注意:此教程仅供技术学习参考!!!!!!!!!
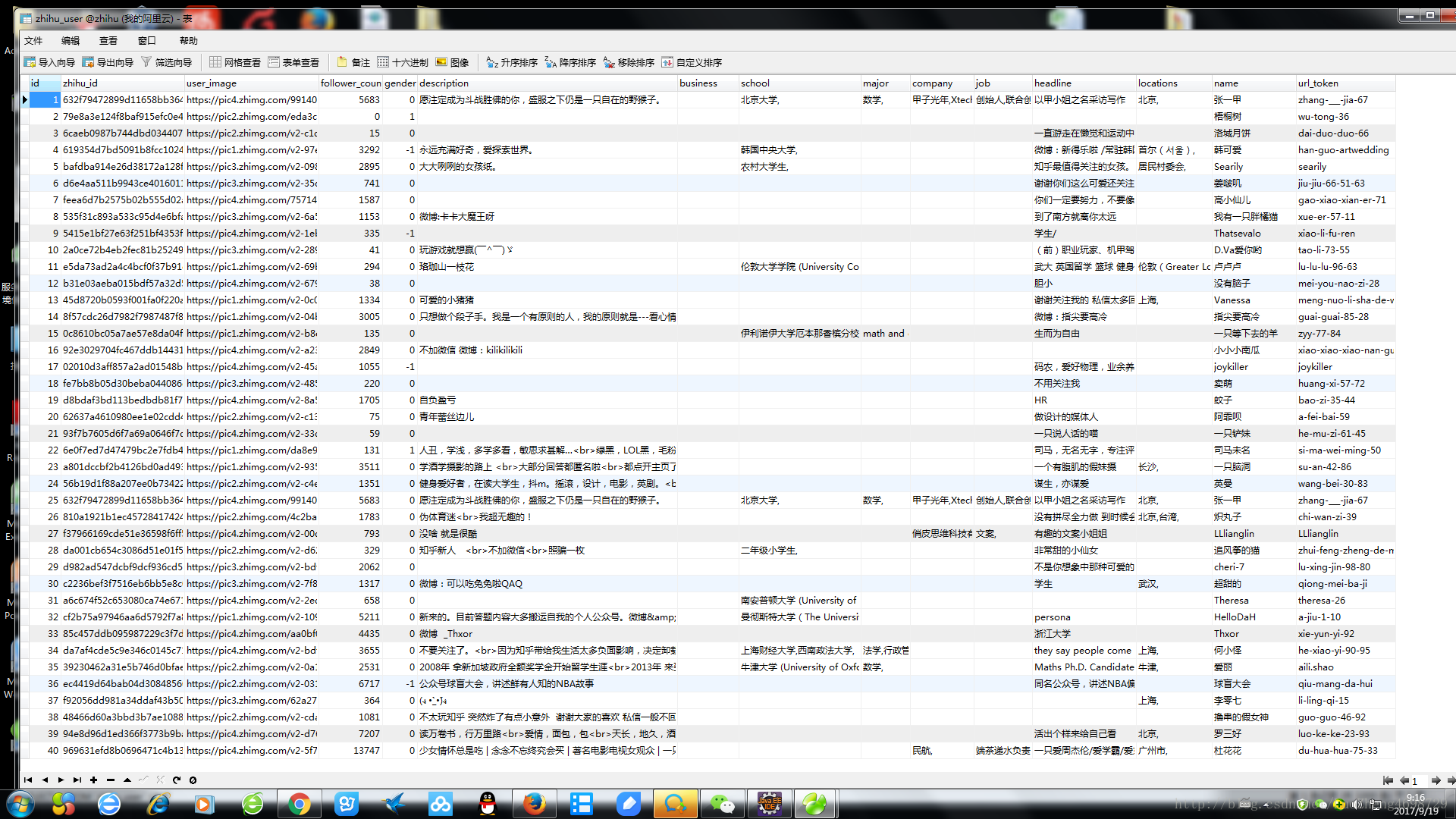
1.今天来介绍下用scrapy爬取知乎某个人圈子的用户信息。本文需要懂scrapy框架,不懂的请先自学,爬取结果如下图:
2.实现
2.1新建数据存储表。
CREATE TABLE `zhihu_user` (
`id` int(10) NOT NULL AUTO_INCREMENT COMMENT '主键id',
`zhihu_id` varchar(100) COLLATE utf8_unicode_ci DEFAULT NULL COMMENT '知乎自己的主键',
`user_image` varchar(100) COLLATE utf8_unicode_ci DEFAULT NULL COMMENT '用户头像',
`follower_count` int(10) DEFAULT '0' COMMENT '关注它的人',
`gender` int(10) DEFAULT '0' COMMENT '性别, 1-男; 2-女',
`description` varchar(500) COLLATE utf8_unicode_ci DEFAULT NULL COMMENT '个人简介',
`business` varchar(500) COLLATE utf8_unicode_ci DEFAULT NULL COMMENT '所在行业',
`school` varchar(500) COLLATE utf8_unicode_ci DEFAULT NULL COMMENT '学校',
`major` varchar(500) COLLATE utf8_unicode_ci DEFAULT NULL COMMENT '专业',
`company` varchar(500) COLLATE utf8_unicode_ci DEFAULT NULL COMMENT '公司',
`job` varchar(500) COLLATE utf8_unicode_ci DEFAULT NULL COMMENT '工作类型',
`headline` varchar(500) COLLATE utf8_unicode_ci DEFAULT NULL COMMENT 'headline',
`locations` varchar(500) COLLATE utf8_unicode_ci DEFAULT NULL COMMENT '居住地',
`name` varchar(500) COLLATE utf8_unicode_ci DEFAULT NULL COMMENT 'name',
`url_token` varchar(50) COLLATE utf8_unicode_ci DEFAULT NULL COMMENT 'url_token',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=2055 DEFAULT CHARSET=utf8 COLLATE=utf8_unicode_ci COMMENT='知乎用户表';2.2items.py 定义要抓取的字段,这里跟数据库表字段保持一致
import scrapy
class MytestItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
zhihu_id = scrapy.Field()
user_image = scrapy.Field()
follower_count = scrapy.Field()
gender = scrapy.Field()
description = scrapy.Field()
business = scrapy.Field()
school = scrapy.Field()
major = scrapy.Field()
company = scrapy.Field()
job = scrapy.Field()
headline = scrapy.Field()
locations = scrapy.Field()
name = scrapy.Field()
url_token = scrapy.Field()2.3分析爬取接口
我们要爬取某个知乎用户的圈子,所以得找一个开始人,首先爬取这个人详细信息,然后在爬取这个人关注的人
