相关概念
先来理解一下从导数到梯度的相关概念。
导数
一元函数中导数就是该函数所代表的曲线在这一点上的切线斜率。
多元函数的导数可以称为全导数,可以得到无数条曲线,每条曲线都有一条切线,每条切线与一个全导数相互对应,全导数可以通过偏导数计算。
偏导数
多元函数中的概念,通俗地讲就是固定其他自变量所得到平面曲线的某一点的切线斜率。
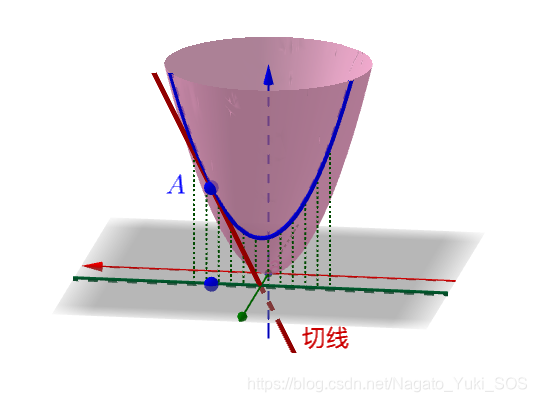
方向导数
顾名思义,就是某一方向的导数。偏导数是对于水平和垂直平面来说的,而方向导数是针对各个不同方向的平面来说的。
关于以上导数如果还不懂的话可看:全导数、偏导数、方向导数
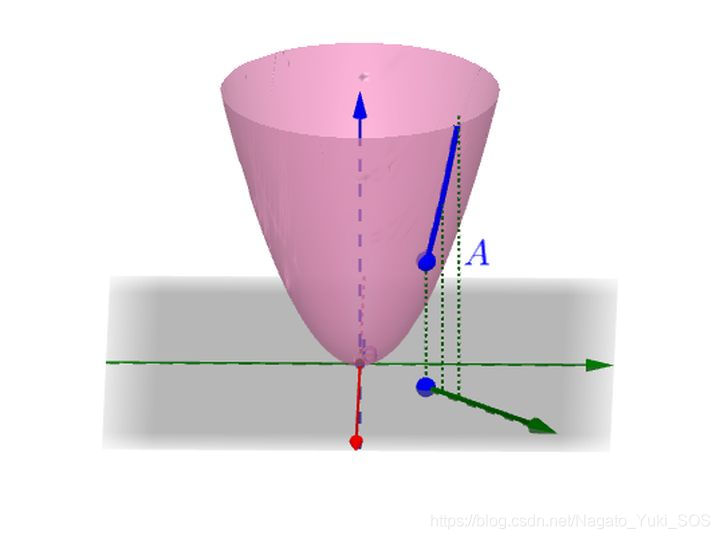
梯度
梯度是一个矢量(向量),方向与最大方向导数的方向一致,也就是使得导数最大的方向。
计算和表示方法如下图:

梯度的值(模)为方向导数的最大值,感兴趣可以直接在百度百科上看到。
强烈推荐文章:梯度与方向导数的关系(链接中有动态效果,可以更好地理解方向导数的几何意义)
梯度下降法
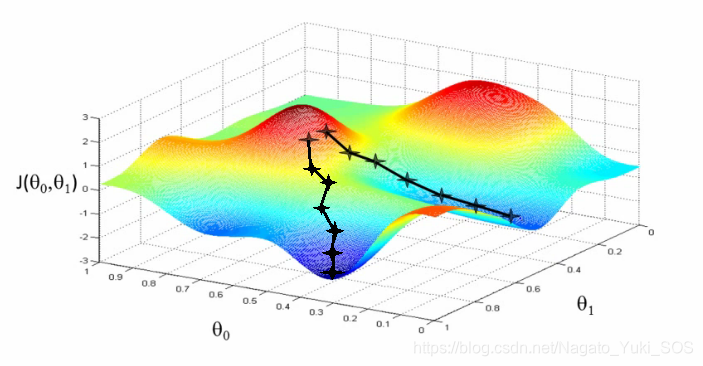
深度学习通过最小化损失函数来寻找到模型的最优参数,通过梯度下降法来一步步的迭代来寻找损失函数的最小值。具体思想像上图一样,一次次沿着梯度的反方向就能达到最低点(即损失函数最小值),此时的参数就是我们要的最优参数(即最优解)。
自动求梯度
正片开始。
PyTorch提供的autograd包能够根据输入和前向传播过程自动构建计算图,并执行反向传播。下面将介绍如何使用autograd包来进行自动求梯度的有关操作。
概念
Tensor是这个包的核心类,如果将其属性.requires_grad设置为True,它将开始追踪(track)在其上的所有操作(这样就可以利用链式法则进行梯度传播了)。完成计算后,可以调用.backward()来完成所有梯度计算。此Tensor的梯度将累积到.grad属性中。
注意在
y.backward()时,如果y是标量,则不需要为backward()传入任何参数;否则,需要传入一个与y同形的Tensor。后面会详细解释。
如果不想要被继续追踪,可以调用.detach()将其从追踪记录中分离出来,这样就可以防止将来的计算被追踪,这样梯度就传不过去了。此外,还可以用with torch.no_grad()将不想被追踪的操作代码块包裹起来,这种方法在评估模型的时候很常用,因为在评估模型时,我们并不需要计算可训练参数(requires_grad=True)的梯度。
Function是另外一个很重要的类。Tensor和Function互相结合就可以构建一个记录有整个计算过程的有向无环图(DAG)。每个Tensor都有一个.grad_fn属性,该属性即创建该Tensor的Function, 就是说该Tensor是不是通过某些运算得到的,若是,则grad_fn返回一个与这些运算相关的对象,否则是None。
