文章目录
零基础之pandas
一.pandas基础知识
1.pandas初认识
import pandas as ps
data={
'name':['lcl','小明','小红'],
'age':[10,20,30],
}
df=ps.DataFrame(data)
print(type(df))
print(df)
运行结果:
<class 'pandas.core.frame.DataFrame'>
name age
0 lcl 10
1 小明 20
2 小红 30
进程已结束,退出代码为 0
初步收获:
我们发现dataframe可以把一个字典格式的数据转换成类似于excel表格的列表形式。
2.pandas数据结构之Series
#### 2.1series概念
pandas Series类似于表格中的一个列(column),类似于一维数组,可以保存任何数据类型。
Series由索引(index)和列组成,函数如下:
pandas.Series(data,index,dtype,name.copy)
参数说明:
data:⼀组数据(ndarray 类型)。
index:数据索引标签,如果不指定,默认从 0 开始。
dtype:数据类型,默认会⾃⼰判断。
name:设置名称。
copy:拷⻉数据,默认为 False。
data可以是列表,也可以是字典。
如果是列表,不指定index参数,默认index从0开始,指定index的话需要和列表中的数据个数一致
如果是字典,不指定index,默认索引为字典的全部key,指定index的话可以选取部分字典数据
2.2创建⼀个简单的 Series 实例:
import pandas as pd
data1=[3,2,4]
data2=['a','b','c']
s1=pd.Series(data1)
s2=pd.Series(data2)
print(type(s1))
print(type(s2))
print(s1)
print(s2)
输出如下:
<class 'pandas.core.series.Series'>
<class 'pandas.core.series.Series'>
0 3
1 2
2 4
dtype: int64 #数字类型
#索引 数据
0 a
1 b
2 c
#数据类型
dtype: object #字符串类型,但在python中字符串为对象类型
从上图可知,如果没有指定索引,索引值就从0开始
我们可以根据索引值读取数据
print(s1[0])
2.3指定索引值
a=['小明','小红','小亮']
myvar=pd.Series(a,index=['x','y','z'])
print(myvar)
x 小明
y 小红
z 小亮
dtype: object
索引取值:
myvar[‘x’]:小明
2.4使⽤ key/value 对象,类似字典来创建 Series:
import pandas as pd
data = {1: "哈哈", 2: "呵呵", 3: "喜喜"}
myvar = pd.Series(data)
print(myvar)
out:
1 哈哈
2 呵呵
3 喜喜
dtype: object
从上可知,字典的 key 变成了索引值。
如果我们只需要字典中的⼀部分数据,只需要指定需要数据的索引即可,如下:
import pandas as pd
data = {1: "哈哈", 2: "呵呵", 3: "喜喜"}
myvar = pd.Series(data, index = [1, 3]) #可以index参数指定索引
print(myvar)
out:
1 哈哈
3 喜喜
dtype: object
2.5设置 Series 名称参数:
myvar = pd.Series(data, index = [1, 3],name='小明') #参数name设置series名称
print(myvar)
out:
1 哈哈
3 喜喜
Name: 小明, dtype: object #我们输出时多了name属性
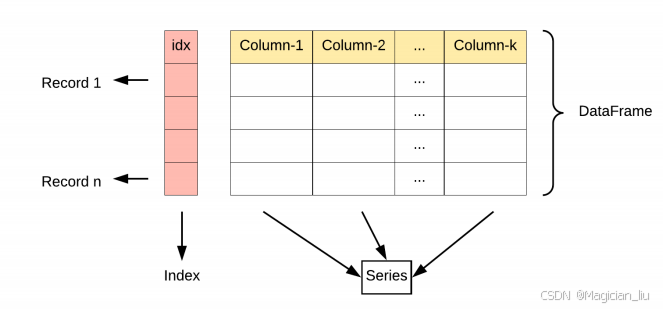
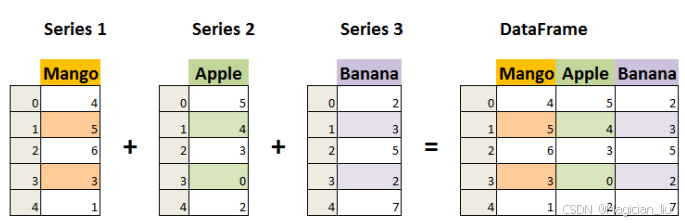
3 Pandas 数据结构 之DataFrame
3.1DataFrame初认识
DataFrame 是⼀个表格型的数据结构,它含有⼀组有序的列,
每列可以是不同的值类型(数值、字符串、布尔型值)。
DataFrame 既有⾏索引也有列索引,它可以被看做由 Series
组成的字典(共同⽤⼀个索引)。
3.2DataFrame 构造⽅法
pandas.DataFrame( data, index, columns, dtype,copy)
参数说明:
data:⼀组数据(ndarray、series, map, lists, dict 等类
型)。
index:索引值,或者可以称为⾏标签。
columns:列标签,默认为 RangeIndex (0, 1, 2, …, n) 。
dtype:数据类型。
copy:拷⻉数据,默认为 False。
3.3使用列表创建实例
Pandas DataFrame 是⼀个⼆维的数组结构,类似⼆维数组。
实例 - 使⽤列表创建
import pandas as pd
data=[['小明',10,200],['小红',12,300],['小亮',100,300]]
df=pd.DataFrame(data,columns=['name','age','account'],dtype=float)
print(df)
类似于一个二维数组,创建时columns参数就是设置列索引,dtype就是设置数据类型,index和series一样设置行索引
out:
name age account
0 小明 10.0 200.0
1 小红 12.0 300.0
2 小亮 100.0 300.0
3.4使⽤ ndarrays 创建
ndarray ( N 维数组)是⼀个快速且灵活的数据集容器
