神经网络简介
在生物神经网络中1 每个神经元与其他神经元相连,当它"兴奋"时,就会向相连的神经元发送化学物质,从而改变这些神经元内的电位:如果某神经元的电位超过了一个"阈值" (threshold) , 那么它就会被激活, 即"兴奋"起来,向其他神经元发送化学物质。
1943 年, [McCulloch and Pitts, 1943] 将上述情形抽象为下图所示的简单模型,这就是一直沿用至今的"M-P 神经元模型" 在这个模型中, 神经元接收到来自N个其他神经元传递过来的输入信号,这些输入信号通过带权重的连接( connection)进行传递,神经元接收到的总输入值将与神经元的阀值进行比较,然后通过"激活函数" (activation function) 处理以产生神经元的输出。
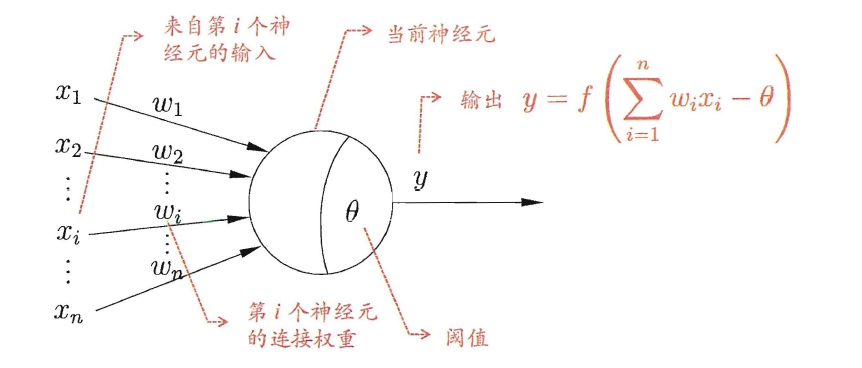
理想中的激活函数是下图所示的阶跃函数:
然而,阶跃函数并不连续,不光滑的性质,所以常用其他函数作为激活函数(我之前写过一期激活函数的文章 https://blog.csdn.net/No_Game_No_Life_/article/details/89511056 )。比如,sigmoid函数:
把许多个这样的神经元按-定的层次结构连接起来,就得到了神经网络。
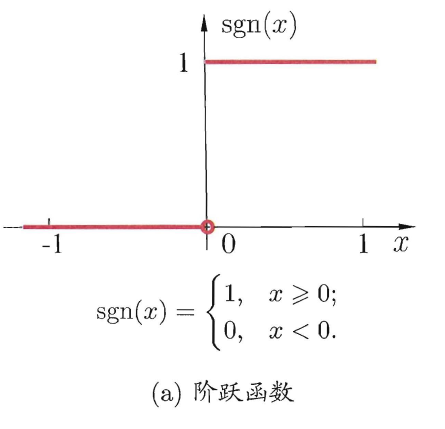

感知机与多层网络
两个输入神经元的感知机网络结构:
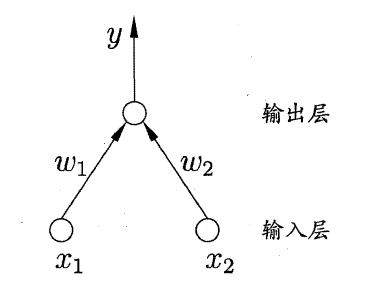
感知机能容易地实现逻辑且、或、非运算.。注意到 y = f ( ∑ i w i x i − θ ) y=f(\sum_{i}w_ix_i-\theta) y=f(∑iwixi−θ),其中f是激活函数。一般给定数据集,需要求的的就是权重 w T w^T wT(向量),和阈值 θ \theta θ。阈值和权重是通过学习得到的,可以统一称为权重的学习。
感知机学习规则非常简单,对训练样例
(
x
,
y
)
(x,y)
(x,y),若当前感知机的输出为
y
^
\hat y
y^,那么感知机权重将通过下面两个公式调整:
(1)
Δ
w
i
=
η
(
y
−
y
^
)
x
i
\Delta w_i=\eta (y-\hat y)x_i
Δwi=η(y−y^)xi
(2)
w
i
+
Δ
w
i
→
w
i
w_i+\Delta w_i → w_i
wi+Δwi→wi
其中
η
∈
(
0
,
1
)
\eta \in (0,1)
η∈(0,1)称为学习率。
从上面可以看出,,若感知机对训练样例 ( x , y ) (x,y) (x,y)预测正确,即 y ^ = y \hat y=y y^=y,则感知机不会发生变化,否则将做出一定程度的调整。
需注意的是,感知机只有输出层神经元进行激活函数处理,即只拥有层功能神经元(functional neuron) ,其学习能力非常有限。事实上,上述描述的都是线性可分的问题,若两类模式是线性可分的,即存在一个线性超平面能将它们分开。

