1: 留存率统计分析
select
log_day `日期`,
count(user_id_day0) `新增数量`,
count(user_id_day1)/count(user_id_day0) `次日留存率`,
count(user_id_day2)/count(user_id_day0) `3日留存率`,
count(user_id_day7)/count(user_id_day0) `7日留存率`,
count(user_id_day30)/count(user_id_day0) `30日留存率`
from(
select distinct log_day,
a.user_id_day0,
b.user_id as user_id_day1,
c.user_id as user_id_day3,
d.user_id as user_id_day7,
e.user_id as user_id_day30
from(
select distinct
Date(log_time) as log_day,
user_id as user_id_day0
from
t_user_login
where login_device='Android'
group by user_id
order by log_day
)a
left join t_user_login b on datediff(Date(b.log_time),a.log_day)=1
and a.user_id_day0=b.user_id
left join t_user_login c on datediff(Date(c.log_time),a.log_day)=2
and a.user_id_day0=c.user_id
left join t_user_login d on datediff(Date(d.log_time),a.log_day)=6
and a.user_id_day0=d.user_id
left join t_user_login e on datediff(Date(e.log_time),a.log_day)=29
and a.user_id_day0=e.user_id
) temp
group by log_day
2:计算直播同时在线人数最大值
如下为某直播平台主播开播及关播时间,根据该数据计算出平台最高峰同时在线的最多的主播人数。
id stt edt
1001 2021-06-14 12:12:12 2021-06-14 18:12:12
1003 2021-06-14 13:12:12 2021-06-14 16:12:12
1004 2021-06-14 13:15:12 2021-06-14 20:12:12
1002 2021-06-14 15:12:12 2021-06-14 16:12:12
1005 2021-06-14 15:18:12 2021-06-14 20:12:12
1001 2021-06-14 20:12:12 2021-06-14 23:12:12
1006 2021-06-14 21:12:12 2021-06-14 23:15:12
1007 2021-06-14 22:12:12 2021-06-14 23:10:12
分析思路:
1.将上线时间作为 +1,下线时间作为 -1
2.然后运用union all 合并两列
3.利用sum()over()对其分区排序,求出不同时间段的人数(每一个时间点都会对应一个总在线人数)
4.对时间进行分组,求出所有时间点中最大的同时在线总人数
将一条数据拆分成两条(id,dt,p),并且对数据进行标记:开播为1,关播为-1,1表示有主播开播在线,-1表示有主播关播离线,其中dt为开播时间或者关播时间。
然后按照dt排序,求某一时刻的主播在线人数,对时间排序,然后直接对那时刻之前的p求和即可。
那要求一天中最大的同时在线人数,就需要先分别求出每个时刻的同时在线人数,再取最大值即可。需要用到开窗函数:sum() over(…)
实现:
-- 1) 对数据分类,在开始数据后添加正1,表示有主播上线,同时在关播数据后添加-1,表示有主播下线
select id , stt as dt , 1 as p from test
union all
select id , edt as dt , -1 as p from test;
记为 t1
得到:
1001 2021-06-14 12:12:12 1
1001 2021-06-14 18:12:12 -1
1001 2021-06-14 20:12:12 1
1001 2021-06-14 23:12:12 -1
1002 2021-06-14 15:12:12 1
1002 2021-06-14 16:12:12 -1
1003 2021-06-14 13:12:12 1
1003 2021-06-14 16:12:12 -1
1004 2021-06-14 13:15:12 1
1004 2021-06-14 20:12:12 -1
1005 2021-06-14 15:18:12 1
1005 2021-06-14 20:12:12 -1
1006 2021-06-14 21:12:12 1
