背景
在日常运维过程中,偶尔会碰到内核线程调度不及时的场景,针对“单个任务陷入内核台执行时间过长”这个case,字节跳动的同学开发了trace_noschedule模块,用来定位占用时间过长的任务和栈信息,本文就是要分析trace_noschedule模块的使用方法和实现原理。
项目地址
功能介绍
一图胜千言,我们看图说话
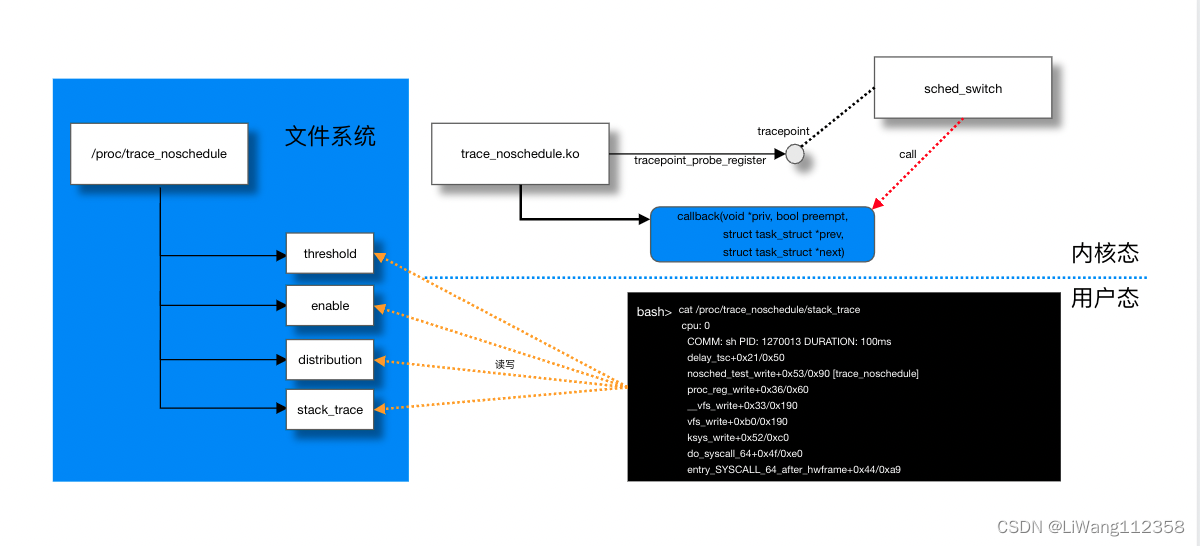
在使用trace_noschedule的时候,第一步是将编译好的模块安装到内核。
一旦安装成功,模块会在/proc中暴露出四个文件(图中左侧蓝色区域),用来对内核模块的行为进程控制,和读取输出。
一般使用的场景可能是这样
1. 发现线上机器有卡顿,比如icmp响应延迟,怀疑内核调度进程有延迟
2. 使用 perf sched 去看kirqsoftd的延迟,比如下面这样
perf sched record -- sleep 100
perf sched latency -p --sort max | grep soft
3. 确认有延迟之后,想要确认是谁的调度延迟比较大
4. 安装trace_noschedule
5. 向/proc/trace_noschedule/threshold 写入一个时间下限,超过这个时间限制的内核调度将被记录到/proc/trace_noschedule/stack_trace 中
6. 向/proc/trace_noschedule/enable写1,开启trace
7. cat /proc/trace_noschedule/stack_trace 查看调度延迟较大的栈
8. cat /proc/trace_noschedule/distribution 查看调度延迟分布
实现思路
trace_noschedule 利用了内核中 sched_switch这个静态插桩点,内核在调度任务的时候会调用我们注册的callback函数,原型是这样的
callback(void *priv, bool preempt,
struct task_struct *prev,
struct task_struct *next)
我们通过使用tracepoint_probe_register这个内核函数将回调函数注册上,函数原型如下