要解决非线性可分问题,需考虑使用多层功能神经元。如下图的两层感知机,输出层与输入居之间的一层神经元,被称为隐层或隐含层(hidden layer) ,隐含层和输出层神经元都是拥有激活函数的功能神经元。
更一般的,常见的神经网络如下图所示,每层神经元与下层神经元全互连,神经元之间不存在同层连接,也不存在跨层连接.。这样的神经网络结构通常称为" 多层前馈神经网络"。

误差逆传播算法(BP)
多层网络的学习能力比单层感知机强得多,要想训练多层网络,前面提到的两个公式显然就不够了,需要更强大的学习算法。误差逆传播(BP)就是其中的一种算法。
值得指出的是, BP 算法不仅可用于多层前馈神经网络,还可用于其他类型
的神经网络,例如训练递归神经网络。但通常提到BP网络的时候,还是说的前者。
给定训练集
D
=
{
(
x
1
,
y
1
)
,
(
x
2
,
y
2
)
,
(
x
3
,
y
3
)
.
.
.
(
x
m
,
y
m
)
}
D=\{(x_1,y_1),(x_2,y_2),(x_3,y_3)...(x_m,y_m)\}
D={(x1,y1),(x2,y2),(x3,y3)...(xm,ym)},输入
x
i
x_i
xi由
d
d
d个属性描述,输出
y
i
y_i
yi由
l
l
l个属性描述。
对于训练样例
(
x
k
,
y
k
)
(x_k,y_k)
(xk,yk),有神经网络输出为
y
k
^
=
(
y
1
^
k
,
y
2
^
k
,
y
3
^
k
.
.
.
y
l
^
k
)
\hat {y_k}=(\hat{y_1}^k,\hat{y_2}^k,\hat{y_3}^k...\hat{y_l}^k)
yk^=(y1^k,y2^k,y3^k...yl^k),那么网络在
(
x
k
,
y
k
)
(x_k,y_k)
(xk,yk)上的均方误差为:
E
k
=
1
2
∑
j
=
1
l
(
y
j
^
k
−
y
j
k
)
2
E_k=\frac{1}{2} \sum_{j=1}^{l}(\hat{y_j}^k-{y_j}^k)^2
Ek=21∑j=1l(yj^k−yjk)2

BP 算法基于梯度下降(gradient descent)策略, 以目标的负梯度方向对参数进行调整。对于均方误差
E
k
E_k
Ek,给定一个学习率
η
\eta
η(太大容易震荡,太小则收敛速度又会过慢),有:
Δ
w
h
j
=
−
η
∂
E
k
∂
w
h
j
\Delta w_{hj}=-\eta \frac{\partial {E_k}}{\partial w_{hj}}
Δwhj=−η∂whj∂Ek
这个公式求解的推导在此略过。
最后,BP算法的目标是最小化训练集D上的积累误差:
E
=
1
m
∑
k
=
1
m
E
k
E=\frac{1}{m} \sum_{k=1}^{m}E_k
E=m1∑k=1mEk
BP算法的工作流程如下所示:
对于每个训练样例,输入给输入层神经元,然后逐层将信号前传,直到产生输出层的结果,然后计算输出层的误差,再将误差逆向传播到隐层神经元,最后根据隐层神经元的误差来对连接权和阈值进行调整。
该迭代过程循环进行,直到达到某个条件。比如,训练误差足够小的时候。
没看懂上面的栗子不要紧,下面举例说明一下,马上就能明白是如何计算的。
- 举例
假设,你有这样一个网络层:
第一层是输入层,包含两个神经元i1,i2,和截距项b1;第二层是隐含层,包含两个神经元h1,h2和截距项b2,第三层是输出o1,o2,每条线上标的wi是层与层之间连接的权重,激活函数我们默认为sigmoid函数。

