目录
一、Yolov3目标检测背景
二、新的主干网络--DarkNet-53
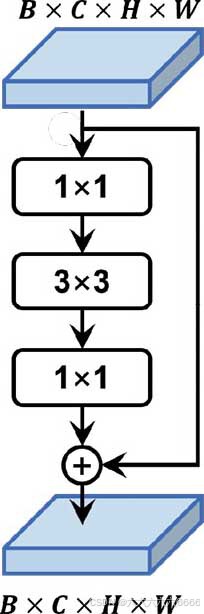
YOLOv3的第一处改进便是更换了更好的主干网络:DarkNet-53。相较于DarkNet-19,新的网络使用了更多层的卷积—53层卷积,每一层卷积依旧是先前所提到的“卷积三件套”:线性卷积、BN层以及LeakyReLU激活函数。同时,DarkNet-53还借鉴了当时已经是主流的由ResNet提出的残差连接结构。下图展示了DarkNet-53的网络结构。
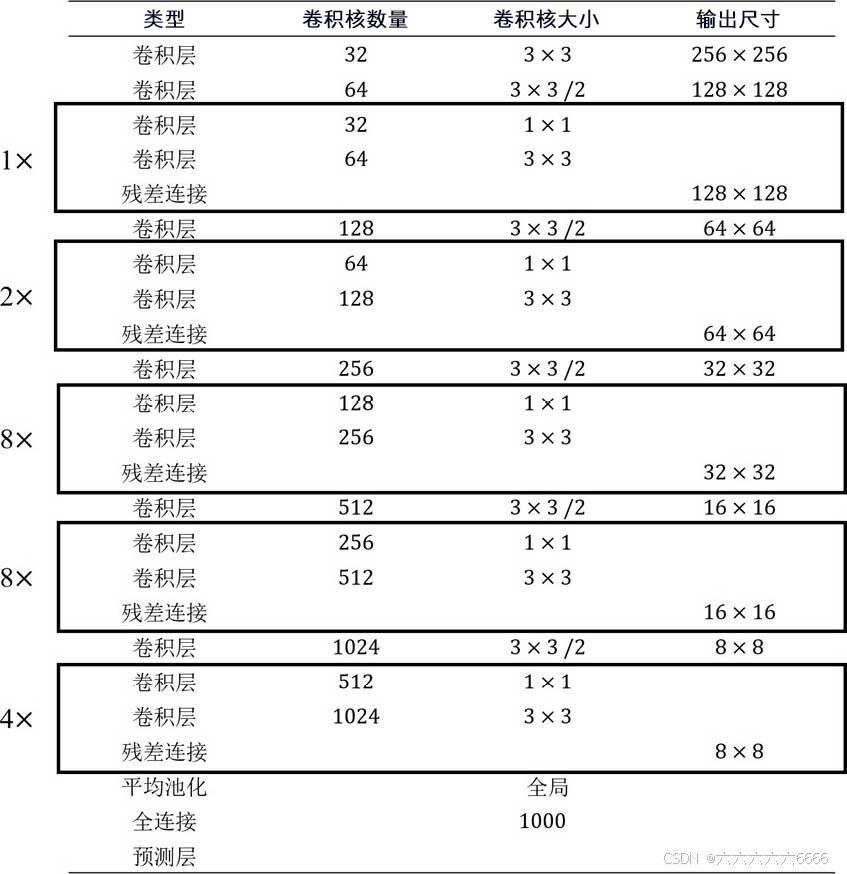


