备名称节点,以应对名称节点死机后对业务产生的影响。
HDFS 联邦的设计
HDFS 联邦可以很好地解决上述 3 个方面的问题。在 HDFS 联邦中,设计了多个相互独立的名称节点,使得 HDFS 的命名服务能够横向扩展,这些名称节点分别进行各自命名空间和块的管理,相互之间是联邦关系,不需要彼此协调。HDFS 联邦并不是真正的分布式设计,但是采用这种简单的“联合”设计方式,在实现和管理复杂性方面,都要远低于真正的分布式设计,而且可以快速满足需求。在兼容性方面,HDFS 联邦具有良好的向后兼容性,可以无缝地支持单名称节点架构中的配置。所以,原有针对单名称节点的部署配置,不需要做任何修改就可以继续工作。
HDFS 联邦中的名称节点提供了命名空间和块管理功能。在 HDFS 联邦中,所有名称节点会共享底层的数据节点存储资源,如图 8-2 所示。每个数据节点要向集群中所有的名称节点注册,并周期性地向名称节点发送“心跳”和块信息,报告自己的状态,同时处理来自名称节点的指令。
HDFS 1.0 只有一个命名空间,这个命名空间使用底层数据节点全部的块。与 HDFS 1.0 不同的是,HDFS 联邦拥有多个独立的命名空间,其中,每一个命名空间管理属于自己的一组块,这些属于同一个命名空间的块构成一个“块池”(Block Pool)。每个数据节点会为多个块池提供块的存储。可以看出,数据节点是一个物理概念,块池则属于逻辑概念,一个块池是一组块的逻辑集合,块池中的各个块实际上存储在各个不同的数据节点中。因此,HDFS 联邦中的一个名称节点失效,也不会影响到与它相关的数据节点继续为其他名称节点提供服务。
HDFS 联邦的访问方式
对于 HDFS 联邦中的多个命名空间,可以采用客户端挂载表(Client-Side Mount-Table)方式进行数据共享和访问。每个阴影三角形代表一个独立的命名空间,上方空白三角形表示从客户方向去访问下面子命名空间,如图 8-3 所示。客户可以通过不同的挂载点来访问不同的子命名空间。这就是 HDFS 联邦中命名空间管理的基本原理,即把各个命名空间挂载到全局“挂载表”(Mount-table)中,实现数据全局共享。同样地,命名空间挂载到个人的挂载表中,就成为应用程序可见的命名空间。
8.3 新一代资源管理调度框架YARN※
(1)MapReduce1.0的缺陷-需要切实理解四个缺点的具体含义 P160(可以结合MapReduce1.0的工作流程理解)
MapReduce 1.0 采用 Master/Slave 架构设计(见图 8-4),包括一个 JobTracker 和若干个TaskTracker,前者负责作业的调度和资源的管理,后者负责执行 JobTracker 指派的具体任务。这种架构设计具有一些很难克服的缺陷,具体如下。
-
存在单点故障。MapReduce 1.0 由 JobTracker 负责所有 MapReduce 作业的调度,而系统中只有一个 JobTracker,因此会存在单点故障问题,即这个唯一的 JobTracker 出现故障就会导致系统不可用。
-
JobTracker“大包大揽”导致任务过重。JobTracker 既要负责作业的调度和失败恢复,又要负责资源管理分配。JobTracker 执行过多的任务,需要消耗大量的资源,例如当存在非常多的MapReduce 任务时,JobTracker 需要巨大的内存开销,这也潜在地增加了 JobTracker 失败的风险。正因如此,业内普遍总结出 MapReduce 1.0 支持主机数目的上限为 4000 个。
-
容易出现内存溢出。在 TaskTracker 端,资源的分配并不考虑 CPU、内存的实际使用情况,而只是根据 MapReduce 任务的个数来分配资源。当两个具有较大内存消耗的任务被分配到同一个 TaskTracker 上时,很容易发生内存溢出的情况。
-
资源划分不合理。资源(CPU、内存)被强制等量划分成多个“槽”(Slot),槽又被进一步划分为 Map 槽和 Reduce 槽两种,分别供 Map 任务和 Reduce 任务使用,彼此之间不能使用分配给对方的槽。也就是说,当 Map 任务已经用完 Map 槽时,即使系统中还有大量剩余的 Reduce槽,也不能拿来运行 Map 任务,反之亦然。这就意味着,当系统中只存在单一 Map 任务或 Reduce任务时,会造成资源的浪费。
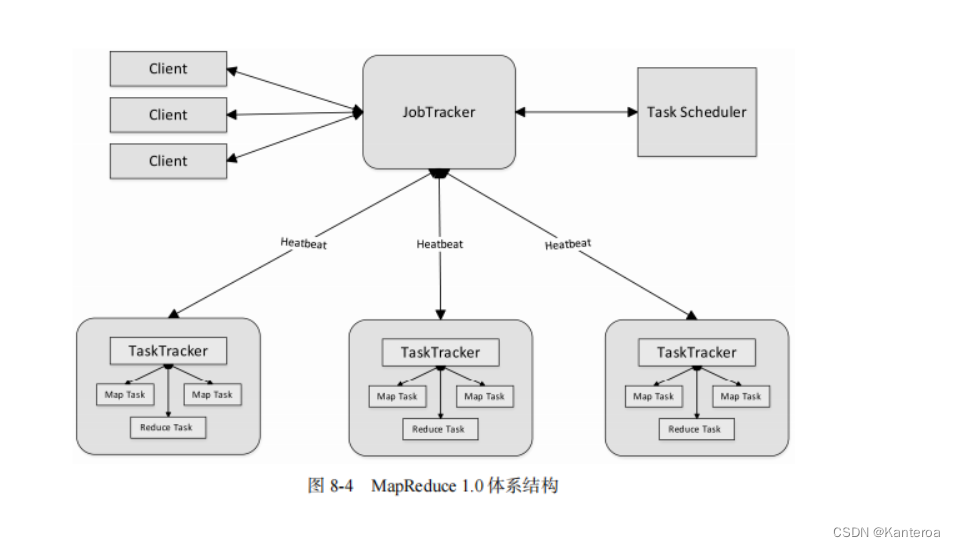
(2)Yarn的体系结构和工作流程 -需要具体详细理解 P162-163
YARN 体系结构
如图 8-6 所示,YARN 体系结构中包含了 3 个组件:ResourceManager、ApplicationMaster 和NodeManager。YARN 各个组件的功能见下表。
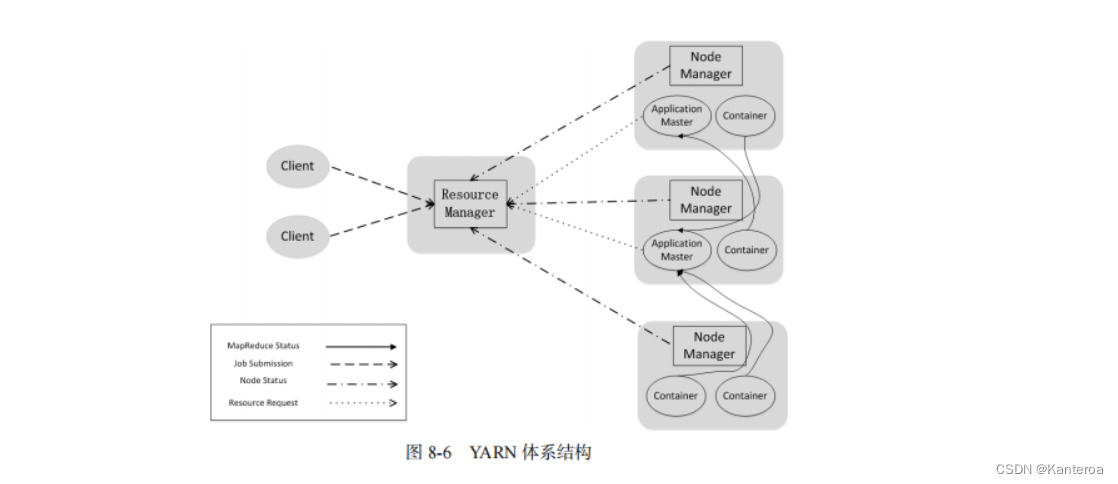
| 组件 | 功能 |
|---|---|
| ResourceManager | 处理客户端请求 启动/监控ApplicationMaster 监控 NodeManager 资源分配与调度 |
| ApplicationMaster | 为应用程序申请资源,并分配给内部任务 任务调度、监控与容错 |
| NodeManager | 单个节点上的资源管理 处理来自ResourceManger的命令 处理来自ApplicationMaster的命令 |
资源管理器(ResourceManager,RM)负责整个系统的资源管理和分配,主要包括两个组件,即资源调度器(Resource Scheduler)和应用程序管理器(Applications Manager)。资源调度器主要负责资源管理和分配,不再负责跟踪和监控应用程序的执行状态,也不负责执行失败恢复,因为这些任务都已经交给 ApplicationMaster 组件来负责。调度器接收来自 ApplicationMaster 的应用程序资源请求,并根据容量、队列等限制条件(如每个队列分配一定的资源,最多执行一定数量的作业等),把集群中的资源以“容器”(Container)的形式分配给提出申请的应用程序。容器的选择通常会考虑应用程序所要处理的数据的位置,就近进行选择,从而实现“计算向数据靠拢”。在MapReduce 1.0 中,资源分配的单位是“槽”,而在 YARN 中是以容器作为动态资源分配单位,每个容器中都封装了一定数量的 CPU、内存、磁盘等资源,从而限定每个应用程序可以使用的资源量。同时,在 YARN 中调度器被设计成是一个可插拔的组件,YARN 不仅自身提供了许多种直接可用的调度器,也允许用户根据自己的需求重新设计调度器。应用程序管理器负责系统中所有应用程序的管理工作,主要包括应用程序提交、与资源调度器协商资源以启动 ApplicationMaster、监控 ApplicationMaster 运行状态并在失败时重新启动等。
在 Hadoop 平台上,用户的应用程序是以作业的形式提交的,然后一个作业会被分解成多个任务(包括 Map 任务和 Reduce 任务)进行分布式执行。ResourceManager 接收用户提交的作业,按照作业的上下文信息以及从 NodeManager 收集来的容器状态信息,启动调度过程,为用户作业启动一个 ApplicationMaster 。 ApplicationMaster 的主要功能是:当用户作业提交时,ApplicationMaster 与 ResourceManager 协商获取资源,ResourceManager 会以容器的形式为ApplicationMaster 分配资源;把获得的资源进一步分配给内部的各个任务(Map 任务或 Reduce 任务),实现资源的“二次分配”;与 NodeManager 保持交互通信,进行应用程序的启动、运行、监控和停止,监控申请到的资源的使用情况,监控所有任务的执行进度和状态,并在任务发生失败时执行失败恢复(即重新申请资源重启任务);定时向 ResourceManager 发送“心跳”消息,报告资源的使用情况和应用的进度信息;当作业完成时,ApplicationMaster 向 ResourceManager 注销容器,执行周期完成。
NodeManager 是驻留在一个 YARN 集群中的每个节点上的代理,主要负责容器生命周期管理,监控每个容器的资源(CPU、内存等)使用情况,跟踪节点健康状况,并以“心跳”的方式与ResourceManager保持通信,向ResourceManager汇报作业的资源使用情况和每个容器的运行状态,同时,它还要接收来自 ApplicationMaster 的启动/停止容器的各种请求。需要说明的是,NodeManager 主要负责管理抽象的容器,只处理与容器相关的事情,而不具体负责每个任务(Map任务或 Reduce 任务)自身状态的管理,因为这些管理工作是由 ApplicationMaster 完成的,ApplicationMaster 会通过不断与 NodeManager 通信来掌握各个任务的执行状态。
在集群部署方面,YARN 的各个组件是和 Hadoop 集群中的其他组件统一部署的。如图 8-7所示,YARN 的 ResourceManager 组件和 HDFS 的名称节点(NameNode)部署在一个节点上,YARN的 ApplicationMaster、NodeManager 和 HDFS 的数据节点(DataNode)部署在一起。YARN 中的容器代表了 CPU、内存、网络等计算资源,它也和 HDFS 的数据节点部署在一起。
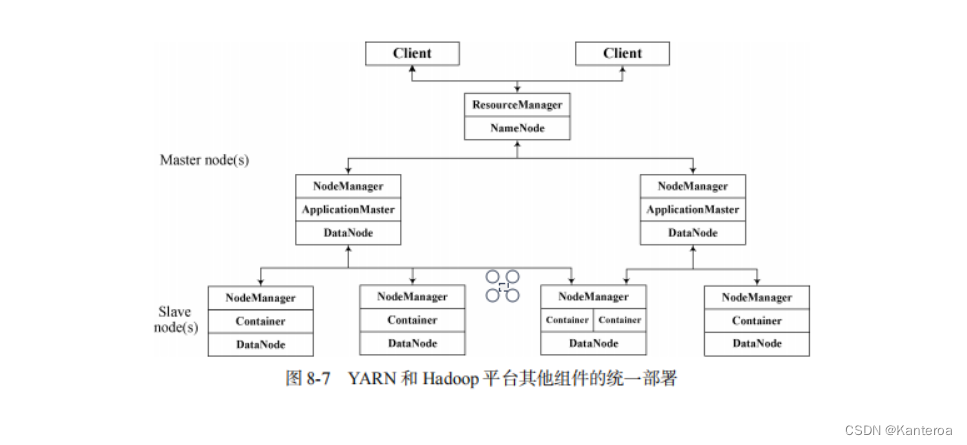
YARN 工作流程
YARN 的工作流程如图 8-8 所示,在 YARN 框架中执行一个 MapReduce 程序时,从提交到完成需要经历如下 8 个步骤。
- 用户编写客户端应用程序,向 YARN 提交应用程序,提交的内容包括 ApplicationMaster程序、启动 ApplicationMaster 的命令、用户程序等。
- YARN 中的 ResourceManager 负责接收和处理来自客户端的请求。接到客户端应用程序请求后,ResourceManager 里面的调度器会为应用程序分配一个容器。同时,ResourceManager 的应用程序管理器会与该容器所在的 NodeManager 通信,为该应用程序在该容器中启动一个ApplicationMaster(即图 8-8 中的“MR App Mstr”)。
- ApplicationMaster 被创建后会首先向 ResourceManager 注册,从而使得用户可以通过ResourceManager 来直接查看应用程序的运行状态。接下来的步骤(4)~(7)是具体的应用程序执行步骤。
- ApplicationMaster 采用轮询的方式通过 RPC 协议向 ResourceManager 申请资源。
- ResourceManager 以“容器”的形式向提出申请的 ApplicationMaster 分配资源,一旦ApplicationMaster 申请到资源,就会与该容器所在的 NodeManager 进行通信,要求它启动任务。
- 当 ApplicationMaster 要求容器启动任务时,它会为任务设置好运行环境(包括环境变量、JAR 包、二进制程序等),然后将任务启动命令写到一个脚本中,最后通过在容器中运行该脚本来启动任务。
- 各个任务通过某个 RPC 协议向 ApplicationMaster 汇报自己的状态和进度,让ApplicationMaster 可以随时掌握各个任务的运行状态,从而可以在任务失败时重新启动任务。
- 应用程序运行完成后,ApplicationMaster 向 ResourceManager 的应用程序管理器注销并关闭自己。若 ApplicationMaster 因故失败,ResourceManager 中的应用程序管理器会监测到失败的情形,然后将其重新启动,直到所有的任务执行完毕。
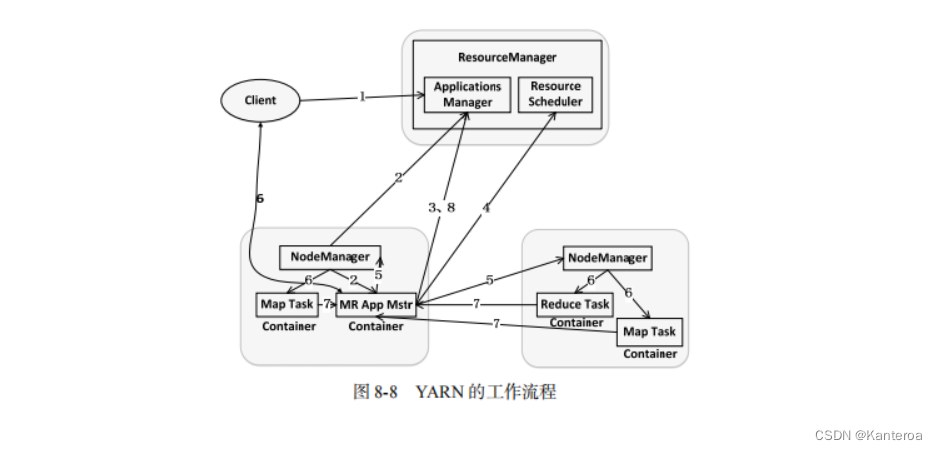
(3)Yarn和Mapreduce1.0的对比分析※ P164
从 MapReduce 1.0 框架发展到 YARN 框架,客户端并没有发生变化,其大部分调用 API 及接口都保持兼容。因此,原来针对 Hadoop 1.0 开发的代码不用做大的改动,就可以直接在 Hadoop 2.0平台上运行。
在 MapReduce 1.0 框架中的 JobTracker 和 TaskTracker,在 YARN 框架中变成了 3 个组件,即ResourceManager、ApplicationMaster 和 NodeManager。ResourceManager 要负责调度、启动每一
个作业所属的 ApplicationMaster,监控 ApplicationMaster 运行状态并在失败时重新启动,而作业里面的不同任务的调度、监控、重启等,不再由 ResourceManager 负责,而是交给与该作业相关联的 ApplicationMaster 来负责。ApplicationMaster 要负责一个作业生命周期内的所有工作。也就是说,它承担了 MapReduce 1.0 中 JobTracker 的“作业监控”功能。
总体而言,YARN 相对 MapReduce 1.0 具有以下优势。
- 大大减少了承担中心服务功能的 ResourceManager 的资源消耗。MapReduce 1.0 中的JobTracker 需要同时承担资源管理、任务调度和任务监控等三大功能,而 YARN 中的ResourceManager 只需要负责资源管理,需要消耗大量资源的任务调度和监控重启工作则交由ApplicationMaster 来完成。由于每个作业都有与之关联的独立的 ApplicationMaster,因此,系统中存在多个作业时,就会同时存在多个 ApplicationMaster,这就实现了监控任务的分布化,不再像MapReduce 1.0 那样监控任务只集中在一个 JobTracker 上。
