★人工智能;大数据技术;AIGC;Turbo;DALL·E 3;多模态大模型;MLLM;LLM;Agent;Llama2;国产GPU芯片;GPU;CPU;高性能计算机;边缘计算;大模型显存占用;5G;深度学习;A100;H100;A800;H800;L40s;Intel;英伟达;算力
近年来,AIGC的技术取得了长足的进步,其中最为重要的技术之一是基于源代码的CPU调优,可以有效地提高人工智能模型的训练速度和效率,从而加快了人工智能的应用进程。同时,多GPU编程技术也在不断发展,大大提高人工智能模型的计算能力,更好地满足实际应用的需求。
本文将分析AIGC的最新进展,深入探讨以上话题,以及中国算力产业的瓶颈和趋势。
AIGC发展现状
AIGC产业在上半年经历“百模大战”和“百花齐放”的阶段后,现在正站在从“玩具”到“工具”的关键时期。大模型市场格局发生深刻变化,行业关注焦点也转向人工智能发展的“终极命题”——应用与商业化落地。AIGC研发范式的变革从根本上提高数据生产效率,降低使用者和开发者的门槛。
为提升模型的能力和效用,行业共同关注放大模型能力的有效途径,如微调、提示工程、搜索增强生成、AI Agent等技术手段。同时,开源模型迅速发展,产品向终端延伸,结合更多AI应用技术,推动应用场景多元化。然而,由于政策面向C端设置准入门槛,标准体系覆盖多个行业,强调数据、算法、模型和安全因素的重要性,因此“百模大战”回归理性,行业格局迈入整合阶段。
2023 Q3国内AIGC行业发生融资事件35起,涉及公司33家,投资机构51家。融资金额39.61亿人民币,种子轮~天使轮21家(占比63.64%)。通用大模型(6起)和工具平台(6起)两个细分赛道相对活跃。在应用层中,元宇宙/数字人(5起)和营销(5起)是融资事件最频繁的细分领域。有1家国内AIGC企业完成上市——第四范式(决策类人工智能公司)。2023年Q3国内AIGC行业发生1起并购事件——美团收购光年之外,融资额20.65亿元。
一、技术迭代
1、多模态大模型DALL·E 3带来产业冲击
多模态大语言模型(MLLM)是一种将文本、图像、音频和视频等多模态信息结合训练的模型,相比大语言模型(LLM)更符合人类感知世界的方式。通过多模态输入的支持,用户可以更灵活的方式与智能助手进行交互,并利用强大的大模型作为大脑来执行多模态任务。
DALL·E 3能够更好地捕捉语义描述的细微差异,实现提示词的完美遵循,并高效避免混淆详细请求中的元素,在画面呈现方面取得明显进步。同时,文生图模型与ChatGPT的结合,极大地减少了提示工程的约束。

2、长文本技术增强产品用户体验
LLM中的“上下文长度”是指大语言模型在生成预测时考虑的输入文本长度。更长的文本建模能力使模型能够观察到更长的上下文,避免重要信息的丢失。大模型的应用效果取决于两个核心指标:模型参数量和上下文长度。其中,上下文长度决定大模型的“内存”能力,长文本可以提供更多上下文和细节信息来辅助模型判断语义,减少歧义,提高归纳和推理的准确性。
目前,国内外对于文本长度的探索还没有达到“临界点”,长文本在未来的Agent和AI原生应用中仍然扮演着重要角色。Agent需要依靠历史信息进行规划和决策,而AI原生应用需要依靠上下文来保持连贯、个性化的用户体验。这也是为什么像月之暗面、OpenAI等大模型公司关注长文本技术的原因。
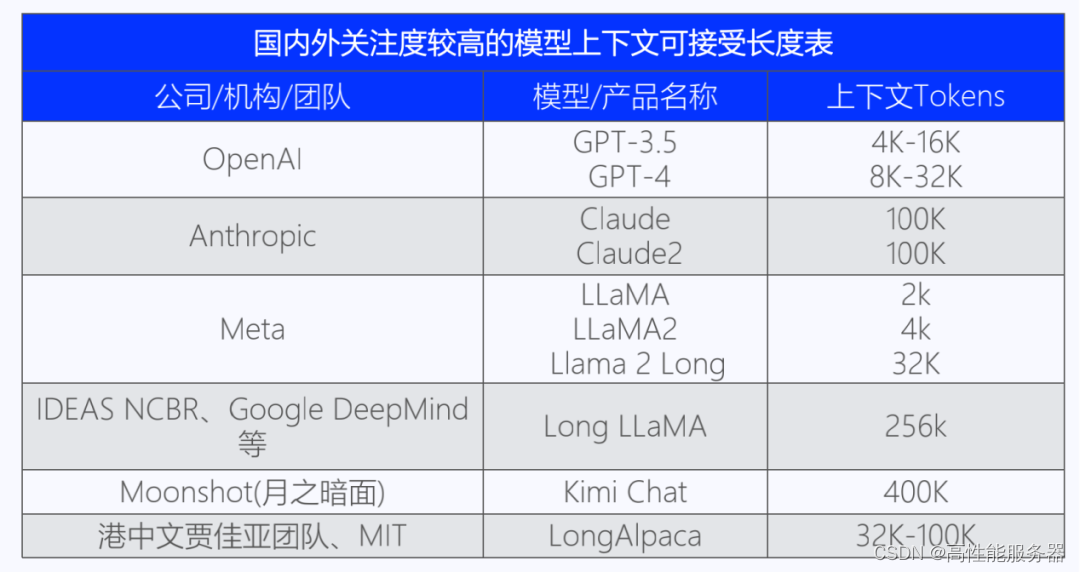
3、Llama2掀起大模型市场新格局
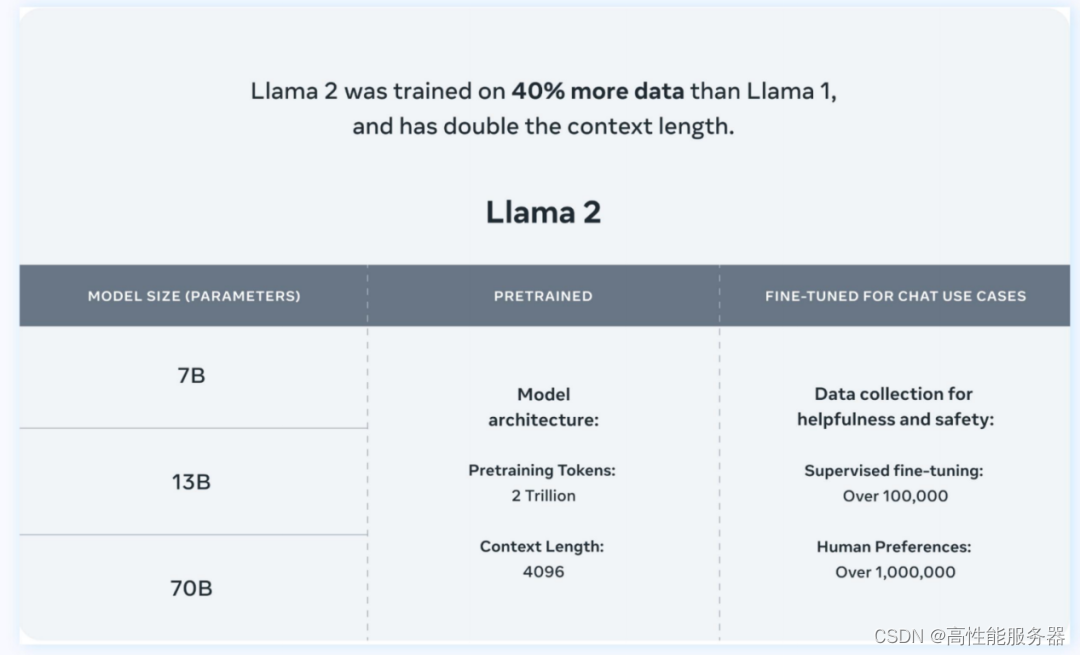
Llama是Meta发布的一款使用公开数据集训练的大型语言模型,因其与开源协议的兼容性和可复现性而受到AI社区欢迎。但受限于开源协议,LLaMA仅限学术研究使用,不能用于商业用途。
相比Llama 1,Llama 2预训练语料库增加40%,达到2万亿Tokens。9月,Llama2的token已达32,768个,并采用分组查询注意力机制,对文本语义的理解更深入。在MMLU和GSM8K测试中,Llama 2 70B的性能接近GPT-3.5。
4、AI Agent深入挖掘大模型潜力
Agent是指具有自主性、反应性、社会性、预动性、慎思性和认知性等智能特征的软件或硬件实体,等于大模型+记忆+主动规划+工具。AI Agent能够理解、规划、执行和自我调整,解决更复杂的问题。与LLM相比,AI Agent能够独立思考并调用工具逐步完成目标,区别于RPA的是其能够处理未知环境信息。
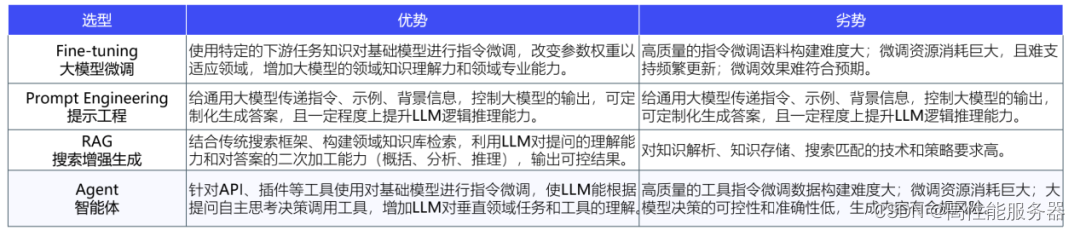
AI Agent与其他技术选型方案发展及优劣势比较
二、技术趋势
1、拥抱开源精神,国产模型的崛起已成燎原之势
在国家的大力支持和头部厂商的推动下,国产模型已成为大语言模型阵营中的重要力量。尽管起步较晚,且面临国外高端GPU芯片的围堵,但国产模型的崛起之势已成燎原。基础的互联网大厂积极推动开源生态体系的构建。
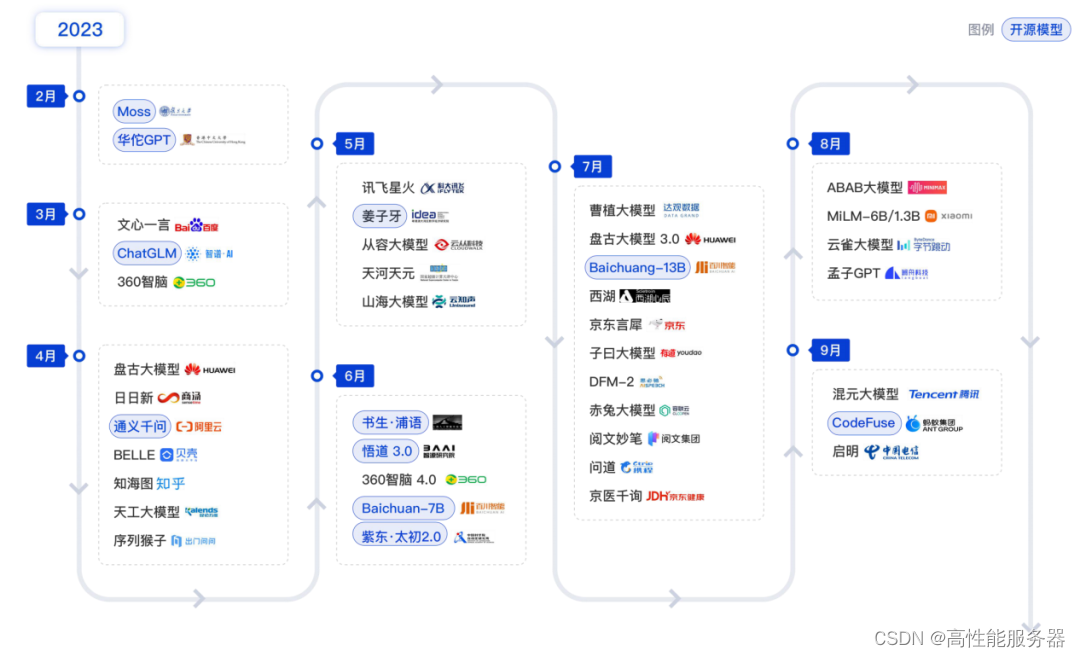
国内AI大模型发展进程 (截至2023年Q3)
2、大模型产品向终端延伸,推动应用场景多元化发展
大模型开源、多模态和Agent等技术将带来全新、个性化、人性化的交互体验。未来,大模型将部署在手机、PC、汽车、人形机器人等终端,解决云端AI在成本、能耗、性能、隐私、安全和个性化等方面的问题,并拓宽自动驾驶、智慧教育、智慧家居等场景的多元化应用。然而,如何在端侧实现轻量部署和软硬件深度融合仍是难点问题。

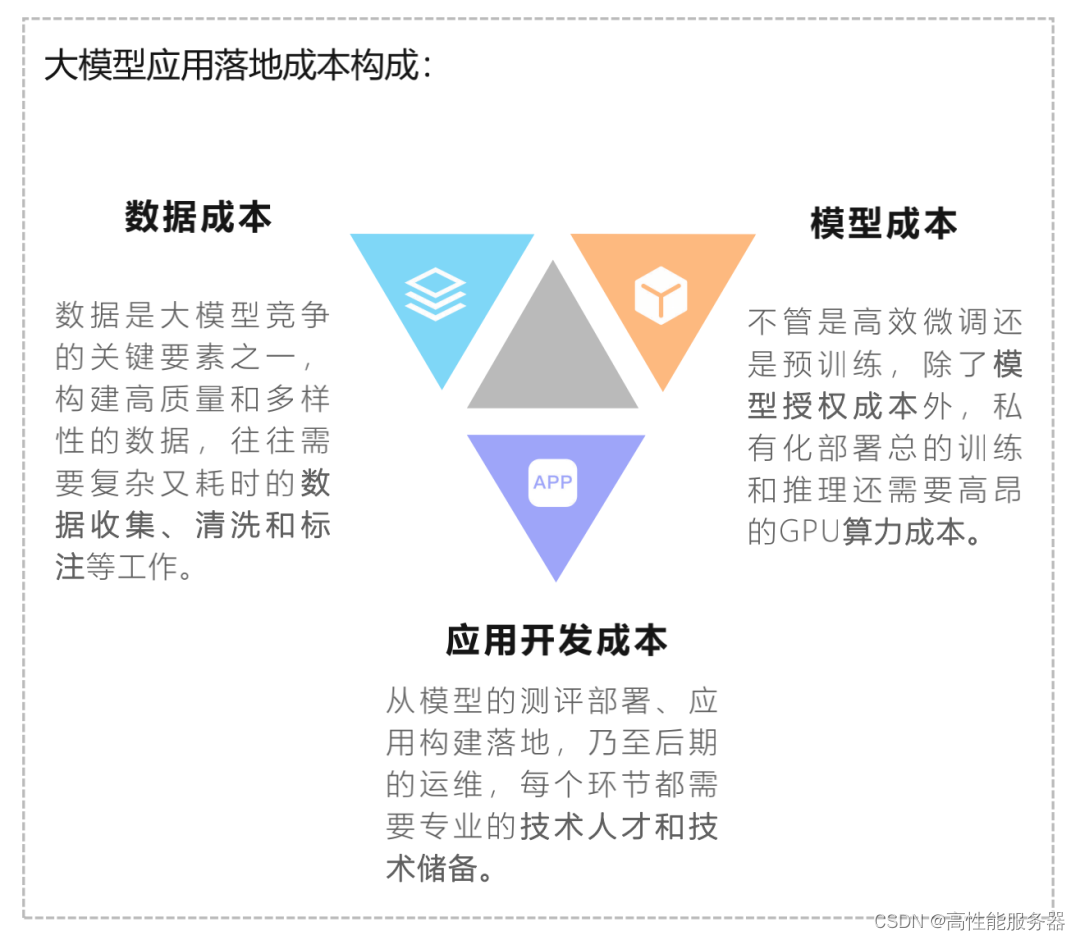
企业私有化部署大模型综合成本持续降低
大模型应用落地成本包括数据、模型和应用开发成本。模型成本包括授权成本和算力成本。随着Llama2推动国内模型的商用免费化,MaaS逐渐被市场接受,授权成本过高的壁垒正在消失。通过QLoRA微调和GPTQ量化,中小企业也可以使用千亿级模型,算力成本大幅降低。企业私有化部署综合成本持续降低,有利于大模型对B端市场的渗透。