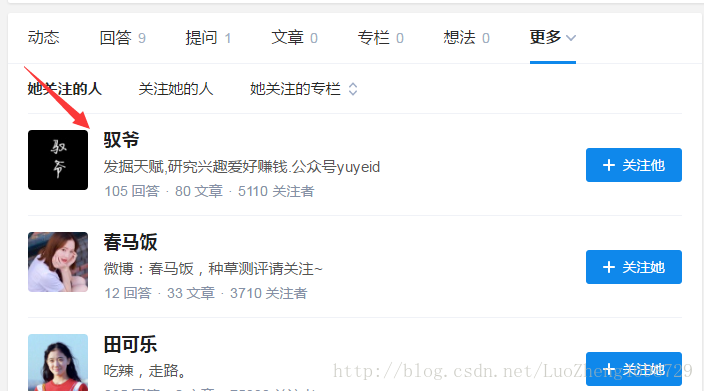
然后再爬取每一个关注的人的详细信息,在爬取关注人的关注的人,这样循环递归,就爬到了此人的圈子所有的用户信息。
这里选取了一位开始人美女 https://www.zhihu.com/people/wang-jing-15-15-28/activities , 打开F12找到
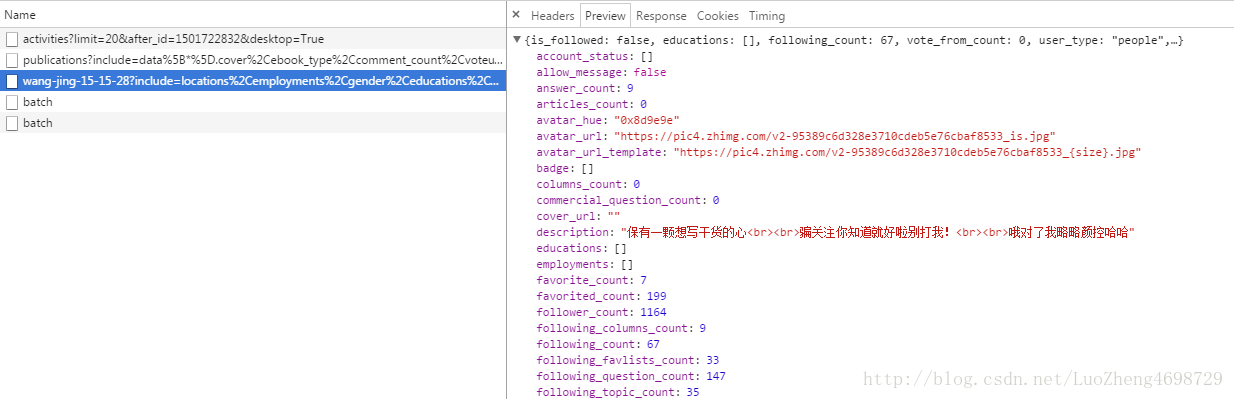
没错这个就是我们要找的用户详细接口:
https://www.zhihu.com/api/v4/members/wang-jing-15-15-28?include=locations%2Cemployments%2Cgender%2Ceducations%2Cbusiness%2Cvoteup_count%2Cthanked_Count%2Cfollower_count%2Cfollowing_count%2Ccover_url%2Cfollowing_topic_count%2Cfollowing_question_count%2Cfollowing_favlists_count%2Cfollowing_columns_count%2Cavatar_hue%2Canswer_count%2Carticles_count%2Cpins_count%2Cquestion_count%2Ccolumns_count%2Ccommercial_question_count%2Cfavorite_count%2Cfavorited_count%2Clogs_count%2Cmarked_answers_count%2Cmarked_answers_text%2Cmessage_thread_token%2Caccount_status%2Cis_active%2Cis_bind_phone%2Cis_force_renamed%2Cis_bind_sina%2Cis_privacy_protected%2Csina_weibo_url%2Csina_weibo_name%2Cshow_sina_weibo%2Cis_blocking%2Cis_blocked%2Cis_following%2Cis_followed%2Cmutual_followees_count%2Cvote_to_count%2Cvote_from_count%2Cthank_to_count%2Cthank_from_count%2Cthanked_count%2Cdescription%2Chosted_live_count%2Cparticipated_live_count%2Callow_message%2Cindustry_category%2Corg_name%2Corg_homepage%2Cbadge%5B%3F(type%3Dbest_answerer)%5D.topics
这里就一个动态参数:wang-jing-15-15-28 这个在知乎里面是url_token, 就是用户标识接下来找到关注的人的接口
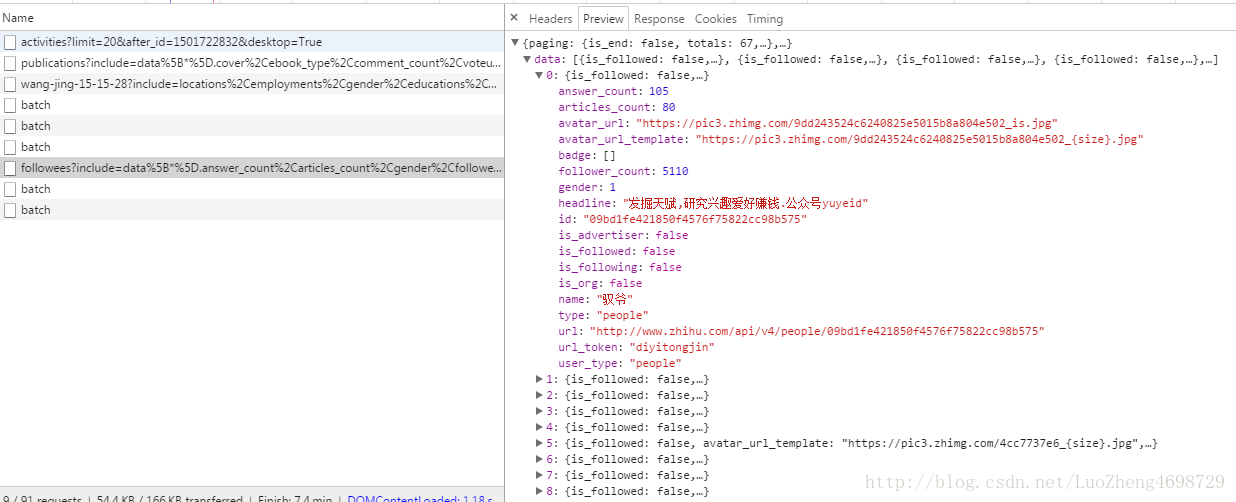
https://www.zhihu.com/api/v4/members/wang-jing-15-15-28/followees?include=data%5B*%5D.answer_count%2Carticles_count%2Cgender%2Cfollower_count%2Cis_followed%2Cis_following%2Cbadge%5B%3F(type%3Dbest_answerer)%5D.topics&offset=0&limit=20
这里动态参数是:wang-jing-15-15-28 , offset , limit2.4重头戏spider蜘蛛的编写 [先调用爬取起始人的详细资料的函数,在详细函数里面调用分页爬取关注人的函数并递归调用爬取详细信息函数, 大致逻辑就是这样,看不懂文字就直接看代码]
# -*- coding: utf-8 -*-
import scrapy
import logging
import json
from mytest.items import MytestItem