- MapReduce 1.0 既是一个计算框架,又是一个资源管理调度框架,但是它只能支持MapReduce 编程模型。而 YARN 是一个纯粹的资源调度管理框架,在它上面可以运行包括MapReduce 在内的不同类型的计算框架,默认类型是 MapReduce 。因为 YARN 中 的ApplicationMaster 是可变更的,针对不同的计算框架,用户可以采用任何编程语言自己编写服务于该计算框架的 ApplicationMaster。比如用户可以编写一个面向 MapReduce 计算框架的ApplicationMaster,从而使得 MapReduce 计算框架可以运行在 YARN 框架之上。同理,用户还可以编写面向 Spark、Storm 等计算框架的 ApplicationMaster,从而使得 Spark、Storm 等计算框架也可以运行在 YARN 框架之上。
- YARN 中的资源管理比 MapReduce 1.0 更加高效。YARN 以容器为单位进行资源管理和分配,而不是以槽为单位,避免了 MapReduce 1.0 中槽的闲置浪费情况,大大提高了资源的利用率。
8.4 Hadoop生态系统中具有代表性的功能组件※
(1)Pig是什么?解决了Hadoop什么问题 P166
Pig
Pig 是 Hadoop 生态系统的一个组件,提供了类似 SQL 的 Pig Latin(包含 Filter、GroupBy、Join、OrderBy 等操作,同时也支持用户自定义函数),允许用户通过编写简单的脚本来实现复杂的数据分析,而不需要编写复杂的 MapReduce 应用程序。Pig 会自动把用户编写的脚本转换成MapReduce 作业在 Hadoop 集群上运行,而且具备对生成的 MapReduce 程序进行自动优化的功能,所以用户在编写 Pig 程序的时候,不需要关心程序的运行效率,这就大大缩短了用户编程时间。
因此,通过配合使用 Pig 和 Hadoop,用户在处理海量数据时就可以达到事半功倍的效果。这比使用 Java、C++等语言编写 MapReduce 程序的难度要小很多,并且用更少的代码量实现了相同的数据处理分析功能。
Pig 可以加载数据、表达转换数据以及存储最终结果,因此在企业数据分析系统实际应用中(见图 8-10),Pig 通常用于数据提取、转换和加载(Extraction、Transformation、Loading,ETL)过程,即来自各个不同数据源的数据被收集过来以后,使用 Pig 进行统一加工处理,然后加载到数据仓库 Hive 中,由 Hive 实现对海量数据的分析。需要特别指出的是,每种数据分析工具都有一定的局限性,Pig 的设计和 MapReduce 一样,都是面向批处理的,因此 Pig 并不适合所有的数据处理任务,特别是当需要查询大数据集中的一小部分数据时,Pig 仍然需要对整个或绝大部分数据集进行扫描,因此实现性能不会很好。
(2)Tez基于什么执行机制,解决Hadoop什么问题 P168
Tez
Tez 是 Apache 开源的支持 DAG 作业的计算框架,直接源于 MapReduce 框架。其核心思想是将 Map 和 Reduce 两个操作进一步进行拆分,即将 Map 拆分成 Input、Processor、Sort、Merge 和Output 等,将 Reduce 拆分成 Input、Shuffle、Sort、Merge、Processor 和 Output 等,经过分解后的这些元操作可以进行任意组合产生新的操作,经过一些控制程序组装后就可形成一个大的 DAG 作业。通过 DAG 作业的方式运行 MapReduce 作业,提供了程序运行的整体处理逻辑,就可以去除工作流当中多余的 Map 阶段,减少不必要的操作,提升数据处理的性能。Hortonworks 把 Tez 应用到数据仓库 Hive 的优化中,使得性能提升了约 100 倍。
(3)Kafka解决了Hadoop什么问题 P169
Kafka
Kafka 是由 LinkedIn 开发的一种高吞吐量的分布式发布/订阅消息系统,用户通过 Kafka 系统可以发布大量的消息,同时能实时订阅消费消息。Kafka 设计的初衷是构建一个可以处理海量日志、用户行为和网站运营统计等的数据处理框架。为了满足上述应用需求,系统需要同时提供实时在线处理的低延迟和批量离线处理的高吞吐量。现有的一些消息队列框架,通常设计了完备的机制来保证消息传输的可靠性,但是由此会带来较大的系统负担,在批量处理海量数据时无法满足高吞吐率的要求;另外有一些消息队列框架则被设计成实时消息处理系统,虽然可以带来很高的实时处理性能,但是在批量离线场合时无法提供足够的持久性,即可能发生消息丢失。同时,在大数据时代涌现的新的日志收集处理系统(如 Flume、Scribe 等)往往更擅长批量离线处理,而不能较好地支持实时在线处理。相对而言,Kafka 可以同时满足在线实时处理和批量离线处理。
最近几年,Kafka 在大数据生态系统中开始发挥着越来越重要的作用,在 Uber、Twitter、Netflix、LinkedIn、Yahoo!、Cisco、Goldman Sachs 等公司得到了大量的应用。目前,在很多公司的大数据平台中,Kafka 通常扮演数据交换枢纽的角色。
传统的关系数据库一直是企业关键业务系统的首选数据库产品,能够较好地满足企业对数据一致性和高效复杂查询的需求。但是,关系数据库只能支持规范的结构化数据存储,无法有效应对各种不同类型的数据,比如各种非结构化的日志记录、图结构数据等,同时面对海量大规模数据也显得“力不从心”。因此,关系数据库无法达到“一种产品满足所有应用场景”的目的。在这样的大背景下,各种专用的分布式系统纷纷涌现,包括离线批处理系统(如 MapReduce、HDFS等)、NoSQL 数据库(如 Redis、MongoDB、HBase、Cassandra 等)、流计算框架(如 Storm、S4、Spark Streaming、Samza 等)、图计算框架(如 Pregel、Hama 等)、搜索系统(如 ElasticSearch、Solr 等)等。这些系统不追求“大而全”,而是专注于满足企业某一方面的业务需求,因此有很好的性能。但是,随之而来的问题是如何实现这些专用系统与 Hadoop 系统各个组件之间数据的导入和导出。一种简单的想法是,为各个专用系统单独开发数据导入导出工具。这种解决方案在技术上没有实现难度,但是带来了较高的实现代价。因为每当有一款新的产品加入企业的大数据生态系统中,就需要为这款产品开发和 Hadoop 各个组件的数据交换工具。因此,有必要设计一种通用的工具,起到数据交换枢纽的作用。当其他工具加入大数据生态系统后,只需要开发和这款通用工具的数据交换方案,就可以通过这个交换枢纽轻松实现和其他 Hadoop 组件的数据交换。
Kafka 就是一款可以实现这种功能的产品。在公司的大数据生态系统中,可以把 Kafka 作为数据交换枢纽,不同类型的分布式系统(如关系数据库、NoSQL 数据库、流处理系统、批处理系统等)可以统一接入 Kafka,从而实现和Hadoop 各个组件之间的不同类型数据的实时高效交换,较好地满足各种企业的应用需求,如图 8-14 所示。同时,借助于 Kafka 作为交换枢纽,也可以很好地解决不同系统之间的数据生产/消费速率不同的问题。比如在线上实时数据需要写入 HDFS 的场景中,线上数据不仅生成速率快,而且具有突发性,如果直接把线上数据写入 HDFS,可能导致高峰时间 HDFS 写入失败,在这种情况下就可以先把线上数据写入 Kafka,然后借助于 Kafka 导入 HDFS。
习题
单选题
-
Hadoop1.0的核心组件(仅指MapReduce和HDFS,不包括Hadoop生态系统内的Pig、Hive、HBase等其他组件),下列哪项是它的不足?(B)
A、抽象层次高
B、表达能力有限,抽象层次低,需人工编码
C、价格昂贵
D、可维护性低
-
下面哪个选项不属于Hadoop1.0 的问题?(D)
A、单一名称节点,存在单点失效问题
B、单一命名空间,无法实现资源隔离
C、资源管理效率低
D、很难上手
-
下列哪项是Hadoop生态系统中Spark的功能?(D)
A、处理大规模数据的脚本语言
B、工作流和协作服务引擎,协调Hadoop上运行的不同任务
C、不支持DAG作业的计算框架
D、基于内存的分布式并行编程框架,具有较高的实时性,并且较好支持迭代计算
-
在Hadoop生态系统中,Kafka主要解决Hadoop 中存在哪些的问题?(A)
A、Hadoop生态系统中各个组件和其他产品之间缺乏统一的、高效的数据交换中介
B、不同的MapReduce任务之间存在重复操作,降低了效率
C、延迟高,而且不适合执行迭代计算
D、抽象层次低,需要手工编写大量代码
-
下列哪一个不属于HDFS1.0 中存在的问题?(A)
A、无法水平扩展
B、单点故障问题
C、单一命名空间
D、系统整体性能受限于单个名称节点的吞吐量
-
关于HDFS Federation 的设计的描述,哪个是错误的?(A)
A、属于不同命名空间的块可以构成同一个“块池”
B、HDFS Federation中,所有名称节点会共享底层的数据节点存储资源,数据节点向所有名称节点汇报
C、设计了多个相互独立的名称节点
D、HDFS的命名服务能够水平扩展
-
下列关于MapReduce1.0的描述,错误的是?(B)
A、JobTracker“大包大揽”导致任务过重
B、不存在单点故障
C、容易出现内存溢出(分配资源只考虑MapReduce任务数,不考虑CPU、内存)
D、资源划分不合理(强制划分为slot ,包括Map slot和Reduce slot)
-
下列哪个不属于YARN体系结构中ResourceManager的功能?(D)
A、处理客户端请求
B、监控NodeManager
C、资源分配与调度
D、处理来自ApplicationMaster的命令
-
下列哪个不属于YARN体系结构中ApplicationMaster的功能?(D)
A、任务调度、监控与容错
B、为应用程序申请资源
C、将申请的资源分配给内部任务
D、处理来自ResourceManager的命令
多选题
-
下列选项中,哪些属于Hadoop1.0的核心组件的不足之处?(ABCD)
A、实时性差(适合批处理,不支持实时交互式)
B、资源浪费(Map和Reduce分两阶段执行)
C、执行迭代操作效率低
D、难以看到程序整体逻辑
-
Hadoop的优化与发展主要体现在哪几个方面?(ABC)
A、Hadoop自身核心组件MapReduce的架构设计改进
B、Hadoop自身核心组件HDFS的架构设计改进
C、Hadoop生态系统其它组件的不断丰富
D、Hadoop生态系统减少不必要的组件,整合系统
-
下列哪些属于Hadoop2.0相对于Hadoop1.0的改进?(ABCD)
A、设计了HDFS HA
B、提供名称节点热备机制
C、设计了HDFS Federation,管理多个命名空间
D、设计了新的资源管理框架YARN
-
下面哪个属于不断完善的Hadoop生态系统中的组件?(ABC)
A、Pig
B、Tez
C、Kafka
D、DN8
-
HDFS1.0 主要存在哪些问题?(ABCD)
A、单点故障问题
B、不可以水平扩展
C、单个名称节点难以提供不同程序之间的隔离性
D、系统整体性能受限于单个名称节点的吞吐量
-
HDFS Federation 相对于HDFS1.0 的优势主要体现在哪里?(BCD)
A、能够解决单点故障问题
B、HDFS 集群扩展性
C、性能更高效
D、良好的隔离性
-
JobTracker主要包括哪三大功能?(ABC)
A、资源管理
B、任务调度
C、任务监控
D、数据即服务
-
YARN 体系结构主要包括哪三部分?(ABD)
A、ResourceManager
B、NodeManager
C、DataManager
D、ApplicationMaster
-
在YARN体系结构中,ApplicationMaster主要功能包括哪些?(ABC)
A、当用户作业提交时,ApplicationMaster与ResourceManager协商获取资源,ResourceManager会以容器的形式为ApplicationMaster分配资源
B、把获得的资源进一步分配给内部的各个任务(Map任务或Reduce任务),实现资源的“二次分配”
C、定时向ResourceManager发送“心跳”消息,报告资源的使用情况和应用的进度信息
D、向ResourceManager汇报作业的资源使用情况和每个容器的运行状态
简答题
- 试述流数据的概念。
数据密集型应用——流数据, 即数据以大量、快速、时变的流形式持续到达。以传感监测为例,在大气中放置PM2.5传感器实时监测大气中的PM2.5的浓度,监测数据会源源不断地实时传输回数据中心,监测系统对回传数据进行实时分析,预判空气质量变化趋势,如果空气质量在未来一段时间内会达到影响人体健康的程度,就启动应急响应机制。
- 试述流数据的特点。
① 数据快速持续到达,潜在大小也许是无穷无尽的。
② 数据来源众多,格式复杂。
③ 数据量大,但是不十分关注存储,一旦流数据中的某个元素经过处理,要么被丢弃,要么被归档存储。
④ 注重数据的整体价值,不过分关注个别数据。
⑤ 数据顺序颠倒,或者不完整,系统无法控制将要处理的新到达的数据元素的顺序。
- 在流计算的理念中,数据的价值与时间具备怎样的关系?
