一.实验目的
1.掌握单周期CPU数据通路图的构成、原理及其设计方法
2.掌握单周期CPU的实现方法,代码实现方法
3.认识和掌握指令与CPU的关系
4.掌握测试单周期CPU的方法
二.实验内容
设计一个单周期CPU,该CPU至少能实现以下指令功能操作。需设计的指令与格式如下:


三.实验原理
单周期CPU指的是一条指令的执行在一个时钟周期内完成,然后开始下一条指令的执行,即一条指令用一个时钟周期完成。电平从低到高变化的瞬间称为时钟上升沿,两个相邻时钟上升沿之间的时间间隔称为一个时钟周期。时钟周期一般也称振荡周期。
CPU在处理指令时,一般需要经过以下几个步骤:
(1) 取指令(IF):根据程序计数器PC中的指令地址,从存储器中取出一条指令,同时,PC根据指令字长度自动递增产生下一条指令所需要的指令地址,但遇到“地址转移”指令时,则控制器把“转移地址”送入PC,当然得到的“地址”需要做些变换才送入PC。
(2) 指令译码(ID):对取指令操作中得到的指令进行分析并译码,确定这条指令需要完成的操作,从而产生相应的操作控制信号,用于驱动执行状态中的各种操作。
(3) 指令执行(EXE):根据指令译码得到的操作控制信号,具体地执行指令动作,然后转移到结果写回状态。
(4) 存储器访问(MEM):所有需要访问存储器的操作都将在这个步骤中执行,该步骤给出存储器的数据地址,把数据写入到存储器中数据地址所指定的存储单元或者从存储器中得到数据地址单元中的数据。
(5) 结果写回(WB):指令执行的结果或者访问存储器中得到的数据写回相应的目的寄存器中。
单周期CPU,是在一个时钟周期内完成这五个阶段的处理。


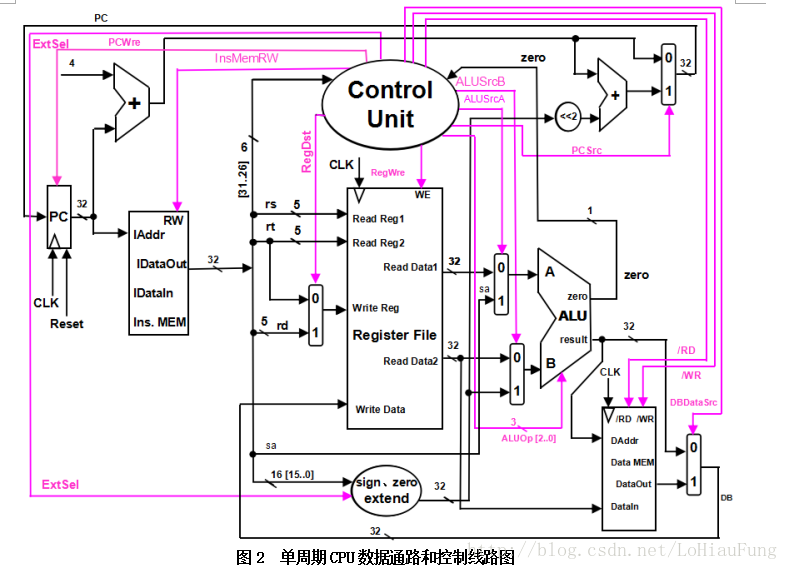
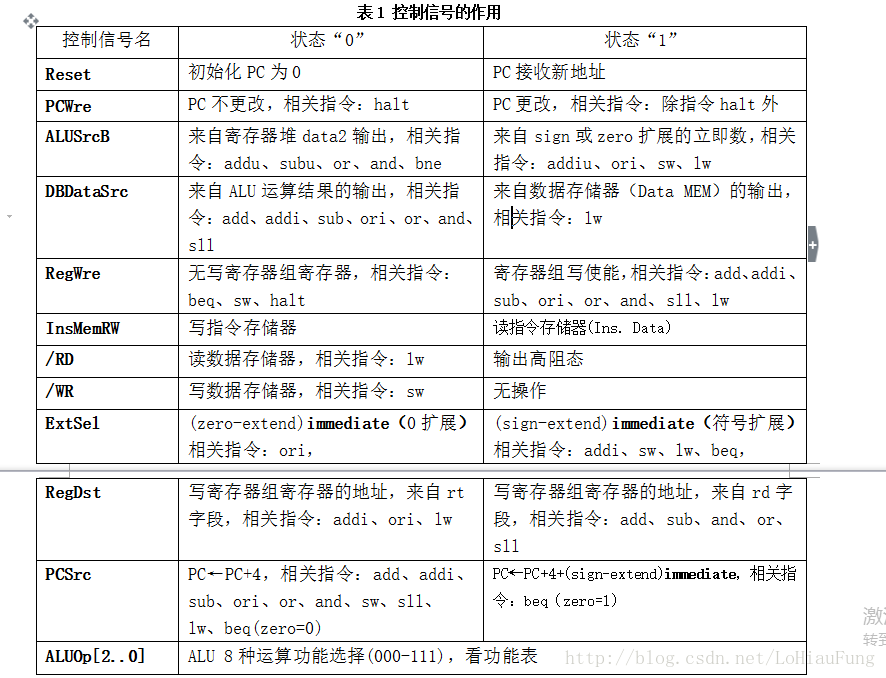
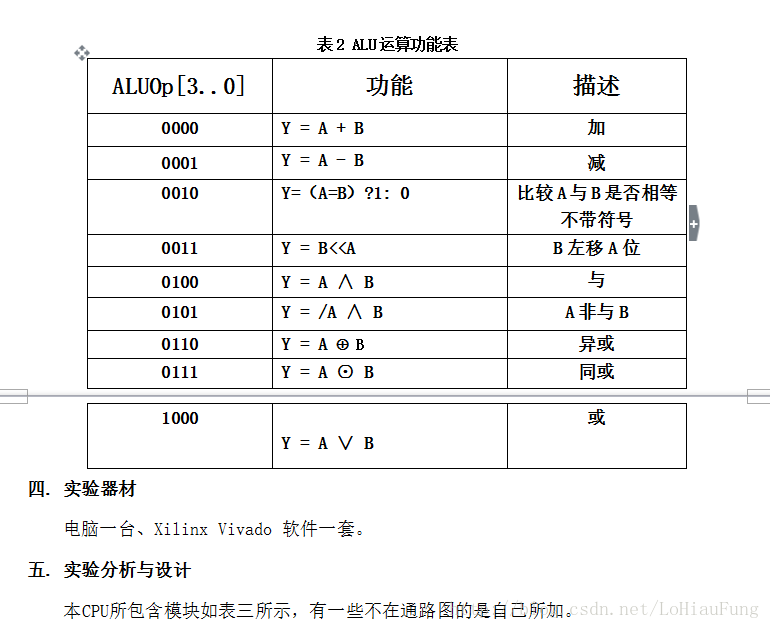
