✍ 个人博客:https://blog.csdn.net/Newin2020?type=blog
📝 专栏地址:https://blog.csdn.net/newin2020/category_12801353.html
📣 专栏定位:为 0 基础刚入门 Python 的小伙伴提供详细的讲解,也欢迎大佬们一起交流~
📚 专栏简介:在这个专栏,我将带着大家从 0 开始入门 Python 的学习。在这个 Python 的新人系列专栏下,将会总结 Python 入门基础的一些知识点,方便大家快速入门学习~
❤️ 如果有收获的话,欢迎点赞 👍 收藏 📁 关注,您的支持就是我创作的最大动力 💪
1. 线程和进程的区别
- 进程:进程在操作系统中可以独立运行是程序在执行过程中分配和管理资源的基本单位每一个进程都有一个自己的地址空间。
- 线程:线程是进程中的一个实例作为系统(CPU)调度和分派的基本单位它与同属一个进程的其他的线程共享进程所拥有的全部资源。
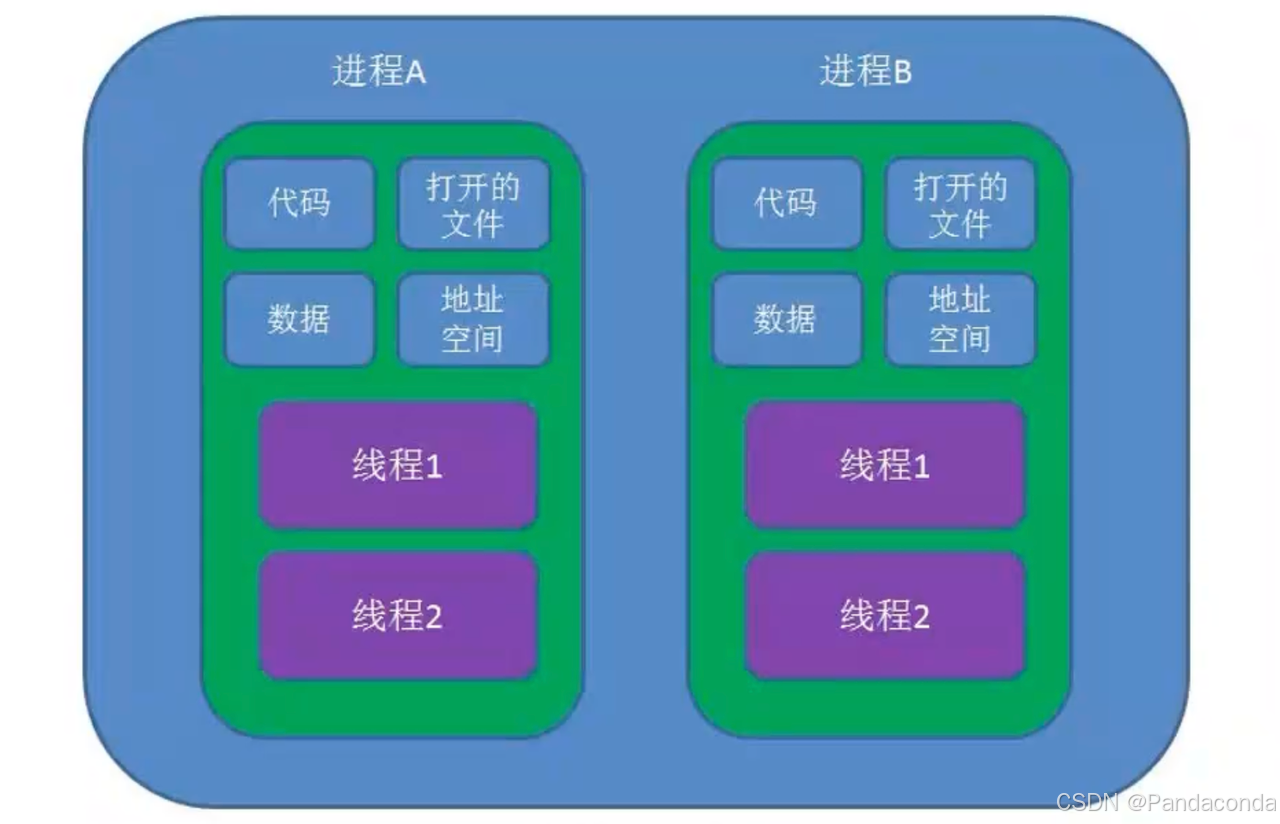
操作系统上可以运行多个进程,一个进程可以有多个线程,多个我程可以被分配到不同的 CPU 核上跑,但实际上每个 CPU 核上只有一个线程,只是这个线程在不停的进行上下文的切换。
- Python 多线程适合 I/O 操作密集型的任务(I/O 操作不占用 CPU,从硬盘、从网络、从内存读数据都算 I/O)。
- Python 多线程不适合 CPU 密集操作型的任务,主要使用 CPU 来计算,如大量的数学计算。
- 进程之间不需要使用 GIL 锁,因为进程是独立的,且默认是不会共享数据。
2. 单线程
在单线程程序中可能包含多个方法,运行程序后,默认是在一个主线程里按顺序运行。
这意味着程序在任何给定的时间点只能执行一个操作,必须按顺序完成一项任务后才能进行下一项任务,无法同时进行多个任务。
例如,如果一个程序中有多个操作,如读取文件、进行计算和写入文件,在单线程环境中,它会先读取文件,完成后再进行计算,计算结束才会写入文件,依次顺序执行。
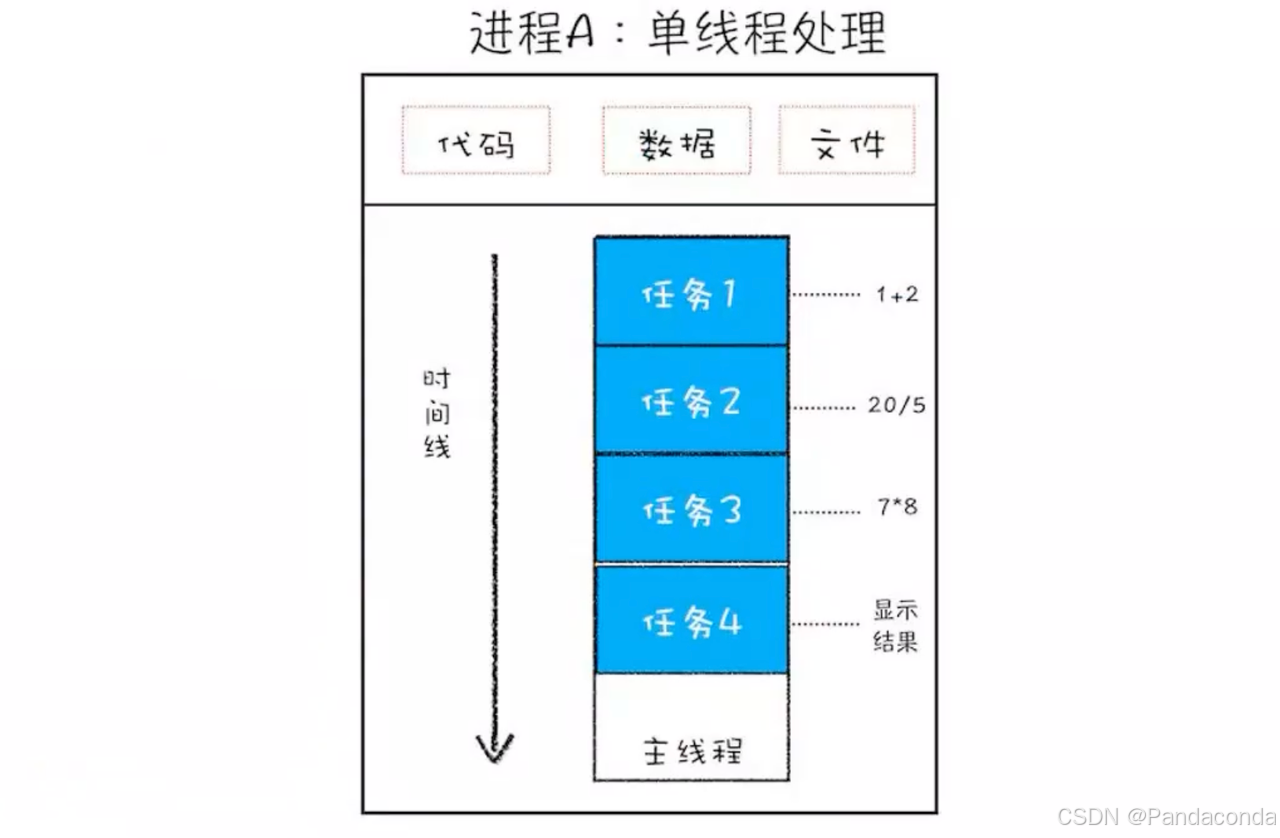
单线程程序相对简单,不存在线程间的同步和资源竞争问题,但在处理多个耗时操作时,可能会导致程序的响应性和效率较低。