数据的价值随着时间的流逝而降低。
- 试述流计算的需求。
① 高性能。 处理大数据的基本要求, 如每秒处理几十万 条数据。
② 海量式。支持TB级甚至是PB级的数据规模。
③ 实时性。必须保证-一个较低的延迟时间,达到秒级别,甚至是毫秒级别。
④ 分布式。支持大数据的基本架构,必须能够平滑扩展。
⑤ 易用性。能够快速进行开发和部署。
⑥ 可靠性。能可靠地处理流数据。
- 试述MapReduce框架为何不适合用于处理流数据。
(1) Hadoop设计的初衷是面向大规模数据的批量处理。批量任务的处理方式,在时间延迟方面无法满足流计算的实时响应需求。
(2) 将MapReduce的批量处理转为小批量处理,将输入数据切成小的片段,每隔一个周期启动一次MapReduce作业。此方法存在如下问题:
① 切分成小的片段,虽然可以降低延迟,但是,也增加了任务处理的附加开销,而且还要处理片段之间的依赖关系,因为一个片段可能需要用到前一个片段的计算结果。
② 需要对MapReduce进行改造以支持流式处理,Reduce阶段的结果不能直接输出,而是保存在内存中;这种做法会大大增加MapReduce框架的复杂度,导致系统难以维护和扩展;
③ 降低了用户程序的可伸缩性,因为,用户必须要使用MapReduce接口来定义流式作业。
- 将基于MapReduce的批量处理转为小批量处理,每隔一个周期就启动一次MapReduce作业,通过这样的方式来处理流数据是否可行?为什么?
不可行。
切分成小的片段,虽然可以降低延迟,但是,也增加了任务处理的附加开销,而且还要处理片段之间的依赖关系;Reduce阶段的结果不能直接输出;降低了用户程序的可伸缩性。
- 列举几个常见的流计算框架。
目前有三类常见的流计算框架和平台:商业级的流计算平台、开源流计算框架、公司为支持自身业务开发的流计算框架。
(1)商业级:IBM InfoSphere Streams和IBM StreamBase
(2)较为常见的是开源流计算框架,代表如下:
Twitter Storm:免费、开源的分布式实时计算系统,可简单、高效、可靠地处理大量的流数据
Yahoo! S4(Simple Scalable Streaming System):开源流计算平台,是通用的、分布式的、可扩展的、分区容错的、可插拔的流式系统
(3)公司为支持自身业务开发的流计算框架:
Facebook Puma
Dstream(百度)
银河流数据处理平台(淘宝)
- 试述流计算的一般处理流程。
流计算的处理流程一般包含三个阶段:数据实时采集、数据实时计算、实时查询服务。
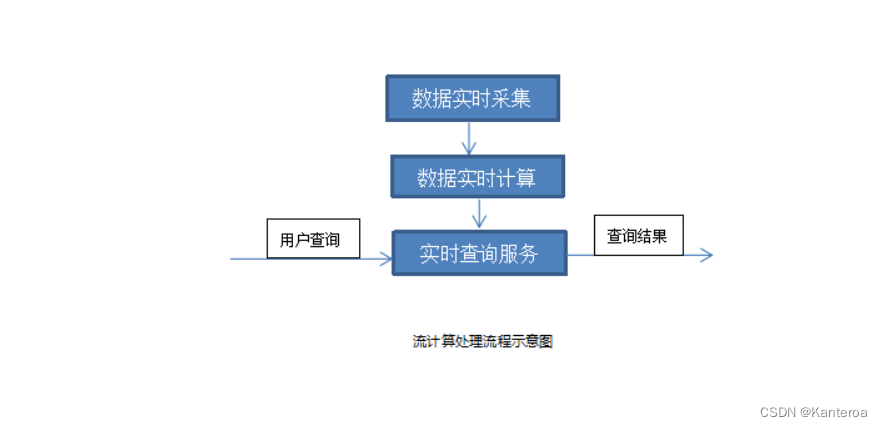
- 试述流计算流程与传统的数据处理流程之间的主要区别。
传统数据处理的数据是旧的;查询传统数据处理的数据需要主动发出请求。
- 试述数据实时采集系统的一般组成部分。
① Agent: 主动采集数据,并把数据推送到Collctor 部分。
② Collector: 接收多个Agent的数据,并实现有序、可靠、高性能的转发。
③ Store: 存储Collector转发过来的数据。
- 试述流计算系统与传统的数据处理系统对所采集数据的处理方式有什么不同。
流处理系统处理的是实时的数据,而传统的数据处理系统处理的是预先存储好的静态数据;
用户通过流处理计算系统获取的是实时结果,而传统的数据处理系统获取的是过去某一时刻的结果。
- 试列举几个流计算的应用领域。
① 实时分析。购物网站,社交网站的推荐基于对用户行为的分析来实现。
② 实时交通。通过结合来自不同源的实时数据,生成动态的、多方位的观察交通流量的方式,为城市规划者和乘客提供实时交通状况查询。
- 流计算适用于具备怎样特点的场景?
适合于具备需要处理持续到达的流数据、对数据处理有较高实时性要求的场景。
- 试述流计算为业务分析带来了怎样的改变。
能在秒级别内得到实时的分析结果,有利于根据当前得到的分析结果及时地作出决策。
- 除了实时分析和实时交通,试再列举一个适 合采用流计算的应用场景,并描述流计算可带来怎样的改变。
以淘宝网“双十一”“双十二”的促销活动为例,商家会在淘宝网上或者在店铺内投放相应的广告来吸引用户,同时,商家也可能会准备多个广告样式、文案,根据广告效果来做出调整,对对广告的点击情况、用户的访问情况进行分析,基于实时分析,推荐的结果得到有效提升。
- 试述Storm框架如何改变开发人员开发实时应用的方式。
以往开发人员在开发一个实时应用的时候,除了要关注处理逻辑,还要为实时数据的获取、传输、存储大伤脑筋,但是,现在情况却大为不同。开发人员可以基于开源流处理框架Storm,快速地搭建一套健壮、 易用的实时流处理系统,并配合Hadoop等平台,就可以低成本地做出很多以前很难想象的实时产品。
- 为什么说使用Storm流处理框架开发实时应用,其开发成本较低?
Storm 是开源免费的,用户可以轻易进行搭建、使用,大大降低了学习和使用成本。
- 试述Twitter采用的分层数据处理框架。
实时系统和批处理系统组成的分层数据处理架构。
- 试列举几个Storm框架的主要特点。
① 整合性。Storm 可方便地与队列系统和数据库系统进行整合。
② 简易的API。Storm的API在使用上即简单又方便。
③ 可扩展性。Storm 的并行特性使其可以运行在分布式集群中。
④ 容错性。Storm 可以自动进行故障节点的重启,以及节点故障时任务的重新分配。
⑤ 可靠的消息处理。Storm保证每个消息都能完整处理。
⑥ 支持各种编程语言。Storm 支持使用各种编程语言来定义任务。
⑦ 快速部署。Storm 仅需要少量的安装和配置就可以快速进行部署和使用。
⑧ 免费、开源。Storm 是- -款开源框架,可以免费使用。
- 试列举几个Storm框架的应用领域。
实时分析、在线机器学习、持续计算、远程RPC等。
- Storm 的主要术语包括Streams、Spouts、 Bolts 、Topology 和Stream Groupings, 请分别简要描述这几个术语。
Streams:是一个无限的Tuple序列。
Spouts: Stream 的源头抽象。
Bolts: Streams 的状态转换过程。
Topology: Spouts 和Bolts组成的网络。
Stream Groupings: 用于告知Topology如何在两个组件间进行Tuple的传送。
- 试述Tuple的概念。
Tuple即元组,是元素的有序列表。
- 一个Topology由哪些组件组成?
Storm将Spouts和Bolts组成的网络抽象成Topology。
- 不同的Bolt之间如何传输Tuple?
由StreamGroupings决定。
- 试列举几种Stream Groupings的方式。
Shuffle Grouping: 随机分组,随机分发Tuple。
Fields Grouping: 按字段分组,有相同值的Tuple会被分发到对应的Bolt。
All Grouping: 广播分发,每个Tuple都会被分发到所有Bolt中。
Global Grouping: 全局分组,Tuple 只会分发给一个 Bolt。
Non Grouping: 不分组,与随机分组效果类似。
Direct Grouping: 直接分组,由Tuple的生产者来定义接收者。
- 试述MapReduce Job和Storm Topology的区别和联系。
Storm运行在分布式集群中,其运行任务的方式与Hadoop 类似:在Hadoop 上运行的是MapReduce作业,而在Storm上运行的是“Topology"。 但两者的任务大不相同,其中主要的不同是一个MapReduce作业最终会完成计算并结束运行,而一个Topology将持续处理消息。
- Storm集群中的Master节点和Worker节点各自运行什么后台进程?这些进程又分别负责什么工作?
Storm集群采用“Master-Worker” 的节点方式,其中,Master 节点运行名“Nimbus”的后台程序(类似Hadoop中的“JobTracker" ),负责在集群范围内分发代码、为Worker分配任务和监测故障。
每个Worker节点运行名为“Supervisor”的后台程序,负责监听分配给它所在机器的工作,即根据Nimbus分配的任务来决定启动或停止Worker进程。
- 试述Zookeeper在Storm框架中的作用。
Storm采用了Zookeeper 来作为分布式协调组件,负责Nimbus和多个Supervisor 之间的所有协调工作。
- Nimbus 进程和Supervisor 进程都是快速失败( fail-fast)和无状态( stateless)的,这样的设计有什么优点?
一旦重启,两个进程借助Zookeeper将状态信息存放在Zookeeper
中或本地磁盘中进行恢复并继续工作。使Storm很稳定。
- Nimbus 进程或Supervisor进程意外终止后,重启时能否恢复到终止之前的状态?为什么?
Nimbus 进程或Supervisor进程意外终止后,重启时可以恢复到终止之前的状态。
Master节点并没有直接和Worker节点通信,而是借助Zookeeper ,将状态信息存放在Zookeeper中或本地磁盘中,以便节点故障时进行快速恢复。这意味着若Nimbus进程或Supervisor进程终止后,一旦进程重启,它们将恢复到之前的状态并继续工作。这种设计使Storm极其稳定。
- 试述Storm框架的工作流程。
客户端提交Topology到Storm集群中; .