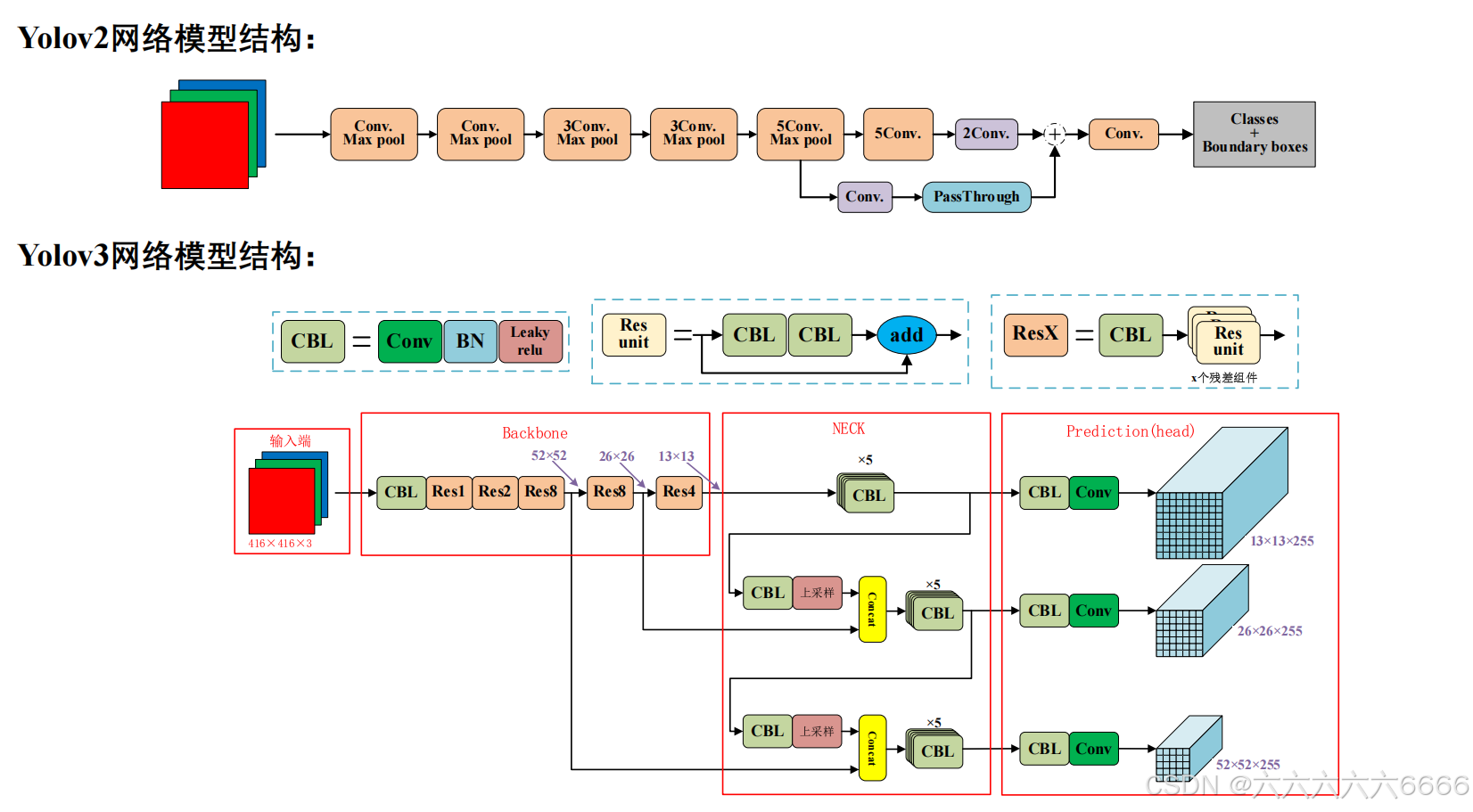
下图是Yolov2和Yolov3结构图的对比
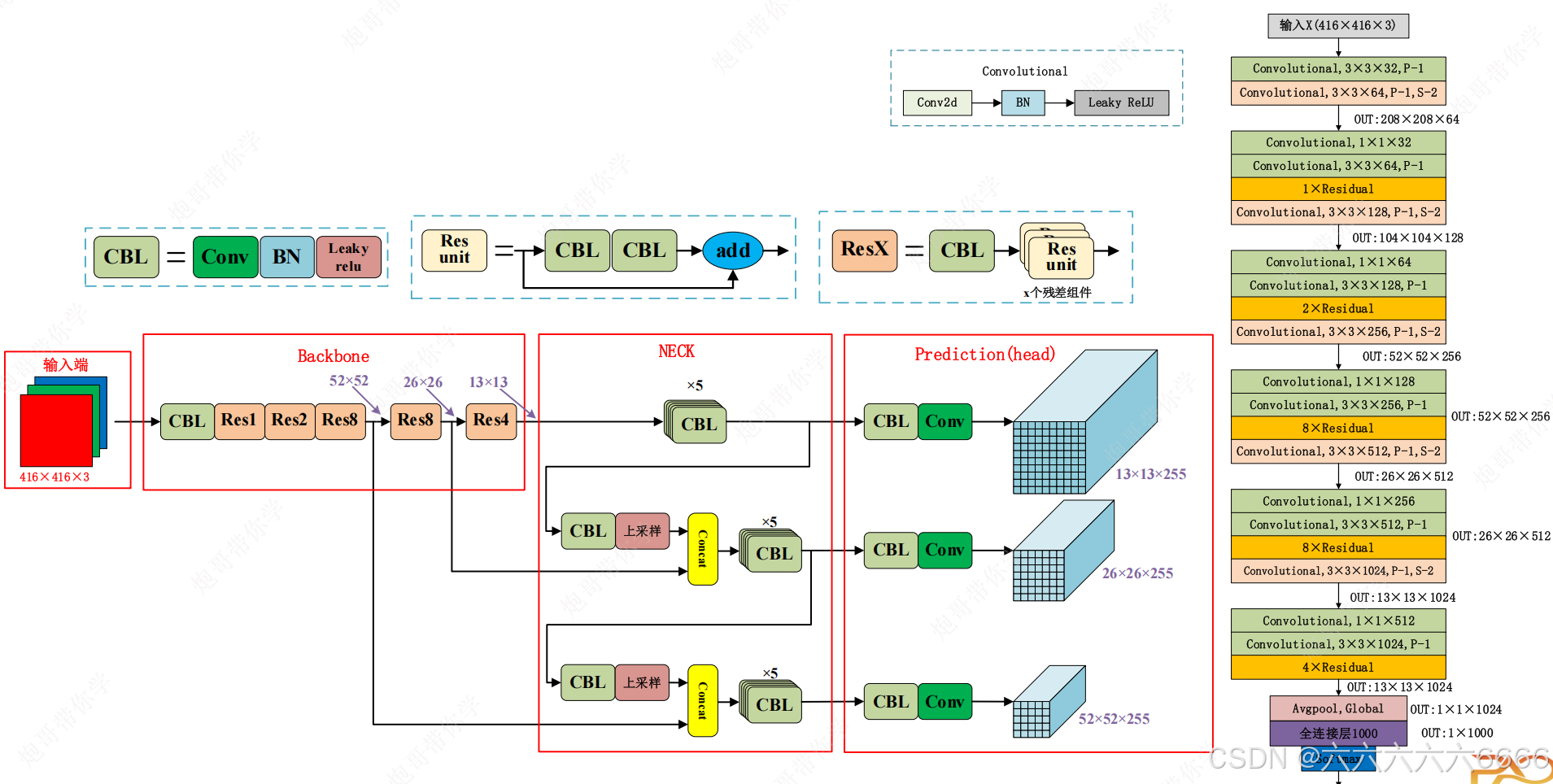
Yolov3分类模型具体参数
三、多级检测与特征金字塔
SSD网络大概是第一个为通用目标检测任务提出“多级检测”架构的工作,虽然它在VOC数据集上的性能被同年出现的YOLOv2所超越,但是在难度更大的COCO数据集上,SSD的性能更优,尤其是在小目标检测上,SSD略胜一筹。这主要得益于“多级检测”的架构,即使用不同尺度的特征(具有不同大小的空间尺寸)去共同检测图像中的物体。