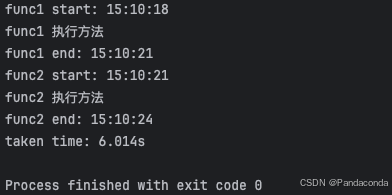
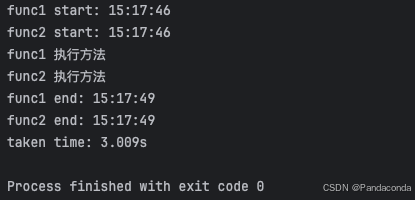
举个计算时间的例子,在下述代码中,func1 和 func2 两个函数会依次执行,因为这是在单线程环境中,所以无法同时执行这两个任务。
import time
import threading
def exe_time(func):
def new_func(*args, **kwargs):
print("%s start: %s" % (func.__name__, time.strftime("%X", time.localtime())))
back = func(*args, **kwargs)
print("%s end: %s" % (func.__name__, time.strftime("%X", time.localtime())))
return back
return new_func
@exe_time
def func1():
time.sleep(1)
print("func1 执行方法")
time.sleep(2)
@exe_time
def func2():
time.sleep(1)
print("func2 执行方法")
time.sleep(2)
if __name__ == "__main__":
before = time.time()
func1()
func2()
after = time.time()
print("taken time: %.3fs " % (after - before))
从执行结果可以看出全程花了 6.014s,因此 func1 和 func2 是串行执行的,func2 要等 func1 执行完才能执行。
3. 多线程
多线程是指在一个程序中同时运行多个线程。线程是进程中的执行单元,一个进程可以包含多个线程。
在多线程编程中,多个线程可以并发地执行,即在同一时间段内,多个线程都在推进各自的任务。这使得程序能够在同一时间内处理多个任务,从而提高程序的并发性和响应性。
例如,一个多线程的网络服务器可以同时处理多个客户端的请求,一个图形界面应用程序可以在处理用户输入的同时在后台进行数据加载等任务。