int tracepoint_probe_register(struct tracepoint *tp, void *probe, void *data)
tp 是tracepoint点,probe是回调函数,data是私有数据,在调用回调函数的时候被当作第一个参数传入,给用户一个机会保存自己的上下文信息。
既然有了这个trace点,我们很容易想到,只要在任务换入的时候记录初试时间,换出的时候记录结束时间,换出的时候发现差值大于我们设定的下限,就可以记录这个任务是一个长耗时调度任务。
但是这里有一个问题,我们什么时候记录栈呢,在换出的时候记录栈,显然这个时候已经不是引起调度耗时高的栈了,那么在进程一换入的时候就记录?也不行,原因有两个,第一,如果一换入就记录,那么有很多没有调度耗时高的栈就被记录了,记录的数据太多,并且大部分没有用,第二,还是没有办法确认调度高耗时时候的栈。
怎么解决呢,可以每经过一小段时间检查一下当前的任务耗时,一旦耗时超过下限,就记录一次栈,这时记录的栈是相对准确的。这里通过引入一个hrtimer来实现。
实现细节
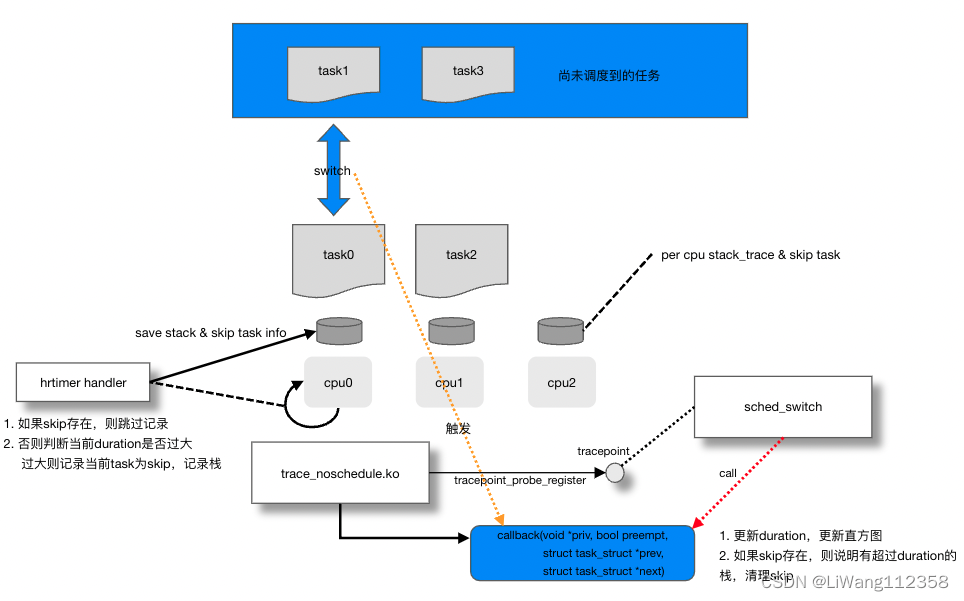
timer handler
我们先看timer handler的实现,看在什么时机记录栈
static enum hrtimer_restart trace_nosched_hrtimer_handler(struct hrtimer *hrtimer)
{
struct pt_regs *regs = get_irq_regs();
struct per_cpu_stack_trace *stack_trace;
u64 now = local_clock();
stack_trace = container_of(hrtimer, struct per_cpu_stack_trace,
hrtimer);
/**
* Skip the idle task and make sure we are not only the
* running task on the CPU. If we are interrupted from
* user mode, it indicate that we are not executing in
* the kernel space, so we should also skip it.