Nimbus将分配给Supervisor的任务写入Zookeeper;
Supervisor从Zookeeper中获取所分配的任务,并启动Worker进程;
Worker进程执行具体的任务。
- 试述Storm框架实现单词统计的一般流程。
① 从Spout中发送Stream;
② 用于分割单词的Bolts将接受的句子分解为独立的单词,将单词作为Tuple的字段名发送出去;
③ 用于计数的Bolts接受表示单词的Tuple,并对其进行统计;
④ 输出每个单词以及单词出现过的次数。
- 试述采用MapReduce框架进行单词统计,与采用Storm框架进行单词统计,有什么区别?
MapReduce使用的是Map和Reduce的抽象,而Storm使用的是Spout和Bolts的抽象。
- Storm 框架中的单词统计Topology定义如下,其中定义了两个Bolt,试述两个Bolt各自
完成的功能,以及中间结果如何在两个Bolt之间传输。
第一个Bolt用于单词的分割,该Bolt中的任务随机接收Spout发送的句子,并从接收的句子中提取出单词。
第二个Bolt 接收第一个Bolt发送的Tuple进行处理,即统计分割后的单词出现的次数。
每个Bolt使用了Groupings()系列定义了Tuple 的发送方式。
- 在Storm的单词统计实例中,为何需要使用fieldsGrouping()方法保证相同单词发送到同一个任务上进行处理?
通过fieldsGrouping()方法,在“word”-上具有相同字段值的所有Tuple将发送到同一个任务中进行统计,从而保证了统计的准确性。
第十章Spark
10.1 Spark概述
(1)是什么、谁提出的、哪年打破了什么记录、有什么特点 P192-P193
Spark 最初由美国加州大学伯克利分校(University of California,Berkeley)的 AMP(Algorithms, Machines and People)实验室于 2009 年开发,是基于内存计算的大数据并行计算框架,可用于构建大型的、低延迟的数据分析应用程序。Spark 在诞生之初属于研究性项目,其诸多核心理念均源自学术研究论文。2013 年,Spark 加入 Apache 孵化器项目后,开始迅速地发展,如今已成为Apache 软件基金会最重要的三大分布式计算系统开源项目之一(即 Hadoop、Spark、Storm)。
Spark 作为大数据计算平台的后起之秀,在 2014 年打破了 Hadoop 保持的基准排序(Sort Benchmark)纪录,使用 206 个节点在 23 min 的时间里完成了 100 TB 数据的排序,而 Hadoop 是使用 2000 个节点在 72 min 的时间里才完成同样数据的排序。也就是说,Spark 仅使用了约十分之一的计算资源,获得了约比 Hadoop 快 3 倍的速度。新纪录的诞生,使得 Spark 获得多方追捧,也表明了 Spark 可以作为一个更加快速、高效的大数据计算框架。
Spark 具有如下 4 个主要特点。
- 运行速度快。Spark 使用先进的有向无环图(Directed Acyclic Graph,DAG)执行引擎,以支持循环数据流与内存计算,基于内存的执行速度可比 Hadoop MapReduce 快上百倍,基于磁盘的执行速度也能快十倍左右。
- 容易使用。Spark 支持使用 Scala、Java、Python 和 R 语言进行编程,简洁的 API 设计有助于用户轻松构建并行程序,并且可以通过 Spark Shell 进行交互式编程。
- 通用性。Spark 提供了完整而强大的技术栈,包括 SQL 查询、流式计算、机器学习和图算法组件,这些组件可以无缝整合在同一个应用中,足以应对复杂的计算。
- 运行模式多样。Spark 可运行于独立的集群模式中,或者运行于 Hadoop 中,也可运行于Amazon EC2 等云环境中,并且可以访问 HDFS、Cassandra、HBase、Hive 等多种数据源。
Spark 如今已吸引了国内外各大公司的注意,如腾讯、淘宝、百度、亚马逊等公司均不同程度地使用了 Spark 来构建大数据分析应用,并应用到实际的生产环境中。相信在将来,Spark 会在更多的应用场景中发挥重要作用。
10.2 Spark生态系统 -各个组件的功能 P196
Spark 生态系统主要包含了 Spark Core、Spark SQL、Spark Streaming、Structured Streaming、MLlib 和 GraphX 等组件,各个组件的具体功能如下。
(1)Spark Core。
Spark Core 包含 Spark 的基本功能,如内存计算、任务调度、部署模式、故障恢复、存储管理等,主要面向批量数据处理。Spark 建立在统一的抽象弹性分布式数据集(Resilient Distributed Dataset,RDD)之上,使其可以以基本一致的方式应对不同的大数据处理场景。
(2)Spark SQL。
Spark SQL 允许开发人员直接处理 RDD,同时也可查询 Hive、HBase 等外部数据源。Spark SQL的一个重要特点是其能够统一处理关系表和 RDD,使得开发人员不需要自己编写 Spark 应用程序。开发人员可以轻松地使用 SQL 命令进行查询,并进行更复杂的数据分析。
(3)Spark Streaming。
Spark Streaming 支持高吞吐量、可容错处理的实时流数据处理,其核心思路是将流数据分解成一系列短小的批处理作业,每个短小的批处理作业都可以使用 Spark Core 进行快速处理。Spark Streaming 支持多种数据输入源,如 Kafka、Flume 和 TCP 套接字等。
(4)Structured Streaming。
Structured Streaming 是一种基于 Spark SQL 引擎构建的、可扩展且容错的流处理引擎。通过一致的 API,Structured Streaming 使得使用者可以像编写批处理程序一样编写流处理程序,简化了使用者的使用难度。
(5)MLlib(机器学习)。
MLlib 提供了常用机器学习算法的实现,包括聚类、分类、回归、协同过滤等,降低了机器学习的门槛,开发人员只要具备一定的理论知识就能进行机器学习的工作。
(6)GraphX(图计算)。
GraphX 是 Spark 中用于图计算的 API,可认为是 Pregel 在 Spark 上的重写及优化。GraphX性能良好,拥有丰富的功能和运算符,能在海量数据上自如地运行复杂的图算法。
需要说明的是,无论是 Spark SQL、Spark Streaming、MLlib,还是 GraphX,都可以使用 Spark Core 的 API 处理问题,它们的方法几乎是通用的,处理的数据也可以共享,不同应用之间的数据可以无缝集成。
在不同的应用场景下,可以选用的其他框架和 Spark 生态系统中的组件见下表。
| 应用场景 | 时间跨度 | 其他框架 | Spark生态系统中的组件 |
|---|---|---|---|
| 复杂的批量数据处理 | 小时级 | MapReduce、Hive | Spark Core |
| 基于历史数据的交互式查询 | 分钟级、秒级 | Impala、Dremel、Drill | Spark SQL |
| 基于实时数据流的数据处理 | 毫秒级、秒级 | Storm、S4 | Spark Streaming Structured Streaming |
| 基于历史数据的数据挖掘 | - | Mahout | MLlib |
| 图结构数据的处理 | - | Pregel、Hama | GraphX |
10.3 Spark运行架构※
(1)7个基本概念:需要理解,结合运行原理去理解概念 P197
- RDD:是分布式内存的一个抽象概念,提供了一种高度受限的共享内存模型。
- DAG:反映 RDD 之间的依赖关系。
- Executor:是运行在工作节点(Worker Node)上的一个进程,负责运行任务,并为应用程序存储数据。
- 应用:用户编写的 Spark 应用程序。
- 任务:运行在 Executor 上的工作单元。
- 作业:一个作业(Job)包含多个 RDD 及作用于相应 RDD 上的各种操作。
- 阶段:是作业的基本调度单位,一个作业会分为多组任务(Task),每组任务被称为“阶
段”(Stage),或者也被称为“任务集”。
(2)Spark运行基本流程 P198
Spark 运行基本流程如图 10-6 所示,流程如下。
- 当一个 Spark 应用被提交时,首先需要为这个应用构建起基本的运行环境,即由任务控制节点(Driver)创建一个 SparkContext,由 SparkContext 负责和资源管理器—Cluster Manager的通信,以及进行资源的申请、任务的分配和监控等。SparkContext 会向资源管理器注册并申请运行 Executor 的资源。
- 资源管理器为 Executor 分配资源,并启动 Executor 进程,Executor 运行情况将随着“心跳”发送到资源管理器上。
- SparkContext 根据 RDD 的依赖关系构建 DAG,并将 DAG 提交给 DAG 调度器(DAGScheduler)进行解析,将 DAG 分解成多个“阶段”(每个阶段都是一个任务集),并且计算出各个阶段之间的依赖关系,然后把一个个“任务集”提交给底层的任务调度器(TaskScheduler)进行处理;Executor 向 SparkContext 申请任务,任务调度器将任务分发给 Executor 运行,同时SparkContext 将应用程序代码发放给 Executor。
- 任务在 Executor 上运行,把执行结果反馈给任务调度器,然后反馈给 DAG 调度器,运行完毕后写入数据并释放所有资源。
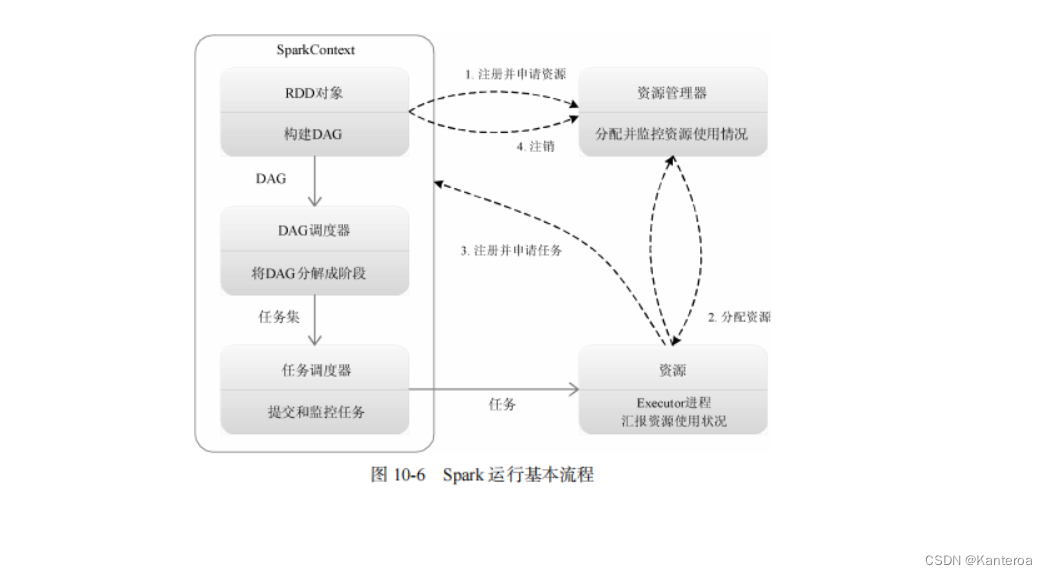
(3)RDD的基本理解、特性、依赖关系、stage、运行过程 P202-P207
RDD 概念
一个 RDD 就是一个分布式对象集合,本质上是一个只读的分区记录集合。每个 RDD 可以分成多个分区,每个分区就是一个数据集片段,并且一个 RDD 的不同分区可以被保存到集群中不同的节点上,从而可以在集群中的不同节点上进行并行计算。RDD 提供了一种高度受限的共享内存模型,即 RDD 是只读的记录分区的集合,不能直接修改,只能基于稳定的物理存储中的数据集来创建 RDD,或者通过在其他 RDD 上执行确定的转换操作(如 map、join 和 groupBy 等)而创建得到新的 RDD。RDD 提供了一组丰富的操作以支持常见的数据运算,分为“行动”(Action)和“转换”(Transformation)两种类型,前者用于执行计算并指定输出的形式,后者指定 RDD 之间的相互依赖关系。两类操作的主要区别是,转换操作(如 map、filter、groupBy、join 等)接受RDD 并返回 RDD,而行动操作(如 count、collect 等)接受 RDD 但是返回非 RDD(即输出一个值或结果)。RDD 提供的转换接口都非常简单,都是类似 map、filter、groupBy、join 等粗粒度的数据转换操作,而不是针对某个数据项的细粒度修改。因此,RDD 比较适合对于数据集中元素执行相同操作的批处理式应用,而不适用于需要异步、细粒度状态的应用,比如 Web 应用系统、增量式的网页爬虫等。正因为这样,这种粗粒度转换接口设计,会使人直觉上认为 RDD 的功能很受限、不够强大。但是,实际上 RDD 已经被实践证明可以很好地应用于许多并行计算应用中,可以具备很多现有计算框架(如 MapReduce、SQL、Pregel 等)的表达能力,并且可以应用于这些框架处理不了的交互式数据挖掘应用。
RDD 特性
总体而言,Spark 采用 RDD 以后能够实现高效计算的主要原因如下。
- 高效的容错性。现有的分布式共享内存、键值存储、内存数据库等,为了实现容错,必须在集群节点之间进行数据复制或者记录日志,也就是在节点之间会发生大量的数据传输的情况,这对于数据密集型应用而言会带来很大的开销。在 RDD 的设计中,数据只读,不可修改,如果需要修改数据,必须从父 RDD 转换到子 RDD,由此在不同 RDD 之间建立了血缘关系。所以,RDD 是一种天生具有容错机制的特殊集合,不需要通过数据冗余的方式(比如检查点)实现容错,而只需通过 RDD 父子依赖(血缘)关系重新计算丢失的分区来实现容错,无须回滚整个系统。这样就避免了数据复制的高开销,而且重算过程可以在不同节点之间并行进行,实现高效的容错。此外,RDD 提供的转换操作都是一些粗粒度的操作(比如 map、filter 和 join 等),RDD 依赖关系只需要记录这种粗粒度的转换操作,而不需要记录具体的数据和各种细粒度操作的日志(比如对哪个数据项进行了修改),这就大大降低了数据密集型应用中的容错开销。