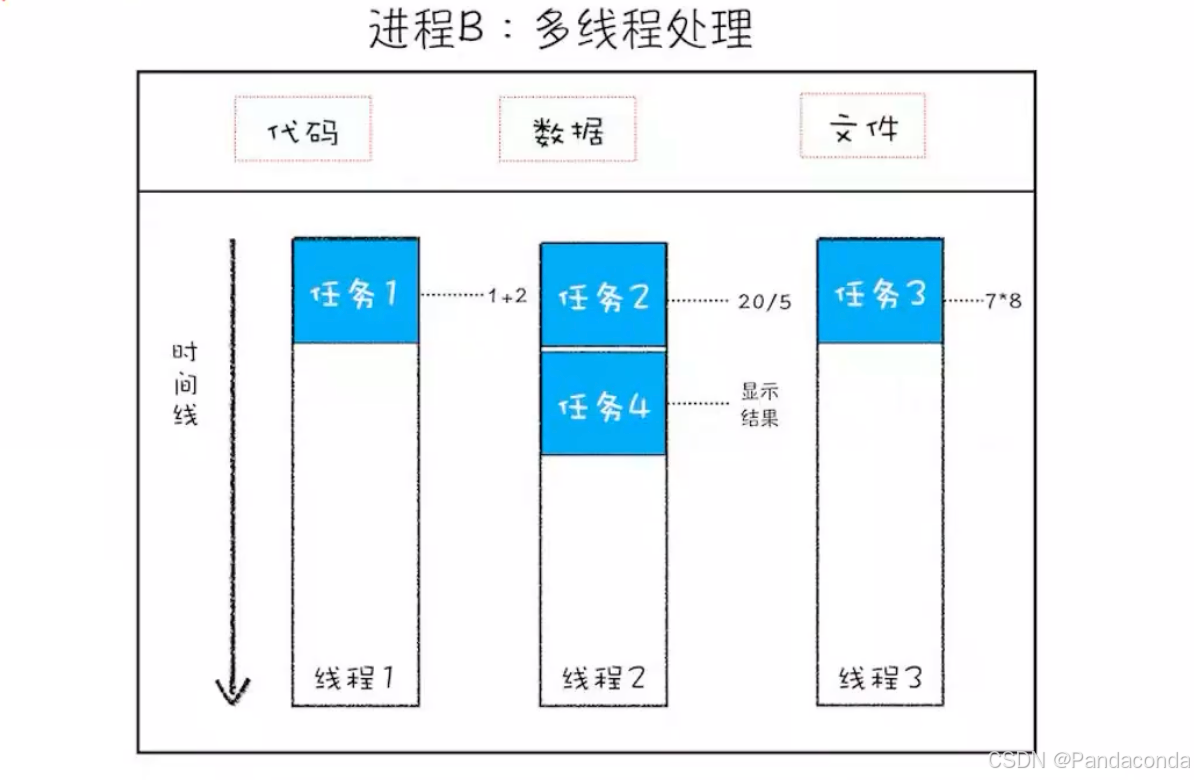
每个线程都有自己的执行上下文,包括程序计数器、栈等,但它们共享进程的内存空间和其他资源。
多线程编程可以提高 CPU 的利用率,特别是在存在大量 I/O 操作或等待的情况下,一个线程被阻塞时,其他线程可以继续执行。然而,多线程编程也带来了一些挑战,如线程同步、资源竞争和死锁等问题,需要谨慎处理以确保程序的正确性和稳定性。
3.1 实现方式
threading
在 Python3 标准库中,有两个模块 _thread 和 threading 可以提供多线程支持。但由于 _thread 是低级模块,很多功能还不完善,一般只会用到 threading 这个比较完善的高级模块,因此这里只讨论 threading 模块的使用。
Python 中使用线程有两种方式:函数或者用类来包装线程对象。
采用函数创建多线程语法如下:
threading.Thread(target=function, args[, kwargs])
参数说明:
- function - 线程函数
- args - 传递给线程函数的参数,他必须是个 tuple 类型
- kwargs - 可选参数
- 不带参数
我们还是以上面那个计算时间的函数为例,这里我们将单线程优化成多线程模式。
import time
import threading
def exe_time(func):
def new_func(*args, **kwargs):
print("%s start: %s" % (func.__name__, time.strftime("%X", time.localtime())))
back = func(*args, **kwargs)
print("%s end: %s" % (func.__name__, time.strftime("%X", time.localtime())))
return back
return new_func
@exe_time
def func1():
time.sleep(1)
print("func1 执行方法")
time.sleep(2)
@exe_time
def func2():
time.sleep(1)
print("func2 执行方法")
time.sleep(2)