图2是一个简单的基本上能够在单周期CPU上完成所要求设计的指令功能的数据通路和必要的控制线路图。其中指令和数据各存储在不同存储器中,即有指令存储器和数据存储器。访问存储器时,先给出地址,然后由读或写信号控制操作。对于寄存器组,读操作时,先给出地址,输出端就直接输出相应数据;而在写操作时,在 WE使能信号为1时,在时钟边沿触发写入。图中控制信号作用如表1所示,表2是ALU运算功能表。

1.InstructionMemory
该模块实现了根据RW信号读Iaddr地址的指令的功能,写指令功能因为本实验没有用到,注释掉了。在初始化的时候,本模块先用系统调用$readmemb装载指令。
module InstructionMemory(
input [31:0] Iaddr, // 指令存储器地址输入端口
// input [31:0] IDataIn, // 指令存储器数据输入端口(指令代码输入端口)
input RW, // 指令存储器读写控制信号,为1写,为0读
output reg[31:0] IDataOut // 指令存储器数据输出端口(指令代码输出端口)
);
reg[7:0] storage [127:0];
always @(RW or Iaddr ) begin
if(RW == 1) begin //write
/* 本次实验不需要用到写指令功能
storage[Iaddr] <= IDataIn[7:0];
storage[Iaddr + 1] <= IDataIn[15:8];
storage[Iaddr + 2] <= IDataIn[23:16];
storage[Iaddr + 3] <= IDataIn[31:24];
*/
end
else begin // read
IDataOut[7:0] <= storage[Iaddr + 3];
IDataOut[15:8] <= storage[Iaddr + 2];
IDataOut[23:16] <= storage[Iaddr + 1];
IDataOut[31:24] <= storage[Iaddr];
end
end
initial begin