###### 全局变量,个人详细资料接口,动态参数为:person_name
person_detail = 'https://www.zhihu.com/api/v4/members/{person_name}?include=locations%2Cemployments%2Cgender%2Ceducations%2Cbusiness%2Cvoteup_count%2Cthanked_Count%2Cfollower_count%2Cfollowing_count%2Ccover_url%2Cfollowing_topic_count%2Cfollowing_question_count%2Cfollowing_favlists_count%2Cfollowing_columns_count%2Cavatar_hue%2Canswer_count%2Carticles_count%2Cpins_count%2Cquestion_count%2Ccolumns_count%2Ccommercial_question_count%2Cfavorite_count%2Cfavorited_count%2Clogs_count%2Cmarked_answers_count%2Cmarked_answers_text%2Cmessage_thread_token%2Caccount_status%2Cis_active%2Cis_bind_phone%2Cis_force_renamed%2Cis_bind_sina%2Cis_privacy_protected%2Csina_weibo_url%2Csina_weibo_name%2Cshow_sina_weibo%2Cis_blocking%2Cis_blocked%2Cis_following%2Cis_followed%2Cmutual_followees_count%2Cvote_to_count%2Cvote_from_count%2Cthank_to_count%2Cthank_from_count%2Cthanked_count%2Cdescription%2Chosted_live_count%2Cparticipated_live_count%2Callow_message%2Cindustry_category%2Corg_name%2Corg_homepage%2Cbadge%5B%3F(type%3Dbest_answerer)%5D.topics'
###### 全局变量,关注的人接口,动态参数为:person_name,offset,limit
his_about_person = 'https://www.zhihu.com/api/v4/members/{person_name}/followees?include=data%5B*%5D.answer_count%2Carticles_count%2Cgender%2Cfollower_count%2Cis_followed%2Cis_following%2Cbadge%5B%3F(type%3Dbest_answerer)%5D.topics&offset={offset}&limit={limit}'
class TestspiderSpider(scrapy.Spider):
name = 'testSpider'
allowed_domains = ['zhihu.com']
start_urls = ['https://www.zhihu.com']
### 初始调用
def start_requests(self):
### 起始人的 url_token
init_url_token = 'wang-jing-15-15-28'
# 爬取此人的 详细信息
yield scrapy.Request(url=person_detail.format(person_name=init_url_token), callback=self.parse_person_detail)
## 解析 他关注的人
def parse_his_followees(self, response):
## 转成字典
detail_dict = json.loads(response.text)
## 解析当前页 每个followers 的 url_token
if 'data' in detail_dict.keys():
