引入必要的库
import numpy as np
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score, classification_report生成自定义数据集
X, y = make_classification(n_samples=1000, n_features=10, n_informative=5, n_redundant=0, random_state=42)划分训练集和数据集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=50)创建并训练 SVM 分类器
# 创建 SVM 分类器实例,使用径向基函数(RBF)作为核函数
clf = SVC(kernel='rbf', random_state=50)
# 使用训练集对模型进行训练
clf.fit(X_train, y_train)模型预测与评估
# 使用训练好的模型对测试集进行预测
y_pred = clf.predict(X_test)
# 计算模型在测试集上的准确率
accuracy = accuracy_score(y_test, y_pred)
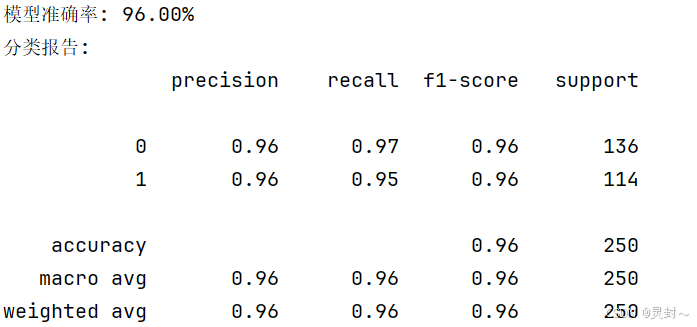
print(f"模型准确率: {accuracy * 100:.2f}%")
# 打印详细的分类报告,包含精确率、召回率、F1 值等信息
print("分类报告:")
print(classification_report(y_test, y_pred))结果展示