下面通过一些例子来理解这些概念。
Tensor
创建一个Tensor并设置requires_grad=True:
x = torch.ones(2, 2, requires_grad=True)
print(x)
print(x.grad_fn)
输出:
tensor([[1., 1.],
[1., 1.]], requires_grad=True)
None
再做一下运算操作:
y = x + 2
print(y)
print(y.grad_fn)
输出:
tensor([[3., 3.],
[3., 3.]], grad_fn=<AddBackward>)
<AddBackward object at 0x1100477b8>
注意x是直接创建的,所以它没有grad_fn, 而y是通过一个加法操作创建的,所以它有一个为<AddBackward>的grad_fn。
像x这种直接创建的称为叶子节点,叶子节点对应的grad_fn是None。
x = torch.ones(2, 2, requires_grad=True)
y = x + 2
print(x.is_leaf, y.is_leaf) # True False
再来点复杂度运算操作:
x = torch.ones(2, 2, requires_grad=True)
y = x + 2
z = y * y * 3
out = z.mean() #计算平均值,返回一个标量
print(z, out)
输出:
tensor([[27., 27.],
[27., 27.]], grad_fn=<MulBackward>) tensor(27., grad_fn=<MeanBackward1>)
通过.requires_grad_()来用in-place的方式改变requires_grad属性:
a = torch.randn(2, 2) # 缺失情况下默认 requires_grad = False
a = ((a * 3) / (a - 1))
print(a.requires_grad) # False
a.requires_grad_(True)
print(a.requires_grad) # True
b = (a * a).sum()
print(b.grad_fn)
输出:
False
True
<SumBackward0 object at 0x118f50cc0>
反向传播求梯度
因为out是一个标量,所以调用backward()时不需要指定求导变量:
x = torch.ones(2, 2, requires_grad=True)
y = x + 2
z = y * y * 3
out = z.mean() #计算平均值,返回一个标量
out.backward() # 等价于 out.backward(torch.tensor(1.))