for item in detail_dict.get('data'):
# 爬取此人的 详细信息
print('urltoken:',item.get('url_token'))
yield scrapy.Request(url=person_detail.format(person_name=item.get('url_token')), callback=self.parse_person_detail)
### 解析下一页的 解析每个followers
if 'paging' in detail_dict:
if 'is_end' in detail_dict.get('paging'):
## 是否是最后一页
if detail_dict.get('paging').get('is_end'):
##是最后一页, 不用请求下一页了
return
##请求下一页
print('开始请求第 ',detail_dict.get('paging').get('next'))
if 'next' in detail_dict.get('paging'):
yield scrapy.Request(url=detail_dict.get('paging').get('next'),callback=self.parse_his_followees)
### 解析个人详细资料
def parse_person_detail(self,response):
## 转成字典
detail_dict = json.loads(response.text)
name = detail_dict.get('name')
my_item = MytestItem()
print(name)
#######以下为数据提取
if 'id' in detail_dict:
my_item['zhihu_id'] = detail_dict.get('id')
if 'avatar_url_template' in detail_dict:
my_item['user_image'] = detail_dict.get('avatar_url_template').replace('{size}','xl')
else:
my_item['user_image'] = ''
if 'follower_count' in detail_dict:
my_item['follower_count'] = detail_dict.get('follower_count')
else:
my_item['follower_count'] = 0
if 'gender' in detail_dict:
my_item['gender'] = detail_dict.get('gender')
else:
my_item['gender'] = 1
if 'description' in detail_dict:
my_item['description'] = detail_dict.get('description')
else:
my_item['description'] = ''
if 'business' in detail_dict and 'name' in detail_dict.get('business').get('name'):
my_item['business'] = detail_dict.get('business').get('name')
else:
my_item['business'] =''
if 'educations' in detail_dict:
school_list = ''
for item in detail_dict.get('educations'):
if 'school' in item and 'name' in item.get('school'):
school_list = school_list + item.get('school').get('name') + ','
my_item['school'] = school_list
if 'educations' in detail_dict:
major_list = ''
for item in detail_dict.get('educations'):
