OpenCV-Python实战(1)——OpenCV简介与图像处理基础
OpenCV介绍
OpenCV 是一个的跨平台计算机视觉库,可以运行在 Linux、Windows 和 Mac OS 操作系统上。它轻量级而且高效——由一系列 C 函数和少量 C++ 类构成,同时也提供了 Python 接口,实现了图像处理和计算机视觉方面的很多通用算法。在本文中,将介绍 OpenCV 库,包括它的主要模块和典型应用场景。
Python安装OpenCV
对于 Linux 和 Windows 操作系统,首需要在 shell 或 cmd 中运行以下命令安装 NumPy:
pip install numpy
然后再安装 OpenCV,可以选择两种不同版本:
- 仅安装主模块包
pip install opencv-python - 安装完整包(包括主模块和附加模块)
pip install opencv-contrib-python
OpenCV主要模块
OpenCV 可以被划分为不同模块,其主要模块如下:
下表整理介绍了各主要模块的作用:
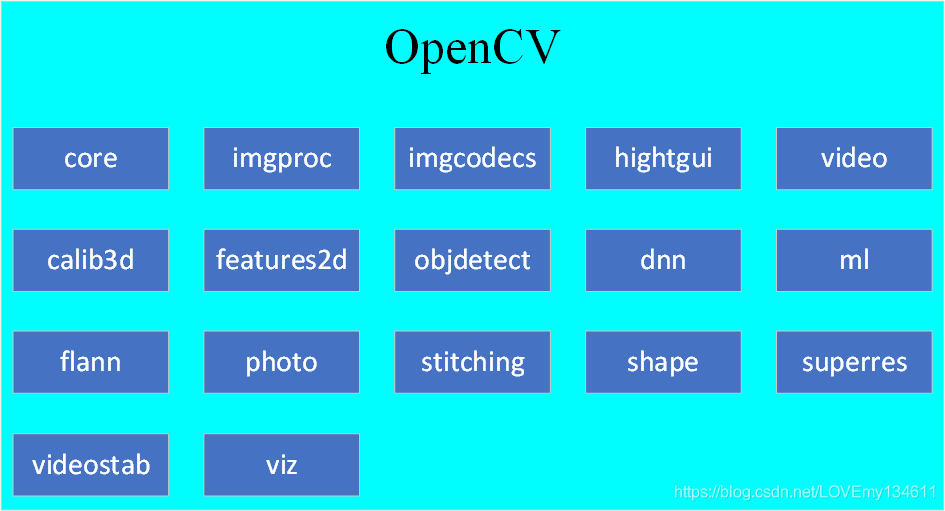
| 模块 | 介绍 |
|---|---|
| core | 核心模块,是定义基本数据结构的模块,也包括库中所有其他模块使用的基本函数 |
| imgproc | 图像处理模块,包括图像滤波、几何图像变换、颜色空间变换和直方图 |
| imgcodecs | 图像文件读写 |
| highgui | 高级GUI,提供UI功能的接口,可以执行以下操作:创建和操作可以显示的窗口、将滑动条添加到窗口、键盘命令和处理鼠标事件等 |
| videoio | 视频I/O,视频捕获和视频编解码器的接口 |
| video | 视频分析模块,包括背景减法、运动估计和目标跟踪算法 |
| calib3d | 摄像机标定和三维重建,包括基本的多视点几何算法、立体匹配算法、目标姿态估计、单摄像机和立体摄像机标定以及三维重建 |
| features2d | 二维特征框架,该模块包括特征检测器、描述符和描述符匹配器 |
| objdetect | 目标检测,检测预定义类的对象和实例(例如,人脸、眼睛、人和汽车) |
| dnn | 深度神经网络(Deep neural network, DNN)模块,本模块包含以下内容:用于创建新层的API、一组预定义的常用层、从层构造和修改神经网络的API、从不同深度学习框架加载序列化网络模型的功能等 |
| ml | 机器学习库(Machine Learning Library, MLL)是一组可用于分类、回归和聚类目的的类和方法 |
| flann | 快速近似近邻库(Fast Library for Approximate Nearest Neighbors, FLANN)是一组非常适合快速近邻搜索的算法,用于多维空间中的聚类和搜索 |
| photo | 计算摄影,提供一些计算摄影的函数 |
| stitching | 图像拼接,实现了一个自动拼接全景图像的拼接流水线 |
| shape | 形状距离和匹配模块,可用于形状匹配、检索或比较 |
| superres | 超分辨率,包含一组可用于提高分辨率的类和方法 |
| videostab | 视频稳定,包含一组用于视频稳定的类和方法 |