三、如何确定大模型显存占用?
在部署大模型时,显存占用是个关键问题。大模型因其巨大规模,要么因显存溢出而无法运行,要么因模型过大导致推理速度慢。优化大模型的推理与优化小模型CNN的推理有所不同。下面将主要探讨如何计算大模型的显存占用。
以流行的LLama2大模型为例,主要有7B、13B、70B三个版本。B(Billion)是十亿,M(Million)是百万,所以LLama2这类大模型可称为十亿、百亿级大模型。
对于深度学习模型,精度通常有float32、float16、int8、int4等。后面的int8、int4等低精度主要用于推理加速。比如,一个float32会占用4个字节32个比特,往后就减半,如int8是1字节占用8比特,int4的占用空间会更加小。参数量和模型精度可以用来计算模型的显存占用。以LLama2-13B为例:
对于float32精度:13 * 10^9 * 4 / 1024^3 约等于 48.42G
对于float16精度:13 * 10^9 * 2 / 1024^3 约等于 24.21G
以此类推,计算LLama2-7B的显存占用。
对于float32精度:7 * 10^9 * 4 / 1024^3 约等于 26.08G;
对于float16精度显存减半:约等于 13G;
对于int8精度再减半:约等于6.5G;
对于int4精度再减半:约等于3.2G。
可见低比特量化在大模型部署显存管理中的重要性。上述推理显存占用只适用于模型前向推理,不适用于模型训练。训练过程中还会受梯度、优化器参数、bs等因素影响。一般经验来说,训练时的显存占用会是推理时的好多倍,甚至十几倍。上述推理显存占用是理论值,实际肯定会更多一些,因此需要预留一些余量。例如,实测LLama2-13B时,理论值约为48.21G,但实际需要大约52G的显存。当然,这种方法也适用于CNN模型的前向推理显存占用计算。
基于源代码的CPU调优
对于高性能应用,如云服务、科学计算和3A游戏等,硬件基础至关重要。忽视硬件因素可能导致性能瓶颈。标准算法和数据结构在某些场景下可能无法提供最佳性能。
一、CPU前端优化
随着“扁平化”数据结构的普及,链表逐渐被淘汰。传统链表每个节点动态分配内存,导致内存访问延迟和碎片化。这使得遍历链表比遍历数组更耗时。有些数据结构(如二叉树)有类似链表的天然结构,使用指针追踪实现可能更高效。另外,更高效的数据结构版本如boost::flat_map 和 boost::flat_set也存在。
特定问题的最优算法在特定场景中可能不是最好的选择。例如,二分搜索在排序数组中查找元素很高效,但分支预测错误可能导致其在大规模数据中表现不佳。因此,在处理小规模整型数组时,线性搜索可能更有效。总之,针对高性能应用,需要深入理解硬件和算法性能,并灵活选择和优化合适的算法和数据结构以适应不同场景。
“数据驱动”优化是一种重要的调优技术,基于对程序处理数据的深入理解。专注于数据的分布和在程序中的转化方式。其中一个典型的例子是将数组结构体(SOA)转换为结构体数组(AOS)。选择哪种布局取决于代码访问数据的方式。如果程序遍历数据结构并仅访问字段b,则SOA更有效,这主要是由于所有内存访问都是按顺序执行;如果程序遍历数据结构并对对象的所有字段(即a、b和c)进行大量操作,则AOS更佳,因为所有成员都可能保存在相同的缓存行中,减少缓存行读取,提高内存带宽利用率。要进行此类优化,需要了解程序将处理哪些数据和数据的分布情况,并相应地修改程序。

另一个重要的数据驱动优化方法是“小尺寸优化”,旨在为容器预先分配固定量的内存,以避免动态内存分配。该方法在LLVM基础设施中广泛应用,并可显著提升性能(如对于SmallVector,boost::static_vector也是基于相同概念实现)。现代CPU是非常复杂的设备,几乎不可能预测某段代码的运行方式。CPU指令的执行受制于众多因素,包括许多变化的组件。
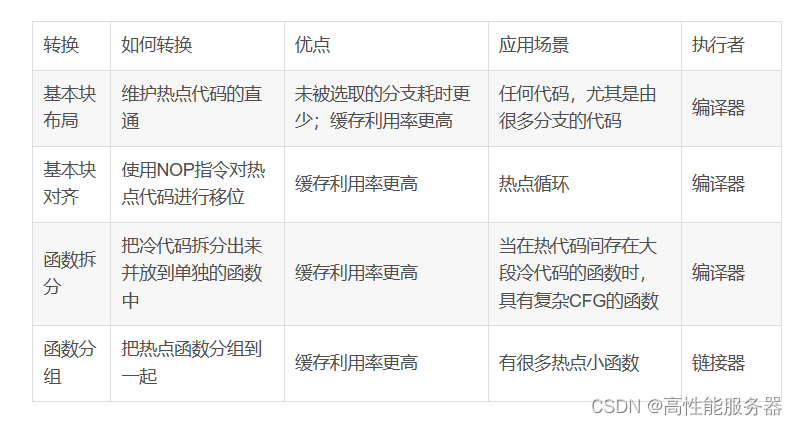
1、机器码布局
机器码布局指编译器将源代码转化为串行的字节列。由于编译器会影响到二进制文件的性能,因此在将源代码翻译为机器码时,会考虑到指令在内存中的放置偏移位置。
2、基本块
基本块是指具有单个入口和出口的指令序列,可以有多个前驱和后继,但在基本块中间没有任何指令可以跳出基本块。这种结构确保了基本块中的每条代码只会被执行一次,从而大大减少控制流图分析和转换的问题。
3、基本块布局
// hot path
if (cond)
coldFunc();
// hot path again
如果条件cond通常为真,那么选择默认布局,因为另一个布局会导致两次而不是一次跳转。coldFunc是错误处理函数,不太可能经常执行,因此选择保持热点代码间的直通,并将选取分支转化为未被选取分支。选择这种布局的原因如下:
1)CPU每个时钟可以执行2个未被选择的分支,但每2个时钟周期才能执行一个被选取的分支,因此未被选取的分支比被选取时耗时更少。
2)所有热点代码都是连续的,没有缓存行碎片化问题,因此可以更充分利用指令和微操作缓存。
3)每个被选取的跳转指令都意味着跳转之后的字节都是无效的,因此被选取的分支对于读取单元来说也更耗时。
4、基本块对齐
性能因指令在内存中的偏移而变化。若循环跨越多条缓存行,CPU前端可能会出现性能问题。因此,可以使用nop指令将循环提前,使其整个循环位于一条缓存行中。
LLVM使用-mllvm-align-all-blocks对齐基本块,但可能造成性能劣化。插入nop指令会增加程序开销,尤其在关键路径上。尽管nop指令不需要执行,但仍需从内存中读取、解码和执行,消耗前端数据结构和记账缓冲区空间。
为精确控制对齐,可使用ALIGN汇编指令。开发人员先生成汇编列表,然后插入ALIGN指令以满足特定实验场景的需求。
5、函数拆分
函数拆分是为了优化在热点路径具有复杂CFG和大量冷代码的函数。通过将冷代码移动到单独的函数中,可以避免在运行时加载不必要的代码,从而改善内存占用情况。
