在互联网上,有许多有趣的内容等待我们去挖掘和收集。今天,我们就来深入了解一段 Python 代码,它能够帮助我们从指定网站抓取笑话内容,并将其整理保存为 CSV 文件,方便后续查看和分析。
结果展示(文末附完整代码):
目录
一、代码整体介绍
这段代码主要实现了从 “xiaohua.zol.com.cn” 这个网站上抓取笑话相关信息的功能。它通过几个函数的协作,完成了获取笑话列表、解析每个笑话的具体内容以及将数据保存到 CSV 文件的一系列操作。
二、代码准备与环境搭建
在开始解读代码之前,确保你已经安装了以下必要的库:
csv:这是 Python 内置的用于处理 CSV 文件(逗号分隔值文件)的库,通过它我们可以方便地进行数据的读写操作,将抓取到的笑话数据保存为 CSV 格式。re:正则表达式库,在代码中起到了至关重要的作用,用于在网页文本内容中进行模式匹配,提取我们需要的笑话标题、链接以及具体内容等信息。requests:一个常用的用于发送 HTTP 请求的库,通过它我们可以向目标网站发送请求,获取网页的源代码,进而从中提取我们所需的数据。
如果你还没有安装requests库(因为csv和re是 Python 内置库,一般无需单独安装),可以通过以下命令在命令行中进行安装(假设你已经安装了 Python 并且配置好了相应的环境):
pip install requests
三、Get函数:获取笑话列表页面信息
Get函数是整个抓取流程的第一步,它接受一个参数num,这个参数代表要获取的笑话列表页面的页码。
1. 设置请求头(headers)和 Cookies
在函数内部,首先设置了请求头(headers)和 Cookies 信息。请求头包含了诸如浏览器类型、接受的内容类型等信息,模拟了一个真实浏览器访问网站的情况,有助于顺利获取网页内容。Cookies 则是网站在之前访问时可能存储在客户端的一些信息,这里设置的具体值可能是在之前与该网站交互过程中获取到的,或者是通过分析网站的访问机制确定的。
headers = {
"authority": "xiaohua.zol.com.cn",
"accept": "text/ht........
"pragma": "no-cache",
"referer": "https://xiaohua.zol.com.cn/",
"sec-ch-ua": "^\\^Not.A/Brand^^;v=^\\^8^^, ^\\^Chromium^^;v=^\\^114^^, ^\\^Microsoft",
"sec-ch-ua-mobile": "?0",
"sec-ch-ua-platform": "^\\^Windows^^",
"sec-fetch-dest": "document",
"sec-fetch-mode": "navigate",
"sec-fetch-site": "same-origin",
"sec-fetch-user": "?1",
"upgrade-insecure-requests": "1",
......
cookies = {
"ip_ck": "3Iqk0oW.....c3Mzg^%^3D",
"Hm_lvt_a.....