我们来看看out关于x的梯度
d
(
o
u
t
)
d
x
\frac{d(out)}{dx}
dxd(out):
print(x.grad)
输出:
tensor([[4.5000, 4.5000],
[4.5000, 4.5000]])
我们令out为
o
o
o , 因为
o
=
1
4
∑
i
=
1
4
z
i
=
1
4
∑
i
=
1
4
3
(
x
i
+
2
)
2
o=\frac14\sum_{i=1}^4z_i=\frac14\sum_{i=1}^43(x_i+2)^2
o=41i=1∑4zi=41i=1∑43(xi+2)2
所以
∂
o
∂
x
i
∣
x
i
=
1
=
9
2
=
4.5
\frac{\partial{o}}{\partial{x_i}}\bigr\rvert_{x_i=1}=\frac{9}{2}=4.5
∂xi∂o∣∣xi=1=29=4.5
所以上面的输出是正确的。
数学上,如果有一个函数值和自变量都为向量的函数
y
⃗
=
f
(
x
⃗
)
\vec{y}=f(\vec{x})
y=f(x), 那么
y
⃗
\vec{y}
y 关于
x
⃗
\vec{x}
x 的梯度就是一个雅可比矩阵(Jacobian matrix):
J
=
(
∂
y
1
∂
x
1
⋯
∂
y
1
∂
x
n
⋮
⋱
⋮
∂
y
m
∂
x
1
⋯
∂
y
m
∂
x
n
)
J=\left(\begin{array}{ccc} \frac{\partial y_{1}}{\partial x_{1}} & \cdots & \frac{\partial y_{1}}{\partial x_{n}}\\ \vdots & \ddots & \vdots\\ \frac{\partial y_{m}}{\partial x_{1}} & \cdots & \frac{\partial y_{m}}{\partial x_{n}} \end{array}\right)
J=⎝⎜⎛∂x1∂y1⋮∂x1∂ym⋯⋱⋯∂xn∂y1⋮∂xn∂ym⎠⎟⎞
而torch.autograd这个包就是用来计算一些雅克比矩阵的乘积的。例如,如果
v
v
v 是一个标量函数的
l
=
g
(
y
⃗
)
l=g\left(\vec{y}\right)
l=g(y) 的梯度:
v
=
(
∂
l
∂
y
1
⋯
∂
l
∂
y
m
)
v=\left(\begin{array}{ccc}\frac{\partial l}{\partial y_{1}} & \cdots & \frac{\partial l}{\partial y_{m}}\end{array}\right)
v=(∂y1∂l⋯∂ym∂l)
那么根据链式法则我们有
l
l
l 关于
x
⃗
\vec{x}
x 的雅克比矩阵就为:
v
J
=
(
∂
l
∂
y
1
⋯
∂
l
∂
y
m
)
(
∂
y
1
∂
x
1
⋯
∂
y
1
∂
x
n
⋮
⋱
⋮
∂
y
m
∂
x
1
⋯
∂
y
m
∂
x
n
)
=
(
∂
l
∂
x
1
⋯
∂
l
∂
x
n
)
v J=\left(\begin{array}{ccc}\frac{\partial l}{\partial y_{1}} & \cdots & \frac{\partial l}{\partial y_{m}}\end{array}\right) \left(\begin{array}{ccc} \frac{\partial y_{1}}{\partial x_{1}} & \cdots & \frac{\partial y_{1}}{\partial x_{n}}\\ \vdots & \ddots & \vdots\\ \frac{\partial y_{m}}{\partial x_{1}} & \cdots & \frac{\partial y_{m}}{\partial x_{n}} \end{array}\right)=\left(\begin{array}{ccc}\frac{\partial l}{\partial x_{1}} & \cdots & \frac{\partial l}{\partial x_{n}}\end{array}\right)
vJ=(∂y1∂l⋯∂ym∂l)⎝⎜⎛∂x1∂y1⋮∂x1∂ym⋯⋱⋯∂xn∂y1⋮∂xn∂ym⎠⎟⎞=(∂x1∂l⋯∂xn∂l)
注意:grad在反向传播过程中是累加的(accumulated),这意味着每一次运行反向传播,梯度都会累加之前的梯度,所以一般在反向传播之前需把梯度清零。
x = torch.ones(2, 2, requires_grad=True)
y = x + 2
z = y * y * 3
out = z.mean() #计算平均值,返回一个标量
# 再来反向传播一次,注意grad是累加的
out2 = x.sum()
out2.backward()
print(x.grad)
out3 = x.sum()
x.grad.data.zero_()
out3.backward()
print(x.grad)
输出:
tensor([[5.5000, 5.5000],
[5.5000, 5.5000]])
tensor([[1., 1.],
[1., 1.]])
