引言
本文将基于前一篇爬取的网易云音乐数据, 利用Python的
wordcloud、matplotlib等库, 对歌名数据进行深入的词云可视化分析. 我们将探索不同random_state对词云布局的影响, 并详细介绍如何将生成的词云图部署到GitHub Pages, 实现数据可视化的在线展示. 介绍了如何从原始数据出发, 生成超酷词云图, 并将其部署到 GitHub Pages 上.
词云预览
▶️ 点击预览词云交互 ◀️
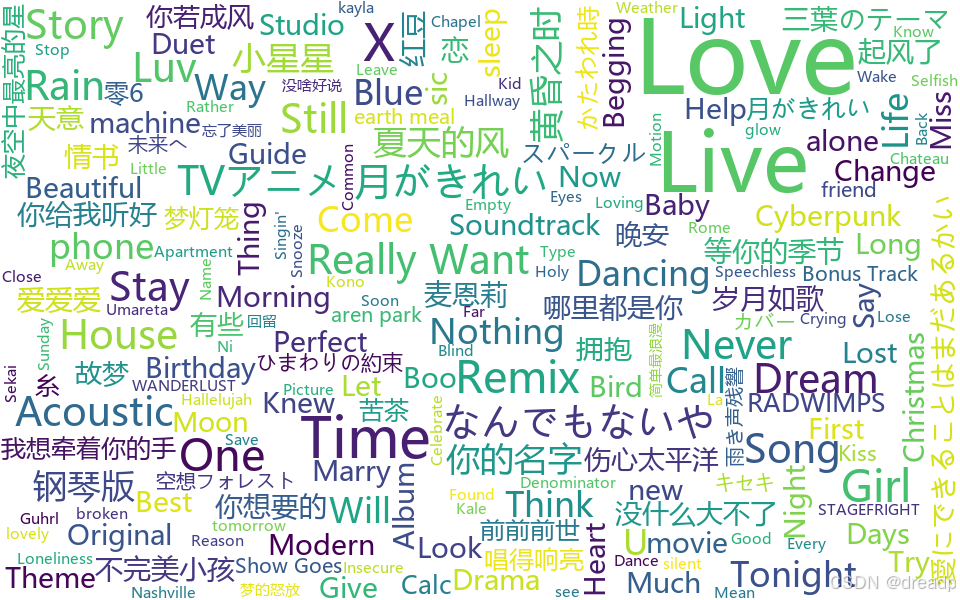

脚本地址:
代码结构和使用方法
文件结构
Gazer/
├── NeteaseCloudMusicGaze/
│ ├── data/
│ │ ├── processed/
│ │ ├── raw/
│ │ │ └── me_music_data.json
│ │ └── title_stopwords.txt
│ ├── output/
│ │ └── visualizations/
│ ├── src/
│ │ ├── __init__.py # 确保 src 是一个 Python 包
│ │ ├── utils.py # 包含工具函数
│ │ └── visualization.py # 主要的可视化逻辑
│ └── main.py # 程序的入口点, 用于调用 src 中的函数
└── ...
代码结构
-
utils.pyload_stopwords_from_file从指定文件路径加载停用词列表, 并将其转换为集合. 如果文件不存在, 则返回空集合, 并记录错误日志load_json_data加载爬取的 JSON 数据文件. 如果文件路径错误或 JSON 格式不正确, 将捕获异常并打印错误信息.load_and_extract_text从爬取的 JSON 文件加载数据并提取 title 字段(即歌曲名), 将这些值组成一个列表返回. 如果文件加载失败或数据提取失败, 会进行相应的错误处理.
-
visualization.pygenerate_wordcloud根据文本列表生成词云图, 并返回词频字典save_word_frequencies_to_csv将词频字典保存到 CSV 文件visualize_keywords调用以上两个函数, 并且可视化关键词数据, 生成词云图并保存词频到 CSV 文件
-
main.py
主脚本, 调用utils.py和visualization.py中的函数
使用方法
- 确保已经根据上一篇文档中的方法爬取了相应的数据, 确保 json 文件格式正确, 为一个字典列表.