1006 2021-06-14 23:15:12 -1
1007 2021-06-14 22:12:12 1
1007 2021-06-14 23:10:12 -1
排序后:
1001 2021-06-14 12:12:12 1
1003 2021-06-14 13:12:12 1
1004 2021-06-14 13:15:12 1
1002 2021-06-14 15:12:12 1
1005 2021-06-14 15:18:12 1
1002 2021-06-14 16:12:12 -1
1003 2021-06-14 16:12:12 -1
1001 2021-06-14 18:12:12 -1
1001 2021-06-14 20:12:12 1
1004 2021-06-14 20:12:12 -1
1005 2021-06-14 20:12:12 -1
1006 2021-06-14 21:12:12 1
1007 2021-06-14 22:12:12 1
1007 2021-06-14 23:10:12 -1
1001 2021-06-14 23:12:12 -1
1006 2021-06-14 23:15:12 -1
-- 2) 按照时间排序,计算累加人数
select
t1.id,
t1.dt,
sum(p) over(partition by date_format(t1.dt, 'yyyy-MM-dd') order by t1.dt) sum_p
from (
select id , stt as dt , 1 as p from test
union all
select id , edt as dt , -1 as p from test
) t1
记为 t2
得到:
1001 2021-06-14 12:12:12 1
1003 2021-06-14 13:12:12 2
1004 2021-06-14 13:15:12 3
1002 2021-06-14 15:12:12 4
1005 2021-06-14 15:18:12 5
1002 2021-06-14 16:12:12 3
1003 2021-06-14 16:12:12 3
1001 2021-06-14 18:12:12 2
1001 2021-06-14 20:12:12 1
1004 2021-06-14 20:12:12 1
1005 2021-06-14 20:12:12 1
1006 2021-06-14 21:12:12 2
1007 2021-06-14 22:12:12 3
1007 2021-06-14 23:10:12 2
1001 2021-06-14 23:12:12 1
1006 2021-06-14 23:15:12 0
-- 3) 找出同时在线人数最大值
select
date_format(t2.dt,'yyyy-MM-dd') `date`,
max(sum_p) con
from(
select
t1.id,
t1.dt,
sum(p) over(partition by date_format(t1.dt, 'yyyy-MM-dd') order by t1.dt) sum_p
from (
select id , stt as dt , 1 as p from test
union all
select id , edt as dt , -1 as p from test
) t1
) t2
group by date_format(t2.dt,'yyyy-MM-dd');
同类型的需求有:
构造辅助计数变量及累加变换思路进行求解。
常见的场景有:
直播同时在线人数、
酒店入住离店场景有客人在住的房间数量、
服务器实时并发数、
公交车当前时间段人数、
某个仓库的货物积压数量,某一段时间内的同时处于服务过程中的最大订单量等
3: 区间分段统计 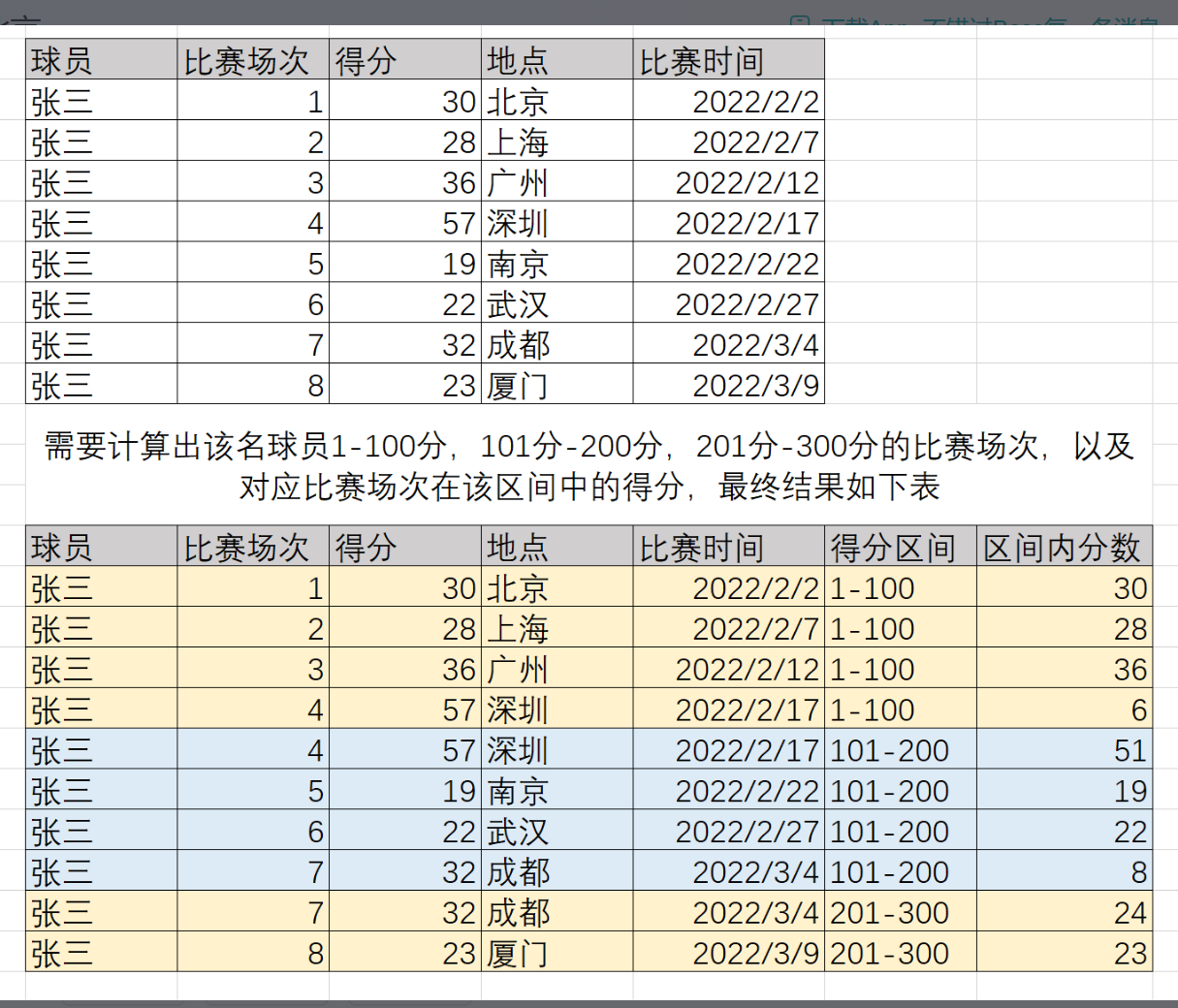
球员 比赛场次 得分 地点 时间
张三 1 30 北京 20220202
张三 2 28 上海 20220207
张三 3 36 广州 20220212
张三 4 57 深圳 20220217
张三 5 19 南京 20220222
张三 6 22 武汉 20220227
张三 7 32 成都 20220304
张三 8 23 厦门 20220309
create table tmp_tc.tmp_test_20230303 (
name String comment '姓名',
number string comment '比赛场次',
score int comment '成绩',
address String comment '地址',
dt String comment '日期'
)
stored as orc tblproperties ("orc.compress"="SNAPPY");
with tmp as (
select '张三' as name,'1' as number,30 as score,'北京' as address , '20220202' as dt union all