在优化后的代码中,将原来的函数拆分为两个函数,一个包含热点代码,另一个包含冷代码。通过将冷代码移动到单独的函数中,可以避免在运行时加载不必要的代码,从而改善内存占用情况。同时,使用__attribute__((noinline))禁止内联冷函数,以避免冷函数被内联到热点代码中,从而影响性能。
通过将热点代码和冷代码分离,可以更好地利用CPU前端数据结构(指令缓存和DSB),提高CPU的利用率。同时,将新函数放在.text段之外,可以避免在运行时加载不必要的代码,从而改善内存占用情况。
6、函数分组
热点函数可以聚集在一起,以提高CPU前端缓存的利用率,降低缓存行的读取需求。链接器负责规划程序中所有函数的排列布局,LLD链接器通过--symbol-ordering-file优化函数布局。HFSort工具能根据剖析数据自动生成分区排序文件。
7、基于剖析文件的编译优化
大多数编译器具备一组转换功能,可根据剖析数据来调整算法,这被称为PGO(Profile-Directed Optimization)。剖析数据生成有两种方式:代码插桩和基于采样的剖析。
1) 利用LLVM编译器通过-fprofile-instr-generate参数生成插桩代码,再使用-fprofile-inst-use参数利用剖析数据重新编译程序,生成PGO调优的二进制文件。
2)基于采样生成编译器所需的剖析数据,然后通过AutoFDO工具将linux perf生成的采样数据转换为GCC和LLVM编译器可理解的形式。但编译器会假设所有负载表现相同。
8、对ITLB的优化
内存中的虚地址到物理地址转换是前端优化的关键领域之一。通过将性能关键代码映射到大页上,可以减轻ITLB(指令翻译缓冲)的压力。这需要重新链接二进制文件,确保代码段在适当的页边界对齐。除使用大页,还可以采用其他技术来优化指令缓存性能,如重新排列函数以使热点函数更集中,使用LTO(链接时间优化)/IPO(内联函数优化)来减小热点区域的大小,使用PGO(基于剖析的编译优化)并避免过度内联。
二、CPU后端优化
在计算机处理过程中,前端完成取指和译码后,如果后端资源不足无法处理新的微操作,会导致前端无法继续交付微操作。例如,当数据缓存未命中或除法单元过载时,后端无法高效处理指令,从而造成前端停滞。
1、存储bound
当应用程序进行大量内存访问并花费较长时间等待内存访问完成时,被视为存储bound。这意味着需要优化存储访问情况,减少存储访问次数或升级存储子系统。
在TMA中,存储bound会统计CPU流水线由于按需加载或存储指令而阻塞的部分槽位。解决此类性能问题的第一步是定位导致高“存储bound”指标的访存操作,并识别具体的访存操作。然后开始进行调优。
1)缓存友好的数据类型
关于缓存友好算法和数据结构是性能关键要素之一,重点在于时间和空间局部性原则,目标是从缓存中高效地读取所需的数据。
-
按顺序访问数据
利用缓存空间局部性的最佳方法是顺序访问内存。标准实现二分搜索不会利用空间局部性,而解决这个问题的方法之一是Eytzinger布局存储数组元素。其思想是维护一个隐式二叉搜索树,并使用类似广度优先搜索的布局将二叉搜索树打包到一个数组中。
-
使用适当容器
几乎所有语言都提供各种现成的容器,理解它们底层存储机制和性能影响至关重要。在处理数据时,需要根据代码的具体情况来选择合适的数据存储方式。
-
打包数据
提高内存层次利用率的一种方式是使数据更加紧凑。打包数据的一个经典例子就是使用位存储,可以极大地减少来回传输的内存数量,同时节省缓存空间。然而,由于b和a与c共享一个机器字,编译器需要执行移位操作。在额外计算的开销比低效内存转移开销低的情况下,打包数据是值得的。
对于结构体或类中的字段布局,程序员可以通过重新排列来减少内存的使用,同时避免由编译器添加结构体填充。例如,如果有一个结构体包含一个布尔值和一个整数,最好将整数放在前面,因为这样可以使用整数的位来存储布尔值,从而节省内存。
-
对齐与填充
当变量存储在能被其大小整除的内存地址时,访问效率最高。对齐可能导致未使用的字节形成空位,降低内存带宽利用率。为避免边缘情况如缓存争用和伪共享,需要填充数据结构成员。例如,两个线程访问同一结构体的不同字段时,缓存一致性问题可能导致程序运行速度明显降低。通过填充方法,可确保结构体的不同字段位于不同的缓存行。当使用malloc进行动态分配时,要确保返回的内存地址满足平台目标的最小对齐要求。最重要的是,对于SIMD代码,当使用编译器向量化内建函数时,地址通常要被16、32或64整除。
-
动态内存分配
malloc的替代方案往往更快、更可扩展,更能有效地处理内存碎片问题。动态内存分配的一个挑战在于,多个线程可能同时尝试申请内存,导致效率降低。
为解决此问题,可以使用自定义分配器加速内存分配。这类分配器的优势在于开销较低,因为避免了每次内存分配都进行系统调用。同时,也具有高度灵活性,允许开发者根据操作系统的内存区域来实现自己的分配策略。一种策略是维护两个不同的分配器,各自负责热数据和冷数据的分配。将热数据放在一起可以共享高速缓存行,从而提高内存带宽利用率和空间局部性。同时,这种策略还可以提高TLB利用率,因为热数据占用的内存页更少。此外,自定义内存分配器还可以利用线程本地存储来实现每个线程的独立分配,从而消除线程间的同步问题。
-
针对存储器层次调优代码
某些应用程序的性能取决于特定层缓存的大小,最著名的例子是使用循环分块来改进矩阵乘法。
2)显式内存预取
当arr数组规模较大时,硬件预取可能无法识别访存模式并提前获取所需数据。为在计算j与arrp[j]请求之间的时间窗口内手动添加预取指令,可使用__builtin_prefetch,如下所示:
for (int i = 0; i < N; ++i) {
int j = calNextIndex();
__builtin_prefetch(arr + j, 0, 1);
// ...
doSomeExtensiveComputation();
// ...
