一 准备数据库与数据表
学生表:
CREATE TABLE `student` (
`id` int NOT NULL AUTO_INCREMENT,
`name` varchar(255) DEFAULT NULL,
`age` int DEFAULT NULL,
`gender` varchar(255) DEFAULT NULL,
`class_id` int DEFAULT NULL,
`score` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=8 DEFAULT CHARSET=utf8mb3;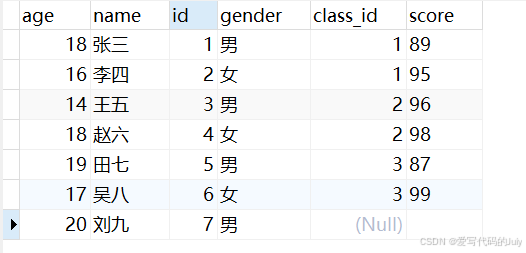
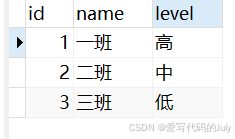
班级表 :
CREATE TABLE `class` (
`id` int NOT NULL,
`name` varchar(255) DEFAULT NULL,
`level` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb3;
二 内连接(inner join)
作用:通过某个条件查询两张表之间的交集
基本语法(inner可以省略):
select * from 表A inner join 表B on 判断条件;
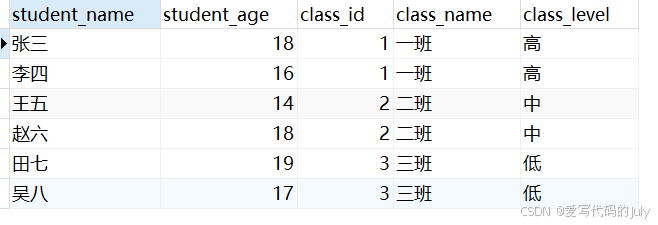
select * from 表A join 表B on 判断条件;根据学生表和班级表之间的班级编号进行匹配,返回学生姓名(
student_name)、学生年龄(student_age)、班级编号(class_id)、班级名称(class_name)、班级级别(class_level)。select s.name student_name, s.age student_age, s.class_id class_id, c.name class_name, c.level class_level from student s join class c on s.class_id = c.id;运行结果(没有分配班级的学生“刘九”没有被查询到):
二 外连接查询 (outer join)
作用:分为左外连接(left join)和右外连接(right join)。以左表(或右表)为主表,查询全部信息,通过关联条件与另一张表合并,辅表中不存在的信息显示为空。

基本语法:
select * from 表A left join 表B on 判断条件;
select * from 表A right join 表B on 判断条件; 根据学生表和班级表之间的班级编号进行匹配,返回学生姓名(
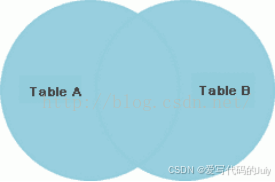
student_name)、学生年龄(student_age)、班级编号(class_id)、班级名称(class_name)、班级级别(class_level),要求必须返回所有学生的信息(即使对应的班级编号不存在)。select s.name student_name, s.age student_age, s.class_id class_id, c.name class_name, c.level class_level from student s left join class c on s.class_id = c.id;运行结果(没有被分配班级的学生“刘九”的相关信息也被查询出来了,班级信息显示为null):
