【Embedding合集】文本数据常用Embedding实现方案
文章目录
前言
对文本数据进行嵌入(Embedding)并计算它们之间的相似度是自然语言处理(NLP)中的一项基础任务,广泛应用于信息检索、文本聚类、推荐系统等领域。常用的文本嵌入的方案有词袋模型、Word2Vec、GloVe、FastText以及Bert等。
一、基于词袋(Bag of Words)模型
词袋模型是自然语言处理中常用的一种表示文本的方法,它将文本看作是一个由词语组成的集合,忽略其词序和语法,仅考虑每个词在文本中出现的频率或存在与否。
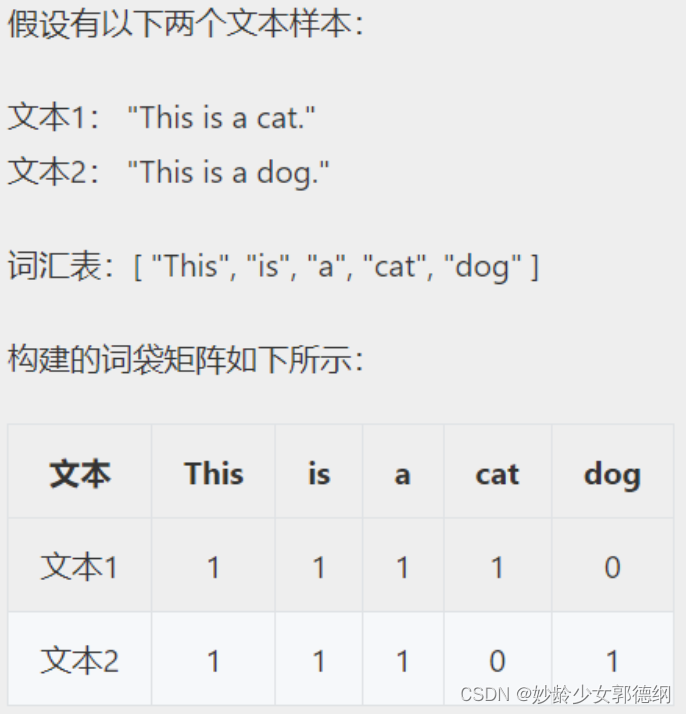
from sklearn.feature_extraction.text import CountVectorizer
# 原始文本数据
corpus = [
"This is a cat.",
"This is a dog."
]
# 创建词袋模型
# vectorizer = CountVectorizer(binary=True) # 二进制表示
vectorizer = CountVectorizer()
# 将文本转换为词袋矩阵
X = vectorizer.fit_transform(corpus)
# 获取词汇表
vocab = vectorizer.get_feature_names_out()
# 打印词汇表
print("词汇表:", vocab)
# 打印词袋矩阵
print("词袋矩阵:\n", X.toarray())
二、Word2Vec
Word2Vec是一种用于生成词嵌入(Word Embeddings)的算法,它使用简单的神经网络模型将单词映射到一个低维空间的向量,使得语义上相似的单词在该空间中距离较近。Word2Vec主要有两种模型:Skip-gram 和 CBOW(Continuous Bag of Words)。详细情况在https://www.heywhale.com/mw/project/64be23353cbcbda8f50cb4f1 中有详细介绍(算是最常用的吧,包括Node2Vec等等都是依据Word2Vec来的)。
from gensim.models import Word2Vec
from nltk.tokenize import word_tokenize
# 准备语料库(示例)
corpus = [
"This is a cat",
"This is a dog",
"The cat is black",
"The dog is brown"
]
# 分词和小写化
tokenized_corpus = [word_tokenize(sentence.lower()) for sentence in corpus]
# 训练 Word2Vec 模型
model = Word2Vec(sentences=tokenized_corpus, min_count=1, vector_size=100, window=5, sg=1, epochs=100)
model.build_vocab(tokenized_corpus)
# 获取词向量
word_vectors = model.wv
# 计算句子向量
def get_sentence_vector(sentence):
tokens = word_tokenize(sentence.lower()) # 分词和小写化
vector_sum = sum(word_vectors[word] for word in tokens if word in word_vectors) # 单词向量求和
return vector_sum / len(tokens) # 平均化得到句子向量
# 测试获取句子向量
test_sentence = "This is a cat"
sentence_vector = get_sentence_vector(test_sentence)
print("句子向量:", sentence_vector)
三、GloVe
GloVe(Global Vectors for Word Representation)是一种用于词嵌入的模型,它结合了全局矩阵分解和局部上下文窗口的优势。GloVe 的目标是将每个词映射到一个向量空间中,使得这些向量能够捕捉到词与词之间的语义和语法关系。
- Glove的包太老了,不太能直接调用,用的话最好自己实现一个
四、FastText
FastText 是一个由 Facebook AI 研究团队开发的用于高效学习单词表示和文本分类的库。适用于处理大规模文本数据,训练速度较快,并且适合处理形态丰富的语言(如土耳其语、芬兰语等等)。
子词嵌入
FastText的一个重要特点是使用了子词嵌入(Subword Embeddings)来处理未登录词(Out-Of-Vocabulary,OOV)和稀有词(Rare Words)。子词嵌入通过将单词分解成字符级别的子词来学习词向量。这样做的好处是即使对于未见过的词,也可以利用其子词的信息来获取词向量。
N-Gram特征
例如,对于单词 “apple” 和 n 的取值范围为 3 到 6,可能的子词包括 “app”, “appl”, “apple”, “pple” 等。FastText 会为这些子词分别学习嵌入,并将一个词的嵌入表示为其所有子词嵌入的和。
from gensim.models import FastText
# 准备语料库(示例)
sentences = [
"This is a cat",
"This is a dog",
"The cat is black",
"The dog is brown"
]
# 构建FastText模型
model = FastText(sentences, vector_size=10, window=3, min_count=1, workers=4, sg=1)
# 训练模型
model.train(sentences, total_examples=model.corpus_count, epochs=10)
# 获取词向量,未出现过的单词
vector = model.wv['word']
五、Bert
BERT(Bidirectional Encoder Representations from Transformers)是一种预训练的自然语言处理模型,由Google在2018年提出,基于Transformer架构。BERT在多项自然语言处理任务中取得了领先水平的性能,能够非常有效地理解文本中的上下文,是目前理解复杂文本语义的最强大工具之一。
Bert预训练模型下载地址:https://hf-mirror.com/google-bert/bert-base-cased/tree/main (模型很大,下载速度很慢,官网不知道怎么回事打不开)
from transformers import BertTokenizer, BertModel
import torch
import warnings
warnings.filterwarnings('ignore')
# 加载BERT模型和Tokenizer
tokenizer = BertTokenizer.from_pretrained('D:/Tools/bert-base-uncased')
model = BertModel.from_pretrained('D:/Tools/bert-base-uncased')
# 输入文本
# text = ["Hello, how are you?", "This is a dog"]
# text = ["Hello, how are you?"]
text = "Hello, how are you?"
# text1 = "Hello"
# 使用Tokenizer对文本进行编码
input_ids = tokenizer.encode(text, add_special_tokens=True, return_tensors="pt")
# 获取单词Embedding
with torch.no_grad():
outputs = model(input_ids)
# 词嵌入,Bert模型最后一层隐向量
word_embeddings = outputs.last_hidden_state
# 输出单词Embedding
print(word_embeddings)
总结
目前最常用的还是Word2Vec,简单且高效,在深度学习领域后续需要进行某些文本分类、情感分析等任务时用Bert,FastText一般是资源有效数据量大并且文本较为复杂时使用。