- 中间结果持久化到内存。数据在内存中的多个 RDD 操作之间进行传递,不需要“落地”到磁盘上,避免了不必要的读写磁盘开销。
- 存放的数据可以是 Java 对象,避免了不必要的对象序列化和反序列化开销。
RDD 之间的依赖关系
RDD 中不同的操作,会使得不同 RDD 分区之间会产生不同的依赖关系。DAG 调度器根据RDD 之间的依赖关系,把 DAG 划分成若干个阶段。RDD 中的依赖关系分为窄依赖(Narrow Dependency)与宽依赖(Wide Dependency),二者的主要区别在于是否包含 Shuffle 操作。
(1)Shuffle 操作。
Spark 中的一些操作会触发 Shuffle 过程,这个过程涉及数据的重新分发,因此,会产生大量的磁盘 IO 和网络开销。这里以 reduceByKey(func)操作为例介绍 Shuffle 过程。在 reduceByKey(func)操作中,对于所有<key,value>形式的 RDD 元素,所有具有相同 key 的 RDD 元素的 value 会被归并,得到<key,value-list>的形式。然后,对这个 value-list 使用函数 func 计算得到聚合值,比如<“hadoop”,1>、<“hadoop”,1>和<“hadoop”,1>这 3 个键值对,会被归并成<“hadoop”,<1,1,1>>的形式,如果 func 是一个求和函数,可以计算得到汇总结果<“hadoop”,3>。这里的问题是,对于与一个 key 关联的 value-list 而言,这个 value-list 里面可能包含了很多的value,而这些 value 一般都会分布在多个分区里,并且是散布在不同的机器上。但是,对于 Spark而言,在执行 reduceByKey 的计算时,必须把与某个 key 关联的所有 value 都发送到同一台机器上。图 10-9 是一个关于 Shuffle 操作的简单实例,假设这里在 3 台不同的机器上有 3 个 Map 任务,即 Map1、Map2 和 Map3,它们分别从输入文本文件中读取数据执行 Map 操作得到了中间结果,为了简化起见,这里让 3 个 Map 任务输出的中间结果都相同,即<“a”,1>、<“b”,1>和<“c”,1>。现在要把 Map 的输出结果发送到 3 个不同的 Reduce 任务中进行处理,Reduce1、Reduce2 和 Reduce3分别运行在 3 台不同的机器上,并且假设 Reduce1 任务专门负责处理 key 为"a"的键值对的词频统计工作,Reduce2 任务专门负责处理 key 为"b"的键值对的词频统计工作,Reduce3 任务专门负责处理 key 为"c"的键值对的词频统计工作。这时,Map1 必须把<“a”,1>发送到 Reduce1,把<“b”,1>发送到 Reduce2,把<“c”,1>发送到 Reduce3,同理,Map2 和 Map3 也必须完成同样的工作,这个过程就被称为“Shuffle”。可以看出,Shuffle 的过程(即把 Map 输出的中间结果分发到 Reduce任务所在的机器),会产生大量的网络数据分发,带来高昂的网络传输开销。
Shuffle 过程不仅会产生大量网络传输开销,也会带来大量的磁盘 IO 开销。Spark 经常被认为是基于内存的计算框架,为什么也会产生磁盘 IO 开销呢?对于这个问题,这里有必要做一个解释。
在 Hadoop MapReduce 框架中,Shuffle 是连接 Map 和 Reduce 的桥梁,Map 的输出结果需要经过 Shuffle 过程以后,也就是经过数据分类以后交给 Reduce 处理。因此,Shuffle 的性能高低直接影响了整个程序的性能和吞吐量。Shuffle 是指对 Map 输出结果进行分区、排序、合并等处理并交给 Reduce 的过程。
Spark 作为 MapReduce 框架的一种改进,自然也实现了 Shuffle 的逻辑(见图 10-10)。
首先是 Map 端的 Shuffle 写入(Shuffle Write)。每一个 Map 任务会根据 Reduce 任务的数量创建出相应的桶(bucket),这里,桶的数量是 m×r,其中,m 是 Map 任务的个数,r 是 Reduce 任务的个数。Map 任务产生的结果会根据设置的分区算法填充到每个桶中去。分区算法可以自定义,也可以采用系统默认的算法;默认的算法是根据每个键值对(key,value)的 key,把键值对哈希到不同的桶中去。当 Reduce 任务启动时,它会根据自己任务的 id 和所依赖的 Map 任务的 id,从远端或是本地取得相应的桶,作为 Reduce 任务的输入进行处理。
这里的桶是一个抽象概念,在实现中每个桶可以对应一个文件,也可以对应文件的一部分。但是,从性能角度而言,每个桶对应一个文件的实现方式,会导致 Shuffle 过程生成过多的文件,比如如果有 1000 个 Map 任务和 1000 个 Reduce 任务,就会生成 100 万个文件,这样会给文件系统带来沉重的负担。
所以,在最新的 Spark 版本中,采用了多个桶写入一个文件的方式(见图 10-11)。每个 Map任务不会为每个 Reduce 任务单独生成一个文件,而是把每个 Map 任务所有的输出数据只写到一个文件中。因为每个 Map 任务中的数据会被分区,所以使用了索引(Index)文件来存储具体 Map任务输出数据在同一个文件中是如何被分区的信息。Shuffle 过程中每个 Map 任务会产生两个文件,即数据文件和索引文件,其中,数据文件存储当前 Map 任务的输出结果,索引文件中则存储数据文件中的数据的分区信息。下一个阶段的 Reduce 任务就是根据索引文件来获取属于自己处理的那个分区的数据。
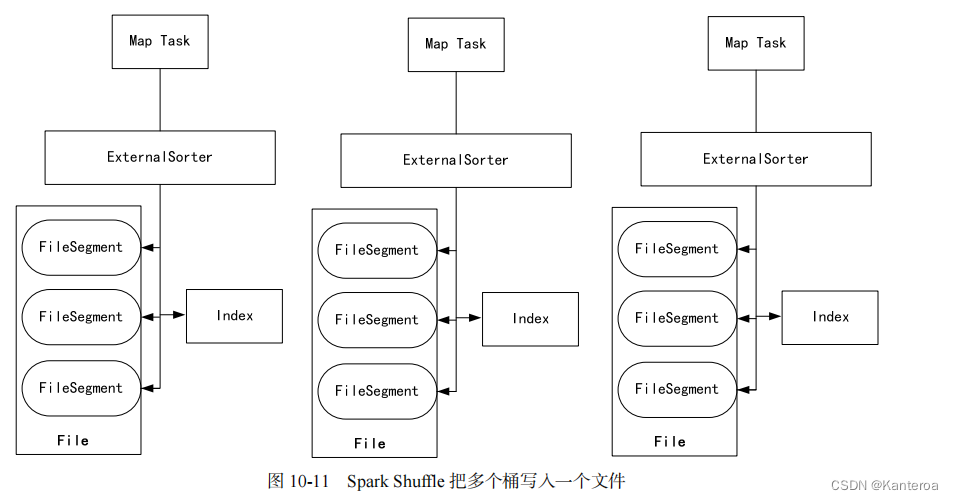
其次是 Reduce 端的 Shuffle 读取(Shuffle Fetch)。在 Hadoop MapReduce 的 Shuffle 过程中,在 Reduce 端,Reduce 任务会到各个 Map 任务那里把自己要处理的数据都拉到本地,并对拉过来的数据进行归并和排序,使得相同 key 的不同 value 按序归并到一起,供 Reduce 任务使用。这个归并和排序的过程,在 Spark 中是如何实现的呢?
虽然 Spark 属于 MapReduce 体系,但是它对传统的 MapReduce 算法进行了一定的改进。Spark假定在大多数应用场景中,Shuffle 数据的排序操作不是必须的,比如在进行词频统计时,如果强制地进行排序,只会使性能变差,因此,Spark 并不在 Reduce 端做归并和排序,而是采用了称为Aggregator 的机制。Aggregator 本质上是一个 HashMap,里面的每个元素是<K,V>形式。以词频统计为例,它会将从 Map 端拉取的每一个(key,value),更新或是插入 HashMap 中,若在 HashMap中没有查找到这个 key,则把这个(key,value)插入其中,若查找到这个 key,则把 value 的值累加到 V 上去。这样就不需要预先把所有的(key,value)进行归并和排序,而是来一个处理一个,避免了外部排序这一步骤。但同时需要注意的是,Reduce 任务所拥有的内存,必须足以存放属于自己处理的所有 key 和 value 值,否则就会产生内存溢出问题。因此,Spark 文档中建议用户执行涉及这类操作的时候尽量增加分区的数量,也就是增加 Map 和 Reduce 任务的数量。增加 Map 和 Reduce任务的数量虽然可以减小分区的大小,使得内存可以容纳这个分区,但是,在 Shuffle 写入环节,桶的数量是由 Map 和 Reduce 任务的数量决定的,任务越多,桶的数量就越多,就需要更多的缓冲区(buffer),带来更多的内存消耗。因此,在内存使用方面,我们会陷入一个两难的境地:一方面,为了减少内存的使用,需要采取增加 Map 和 Reduce 任务数量的策略;另一方面,Map 和Reduce 任务数量的增多,又会带来内存开销增大的问题。最终,为了减少内存的使用,只能将Aggregator 的操作从内存移到磁盘上进行。也就是说,尽管 Spark 经常被称为“基于内存的分布式计算框架”,但是,它的 Shuffle 过程依然需要把数据写入磁盘。
(2)窄依赖和宽依赖。
以是否包含 Shuffle 操作为判断依据,RDD 中的依赖关系可以分为窄依赖(Narrow Dependency)与宽依赖(Wide Dependency),图 10-13 展示了两种依赖之间的区别。**窄依赖表现为一个父 RDD 的分区对应于一个子 RDD 的分区,或多个父 RDD 的分区对应于一个子 RDD 的分区。**比如图 10-13(a)中,RDD1 是 RDD2 的父 RDD,RDD2 是子 RDD,RDD1的分区 1,对应于 RDD2 的一个分区(即分区 4)。再比如 RDD6 和 RDD7 都是 RDD8 的父 RDD,RDD6 中的分区(分区 15)和 RDD7 中的分区(分区 18),两者都对应于 RDD8 中的一个分区(分区 21)。**宽依赖则表现为存在一个父 RDD 的一个分区对应一个子 RDD 的多个分区。**比如图 10-13(b)中,RDD9 是 RDD12 的父 RDD,RDD9 中的分区 24 对应了 RDD12 中的两个分区(即分区 27 和分区 28)。
总体而言,如果父 RDD 的一个分区只被一个子 RDD 的一个分区所使用就是窄依赖,否则就是宽依赖。窄依赖典型的操作包括 map、filter、union 等,不会包含 Shuffle 操作;宽依赖典型的操作包括 groupByKey、sortByKey 等,通常会包含 Shuffle 操作。对于连接操作,可以分为两种情况。
- 对输入进行协同划分,属于窄依赖,如图 10-12(a)所示。协同划分(Co-partitioned)是指多个父 RDD 的某一分区的所有“键”(key),落在子 RDD 的同一个分区内,不会出现同一个父 RDD 的某一分区,落在子 RDD 的两个分区的情况。
- 对输入做非协同划分,属于宽依赖,如图 10-12(b)所示。Spark 的这种依赖关系设计,使其具有了天生的容错性,大大加快了 Spark 的执行速度。因为RDD 数据集通过“血缘关系”记住了它是如何从其他 RDD 中演变过来的(血缘关系记录的是粗颗粒度的转换操作行为),当这个 RDD 的部分分区数据丢失时,它可以通过血缘关系获取足够的信息来重新运算和恢复丢失的分区数据,由此带来了性能的提升。相对而言,在这两种依赖关系中,窄依赖的失败恢复更为高效,它只需要根据父 RDD 分区重新计算丢失的分区即可(不需要重新计算所有分区),而且可以并行地在不同节点进行重新计算。而对于宽依赖而言,单个节点失效通常意味着重新计算过程会涉及多个父 RDD 分区,开销较大。此外,Spark 还提供了数据检查点和记录日志,用于持久化中间 RDD,从而使得在进行失败恢复时不需要追溯到最开始的阶段。在进行故障恢复时,Spark 会对数据检查点开销和重新计算 RDD 分区的开销进行比较,从而自动选择最优的恢复策略。
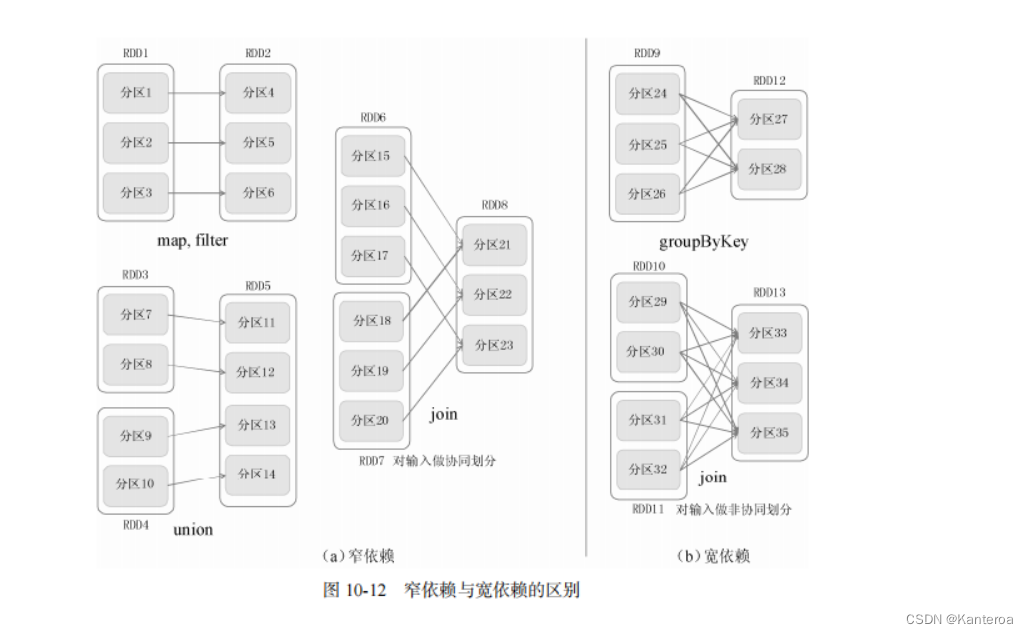
阶段的划分stage
Spark 根据 DAG 中的 RDD 依赖关系,把一个作业分成多个阶段。宽依赖和窄依赖相较而言,窄依赖对于作业的优化很有利。逻辑上,每个 RDD 操作都是一个 fork/join(一种用于并行执行任务的框架),对每个 RDD 分区计算 fork,完成计算后对各个分区得到的结果进行 join 操作,然后fork/join 下一个 RDD 操作。把一个 Spark 作业直接翻译到物理实现(即执行完一个 RDD 操作再继续执行另外一个 RDD 操作)是很不经济的。首先,每一个 RDD(即使是中间结果)都需要保存到内存或磁盘中,时间和空间开销大。其次,join 作为全局的路障(Barrier),代价是很昂贵的。所有分区上的计算都要完成以后,才能进行 join 得到结果,这样,作业执行进度就会严重受制于最慢的那个节点。如果子 RDD 的分区到父 RDD 的分区是窄依赖,就可以实施经典的 fusion 优化,把两个 fork/join 合并为一个。如果连续的变换操作序列都是窄依赖,就可以把很多个 fork/join 合并为一个。这种合并不但减少了大量的全局路障,而且无须保存很多中间结果 RDD,这样可以极大地提升性能。在 Spark 中,这个合并过程就被称为“流水线(Pipeline)优化”。