select '张三' as name,'2' as number,28 as score,'上海' as address , '20220207' as dt union all
select '张三' as name,'3' as number,36 as score,'广州' as address , '20220212' as dt union all
select '张三' as name,'4' as number,57 as score,'深圳' as address , '20220217' as dt union all
select '张三' as name,'5' as number,19 as score,'南京' as address , '20220222' as dt union all
select '张三' as name,'6' as number,22 as score,'武汉' as address , '20220227' as dt union all
select '张三' as name,'7' as number,32 as score,'成都' as address , '20220304' as dt union all
select '张三' as name,'8' as number,23 as score,'厦门' as address , '20220309' as dt
)
set spark.sql.shuffle.partitions=1;
insert overwrite table tmp_tc.tmp_test_20230303
select * from tmp_tc.tmp_test_20230303
distribute by rand()
;
统计分析:
with tmp as (
select *
, sum(score) over(partition by name order by dt) as total_score
, coalesce(sum(score) over(partition by name order by dt rows between unbounded preceding and 1 preceding),0) as total_score2
from tmp_tc.tmp_test_20230303
),
tmp2 as (
-- 区间分数两者之间 上半部分
select
name
, number
, score
, address
, dt
, case when floor(total_score/100) = 0 then '1-100'
when floor(total_score/100) = 1 then '101-200'
when floor(total_score/100) = 2 then '201-300'
else '300+' end as tag
, (ceil(total_score2/100)*100-total_score2) as tag_score
from tmp
where floor(total_score2/100) != floor(total_score/100)
union all
-- 区间分数两者之间 下半部分
select
name
, number
, score
, address
, dt
, case when floor(total_score/100) = 0 then '1-100'
when floor(total_score/100) = 1 then '101-200'
when floor(total_score/100) = 2 then '201-300'
else '300+' end as tag
, (score - (ceil(total_score2/100)*100-total_score2)) as tag_score
from tmp
where floor(total_score2/100) != floor(total_score/100)
union all
-- 区间内分数
select
name
, number
, score
, address
, dt
, case when floor(total_score/100) = 0 then '1-100'
when floor(total_score/100) = 1 then '101-200'
when floor(total_score/100) = 2 then '201-300'
else '300+' end as tag
, score as tag_score
from tmp
where !(floor(total_score2/100) != floor(total_score/100))
)
select
name -- 球员
, number -- 比赛场次
, score -- 得分
, address -- 地点
, dt -- 比赛时间
, tag -- 得分区间
, tag_score -- 区间内分数
from tmp2
order by dt, tag_score
;
4:hive中怎么统计array中非零的个数?