if __name__ == "__main__":
before = time.time()
t1 = threading.Thread(target=func1)
t1.start()
t2 = threading.Thread(target=func2)
t2.start()
t1.join()
t2.join()
after = time.time()
print("taken time: %.3fs " % (after - before))
可以发现执行时间明显要快了差不多一倍。
- 带参数
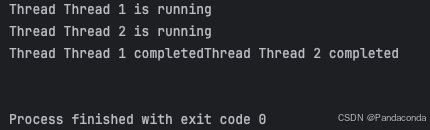
同样,我们再举一个带参数的例子。
import threading
import time
# 定义线程执行的函数
def thread_function(name):
print(f"Thread {name} is running")
time.sleep(2)
print(f"Thread {name} completed")
# 创建线程
thread1 = threading.Thread(target=thread_function, args=("Thread 1",))
thread2 = threading.Thread(target=thread_function, args=("Thread 2",))
# 启动线程
thread1.start()
thread2.start()
# 等待线程完成(可选)
thread1.join()
thread2.join()
继承 Thread 类
我们也可以通过直接从 threading.Thread 继承创建一个新的子类,并实例化后调用 start() 方法启动新线程,即它调用了线程的 run() 方法。
import threading
import time
class MyThread(threading.Thread):
def __init__(self):
threading.Thread.__init__(self)
def run(self):
#重写 run 方法,run 方法中是该线程要执行的动作
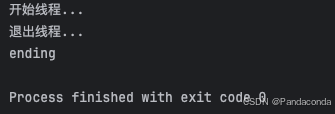
print("开始线程...")