| viz | 三维可视化工具,用于显示与场景交互的小部件 |
OpenCV应用场景
OpenCV 可以应用但不仅限于以下场景:二维和三维特征提取、街景图像拼接、人脸识别系统、手势识别、人机交互、动作识别、物体识别、自动检查和监视、分割与识别、医学图像分析、运动跟踪、增强现实、视频/图像搜索与检索、机器人与无人驾驶汽车导航与控制、驾驶员疲劳驾驶检测等。
OpenCV图像处理基础
图像基础
接下来,首先从理论上介绍图像的相关概念。
图像处理中的主要问题
我们看可以把图像看作是三维世界的二维视图,那么数字图像作为2D图像,可以使用称为像素的有限数字集进行表示(像素的概念将在像素、颜色、通道、图像和颜色空间部分中详细解释)。我们可以,将计算机视觉的目标定义为将这些2D数据转换为以下内容:
- 新的数据表示(例如,新图像)
- 决策目标(例如,执行具体决策任务)
- 目标结果(例如,图像的分类)
- 信息提取(例如,目标检测)
在进行图像处理时,经常会遇到以下问题:
- 图像的模糊性,由于受到透视的影响,从而会导致图像视觉外观的变化。例如,从不同的角度看同一个物体会产生不同的图像;
- 图像通常会受许多自然因素的影响,如光照、天气、反射和运动;
- 图像中的一部分对象也可能会被其他对象遮挡,使得被遮挡的对象难以检测或分类。随着遮挡程度的增加,图像处理的任务(例如,图像分类)可能非常具有挑战性。
为了更好的解释上述问题,我们假设需要开发一个人脸检测系统。该系统应足够鲁棒,以应对光照或天气条件的变化;此外,该系统应该可以处理头部的运动——用户头部可以在坐标系中每个轴上进行一定程度的动作(抬头、摇头和低头,用户可以离相机稍近或稍远的情况)。而许多人脸检测算法在人脸接近正面时表现出良好的性能,但是,如果一张脸不是正面的(例如,侧面对着镜头),算法就无法检测到它。此外,算法需要即使在用户戴着眼镜或太阳镜时,也可能需要检测面部(即使这会在眼睛区域产生遮挡)。综上所述,当开发一个计算机视觉项目时,我们必须综合考虑到所有这些因素,一个很好的表征方法是有使用大量测试图像来验证算法。我们也可以根据测试图像的不同困难程度来对它们进行分类,以便于检测算法的弱点,提高算法的鲁棒性。
图像处理流程
完整的图像处理程序通常可以分为以下三个步骤:
- 读取图像,图像的获取可以有多种不同的来源(相机、视频流、磁盘、在线资源),因此图像的读取可能涉及多个函数,以便可以从不同的来源读取图像;
- 图像处理,通过应用图像处理技术来处理图像,以实现所需的功能(例如,检测图像中的猫);
- 显示结果,将图像处理完成后的结果以人类可读的方式进行呈现(例如,在图像中绘制边界框,有时也可能需要将其保存到磁盘)。
此外,上述第2步图像处理可以进一步分为三个不同的处理级别:
- 低层处理(或者在不引起歧义的情况下可以称为预处理),通常将一个图像作为输入,然后输出另一个图像。可在此步骤中应用的步骤包括但不限于以下方法:噪声消除、图像锐化、光照归一化以及透视校正等;
- 中层处理:是将预处理后的图像提取其主要特征(例如采用 DNN 模型得到的图像特征),输出某种形式的图像表示,它提取了用于图像进一步处理的主要特征。
- 高层处理:接受中层处理得到的图像特征并输出最终结果。例如,处理的输出可以是检测到的人脸.