随后,在2017年,融合不同尺度的特征的“特征金字塔”网络(feature pyramid network,FPN)被提出,作者团队进一步思考了“多级检测”框架,并提出了“自顶向下的特征金字塔融合”结构来对其进行优化。该团队认为,对于一个卷积神经网络,随着层数的加深和降采样操作的增多,网络的不同深度所输出的特征图理应包含了不同程度的空间信息(有利于定位)和语义信息(有利于分类)。对于那些较浅的卷积层所输出的特征图,由于未被较多的卷积层处理,理应具有较浅的语义信息,但也因未被过多地降采样而具备较多的位置信息;而深层的特征图则恰恰相反,经过了足够多的卷积层处理后,其语义信息被大大加强,而位置信息则因经过太多的降采样处理而丢失了,目标的细节信息被破坏,致使对小目标的检测表现较差,同时,随着层数变多,网络的感受野逐渐增大,网络对大目标的识别越来越充分,检测大目标的性能自然更好。下图直观地展示了这一蕴含在当前主流的CNN层次化结构中的主要矛盾。
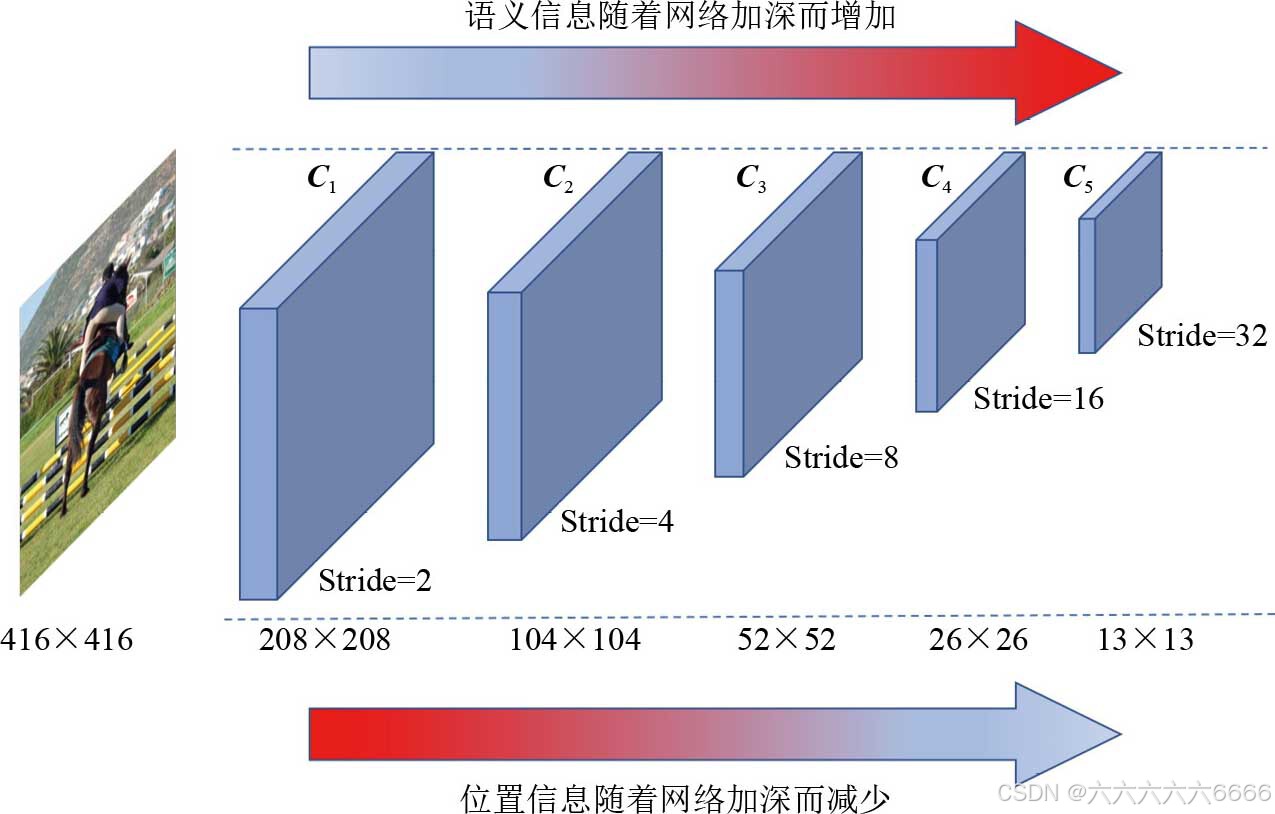
为了解决上一代YOLOv2的问题,YOLO作者团队在这一次改进中引入了“多级检测”和“自顶向下的特征融合”这一对搭配。相较于最初提出的特征金字塔结构,YOLO作者团队在此基础上做了些许改进,下图所示