可以看出,只有窄依赖可以实现流水线优化。对于窄依赖的 RDD,可以以流水线的方式计算所有父分区,不会造成网络之间的数据混合。对于宽依赖的 RDD,则通常伴随着 Shuffle 操作,即首先需要计算好所有父分区数据,然后在节点之间进行 Shuffle,这个过程会涉及不同任务之间的等待,无法以流水线方式处理。因此,RDD 之间的依赖关系就成为把 DAG 划分成不同阶段的依据。
Spark 通过分析各个 RDD 之间的依赖关系生成 DAG,再通过分析各个 RDD 中的分区之间的依赖关系来决定如何划分阶段。具体划分方法是:在 DAG 中进行反向解析,遇到宽依赖就断开(因为宽依赖涉及 Shuffle 操作,无法以流水线方式处理),遇到窄依赖就把当前的 RDD 加入当前的阶段中(因为窄依赖不会涉及 Shuffle 操作,可以以流水线方式处理)。具体的阶段划分算法请参见 AMP 实验室发表的论文《Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing》。如图 10-13 所示,假设从 HDFS 中读入数据生成 3 个不同的 RDD(即 A、C 和 E),通过一系列转换操作后将计算结果保存到 HDFS。对 DAG 进行解析时,在依赖图中进行反向解析,由于从 RDD A 到 RDD B 的转换以及从 RDD B 和 F 到 RDD G 的转换,都属于宽依赖,因此,在宽依赖处断开后可以得到 3 个阶段,即阶段 1、阶段 2 和阶段 3。可以看出,在阶段 2 中,从 map 到 union 都是窄依赖,这两步操作可以形成一个流水线操作。比如分区 7 通过 map 操作生成的分区 9,可以不用等待分区 8 到分区 10 这个转换操作的计算结束,而是继续进行 union 操作,转换得到分区 13,这样流水线执行可大大提高计算的效率。
RDD 运行过程
通过上述对 RDD 概念、依赖关系和阶段划分的介绍,结合之前介绍的 Spark 运行基本流程,下面总结一下 RDD 在 Spark 中的运行过程,如图 10-14 所示。

- 创建 RDD 对象。
- SparkContext 负责计算 RDD 之间的依赖关系,构建 DAG。
- DAGScheduler 负责把 DAG 分解成多个阶段,每个阶段中包含了多个任务,每个任务会被任务调度器分发给各个工作节点上的 Executor 去执行。
10.4 Spark的部署和应用方式 P208
Spark 的部署方式 目前,Spark 支持 5 种不同类型的部署方式,包括 Local、Standalone、Spark on Mesos、Spark on YARN 和 Spark on Kubernetes。其中,Local 模式属于单机部署模式,其他属于分布式部署模式。下面我们对分布式部署模式进行简单介绍。
1.Standalone 模式
与 MapReduce 1.0 框架类似,Spark 框架自带了完整的资源调度管理服务,可以独立部署到一个集群中,而不需要依赖其他系统来为其提供资源管理调度服务。在架构的设计上,Spark 与MapReduce 1.0 完全一致,都是由一个 Master 和若干个 Slave 节点构成,并且以槽作为资源分配单位。不同的是,Spark 中的槽不再像 MapReduce 1.0 那样分为 Map 槽和 Reduce 槽,而是只设计了统一的一种槽提供给各种任务来使用。
2.Spark on Mesos 模式
Mesos 是一种资源调度管理框架,可以为运行在它上面的 Spark 提供服务。由于 Mesos 和 Spark存在一定的血缘关系,因此 Spark 这个框架在进行设计开发的时候就充分考虑到了对 Mesos 的充分支持。相对而言,Spark 运行在 Mesos 上,要比运行在 YARN 上更加灵活、自然。目前,Spark官方推荐采用这种模式,所以许多公司在实际应用中也采用这种模式。
3.Spark on YARN 模式
Spark 可运行于 YARN 之上,与 Hadoop 进行统一部署,即“Spark on YARN”,其架构如图10-15 所示,资源管理和调度依赖于 YARN,分布式存储则依赖于 HDFS。
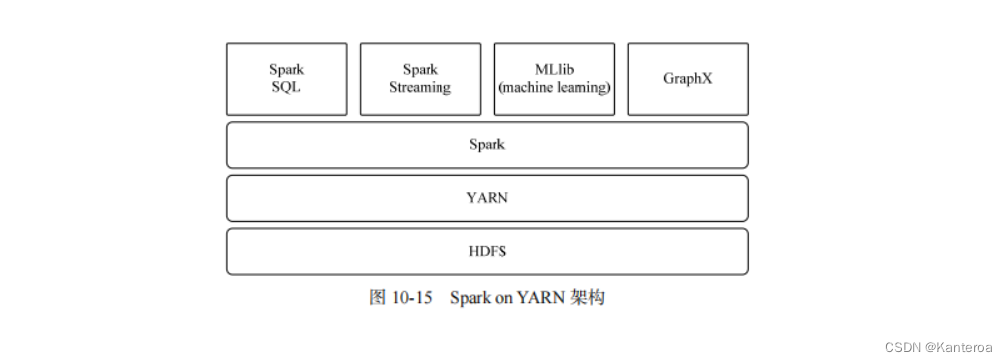
4.Spark on Kubernetes 模式
Kubernetes 作为一个广受欢迎的开源容器协调系统,是 Google 于 2014 年酝酿的项目。Kubernetes 自 2014 年以来热度一路飙升,短短几年时间就已超越了大数据分析领域的明星产品Hadoop。Spark 从 2.3.0 版本引入了对 Kubernetes 的原生支持,可以将编写好的数据处理程序直接通过 spark-submit 提交到 Kubernetes 集群。
10.5 Spark编程实践※
本节介绍 Spark RDD 的基本操作,以及如何编译、打包、运行 Spark 应用程序。更多上机操作实践细节内容,可以参见本书官网(http://dblab.xmu.edu.cn/post/bigdata3/)的“教材配套大数据软件安装和编程实践指南”。在进行下面的编程实践之前,请参照“教材配套大数据软件安装和编程实践指南”或者其他网络教程完成 Spark 的安装。这里采用的 Spark 版本为 2.4.0。
启动 Spark Shell
Spark 包含多种运行模式,可使用单机模式,也可以使用伪分布式、完全分布式模式。简单起见,这里使用单机模式运行 Spark。需要强调的是,如果需要使用 HDFS 中的文件,则在使用Spark 前需要启动 Hadoop。
Spark Shell 提供了简单的方式来学习 Spark API,且能以实时、交互的方式来分析数据。Spark Shell 支持 Scala 和 Python,这里选择使用 Scala 进行编程实践。
执行如下命令启动 Spark Shell:
$ ./bin/spark-shell
启动 Spark Shell 成功后,在输出信息的末尾可以看到“scala >”的命令提示符,如图 10-19所示。
Spark RDD 基本操作
Spark 的主要操作对象是 RDD,RDD 可以通过多种方式灵活创建,即可通过导入外部数据源建立(如位于本地或 HDFS 中的数据文件),也可从其他的 RDD 转化而来。在 Spark 程序中必须创建一个 SparkContext 对象,该对象是 Spark 程序的入口,负责创建RDD、启动任务等。在启动 Spark Shell 后,SparkContext 对象会被自动创建,可以通过变量 sc进行访问。作为示例,这里选择以 Spark 安装目录中的“README.md”文件作为数据源新建一个 RDD,代码如下(后续出现的 Spark 代码中,“scala >”表示一行代码的开始,与代码位于同一行的注释内容表示该代码的说明,代码下面的注释内容表示交互式输出结果):
scala > val textFile = sc.textFile("file:///usr/local/spark/README.md") // 通过 file:前缀指定读取本地文件
Spark RDD 支持两种类型的操作。
- 行动(Action):在数据集上进行运算,返回计算值。
- 转换(Transformation):基于现有的数据集创建一个新的数据集。Spark 提供了非常丰富的 API,表 10-2 和表 10-3 仅列出了几个常用的 Action API 和Transformation API,更详细的 API 和说明可查阅官方文档。
| Action API | 说明 |
|---|---|
| count() | 返回数据集中的元素个数 |
| collect() | 以数组的形式返回数据集中的所有元素 |
| first() | 返回数据集中的第一个元素 |
| take(n) | 以数组的形式返回数据集中的前 n 个元素 |
| reduce(func) | 通过函数 func (输入两个参数并返回一个值)聚合数据集中的元素 |
| foreach(func) | 将数据集中的每个元素传递到函数 func 中运行 |
| Transformation API | 说明 |
|---|---|
| filter(func) | 筛选出满足函数 func 的元素,并返回一个新的数据集 |
| map(func) | 将每个元素传递到函数 func 中,并将结果返回为一个新的数据集 |
| flatMap(func) | 与map0相似,但每个输入元素都可以映射到零个或多个输出结果 |
| groupByKey() | 应用于 < < <K,V > > >键值对的数据集时,返回一个新的 < < <K,TeraBle < < <V > > >> >>形式的数据集 |
| reduceByKey(func) | 应用于 < < <K,V > > >键值对的数据集时,返回一个新的 < < <K,V > > >形式的数据集,其中的每个值是将每个 key 传递到函数 func 中进行聚合的结果 |
比如在下面的实例中,使用 count()这个 Action API 就可以统计出一个文本文件的行数,命令如下(输出结果“Long=95”表示该文件共有 95 行内容):
Scala > textFile.count()
// Long = 95
再比如在下面的实例中,使用 filter()这个 Transformation API 就可以筛选出只包含“Spark”的行,命令如下(第一条命令会返回一个新的 RDD,因此不影响之前 RDD 的内容;输出结果“Long=17”表示该文件中共有 17 行内容包含“Spark”):
scala > val linesWithSpark = textFile.filter(line => line.contains("Spark"))
scala > linesWithSpark.count()
// Long = 17
在上面计算过程中,中间输出结果采用 linesWithSpark 变量进行保存,然后使用 count()计算出行数。假设这里只需要得到包含“Spark”的行数,而不需要了解每行的具体内容,那么使用linesWithSpark 变量存储筛选后的文本数据就是多余的,因为这部分数据在计算得到行数后就不再使用了。实际上,借助于强大的链式操作(即在同一条代码中同时使用多个 API),Spark 可连续进行运算,一个操作的输出直接作为另一个操作的输入,不需要采用临时变量存储中间结果,这样不仅可以使 Spark 代码更加简洁,也优化了计算过程。如上述两条代码可合并为如下一行代码:
scala > val linesCountWithSpark = textFile.filter(line => line.contains("Spark")). count()
// Long = 17
从上面代码可以看出,Spark 基于整个操作链,仅储存、计算所需的数据,提升了运行效率。Spark 属于 MapReduce 计算模型,因此也可以实现 MapReduce 的计算流程,如实现单词统计。首先使用 flatMap()将每一行的文本内容通过空格进行单词划分;然后使用 map()将单词映射为(K,V)的键值对,其中 K 为单词,V 为 1;最后使用 reduceByKey()将相同单词的计数进行相加,最终得到该单词总的出现次数。具体实现命令如下:
scala > val wordCounts = textFile.flatMap(line => line.split(" ")).map(word => (word, 1)).reduceByKey((a, b) => a + b)
scala > wordCounts.collect() // 输出单词统计结果
// Array[(String, Int)] = Array((package,1), (For,2), (Programs,1), (processing,1), (Because,1), (The,1)...)
在上面的代码中,flatMap()、map()和 reduceByKey()都属于“转换”操作。由于 Spark 采用了惰性机制,这些转换操作只是记录了 RDD 之间的依赖关系,并不会真正计算出结果。最后,运行 collect(),它属于“行动”类型的操作,这时才会执行真正的计算,Spark 会把计算打散成多个任务分发到不同的机器上并行执行。
习题
单选题
-
下列关于Spark的描述,错误的是哪一项?(D)
A、Spark最初由美国加州伯克利大学(UCBerkeley)的AMP实验室于2009年开发
B、Spark在2014年打破了Hadoop保持的基准排序纪录.
