在跑通开源代码的过程中,一直难以找到很合适的代码框架或代码模板,尤其对于初学者而言是不小的挑战。本人在跑代码的过程中,发现在GitHub上有一个辅助训练过程的模板。这篇文章主要记录它的使用方法,并标记来源。
代码均在jupyter notebook中跑通。需要提前配置好python, numpy, matplotlib, torch等环境。
nntools源码
"""
Source: UCSD ECE285: Machine Learning and Image Processing
Neural Network tools developed for UCSD ECE285 MLIP.
Copyright 2019. Charles Deledalle, Sneha Gupta, Anurag Paul, Inderjot Saggu.
"""
import os
import time
import torch
from torch import nn
import torch.utils.data as td
from abc import ABC, abstractmethod
class NeuralNetwork(nn.Module, ABC):
"""An abstract class representing a neural network.
All other neural network should subclass it. All subclasses should override
``forward``, that makes a prediction for its input argument, and
``criterion``, that evaluates the fit between a prediction and a desired
output. This class inherits from ``nn.Module`` and overloads the method
``named_parameters`` such that only parameters that require gradient
computation are returned. Unlike ``nn.Module``, it also provides a property
``device`` that returns the current device in which the network is stored
(assuming all network parameters are stored on the same device).
"""
def __init__(self):
super(NeuralNetwork, self).__init__()
@property
def device(self):
# This is important that this is a property and not an attribute as the
# device may change anytime if the user do ``net.to(newdevice)``.
return next(self.parameters()).device
def named_parameters(self, recurse=True):
nps = nn.Module.named_parameters(self)
for name, param in nps:
if not param.requires_grad:
continue
yield name, param
@abstractmethod
def forward(self, x):
pass
@abstractmethod # 使用@abstractmethod标记的方法必须在所有子类中实现 基类需要继承ABC
def criterion(self, y, d):
pass
class StatsManager(object):
"""
A class meant to track the loss during a neural network learning experiment.
Though not abstract, this class is meant to be overloaded to compute and
track statistics relevant for a given task. For instance, you may want to
overload its methods to keep track of the accuracy, top-5 accuracy,
intersection over union, PSNR, etc, when training a classifier, an object
detector, a denoiser, etc.
"""
def __init__(self):
self.init()
def __repr__(self):
"""Pretty printer showing the class name of the stats manager. This is
what is displayed when doing ``print(stats_manager)``.
"""
return self.__class__.__name__
def init(self):
"""Initialize/Reset all the statistics"""
self.running_loss = 0
self.number_update = 0
def accumulate(self, loss, x=None, y=None, d=None):
"""Accumulate statistics
Though the arguments x, y, d are not used in this implementation, they
are meant to be used by any subclasses. For instance they can be used
to compute and track top-5 accuracy when training a classifier.
Arguments:
loss (float): the loss obtained during the last update.
x (Tensor): the input of the network during the last update.
y (Tensor): the prediction of by the network during the last update.
d (Tensor): the desired output for the last update.
"""
self.running_loss += loss
self.number_update += 1
def summarize(self):
"""Compute statistics based on accumulated ones"""
return self.running_loss / self.number_update
class Experiment(object):
"""
A class meant to run a neural network learning experiment.
After being instantiated, the experiment can be run using the method
``run``. At each epoch, a checkpoint file will be created in the directory
``output_dir``. Two files will be present: ``checkpoint.pth.tar`` a binary
file containing the state of the experiment, and ``config.txt`` an ASCII
file describing the setting of the experiment. If ``output_dir`` does not
exist, it will be created. Otherwise, the last checkpoint will be loaded,
except if the setting does not match (in that case an exception will be
raised). The loaded experiment will be continued from where it stopped when
calling the method ``run``. The experiment can be evaluated using the method
``evaluate``.
Attributes/Properties:
epoch (integer): the number of performed epochs.
history (list): a list of statistics for each epoch.
If ``perform_validation_during_training``=False, each element of the
list is a statistic returned by the stats manager on training data.
If ``perform_validation_during_training``=True, each element of the
list is a pair. The first element of the pair is a statistic
returned by the stats manager evaluated on the training set. The
second element of the pair is a statistic returned by the stats
manager evaluated on the validation set.
Arguments:
net (NeuralNetork): a neural network.
train_set (Dataset): a training data set.
val_set (Dataset): a validation data set.
stats_manager (StatsManager): a stats manager.
output_dir (string, optional): path where to load/save checkpoints. If
None, ``output_dir`` is set to "experiment_TIMESTAMP" where
TIMESTAMP is the current time stamp as returned by ``time.time()``.
(default: None)
batch_size (integer, optional): the size of the mini batches.