x = arr[j];
}
为使预取有效,需提前插入预取指示,确保用于计算的值在计算时已加载到缓存中,同时避免过早插入预取提示以避免污染缓存。
显式内存预取不可移植,一个平台上的性能提升无法保证在另一个平台上也有相同效果。此外,显式预取指令会增加代码大小并增加CPU前端的压力。
3)针对DTLB优化
TLB分为ITLB和DTLB在L1,统一TLB在L2。L1 ITLB未命中时延很小,通常被乱序执行隐藏。统一TLB未命中会调用页遍历器,可能导致性能损失。
Linux默认页面大小为4KB,增大页大小可减少TLB条目和未命中次数。Intel 64和AMD 64支持2MB和1GB巨型页。使用大页的TLB更紧凑,遍历内核页表的代价减少。
在Linux系统中,应用程序使用大页的方法有显式大页和透明大页。使用libhugetlbfs库可动态分配大页内存。开发者可以通过以下方式控制对大页的访问:带MAP_HUGETLB参数使用mmap;挂载hugetlbfs文件系统中的文件使用mmap;对SHM_HUGETLB参数使用shmget。
2、计算bound
主要有两种性能瓶颈:硬件计算资源短缺和软件指令依赖关系。前者指执行单元过载或执行端口争用,发生在负载频繁执行大量繁重指令时;后者指程序数据流或指令流中的依赖关系限制了性能。下面讨论函数内联、向量化和循环优化等常见优化手段,旨在减少执行指令总量,提高性能。
1)函数内联
内联函数不仅可以消除函数调用的开销,还可以扩展编译器分析的范围,进行更多优化。但内联也可能增加编译后文件的大小和编译时间。编译器通常基于成本模型来决定是否内联函数,例如LLVM会考虑计算成本和调用次数。一般而言,小函数、单一调用点的函数更可能被内联,而大型函数和递归函数通常不会被内联。通过指针调用的函数可以用内联来代替直接调用。开发者可以使用特殊提示(如C++ 11的gnu::always_inline)来强制内联函数。另一种方法是剖析数据来识别潜在的内联对象,特别是分析函数的参数传递和返回频率。
2)循环优化
循环是程序中执行最频繁的代码段,因此大部分执行时间都在循环中消耗。循环的性能受到内存延迟、内存带宽或计算能力的限制。屋顶线模型是一个很好的基于硬件理论最大值的评估不同循环的方法,TMA分析是另一种处理这种瓶颈的方法。
-
低层优化
通过将循环中永远不会改变的表达式移到循环外,进行循环不变量外提,有助于提高算术强度性能。循环展开可以增加指令级并行,同时减少循环开销,但不建议开发者手动展开任何循环,因为编译器非常擅长并以最佳方式展开循环。借助乱序执行,处理器具有“内嵌的展开器”。循环强度折叠使用开销更小的指令代替开销高的指令,应用于所有循环变量的表达式和数组索引,编译器通过分析变量的值在循环迭代中的演变方式来实现。此外,如果循环内部有不变的判断条件,将其移到循环外,即进行循环判断外提,也有助于提高性能。
-
高层优化
此类优化策略会深度改变循环结构,并可能影响多个嵌套循环的整体性能。其根本目的是提升内存访问效率,解决内存带宽和时延的瓶颈问题。为实现这个目标,可以采用以下几种策略:通过交换嵌套循环的顺序,使得对多维数组元素的内存访问更加有序,从而消除带宽和时延的限制;将多维循环的执行范围合理拆分为多个循环块,使得每块数据的访问能够与CPU缓存的大小相适配,从而优化跨步幅访存的内存带宽和时延;对于可以合并的情况,将多个独立的循环合并在一起,以减少循环开销,同时改善内存访问的时间局部性。
但需要注意的是,循环合并并不总是能提高性能,有时候将循环拆分为多条路径、预过滤数据、对数据进行排序和重组等可能更有效。拆分循环有助于解决在大循环中发生的缓存高度争用问题,还可以减少寄存器压力,并且可以借助编译器对小循环进行进一步的单独优化。
3)发现循环优化的机会
编译优化报告显示转换失败,需要查看由应用程序剖析文件生成的汇编代码的热点部分。优化的策略应从简单的方案开始尝试,然后开发者需明确循环中的瓶颈,并基于硬件理论最大值评估性能。可以使用屋顶线模型来确定需要分析的瓶颈点,然后尝试各种变换。
4)使用循环优化框架
多面体框架可用于检查循环转换的合法性并自动转换循环。Polly是基于LLVM的高层循环和数据局部性优化器及优化基础设施,采用基于整数多面体的抽象数学表示来分析和优化程序的内存访问模式。要启用Polly,需要用户通过显式的编译器选项(-mllvm -polly)来启用,因为LLVM基础设施的标准流水线并未默认启用Polly。
3、向量化
使用SIMD指令可以显著提高未向量化代码的运行速度。性能分析的重点之一是确保关键代码能够被编译器正确向量化。如果编译器无法生成所需的汇编指令,可以使用编译器内建函数重写代码片段。使用编译器内建函数的代码与内联后的汇编代码类似,可读性较差。通常可以通过使用编译注解等方式来指导编译器进行自动向量化。编译器可以进行三种向量化操作:内循环自动向量化、外循环向量化和超字向量化。
1)编译器自动向量化
编译器自动向量化受到多种因素阻碍,包括编程语言的固有语义和处理器向量操作的限制。这些因素导致编译器难以有效地将循环转换为向量化的代码。然而,通过合法性检查、收益检查和转换三个阶段,可以逐步优化代码并提高程序的运行速度。在合法性检查阶段,评估循环向量化是否满足一系列条件,以确保生成的代码正确且有效。在收益检查阶段,比较不同的向量化因子并选择最优的方案,同时考虑代码的执行成本和效率。最后,在转换阶段,将通过插入向量化的保护代码来启用向量化执行,并优化代码以提高运行速度。
2)探索向量化的机会
分析程序中的热点循环,检查编译器已进行哪些优化,最简单方法是查看编译器向量化标记。当循环无法向量化时,编译器会给出失败原因。另一种方法是检查程序的汇编输出,分析剖析工具的输出更好。虽然查看汇编费时,但该技能回报高,因为可从汇编代码中发现次优代码、缺乏向量化、次优向量化因子、执行不必要计算等。
向量化标记能清晰解释问题及编译器不能向量化代码的原因。gcc 10.2可输出优化报告(使用参数-fopt-info启用)。开发者应意识到向量化代码的隐藏成本,尤其是AVX512可能导致大幅降频。对于循环次数小的循环,强制向量化程序使用小向量化因子或计数展开以减少循环处理的元素数量。
多GPU编程
CUDA提供多GPU编程的功能,包括在一个或多个进程中管理多设备,使用统一的虚拟寻址直接访问其他设备内存,GPUDirect,以及使用流和异步函数实现的多设备计算通信重叠。