现在对他们赋上初值,如下图:
其中,输入数据
i
1
=
0.05
,
i
2
=
0.10
;
i1=0.05,i2=0.10;
i1=0.05,i2=0.10;
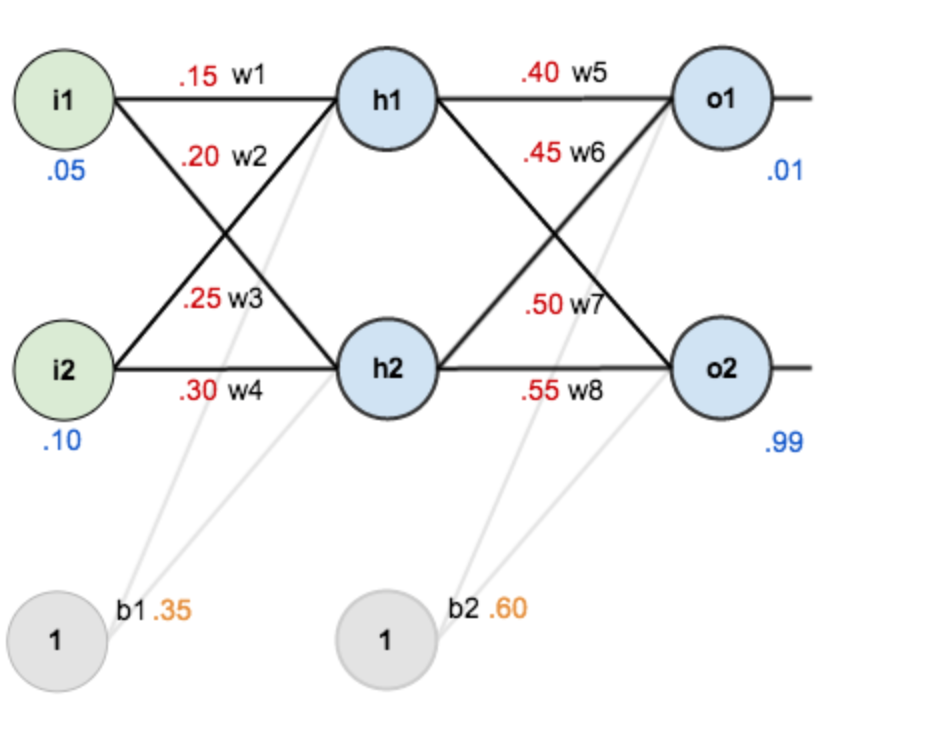
输出数据 o 1 = 0.01 , o 2 = 0.99 ; o1=0.01,o2=0.99; o1=0.01,o2=0.99;
初始权重 w 1 = 0.15 , w 2 = 0.20 , w 3 = 0.25 , w 4 = 0.30 ; w1=0.15,w2=0.20,w3=0.25,w4=0.30; w1=0.15,w2=0.20,w3=0.25,w4=0.30;
w 5 = 0.40 , w 6 = 0.45 , w 7 = 0.50 , w 8 = 0.55 w5=0.40,w6=0.45,w7=0.50,w8=0.55 w5=0.40,w6=0.45,w7=0.50,w8=0.55
目标:给出输入数据i1,i2(0.05和0.10),使输出尽可能与原始输出o1,o2(0.01和0.99)接近。
Step 1 前向传播:
输入层—->隐含层
计算神经元h1的输入加权和:
神经元h1的输出o1:(此处用到激活函数为sigmoid函数):
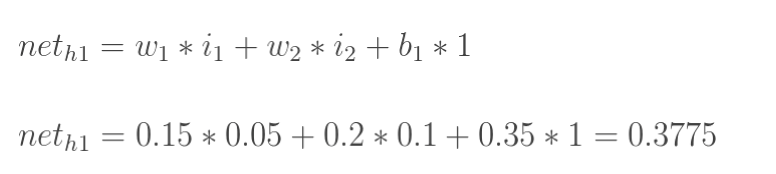
同理,可计算出神经元h2的输出o2:
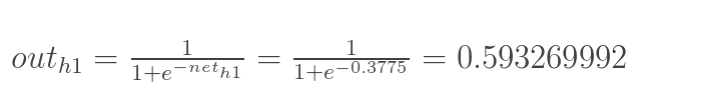
隐含层—->输出层:
计算输出层神经元o1和o2的值:
同理:
这样前向传播的过程就结束了,我们得到输出值为[0.75136079 , 0.772928465],与实际值[0.01 , 0.99]相差还很远,现在我们对误差进行反向传播,更新权值,重新计算输出。
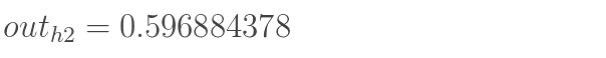