像素、颜色、通道、图像和颜色空间
在表示图像时,有多种不同的颜色模型,但最常见的是红、绿、蓝 (RGB) 模型。
RGB 模型是一种加法颜色模型,其中原色 (在RGB模型中,原色是红色 R、绿色 G 和蓝色 B) 混合在一起就可以用来表示广泛的颜色范围。
每个原色 (R, G, B) 通常表示一个通道,其取值范围为[0, 255]内的整数值。因此,每个通道有共256个可能的离散值,其对应于用于表示颜色通道值的总比特数 (
2
8
=
256
2^8=256
28=256)。此外,由于有三个不同的通道,使用 RGB 模型表示的图像称为24位色深图像:
在上图中,可以看到 RGB 颜色空间的“加法颜色”属性:
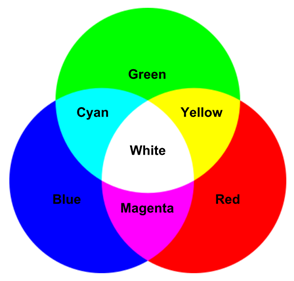
- 红色加绿色会得到黄色
- 蓝色加红色会得到品红
- 蓝色加绿色会得到青色
- 三种原色加在一起得到白色
因此,如前所述,RGB 颜色模型中,特定颜色可以由红、绿和蓝值分量合成表示,将像素值表示为 RGB 三元组 (r, g, b)。典型的 RGB 颜色选择器如下图所示:
分辨率为 800×1200 的图像是一个包含800列和1200行的网格,每个网格就是称为一个像素,因此其中包含 800×1200=96 万像素。应当注意,图像中有多少像素并不表示其物理尺寸(一个像素不等于一毫米)。相反,像素的大小取决于为该图像设置的每英寸像素数 (Pixels Per Inch, PPI)。图像的 PPI 一般设置在 [200-400] 范围内。
计算PPI的基本公式如下:
- PPI=宽度(像素) / 图像宽度(英寸)
- PPI=高度(像素) / 图像高度(英寸)
例如,一个4×6英寸图像,图像分辨率为 800×1200,则PPI是200。
图像描述
图像可以描述为2D函数 f ( x , y ) f(x, y) f(x,y),其中 ( x , y ) (x, y) (x,y) 是空间坐标,而 f ( x , y ) f(x, y) f(x,y) 是图像在点 ( x , y ) (x, y) (x,y) 处的亮度或灰度或颜色值。另外,当f(x, y)和(x, y)值都是有限离散量时,该图像也被称为数字图像,此时:
- x ∈ [ 0 , h − 1 ] x∈ [0, h-1] x∈[0,h−1],其中 h h h 是图像的高度
- y ∈ [ 0 , w − 1 ] y∈ [0, w-1] y∈[0,w−1],其中 w w w 是图像的宽度
- f ( x , y ) ∈ [ 0 , L − 1 ] f(x, y)∈ [0,L-1] f(x,y)∈[0,L−1],其中 L = 256 L=256 L=256 (对于8位灰度图像)
彩色图像也可以用同样的方式表示,只是我们需要定义三个函数来分别表示红色、绿色和蓝色值。这三个单独的函数中的每一个都遵循与为灰度图像定义的
f
(
x
,
y
)
f(x, y)
f(x,y) 函数相同的公式。我们将这三个函数的子索引 R、G 和 B 分别表示为
f
R
(
x
,
y
)
f_R(x, y)
fR(x,y)、
f
G
(
x
,
y
)
f_G(x, y)
fG(x,y) 和
f
B
(
x
,
y
)
f_B(x, y)
fB(x,y)。
同样,黑白图像也可以表示为相同的形式,其仅需要一个函数来表示图像,且
f
(
x
,
y
)
f(x, y)
f(x,y) 只能取两个值。通常,0 表示黑色、1 表示白色。
下图显示了三种不同类型的图像(彩色图像、灰度图像和黑白图像):
数字图像可以看作是真实场景的近似,因为
f
(
x
,
y
)
f(x, y)
f(x,y) 值是有限的离散量。此外,灰度和黑白图像每个点只对应有一个值,彩色图像每个点需要三个函数对应于图像的红色、绿色和蓝色分量。

图像文件类型
