诸神缄默不语-个人CSDN博文目录
诸神缄默不语的论文阅读笔记和分类
论文全名:GPT-4 Technical Report
官方博客:GPT-4 | OpenAI
appendix懒得看了。
1. 模型训练过程心得
模型结构还是Transformers,训练目标还是语言模型(预测下一个token),我写过GPT-1/2/3的博文了直接看之前的博文吧。
增加了后训练对齐过程/用Reinforcement Learning from Human Feedback (RLHF)微调,提升模型回答的真实性,使其更符合人类偏好。
训练过程验证了scaling law,也就是有效的架构和优化方案在小模型上跑过之后,它们在大尺度模型上的效果提升是可预期的,这样只需在小模型上验证方案,就可以在大模型上放心去做了。
GPT-4仍然具有如下缺点(这也是现在很多大模型工作在致力于干掉的):幻觉,上下文长度限制,训练后就无法更新知识(does not learn from experience),偏见
GPT-4模型可以根据用户偏好实现一定程度的定制化。
针对风险的解决方案:
- safety-relevant RLHF training prompts
- rule-based reward models (RBRMs):若干GPT-4零样本分类器,输入是prompt、模型回复和人工评估的标准,输出是这个问答对是否安全
更多安全问题可以看System Card。
2. scaling law
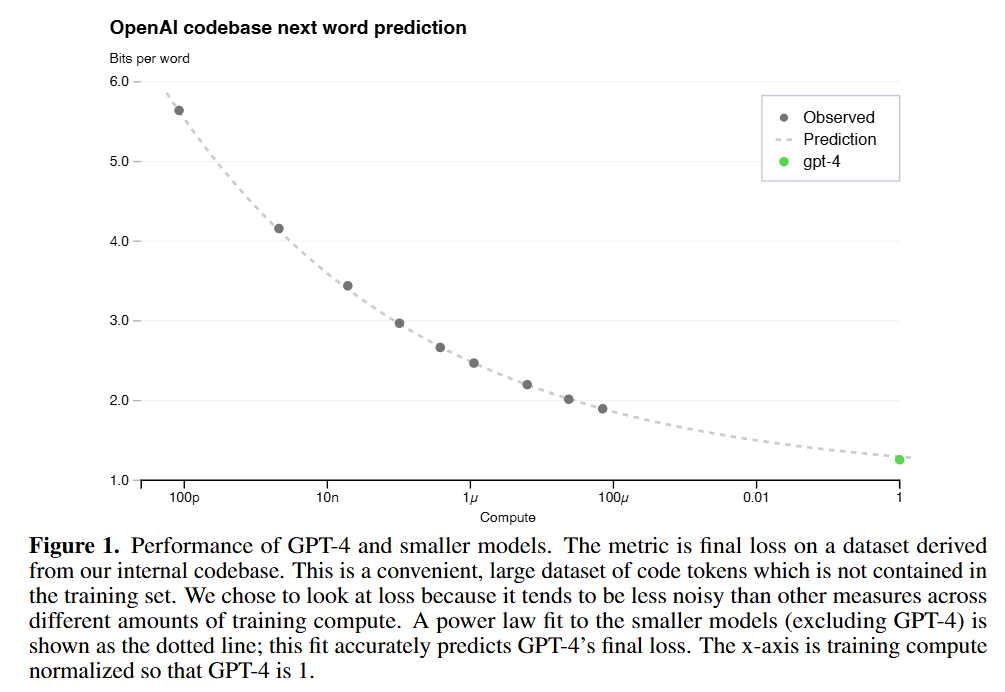
- 损失函数与计算量遵循幂函数,高度可预测
- 指标也是
- 但也有例外:
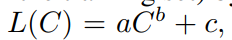