"questionnaire_close_today": "1689811201",
"questionnaire_close_total": "1",
"questionnaire_pv": "1689811230"
}
2. 发送请求获取页面内容并提取笑话链接与标题
接着,根据传入的页码num构建了要访问的 URL,然后使用requests库发送 GET 请求获取该页面的文本内容。之后,通过正则表达式re.findall从获取到的页面内容中提取出笑话的链接和标题信息。
url = f"https://xiaohua.zol.com.cn/new/{num}.html"
response = requests.get(url, headers=headers, cookies=cookies).text
r1 = re.findall(r'<span class="article-title"><a target="_blank" href="(.*?)">(.*?)</a></span>', response, re.S)
for r in r1:
href = 'https://xiaohua.zol.com.cn' + r[0]
title = r[1]
parse(title, href)
对于提取到的每个笑话的链接和标题,都会调用parse函数进一步解析该笑话的具体内容。
四、parse函数:解析单个笑话内容
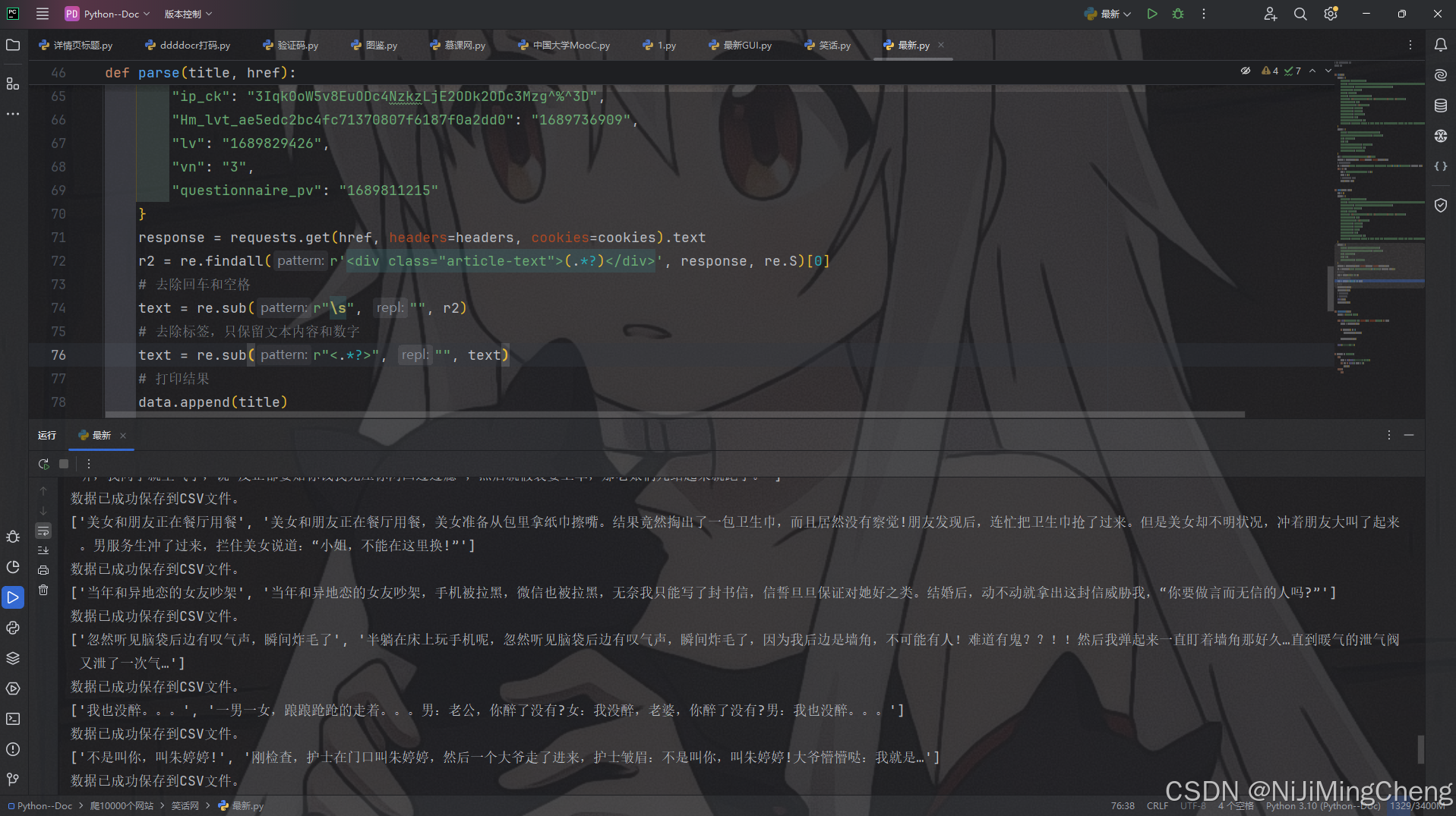
parse函数接受两个参数:title(笑话标题)和href(笑话链接),其主要任务是获取并处理单个笑话的具体内容。
1. 再次设置请求头和 Cookies 并获取页面内容
与Get函数类似,在parse函数内部也需要重新设置请求头和 Cookies,因为访问不同的页面(这里是每个笑话的具体页面)可能需要不同的请求配置。然后使用requests库发送 GET 请求获取笑话具体页面的文本内容。
headers = {
"authority": "xiaohua.zol.com.cn",
"accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7",
"accept-language": "zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6",
"cache-control": "no-cache",
"pragma": "no-cache",
"sec-ch-ua": "^\\^Not.A/Brand^^;v=^\\^8^^, ^\\^Chromium^^;v=^\\^114^^, ^\\^Microsoft",
"sec-ch-ua-mobile": "?0",
"sec-ch-ua-platform": "^\\^Windows^^",
"sec-fetch-dest": "document",
"sec-fetch-mode": "navigate",
"sec-fetch-site": "none",
"sec-fetch-user": "?1",
........