尽管在 OpenCV 中处理的图像时,可以将图像看作 RGB 三元组的矩阵(在 RGB 图像模型情况下),但它们不一定是以这种格式创建、存储或传输的。有许多不同的文件格式,如GIF、PNG、位图或JPEG,使用不同形式的压缩(无损或有损)来更有效地表示图像。
下表列示了 OpenCV 支持的文件格式及其关联的文件扩展名:
| 文件格式 | 文件扩展名 |
|---|---|
| Windows bitmaps | *.bmp和*.dib |
| JPEG files | *.JPEG、*.jpg 和 *.jpe |
| JPEG 2000 files | *.jp2 |
| Portable Network Graphics | *.png |
| Portable image format | *.pbm、*.pgm 和 *.ppm |
| TIFF files | *.TIFF 和 *.tif |
对图像应用无损或有损压缩算法,可以得到比未压缩图像占据存储空间小的图像。其中,在无损压缩算法中,得到的图像与原始图像等价,也就是说,经过反压缩过程后,得到的图像与原始图像完全等价(相同);而在有损压缩算法中,得到的图像并不等同于原始图像,这意味着图像中的某些细节会丢失,在许多有损压缩算法中,压缩级别是可以调整的。
OpenCV中的坐标系
为了更好的展示 OpenCV 中的坐标系以及如何访问各个像素,查看以下低分辨率图像为例:

这个图片的尺寸是 32×41 像素,也就是说,这个图像有 1312 个像素。为了进一步说明,我们可以在每个轴上添加像素计数,如下图所示:

现在,我们来看看
(
x
,
y
)
(x, y)
(x,y) 形式的像素索引。请注意,像素索引起始值为零,这意味着左上角位于
(
0
,
0
)
(0, 0)
(0,0),而不是
(
1
,
1
)
(1, 1)
(1,1)。下面的图像,索引了 4 个单独的像素,图像的左上角是原点的坐标:

单个像素的信息可以从图像中提取,方法与 Python 中引用数组的单个元素相同。
OpenCV中的通道顺序
在 OpenCV 使用中,使用的颜色通道顺序为 BGR 颜色格式而不是 RGB 格式。可以在下图中看到三个通道的顺序:

BGR 图像的像素结构如下图所示,作为演示,图示详细说明了如何访问pixel(y=n, x=1):
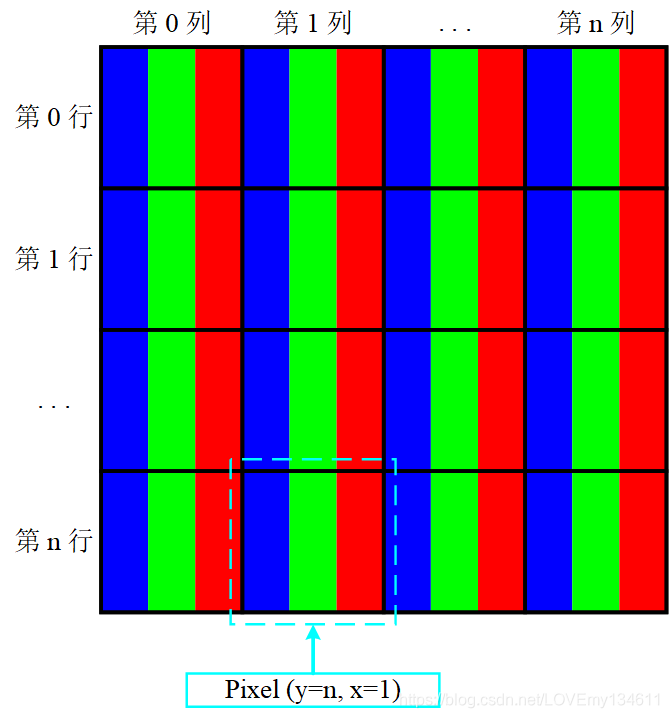
Tips:OpenCV 的最初开发人员选择了 BGR 颜色格式(而不是 RGB 格式),是因为当时 BGR 颜色格式在软件供应商和相机制造商中非常流行,因此选择 BGR 是出于历史原因。
此外,也有其他 Python 包使用的是 RGB 颜色格式(例如,Matplotlib 使用 RGB 颜色格式,Matplotlib 是最流行的 2D Python 绘图库,提供多种绘图方法,可以查看 Python-Matplotlib 可视化获取更多详细信息)。因此,我们需要知道如何将图像从一种格式转换为另一种格式。
当我们掌握了将图像从一种格式转换为另一种格式的方法后,就可以选择使用 OpenCV 进行图像处理,同时利用 Matplotlib 包提供的函数来显示图像,接下来,让我们看看如何处理两个库采用的不同颜色格式。
首先,我们使用 cv2.imread() 函数加载图像:
import cv2
img_OpenCV = cv2.imread('sigonghuiye.jpeg')
图像存储在 img_OpenCV 变量中,因为 cv2.imread() 函数以 BGR 顺序加载图像。然后,我们使用 cv2.split() 函数将加载的图像分成三个通道 (b, g, r) 。这个函数的参数就是我们要分割的图像:
b, g, r = cv2.split(img_OpenCV)
下一步是合并通道(以便根据通道提供的信息构建新图像),但合并时顺序与原图像不同。我们更改 b 和 r 通道的顺序以遵循 RGB 格式,即我们所需要的 Matplotlib 格式:
img_matplotlib = cv2.merge([r, g, b])
此时,我们有两个图像 (img_OpenCV 和 img_matplotlib),接下来,我们将分别使用 OpenCV 和 Matplotlib 绘制她们,以便我们可以对比结果。首先,我们将用 Matplotlib 显示这两个图像。
为了在同一个窗口中使用 Matplotlib 显示两个图像,我们将使用 subplot,它将多个图像放置在同一个窗口中。可以在 subplot 中使用三个参数,例如 subplot(m,n,p),此时,子图处理
m
×
n
m \times n
m×n 网格中的图,其中
m
m
m 确定行数,
n
n
n 确定列数,而
p
p
p 确定要在网格中放置图的位置。要使用 Matplotlib 显示图像,需要使用 imshow 函数。
在这种情况下,当我们水平显示两个图像时,
m
=
1
m = 1
m=1、
n
=
2
n = 2
n=2 。我们将对第一个子图 (img_OpenCV) 使用
p
=
1
p = 1
p=1,对第二个子图(img_matplotlib) 使用
p
=
2
p = 2
p=2:
from matplotlib import pyplot as plt
plt.subplot(121)
plt.imshow(img_OpenCV)
plt.subplot(122)
plt.imshow(img_matplotlib)
plt.show()
程序输出如下图所示:
可以看出,第一个子图以错误的颜色( BGR 顺序)显示图像,而第二个子图以正确的颜色( RGB 顺序)显示图像。接下来,我们使用 cv2.imshow() 显示两个图像:

cv2.imshow('bgr image', img_OpenCV)
cv2.imshow('rgb image', img_matplotlib)
cv2.waitKey(0)
cv2.destroyAllWindows()
以下屏幕截图显示了执行上述代码获得的结果:

正如预期的那样,屏幕截图中,第一张图以正确的色彩显示图像,而第二张图以错误的颜色显示图像。
此外,如果我们想在同一个窗口中显示两个图像,可以构建一个包含这两个图像的拼接图像,将两张图片水平连接起来。为此,我们需要使用 NumPy 的 concatenate() 方法。该方法的参数是要连接的两个图像和要在哪个轴上进行堆叠,这里,我们令 axis = 1 (水平堆叠它们):
import numpy as np
img_concats = np.concatenate((img_OpenCV, img_matplotlib), axis=1)
cv2.imshow('bgr image and rgb image', img_concats)
cv2.waitKey(0)
cv2.destroyAllWindows()
下图显示了连接后的图像:

需要考虑的一个因素是 cv2.split() 是一项耗时的操作。如果确实需要划分不同通道,应当首先考虑使用 NumPy 索引。例如,如果想获取图像的一个通道,则可以使用 NumPy 索引获取通道:
B = img_OpenCV[:, :, 0]
G = img_OpenCV[:, :, 1]
R = img_OpenCV[:, :, 2]
另一个需要注意的是,可以使用 NumPy 在一条语句中将图像从 BGR 转换为 RGB:
img_matplotlib = img_OpenCV[:, :, ::-1]
在不同颜色空间中访问和操作OpenCV中的像素
本节将介绍如何使用 OpenCV 访问和读取像素值以及如何修改它们。此外,还将学习如何访问图像属性。如果想一次处理多个像素,则需要创建图像区域 (Region of Image, ROI)。