实例 - 使⽤ ndarrays 创建
import pandas as pd
# data=[['小明',10,200],['小红',12,300],['小亮',100,300]]
# df=pd.DataFrame(data,columns=['name','age','account'],dtype=float)
data={'name':['小明','小红','小亮'],'age':[10,12,100],'account':[200,300,300]}
df=pd.DataFrame(data)
print(df)
out:
name age account
0 小明 10 200
1 小红 12 300
2 小亮 100 300
从以上输出结果可以知道, DataFrame 数据类型⼀个表格,
包含 rows(⾏)和 columns(列):
还可以使⽤字典(key/value),其中字典的 key 为列名:
3.5实例 - 使⽤字典创建
data = [{'a': 1, 'b': 2},{'a': 5, 'b': 10,'c': 20}]
df = pd.DataFrame(data)
print(df)
out:
a b c
0 1 2 NaN
1 5 10 20.0
没有对应的部分数据为NaN。
3.6使用loc获取指定行数据
Pandas 可以使⽤loc属性返回指定⾏的数据,如果没有设置索引,第⼀⾏索引为0,第⼆⾏索引为1
当然也可以loc[行索引,列索引]精准索引确认某数据
data={
"calories": [420, 380, 390],
"duration": [50, 40, 45]
}
df = pd.DataFrame(data)
# 返回第⼀⾏
print(df.loc[0])
# 返回第⼆⾏
print(df.loc[1])
print(type(df.loc[2]))
out
calories 420
duration 50
Name: 0, dtype: int64
calories 380
duration 40
Name: 1, dtype: int64
<class 'pandas.core.series.Series'>
Pandas 可以使⽤loc属性返回指定索引对应到某⼀⾏:
因此我先把dataframe每一行都认为是series对象,列索引为每个series对象的索引!!!!!
**注意:**返回结果其实就是⼀个 Pandas Series 数据。
也可以返回多⾏数据,使⽤**[[ … ]]格式,…**为各⾏的索引,以逗号隔开:
如下:
data={
"calories": [420, 380, 390],
"duration": [50, 40, 45]
}
df = pd.DataFrame(data)
print(df)
print(type(df.loc[[1,2]]))
print(df.loc[[1,2]])
out:
calories duration
0 420 50
1 380 40
2 390 45
<class 'pandas.core.frame.DataFrame'>
calories duration
1 380 40
2 390 45
注意:返回结果其实就是⼀个 Pandas DataFrame 数据。
我们可以指定索引值,如下实例:
data={
"calories": [420, 380, 390],
"duration": [50, 40, 45]
}
df = pd.DataFrame(data,index=['d1', 'd2', 'd3'])
print(df)
print(type(df.loc[['d1','d2']]))
print(df.loc[['d1','d2']])
out: index参数就是设置行索引!!!!
calories duration
d1 420 50
d2 380 40
d3 390 45
<class 'pandas.core.frame.DataFrame'>
calories duration
d1 420 50
d2 380 40
3.6.1loc小结:
Pandas 可以使⽤loc属性返回指定索引对应到某⼀⾏
如果指定某一行,即df.loc[索引名],返回的是Series对象
如果指定多行,即df.loc[[索引名1,索引名2,...]],返回的仍然是Dateframe对象
二.pandas CSV文件
Pandas 可以很⽅便的处理 CSV ⽂件本⽂以 nba.csv为例
1.CSV文件概述
CSV(Comma-Separated Values,逗号分隔值,有时也称为字符分隔值,因为分隔字符也可以不是逗号),其⽂件以纯⽂本形式存储表格数据(数字和⽂本)。
CSV 是⼀种通⽤的、相对简单的⽂件格式,被⽤户、商业和科学⼴泛应⽤。
2.pandas之写csv文件 :to_csv()
我们可以使⽤**to_csv()**⽅法将 DataFrame 存储为 csv ⽂件:
import pandas as pd
# 三个字段 name, site, age
name = ["小明", "小红", "小亮", "小林"]
site = ["www.xiaoming.com", "www.xiaohong.com","www.xiaoliang.com", "www.xiaolin.org"]
age = [90, 40, 80, 98]
# 字典
dict = {'name': name, 'site': site, 'age': age}
#生成了dataframe对象
df = pd.DataFrame(dict)
print(df)
df.to_csv('./info.csv')
out:
name site age
0 小明 www.xiaoming.com 90
1 小红 www.xiaohong.com 40
2 小亮 www.xiaoliang.com 80
3 小林 www.xiaolin.org 98