(default: 16)
perform_validation_during_training (boolean, optional): if False,
statistics at each epoch are computed on the training set only.
If True, statistics at each epoch are computed on both the training
set and the validation set. (default: False)
"""
def __init__(self, net, train_set, val_set, optimizer, stats_manager,
output_dir=None, batch_size=16, perform_validation_during_training=False):
# Define data loaders
train_loader = td.DataLoader(train_set, batch_size=batch_size, shuffle=True,
drop_last=True, pin_memory=True)
val_loader = td.DataLoader(val_set, batch_size=batch_size, shuffle=False,
drop_last=True, pin_memory=True)
# Initialize history
history = []
# Define checkpoint paths
if output_dir is None:
output_dir = 'experiment_{}'.format(time.time())
os.makedirs(output_dir, exist_ok=True)
checkpoint_path = os.path.join(output_dir, "checkpoint.pth.tar")
config_path = os.path.join(output_dir, "config.txt")
# Transfer all local arguments/variables into attributes
locs = {k: v for k, v in locals().items() if k is not 'self'}
self.__dict__.update(locs)
# Load checkpoint and check compatibility
if os.path.isfile(config_path):
with open(config_path, 'r') as f:
if f.read()[:-1] != repr(self):
raise ValueError(
"Cannot create this experiment: "
"I found a checkpoint conflicting with the current setting.")
self.load()
else:
self.save()
@property
def epoch(self):
"""Returns the number of epochs already performed."""
return len(self.history)
def setting(self):
"""Returns the setting of the experiment."""
return {'Net': self.net,
'TrainSet': self.train_set,
'ValSet': self.val_set,
'Optimizer': self.optimizer,
'StatsManager': self.stats_manager,
'BatchSize': self.batch_size,
'PerformValidationDuringTraining': self.perform_validation_during_training}
def __repr__(self):
"""Pretty printer showing the setting of the experiment. This is what
is displayed when doing ``print(experiment)``. This is also what is
saved in the ``config.txt`` file.
"""
string = ''
for key, val in self.setting().items():
string += '{}({})\n'.format(key, val)
return string
def state_dict(self):
"""Returns the current state of the experiment."""
return {'Net': self.net.state_dict(),
'Optimizer': self.optimizer.state_dict(),
'History': self.history}
def load_state_dict(self, checkpoint):
"""Loads the experiment from the input checkpoint."""
self.net.load_state_dict(checkpoint['Net'])
self.optimizer.load_state_dict(checkpoint['Optimizer'])
self.history = checkpoint['History']
# The following loops are used to fix a bug that was
# discussed here: https://github.com/pytorch/pytorch/issues/2830
# (it is supposed to be fixed in recent PyTorch version)
for state in self.optimizer.state.values():
for k, v in state.items():
if isinstance(v, torch.Tensor):
state[k] = v.to(self.net.device)
def save(self):
"""Saves the experiment on disk, i.e, create/update the last checkpoint."""
torch.save(self.state_dict(), self.checkpoint_path)
with open(self.config_path, 'w') as f:
print(self, file=f)
def load(self):
"""Loads the experiment from the last checkpoint saved on disk."""
checkpoint = torch.load(self.checkpoint_path,
map_location=self.net.device)
self.load_state_dict(checkpoint)
del checkpoint
def run(self, num_epochs, plot=None):
"""Runs the experiment, i.e., trains the network using backpropagation
based on the optimizer and the training set. Also performs statistics at
each epoch using the stats manager.
Arguments:
num_epoch (integer): the number of epoch to perform.
plot (func, optional): if not None, should be a function taking a
single argument being an experiment (meant to be ``self``).
Similar to a visitor pattern, this function is meant to inspect
the current state of the experiment and display/plot/save
statistics. For example, if the experiment is run from a
Jupyter notebook, ``plot`` can be used to display the evolution
of the loss with ``matplotlib``. If the experiment is run on a
server without display, ``plot`` can be used to show statistics
on ``stdout`` or save statistics in a log file. (default: None)
"""
self.net.train()
self.stats_manager.init()
start_epoch = self.epoch
print("Start/Continue training from epoch {}".format(start_epoch))
if plot is not None:
plot(self)
for epoch in range(start_epoch, num_epochs):
s = time.time()
self.stats_manager.init()
for x, d in self.train_loader:
x, d = x.to(self.net.device), d.to(self.net.device)
self.optimizer.zero_grad()
y = self.net.forward(x)
loss = self.net.criterion(y, d)
loss.backward()
self.optimizer.step()
with torch.no_grad():
self.stats_manager.accumulate(loss.item(), x, y, d)
if not self.perform_validation_during_training:
self.history.append(self.stats_manager.summarize())
else:
self.history.append(
(self.stats_manager.summarize(), self.evaluate()))
print("Epoch {} (Time: {:.2f}s)".format(
self.epoch, time.time() - s))
self.save()
if plot is not None:
plot(self)
print("Finish training for {} epochs".format(num_epochs))
def evaluate(self):
"""Evaluates the experiment, i.e., forward propagates the validation set
through the network and returns the statistics computed by the stats
manager.