## 方案一:
select length(translate(concat_ws(',',array('0','1','3','6','0')),',0',''));
## 方案二:
select count(a)
from
(
select explode(array('0','1','3','6','0')) as a
) t
where a!='0'
5:断点重分组问题分析? 需求:流量统计,将同一个用户的多个上网行为数据进行聚合,如果两次上网时间间隔小于10分钟,就进行聚合。
## 数据准备
uid start_time end_time num
1 2020-02-18 14:20:30 2020-02-18 14:46:30 20
1 2020-02-18 14:47:20 2020-02-18 15:20:30 30
1 2020-02-18 15:37:23 2020-02-18 16:05:26 40
1 2020-02-18 16:06:27 2020-02-18 17:20:49 50
1 2020-02-18 17:21:50 2020-02-18 18:03:27 60
2 2020-02-18 14:18:24 2020-02-18 15:01:40 20
2 2020-02-18 15:20:49 2020-02-18 15:30:24 30
2 2020-02-18 16:01:23 2020-02-18 16:40:32 40
2 2020-02-18 16:44:56 2020-02-18 17:40:52 50
3 2020-02-18 14:39:58 2020-02-18 15:35:53 20
3 2020-02-18 15:36:39 2020-02-18 15:24:54 30
## 分析:关键在正确分组
1, 2020-02-18 14:20:30, 2020-02-18 14:46:30,20 ,0 ,0
1, 2020-02-18 14:47:20, 2020-02-18 15:20:30,30 ,0 ,0
1, 2020-02-18 15:37:23, 2020-02-18 16:05:26,40 ,1 ,1
1, 2020-02-18 16:06:27, 2020-02-18 17:20:49,50 ,0 ,1
1, 2020-02-18 17:21:50, 2020-02-18 18:03:27,60 ,0 ,1
1:将end_time往下拉取一行,重新起个名字pre_end_time
2:pre_end_time-start_time<10,记为0用作标识,否则记为1,1即为变化的分割点
3:通过sum over() 将分割的段落再次转换,即可得到正确的可用于分组的标记,依此作为分组条件
完整sql实现:
WITH tmp as (
SELECT
uid,
start_time,
end_time,
lag(end_time,1,null) over(partition by uid order by start_time) as pre_end_time
FROM t
)
SELECT
uid,
min(start_time) as start_time,
max(end_time) as end_time,
sum(num) as amount
FROM
(
SELECT
uid,
start_time,
end_time,
num,
sum(flag) over(partition by uid order by start_time rows between unbounded preceding and current row) as groupid
FROM
(
SELECT
uid,
start_time,
end_time,
num,
if(unix_timestamp(start_time) - nvl(unix_timestamp(pre_end_time),unix_timestamp(start_time))< 10*60,0,1) as flag
FROM tmp
) o1
)o2
GROUP BY uid,groupid
结果展示:
1 2020-02-18 14:20:30 2020-02-18 15:20:30 50
1 2020-02-18 15:37:23 2020-02-18 18:03:27 150
2 2020-02-18 14:18:24 2020-02-18 15:01:40 20
2 2020-02-18 15:20:49 2020-02-18 15:30:24 30
2 2020-02-18 16:01:23 2020-02-18 17:40:52 90
3 2020-02-18 14:39:58 2020-02-18 15:24:54 50
6:SQL重叠交叉区间问题分析? 计算每个品牌总的打折销售天数。
pName sst et
oppo 2021-06-05 2021-06-09
oppo 2021-06-11 2021-06-21
vivo 2021-06-05 2021-06-15
vivo 2021-06-09 2021-06-21
redmi 2021-06-05 2021-06-21
redmi 2021-06-09 2021-06-15
redmi 2021-06-17 2021-06-26
huawei 2021-06-05 2021-06-26
huawei 2021-06-09 2021-06-15
huawei 2021-06-17 2021-06-21
注意:其中的交叉日期,比如vivo品牌,第一次活动时间为2021-06-05到 2021-06-15,第二次活动时间为 2021-06-09到 2021-06-21其中 9号到 15号为重复天数,只统计一次,即 vivo总打折天数为 2021-06-05到 2021-06-21共计 17天。
思路:
总体想法就是计算每一段相差的时间,求其总和减去重复的部分即可。其思路的巧妙之处就是将时间的差值转化成离散的序列值,最终求出每个品牌的总记录数去掉重复的即可。【补齐全集,减去重复值,集合思想】
(1)根据相差的天数生成序列值。(索引值)
根据时间差值生成相应的空格字符串,然后通过split()函数解析,最终根据posexplode()函数生成对应的索引值。当然此处也可以用repeat()函数代替space()函数。由于split()函数解析的时候会生成多余的空串(''),所以具体操作的时候过滤掉为0的索引。具体生成索引的SQL如下:
select
id,
stt,
edt,
t.pos
from(