上方是df对象,写入csv后打开csv如下:
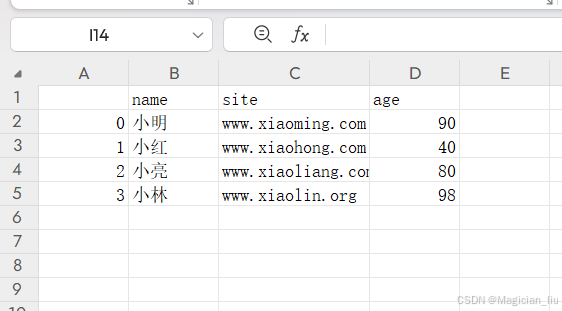
注意:在写⼊csv⽂件会默认将索引写⼊如果不需要索引则需添加参数进⾏处理
df.to_csv('site.csv', index=False)
3.pandas之读csv文件 : ps:pd.read_csv(‘nba.csv’)其返回dataframe对象
to_string()⽤于返回 DataFrame 类型的数据,如果不使⽤该
函数,则输出结果为数据的前⾯ 5 ⾏和末尾 5 ⾏,中间部分以
**…**代替。
例如:
import pandas as pd
data=pd.read_csv('./info.csv')
print(type(data))
print(data)
out:
<class 'pandas.core.frame.DataFrame'>
Unnamed: 0 name site age
0 0 小明 www.xiaoming.com 90
1 1 小红 www.xiaohong.com 40
2 2 小亮 www.xiaoliang.com 80
3 3 小林 www.xiaolin.org 98
注意:
它把我存入csv的索引也当成了数据读了进来,并自动又创建了索引。
4.数据处理
**to_string()⽤于返回 DataFrame 类型的数据,如果不使⽤该函数,则输出结果为数据的前⾯ 5 ⾏和末尾 5 ⾏,中间部分以…**代替。
即dataframe类型数据过多时中间会用**…**替代,而转换为str类型就会全部显示
data=pd.read_csv('./info.csv')
print(type(data)) #<class 'pandas.core.frame.DataFrame'>
print(type(data.to_string())) #<class 'str'>
4.1head()
**head( n)**⽅法⽤于读取前⾯的 n ⾏,如果不填参数 n ,默认返回 5 ⾏。
import pandas as pd
data=pd.read_csv('./info.csv')
print(type(data))
print(data.head())
print(data.head(10))
out:
<class 'pandas.core.frame.DataFrame'>
Unnamed: 0 name site age
0 0 小明 www.xiaoming.com 90
1 1 小红 www.xiaohong.com 40
2 2 小亮 www.xiaoliang.com 80
3 3 小林 www.xiaolin.org 98
4 3 小林 www.xiaolin.org 98
Unnamed: 0 name site age
0 0 小明 www.xiaoming.com 90
1 1 小红 www.xiaohong.com 40
2 2 小亮 www.xiaoliang.com 80
3 3 小林 www.xiaolin.org 98
4 3 小林 www.xiaolin.org 98
5 3 小林 www.xiaolin.org 98
6 3 小林 www.xiaolin.org 98
7 3 小林 www.xiaolin.org 98
8 3 小林 www.xiaolin.org 98
9 3 小林 www.xiaolin.org 98
4.2tail()
tail( n )⽅法⽤于读取尾部的 n ⾏,如果不填参数 n ,默认返回 5 ⾏,空⾏各个字段的值返回NaN。
实例 :
import pandas as pd
data=pd.read_csv('./info.csv')
print(type(data))
print(data.tail())
print(data.tail(10))
out:
<class 'pandas.core.frame.DataFrame'>
Unnamed: 0 name site age
11 3 小林 www.xiaolin.org 98
12 3 小林 www.xiaolin.org 98
13 3 小林 www.xiaolin.org 98
14 3 小林 www.xiaolin.org 98
15 3 小林 www.xiaolin.org 98
Unnamed: 0 name site age
6 3 小林 www.xiaolin.org 98
7 3 小林 www.xiaolin.org 98
8 3 小林 www.xiaolin.org 98
9 3 小林 www.xiaolin.org 98
10 3 小林 www.xiaolin.org 98
11 3 小林 www.xiaolin.org 98
12 3 小林 www.xiaolin.org 98
13 3 小林 www.xiaolin.org 98
14 3 小林 www.xiaolin.org 98
15 3 小林 www.xiaolin.org 98
4.3info()
info() ⽅法返回表格的⼀些基本信息
import pandas as pd
data=pd.read_csv('./info.csv')
print(data.info())
out:
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 16 entries, 0 to 15 ps:行数,索引从0-15
Data columns (total 4 columns): ps:列数,4列
# Column Non-Null Count Dtype ps:各列的数据类型
--- ------ -------------- -----
0 Unnamed: 0 16 non-null int64
1 name 16 non-null object
2 site 16 non-null object
3 age 16 non-null int64