if 'major' in item and 'name' in item.get('major'):
major_list = major_list + item.get('major').get('name') + ','
my_item['major'] = major_list
if 'employments' in detail_dict:
company_list = ''
for item in detail_dict.get('employments'):
if 'company' in item and 'name' in item.get('company'):
company_list = company_list + item.get('company').get('name') + ','
my_item['company'] = company_list
if 'employments' in detail_dict:
job_list = ''
for item in detail_dict.get('employments'):
if 'job' in item and 'name' in item.get('job'):
job_list = job_list + item.get('job').get('name') + ','
my_item['job'] = job_list
if 'headline' in detail_dict:
my_item['headline'] = detail_dict.get('headline')
if 'locations' in detail_dict:
location_list = ''
for item in detail_dict.get('locations'):
if 'name' in item:
location_list = location_list + item.get('name') + ','
my_item['locations'] = location_list
if 'name' in detail_dict:
my_item['name'] = detail_dict.get('name')
else:
my_item['name'] = ''
if 'url_token' in detail_dict:
my_item['url_token'] = detail_dict.get('url_token')
yield my_item
## 解析下面的 followees
url_token = detail_dict.get('url_token')
## 第一页 0 第二页20 第三页是40
yield scrapy.Request(url=his_about_person.format(person_name=url_token, offset=0, limit=20),
callback=self.parse_his_followees)2.5pipline 存到数据库 [先根据知乎id查询是否存在记录,存在就跳过,不存在就插入数据库]
# -*- coding: utf-8 -*-
import MySQLdb
import MySQLdb.cursors
from twisted.enterprise import adbapi
import logging
import requests
class MytestPipeline(object):
def __init__(self):
dbargs = dict(
host='127.0.0.1',
db='数据库名',
user='root',
passwd='密码',
charset='utf8',
cursorclass=MySQLdb.cursors.DictCursor,
use_unicode=True,
)
self.dbpool = adbapi.ConnectionPool('MySQLdb', **dbargs)
def process_item(self, item, spider):
res = self.dbpool.runInteraction(self.insert_into_table, item)
return item
def insert_into_table(self, conn, item):