select id,stt,edt from brand
) tmp lateral view posexplode(
split(space(datediff(edt, stt)+1), '')
) t as pos, val
where t.pos <> 0
生成序列数据如下:
oppo 2021-06-05 2021-06-09 1
oppo 2021-06-05 2021-06-09 2
oppo 2021-06-05 2021-06-09 3
oppo 2021-06-05 2021-06-09 4
oppo 2021-06-05 2021-06-09 5
oppo 2021-06-11 2021-06-21 1
oppo 2021-06-11 2021-06-21 2
oppo 2021-06-11 2021-06-21 3
oppo 2021-06-11 2021-06-21 4
oppo 2021-06-11 2021-06-21 5
oppo 2021-06-11 2021-06-21 6
oppo 2021-06-11 2021-06-21 7
oppo 2021-06-11 2021-06-21 8
oppo 2021-06-11 2021-06-21 9
oppo 2021-06-11 2021-06-21 10
oppo 2021-06-11 2021-06-21 11
vivo 2021-06-05 2021-06-15 1
vivo 2021-06-05 2021-06-15 2
vivo 2021-06-05 2021-06-15 3
vivo 2021-06-05 2021-06-15 4
vivo 2021-06-05 2021-06-15 5
vivo 2021-06-05 2021-06-15 6
vivo 2021-06-05 2021-06-15 7
vivo 2021-06-05 2021-06-15 8
vivo 2021-06-05 2021-06-15 9
vivo 2021-06-05 2021-06-15 10
vivo 2021-06-05 2021-06-15 11
vivo 2021-06-09 2021-06-21 1
vivo 2021-06-09 2021-06-21 2
vivo 2021-06-09 2021-06-21 3
vivo 2021-06-09 2021-06-21 4
vivo 2021-06-09 2021-06-21 5
vivo 2021-06-09 2021-06-21 6
vivo 2021-06-09 2021-06-21 7
vivo 2021-06-09 2021-06-21 8
vivo 2021-06-09 2021-06-21 9
vivo 2021-06-09 2021-06-21 10
vivo 2021-06-09 2021-06-21 11
vivo 2021-06-09 2021-06-21 12
vivo 2021-06-09 2021-06-21 13
redmi 2021-06-05 2021-06-21 1
redmi 2021-06-05 2021-06-21 2
redmi 2021-06-05 2021-06-21 3
redmi 2021-06-05 2021-06-21 4
redmi 2021-06-05 2021-06-21 5
redmi 2021-06-05 2021-06-21 6
redmi 2021-06-05 2021-06-21 7
redmi 2021-06-05 2021-06-21 8
redmi 2021-06-05 2021-06-21 9
redmi 2021-06-05 2021-06-21 10
redmi 2021-06-05 2021-06-21 11
redmi 2021-06-05 2021-06-21 12
redmi 2021-06-05 2021-06-21 13
redmi 2021-06-05 2021-06-21 14
redmi 2021-06-05 2021-06-21 15
redmi 2021-06-05 2021-06-21 16
redmi 2021-06-05 2021-06-21 17
redmi 2021-06-09 2021-06-15 1
redmi 2021-06-09 2021-06-15 2
redmi 2021-06-09 2021-06-15 3
redmi 2021-06-09 2021-06-15 4
redmi 2021-06-09 2021-06-15 5
redmi 2021-06-09 2021-06-15 6
redmi 2021-06-09 2021-06-15 7
redmi 2021-06-17 2021-06-26 1
redmi 2021-06-17 2021-06-26 2
redmi 2021-06-17 2021-06-26 3
redmi 2021-06-17 2021-06-26 4
redmi 2021-06-17 2021-06-26 5
redmi 2021-06-17 2021-06-26 6
redmi 2021-06-17 2021-06-26 7
redmi 2021-06-17 2021-06-26 8
redmi 2021-06-17 2021-06-26 9
redmi 2021-06-17 2021-06-26 10
huawei 2021-06-05 2021-06-26 1
huawei 2021-06-05 2021-06-26 2
huawei 2021-06-05 2021-06-26 3
huawei 2021-06-05 2021-06-26 4
huawei 2021-06-05 2021-06-26 5
huawei 2021-06-05 2021-06-26 6
huawei 2021-06-05 2021-06-26 7
huawei 2021-06-05 2021-06-26 8
huawei 2021-06-05 2021-06-26 9
huawei 2021-06-05 2021-06-26 10
huawei 2021-06-05 2021-06-26 11
huawei 2021-06-05 2021-06-26 12
huawei 2021-06-05 2021-06-26 13
huawei 2021-06-05 2021-06-26 14
huawei 2021-06-05 2021-06-26 15
huawei 2021-06-05 2021-06-26 16