"""
self.stats_manager.init()
self.net.eval()
with torch.no_grad():
for x, d in self.val_loader:
x, d = x.to(self.net.device), d.to(self.net.device)
y = self.net.forward(x)
loss = self.net.criterion(y, d)
self.stats_manager.accumulate(loss.item(), x, y, d)
self.net.train()
return self.stats_manager.summarize()
借助nntools复现DnCNN,并应用自己的数据集
准备工作
定义数据集路径、调包、cuda检查:
dataset_root_dir = './data/'
%matplotlib inline # 常在 jupyter notebook 中使用此命令
import os
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.utils.data as td
import torchvision as tv
from PIL import Image
import matplotlib.pyplot as plt
import time
device = 'cuda:0' if torch.cuda.is_available() else 'cpu'
print(device)
如果有GPU,打印结果如下:
cuda:0
定义数据集&展示数据
这里使用的是自己的数据集,每张图像的大小是512×512像素:
数据集结构:
data
--train
--image
--00001.jpg
--00002.jpg
--...
--label
--00001.jpg
--00002.jpg
--...
--test
--image
--00001.jpg
--00002.jpg
--...
--label
--00001.jpg
--00002.jpg
--...
代码实现:
# make dataset
class MyDataset(td.Dataset):
def __init__(self, root_dir, mode='train', image_size=(512, 512)):
super(MyDataset, self).__init__()
self.mode = mode
self.image_size = image_size
self.images_dir = os.path.join(root_dir, mode) # train/test 路径拼接
self.files1 = os.listdir(os.path.join(self.images_dir, 'label')) # clean_img
self.files2 = os.listdir(os.path.join(self.images_dir, 'image')) # noisy_img
def __len__(self):
return len(self.files1)
def __repr__(self):
return "MyDataset(mode={}, image_size={})". \
format(self.mode, self.image_size)
def __getitem__(self, idx):
# img_path = os.path.join(self.images_dir, self.files[idx])
clean_img_path = os.path.join(self.images_dir, 'label/', self.files1[idx])
noisy_img_path = os.path.join(self.images_dir, 'image/', self.files2[idx])
clean = Image.open(clean_img_path).convert('RGB')
transform = tv.transforms.Compose([
# 转换张量
tv.transforms.ToTensor(),
# [−1, 1]
tv.transforms.Normalize((.5, .5, .5), (.5, .5, .5))
])
clean = transform(clean)
noisy = Image.open(noisy_img_path).convert('RGB')
transform = tv.transforms.Compose([
# 转换张量
tv.transforms.ToTensor(),
# [−1, 1]
tv.transforms.Normalize((.5, .5, .5), (.5, .5, .5))
])
noisy = transform(noisy)
return noisy, clean
注:参考资料[2]中由于是对于图像直接加噪声,因此它在getitem的过程中需要针对已有的干净图像生成含噪声的图像。我需要完成的任务的加噪图像已经提前通过其他方式制作好了,因此在getitem函数中直接使用Image.open()方法导入即可。
定义展示图像的方法。对于表示为Tensor的图像,需要将其部署回cpu上并转为numpy数组的形式,再利用matplotlib.pyplot进行打印。
def myimshow(image,ax = plt):
image = image.to('cpu').numpy()
image = np.moveaxis(image,[0,1,2],[2,0,1])
image = (image + 1) / 2
image[image < 0] = 0
image[image > 1] = 1
h = ax.imshow(image)
ax.axis('off')
return h
制作 trainset 和 testset :
train_set= MyDataset(dataset_root_dir)
test_set = MyDataset(dataset_root_dir,mode = 'test',image_size = (512,512))
print(train_set.__len__())
print(test_set.__len__())
运行后会打印出数据集的大小。
展示导入的数据集中的图像:
x = train_set[0]
fig, axes = plt.subplots(ncols=2)
myimshow(x[0], ax=axes[0])
axes[0].set_title('Noisy')
myimshow(x[1], ax=axes[1])
axes[1].set_title('Clean')
print(f'image size is {x[0].shape}.')
打印语句如下:
image size is torch.Size([3, 512, 512]).