time.sleep(3)
print("退出线程...")
# 创建自定义的线程类对象
t1 = MyThread()
# 调用自定义线程类中的继承自父类的 start 方法,执行自定义线程类中的 run 方法
t1.start()
t1.join()
print('ending')
3.2 常用方法及属性
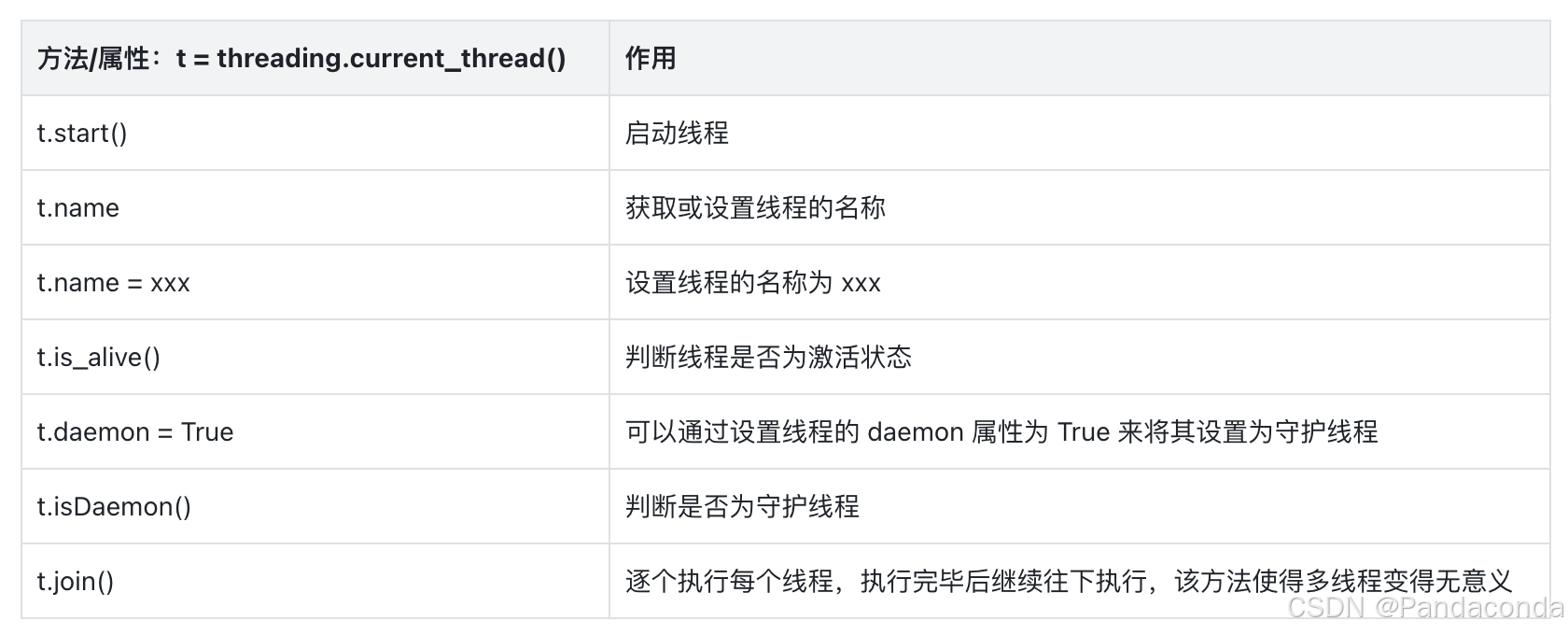
程序默认在一个线程中执行,这个线程称为主线程。
import threading
t = threading.current_thread()
print(t.name) # MainThread
print(t.is_alive()) # True
join 方法
join() 方法:主线程 A 中,创建了子线程 B,并且在主线程 A 中调用了 B.join()。那么主线程 A 会在调用的地方等待,直到子线程 B 完成操作后,才可以接着往下执行。
语法:
join([timeout])
参数为可选,代表线程运行的最大时间,即如果超过这个时间,不管这个此线程有没有执行完毕都会被回收,然后主线程或函数都会接着执行的。
- 不带 timeout 参数
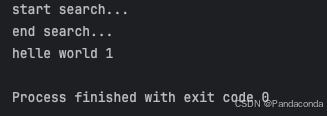
先举个不带参数的例子,可以发现使用 t.join() 之后,主线程会等待线程 t 执行完之后,才会执行后续的逻辑。
import threading
import time
def search():
print('start search...')
time.sleep(5)
print("end search...")
t = threading.Thread(target=search)
t.start()
t.join()
print("helle world 1")
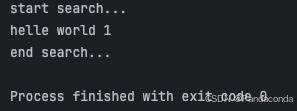
- 带 timeout 参数
再来看一个带参数的例子,我这里设置了 1 秒的超时时间即 t.join(1),而这 1 秒的时间要比我子线程执行的时间要短。因此,主线程只会等 1 秒钟,不会等到子线程 t 执行完,而是继续执行后面的打印操作。
import threading
import time
def search():
print('start search...')
time.sleep(5)
print("end search...")
t = threading.Thread(target=search)
t.start()
t.join(1) # 设置1秒钟超时时间