dtypes: int64(2), object(2)
memory usage: 640.0+ bytes
None
non-null 为⾮空数据,我们可以看到上⾯的信息中,得知哪一列空值最多
三.pandas Excel文件
Pandas提供了⾮常强⼤的功能操作Excel,是数据分析领域处理Excel⽂档的重要⼯具
1.1读取excel (与csv类似)
pd.read_excel()
1.2 写入Excel (与csv类似)
df.to_excel()
读写excel时有很多参数:
index 是否写⼊索引默认为True
header 是否写⼊表头默认True
sheet_name 写⼊哪个sheet⻚默认sheet1
startrow 写⼊Excel数据开始⾏默认0⾏
startcol 写⼊Excel数据开始列默认0列
1.3实例时参数header的区别
import pandas as pd
data_header_None=pd.read_excel('./excel.xlsx',sheet_name='pandas',header=None)
print('header=None时:')
print(data_header_None)
data_header_true=pd.read_excel('./excel.xlsx',sheet_name='pandas')
print('header=True时:')
print(data_header_true)
out
header=None时:
0 1 2 3 4 5
0 销售年份 销售地区 销售人员 品名 数量 销售金额¥
1 43896 北京 苏珊 液晶电视 1 215000
2 44237 北京 李兵 微波炉 5 114400
3 43896 北京 苏珊 按摩椅 13 147000
4 44237 北京 赵琦 按摩椅 20 54400
5 44237 北京 白丁 微波炉 24 22400
6 43896 北京 白丁 微波炉 27 34500
7 44237 北京 白丁 按摩椅 28 36000
8 44237 北京 李兵 跑步机 30 132000
9 43896 北京 苏珊 显示器 33 265000
10 43896 北京 白丁 液晶电视 34 13500
11 44237 北京 赵琦 显示器 40 32500
12 44237 北京 赵琦 液晶电视 41 78000
13 43896 北京 白丁 液晶电视 43 170000
14 44237 北京 白丁 按摩椅 45 16000
15 43896 北京 苏珊 液晶电视 47 5000
16 43896 北京 苏珊 显示器 49 114000
17 44237 北京 李兵 跑步机 52 66000
18 44237 北京 赵琦 显示器 52 270000
19 43896 北京 苏珊 液晶电视 53 235000
20 44237 北京 赵琦 液晶电视 54 60000
21 44237 北京 李兵 跑步机 60 15400
22 44237 北京 赵琦 微波炉 65 2500
23 44237 北京 赵琦 按摩椅 68 115500
24 43896 北京 白丁 微波炉 69 12000
25 43896 北京 苏珊 显示器 76 49500
26 44237 北京 赵琦 显示器 77 205000
27 43896 北京 苏珊 显示器 98 73500
header=True时:
销售年份 销售地区 销售人员 品名 数量 销售金额¥
0 43896 北京 苏珊 液晶电视 1 215000
1 44237 北京 李兵 微波炉 5 114400
2 43896 北京 苏珊 按摩椅 13 147000
3 44237 北京 赵琦 按摩椅 20 54400
4 44237 北京 白丁 微波炉 24 22400
5 43896 北京 白丁 微波炉 27 34500
6 44237 北京 白丁 按摩椅 28 36000
7 44237 北京 李兵 跑步机 30 132000
8 43896 北京 苏珊 显示器 33 265000
9 43896 北京 白丁 液晶电视 34 13500
10 44237 北京 赵琦 显示器 40 32500
11 44237 北京 赵琦 液晶电视 41 78000
12 43896 北京 白丁 液晶电视 43 170000
13 44237 北京 白丁 按摩椅 45 16000
14 43896 北京 苏珊 液晶电视 47 5000
15 43896 北京 苏珊 显示器 49 114000
16 44237 北京 李兵 跑步机 52 66000
17 44237 北京 赵琦 显示器 52 270000
18 43896 北京 苏珊 液晶电视 53 235000
19 44237 北京 赵琦 液晶电视 54 60000
20 44237 北京 李兵 跑步机 60 15400
21 44237 北京 赵琦 微波炉 65 2500
22 44237 北京 赵琦 按摩椅 68 115500
23 43896 北京 白丁 微波炉 69 12000
24 43896 北京 苏珊 显示器 76 49500
25 44237 北京 赵琦 显示器 77 205000
26 43896 北京 苏珊 显示器 98 73500
excel表格如下:
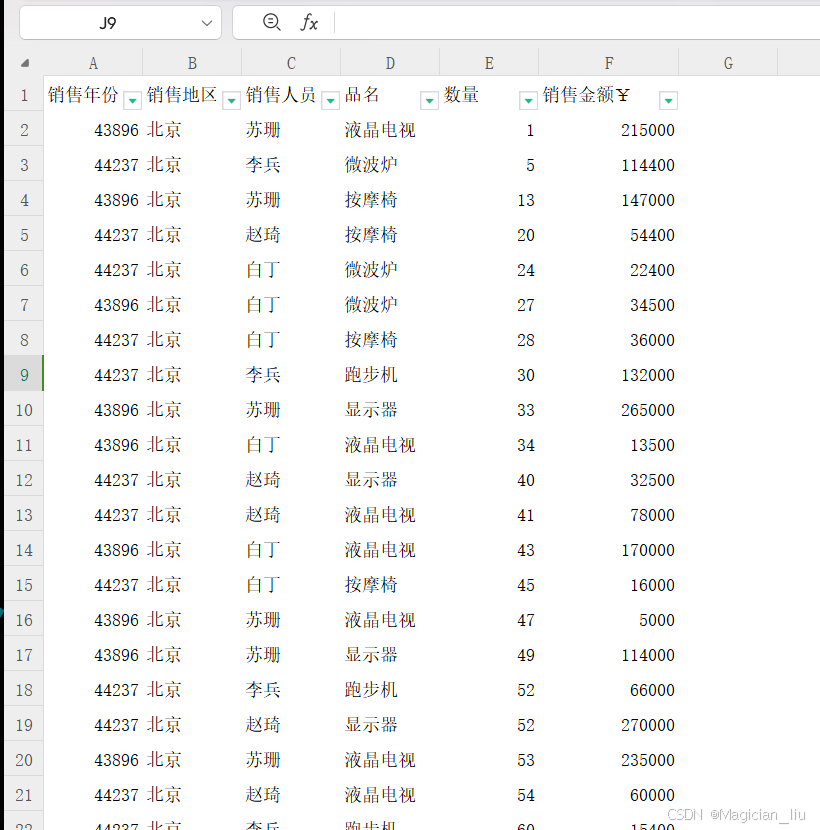
注意(默认把第一行作为表头读入,即列索引)
当前在读取Excel以后会默认把第⼀⾏作为表头,这样在写⼊的时候会⾃带格式,为了防⽌这个问题出现,所以需要再读取和写⼊的时候给定参数
当前上⾯处理csv的所有⽅法在这⾥可以同样去使⽤,这⾥就不在过多赘述咯~
四.pandas数据清洗
数据清洗是对⼀些没有⽤的数据进⾏处理的过程。
很多数据集存在数据缺失、数据格式错误、错误数据或重复数据的情况,如果要对使数据分析更加准确,就需要对这些没有⽤的数据进⾏处理。
因此我们将利⽤ Pandas包来进⾏数据清洗。
1.清洗空值