C、Spark用十分之一的计算资源,获得了比Hadoop快3倍的速度
D、Spark运行模式单一
-
下列关于Spark的描述,错误的是哪一项?(C)
A、使用DAG执行引擎以支持循环数据流与内存计算析
B、可运行于独立的集群模式中,可运行于Hadoop中,也可运行于Amazon EC2等云环境中
C、支持使用Scala、Java、Python和R语言进行编程,但是不可以通过Spark Shell进行交互式编程
D、可运行于独立的集群模式中,可运行于Amazon EC2等云环境中
-
下列关于Scala特性的描述,错误的是哪一项?(A)
A、Scala语法复杂,但是能提供优雅的API计算
B、Scala具备强大的并发性,支持函数式编程,可以更好地支持分布式系统
C、Scala兼容Java,运行速度快,且能融合到Hadoop生态圈中
D、Scala是Spark的主要编程语言
-
下列说法哪项有误?(C)
A、相对于Spark来说,使用Hadoop进行迭代计算非常耗资源
B、Spark将数据载入内存后,之后的迭代计算都可以直接使用内存中的中间结果作运算,避免了从磁盘中频繁读取数据
C、Hadoop的设计遵循“一个软件栈满足不同应用场景”的理念
D、Spark可以部署在资源管理器YARN之上,提供一站式的大数据解决方案
-
在Spark生态系统组件的应用场景中,下列哪项说法是错误的?(C)
A、Spark应用在复杂的批量数据处理
B、Spark SQL是基于历史数据的交互式查询
C、Spark Streaming是基于历史数据的数据挖掘
D、GraphX是图结构数据的处理
-
下列说法错误的是?(A)
A、RDD(Resillient Distributed Dataset)是运行在工作节点(WorkerNode)的一个进程,负责运行Task
B、Application是用户编写的Spark应用程序
C、一个Job包含多个RDD及作用于相应RDD上的各种操作
D、Directed Acyclic Graph反映RDD之间的依赖关系
-
下列关于RDD说法,描述有误的是?(C)
A、一个RDD就是一个分布式对象集合,本质上是一个只读的分区记录集合
B、每个RDD可分成多个分区,每个分区就是一个数据集片段
C、RDD是可以直接修改的
D、RDD提供了一种高度受限的共享内存模型
-
Spark生态系统组件Spark Streaming的应用场景是?(D)
A、基于历史数据的数据挖掘
B、图结构数据的处理
C、基于历史数据的交互式查询
D、基于实时数据流的数据处理
-
Spark生态系统组件MLlib的应用场景是?(D)
A、图结构数据的处理
B、基于历史数据的交互式查询
C、复杂的批量数据处理
D、基于历史数据的数据挖掘
多选题
-
Spark具有以下哪几个主要特点?(ABC)
A、运行速度快
B、容易使用
C、通用性
D、运行模式单一
-
Scala具有以下哪几个主要特点?(ABCD)
A、Scala的优势是提供了REPL(Read-Eval-Print Loop,交互式解释器),提高程序开发效率
B、Scala兼容Java,运行速度快,且能融合到Hadoop生态圈中
C、Scala具备强大的并发性,支持函数式编程
D、Scala可以更好地支持分布式系统
-
下列哪些选项属于Hadoop的缺点?(ABCD)
A、表达能力有限
B、磁盘IO开销大
C、延迟高
D、在前一个任务执行完成之前,其他任务就无法开始,难以胜任复杂、多阶段的计算任务
-
下列说法中,哪些选项描述正确?(AB)
A、Spark在借鉴Hadoop MapReduce优点的同时,很好地解决了MapReduce所面临的问题
B、Spark的计算模式也属于MapReduce,但不局限于Map和Reduce操作
C、Hadoop MapReduce编程模型比Spark更灵活
D、Hadoop MapReduce提供了内存计算,可将中间结果放到内存中,对于迭代运算效率更高
-
在实际应用中,大数据处理主要包括以下哪三个类型?(ABD)
A、复杂的批量数据处理:通常时间跨度在数十分钟到数小时之间
B、基于历史数据的交互式查询:通常时间跨度在数十秒到数分钟之间
C、基于实时数据流的数据处理:通常时间跨度在数十秒到数分钟之间
D、基于实时数据流的数据处理:通常时间跨度在数百毫秒到数秒之间
-
在实际应用中,当采用多种计算架构来满足不同应用场景需求时,大数据处理难免会带来哪些问题?(ABCD)
A、不同场景之间输入输出数据无法做到无缝共享,通常需要进行数据格式的转换
B、不同的软件需要不同的开发和维护团队
C、需要较高的使用成本
D、比较难以对同一个集群中的各个系统进行统一的资源协调和分配
-
与Hadoop MapReduce计算框架相比,Spark所采用的Executor具有哪些优点?(AB)
A、利用多线程来执行具体的任务,减少任务的启动开销
B、Executor中有一个BlockManager存储模块,有效减少IO开销
C、提供了一种高度受限的共享内存模型
D、不同场景之间输入输出数据能做到无缝共享
-
Spark运行架构具有以下哪些特点?(ABCD)
A、每个Application都有自己专属的Executor进程,并且该进程在Application运行期间一直驻留
B、Executor进程以多线程的方式运行Task
C、Spark运行过程与资源管理器无关,只要能够获取Executor进程并保持通信即可
D、Task采用了数据本地性和推测执行等优化机制
-
Spark采用RDD以后能够实现高效计算的原因主要在于?(ABC)
A、高效的容错性
B、中间结果持久化到内存,数据在内存中的多个
C、存放的数据可以是Java对象,避免了不必要的对象序列化和反序列化
D、采用数据复制实现容错
-
Spark支持哪三种不同类型的部署方式?(ABC)
A、Standalone(类似于MapReduce1.0,slot为资源分配单位)
B、Spark on Mesos(和Spark有血缘关系,更好支持Mesos)
C、Spark on YARN
D、Spark on HDFS
简答题
- 试述数据可视化的概念。
数据可视化是指将大型数据集中的数据以图形图像形式表示,并利用数据分析和开发工具发现其中未知信息的处理过程。数据可视化技术的基本思想是将数据库中每一个数据项作为单个图元素表示,大量的数据集构成数据图像,同时将数据的各个属性值以多维数据的形式表示,可以从不同的维度观察数据,从而对数据进行更深入的观察和分析。
- 试述数据可视化的重要作用。.
①观测、跟踪数据。利用变化的数据生成实时变化的可视化图表,可以让人们一眼看出各种参数的动态变化过程,有效跟踪各种参数值。
②分析数据。利用可视化技术,实时呈现当前分析结果,引导用户参与分析过程,根据用户反馈信息执行后续分析操作,完成用户与分析算法的全程交互,实现数据分析算法与用户领域知识的完美结合。
③辅助理解数据。帮助普通用户更快、更准确地理解数据背后的定义。
④增强数据吸引力。枯燥的数据被制成具有强大视觉冲击力和说服力的图像,可以大大增强读者的阅读兴趣。
- 可视化工具主要包含哪些类型?各自的代表性产品有哪些?
主要包括入门级工具(Excel)、信息图表工具(Google Chart API、D3、Visual.ly、Raphael、Flot、Tableau、大数据魔镜)、地图工具(Modest Maps、Leaflet、PolyMaps、OpenLayers、Kartography、Google Fushion Tables、Quanum GIS)、时间线工具(Timetoast、Xtimeline、Timeslide、Dipity)和高级分析工具(Processing、NodeBox、R、Weka和Gephi)等。
- 请举出几个数据可视化的有趣案例。
① 全球黑客活动
安全供应商Norse打造了一张能够反映全球范围内黑客攻击频率的地图,它利用Norse的“蜜罐”攻击陷阱显示出所有实时渗透攻击活动。地图中的每一条线代表的都是一次攻击活动,借此可以了解每天、每一分钟甚至每一 秒世界 上发生了多少次恶意渗透。
② 世界国家健康 与财富之间的关系
“世界国家健康与财富之间的关系"利用可视化技术,把世界上200个国家,从1810年到2010年历时200年其各国国民的健康、财富变化数据(收集了1000 多万个数据)制作成三维动画进行了直观展示。
第十三章推荐系统
13.1 推荐系统
(1)推荐系统是什么、为什么产生、有什么用 P286-P287
什么是推荐系统
随着互联网的飞速发展,网络信息的快速膨胀让人们逐渐从信息匮乏的时代步入了信息过载的时代。借助于搜索引擎,用户可以从海量信息中查找自己所需的信息。但是,通过搜索引擎查找内容是以用户有明确的需求为前提的,用户需要将其需求转化为相关的关键词进行搜索。因此,当用户需求很明确时,搜索引擎的结果通常能够较好地满足用户需求。比如用户打算从网络上下载一首由筷子兄弟演唱的、名为《小苹果》的歌曲时,只要在百度音乐搜索中输入“小苹果”,就可以找到该歌曲的下载地址。然而,**当用户没有明确需求时,就无法向搜索引擎提交明确的搜索关键词。**这时,看似“神通广大”的搜索引擎也会变得无能为力,难以帮助用户对海量信息进行筛选。比如用户突然想听一首自己从未听过的最新的流行歌曲,面对当前众多的流行歌曲,用户可能显得茫然无措,不知道自己想听哪首歌曲,因此他可能不会告诉搜索引擎要搜索什么名字的歌曲,搜索引擎自然无法为其找到爱听的歌曲。
推荐系统是可以解决上述问题的一个非常有潜力的办法,**它通过分析用户的历史数据来了解用户的需求和兴趣,从而将用户感兴趣的信息、物品等主动推荐给用户。**现在让我们设想一个生活中可能遇到的场景:假设你今天想看电影,但不明确想看哪部电影,这时你打开在线电影网站,面对近百年来所拍摄的成千上万部电影,要从中挑选一部自己感兴趣的电影就不是一件容易的事情。我们经常会打开一部看起来不错的电影,看几分钟后无法提起兴趣就结束观看,然后继续寻找下一部电影,等终于找到一部自己爱看的电影时,可能已经有点筋疲力尽了,渴望放松的心情也会荡然无存。为解决挑选电影的问题,你可以向朋友、电影爱好者进行请教,让他们为你推荐电影。但是,这需要一定的时间成本,而且,由于每个人的喜好不同,他人推荐的电影不一定会令你满意。此时,你可能更想要的是一个针对你的自动化工具,它可以分析你的观影记录,了解你对电影的喜好,并从庞大的电影库中找到符合你兴趣的电影供你选择。这个你所期望的工具就是“推荐系统”。
**推荐系统是自动联系用户和物品的一种工具。**和搜索引擎相比,推荐系统通过研究用户的兴趣偏好,进行个性化计算,可发现用户的兴趣点,帮助用户从海量信息中去发掘自己潜在的需求。
13.2 协同过滤
(1)基于用户的协同过滤含义+英文缩写+公式理解+偏向社会化 P289
下面介绍基于用户的协同过滤的算法思想,以及如何实现算法的关键步骤—计算用户与用户之间的兴趣相似度。
1.算法思想
基于用户的协同过滤算法(简称 UserCF 算法)是推荐系统中最古老的算法。可以说,UserCF的诞生标志着推荐系统的诞生。该算法于 1992 年被提出,直到现在该算法仍然是推荐系统领域最著名的算法之一。
UserCF 算法符合人们对于“趣味相投”的认知,即兴趣相似的用户往往有相同的物品喜好。当目标用户需要个性化推荐时,可以先找到和目标用户有相似兴趣的用户群体,然后将这个用户群体喜欢的、而目标用户没有听说过的物品推荐给目标用户,这种方法就称为“基于用户的协同过滤算法”。
UserCF 算法的实现主要包括两个步骤。
-
找到和目标用户兴趣相似的用户集合。
-
找到该集合中的用户喜欢的、且目标用户没有听说过的物品推荐给目标用户。
假设有用户 a、b、c 和物品 A、B、C、D,其中用户 a、c 都喜欢物品 A 和物品 C,如图 15-4所示,因此认为这两个用户是相似用户,于是将用户 c 喜欢的物品 D(物品 D 是用户 a 还未接触过的)推荐给用户 a。
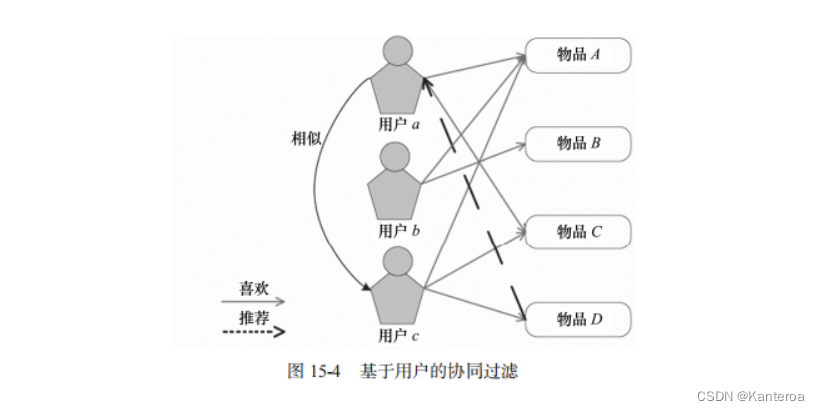
2. 计算用户相似度
实现 UserCF 算法的关键步骤是计算用户与用户之间的兴趣相似度。目前使用较多的相似度
算法如下。
- 泊松相关系数(Person Correlation Coefficient)。
- 余弦相似度(Cosine Similarity)。
- 调整余弦相似度(Adjusted Cosine Similarity)。
给定用户 u 和用户 v,令 N(u)表示用户 u 感兴趣的物品集合,令 N(v)为用户 v 感兴趣的物品集合,则使用余弦相似度计算用户相似度的公式如下。
W
u
v
=
∣
N
(
u
)
∩
N
(
v
)
∣
∣
∣
N
(
u
)
∣
∣
N
(
v
)
∣
W_{uv}=\frac{|N(u)\cap N(v)|}{|\sqrt{|N(u)||N(v)|}}
Wuv=∣∣N(u)∣∣N(v)∣∣N(u)∩N(v)∣
由于很多用户相互之间并没有对同样的物品产生过行为,因此其相似度公式的分子为 0,相似度也为 0。所以,在计算相似度
w
u
v
w_{uv}
wuv时,我们可以利用物品到用户的倒排表(每个物品所对应的、对该物品感兴趣的用户列表),仅对有对相同物品产生交互行为的用户进行计算。