在 Python 中,图像表示为 NumPy 数组。因此,示例中包含的大多数操作都与 NumPy 相关,建议需要对 NumPy 包一些了解,才能更好明白示例代码的原理,但即使不了解也没关系,必要时会对所用函数进行讲解。
彩色图像访问和操作OpenCV中的像素
现在,我们来看看如何在 OpenCV 中处理BGR图像。如上所述,OpenCV 加载彩色图像时,蓝色通道是第一个,绿色通道是第二个,红色通道是第三个。
首先,使用 cv2.imread() 函数读取图像。图像应该在工作目录中,或者应该提供图片的完整路径。在本例中,读取 sigonghuiye.jpeg 图像并将其存储在img变量中:
img = cv2.imread('sigonghuiye.jpeg')
图像加载到 img 后,可以获得图像的一些属性。我们要从加载的图像中提取的第一个属性是 shape,它将告诉我们行、列和通道的数量(如果图像是彩色的)。我们将此信息存储在 dimensions 变量中:
dimensions = img.shape
第二个属性是图像的大小(img.size=图像高度 × 图像宽度 × 图像通道数):
total_number_of_elements= img.size
第三个属性是图像数据类型,可以通过 img.dtype 获得。因为像素值在 [0-255] 范围内,所以图像数据类型是 uint8 (unsigned char):
image_dtype = img.dtype
上面示例中,我们已经使用了 cv2.imshow() 函数来在窗口中显示图像,这里我们对其进行更详细的介绍,使用 cv2.imshow() 函数显示图像时,窗口会自动适应图像大小。此函数的第一个参数是窗口名,第二个参数是要显示的图像。在这种情况下,由于加载的图像已存储在 img 变量中,因此使用此变量作为第二个参数:
cv2.imshow("original image", img)
显示图像后,我们来介绍下键盘绑定函数——cv2.waitKey(),它为任何键盘事件等待指定的毫秒数。参数是以毫秒为单位的时间。当执行到此函数时,程序将暂停执行,当按下任何键后,程序将继续执行。如果毫秒数为 0 (cv2.waitKey(0)),它将无限期地等待键盘敲击事件:
cv2.waitKey(0)
要访问(读取)某个像素值,我们需要向 img 变量(包含加载的图像)提供所需像素的行和列,例如,要获得 ( x = 40 , y = 6 ) (x=40, y=6) (x=40,y=6) 处的像素值 :
(b, g, r) = img[6, 40]
我们在三个变量 (b, g, r) 中存储了三个像素值。请牢记 OpenCV 对彩色图像使用 BGR 格式。另外,我们可以一次仅访问一个通道。在本例中,我们将使用所需通道的行、列和索引进行索引。例如,要仅获取像素
(
x
=
40
,
y
=
6
)
(x=40, y=6)
(x=40,y=6) 处的蓝色值:
b = img[6, 40, 0]
像素值也可以以相同的方式进行修改。例如,要将像素 (x=40, y=6) 处设置为红色:
img[6, 40] = (0, 0, 255)
有时,需要处理某个区域而不是一个像素。在这种情况下,应该提供值的范围(也称切片),而不是单个值。例如,要获取图像的左上角:
top_left_corner = img[0:50, 0:50]
变量 top_left_corner 可以看做是另一个图像(比img小),但是我们可以用同样的方法处理它。
最后,如果想要关闭并释放所有窗口,需要使用 cv2.destroyAllWindows() 函数:
cv2.destroyAllWindows()
灰度图像访问和操作OpenCV中的像素
灰度图像只有一个通道。因此,在处理这些图像时会引入一些差异。我们将在这里重点介绍这些差异,相同的部分不再赘述。