同时,会输出两张图像,分别是clean和noisy的图像。
模型构建(DnCNN)
import nntools as nt
class NNRegressor(nt.NeuralNetwork):
def __init__(self):
super(NNRegressor, self).__init__()
self.mse = nn.MSELoss()
def criterion(self, y, d):
return self.mse(y, d)
class DnCNN(NNRegressor):
def __init__(self, D, C=64):
super(DnCNN, self).__init__()
self.D = D
self.conv = nn.ModuleList()
self.conv.append(nn.Conv2d(3, C, 3, padding=1))
self.conv.extend([nn.Conv2d(C, C, 3, padding=1) for _ in range(D)]) # extend: 将参数中所有模块加到ModuleList中
self.conv.append(nn.Conv2d(C, 3, 3, padding=1))
# Kaiming 正态分布初始化,又叫 He('s) initialization
for i in range(len(self.conv[:-1])):
nn.init.kaiming_normal_(self.conv[i].weight.data, nonlinearity='relu')
# Batch norm
self.bn = nn.ModuleList()
self.bn.extend([nn.BatchNorm2d(C, C) for _ in range(D)])
# Batch norm layer 初始化权值
for i in range(D):
nn.init.constant_(self.bn[i].weight.data, 1.25 * np.sqrt(C))
def forward(self, x):
D = self.D
h = F.relu(self.conv[0](x))
for i in range(D):
h = F.relu(self.bn[i](self.conv[i+1](h)))
y = self.conv[D+1](h) + x
return y
这里定义的类均将nt.NeuralNetwork视为父类。由于nntools中定义函数forward和函数criterion均有@abstract,使用@abstract标记的方法必须在所有子类中实现,即前向传播过程和损失函数。
模型构建(PMRID)
这里可以展示此框架的可拓展性。如果能够发掘更加合适的图像处理方法(基于深度学习的),则可以进行替换。找到开源代码中的model.py文件(通常是这样的),直接复制粘贴到此部分中,将原有的父类nn.module替换成此处的NNRegressor即可。(NNRegressor需要定义好损失函数的形式)
以下为使用PMRID替换时使用的代码:
import nntools as nt
class NNRegressor(nt.NeuralNetwork):
def __init__(self):
super(NNRegressor, self).__init__()
self.mse = nn.MSELoss()
def criterion(self, y, d):
return self.mse(y, d)
from collections import OrderedDict
def Conv2D(
in_channels: int, out_channels: int,
kernel_size: int, stride: int, padding: int,
is_seperable: bool = False, has_relu: bool = False,
):
modules = OrderedDict()
if is_seperable:
modules['depthwise'] = nn.Conv2d(
in_channels, in_channels, kernel_size, stride, padding,
groups=in_channels, bias=False,
)
modules['pointwise'] = nn.Conv2d(
in_channels, out_channels,
kernel_size=1, stride=1, padding=0, bias=True,
)
else:
modules['conv'] = nn.Conv2d(
in_channels, out_channels, kernel_size, stride, padding,
bias=True,
)
if has_relu:
modules['relu'] = nn.ReLU()
return nn.Sequential(modules)
class EncoderBlock(NNRegressor):
def __init__(self, in_channels: int, mid_channels: int, out_channels: int, stride: int = 1):
super().__init__()
self.conv1 = Conv2D(in_channels, mid_channels, kernel_size=5, stride=stride, padding=2, is_seperable=True, has_relu=True)
self.conv2 = Conv2D(mid_channels, out_channels, kernel_size=5, stride=1, padding=2, is_seperable=True, has_relu=False)
self.proj = (
nn.Identity()
if stride == 1 and in_channels == out_channels else