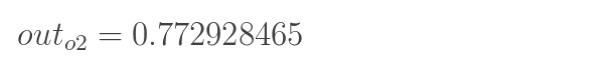
Step 2 反向传播
计算总误差
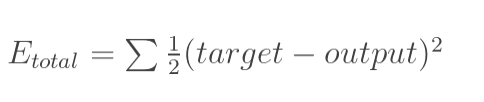
但是有两个输出,所以分别计算o1和o2的误差,总误差为两者之和:
所以:
隐含层—->输出层的权值更新:
以权重参数w5为例,如果我们想知道w5对整体误差产生了多少影响,可以用整体误差对w5求偏导求出:(链式法则)
下面的图可以更直观的看清楚误差是怎样反向传播的:
注意分清楚net和out的区别。
现在我们来分别计算每个式子的值:
计算
∂
E
t
o
t
a
l
∂
o
u
t
o
1
\frac{\partial {E_{total}}}{\partial {out_{o1}}}
∂outo1∂Etotal:
计算
∂
o
u
t
o
1
∂
n
e
t
o
1
\frac{\partial {out_{o1}}}{\partial {net_{o1}}}
∂neto1∂outo1:
计算
∂
n
e
t
o
1
∂
w
5
\frac{\partial {net_{o1}}}{\partial w_5}
∂w5∂neto1:
最后,三者相乘得出答案:
这样我们就计算出整体误差
E
t
o
t
a
l
E_{total}
Etotal对w5的偏导值。
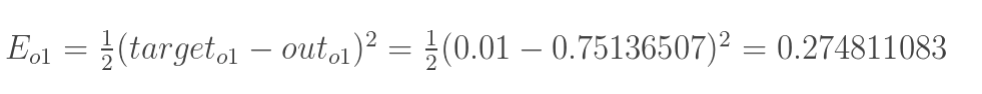

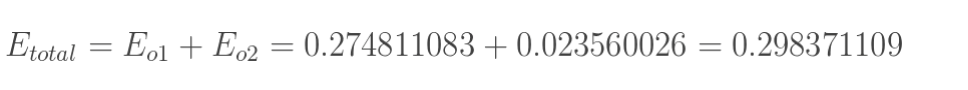

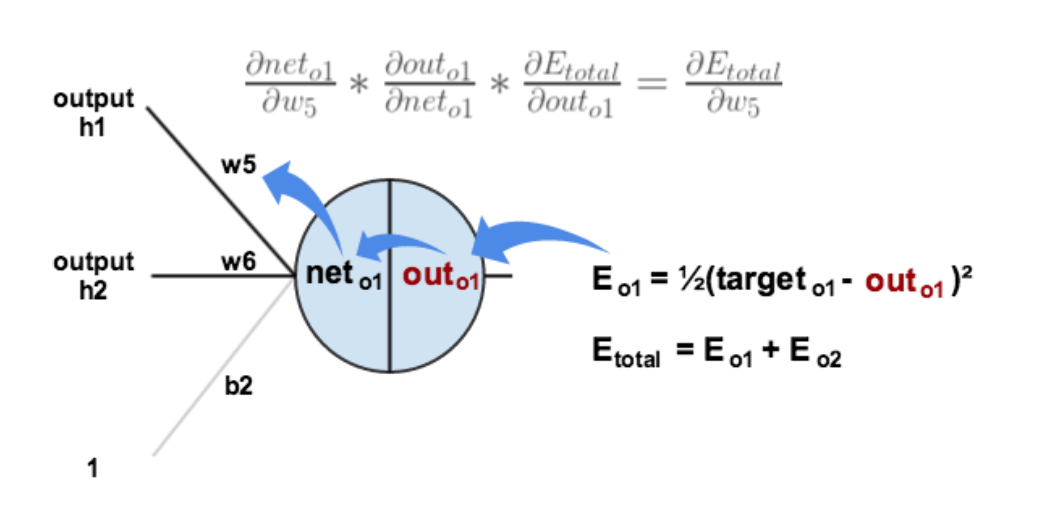
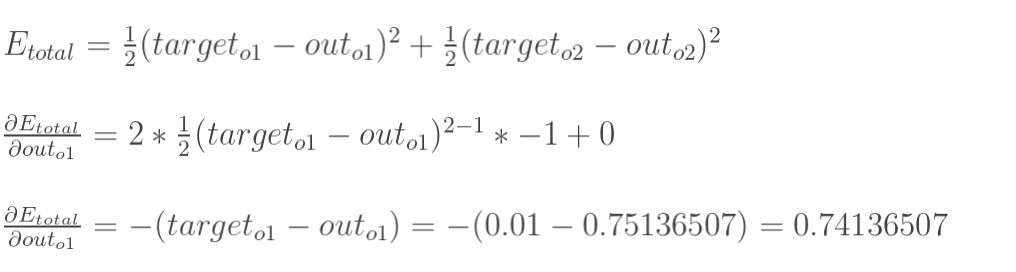

