1. 基因分型Phasing概念
基因分型,也称为基因定相、单倍体分型、单倍体构建等,即将一个二倍体(或多倍体)基因组上的等位基因(或杂合位点)正确定位到父亲或母亲的染色体上,最终使得来自同一亲本的等位基因能排列在同一条染色体上。
二代测序是将序列混在一起进行测序,通过比对到参考基因组,检测存在哪些变异以及变异的基因型(Genotype),但无法直接区分序列是母源还是父源,只有通过基因分型才能判断亲本来源。
2. 基因分型的方法
家系分型和LD分型常用的工具有Beagle和Shapeit,都包含了家系分型和LD分型模块。
2.1 家系分型
家系分型是目前构建单倍型最准确的方法,家系样本越多,分型效果越好,缺点就是需要家系Trio样本,对于无法获取家系样本时则无法完成分型,并对于父亲、母亲和子女都是杂合的位点无法进行分型(大约占总变异位点的1/5)。
2.2 LD分型
利用群体中大量无血缘关系的个体,根据LD(连锁不平衡)原理和数据模型,推断群体中每个个体的单倍型方法。通过人群频率大于5%的变异存在的LD block(Tajima’s D > 0.5)长度大多为50kbp-60kbp,block的长度在不同人种中不相同,非洲人由于更古老因此姐妹染色单体发生重组的次数会更多,LD block相比于其他人种长度更短。由于LD block的存在,因此可以利用数学模型(如HMM算法)反推出个体的单倍型。
LD分型精度受到群体的影响,对于人群频率大于5%的变异分型效果很好,但对于罕见变异和低频变异(<1%)的效果较差,因此很难获得个体完整的单倍型。
2.3 物理分型
一条reads/一对reads或克隆上存在的碱基必定来自同一条染色体,每个片段就是单倍体的局部,将局部连接为整体即可完成Phasing。物理分型不需要家系数据,无需借助LD关系,仅依赖自身的测序数据,就可以完成Phasing。物理分型依赖于reads上的杂合SNP位点作为区分标记,由于人类基因组杂合SNP之间的距离大约为1.5kpb,因此需要长序列的测序技术(三代PacBio、ONT和华大Long Fragment Read-LFR等)获取测序数据。
3. 遗传解读中的应用
在遗传解读时,需要获取基因突变位点的相位后,才能更好地判断突变是否会产生对应的表型。当一个等位基因的一个拷贝发生了变异(例如LOF,功能缺失或缺失等),由于存在另一个拷贝,基因表达可能不会受到影响,从而不具有表型,只有当两个拷贝都发生变异时,才影响基因的表达从而产生表型。
4. 人类单倍型参考序列Reference Consortium(HRC)
基因型推断(Imputation)
需要单倍型参考序列集作为基础数据,在全基因组关联分析GWAS中是必要的环节,参考基因序列的质量直接影响了后续基因型-表型关联分析的结果。
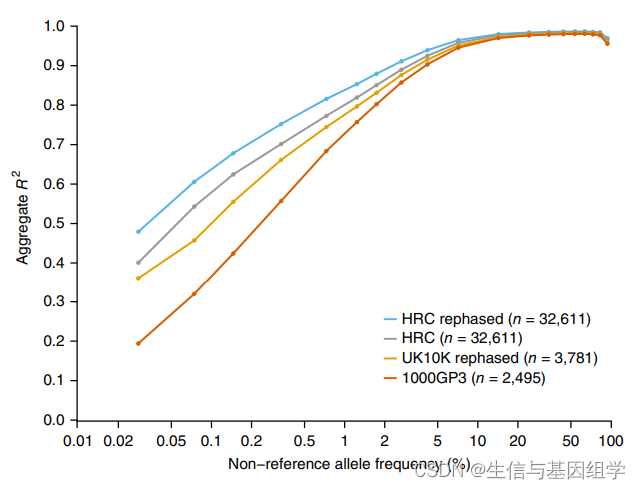
HRC是一个大型的人类单倍型参考序列,合并了多个项目的测序数据。全基因组SNP微阵列芯片获得样本基因型后,可使用该单倍型参考基因组进行基因型的推断(或称为填充)和定相,GWAS研究中运用较为常见。截止到2024年7月,HRC包含了64,976个人类单倍型和39,235,157个SNP。相比于1000G、UK10K数据库,采用HRC单倍型数据库基因型填充的准确率更高。
目前提供网页版的免费的基因型推断和定相服务-Sanger Imputation,网址如下:
https://www.sanger.ac.uk/tool/sanger-imputation-service/
基因型推断的工具网站:
https://imputation.sanger.ac.uk/
sanger网站需要上传VCF或23andMe格式的GWAS数据,预定相可选择EAGLE2或SHAPEIT 2,基因型推断PBWT算法,参考panels可选择1000 Genomes Phase 3, UK10K和 the Haplotype Reference Consortium。
https://imputationserver.sph.umich.edu/
HRC 只公开了部分数据提供下载,通过Request Access下载,链接如下:
https://ega-archive.org/datasets/EGAD00001002729