Conv2D(in_channels, out_channels, kernel_size=3, stride=stride, padding=1, is_seperable=True, has_relu=False)
)
self.relu = nn.ReLU()
def forward(self, x):
proj = self.proj(x)
x = self.conv1(x)
x = self.conv2(x)
x = x + proj
return self.relu(x)
def EncoderStage(in_channels: int, out_channels: int, num_blocks: int):
blocks = [
EncoderBlock(
in_channels=in_channels,
mid_channels=out_channels//4,
out_channels=out_channels,
stride=2,
)
]
for _ in range(num_blocks-1):
blocks.append(
EncoderBlock(
in_channels=out_channels,
mid_channels=out_channels//4,
out_channels=out_channels,
stride=1,
)
)
return nn.Sequential(*blocks)
class DecoderBlock(NNRegressor):
def __init__(self, in_channels: int, out_channels: int, kernel_size: int = 3):
super().__init__()
padding = kernel_size // 2
self.conv0 = Conv2D(
in_channels, out_channels, kernel_size=kernel_size, padding=padding,
stride=1, is_seperable=True, has_relu=True,
)
self.conv1 = Conv2D(
out_channels, out_channels, kernel_size=kernel_size, padding=padding,
stride=1, is_seperable=True, has_relu=False,
)
def forward(self, x):
inp = x
x = self.conv0(x)
x = self.conv1(x)
x = x + inp
return x
class DecoderStage(NNRegressor):
def __init__(self, in_channels: int, skip_in_channels: int, out_channels: int):
super().__init__()
self.decode_conv = DecoderBlock(in_channels, in_channels, kernel_size=3)
self.upsample = nn.ConvTranspose2d(in_channels, out_channels, kernel_size=2, stride=2, padding=0)
self.proj_conv = Conv2D(skip_in_channels, out_channels, kernel_size=3, stride=1, padding=1, is_seperable=True, has_relu=True)
# M.init.msra_normal_(self.upsample.weight, mode='fan_in', nonlinearity='linear')
def forward(self, inputs):
inp, skip = inputs
x = self.decode_conv(inp)
x = self.upsample(x)
y = self.proj_conv(skip)
return x + y
class Network(NNRegressor):
def __init__(self):
super().__init__()
self.conv0 = Conv2D(in_channels=3, out_channels=16, kernel_size=3, padding=1, stride=1, is_seperable=False, has_relu=True)
self.enc1 = EncoderStage(in_channels=16, out_channels=64, num_blocks=2)
self.enc2 = EncoderStage(in_channels=64, out_channels=128, num_blocks=2)
self.enc3 = EncoderStage(in_channels=128, out_channels=256, num_blocks=4)
self.enc4 = EncoderStage(in_channels=256, out_channels=512, num_blocks=4)
self.encdec = Conv2D(in_channels=512, out_channels=64, kernel_size=3, padding=1, stride=1, is_seperable=True, has_relu=True)
self.dec1 = DecoderStage(in_channels=64, skip_in_channels=256, out_channels=64)
self.dec2 = DecoderStage(in_channels=64, skip_in_channels=128, out_channels=32)
self.dec3 = DecoderStage(in_channels=32, skip_in_channels=64, out_channels=32)
self.dec4 = DecoderStage(in_channels=32, skip_in_channels=16, out_channels=16)