同样,我们将使用 cv2.imread() 函数来读取图像。在这种情况下,需要第二个参数,因为我们希望以灰度加载图像。第二个参数是一个标志位,指定读取图像的方式。以灰度加载图像所需的值是 cv2.IMREAD_grayscale:
gray_img = cv2.imread('logo.png', cv2.IMREAD_GRAYSCALE)
在这种情况下,我们将图像存储在gray_img变量中。如果我们打印图像的尺寸(使用 gray_img.shape ),只能得到两个值,即行和列。在灰度图像中,不提供通道信息:
dimensions = gray_img.shape
shape将以元组形式返回图像的维度 —— (828, 640)。
像素值可以通过行和列坐标来访问。在灰度图像中,只获得一个值(通常称为像素的强度)。例如,如果我们想得到像素
(
x
=
40
,
y
=
6
)
(x=40, y=6)
(x=40,y=6) 处的像素强度:
i = gray_img[6, 40]
图像的像素值也可以以相同的方式修改。例如,如果要将像素 ( x = 40 , y = 6 ) (x=40, y=6) (x=40,y=6) 处的值更改为黑色(强度等于0):
gray_img[6, 40] = 0
OpenCV图像处理基础小结
在本文中,首先介绍了与图像相关的关键概念。图像构成了构建计算机视觉项目所必需的丰富信息。然后,我们需要了解 OpenCV 使用 BGR 颜色格式而不是 RGB,但有一些 Python 包(例如 Matplotlib )使用后一种格式。因此,需要了解如何将图像从一种颜色格式转换为另一种颜色格式。
此外,还总结了处理图像的主要函数和参数:
- 访问图像属性
- OpenCV 常用函数,例如 cv2.imread() 、 cv2.split() 、 cv2.merge() 、 cv2.imshow() 、 cv2.waitKey() 和 cv2.destroyAllWindows()
- 如何在 BGR 和灰度图像中获取和操作图像像素
系列链接
OpenCV-Python实战(2)——图像与视频文件的处理
OpenCV-Python实战(3)——OpenCV中绘制图形与文本
OpenCV-Python实战(4)——OpenCV常见图像处理技术
OpenCV-Python实战(5)——OpenCV图像运算
OpenCV-Python实战(6)——OpenCV中的色彩空间和色彩映射
OpenCV-Python实战(7)——直方图详解
OpenCV-Python实战(8)——直方图均衡化
OpenCV-Python实战(9)——OpenCV用于图像分割的阈值技术
OpenCV-Python实战(10)——OpenCV轮廓检测
OpenCV-Python实战(11)——OpenCV轮廓检测相关应用
OpenCV-Python实战(12)——一文详解AR增强现实
OpenCV-Python实战(13)——OpenCV与机器学习的碰撞
OpenCV-Python实战(14)——人脸检测详解
OpenCV-Python实战(15)——面部特征点检测详解
OpenCV-Python实战(16)——人脸追踪详解
OpenCV-Python实战(17)——人脸识别详解
OpenCV-Python实战(18)——深度学习简介与入门示例
OpenCV-Python实战(19)——OpenCV与深度学习的碰撞
OpenCV-Python实战(20)——OpenCV计算机视觉项目在Web端的部署
OpenCV-Python实战(21)——OpenCV人脸检测项目在Web端的部署
OpenCV-Python实战(22)——使用Keras和Flask在Web端部署图像识别应用
OpenCV-Python实战(23)——将OpenCV计算机视觉项目部署到云端