print("helle world 1")
daemon 属性
daemon 属性用于将线程设置为守护线程(Daemon Thread)。
守护线程是一种在后台运行的线程,当所有的非守护线程结束时,守护线程会自动结束,即使它仍在运行中。
Tips:
daemon 属性必须在 t.start() 即子线程执行之前设置,不然不起作用。
- 不设置 daemon 属性
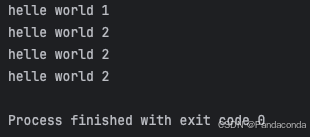
先来看一下下述案例正常执行的效果,可以发现主线程并没有等待子线程执行完,就往下执行了。
import threading
import time
def search():
for i in range(3):
time.sleep(1)
print("helle world 2")
t = threading.Thread(target=search)
t.start()
print("helle world 1")
- 设置 daemon 属性
接下来,我将案例中的子线程的 daemon 属性设置为 True,即设置为守护线程。那么主线程执行结束之后,子线程也会跟着结束,不会执行后续的操作了。
import threading
import time
def search():
for i in range(3):
time.sleep(1)
print("helle world 2")
t = threading.Thread(target=search)
t.daemon = True
t.start()
print("helle world 1")
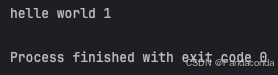
上面这个结果,看不出子线程是否执行了。为了理解的更透彻一些,我在主线程后再加两行代码,主线程执行完第一个 print 语句后不会立马结束,而是睡眠个 2 秒,再执行一个 print 语句才结束。
那么从结果中就可以发现,子线程确实执行了的,因为打印了一行语句出来,只不过在主线程结束之后,就没有继续往下执行了。
import threading
import time
def search():
for i in range(3):
time.sleep(1)
print("helle world 2")
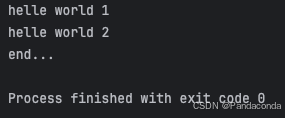
t = threading.Thread(target=search)
t.daemon = True
t.start()
print("helle world 1")
time.sleep(2)
print("end...")