$readmemb("F:/ECOP_Experiment/CPU/CPU.srcs/sources_1/new/ins.txt",storage);
end
endmodule
2.ALU32
ALU实现不复杂,根据表2,对每个opCode实现对应的运算,输出便可。
module ALU32(
input [3:0] ALUopcode,
input [31:0] rega,
input [31:0] regb,
output reg [31:0] result,
output zero
);
assign zero = (result==0)?1:0;
always @( ALUopcode or rega or regb ) begin
case (ALUopcode)
4'b0000 : result = rega + regb;
4'b0001 : result = rega - regb;
4'b0010 : result = (rega == regb)?1:0;
4'b0011 : result = regb << rega;
4'b0100 : result = rega & regb;
4'b0101 : result = (!rega) & regb;
4'b0110 : result = rega ^ regb;
4'b0111 : result = rega ^~ regb
4'b1000 : result = rega | regb;
// 4'b1001 : result = (rega < regb)?1:0;
default : begin
result = 32'h00000000;
$display (" no match");
end
endcase
end
endmodule3.CU
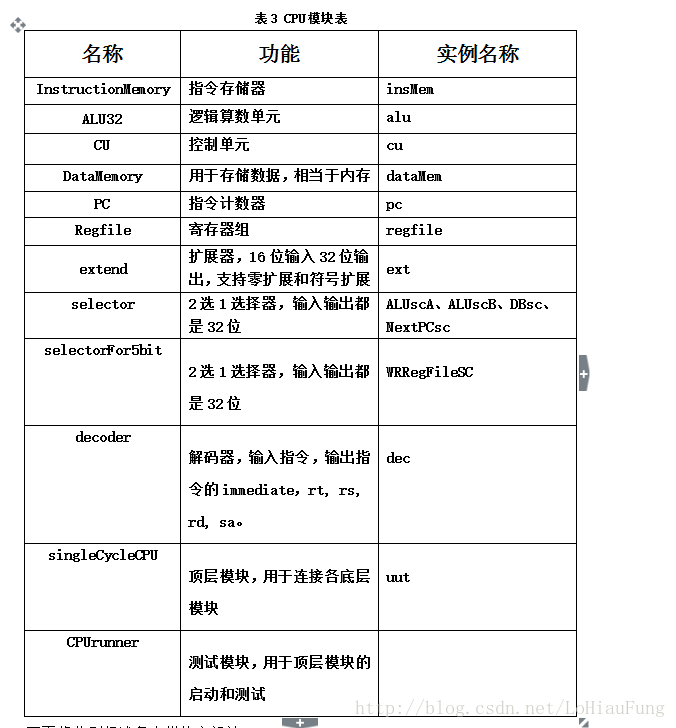
CU的设计较为复杂,实现的功能主要是根据输入的操作码opCode和ALU的zero信号来控制各个信号的输出。根据表1和表2,我们可以得出表3的ALU输出信号真值表。根据该表,实现每种输入对应的使出便可,如图6、图7、图8所示。