huawei 2021-06-05 2021-06-26 17
huawei 2021-06-05 2021-06-26 18
huawei 2021-06-05 2021-06-26 19
huawei 2021-06-05 2021-06-26 20
huawei 2021-06-05 2021-06-26 21
huawei 2021-06-05 2021-06-26 22
huawei 2021-06-09 2021-06-15 1
huawei 2021-06-09 2021-06-15 2
huawei 2021-06-09 2021-06-15 3
huawei 2021-06-09 2021-06-15 4
huawei 2021-06-09 2021-06-15 5
huawei 2021-06-09 2021-06-15 6
huawei 2021-06-09 2021-06-15 7
huawei 2021-06-17 2021-06-21 1
huawei 2021-06-17 2021-06-21 2
huawei 2021-06-17 2021-06-21 3
huawei 2021-06-17 2021-06-21 4
huawei 2021-06-17 2021-06-21 5
(2) 根据索引生成时间补齐所有时间段值
select
id,
stt,
edt,
pos-1,
date_add(stt, pos-1)
from(
select id,stt,edt from brand
) tmp lateral view posexplode(
split(space(datediff(edt, stt)+1), '')
) t as pos, val
where pos <> 0
数据如下:
oppo 2021-06-05 2021-06-09 0 2021-06-05
oppo 2021-06-05 2021-06-09 1 2021-06-06
oppo 2021-06-05 2021-06-09 2 2021-06-07
oppo 2021-06-05 2021-06-09 3 2021-06-08
oppo 2021-06-05 2021-06-09 4 2021-06-09
oppo 2021-06-11 2021-06-21 0 2021-06-11
oppo 2021-06-11 2021-06-21 1 2021-06-12
oppo 2021-06-11 2021-06-21 2 2021-06-13
oppo 2021-06-11 2021-06-21 3 2021-06-14
oppo 2021-06-11 2021-06-21 4 2021-06-15
oppo 2021-06-11 2021-06-21 5 2021-06-16
oppo 2021-06-11 2021-06-21 6 2021-06-17
oppo 2021-06-11 2021-06-21 7 2021-06-18
oppo 2021-06-11 2021-06-21 8 2021-06-19
oppo 2021-06-11 2021-06-21 9 2021-06-20
oppo 2021-06-11 2021-06-21 10 2021-06-21
vivo 2021-06-05 2021-06-15 0 2021-06-05
vivo 2021-06-05 2021-06-15 1 2021-06-06
vivo 2021-06-05 2021-06-15 2 2021-06-07
vivo 2021-06-05 2021-06-15 3 2021-06-08
vivo 2021-06-05 2021-06-15 4 2021-06-09
vivo 2021-06-05 2021-06-15 5 2021-06-10
vivo 2021-06-05 2021-06-15 6 2021-06-11
vivo 2021-06-05 2021-06-15 7 2021-06-12
vivo 2021-06-05 2021-06-15 8 2021-06-13
vivo 2021-06-05 2021-06-15 9 2021-06-14
vivo 2021-06-05 2021-06-15 10 2021-06-15
vivo 2021-06-09 2021-06-21 0 2021-06-09
vivo 2021-06-09 2021-06-21 1 2021-06-10
vivo 2021-06-09 2021-06-21 2 2021-06-11
vivo 2021-06-09 2021-06-21 3 2021-06-12
vivo 2021-06-09 2021-06-21 4 2021-06-13
vivo 2021-06-09 2021-06-21 5 2021-06-14
vivo 2021-06-09 2021-06-21 6 2021-06-15
vivo 2021-06-09 2021-06-21 7 2021-06-16
vivo 2021-06-09 2021-06-21 8 2021-06-17
vivo 2021-06-09 2021-06-21 9 2021-06-18
vivo 2021-06-09 2021-06-21 10 2021-06-19
vivo 2021-06-09 2021-06-21 11 2021-06-20
vivo 2021-06-09 2021-06-21 12 2021-06-21
redmi 2021-06-05 2021-06-21 0 2021-06-05
redmi 2021-06-05 2021-06-21 1 2021-06-06
redmi 2021-06-05 2021-06-21 2 2021-06-07
redmi 2021-06-05 2021-06-21 3 2021-06-08
redmi 2021-06-05 2021-06-21 4 2021-06-09
redmi 2021-06-05 2021-06-21 5 2021-06-10
redmi 2021-06-05 2021-06-21 6 2021-06-11
redmi 2021-06-05 2021-06-21 7 2021-06-12
redmi 2021-06-05 2021-06-21 8 2021-06-13
redmi 2021-06-05 2021-06-21 9 2021-06-14
redmi 2021-06-05 2021-06-21 10 2021-06-15
redmi 2021-06-05 2021-06-21 11 2021-06-16