- 安装依赖:
pip install wordcloud matplotlib jieba numpy, 或者克隆项目代码后pip install -r requirements.txt - 修改
main.py文件中的配置:- 填写
data_path爬取的 json 文件路径 - 填写
output_dir输出的词云图和词频 csv 文件路径
- 填写
代码分析
文件读取
之前爬取的 JSON 文件是一个包含多个字典的列表, 那么 load_json_data 函数如果成功加载, 就会返回一个列表, 这个列表里面包含的就是你的 JSON 文件中的那些字典.
以我的 me_music_data.json 为例, 文件内容是这样的(假设只有 2 条):
[
{
"title": "Common Denominator [Bonus Track]",
"singer": "Justin Bieber",
"album": "My World",
"comment": 3118
},
{
"title": "I Found a Reason",
"singer": "Cat Power",
"album": "V for Vendetta",
"comment": 841
}
]
那么 load_json_data 函数加载成功后, 返回的 data 变量就会是一个列表:
data = [
{
"title": "Common Denominator [Bonus Track]",
"singer": "Justin Bieber",
"album": "My World",
"comment": 3118
},
{
"title": "I Found a Reason",
"singer": "Cat Power",
"album": "V for Vendetta",
"comment": 841
}
]
然后你就可以通过索引访问列表中的每一个字典, 例如 data[0] 就是第一个字典, data[1] 就是第二个字典, 以此类推. 并且可以通过键值对的方式访问字典中的每一个值, 例如data[0]["title"]就是"Common Denominator [Bonus Track]".
停用词
为了后续更多的数据处理, 将 TITLE_STOPWORDS 写入文件, 并创建一个函数来读取它.
在 E:\Gazer\NeteaseCloudMusicGaze\data\ 目录下手动创建一个名为 title_stopwords.txt 的文本文件, 每个停用词占一行.
这里提供了一些适用于歌名的停用词示例. 为了获得更加精确的可视化效果, 建议你先运行一次 main.py, 然后根据生成的词频 CSV 文件(例如word_frequencies_me_music_data.csv), 观察高频出现的、但对你的分析目标没有实际意义的词语, 并将它们添加到 title_stopwords.txt 文件中. 之后再次运行main.py, 观察词云图的变化.
、
版
feat
翻自
Cover
EDIT
Instrumental
插曲
version
ver
Piano
Mix
丶
WorldCloud 类一些常用参数及其含义和说明
wordcloud = WordCloud(
width=960, # 词云图宽度(px), 默认为 400
height=600, # 词云图高度(px), 默认为 200
background_color=None, # 设置背景颜色为透明, 或自定义如"white", "#000000", 默认为 "black"
stopwords=stopwords,
font_path=DEFAULT_FONT_PATH,
max_words=200, # 词云图中显示的最大词数, 默认为 200
max_font_size=100, # 词云图中最大的字体大小, 可以根据你的数据量调整, 默认为None, 表示自动根据词频调整
random_state=42, # 随机数种子, 用于控制词云图的布局, 设置相同的值可以得到相同的布局
mode="RGBA" # 颜色模式, "RGB" 或 "RGBA", 默认为 "RGB"
# ... 还有很多其他参数, 具体可以参考官方文档
)
这些参数都不需要你全部设置, 只有在你需要自定义某些效果的时候设置就行了. 你可以根据自己的需求调整这些参数, 生成各种各样的词云图.
wordcloud.generate(text): 根据文本生成词云. 这一步会根据传入的文本text, 统计词频, 应用停用词, 计算每个词的位置和大小, 最终生成词云图. 但是这个时候词云图还在内存里. 这里面的text就是所有歌名使用空格连接起来的一个超级长的字符串.wordcloud.to_file(output_path): 将生成的词云图保存到文件. 这一步将内存中的词云图渲染成图片, 并保存到指定的路径output_path.wordcloud.words_: 获取词云中每个词及其对应的归一化频率. 这是一个字典属性, 包含了生成词云图的词语及其频率信息, 后续save_word_frequencies_to_csv函数会使用这个字典属性.