相较于原版的FPN结构,YOLOv3所设计的FPN要略微复杂一些,比如特征融合时采用的是通道拼接(concatenate)操作,而非求和操作,同时,使用的卷积层也更多一些。

四、检测头结构
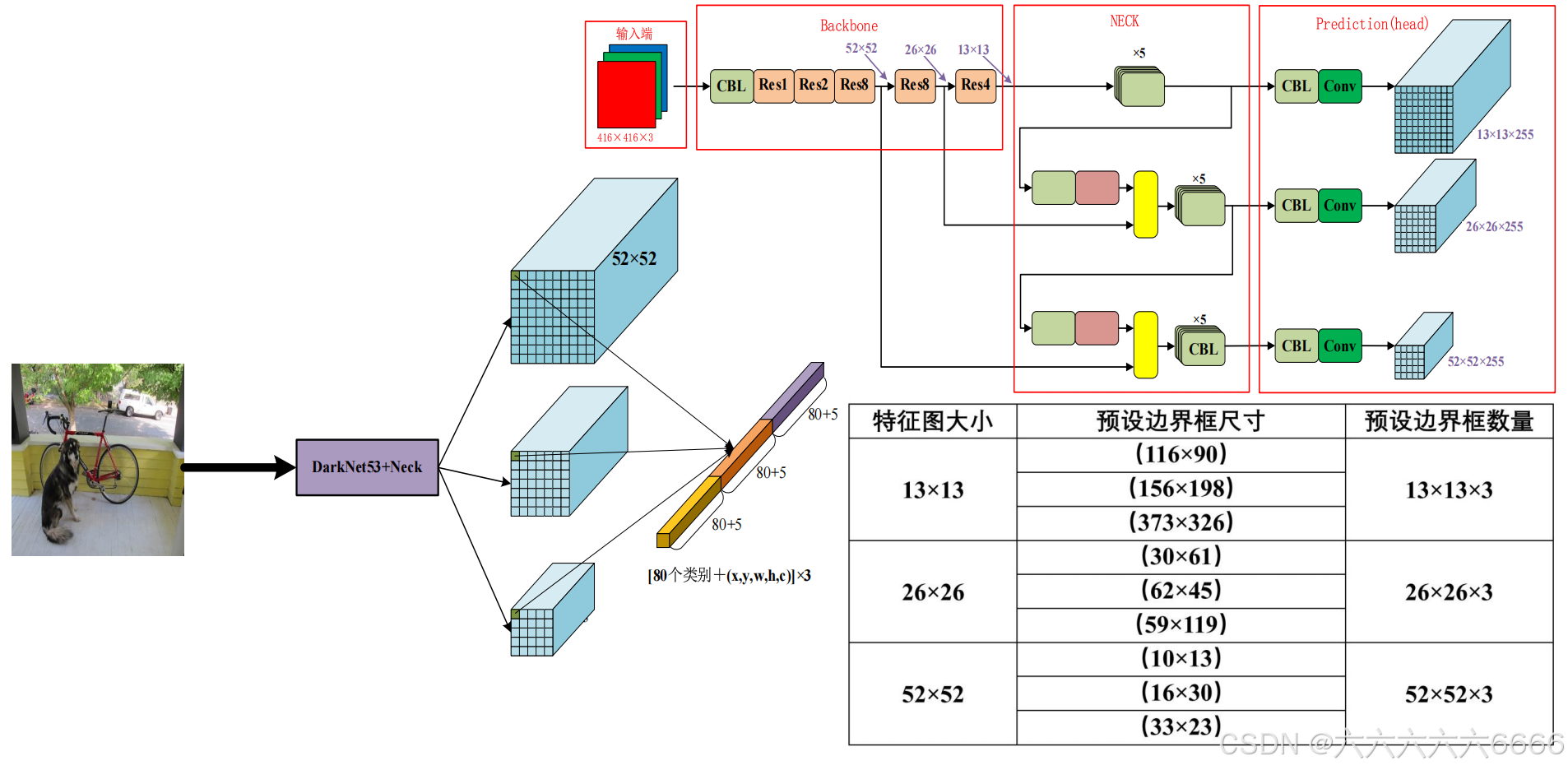
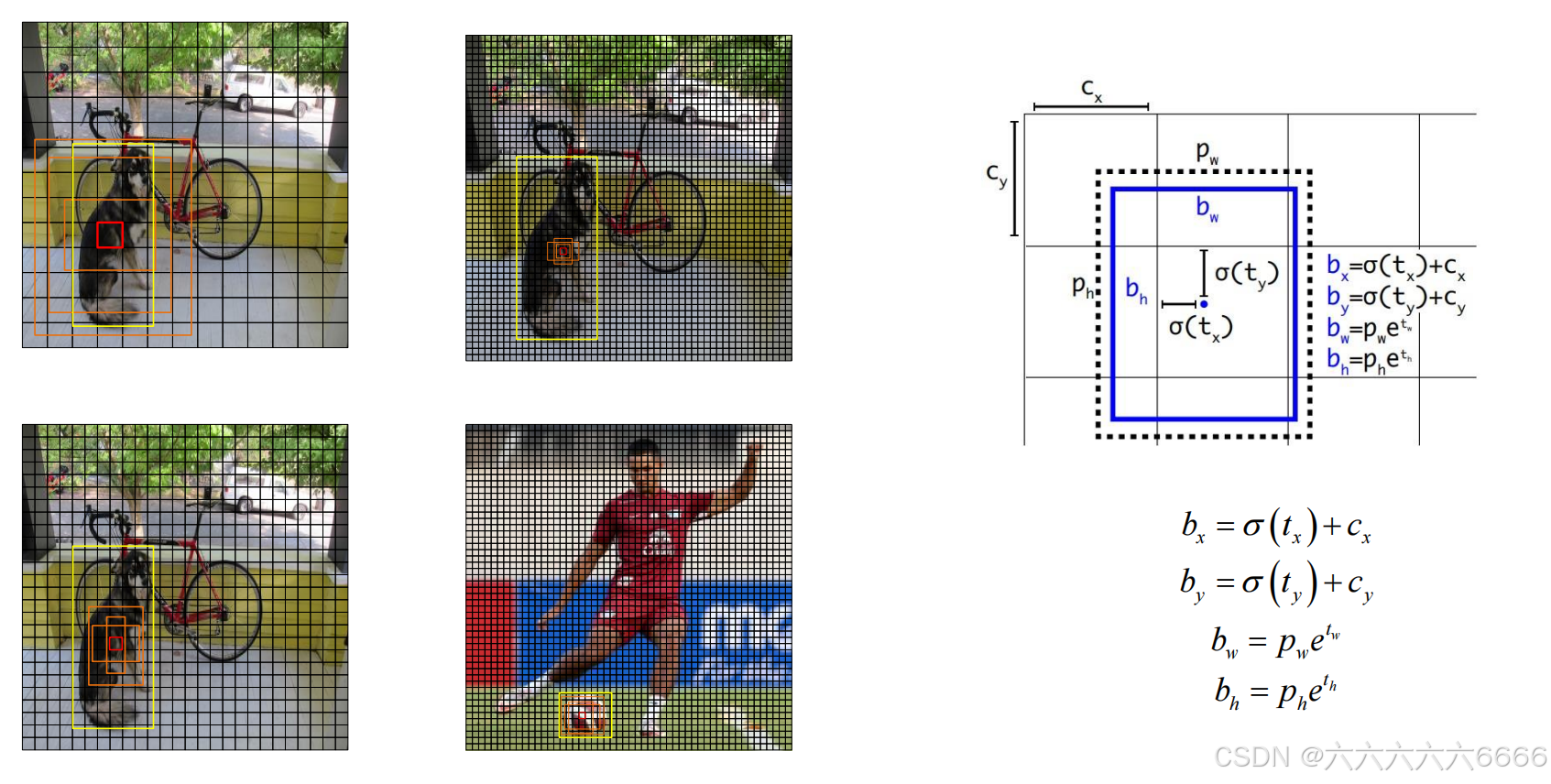
五、Yolov3 模型具体参数和正负样本
1.具体参数

2.正负样本
- 预 测 框 一 共 分 为 三 种 情 况 : 正 例 (positive) 、 负 例(negative)、忽略样例(ignore)。