}
cookies = {
"ip_ck": "....D",
"Hm_lvt_a...... "1689736909",
"lv": "1689829426",
"vn": "3",
"questionnaire_pv": "1689811215"
}
response = requests.get(href, headers=headers, cookies=cookies).text
2. 提取并处理笑话内容
使用正则表达式从获取到的页面内容中提取出笑话的文本内容部分,然后通过一系列的正则表达式替换操作,去除其中的回车、空格以及 HTML 标签等,只保留纯净的文本内容和数字。最后,将笑话标题和处理后的文本内容添加到一个列表data中,并打印出来,同时调用save_to_csv函数将数据保存到 CSV 文件。
r2 = re.findall(r'<div class="article-text">(.*?)</div>', response, re.S)[0]
# 去除回车和空格
text = re.sub(r"\s", "", r2)
# 去除标签,只保留文本内容和数字
text = re.sub(r"<.*?>", "", text)
# 打印结果
data.append(title)
data.append(text)
print(data)
save_to_csv(data)
五、save_to_csv函数:保存数据到 CSV 文件
save_to_csv函数负责将抓取到的笑话数据保存到 CSV 文件中。
1. 设置 CSV 文件的表头
首先定义了 CSV 文件的表头,这里设置为['title', 'text'],分别对应笑话的标题和内容。
headers = ['title', 'text']
2. 写入数据到 CSV 文件
使用csv.writer创建一个 CSV 文件写入对象,然后判断文件是否为空(通过file.tell()判断写入指针的位置),如果为空则先写入表头。接着,将传入的笑话数据列表data写入到 CSV 文件中,并在写入成功后打印提示信息。
with open('./joker.csv', 'a', newline='', encoding='utf-8') as file:
writer = csv.writer(file)
if file.tell() == 0:
writer.writerow(headers)
writer.writerow(data)
print("数据已成功保存到CSV文件。")
六、主程序入口(__main__部分)
在if __name__ == "__main__"这部分代码中,是整个程序的入口点。首先通过input函数提示用户输入要下载的页数,然后使用for循环遍历从1到用户输入的页数relit,在每次循环中调用Get函数来获取对应页码的笑话列表页面信息,进而完成整个抓取和保存数据的流程。
try:
relit = int(input('请输入要下载的页数(一页20条):'))
for num in range(1, relit + 1):
Get(num)
except:
pass
完整代码:
# -*- coding:utf-8 -*-
import csv
import re
import requests
def Get(num):
headers = {
}
cookies = {
}
url = f"https://xiaohua.zol.com.cn/new/{num}.html"
response = requests.get(url, headers=headers, cookies=cookies).text
# print(response)
r1 = re.findall(r'<span class="article-title"><a target="_blank" href="(.*?)">(.*?)</a></span>', response, re.S)
for r in r1:
href = 'https://xiaohua.zol.com.cn' + r[0]
title = r[1]
# print(title, href)
parse(title, href)
def parse(title, href):
data = []
headers = {
}
cookies = {
response = requests.get(href, headers=headers, cookies=cookies).text
r2 = re.findall(r'<div class="article-text">(.*?)</div>', response, re.S)[0]
# 去除回车和空格
text = re.sub(r"\s", "", r2)
# 去除标签,只保留文本内容和数字
text = re.sub(r"<.*?>", "", text)
# 打印结果
data.append(title)
data.append(text)
# print(title)
# print(text)
print(data)
save_to_csv(data)
def save_to_csv(data):
headers = ['title', 'text']
with open('./joker.csv', 'a', newline='', encoding='utf-8') as file:
writer = csv.writer(file)
if file.tell() == 0:
writer.writerow(headers)
writer.writerow(data)
print("数据已成功保存到CSV文件。")
if __name__ == "__main__":
try:
relit = int(input('请输入要下载的页数(一页20条):'))
for num in range(1, relit + 1):
Get(num)
except:
pass
注意:
在使用本代码进行网站数据抓取时,请务必遵守相关法律法规以及目标网站(“xiaohua.zol.com.cn”)的使用规则和服务协议。本代码仅用于学习和研究目的,不得用于任何非法的商业用途或侵犯他人权益的行为。若因不当使用本代码而导致的任何法律纠纷或不良后果,使用者需自行承担全部责任。在进行数据抓取操作之前,请确保你已经充分了解并获得了合法的授权与许可,尊重网站的正常运营和其他用户的合法权益。