简单来说, 这三行代码完成了“根据文本生成词云图”、“将词云图保存到文件”和“获取词频数据”这三个操作.
关于 random_state 随机种子
random_state 参数用于控制 wordcloud 库在生成词云图时涉及到的随机过程. 这些随机过程包括:
- 词语位置的随机扰动:为了避免词语重叠,
wordcloud会在一定范围内随机调整词语的位置. - 词语颜色的随机选择:如果没有指定每个词的颜色,
wordcloud会从一个颜色列表中随机选择颜色.
random_state 的作用就是控制这些随机过程的可重复性.
- 如果你设置了
random_state为一个固定的整数(例如 42, 或者其他任何整数), 那么每次运行代码时, 只要其他参数相同, 生成的词云图布局和颜色都会是一样的. 这对于调试代码、复现结果、保持结果一致性非常有用. - 如果你不设置
random_state, 或者将其设置为None, 那么每次运行代码时, 词云图的布局和颜色都会随机变化.
42 这个数字本身并没有什么特殊的含义, 你可以把它设置为任何你喜欢的整数. 大家经常用 42, 可能是因为道格拉斯·亚当斯在他的科幻小说《银河系漫游指南》中说 “The Answer to the Ultimate Question of Life, the Universe, and Everything is 42” .
想来点不一样的?
-
如果你想每次生成的词云图都不同, 就不要设置
random_state, 或者设置为None. -
如果你想尝试几种不同的布局, 但又希望每次运行代码时这几种布局能够固定下来, 你可以尝试几个不同的
random_state值, 例如1、2、3, 看看哪个布局你最喜欢, 然后就固定使用那个值.不同的 random_state 值的布局预览
生成这些预览图需要实际运行代码, 并设置不同的
random_state值.这里提供一段代码, 让你能够自己生成并比较不同
random_state值对应的词云图:from wordcloud import WordCloud, STOPWORDS import matplotlib.pyplot as plt import os from typing import List, Dict import csv from src.utils import load_json_data, load_and_extract_text, load_stopwords_from_file # 常量定义 (根据你的实际情况修改) WORD_HEADER = "Word" FREQUENCY_HEADER = "Frequency" DEFAULT_FONT_PATH = "msyh.ttc" TITLE_STOPWORDS_PATH = r"E:\Gazer\NeteaseCloudMusicGaze\data\title_stopwords.txt" DATA_PATH = r"E:\Gazer\NeteaseCloudMusicGaze\data\raw\me_music_data.json" OUTPUT_DIR = r"E:\Gazer\NeteaseCloudMusicGaze\output\visualizations" def generate_wordcloud(text_list: List[str], output_path: str, stopwords: set = None, random_state=None) -> Dict[str, float]: # 为了演示, 我把 random_state 提到这里了 """ 根据文本列表生成词云图, 并返回词频字典. (文档字符串的其他部分保持不变) """ text = " ".join(text_list) if stopwords is None: stopwords = set(STOPWORDS) title_stopwords = load_stopwords_from_file(TITLE_STOPWORDS_PATH) stopwords.update(title_stopwords) wordcloud = WordCloud( width=960, height=600, background_color=None, stopwords=stopwords, font_path=DEFAULT_FONT_PATH, max_words=200, max_font_size=100, random_state=random_state, # 使用传入的 random_state mode="RGBA" ) wordcloud.generate(text) wordcloud.to_file(output_path) return wordcloud.words # 其他函数 (save_word_frequencies_to_csv, visualize_keywords) 保持不变 if __name__ == "__main__": text_list = load_and_extract_text(DATA_PATH) os.makedirs(OUTPUT_DIR, exist_ok=True) # 尝试不同的 random_state 值 for i in range(1, 6): # 生成 5 个不同的 random_state 的结果 output_path = os.path.join(OUTPUT_DIR, f"wordcloud_random_state_{i}.png") generate_wordcloud(text_list, output_path, random_state=i) print(f"已生成词云图:{output_path}")这段代码会生成 5 个词云图, 分别对应
random_state值为 1、2、3、4、5 的情况. 你可以查看这些图片, 比较它们的布局差异.