一、从一个GPU到多GPU
在处理大规模数据集时,使用多GPU是提高计算效率和吞吐量的有效方式。多GPU系统通过不同的连接方式,如通过PCIe总线或在集群中的网络交换机连接,来实现高效的GPU间通信。在多GPU应用程序中,工作负载的分配和数据交换模式是关键因素。最基本的模式是各问题分区在独立GPU上运行,而更复杂的模式则需要考虑数据如何在设备间进行最优移动以避免数据复制到主机再复制到另一GPU。
1、在多GPU上执行
CUDA的cudaGetDeviceCount函数可确定系统内可用的CUDA设备数量。在利用CUDA与多GPU协作的应用程序中,必须显式指定目标GPU。使用cudaSetDevice(int id)函数可设置当前设备,该函数将具有特定ID的设备设置为当前设备,与其他设备无同步,因此开销较低。
如果在首个CUDA API调用前未显示调用cudaSetDevice函数,则当前设备将自动设置为设备0。选定当前设备后,所有CUDA运算将应用于此设备,包括:从主线程分配的设备内存、由CUDA运行时函数分配的主机内存、由主机线程创建的流或事件以及由主机线程启动的内核。
多GPU适用于以下场景:单节点的单线程、单节点的多线程、单节点的多进程以及多节点的多进程。以下代码展示如何在主机线程中执行内核和内存拷贝:
for (int i = 0; i < ngpus; i++) {
cudaSetDevice(i);
kernel<<<grid, block>>>(...);
cudaMemcpyAsync();
}
由于循环中的内核启动和数据传输是异步的,因此在每次操作后,控制将快速返回至主机线程。
2、点对点通信
在计算能力2.0或以上的设备上,64位应用程序执行的内核可以直接访问连接到同一PCIe根节点的GPU全局内存,但需使用CUDA点对点API进行设备间直接通信,该功能需要CUDA4.0或更高版本。点对点访问和传输是CUDA P2P API支持的两种模式,但当GPU连接到不同PCIe根节点时,将不允许直接点对点访问,此时可使用CUDA P2P API进行点对点传输,但数据传输会通过主机内存进行。
1)启用点对点访问
点对点访问允许GPU直接引用连接到同一PCIe根节点的其他GPU设备内存上的数据。使用cudaDeviceCanAccessPeer检查设备是否支持P2P,设备能直接访问对等设备全局内存则返回1,否则返回0。在两个设备间,必须使用cudaDeviceEnablePeerAccess显式启用点对点内存访问,该函数允许当前设备到peerDevice的点对点访问,授权的访问是单向的。点对点访问保持启用状态,直到被cudaDeviceDisablePeerAccess显式禁用。32位应用程序不支持点对点访问。
2)点对点内存复制
在两个设备之间启用对等访问后,可以使用cudaMemcpyPeerAsync函数异步复制设备上的数据。该函数将数据从源设备srcDev传输到目标设备dstDev。如果srcDev和dstDev连接在同一PCIe根节点上,数据传输将沿着PCIe的最短路径执行,无需通过主机内存中转。
3、多GPU间同步
多GPU应用程序中,流和事件与单一设备关联,典型工作流程包括:选择GPU集、为每个设备创建流和事件、分配设备资源、通过流启动任务、查询和等待任务完成并清空资源。只有与流关联的设备才能启动内核和记录事件。内存拷贝可在任何流中进行,与设备和当前状态无关。即使流或事件与当前设备不相关,也可以查询或同步它们。
二、多GPU间细分计算
1、在多设备上分配内存
在分配多个设备任务之前,首先需要确定系统中的可用GPU数量。通过cudaGetDeviceCount获取GPU数量并打印。
接下来,为每个设备声明所需的内存和流。使用cudaSetDevice为每个设备分配内存和流。
对于每个设备,分配一定大小的主机内存和设备内存,并创建流。为了在设备和主机之间进行异步数据传输,还需要分配锁页内存。
最后,使用循环为每个设备执行以下操作:
1)设置当前设备
2)分配设备内存:cudaMalloc
3)分配主机内存:cudaMallocHost
4)创建流:cudaStreamCreate
这样,就为每个设备分配了内存和流,准备好进行任务分配和数据传输。
2、单主机线程分配工作
// 在设备间分配操作之前,为每个设备初始化主机数组的状态
for (int i = 0; i < ngpus; i++)
{
cudaSetDevice(i);
initial(h_A[i], iSize);
initial(h_B[i], iSize);
}
// 在多个设备间分配数据和计算
for (int i = 0; i < ngpus; i++)
{
cudaSetDevice(i);
cudaMemcpyAsync(d_A[i], h_A[i], iBytes, cudaMemcpyHostToDevice, streams[i]);
cudaMemcpyAsync(d_B[i], h_B[i], iBytes, cudaMemcpyHostToDevice, streams[i]);
iKernel<<<grid, block, 0, streams[i]>>>(d_A[i], d_B[i], d_C[i], iSize);
cudaMemcpyAsync(gpuRef[i], d_C[i], iBytes, cudaMemcpyDeviceToHost, stream[i]);
}
cudaDeviceSynchronize();
这个循环遍历多个GPU,为设备异步地复制输入数组。然后在想要的流中操作iSize个数据元素以便启动内核。最后,设备发出异步拷贝命令,把结果从内核返回到主机。因为所有的元素都是异步的,所以控制会立即返回到主机线程。
三、多个GPU上的点对点通信
下面将测试两个GPU之间的单向内存复制;两个GPU之间的双向内存和内核中对等设备内存的访问3种情况;
1、实现点对点访问
首先,必须对所有设备启用双向点对点访问,代码如下;
// 启动双向点对点访问权限
inline void enableP2P(int ngpus)
{
for (int i = 0; i < ngpus; i++)
{
cudaSetDevice(i)
for (int j = 0; j < ngpus; j++)
{
if (i == j)
continue;