# 先查询存不存在
if self.exsist(item, conn):
return
sql = 'insert into zhihu_user (zhihu_id,user_image,follower_count,gender,description,business,school,major,company,job,headline,locations,name,url_token) VALUES ('
sql = sql + '"' + item['zhihu_id'] + '",'
sql = sql + '"' + item['user_image'] + '",'
sql = sql + '"' + str(item['follower_count']) + '",'
sql = sql + '"' + str(item['gender']) + '",'
sql = sql + '"' + item['description'] + '",'
sql = sql + '"' + item['business'] + '",'
sql = sql + '"' + item['school'] + '",'
sql = sql + '"' + item['major'] + '",'
sql = sql + '"' + item['company'] + '",'
sql = sql + '"' + item['job'] + '",'
sql = sql + '"' + item['headline'] + '",'
sql = sql + '"' + item['locations'] + '",'
sql = sql + '"' + item['name'] + '",'
sql = sql + '"' + item['url_token'] + '",'
sql = sql[0:-1]
sql = sql + ')'
try:
conn.execute(sql)
print(sql)
except Exception as e:
print( "sqlsqlsqlsqlsqlsqlsql error>> " ,str(e))
def exsist(self, item, conn):
sql = 'select id from zhihu_user where zhihu_id="' + item['zhihu_id']
try:
# 执行SQL语句
conn.execute(sql)
# 获取所有记录列表
results = conn.fetchall()
if len(results) > 0: ## 存在
return True
except:
return False
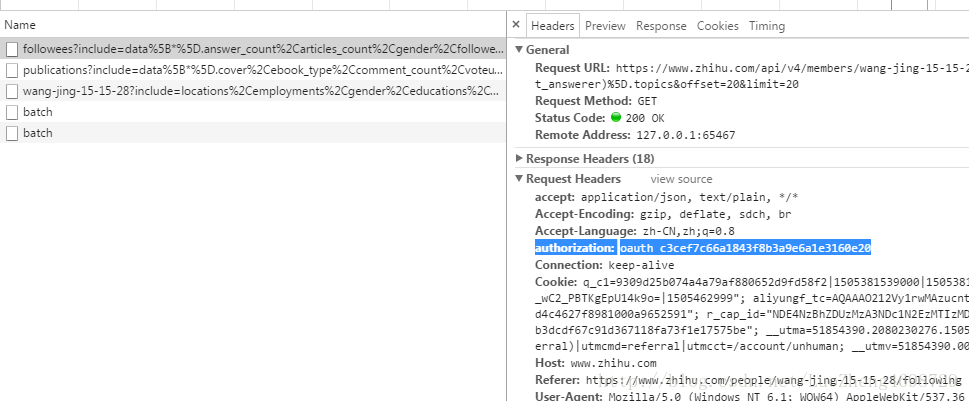
return False2.6settings.py[这里重要的是authorization]
# -*- coding: utf-8 -*-
BOT_NAME = 'mytest'
SPIDER_MODULES = ['mytest.spiders']
NEWSPIDER_MODULE = 'mytest.spiders'
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
'User-Agent' : 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36',
######知乎的 header,不传会报401
'authorization':'oauth c3cef7c66a1843f8b3a9e6a1e3160e20'
}
ITEM_PIPELINES = {
'mytest.pipelines.MytestPipeline': 300,
}
ROBOTSTXT_OBEY = False结果: 由于爬取一段时间服务器会认出是爬虫返回403, 这里可以用我另外的教程使用ip代理池来继续进行爬取,ip代理池博客地址:http://blog.csdn.net/luozheng4698729/article/details/77966752, 就到这里谢谢大家。
注意:此教程仅供技术学习参考!!!!!!!!!
老生常谈:深圳有爱好音乐的会打鼓(吉他,键盘,贝斯等)的程序员和其它职业可以一起交流加入我们乐队一起嗨。我的QQ:657455400