redmi 2021-06-05 2021-06-21 12 2021-06-17
redmi 2021-06-05 2021-06-21 13 2021-06-18
redmi 2021-06-05 2021-06-21 14 2021-06-19
redmi 2021-06-05 2021-06-21 15 2021-06-20
redmi 2021-06-05 2021-06-21 16 2021-06-21
redmi 2021-06-09 2021-06-15 0 2021-06-09
redmi 2021-06-09 2021-06-15 1 2021-06-10
redmi 2021-06-09 2021-06-15 2 2021-06-11
redmi 2021-06-09 2021-06-15 3 2021-06-12
redmi 2021-06-09 2021-06-15 4 2021-06-13
redmi 2021-06-09 2021-06-15 5 2021-06-14
redmi 2021-06-09 2021-06-15 6 2021-06-15
redmi 2021-06-17 2021-06-26 0 2021-06-17
redmi 2021-06-17 2021-06-26 1 2021-06-18
redmi 2021-06-17 2021-06-26 2 2021-06-19
redmi 2021-06-17 2021-06-26 3 2021-06-20
redmi 2021-06-17 2021-06-26 4 2021-06-21
redmi 2021-06-17 2021-06-26 5 2021-06-22
redmi 2021-06-17 2021-06-26 6 2021-06-23
redmi 2021-06-17 2021-06-26 7 2021-06-24
redmi 2021-06-17 2021-06-26 8 2021-06-25
redmi 2021-06-17 2021-06-26 9 2021-06-26
huawei 2021-06-05 2021-06-26 0 2021-06-05
huawei 2021-06-05 2021-06-26 1 2021-06-06
huawei 2021-06-05 2021-06-26 2 2021-06-07
huawei 2021-06-05 2021-06-26 3 2021-06-08
huawei 2021-06-05 2021-06-26 4 2021-06-09
huawei 2021-06-05 2021-06-26 5 2021-06-10
huawei 2021-06-05 2021-06-26 6 2021-06-11
huawei 2021-06-05 2021-06-26 7 2021-06-12
huawei 2021-06-05 2021-06-26 8 2021-06-13
huawei 2021-06-05 2021-06-26 9 2021-06-14
huawei 2021-06-05 2021-06-26 10 2021-06-15
huawei 2021-06-05 2021-06-26 11 2021-06-16
huawei 2021-06-05 2021-06-26 12 2021-06-17
huawei 2021-06-05 2021-06-26 13 2021-06-18
huawei 2021-06-05 2021-06-26 14 2021-06-19
huawei 2021-06-05 2021-06-26 15 2021-06-20
huawei 2021-06-05 2021-06-26 16 2021-06-21
huawei 2021-06-05 2021-06-26 17 2021-06-22
huawei 2021-06-05 2021-06-26 18 2021-06-23
huawei 2021-06-05 2021-06-26 19 2021-06-24
huawei 2021-06-05 2021-06-26 20 2021-06-25
huawei 2021-06-05 2021-06-26 21 2021-06-26
huawei 2021-06-09 2021-06-15 0 2021-06-09
huawei 2021-06-09 2021-06-15 1 2021-06-10
huawei 2021-06-09 2021-06-15 2 2021-06-11
huawei 2021-06-09 2021-06-15 3 2021-06-12
huawei 2021-06-09 2021-06-15 4 2021-06-13
huawei 2021-06-09 2021-06-15 5 2021-06-14
huawei 2021-06-09 2021-06-15 6 2021-06-15
huawei 2021-06-17 2021-06-21 0 2021-06-17
huawei 2021-06-17 2021-06-21 1 2021-06-18
huawei 2021-06-17 2021-06-21 2 2021-06-19
huawei 2021-06-17 2021-06-21 3 2021-06-20
huawei 2021-06-17 2021-06-21 4 2021-06-21
(3) 去掉重复值,计算剩余点个数。
select
id,
count(distinct date_add(stt, pos-1)) as day_count
from(
select id,stt,edt from brand
) tmp lateral view posexplode(
split(space(datediff(edt, stt)+1), '')
) t as pos, val
where t.pos <> 0
group by id
完整优化后代码:
select
id,
count(distinct date_add(stt, pos-1)) as day_count
from(
select id,stt,edt from brand
) tmp lateral view posexplode(
split(repeat('a',datediff(edt, stt)+1), 'a(?!a$)')
) t as pos, val
group by id
7:SQL之存在性问题分析
求截止当前月退费总人数【退费人数:上月存在,这月不存在的学生个数】?