外连接查询还包括全外连接(full join)查询,即查询出两张表中的所有数据信息。
基本语法:
select * from 表A full join 表B on 判断条件; 但是需要注意,MySQL中不支持这种用法。
三 关联查询(cross join)
作用:不需要任何条件来匹配行,它直接将左表的每一行与右表的每一行进行组合,返回的结果是两个表的笛卡尔积。
基本语法():
select * from 表A,表B
将学生表和班级表的所有行组合在一起,并返回学生姓名(student_name)、学生年龄(student_age)、班级编号(class_id)以及班级名称(class_name)。
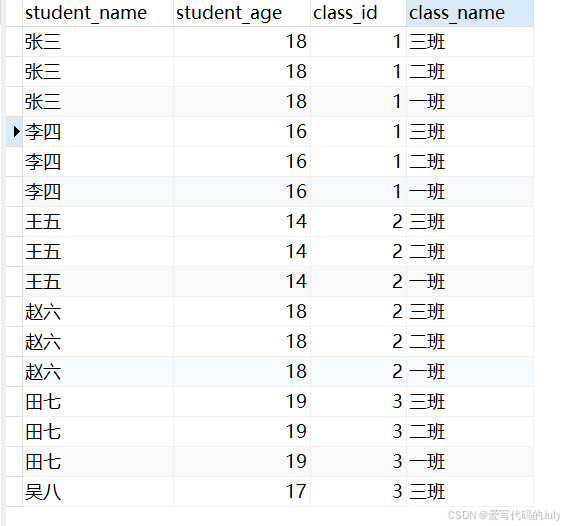
select s.name student_name, s.age student_age, s.class_id class_id, c.name class_name from student s, class c;运行结果(主表中有7条数据,班级表中有3条数据,返回了7*3条数据):
四 联合查询(union)
作用:与full join相同,查询多表之间的全部信息。MySQL 不识别 FULL join,只能通过 union 来实现。
UNION 操作:它用于将两个或多个查询的结果集合并, 并去除重复的行 。即如果两个查询的结果有相同的行,则只保留一行。
UNION ALL 操作:它也用于将两个或多个查询的结果集合并, 但不去除重复的行 。即如果两个查询的结果有相同的行,则全部保留。
基本语法:
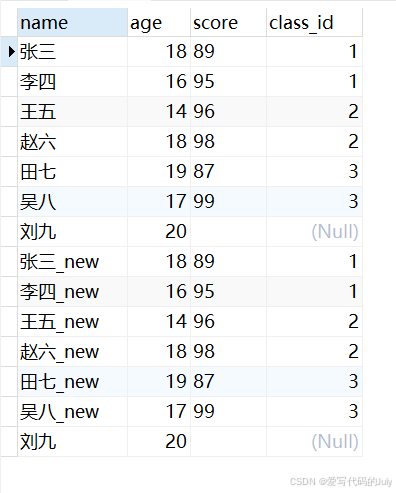
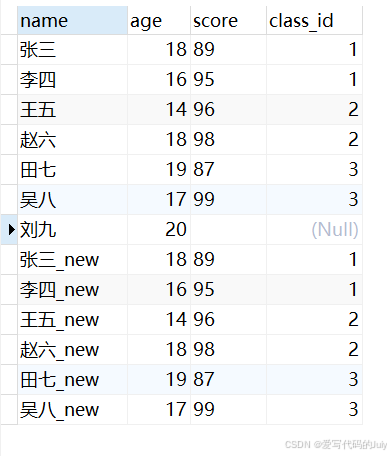
select * from 表A union (all) select * from 表B新建一张student_new表,表结构与student表相同。获取所有学生表和新学生表的学生姓名(
name)、年龄(age)、分数(score)、班级编号(class_id)字段,要求保留重复的学生记录。select name, age, score, class_id from student union all select name, age, score, class_id from student_new;查询结果(相同数据“刘九”显示了两遍):
select name, age, score, class_id from student union select name, age, score, class_id from student_new;运行结果(相同学生信息“刘九”只显示了一遍):
五 子查询
作用:在一个查询语句内部嵌套另一个完整的查询语句,内层查询被称为子查询。子查询可以用于获取更复杂的查询结果或者用于过滤数据。当执行包含子查询的查询语句时,数据库引擎会首先执行子查询,然后将其结果作为条件或数据源来执行外层查询。
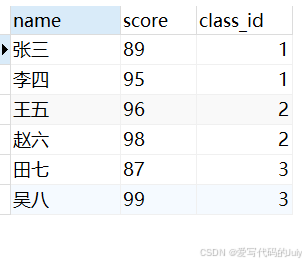
使用子查询的方式来获取存在对应班级的学生的所有数据,返回学生姓名(
name)、分数(score)、班级编号(class_id)字段。select name, score, class_id from student where class_id in ( select distinct id from class );运行结果(只查询出了class_id字段在class表中的数据):
本篇习题来源:SQL进阶之路 (easycode.top)