- 正例:任取一个标注框,与全部计算IOU,IOU最大的预测框,即为正例。并且一个预测框,只能分配给一个标注框。例如第一个标注框已经匹配了一个正例检测框,那么下一个标注框,就在余下的检测框中,寻找IOU最大的检测框作为正例。标注框的先后顺序可忽略。正例产生置信度loss、检测框loss、类别loss。预测框坐标对应的标注框标签;类别标签对应类别为1,其余为0;置信度标签为1。
- 忽略样例:正例除外,与任意一个ground truth的IOU大于阈值(论文中使用0.5),则为忽略样例。忽略样例不产生任何loss。
- 负例:正例除外(与ground truth计算后IOU最大的检测框,但是IOU小于阈值,仍为正例)与全部ground truth的IOU都小于阈值(0.5),则为负例。负例只有置信度产生loss、置信度标签为0。
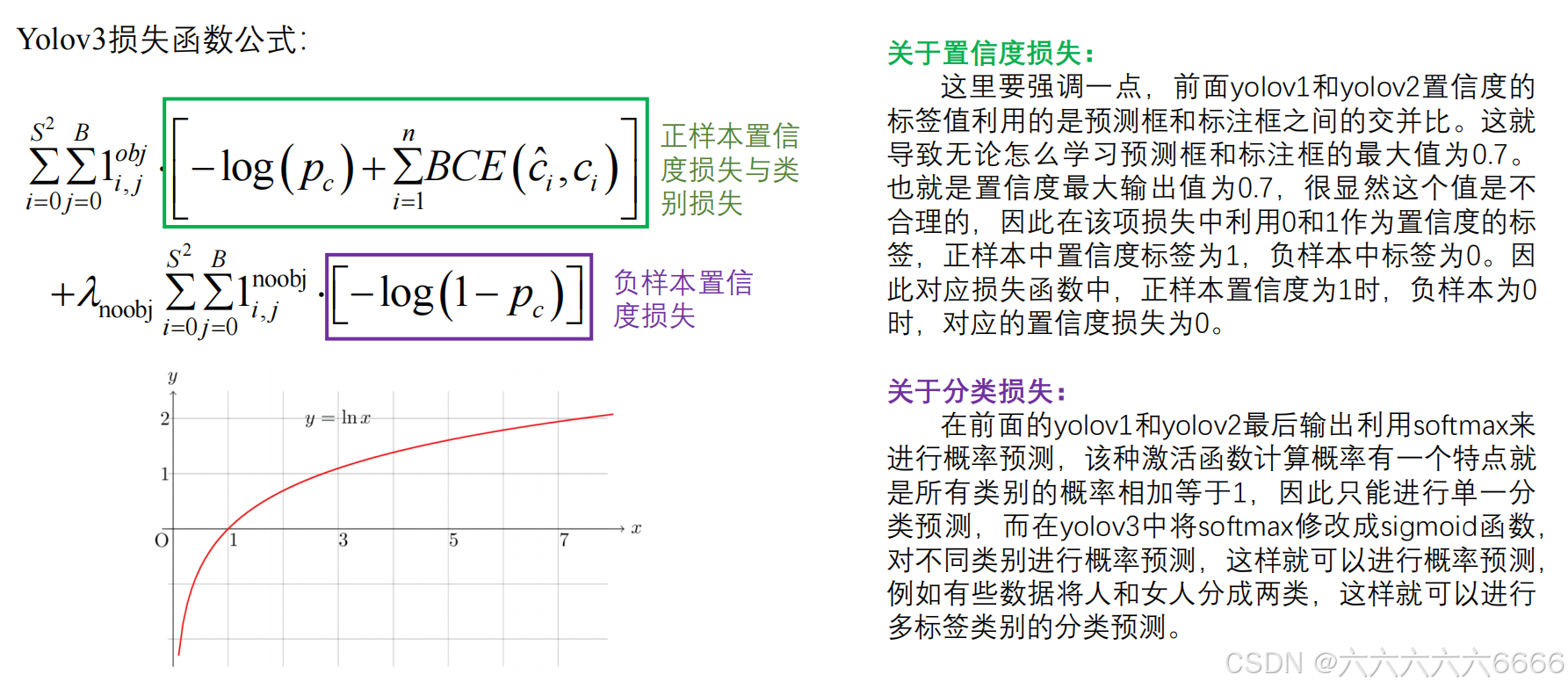
六、损失函数
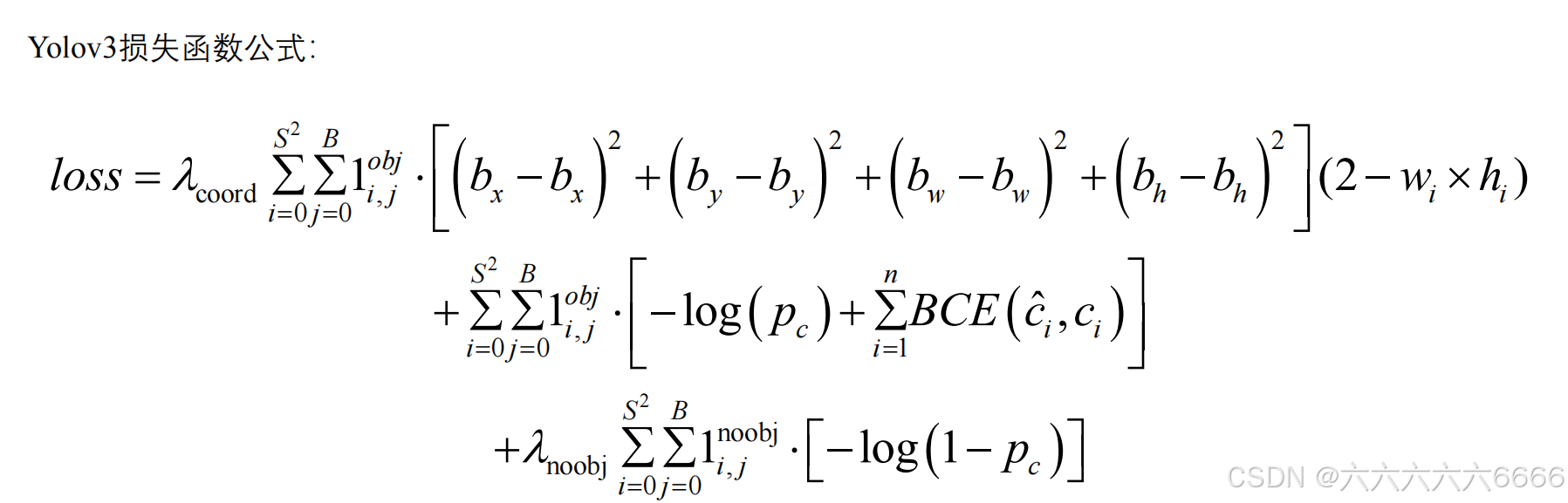

七、总结
- 多尺度检测:YOLOv3在三个不同的尺度上进行检测,提高了模型对于不同大小物体的识别能力。
- 在类别预测方面,YOLOv3采用了逻辑回归而非softmax,从而可以更好地处理多标签场景。
- 更多的Anchor Boxes:YOLOv3使用了多达9个锚框(分布在三个不同的尺度上),相比YOLOv2更能准确地适应不同形状和大小的目标。
- 更大的模型和更深的架构:YOLOv3使用了Darknet-53,一个比YOLOv2的Darknet-19更大、更深的网络架构,以获得更高的准确性。
- 新的损失函数:YOLOv3采用了一个新的损失函数,更加注重目标的定位和分类,使模型在多方面都得到了改进。
- 小目标检测仍有局限性:尽管YOLOv3通过多尺度检测做了一定程度的改进,但对于小目标的检测准确性相对仍然较低
- 高置信度的错误检测:YOLOv3可能会生成一些高置信度的错误检测,尤其是在目标密集或重叠的场景中