# 数据如下:
dt stu_id
2020-01-02 1001
2020-01-02 1002
2020-02-02 1001
2020-02-02 1002
2020-02-02 1003
2020-02-02 1004
2020-03-02 1001
2020-03-02 1002
2020-04-02 1005
2020-05-02 1006
预期结果:
月份 累计退费人数
2020-01 0
2020-02 0
2020-03 2
2020-04 4
2020-05 5
分析思路:
dt stu_id
2020-01 1001
2020-01 1002
2020-02 1001
2020-02 1002
2020-02 1003
2020-02 1004
2020-03 1001
2020-03 1002
2020-04 1005
2020-05 1006
left join
2020-01 [1001 1002] [1001 1002 1003 1004]
2020-02 [1001 1002 1003 1004] [1001 1002]
2020-03 [1001 1002] [1005]
2020-04 [1005] [1006]
2020-04 [1006] NULL
====>
2020-01 1001 2020-01 [1001,1002,1003,1004]
2020-01 1002 2020-01 [1001,1002,1003,1004]
2020-02 1001 2020-02 [1001,1002]
2020-02 1002 2020-02 [1001,1002]
2020-02 1003 2020-02 [1001,1002]
2020-02 1004 2020-02 [1001,1002]
2020-03 1001 2020-03 [1005]
2020-03 1002 2020-03 [1005]
2020-04 1005 2020-04 [1006]
2020-05 1006 2020-05 NULL
====>
sum(if(!array_contains(col1,col2),1,0)) over(partition by xxx)
2020-01 0
2020-02 2
2020-03 2
2020-04 1
2020-05 1
===> lag over()
2020-01 0 0
2020-02 2 0
2020-03 2 2
2020-04 1 2
2020-05 1 1
===> sum() over()
OK
2020-01 0
2020-02 0
2020-03 2
2020-04 4
2020-05 5
完整sql实现:
select month
,sum(lag_month_cnt) over(order by month)
from(
select month
,lag(next_month_cnt,1,0) over(order by month) as lag_month_cnt
from(
select distinct t0.month as month
,sum(if(!array_contains(t1.lag_stu_id_arr,t0.stu_id),1,0)) over(partition by t0.month) as next_month_cnt
from
(select substr(day,1,7) as month
,stu_id
from stu) t0
left join
(
select month
,lead(stu_id_arr,1) over(order by month) as lag_stu_id_arr
from(
select substr(day,1,7) as month
,collect_list(stu_id) as stu_id_arr
from stu
group by substr(day,1,7)
) m
) t1
on t0.month = t1.month
) n
) o
8:水位线思想在解决SQL复杂场景问题中的应用与研究?
水位线的思想处理问题,我们先根据实际场景需要解决的问题来引出这一话题,例如有下面的场景:
我们希望删除某id中存在NULL值的所有行,但是保留第一次出现不为NULL值的以下所有存在NULL值的行。具体如下图所示:
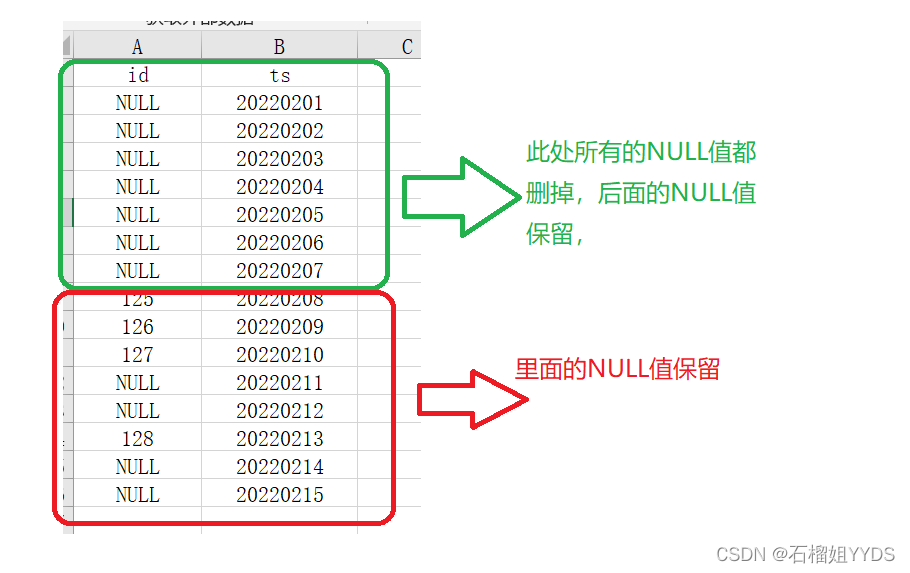
解决思路一:sum(id) over(order by ts)思想取出值不为0的,即为需要的结果。
select *
from
(select *
,sum(coalesce(id,0)) over(order by ts) as water_mark
from test01
) t
where water_mark !=0
11:SQL之定位连续区间的起始位置和结束位置?
Logs 表:
+------------+
| log_id |
+------------+
| 1 |
| 2 |
| 3 |
| 7 |
| 8 |
| 10 |
+------------+
结果表:
+------------+--------------+
| start_id | end_id |
+------------+--------------+
| 1 | 3 |
| 7 | 8 |
| 10 | 10 |
+------------+--------------+
第一步:
通过log_id - row_number() over(order by a.log_id)得到rn:
log_id rn1 rn
1 1 0
2 2 0
3 3 0
7 4 3
8 5 3
10 6 4
第二步:根据rn分组,取出最小值和最大值,即结果。
select
min(a.log_id) start_id,
max(a.log_id) end_id
from
(
select
a.log_id,
a.log_id - row_number() over(order by a.log_id) rn
from Logs a
)a
group by a.rn;

本文由 mdnice 多平台发布