int peer_access_available = 0;
cudaDeviceCanAccessPeer(&peer_access_available, i, j);
if (peer_access_avilable)
{
cudaDeviceEnablePeerAccess(j, i);
printf(" > GP%d enbled direct access to GPU%d\n", i, j);
}
else
printf("(%d, %d)\n", i, j);
}
}
}
函数enbleP2P遍历所有设备对(i,j),如果支持点对点访问,则使用cudaDeviceEnablePeerAccess函数启用双向点对点访问。
2、点对点内存复制
不能启用点对点访问的最有可能的原因是它们没有连接到同一个PCIe根节点上。如果两个GPU之间不支持点对点访问,那么这两个设备之间的点对点内存复制将通过主机内存中转,从而降低了性能。
启用点对点访问后,下面的代码在两个设备间执行ping-pong同步内存复制,次数为100次。
// ping-pong undirectional gmem copy
cudaEventRecord(start, 0);
for (int i = 0; u < 100; i++)
{
if (i % 2 == 0)
cudaMemcpy(d_src[1], drc[0], iBytes, cudaMemcpyDeviceToHost);
else
cudaMemcpy(d_src[0], drc[1], iBytes, cudaMemcpyDeviceToHost);
}
请注意,在内存复制之前没有指定设备,因为跨设备的内存复制不需要显式地设定当前设备。如果在内存复制前指定了设备,也不会影响它的行为。
如需衡量设备之间数据传输的性能,需要把启动和停止事件记录在同一设备上,并将ping-pong内存复制包含在内。然后,用cudaEventElapsedTime计算两个事件之间消耗的时间。
// ping-pong undirectional gmem copy
cudaEventRecord(start, 0);
for (int i = 0; u < 100; i++)
{
if (i % 2 == 0)
cudaMemcpy(d_src[1], drc[0], iBytes, cudaMemcpyDeviceToHost);
else
cudaMemcpy(d_src[0], drc[1], iBytes, cudaMemcpyDeviceToHost);
}
cudaEventRecord(start, 0);
for (int i = 0; u < 100; i++)
{
...
}
cudaSetDevice(0);
cudaEventRecord(stop, 0);
cudaEventSynchronize(stop);
float elapsed_time_ms;
cudaEventElapsedTime(&elapsed_time_ms, start, stop);
elapsed_time_ms /= 100;
printf("Ping-pong unidirectional cudaMemcpy: \t\t %8.2f ms", elapsed_time_ms);
printf("performance: %8.2f GB/s\n", (float)iBytes / (elapsed_time_ms * 1e6f));
因为PCIe总线支持任何两个端点之间的全双工通道,所以也可以使用异步复制函数来进行双向的且点对点的内存复制。
// bidirectional asynchronous gmem copy
for (int i = 0; u < 100; i++)
{
if (i % 2 == 0)
cudaMemcpyAsync(d_src[1], drc[0], iBytes, cudaMemcpyDeviceToHost);
else
cudaMemcpyAsync(d_rcv[0], drcv[1], iBytes, cudaMemcpyDeviceToHost);
}
注意,由于PCIe总线是一次两个方向上使用的,所以获得的带宽增加了一倍。
中国算力产业发展及瓶颈
一、市场规模:服务器作为算力载体,受益云计算需求提升
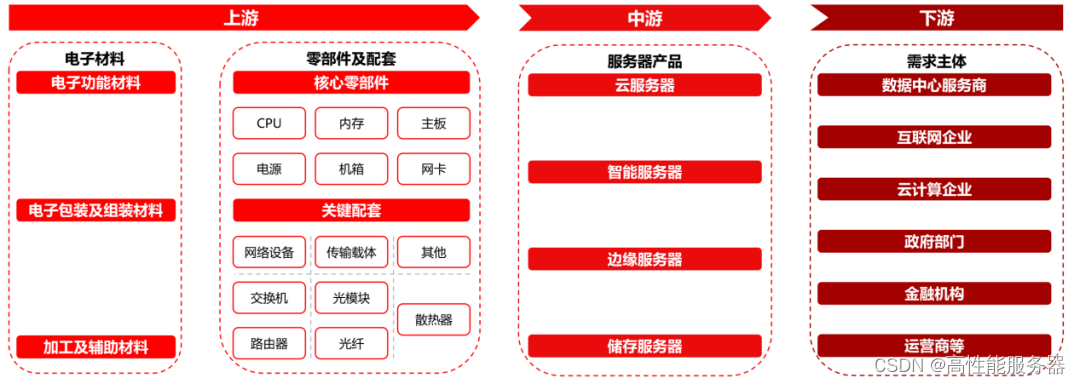
1、产业链:下游各领域算力需求带动服务器产业发展
服务器产业链上游主要是电子材料及零部件/配套。中游为各类服务器产品,包括云服务器、智能服务器、边缘服务器、储存服务器。下游需求主体为数据中心服务商、互联网企业、政府部门、金融机构、电信运营商等。
服务器产业链全景图
2、云计算:算力应用互联网需求最大,其次为政府、服务等
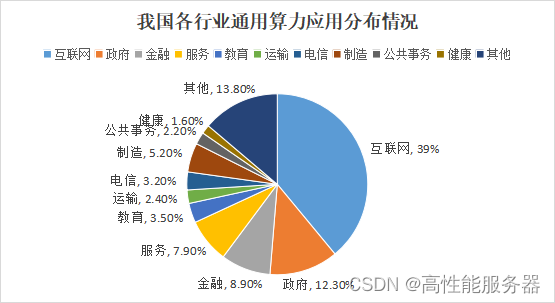
在通用算力领域,互联网行业依然是算力需求最大的行业,占据了通用算力的39%。电信行业加大了对算力基础设施的投入,算力份额首次超过政府行业,位列第二。而政府、服务、金融、制造、教育、运输等行业位列三到八位。
在智能算力领域,互联网行业对数据处理和模型训练的需求持续增长,成为智能算力需求最大的行业,占据了智能算力的53%。服务行业正在快速从传统模式转向新兴智慧模式,其算力份额占比位列第二。而政府、电信、制造、教育、金融、运输等行业分列第三到八位。

2、云计算:中国市场增速快于全球,预计2025年突破万亿元
根据Gartner数据,2022年全球云计算市场规模达到4910亿美元,同比增长19%,但较2021年同比下降13.5%。而根据中国信息通信研究院的统计,2022年中国云计算市场规模达到4550亿元,同比增长40.91%。
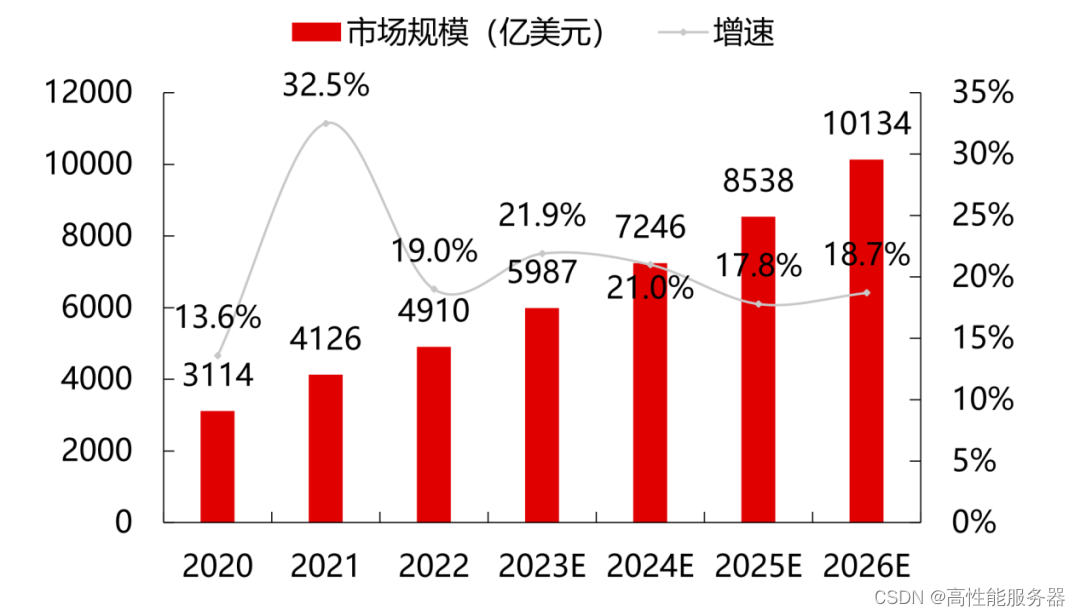
全球云计算市场规模及增速
云计算仍然是新技术融合和业态发展的重要推动力。预计在大模型和算力需求的刺激下,市场将继续保持稳定增长,到2026年全球云计算市场将突破万亿美元。相比全球19%的增速,中国云计算市场仍处于快速发展阶段,在大经济颓势下仍保持较高的抗风险能力,预计到2025年我国云计算整体市场规模将突破万亿元。
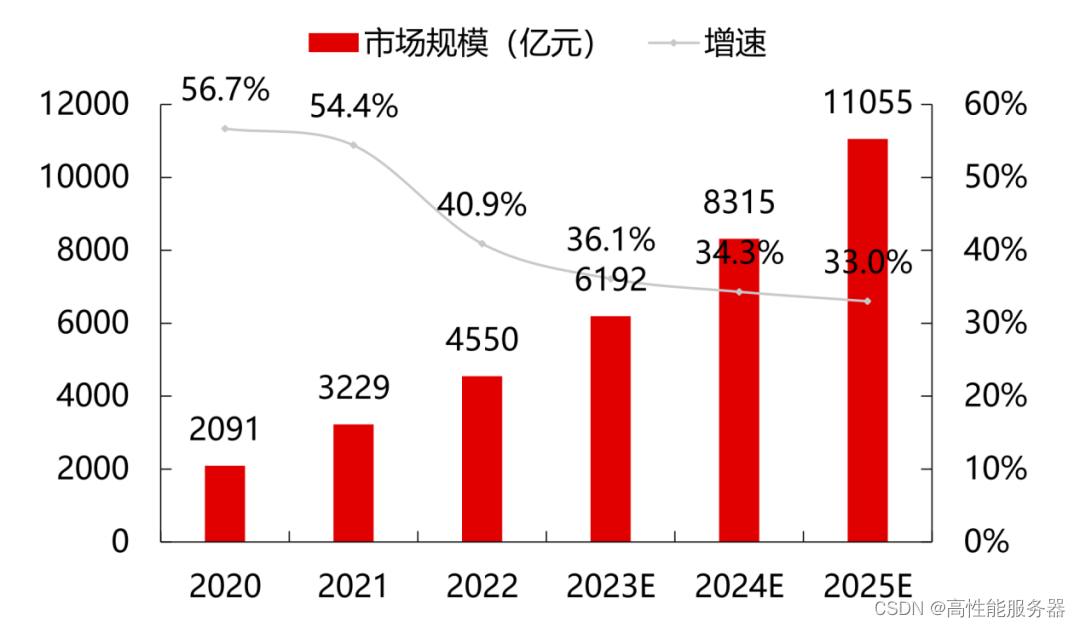