visualize_keywords
这个函数是否重复了前两个函数的功能?
visualize_keywords 函数确实调用了 generate_wordcloud 和 save_word_frequencies_to_csv 这两个函数, 但它并不是简单地重复它们的功能, 而是**将它们组合起来, 形成一个更高级别的功能:从原始数据文件出发, 生成词云图和对应的词频 CSV 文件. **
可以这样理解:
generate_wordcloud负责根据文本生成词云图, 并返回词频数据.save_word_frequencies_to_csv负责将词频数据保存到 CSV 文件.visualize_keywords负责统筹安排, 它首先调用load_and_extract_text从数据文件提取文本, 然后调用generate_wordcloud生成词云图和获取词频, 最后调用save_word_frequencies_to_csv将词频保存到文件.
visualize_keywords 函数的作用是对数据进行可视化, 属于数据分析和数据可视化的高级功能, generate_wordcloud 和 save_word_frequencies_to_csv只是可视化过程中的步骤. 这样划分可以让代码的逻辑更清晰, 也更易于维护和扩展.
你可以把 generate_wordcloud 和 save_word_frequencies_to_csv 看作是工具函数, 它们分别负责生成词云和保存词频这两个独立的任务. 而 visualize_keywords 则是一个更高级别的函数, 它利用这两个工具函数来完成一个更复杂的目标.
使用 wordart 获取更美观的词云可视化, 并使用 github-pages 部署
wordart 提供了可高度自定义的词云图, 可以使用生成的 csv 导入词频自定义词云颜色, 形状等. 完成后, 点 SAVE, 然后点 Share 将当前作品设置为公开, 点 Webpage 复制 iframe 标签.
<iframe style="width:100%; height: 100%; border: none" src="https://cdn.wordart.com/iframe/qfwzk59spavk"></iframe>
将iframe 标签放进创建的 HTML 文件的 body 中, 使用 Cursor / VS Code 的 Live Server 打开. 按 Ctrl+S 保存 HTML 到本地, 命名为 index.html, 以便后续在 github-pages 中部署. 这时也会自动下载一个文件夹 index_files, 包含 qfwzk59spavk.html 和 wordart.min.js.下载. 此时可以直接用本地浏览器打开 index.html, 也可以获取鼠标和词云的交互功能.
这个方法完美地绕过了编码问题和 cdn.wordart.com 的访问限制, 直接将你在 Live Server 中看到的、已经渲染好的、包含交互式词云的页面完整地保存到了本地.
需要注意的地方:
- Live Server 的依赖: 这种方法依赖于 Live Server 能够正确地渲染你的网页. 如果你的网页在 Live Server 中显示有问题, 那么保存下来的网页也会有问题.
iframe的内容: 这种方法会将iframe中的内容 (也就是qfwzk59spavk.html) 也一起保存下来. 这通常是没问题的, 但如果iframe中的内容非常大, 或者你不希望将iframe的内容保存到本地, 那么你需要手动编辑保存后的 HTML 文件, 删除iframe相关的代码.- 如果你之后需要部署到 GitHub, 你仍需检查
index.html中的文件路径是否正确.
确保你已经为你的仓库开启 GitHub pages:
可以点击 开启 GitHub pages 教程 查看
开启后直接 push 到仓库同步, 等待 pages 部署完毕就能在 https://YourGithubUserName.github.io/RepositoryName/ 看到可交互式词云已经成功部署到网站.