1.1isnull的使用(查找空值)
csv文件内容如下:
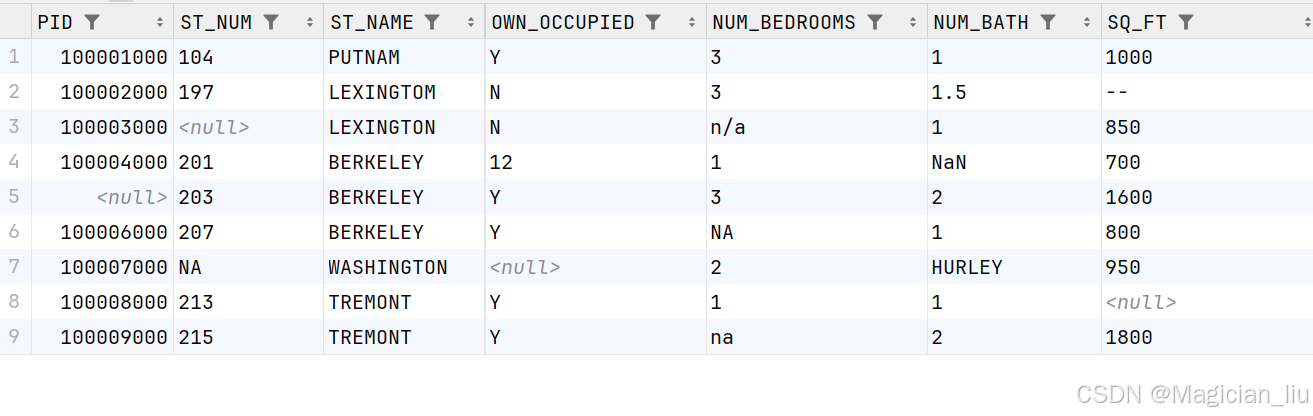
#isnull的使用
import pandas as pd
df=pd.read_csv('info.csv')
#打印所有列
print(df)
#打印NUM_BEDROOMS
print(df['NUM_BEDROOMS'])
print(type(df['NUM_BEDROOMS']))
out:
PID ST_NUM ST_NAME OWN_OCCUPIED NUM_BEDROOMS NUM_BATH SQ_FT
0 100001000.0 104.0 PUTNAM Y 3 1 1000
1 100002000.0 197.0 LEXINGTOM N 3 1.5 --
2 100003000.0 NaN LEXINGTON N NaN 1 850
3 100004000.0 201.0 BERKELEY 12 1 NaN 700
4 NaN 203.0 BERKELEY Y 3 2 1600
5 100006000.0 207.0 BERKELEY Y NaN 1 800
6 100007000.0 NaN WASHINGTON NaN 2 HURLEY 950
7 100008000.0 213.0 TREMONT Y 1 1 NaN
8 100009000.0 215.0 TREMONT Y na 2 1800
0 3
1 3
2 NaN
3 1
4 3
5 NaN
6 2
7 1
8 na
Name: NUM_BEDROOMS, dtype: object
<class 'pandas.core.series.Series'>
我们发现原本csv文件中的值n/a,NA读入时转换成了NAN,即为NULL类型,比如我们用isnull验证一下:
print(df['NUM_BEDROOMS'].isnull())
print(type(df['NUM_BEDROOMS'].isnull()))
out:
0 False
1 False
2 True
3 False
4 False
5 True
6 False
7 False
8 False
Name: NUM_BEDROOMS, dtype: bool
<class 'pandas.core.series.Series'>
我们发现数据na没有被转换成NAN,从而isnull之后为False,因此我们需要在实例化时添加参数,使其将对应的数据转换成NAN。
如下:
import pandas as pd
miss_values=['na','--','n/a']
df=pd.read_csv('info.csv',na_values=miss_values)
#打印NUM_BEDROOMS
print(df['NUM_BEDROOMS'].isnull())
out:
0 False
1 False
2 True
3 False
4 False
5 True
6 False
7 False
8 True
Name: NUM_BEDROOMS, dtype: bool
索引为8的数据变为了true。
代表成功将不需要的数据变为NAN,即为空,为之后清洗做准备
isnull()小结:
读取的数据中有无效的数据,在我们将其转为dataframe对象时,应添加na_values参数将无用的目标数据转换为NAN,其为空后即可方便对其删除
1.2dropna()的使用 (删除空值)
如果我们要删除包含空字段的⾏,可以使⽤**dropna()**⽅法,
语法格式如下:
DataFrame.dropna(axis=0, how='any',thresh=None, subset=None, inplace=False)
参数说明:
axis:默认为0,表示逢空值剔除整⾏,如果设置参数axis =1表示逢空值去掉整列。
how:默认为**'any’如果⼀⾏(或⼀列)⾥任何⼀个数据有出现 NA 就去掉整⾏,如果设置how=‘all’**⼀⾏(或列)都是 NA 才去掉这整⾏。
thresh:设置需要多少⾮空值的数据才可以保留下来的。
subset:设置想要检查的列。如果是多个列,可以使⽤列名的 list 作为参数。
inplace:如果设置 True,将计算得到的值直接覆盖之前的值并返回 None,修改的是源数据。
接下来的实例演示了删除包含空数据的⾏。
#dropna的使用
import pandas as pd
df=pd.read_csv('info.csv')
new_df=df.dropna()
print(df)
print(new_df)
out:
PID ST_NUM ST_NAME OWN_OCCUPIED NUM_BEDROOMS NUM_BATH SQ_FT
0 100001000.0 104.0 PUTNAM Y 3 1 1000
1 100002000.0 197.0 LEXINGTOM N 3 1.5 --
2 100003000.0 NaN LEXINGTON N NaN 1 850
3 100004000.0 201.0 BERKELEY 12 1 NaN 700
4 NaN 203.0 BERKELEY Y 3 2 1600
5 100006000.0 207.0 BERKELEY Y NaN 1 800
6 100007000.0 NaN WASHINGTON NaN 2 HURLEY 950
7 100008000.0 213.0 TREMONT Y 1 1 NaN
8 100009000.0 215.0 TREMONT Y na 2 1800
PID ST_NUM ST_NAME OWN_OCCUPIED NUM_BEDROOMS NUM_BATH SQ_FT
0 100001000.0 104.0 PUTNAM Y 3 1 1000
1 100002000.0 197.0 LEXINGTOM N 3 1.5 --