中国云计算市场规模及增速
3、服务器:销售端头部集中,采购端以科技巨头为主
根据IDC之前公布的数据,2022年中国服务器市场的主要供应商包括浪潮信息、新华三、超聚变、宁畅和中兴通讯。
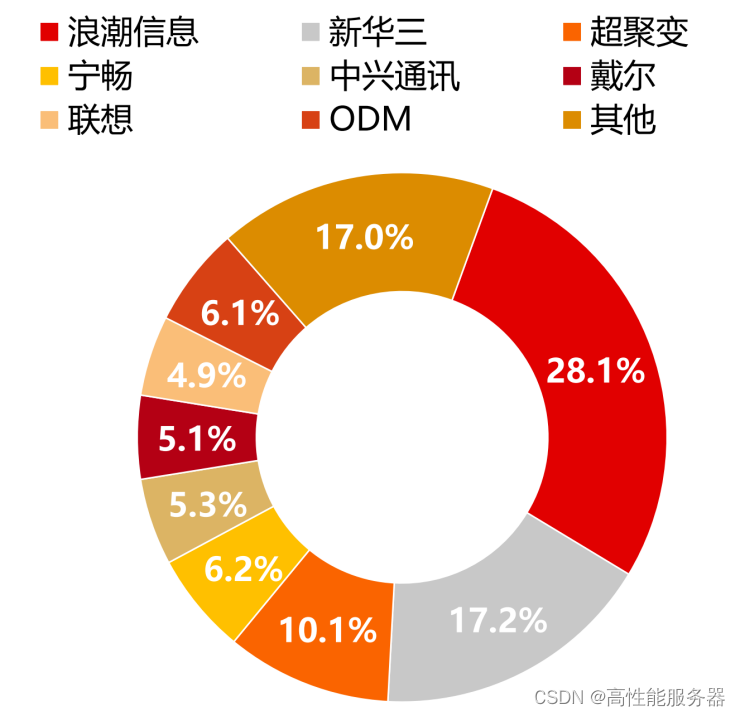
2022年中国服务器市份额情况
国内AI服务器行业采用CPU+加速芯片的架构形式,在进行模型训练和推断时具有效率优势。浪潮信息在国内市场份额较高,其次为新华三、宁畅、安擎等。
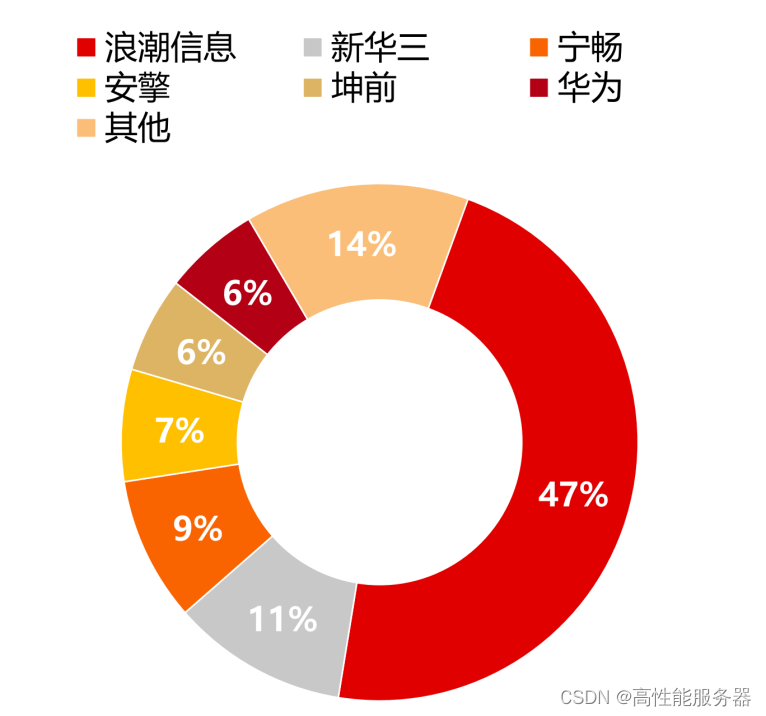
2022年中国AI服务器市份额情况
随着云计算、移动互联网、物联网、大数据、人工智能等技术的兴起,互联网巨头逐渐取代政府和银行等部门成为服务器的主要采购方。在2012年之前,服务器的下游客户主要是政府、银行等金融机构、电信和其他大型企业。然而,现在服务器的下游客户主要以科技巨头为主,如海外亚马逊、微软、谷歌以及国内阿里、腾讯等为代表的云计算巨头逐步成为服务器市场的主要采购客户。
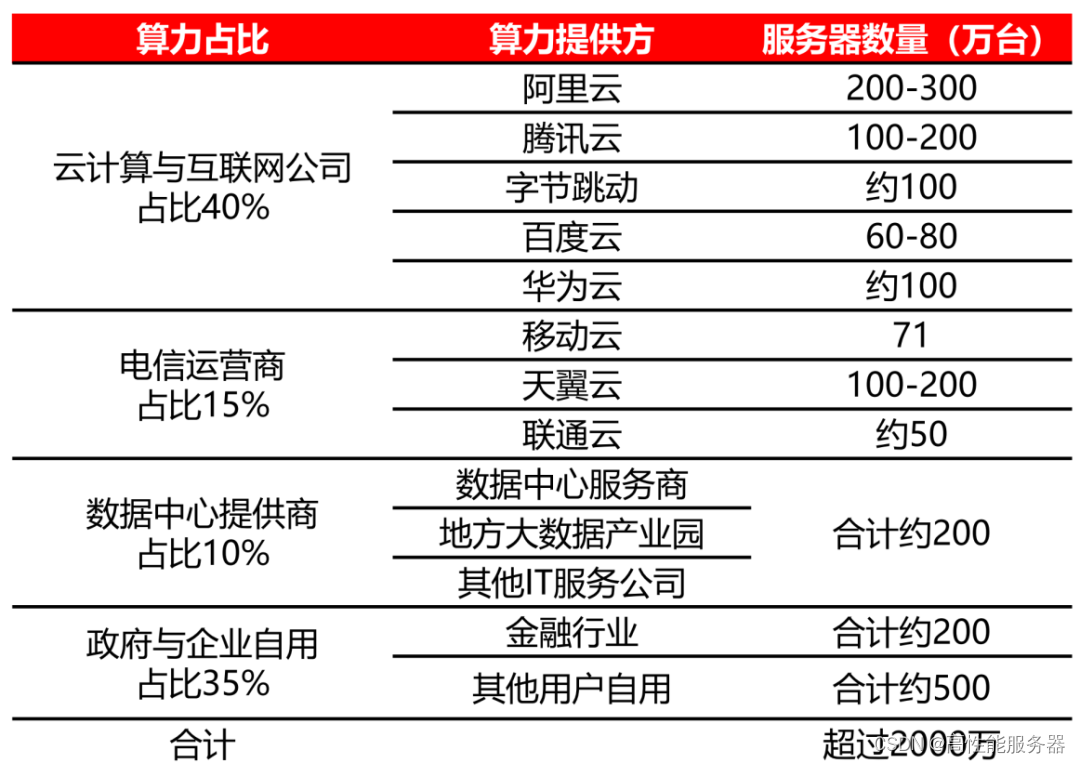
2022年中国主要云厂商服务器规模
根据IDC的预测数据,2023年全球服务器市场规模同比几乎持平,而2024年及以后服务器市场将保持8-11%的增速,预计到2027年市场规模将达到1780亿美元。
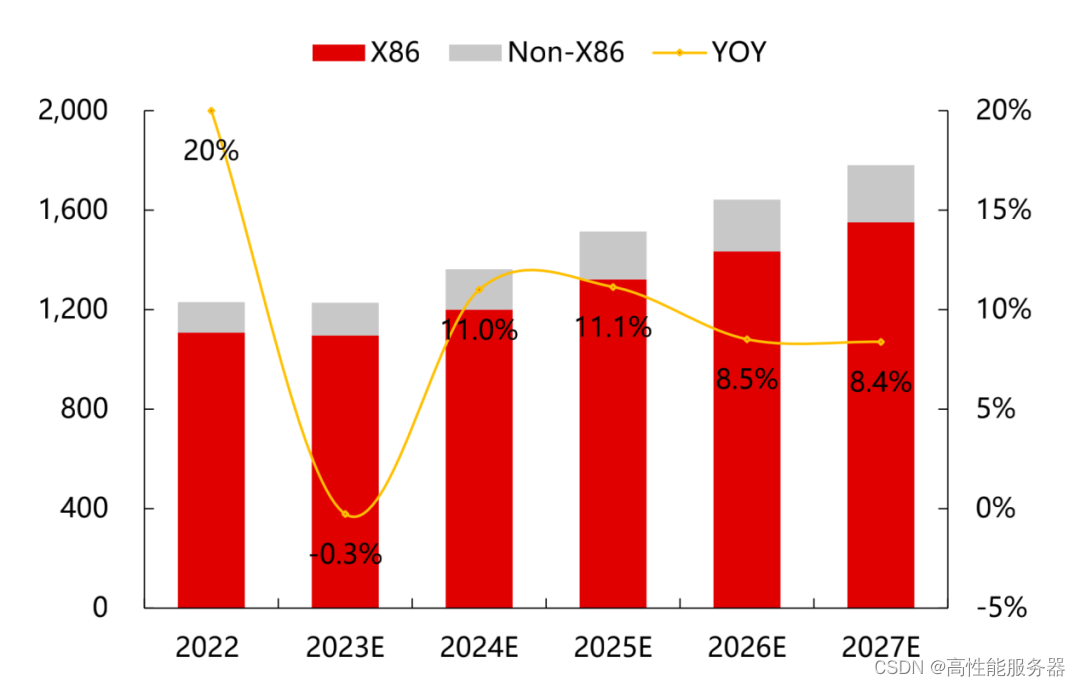
2022-2027E全球服务器市场规模(亿美元)
2022年中国服务器市场规模约为273.4亿美元,同比增长9%,增速有所放缓。根据华经产业研究院的数据,2023年市场规模将达到308亿美元,增速为13%。随着东数西算项目的推进、海量数据运算和存储需求的快速增长等因素的影响,中国服务器整体的采购需求将进一步增加。IDC预测,到2027年中国AI服务器市场规模将达到164亿美元。
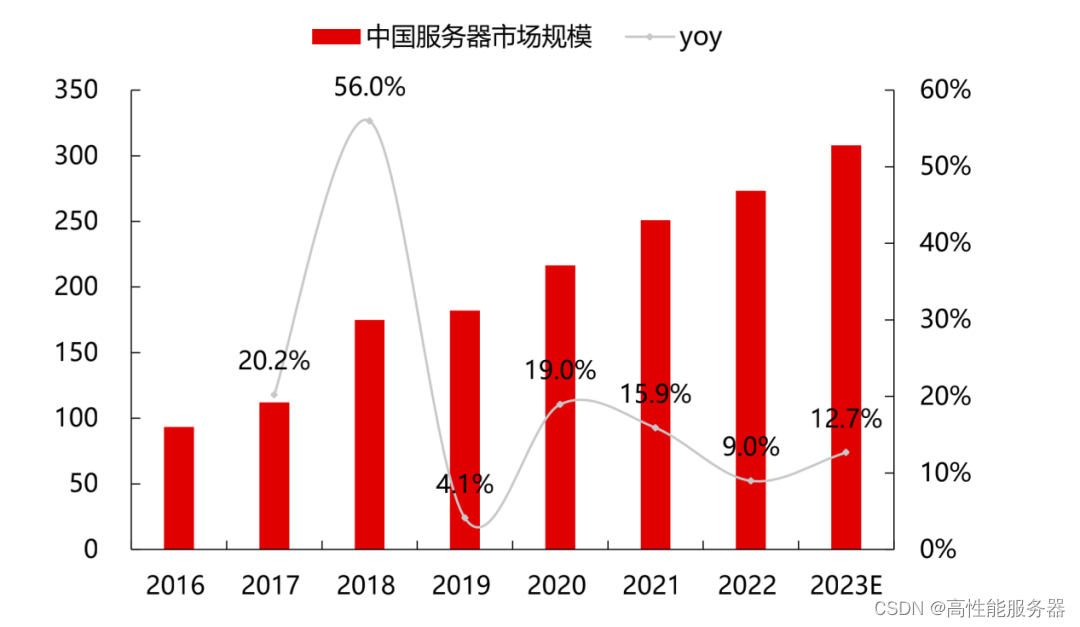
2016-2023E中国服务器市场规模(亿美元)
二、底层关键: CPU是服务器的大脑,国产替代空间广阔
1、作用关键:CPU是服务器的大脑,GPU并行计算能力很强
CPU是服务器的控制中心,负责完成布局谋略、发号施令、控制行动等任务,其结构包括运算器、控制单元、寄存器、高速缓存器和通讯的总线。GPU由于图形渲染、数值分析、AI推理等底层逻辑需要将繁重的数学任务拆解,利用GPU多流处理器机制,将大量运算拆解为小运算,并行处理。CPU和GPU是两种不同的处理器,CPU是程序控制、顺序执行的通用处理器,而GPU是用于特定领域分析的专用处理器,受CPU控制。在许多终端设备中,CPU和GPU通常集成在一个芯片中,同时具备CPU或GPU处理能力。
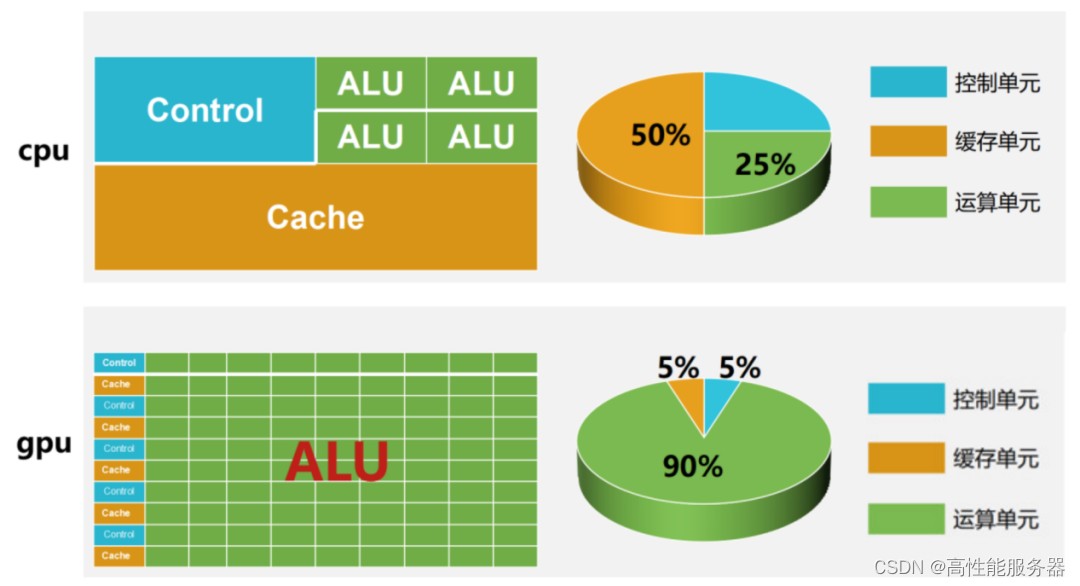
GPU投入更多晶体管进行数据处理,并行运算能力强
2、价值关键:CPU、GPU占据各类服务器的硬件成本高
服务器的硬件成本构成上,CPU及芯片组、内存和外部存储是主要部分:在普通服务器中,CPU及芯片组约占32%,内存约占27%,外部存储约占18%,其他硬件约占23%。而在AI服务器上,GPU的成本占比则远高于其他部分,可能接近整体成本的70%。从普通服务器升级到AI训练服务器时,其他单台服务器价值量增量较大的部件包括内存、SSD、PCB、电源等,都有数倍的提升。
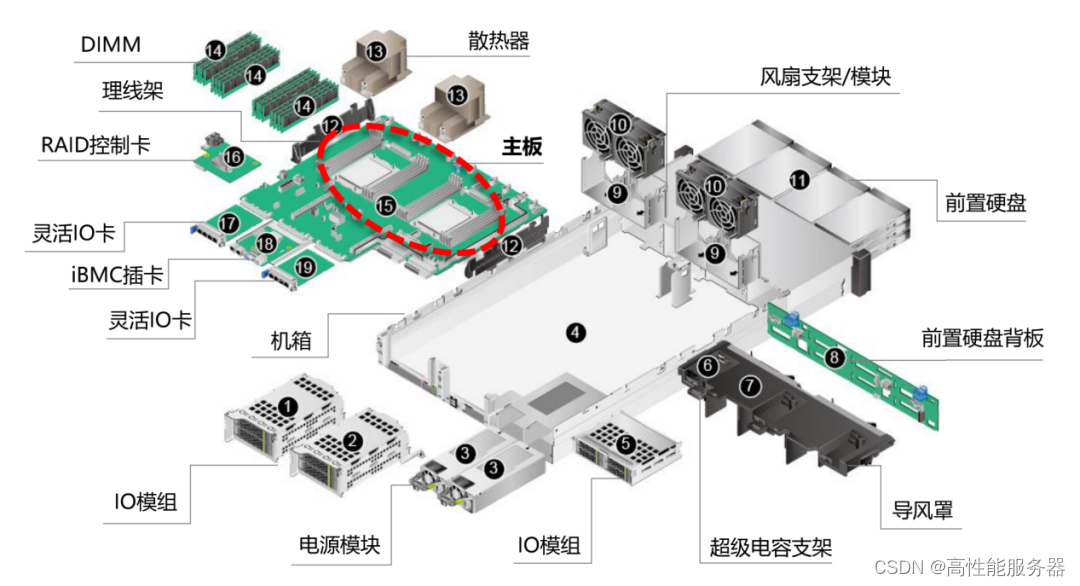
服务器内部拆解示意图
3、处理器:CPU主导地位,GPU增长迅猛
根据Yole Intelligence的报告,预计到2028年处理器市场的收入将达到2420亿美元,复合年增长率为8%。CPU市场的主导地位将得到巩固,2028年市场规模将达到970亿美元,复合年增长率为6.9%。GPU市场也将实现显著增长,2028年市场规模将达到550亿美元,复合年增长率为16.5%。在处理器市场上,英特尔、AMD、英伟达等巨头以及紫光展锐主导着市场。在国内外服务器所使用的处理器方面,英特尔、AMD、英伟达、龙芯、兆芯、鲲鹏、海光、飞腾、申威、昇腾等占主导地位。
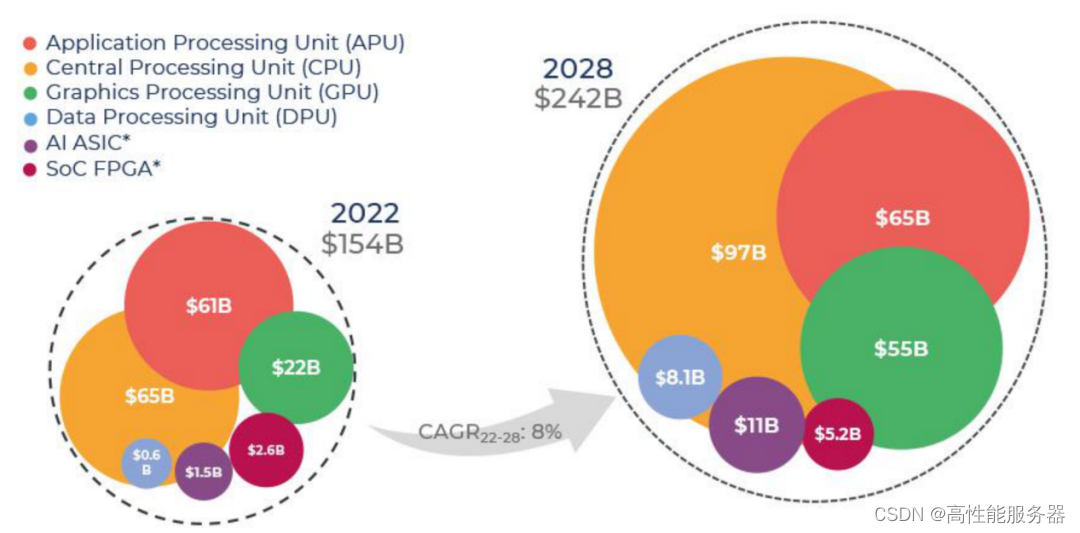
2022-2028年按处理器类型划分的处理器收入预测
4、我国在美国多轮制裁下不断进行科技攻坚
自2019年5月至2020年9月,美国政府对华为实施多轮制裁,导致华为5G手机芯片供应被切断,华为手机销量大幅下滑。此后,美国针对我国半导体领域的限制不断升级。然而,华为最新旗舰机型采用了7nm工艺的麒麟9000s芯片,标志着中国在芯片设计和制造领域的里程碑。
2023年10月17日,美国商务部工业和安全局公布了新的尖端芯片出口管制规则,共计近500页,全面限制美国芯片巨头如英伟达、英特尔等生产的“特供版”芯片出口到中国及40余个国家。此外,还更新了半导体设备和技术相关的“长臂管辖”,扩大荷兰光刻机企业ASML不可对华出口机型范围,并限制波及中国之外20余个国家。同时,将壁仞科技、摩尔线程等13个中国实体加入美国管制清单,限制中国企业通过代工厂生产先进芯片。

10月17日美国商务部工业和安全局公布管制新规
三、算力的瓶颈在哪里,机会就会在哪里
算力是现代计算机技术的核心,其瓶颈主要存在于数据传输和存储方面。目前,计算机普遍采用冯诺依曼架构,数据存储和数据计算分开,算力容易被卡在数据传输,而非真正的计算。算力分为四层,每一层都需要解决如何让数据连接更快的问题。
1、GPU内部
GPU内部的计算单元与显存之间的数据传输是性能提升的瓶颈,同时多个GPU间的协同计算也受到数据传输速度的限制。传统GPU通常采用GDDR内存,这种内存是平面封装,导致数据传输速度跟不上GPU的计算速度。为解决这一问题,升级后的方案采用HBM内存技术。HBM内存是垂直封装,能够提供更大的带宽,从而将数据更快地传输到GPU的计算单元中。例如,HBM2的带宽高达256GB/s,比传统的GDDR内存快十倍以上。
2、AI服务器
每台AI服务器都由多个GPU组成(4个、8个甚至更多),GPU需要进行协同计算。然而,它们之间的数据传输速度成为性能的瓶颈。在这方面,英伟达GPU连接技术最为先进,使用的是其NVLink协议,每秒传输速度高达50GB。华为也拥有自己的HCCS协议,带宽表现不错,每秒30GB,与英伟达没有量级的差异。然而,其他传统的服务器只采用PCIe 5标准接口,每通道传输速度只有4GB,不到英伟达的十分之一。因此,为提高数据传输速度并解决该瓶颈问题,需要采用更先进的技术和协议。