*/
if (!is_idle_task(current) && regs && !user_mode(regs) &&
!single_task_running()) {
u64 delta;
delta = now - stack_trace->last_timestamp;
if (!stack_trace->skip && stack_trace_record(stack_trace, delta))
stack_trace->skip = current;
} else {
stack_trace->last_timestamp = now;
}
hrtimer_forward_now(hrtimer, ns_to_ktime(sampling_period));
return HRTIMER_RESTART;
}
这里有比较重要的两句话
-
!is_idle_task(current) && regs && !user_mode(regs) && !single_task_running()
这里是说“什么时候要计算延时呢”,前提必须是“被timer中断的不是idle进程”,“被timer中断的不是用户态上下文”,“cpu不是只执行一个任务”
在这三条都满足的情况下,必然是在内核态的某个上下文被中断到timer的上下文的,所以这时如果发现duration大于下限(注意这个判断大于是在stack_trace_record做的,如果小于于则返回false),就可以做以下两个动作- 记录栈
- 将当前进程task标记给skip变量
-
if (!stack_trace->skip && stack_trace_record(stack_trace, delta))
如果有skip被记录了,说明当前的任务已经被记录栈了,跳过
否则进入stack_trace_record逻辑
在看一下的实现细节static inline bool stack_trace_record(struct per_cpu_stack_trace *stack_trace, u64 delta) { if (unlikely(delta >= duration_threshold)) return __stack_trace_record(stack_trace, get_irq_regs(), delta); return false; }
最后的return false很重要,这里如果delta小于duration_threshold,则不更新skip
callback
再看一下callback的实现probe_sched_switch
static void probe_sched_switch(void *priv, bool preempt,
struct task_struct *prev,
struct task_struct *next)
{
u64 now = local_clock();
struct per_cpu_stack_trace __percpu *stack_trace = priv;
struct per_cpu_stack_trace *cpu_stack_trace = this_cpu_ptr(stack_trace);
u64 last = cpu_stack_trace->last_timestamp;
if (unlikely(!trace_enable))
return;
cpu_stack_trace->last_timestamp = now;
if (unlikely(cpu_stack_trace->skip)) {
unsigned int index = cpu_stack_trace->nr_stack_entries - 1;
cpu_stack_trace->skip = NULL;
cpu_stack_trace->duration[index] = now - last;
}
/**
* Skip the idle task and make sure we are not only the
* running task on the CPU.
*/
if (!is_idle_task(prev) && !single_task_running())
hist_update(cpu_stack_trace, now - last);
}
可以这里根本没有用到,第2 3 4这几个参数,所有的上下文都通过priv获取,这里面有skip信息,但是这个skip一般不会有,所以是unlikely(cpu_stack_trace->skip)
output
首先必须读懂下面三个宏
#define MAX_STACE_TRACE_ENTRIES \
(MAX_TRACE_ENTRIES / PER_TRACE_ENTRIES_AVERAGE)
#define DEFINE_PROC_ATTRIBUTE(name, __write) \
static int name##_open(struct inode *inode, struct file *file) \
{ \
return single_open(file, name##_show, PDE_DATA(inode)); \
} \
\
static const struct file_operations name##_fops = { \
.owner = THIS_MODULE, \
.open = name##_open, \
.read = seq_read, \
.write = __write, \
.llseek = seq_lseek, \
.release = single_release, \
}
#define DEFINE_PROC_ATTRIBUTE_RW(name) \
static ssize_t name##_write(struct file *file, \
const char __user *buf, \
size_t count, loff_t *ppos) \
{ \
return name##_store(PDE_DATA(file_inode(file)), buf, \
count); \
} \
DEFINE_PROC_ATTRIBUTE(name, name##_write)
#define DEFINE_PROC_ATTRIBUTE_RO(name) \
DEFINE_PROC_ATTRIBUTE(name, NULL)
这里通过seq_file机制来实现/proc下面的文件读写
关于seq_file 请参考
linux seq_file机制学习
可以看到,在输出的时候需要实现name##_show这个函数
比如DEFINE_PROC_ATTRIBUTE_RW(stack_trace);定义了/proc/trace_noschedule/stack_trace的读写方式
就需要实现stack_trace_show
static int stack_trace_show(struct seq_file *m, void *ptr)
{
int cpu;
struct per_cpu_stack_trace __percpu *stack_trace = m->private;
for_each_online_cpu(cpu) {
int i;
unsigned int nr;
struct per_cpu_stack_trace *cpu_stack_trace;
cpu_stack_trace = per_cpu_ptr(stack_trace, cpu);
/**
* Paired with smp_store_release() in the
* __stack_trace_record().
*/
nr = smp_load_acquire(&cpu_stack_trace->nr_stack_entries);
if (!nr)
continue;
seq_printf(m, " cpu: %d\n", cpu);
for (i = 0; i < nr; i++) {
struct stack_entry *entry;
entry = cpu_stack_trace->stack_entries + i;
seq_printf(m, "%*cCOMM: %s PID: %d DURATION: %llums\n",
5, ' ', cpu_stack_trace->comms[i],
cpu_stack_trace->pids[i],
cpu_stack_trace->duration[i] / (1000 * 1000UL));
seq_print_stack_trace(m, entry);
seq_putc(m, '\n');
cond_resched();
}
}
return 0;
}
值得一提的点
seq_print_stack_trace函数中
seq_printf(m, "%*c%pS\n", 5, ' ', (void *)entry->entries[i]);
%*c 是重复多少次字符串
%pS 是将地址转换为符号字符串