8 100009000.0 215.0 TREMONT Y na 2 1800
new_df所有包含空值的行都被删除了!!!!!!!!!!!!!!!!
1.2.1inplace参数(决定是否在源数据上修改)
默认情况下,dropna不会在源df上修改,而是复制产生了一个新的new_df
要想在源数据上修改,我们需要添加参数,示例如下:
new_df=df.dropna(inplace=True)
print(df)
print(new_df)
out:
PID ST_NUM ST_NAME OWN_OCCUPIED NUM_BEDROOMS NUM_BATH SQ_FT
0 100001000.0 104.0 PUTNAM Y 3 1 1000
1 100002000.0 197.0 LEXINGTOM N 3 1.5 --
8 100009000.0 215.0 TREMONT Y na 2 1800
None
new_df为空,而原来的df发生改变了!!!
1.2.2 subset参数(指定根据某些列上是否有空值来删除)
import pandas as pd
df=pd.read_csv('info.csv')
new_df=df.dropna(subset=['NUM_BEDROOMS']) #某列
#new_df=df.dropna(subset=['NUM_BEDROOMS','ST_NUM']) #多列
print(df)
print(new_df)
out:
PID ST_NUM ST_NAME OWN_OCCUPIED NUM_BEDROOMS NUM_BATH SQ_FT
0 100001000.0 104.0 PUTNAM Y 3 1 1000
1 100002000.0 197.0 LEXINGTOM N 3 1.5 --
2 100003000.0 NaN LEXINGTON N NaN 1 850
3 100004000.0 201.0 BERKELEY 12 1 NaN 700
4 NaN 203.0 BERKELEY Y 3 2 1600
5 100006000.0 207.0 BERKELEY Y NaN 1 800
6 100007000.0 NaN WASHINGTON NaN 2 HURLEY 950
7 100008000.0 213.0 TREMONT Y 1 1 NaN
8 100009000.0 215.0 TREMONT Y na 2 1800
PID ST_NUM ST_NAME OWN_OCCUPIED NUM_BEDROOMS NUM_BATH SQ_FT
0 100001000.0 104.0 PUTNAM Y 3 1 1000
1 100002000.0 197.0 LEXINGTOM N 3 1.5 --
3 100004000.0 201.0 BERKELEY 12 1 NaN 700
4 NaN 203.0 BERKELEY Y 3 2 1600
6 100007000.0 NaN WASHINGTON NaN 2 HURLEY 950
7 100008000.0 213.0 TREMONT Y 1 1 NaN
8 100009000.0 215.0 TREMONT Y na 2 1800
1.3fillna()的使用 (替换空值)
我们也可以**fillna()**⽅法来替换⼀些空字段:
例如使⽤ 12345 替换空字段:
#fillna的使用
import pandas as pd
df=pd.read_csv('info.csv')
new_df=df.fillna(123456)
print(df)
print(new_df)
out:
PID ST_NUM ST_NAME OWN_OCCUPIED NUM_BEDROOMS NUM_BATH SQ_FT
0 100001000.0 104.0 PUTNAM Y 3 1 1000
1 100002000.0 197.0 LEXINGTOM N 3 1.5 --
2 100003000.0 NaN LEXINGTON N NaN 1 850
3 100004000.0 201.0 BERKELEY 12 1 NaN 700
4 NaN 203.0 BERKELEY Y 3 2 1600
5 100006000.0 207.0 BERKELEY Y NaN 1 800
6 100007000.0 NaN WASHINGTON NaN 2 HURLEY 950
7 100008000.0 213.0 TREMONT Y 1 1 NaN
8 100009000.0 215.0 TREMONT Y na 2 1800
PID ST_NUM ST_NAME OWN_OCCUPIED NUM_BEDROOMS NUM_BATH SQ_FT
0 100001000.0 104.0 PUTNAM Y 3 1 1000
1 100002000.0 197.0 LEXINGTOM N 3 1.5 --
2 100003000.0 123456.0 LEXINGTON N 123456 1 850
3 100004000.0 201.0 BERKELEY 12 1 123456 700
4 123456.0 203.0 BERKELEY Y 3 2 1600
5 100006000.0 207.0 BERKELEY Y 123456 1 800
6 100007000.0 123456.0 WASHINGTON 123456 2 HURLEY 950
7 100008000.0 213.0 TREMONT Y 1 1 123456
8 100009000.0 215.0 TREMONT Y na 2 1800
inplace参数与dropna同理
我们也可以指定某⼀个列来替换数据:
使⽤ 12345 替换 PID 为空数据:
import pandas as pd
df=pd.read_csv('info.csv')
new_df=df['PID'].fillna(123456,inplace=True)