self.out0 = DecoderBlock(in_channels=16, out_channels=16, kernel_size=3)
self.out1 = Conv2D(in_channels=16, out_channels=3, kernel_size=3, stride=1, padding=1, is_seperable=False, has_relu=False)
def forward(self, inp):
conv0 = self.conv0(inp)
conv1 = self.enc1(conv0)
conv2 = self.enc2(conv1)
conv3 = self.enc3(conv2)
conv4 = self.enc4(conv3)
conv5 = self.encdec(conv4)
up3 = self.dec1((conv5, conv3))
up2 = self.dec2((up3, conv2))
up1 = self.dec3((up2, conv1))
x = self.dec4((up1, conv0))
x = self.out0(x)
x = self.out1(x)
pred = inp + x
return pred
训练
定义训练:
class DenoisingStatsManager(nt.StatsManager):
def __init__(self):
super(DenoisingStatsManager, self).__init__()
def init(self):
super(DenoisingStatsManager, self).init()
self.running_psnr = 0
def accumulate(self, loss, x, y, d):
super(DenoisingStatsManager, self).accumulate(loss, x, y, d)
n = x.shape[0] * x.shape[1] * x.shape[2] * x.shape[3]
self.running_psnr += 10*torch.log10(4*n/(torch.norm(y-d)**2))
def summarize(self):
loss = super(DenoisingStatsManager, self).summarize()
psnr = self.running_psnr / self.number_update
return {'loss': loss, 'PSNR': psnr.cpu()}
定义展示训练结果的代码:(左上:原含噪图像;右上:模型去噪后图像;左下:loss;右下:psnr)
def plot(exp, fig, axes, noisy, visu_rate=2):
if exp.epoch % visu_rate != 0:
return
with torch.no_grad():
denoised = exp.net(noisy[None].to(net.device))[0]
axes[0][0].clear()
axes[0][1].clear()
axes[1][0].clear()
axes[1][1].clear()
myimshow(noisy, ax=axes[0][0])
axes[0][0].set_title('Noisy image')
myimshow(denoised, ax=axes[0][1])
axes[0][1].set_title('Denoised image')
axes[1][0].plot([exp.history[k][0]['loss'] for k in range(exp.epoch)], label='training loss')
axes[1][0].set_ylabel('Loss')
axes[1][0].set_xlabel('Epoch')
axes[1][0].legend()
axes[1][1].plot([exp.history[k][0]['PSNR'] for k in range(exp.epoch)], label='training psnr')
axes[1][1].set_ylabel('PSNR')
axes[1][1].set_xlabel('Epoch')
axes[1][1].legend()
plt.tight_layout()
fig.canvas.draw()
开始训练:
lr = 1e-3
net = DnCNN(6).to(device)
adam = torch.optim.Adam(net.parameters(), lr=lr)
stats_manager = DenoisingStatsManager()
exp1 = nt.Experiment(net, train_set, test_set, adam, stats_manager, batch_size=8,
output_dir="./checkpoints/denoising1", perform_validation_during_training=True)
fig, axes = plt.subplots(ncols=2, nrows=2, figsize=(9, 7))
exp1.run(num_epochs=200, plot=lambda exp: plot(exp, fig=fig, axes=axes,
noisy=test_set[0][0]))
注意:不同训练时需要将第一个代码块中的output_dir的名字进行更改(改数字即可),否则会报错。
训练时会打印如下内容:(设备参考:i9-13980HX, RTX4060 laptop, DnCNN;数据量:9000张图像)
Start/Continue training from epoch 0
Epoch 1 (Time: 17.74s)
Epoch 2 (Time: 13.82s)
Epoch 3 (Time: 13.77s)
Epoch 4 (Time: 13.68s)
Epoch 5 (Time: 13.84s)