3、数据中心
数据中心由上百甚至上千台AI服务器组成计算集群,服务器之间需要快速的数据连接。英伟达采用专用的InfiniBand网络,而其他厂商则使用ROC高速以太网网络。尽管这两种网络在物理层都使用光纤连接,但都离不开光模块。无论是数据发送还是接收,无论是服务器端还是交换机端,都需要光模块。今年,光模块的技术从400G升级到800G,因为国内厂商在光模块制造领域的占比很高,因此这一块的业绩能够真正实现,导致光模块技术在算力领域被炒作得最多。
4、数据网络
不同地点和城市的数据中心可以组成一个庞大的算力网络,通过调度和统筹,终端用户轻松地使用最快且最便宜的算力资源。目前,算力网络的发展趋势是采用云-边-端的架构,旨在解决数据传输的问题。其中,边缘计算是最为热门的技术之一。边缘计算并不仅仅是指手机和智能车辆,而是指在传统的云计算中心之外,更靠近终端地方增加一层直接计算能力,以节省数据传输的成本和时间。因此,未来的大趋势是云的AI算力、边缘的AI算力和用户端的AI算力相互结合,共同推动人工智能技术的发展。
蓝海大脑深度学习大数据平台
蓝海大脑深度学习大数据平台是面向多源空间数据的处理平台,集成存储、计算和数据处理软件,具有高效、易操作、低成本、多层次扩展和快速部署等显著优势,在测绘、农业、林业、水利、环保等领域大大提升图像处理能力,保护投资,高效应对大数据挑战,加速业务突破和转型。
一、主要技术指标
-
可 靠 性:平均故障间隔时间MTBF≥15000 h
-
工作温度:5~40 ℃
-
工作湿度:35 %~80 %
-
存储温度:-40~55 ℃
-
存储湿度:20 %~90 %
-
声 噪:≤35dB

二、特点及优势:
-
基于统一的整体架构,采用先进成熟可靠的技术与软硬件平台,保证基础数据平台易扩展、易升级、易操作、易维护等特性。基于业界热门,且领先的 Spark 技术,极速提高平台的整体计算性能。
-
支持基础数据模型、应用分析模型、前端应用的扩展性;支持在统一系统架构中服务器、存储、I/O 设备等的可扩展性。
-
制定并实施基础数据平台高可用性方案、运行管理监控制度、运行维护制度、故障处理预案等,保证系统在多用户、多节点等复杂环境下的可靠性。
-
高效性:在规定时间内完成数据写入操作,并将数据写入对数据分析的影响降到最低;提升实现规划要求的数据查询和统计分析速度。
-
数据质量贯穿基础数据平台系统建设的每个环节,基础数据平台系统通过合理的数据质量管理解决方案保证数据质量。
-
按国家标准、行业标准、安全规范等实现数据安全管理。
-
统一的管理平台,对系统进行相应的性能管理和日志监控。
-
人机接口灵活多样的展现方式,最终用户只需进行适当的培训就可以方便地使用新的分析工具,减少 IT 人员的工作量,加强集群监管的时效性。
-
具有超强影像处理能力,每天(24小时)可处理多达500景对(全色和多光谱)高分一号影像数据。
-
广泛适用于基础测绘、农业、林业、水利、环保等领域,适合常规模式下产品生产和应急模式下快速影像图生成。
针对大数据原始技术存在的问题,蓝海大脑大数据平台从企业应用角度出发,对 Apache Hadoop 进行了系列技术开发,形成了适应企业级应用的一站式大数据平台,从而满足各类企业的要求:
-
超大数据的分布式存储、流数据实时计算要求
-
满足大数据的高并发、低延迟查询请求
-
分布式应用系统异常故障时,业务切换
-
系统线性扩展时,无需增加开发工作,实现无成本扩展
三、常用配置推荐
1、CPU:
- Intel Xeon Gold 8358P 32C/64T 2.6GHz 48MB,DDR4 3200,Turbo,HT 240W
- Intel Xeon Platinum 8458P 28C/56T 2.7GHz 38.5MB,DDR4 2933,Turbo,HT 205W
- Intel Xeon Platinum 8468 Processor 48C/64T 2.1GHz 105M Cache 350W
- AMD EPYC™ 7742 64C/128T,2.25GHz to 3.4GHz,256MB,DDR4 3200MT/s,225W
- AMD EPYC™ 9654 96C/192T,2.4GHz to 3.55GHz to 3.7GHz,384MB,DDR5 4800MT/s,360W
- Intel Xeon Platinum 8350C 32C/64T 2.6GHz 48MB,DDR4 3200,Turbo,HT 240W
- Intel Xeon Gold 6240R 24C/48T,2.4GHz,35.75MB,DDR4 2933,Turbo,HT,165W.1TB
- Intel Xeon Gold 6258R 28C/56T,2.7GHz,38.55MB,DDR4 2933,Turbo,HT,205W.1TB
- Intel Xeon W-3265 24C/48T 2.7GHz 33MB 205W DDR4 2933 1TB
- Intel Xeon Platinum 8280 28C/56T 2.7GHz 38.5MB,DDR4 2933,Turbo,HT 205W 1TB
- Intel Xeon Platinum 9242 48C/96T 3.8GHz 71.5MB L2,DDR4 3200,HT 350W 1TB
- Intel Xeon Platinum 9282 56C/112T 3.8GHz 71.5MB L2,DDR4 3200,HT 400W 1TB
2、GPU:
- NVIDIA A100, NVIDIA GV100
- NVIDIA L40S GPU 48GB
- NVIDIA NVLink-A100-SXM640GB
- NVIDIA HGX A800 80GB
- NVIDIA Tesla H800 80GB HBM2
- NVIDIA A800-80GB-400Wx8-NvlinkSW
- NVIDIA RTX 3090, NVIDIA RTX 3090TI
- NVIDIA RTX 8000, NVIDIA RTX A6000
- NVIDIA Quadro P2000,NVIDIA Quadro P2200