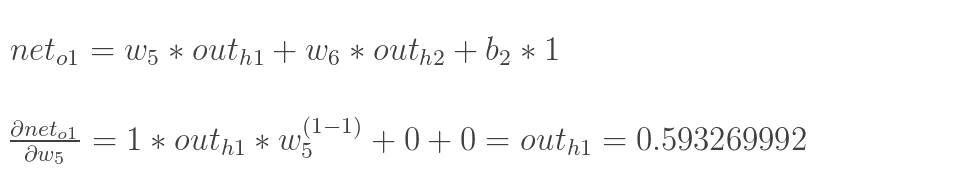

最后我们来更新w5的值:
η
\eta
η是学习速率,我们这里取0.5
同理,可更新w6,w7,w8:


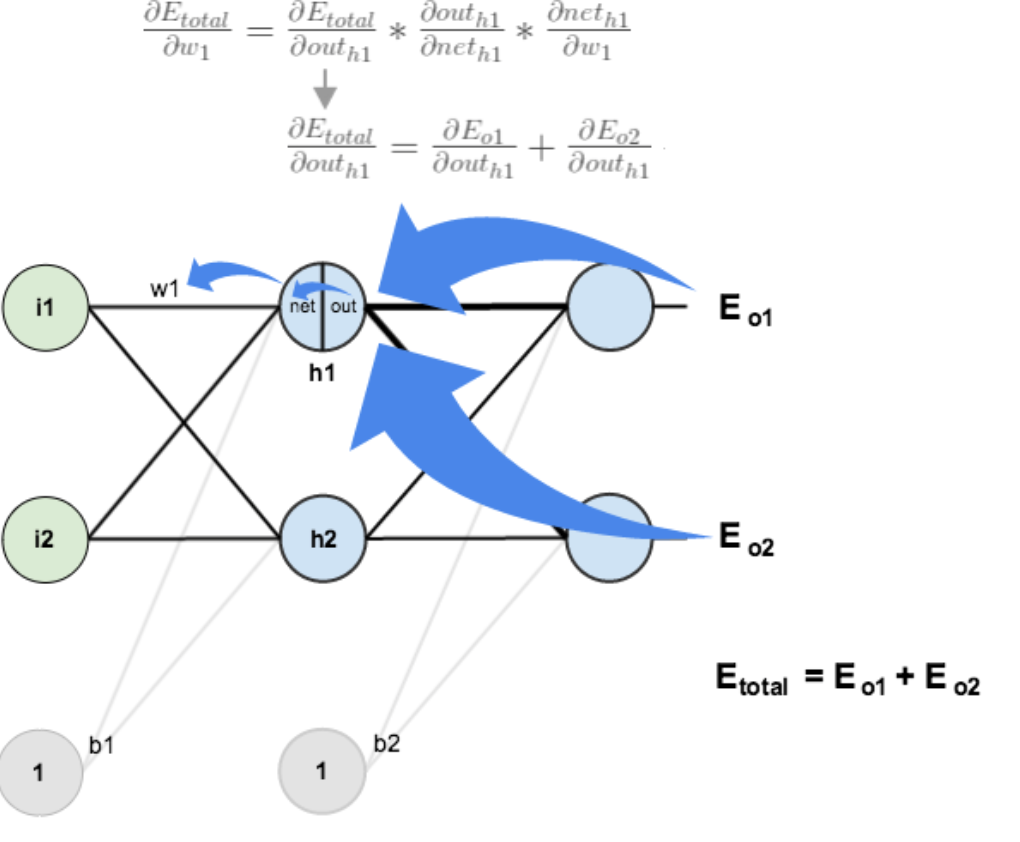
隐含层—->隐含层的权值更新:
方法其实与上面说的差不多,但是有个地方需要变一下,在上文计算总误差对w5的偏导时,是从out(o1)—->net(o1)—->w5,但是在隐含层之间的权值更新时,是out(h1)—->net(h1)—->w1,而out(h1)会接受E(o1)和E(o2)两个地方传来的误差,所以这个地方两个都要计算。
其中:
只需要分别计算这两个值即可。这两个值的求法,我们提一下:
同理,计算出:
两者相加得到总值:

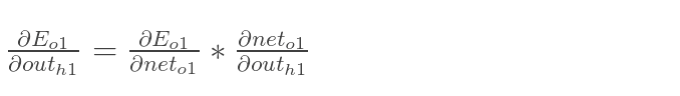
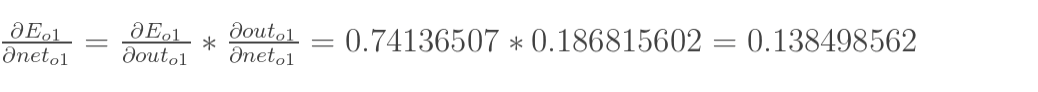
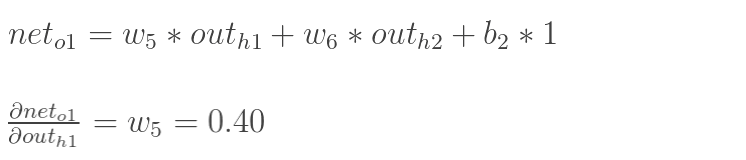
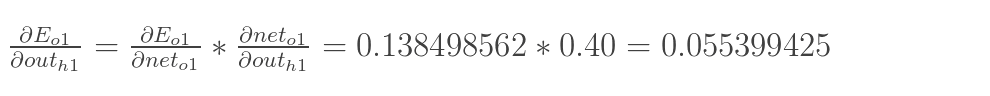
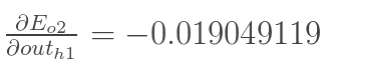

接着计算后面两个乘法因子的值:

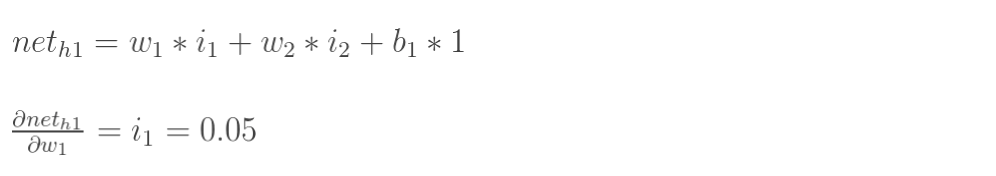
最后三者相乘:
更新w1的权值:
同理,额可更新w2,w3,w4的权值:
这样误差反向传播法就完成了,最后我们再把更新的权值重新计算,不停地迭代,在这个例子中第一次迭代之后,总误差E(total)由0.298371109下降至0.291027924。迭代10000次后,总误差为0.000035085,输出为[0.015912196,0.984065734] (原输入为[0.01,0.99]),证明效果还是不错的。



我们上面介绍的"标准BP算法"每次仅针对一个训练样例更新连接权和阈值。也就是说,算法的更新规则是基于单个的 E k E_k Ek推导而得。如果类似地推导出基于累积误差最小化的更新规则,就得到了累积误差逆传播算法,累积BP算法与标准BP算法都很常用。一般来说,标准BP算法每次更新只针对单个样例,参数更新得非常频繁,而且对不同样例进行更新的效果可能出现"抵消"现象.因此,为了达到同样的累积误差极小点, 标准BP算法往往需进行更多次数的迭代。累积BP 算法直接针对累积误差最小化,它在读取整个训练集D 一遍后才对参数进行更新,其参数更新的频率低得多。但在很多任务中,累积误差下降到一定程度之后,进一步下降会非常缓慢,这时标准BP往往会更快获得较好的解,尤其是在训练集D 非常大时更明显。
正是由于其强大的表示能力,BP神经网络经常遭遇过拟合,其训练误差持续降低,但测试误差却可能上升。
通常有两种策略来缓解BP网络的过拟合。第一种策略是**“早停”(early stopping)**:将数据分成训练集合验证集,训练集用来计算梯度、更新连接权和阈值,验证集用来估计误差,若训练集误差降低但验证集误差升高,则停止训练,同时返回具有最小验证集误差的连接权和阈值。
第二种策略是**“正则化”(regularization)**,其基本思想是在误差目标函数中增加一个用于描述网络复杂度的部分,例如连接权和阈值的平方和。