Epoch 6 (Time: 13.77s)
Epoch 7 (Time: 13.79s)
Epoch 8 (Time: 13.72s)
Epoch 9 (Time: 13.80s)
Epoch 10 (Time: 13.78s)
Epoch 11 (Time: 13.71s)
Epoch 12 (Time: 13.84s)
Epoch 13 (Time: 15.42s)
Epoch 14 (Time: 14.29s)
Epoch 15 (Time: 14.35s)
Epoch 16 (Time: 14.35s)
Epoch 17 (Time: 14.17s)
Epoch 18 (Time: 14.19s)
Epoch 19 (Time: 14.40s)
Epoch 20 (Time: 14.30s)
Epoch 21 (Time: 14.39s)
Epoch 22 (Time: 14.33s)
Epoch 23 (Time: 14.16s)
Epoch 24 (Time: 14.18s)
Epoch 25 (Time: 14.39s)
Epoch 26 (Time: 14.34s)
Epoch 27 (Time: 14.39s)
Epoch 28 (Time: 14.32s)
Epoch 29 (Time: 14.20s)
Epoch 30 (Time: 14.14s)
Epoch 31 (Time: 14.17s)
Epoch 32 (Time: 14.19s)
Epoch 33 (Time: 14.52s)
Epoch 34 (Time: 14.29s)
Epoch 35 (Time: 14.26s)
Epoch 36 (Time: 14.15s)
Epoch 37 (Time: 14.24s)
Epoch 38 (Time: 14.17s)
Epoch 39 (Time: 14.34s)
Epoch 40 (Time: 14.20s)
Epoch 41 (Time: 14.34s)
Epoch 42 (Time: 14.19s)
Epoch 43 (Time: 14.37s)
Epoch 44 (Time: 14.16s)
Epoch 45 (Time: 14.36s)
Epoch 46 (Time: 14.42s)
Epoch 47 (Time: 14.30s)
Epoch 48 (Time: 14.16s)
Epoch 49 (Time: 14.19s)
Epoch 50 (Time: 14.22s)
Epoch 51 (Time: 14.31s)
Epoch 52 (Time: 14.23s)
Epoch 53 (Time: 14.27s)
Epoch 54 (Time: 14.15s)
Epoch 55 (Time: 14.19s)
Epoch 56 (Time: 14.15s)
Epoch 57 (Time: 14.26s)
Epoch 58 (Time: 14.30s)
Epoch 59 (Time: 14.16s)
Epoch 60 (Time: 14.28s)
Epoch 61 (Time: 14.33s)
Epoch 62 (Time: 14.35s)
Epoch 63 (Time: 14.35s)
Epoch 64 (Time: 14.22s)
Epoch 65 (Time: 14.31s)
Epoch 66 (Time: 14.92s)
Epoch 67 (Time: 15.11s)
Epoch 68 (Time: 14.40s)
Epoch 69 (Time: 14.57s)
Epoch 70 (Time: 14.52s)
Epoch 71 (Time: 14.55s)
Epoch 72 (Time: 14.63s)
Epoch 73 (Time: 14.70s)
Epoch 74 (Time: 14.73s)
Epoch 75 (Time: 14.48s)
Epoch 76 (Time: 14.57s)
Epoch 77 (Time: 14.58s)
Epoch 78 (Time: 14.54s)
Epoch 79 (Time: 14.51s)
Epoch 80 (Time: 14.56s)
Epoch 81 (Time: 14.59s)
Epoch 82 (Time: 14.47s)
Epoch 83 (Time: 14.56s)
Epoch 84 (Time: 14.63s)
Epoch 85 (Time: 14.54s)
Epoch 86 (Time: 14.59s)
Epoch 87 (Time: 14.56s)
Epoch 88 (Time: 14.48s)
Epoch 89 (Time: 14.57s)
Epoch 90 (Time: 14.51s)
Epoch 91 (Time: 14.60s)
Epoch 92 (Time: 14.48s)
Epoch 93 (Time: 14.58s)
Epoch 94 (Time: 14.56s)
Epoch 95 (Time: 14.52s)
Epoch 96 (Time: 14.52s)
Epoch 97 (Time: 14.53s)
Epoch 98 (Time: 14.55s)
Epoch 99 (Time: 14.59s)
Epoch 100 (Time: 14.58s)
Epoch 101 (Time: 14.52s)
Epoch 102 (Time: 14.53s)
Epoch 103 (Time: 14.52s)
Epoch 104 (Time: 14.64s)
Epoch 105 (Time: 14.48s)
Epoch 106 (Time: 14.56s)
Epoch 107 (Time: 14.57s)
Epoch 108 (Time: 14.53s)
Epoch 109 (Time: 14.54s)
Epoch 110 (Time: 14.57s)
Epoch 111 (Time: 14.50s)
Epoch 112 (Time: 14.58s)
Epoch 113 (Time: 14.59s)
Epoch 114 (Time: 14.62s)
Epoch 115 (Time: 14.60s)
Epoch 116 (Time: 14.50s)