print(df)
print(new_df)
out:
PID ST_NUM ST_NAME OWN_OCCUPIED NUM_BEDROOMS NUM_BATH SQ_FT
0 100001000.0 104.0 PUTNAM Y 3 1 1000
1 100002000.0 197.0 LEXINGTOM N 3 1.5 --
2 100003000.0 NaN LEXINGTON N NaN 1 850
3 100004000.0 201.0 BERKELEY 12 1 NaN 700
4 123456.0 203.0 BERKELEY Y 3 2 1600
5 100006000.0 207.0 BERKELEY Y NaN 1 800
6 100007000.0 NaN WASHINGTON NaN 2 HURLEY 950
7 100008000.0 213.0 TREMONT Y 1 1 NaN
8 100009000.0 215.0 TREMONT Y na 2 1800
None
要对某列进行替换,我们只要选中某列再dropna()即可
替换空单元格的常⽤⽅法是计算列的均值、中位数值或众数。
Pandas使⽤mean()、**median()和mode()**⽅法计算列的均值(所有值加起来的平均值)、中位数值(排序后排在中间的数)和众数(出现频率最⾼的数)。
1.3.1使⽤mean()、median()和mode()⽅法计算列的均值并替换空单元格:
#mean(),median() mode()的使用
import pandas as pd
df=pd.read_csv('info.csv')
print('原数据如下:')
print(df)
#---------------------------------------------------
mean=df['PID'].mean() #求平均值
print('PID列的平均数为:',mean)
df['PID'].fillna(mean,inplace=True) #替换该列空值为平均值
#---------------------------------------------------
median=df['ST_NUM'].median() #求该列中位数
print('ST_NUM列的中位数为:',median)
df['ST_NUM'].fillna(median,inplace=True) #替换该列空值为中位数
#------------------------------------------------------
mode=df['NUM_BATH'].mode() #求该列众数
print('NUM列的众数为:',mode)
df['NUM_BATH'].fillna(mode,inplace=True) #替换该列空值为众数
#--------------------------------------------------------------
print('替换后的数据如下:')
print(df)
out:
原数据如下:
PID ST_NUM ST_NAME OWN_OCCUPIED NUM_BEDROOMS NUM_BATH SQ_FT
0 100001000.0 104.0 PUTNAM Y 3 1 1000
1 100002000.0 197.0 LEXINGTOM N 3 1.5 --
2 100003000.0 NaN LEXINGTON N NaN 1 850
3 100004000.0 201.0 BERKELEY 12 1 NaN 700
4 NaN 203.0 BERKELEY Y 3 2 1600
5 100006000.0 207.0 BERKELEY Y NaN 1 800
6 100007000.0 NaN WASHINGTON NaN 2 HURLEY 950
7 100008000.0 213.0 TREMONT Y 1 1 NaN
8 100009000.0 215.0 TREMONT Y na 2 1800
PID列的平均数为: 100005000.0
ST_NUM列的中位数为: 203.0
NUM列的众数为: 0 1
Name: NUM_BATH, dtype: object
替换后的数据如下:
PID ST_NUM ST_NAME OWN_OCCUPIED NUM_BEDROOMS NUM_BATH SQ_FT
0 100001000.0 104.0 PUTNAM Y 3 1 1000
1 100002000.0 197.0 LEXINGTOM N 3 1.5 --
2 100003000.0 203.0 LEXINGTON N NaN 1 850
3 100004000.0 201.0 BERKELEY 12 1 NaN 700
4 100005000.0 203.0 BERKELEY Y 3 2 1600
5 100006000.0 207.0 BERKELEY Y NaN 1 800
6 100007000.0 203.0 WASHINGTON NaN 2 HURLEY 950
7 100008000.0 213.0 TREMONT Y 1 1 NaN
8 100009000.0 215.0 TREMONT Y na 2 1800
进程已结束,退出代码为 0
2.清洗错误格式数据
数据格式错误的单元格会使数据分析变得困难,甚⾄不可能。
我们可以通过包含空单元格的⾏,或者将列中的所有单元格转换为相同格式的数据。
以下实例会格式化⽇期:
#清洗错误格式的数据
import pandas as pd
data={
'name':['小红','小明','小亮'],
'birthday':['2006/01/01','2003/06/01','20020612'],
}
df=pd.DataFrame(data)
print(df)
print('清洗后,将日期格式转换为正确的格式!')