现在我们解释之前留下的问题,为什么在
y.backward()时,如果y是标量,则不需要为backward()传入任何参数;否则,需要传入一个与y同形的Tensor?
简单来说就是为了避免向量(甚至更高维张量)对张量求导,而转换成标量对张量求导。举个例子,假设形状为m x n的矩阵 X 经过运算得到了p x q的矩阵 Y,Y 又经过运算得到了s x t的矩阵 Z。那么按照前面讲的规则,dZ/dY 应该是一个s x t x p x q四维张量,dY/dX 是一个p x q x m x n的四维张量。问题来了,怎样反向传播?怎样将两个四维张量相乘???这要怎么乘???就算能解决两个四维张量怎么乘的问题,四维和三维的张量又怎么乘?导数的导数又怎么求,这一连串的问题,感觉要疯掉……
为了避免这个问题,我们不允许张量对张量求导,只允许标量对张量求导,求导结果是和自变量同形的张量。所以必要时我们要把张量通过将所有张量的元素加权求和的方式转换为标量,举个例子,假设y由自变量x计算而来,w是和y同形的张量,则y.backward(w)的含义是:先计算l = torch.sum(y * w),则l是个标量,然后求l对自变量x的导数。
参考
来看一些实际例子。
x = torch.tensor([1.0, 2.0, 3.0, 4.0], requires_grad=True)
y = 2 * x
z = y.view(2, 2)
print(z)
输出:
tensor([[2., 4.],
[6., 8.]], grad_fn=<ViewBackward>)
现在 z 不是一个标量,所以在调用backward时需要传入一个和z同形的权重向量进行加权求和得到一个标量。
v = torch.tensor([[1.0, 0.1], [0.01, 0.001]], dtype=torch.float)
z.backward(v)
print(x.grad)
输出:
tensor([2.0000, 0.2000, 0.0200, 0.0020])
注意,x.grad是和x同形的张量。
再来看看中断梯度追踪的例子:
x = torch.tensor(1.0, requires_grad=True)
y1 = x ** 2
with torch.no_grad():
y2 = x ** 3
y3 = y1 + y2
print(x.requires_grad)
print(y1, y1.requires_grad) # True
print(y2, y2.requires_grad) # False
print(y3, y3.requires_grad) # True
输出:
True
tensor(1., grad_fn=<PowBackward0>) True
tensor(1.) False
tensor(2., grad_fn=<ThAddBackward>) True
可以看到,上面的y2是没有grad_fn而且y2.requires_grad=False的,而y3是有grad_fn的。如果我们将y3对x求梯度的话会是多少呢?
y3.backward()
print(x.grad)
输出:
tensor(2.)
为什么是2呢?
y
3
=
y
1
+
y
2
=
x
2
+
x
3
y_3 = y_1 + y_2 = x^2 + x^3
y3=y1+y2=x2+x3,当
x
=
1
x=1
x=1 时
d
y
3
d
x
\frac {dy_3} {dx}
dxdy3 不应该是5吗?事实上,由于
y
2
y_2
y2 的定义是被torch.no_grad():包裹的,所以与
y
2
y_2
y2 有关的梯度是不会回传的,只有与
y
1
y_1
y1 有关的梯度才会回传,即
x
2
x^2
x2 对
x
x
x 的梯度。
上面提到,y2.requires_grad=False,所以不能调用 y2.backward(),会报错:
RuntimeError: element 0 of tensors does not require grad and does not have a grad_fn
此外,如果我们想要修改tensor的数值,但是又不希望被autograd记录(即不会影响反向传播),那么我么可以对tensor.data进行操作。
x = torch.ones(1,requires_grad=True)
print(x.data) # 还是一个tensor
print(x.data.requires_grad) # 但是已经是独立于计算图之外
y = 2 * x
x.data *= 100 # 只改变了值,不会记录在计算图,所以不会影响梯度传播
y.backward()
print(x) # 更改data的值也会影响tensor的值
print(x.grad)
输出:
tensor([1.])
False
tensor([100.], requires_grad=True)
tensor([2.])
本文参考链接:
动手学习深度学习Pytorch
梯度与方向导数的关系
全导数、偏导数、方向导数
梯度-百度百科