Epoch 117 (Time: 14.57s)
Epoch 118 (Time: 14.51s)
Epoch 119 (Time: 14.59s)
Epoch 120 (Time: 14.51s)
Epoch 121 (Time: 14.56s)
Epoch 122 (Time: 14.53s)
Epoch 123 (Time: 14.53s)
Epoch 124 (Time: 14.58s)
Epoch 125 (Time: 14.57s)
Epoch 126 (Time: 14.56s)
Epoch 127 (Time: 14.53s)
Epoch 128 (Time: 14.57s)
Epoch 129 (Time: 14.51s)
Epoch 130 (Time: 15.20s)
Epoch 131 (Time: 15.62s)
Epoch 132 (Time: 15.11s)
Epoch 133 (Time: 14.93s)
Epoch 134 (Time: 15.01s)
Epoch 135 (Time: 14.92s)
Epoch 136 (Time: 14.79s)
Epoch 137 (Time: 14.89s)
Epoch 138 (Time: 14.83s)
Epoch 139 (Time: 14.74s)
Epoch 140 (Time: 14.92s)
Epoch 141 (Time: 14.91s)
Epoch 142 (Time: 14.69s)
Epoch 143 (Time: 14.58s)
Epoch 144 (Time: 15.17s)
Epoch 145 (Time: 15.56s)
Epoch 146 (Time: 14.93s)
Epoch 147 (Time: 15.04s)
Epoch 148 (Time: 15.05s)
Epoch 149 (Time: 15.07s)
Epoch 150 (Time: 14.78s)
Epoch 151 (Time: 14.99s)
Epoch 152 (Time: 14.81s)
Epoch 153 (Time: 14.78s)
Epoch 154 (Time: 15.52s)
Epoch 155 (Time: 15.63s)
Epoch 156 (Time: 15.71s)
Epoch 157 (Time: 15.48s)
Epoch 158 (Time: 15.56s)
Epoch 159 (Time: 15.23s)
Epoch 160 (Time: 14.91s)
Epoch 161 (Time: 14.74s)
Epoch 162 (Time: 14.74s)
Epoch 163 (Time: 14.71s)
Epoch 164 (Time: 14.87s)
Epoch 165 (Time: 14.58s)
Epoch 166 (Time: 14.67s)
Epoch 167 (Time: 15.16s)
Epoch 168 (Time: 14.87s)
Epoch 169 (Time: 14.56s)
Epoch 170 (Time: 14.56s)
Epoch 171 (Time: 14.70s)
Epoch 172 (Time: 14.57s)
Epoch 173 (Time: 14.73s)
Epoch 174 (Time: 14.72s)
Epoch 175 (Time: 14.52s)
Epoch 176 (Time: 14.68s)
Epoch 177 (Time: 14.59s)
Epoch 178 (Time: 14.53s)
Epoch 179 (Time: 14.77s)
Epoch 180 (Time: 14.73s)
Epoch 181 (Time: 14.73s)
Epoch 182 (Time: 14.74s)
Epoch 183 (Time: 14.73s)
Epoch 184 (Time: 14.99s)
Epoch 185 (Time: 15.12s)
Epoch 186 (Time: 15.07s)
Epoch 187 (Time: 15.26s)
Epoch 188 (Time: 15.32s)
Epoch 189 (Time: 14.99s)
Epoch 190 (Time: 15.13s)
Epoch 191 (Time: 14.83s)
Epoch 192 (Time: 15.23s)
Epoch 193 (Time: 15.89s)
Epoch 194 (Time: 15.59s)
Epoch 195 (Time: 14.87s)
Epoch 196 (Time: 14.97s)
Epoch 197 (Time: 14.93s)
Epoch 198 (Time: 15.45s)
Epoch 199 (Time: 15.25s)
Epoch 200 (Time: 14.69s)
Finish training for 200 epochs
正常情况下,loss值会随训练而下降,psnr值会随训练而升高。以下是我训练DnCNN时打印的图像。
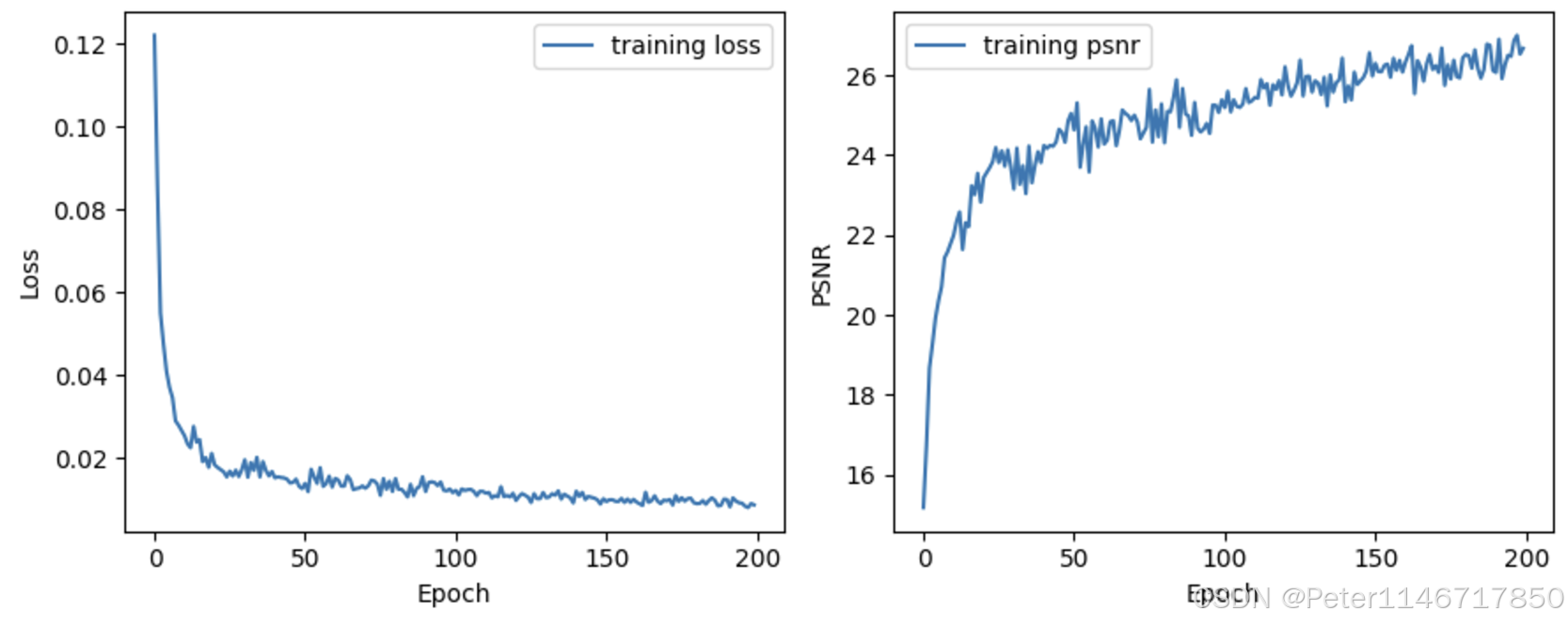
通过调节test_set后面的下标,可以看不同的测试图像在模型中的效果。
img = []
model = exp1.net.to(device)
titles = ['clean', 'noisy', 'DnCNN']
x, clean = test_set[0]
x = x.unsqueeze(0).to(device)
img.append(clean)
img.append(x[0])
model.eval()
with torch.no_grad():
y = model.forward(x)
img.append(y[0])
fig, axes = plt.subplots(ncols=3, figsize=(20,10), sharex='all', sharey='all')
for i in range(len(img)):
myimshow(img[i], ax=axes[i])
axes[i].set_title(f'{titles[i]}')