df['birthday']=pd.to_datetime(df['birthday'])
print(df)
out:
name birthday
0 小红 2006/01/01
1 小明 2003/06/01
2 小亮 20020612
清洗后,将日期格式转换为正确的格式!
name birthday
0 小红 2006-01-01
1 小明 2003-06-01
2 小亮 2002-06-12
3.清洗错误数据(df.loc[2][‘age’]能查数据,但不能修改,修改要df.loc[2,'age']=18)
数据错误也是很常⻅的情况,我们可以对错误的数据进⾏替换或移除。
以下实例会替换错误年龄的数据:
3.1替换已经确定位置的值
#清洗错误数据
import pandas as pd
data={
'name':['小明','小红','小亮'],
'age':[10,20,122],
}
df=pd.DataFrame(data)
print(df)
df.loc[2,'age']=18
#print(df.loc[2]['age'])
#df.loc[1]['age']=100 会报错
print(df)
out:
name age
0 小明 10
1 小红 20
2 小亮 122
name age
0 小明 10
1 小红 20
2 小亮 18
进程已结束,退出代码为 0
3.2也可以设置条件语句:将 age ⼤于 120 的设置为 120:
import pandas as pd
data={
'name':['小明','小红','小亮'],
'age':[10,20,122],
}
df=pd.DataFrame(data)
print(df)
for index in df.index:
if df.loc[index,'age']>120:
df.loc[index,'age']=120
print(df)
out:
name age
0 小明 10
1 小红 20
2 小亮 122
name age
0 小明 10
1 小红 20
2 小亮 120
3.3可以将错误数据的⾏删除:df.drop(index,…)
将 age ⼤于 120 的删除:
import pandas as pd
data={
'name':['小明','小红','小亮'],
'age':[10,20,122],
}
df=pd.DataFrame(data)
print(df)
for index in df.index:
if df.loc[index,'age']>120:
df.drop(index,inplace=True)
print(df)
out:
name age
0 小明 10
1 小红 20
2 小亮 122
name age
0 小明 10
1 小红 20
进程已结束,退出代码为 0
4.Pandas 清洗重复数据(所有列相同才为重复数据)
如果我们要清洗重复数据,可以使⽤**duplicated()和drop_duplicates()**⽅法。
如果对应的数据是重复的,**duplicated()**会返回 True,否则返回 False。
4.1duplicated()
#删除重复数据
import pandas as pd
data={
'name':['小明','小红','magician','小明','magician'],
'age':[10,20,122,10,20],
}
df=pd.DataFrame(data)
print(df)
print(df.duplicated())
out:
name age
0 小明 10
1 小红 20
2 magician 122
3 小明 10
4 magician 20
0 False
1 False
2 False
3 True
4 False
dtype: bool
我们发现要所有列全一样才为重复数据!
4.2drop_duplicates()
import pandas as pd
data={
'name':['小明','小红','magician','小明','magician'],
'age':[10,20,122,10,20],
}
df=pd.DataFrame(data)
print(df)
df.drop_duplicates(inplace=True)
print(df)
out:
name age
0 小明 10
1 小红 20
2 magician 122
3 小明 10
4 magician 20
name age
0 小明 10
1 小红 20
2 magician 122
4 magician 20
现在我假设有如下情景,只要name相同,我就要删除重复的后面的数据,只保留第一个name,是否可以如下操作?
import pandas as pd
data={
'name':['小明','小红','magician','小明','magician'],
'age':[10,20,122,10,20],
}
df=pd.DataFrame(data)
print(df)
print(df['name'].duplicated())
df['name'].drop_duplicates(inplace=True)
print(df)
out:
name age
0 小明 10
1 小红 20
2 magician 122
3 小明 10
4 magician 20
-----------------------
0 False
1 False
2 False
3 True
4 True
Name: name, dtype: bool
----------------------------
name age
0 小明 10
1 小红 20
2 magician 122
3 小明 10
4 magician 20
删除失败!!!!!!!!!!!!!!
new_df=df['name'].drop_duplicates()
print(new_df)
out:
0 小明
1 小红
2 magician
Name: name, dtype: object
进程已结束,退出代码为 0
假想错误,经过百度查得:
可以添加subset参数来选择某列来进行判断重复标准来进行删除
4.3根据指定列发生重复进行删除(subset参数的使用)
import pandas as pd
data={
'name':['小明','小红','magician','小明','magician'],
'age':[10,20,122,10,20],
}
df=pd.DataFrame(data)
print(df)
df.drop_duplicates(subset='name',inplace=True)
print(df)
out:
name age
0 小明 10
1 小红 20
2 magician 122
3 小明 10
4 magician 20
name age
0 小明 10
1 小红 20
2 magician 122
进程已结束,退出代码为 0