图 15-5 展示了基于图 15-4 的数据建立物品到用户倒排表并计算用户相似度矩阵的过程。由图 15-5 可知,喜欢物品 C 的用户包括用户 a 和用户 c,因此将 W [ a ] [ c ] W[a][c] W[a][c]和 W [ c ] [ a ] W[c][a] W[c][a]都加 1,以此类推。对每个物品的用户列表进行计算之后,就可以得到用户相似度矩阵 W,矩阵元素 W [ u ] [ v ] W[u][v] W[u][v]为 w u v w_{uv} wuv的分子部分,将 W [ u ] [ v ] W[u][v] W[u][v]除以分母便可得到用户相似度 w u v w_{uv} wuv。
得到用户间的相似度后,再使用如下公式来度量用户 u 对物品 i 的感兴趣程度
P
u
i
P_{ui}
Pui。
P
u
i
=
∑
v
∈
S
(
u
,
K
)
∩
N
(
i
)
W
u
v
r
v
i
P_{ui}=\sum _{v\in S(u, K)\cap N(i)}W_{uv}r_{vi}
Pui=v∈S(u,K)∩N(i)∑Wuvrvi
式中,S(u,K)是和用户 u 兴趣最接近的 K 个用户的集合;N(i)是喜欢物品 i 的用户集合;W u v _{uv} uv 是用户 u 和用户 v 的相似度;r u i _{ui} ui是隐反馈信息,代表用户 v 对物品 i 的感兴趣程度,为简化计算可令 r u i = 1 r_{ui}=1 rui=1。
所有物品计算 P u i P_{ui} Pui后,可以再进行一定的处理,如降序处理,最后取前N个物品作为最终的推荐结果展示给用户u。
(2)基于物品的系统过滤含义+英文缩写+公式理解+偏向个性化 P291
下面介绍基于物品的协同过滤的算法思想,以及如何实现算法的关键步骤—计算物品相似度。
1.算法思想
基于物品的协同过滤算法(简称 ItemCF 算法)是目前业界应用最多的算法。无论是亚马逊还是 Netflix,其推荐系统的基础都是 ItemCF 算法。
ItemCF 算法是给目标用户推荐那些和他们之前喜欢的物品相似的物品。ItemCF 算法并不利用物品的内容属性计算物品之间的相似度,而主要通过分析用户的行为记录来计算物品之间的相似度。该算法基于的假设是:物品 A 和物品 B 具有很大的相似度是因为喜欢物品 A 的用户大多也喜欢物品 B。例如该算法会因为你购买过《数据挖掘导论》而给你推荐《机器学习实战》,因为买过《数据挖掘导论》的用户多数也购买了《机器学习实战》。
ItemCF 算法与 UserCF 算法类似,也分为两步。
-
计算物品之间的相似度。
-
根据物品的相似度和用户的历史行为,给用户生成推荐列表。
仍然以图 15-4 所示的数据为例,用户 a、c 都购买了物品 A 和物品 C,因此可以认为物品 A和物品 C 是相似的。因为用户 b 购买过物品 A 而没有购买过物品 C,所以推荐算法为用户 b 推荐物品 C,如图 15-6 所示。
计算物品相似度
与 UserCF 算法不同,用 ItemCF 算法计算物品相似度是通过建立用户到物品倒排表(每个用户喜欢的物品的列表)来计算的。
图 15-7 展示了基于图 15-4 的数据建立用户到物品倒排表并计算物品相似度矩阵的过程。如图 15-7(a)所示,对每个用户 u 喜欢的物品列表,都建立一个物品相似度矩阵 M u _{u} u,如用户 a 喜欢物品 A 和物品 C,则 M a [ A ] [ C ] M_{a}[A][C] Ma[A][C]和 M a [ C ] [ A ] M_{a}[C][A] Ma[C][A]都加 1,依此类推,得到每个用户的物品相似度矩阵如图 15-7(b)所示。将所有用户的物品相似度矩阵 Mu 相加得到最终的物品相似度矩阵 R,如图 15-7(c)所示,其中 R [ i ] [ j ] R[i][j] R[i][j]记录了同时喜欢物品 i 和物品 j 的用户数,将矩阵 R 归一化,便可得到物品间的余弦相似度矩阵 W。
得到物品相似度后,再使用如下公式来度量用户 u 对物品 j 的感兴趣程度 P u j P_{uj} Puj。
p
w
=
∑
i
∈
N
(
u
)
∖
Ω
(
f
,
K
)
W
i
j
t
u
i
p_{w}=\sum _{i\in N(u)\setminus \Omega (f, K)}W_{ij}t_{ui}
pw=i∈N(u)∖Ω(f,K)∑Wijtui
由式(15-3)可以看出,p
w
_{w}
w与UserCF算法中p
w
_{w}
w的定义基本一致,也是将计算得到的p
w
_{w}
w进行处理后,取前N个物品作为最终的推荐结果展示给用户u。
(3)两个协同过滤算法的对比 P292
UserCF 算法和 ItemCF 算法的对比
从上述介绍中可以看出,UserCF 算法和 ItemCF 算法的思想是相似的,计算过程也类似,最主要的区别在于:UserCF 算法推荐的是那些和目标用户有共同兴趣爱好的其他用户所喜欢的物品,ItemCF 算法则推荐那些和目标用户之前喜欢的物品类似的其他物品。因此,UserCF 算法的推荐更偏向于社会化,而 ItemCF 算法的推荐更偏向于个性化。
UserCF 算法适用于新闻推荐、微博话题推荐等应用场景,其推荐结果在新颖性方面有一定的优势。但是,随着用户数目的增大,计算用户相似度将越来越困难,其运算时间复杂度和空间复杂度的增长与用户数的增长近似于平方关系。而且,UserCF 算法的推荐结果相关性较弱,容易受大众影响而推荐热门物品,同时 UserCF 算法也很难对推荐结果做出解释。此外,新用户或低活跃用户会遇到“冷启动”的问题,即无法找到足够有效的相似用户来计算出合适的推荐结果。
ItemCF 算法则在电子商务、电影、图书等应用场景中广泛使用,并且可以利用用户的历史行为给推荐结果做出解释,让用户更信服推荐的效果。但是,ItemCF 算法倾向于推荐与用户已购买商品相似的商品,往往会出现多样性不足、推荐新颖度较低的问题。
事实上,在实际应用中,没有任何一种推荐算法能够做到适用于各种应用场景且都能取得良好效果,不同推荐算法各有千秋,分别有其适合的应用场景,也各有其局限。因此,实践中推荐系统常采用将不同的推荐算法进行有机结合的方式,这样做往往能显著提升推荐效果。
13.3 大数据在物流领域的应用 P306
智能物流是大数据在物流领域的典型应用。智能物流融合了大数据、物联网和云计算等新兴IT 技术,使物流系统能模仿人的智能,实现物流资源优化调度和有效配置,以及物流系统效率的提升。自从 IBM 在 2010 年提出智能物流概念以来,智能物流在全球范围内得到了快速发展。在我国,阿里巴巴联合多方力量共建“中国智能物流骨干网”,计划用 8~10 年时间建立一张能支撑日均 300 亿元(年度约 10 万亿元)网络零售额的智能物流骨干网络,支持数千万家新型企业成长发展,让全中国任何一个地区做到 24h 内送货必达。大数据技术是智能物流发挥其重要作用的基础和核心,物流行业在货物流转、车辆追踪、仓储等各个环节中都会产生海量的数据,分析这些物流大数据,将有助于我们深刻认识物流活动背后隐藏的规律,优化物流过程,提升物流效率。
习题
单选题
-
下列说法错误的是?(C)
A、UserCF算法推荐的是那些和目标用户有共同兴趣爱好的其他用户所喜欢的物品
B、ItemCF算法推荐的是那些和目标用户之前喜欢的物品类似的其他物品
C、UserCF算法的推荐更偏向个性化
D、UserCF随着用户数目的增大,用户相似度计算复杂度越来越高
-
下面关于UserCF算法和ItemCF算法的对比,哪个是错误的?(C)
A、UserCF算法的推荐更偏向社会化:适合应用于新闻推荐、微博话题推荐等应用场景,其推荐结果在新颖性方面有一定的优势
B、ItemCF算法的推荐更偏向于个性化
C、ItemCF随着用户数目的增大,用户相似度计算复杂度越来越高
D、UserCF推荐结果相关性较弱,难以对推荐结果作出解释,容易受大众影响而推荐热门物品
-
下列关于推荐系统的描述,哪一项是错误的?(D)
A、推荐系统是大数据在互联网领域的典型应用
B、推荐系统是自动联系用户和物品的一种工具
C、推荐系统可以创造全新的商业和经济模式,帮助实现长尾商品的销售
D、推荐系统分为基于物品的协同过滤和基于商家的协同过滤
-
下列哪一项不属于推荐算法?(A)
A、基于物品和商家的联合协同推荐
B、基于统计的推荐
C、专家推荐
D、基于内容的推荐
-
下列描述有误的是?(B)
A、专家推荐:人工推荐,由资深的专业人士来进行物品的筛选和推荐,需要较多的人力成本性
B、基于统计的推荐:通过机器学习的方法去描述内容的特征,并基于内容的特征来发现与之相似的内容
C、协同过滤推荐:应用最早和最为成功的推荐方法之一
D、混合推荐:结合多种推荐算法来提升推荐效果
-
下列哪一项不属于完整推荐系统的三个模块之一?(D)
A、用户建模模块
B、推荐对象建模模块
C、推荐算法模块
D、数据采集模块
-
下列关于协同过滤的说法,哪一项是错误的?(C)
A、协同过滤可分为基于用户的协同过滤和基于物品的协同过滤
B、UserCF算法符合人们对于“趣味相投”的认知,即兴趣相似的用户往往有相同的物品喜好
C、实现UserCF算法的关键步骤是计算物品与物品之间的相似度
D、基于物品的协同过滤算法(简称ItemCF算法)是目前业界应用最多的算法
-
下列哪个说法是错误的?(D)
A、无论是亚马逊还是Netflix,其推荐系统的基础都是ItemCF算法
B、ItemCF算法是给目标用户推荐那些和他们之前喜欢的物品相似的物品
C、ItemCF算法主要通过分析用户的行为记录来计算物品之间的相似度
D、实现UserCF算法的关键步骤是计算物品与物品之间的相似度
-
下列哪一项说法是错误的?(C)
A、UserCF算法推荐的是那些和目标用户有共同兴趣爱好的其他用户所喜欢的物品
B、ItemCF算法推荐的是那些和目标用户之前喜欢的物品类似的其他物品
C、ItemCF算法的推荐更偏向社会化,而UserCF算法的推荐更偏向于个性化
D、ItemCF算法倾向于推荐与用户已购买商品相似的商品,往往会出现多样性不足、推荐新颖度较低的问题
多选题
-
下列哪些属于大数据应用?(ABCD)
A、推荐系统:为用户推荐相关商品
B、物流:基于大数据和物联网技术的智能物流
C、智能交通:利用交通大数据,实现交通实时监控
D、汽车:无人驾驶汽车,实时采集车辆各种行驶数据和周围环境
-
下列关于推荐系统集群的描述,哪些是正确的?(ABC)
A、为了让用户从海量信息中高效地获得自己所需的信息,推荐系统应运而生
B、推荐系统是大数据在互联网领域的典型应用
C、推荐系统是自动联系用户和物品的一种工具
D、推荐系统是利用大数据调整线下门店布局、控制店内人流量
-
下列关于推荐长尾理论的描述,哪些是正确的?(ABCD)
A、推荐系统可以创造全新的商业和经济模式,帮助实现长尾商品的销售
B、“长尾”概念于2004年提出,用来描述以亚马逊为代表的电子商务网站的商业和经济模式
C、可以通过发掘长尾商品并推荐给感兴趣的用户来提高销售额
D、热门推荐的主要缺陷在于推荐的范围有限,所推荐的内容在一定时期内也相对固定。无法实现长尾商品的推荐
-
推荐系统的本质是建立用户与物品的联系,根据推荐算法的不同,推荐方法包括以下哪几类?(ABCD)
A、专家推荐:人工推荐,由资深的专业人士来进行物品的筛选和推荐,需要较多的人力成本
B、基于统计的推荐:基于统计信息的推荐(如热门推荐),易于实现,但对用户个性化偏好的描述能力较弱
C、基于内容的推荐:通过机器学习的方法去描述内容的特征,并基于内容的特征来发现与之相似的内容
D、混合推荐:结合多种推荐算法来提升推荐效果
-
一个完整的推荐系统通常包括以下哪三个模块?(ACD)
A、用户建模模块
B、数据采集模块
C、推荐对象建模模块
D、推荐算法模块
-
下列关于推荐系统的描述,哪些是正确的?(ABCD)
A、用户建模模块:对用户进行建模,根据用户行为数据和用户属性数据来分析用户的兴趣和需求
B、推荐对象建模模块:根据对象数据对推荐对象进行建模
C、推荐算法模块:基于用户特征和物品特征,采用推荐算法计算得到用户可能感兴趣的对象
D、推荐算法模块:根据推荐场景对推荐结果进行一定调整,将推荐结果最终展示给用户
-
协同过滤可分为哪几种过滤方式?(AB)
A、基于用户的协同过滤
B、基于物品的协同过滤
C、基于用户和物品的联合协同过滤
D、基于商家的协同过滤
-
关于基于用户的协同过滤,下列哪些说法是正确的?(ABCD)
A、基于用户的协同过滤算法(简称UserCF算法)在1992年被提出,是推荐系统中最古老的算法
B、UserCF算法符合人们对于“趣味相投”的认知
C、实现UserCF算法的关键步骤是计算用户与用户之间的兴趣相似度
D、UserCF算法符合兴趣相似的用户往往有相同的物品喜好
-
实现UserCF算法的关键步骤是计算用户与用户之间的兴趣相似度,下列哪些是属于计算相似度的算法?(ABC)
A、泊松相关系数
B、余弦相似度
C、调整余弦相似度
D、调整正弦相似度
-
下列关于协同过滤算法的描述,哪些是正确的?(ABCD)
A、基于物品的协同过滤算法(简称ItemCF算法)是目前业界应用最多的算法
B、ItemCF算法是给目标用户推荐那些和他们之前喜欢的物品相似的物品
C、ItemCF算法通过建立用户到物品倒排表(每个用户喜欢的物品的列表)来计算物品相似度
D、UserCF算法推荐的是那些和目标用户有共同兴趣爱好的其他用户所喜欢的物品
结语
祝大家逢考必过呀!