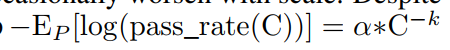
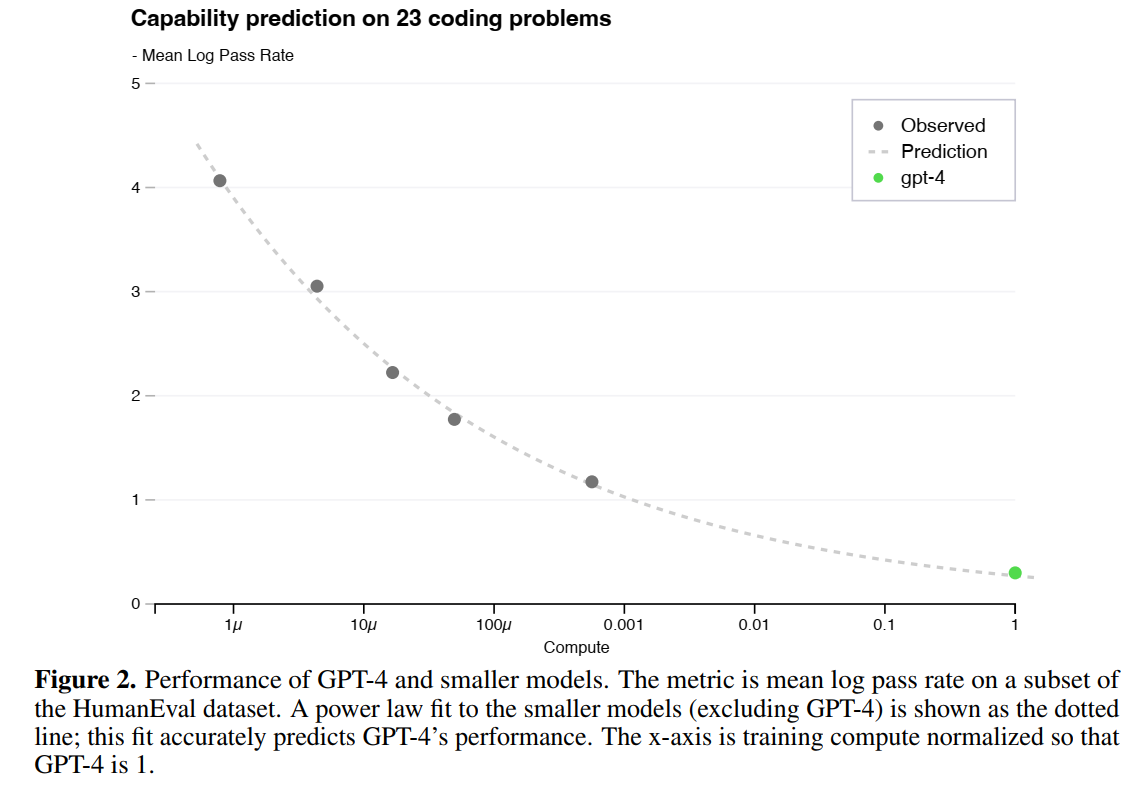
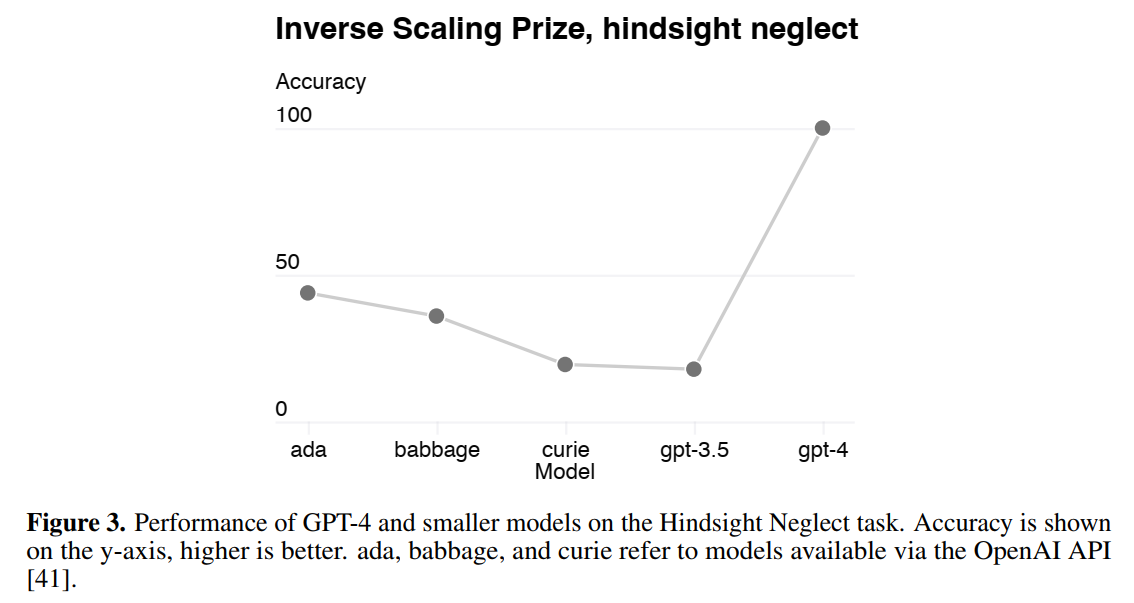
3. 实验结果
对于数据污染情况,又做了一个把测试集中泄露数据去掉的新数据集,报告两个测试集上比较差的结果。
考试:
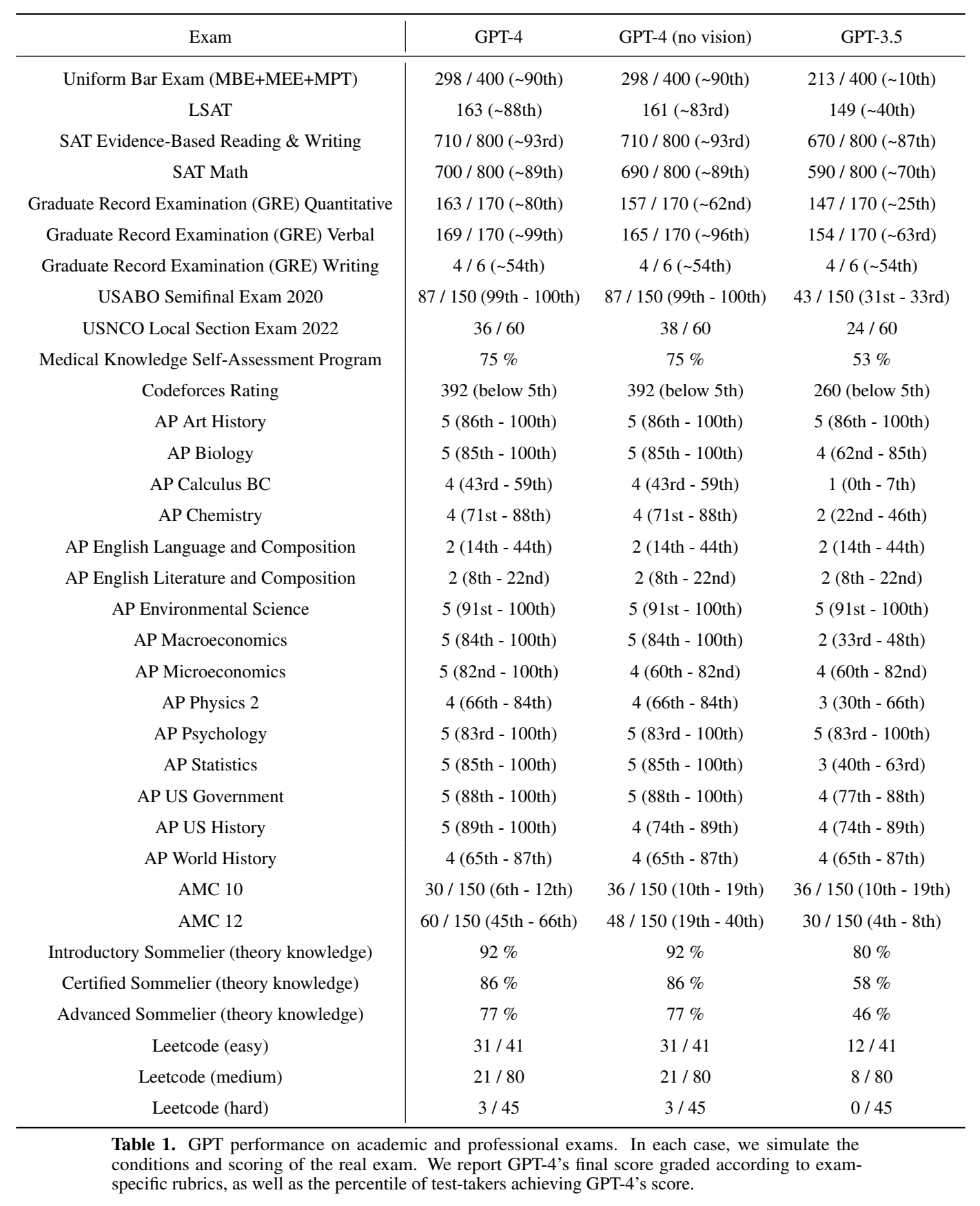
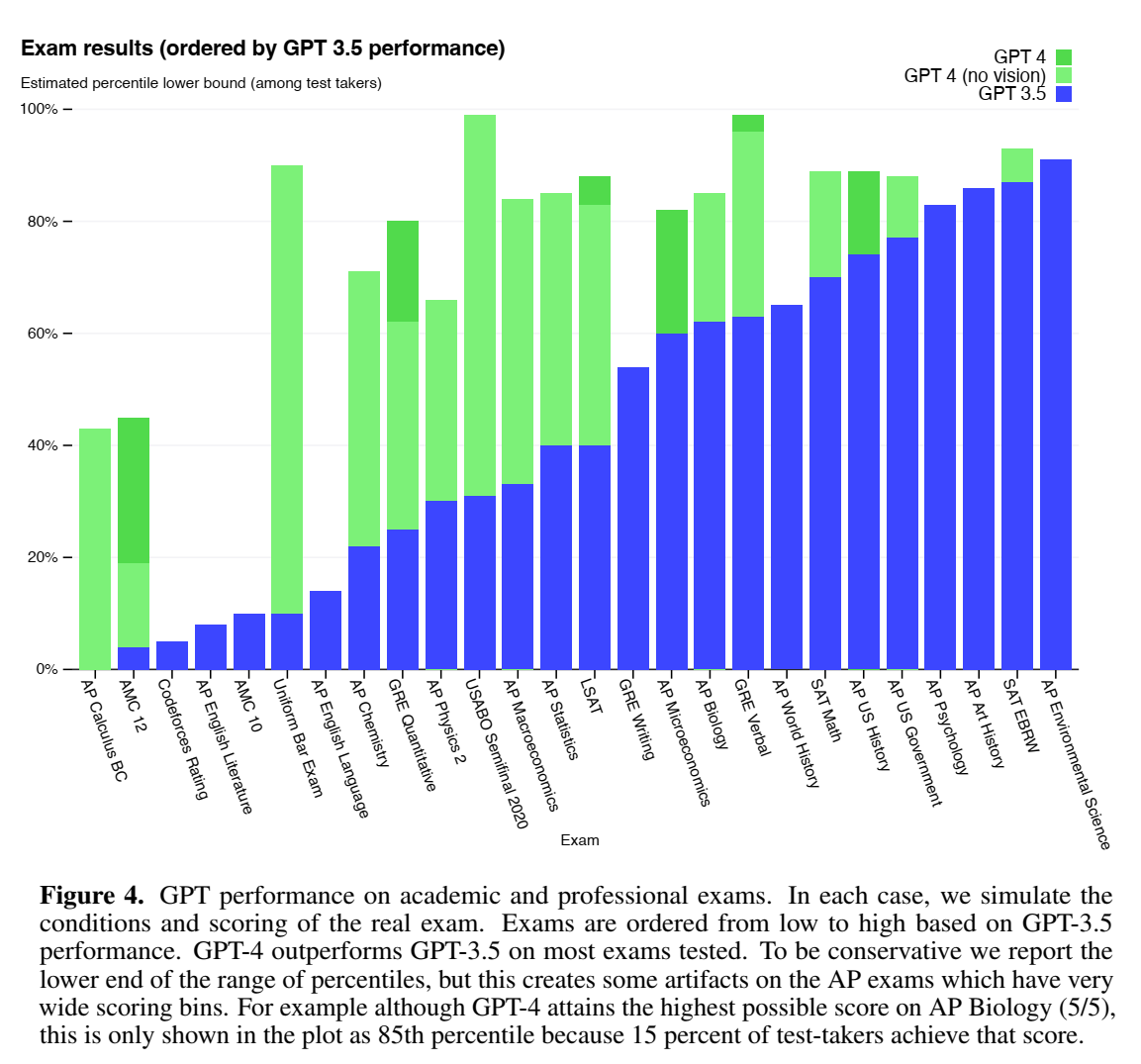
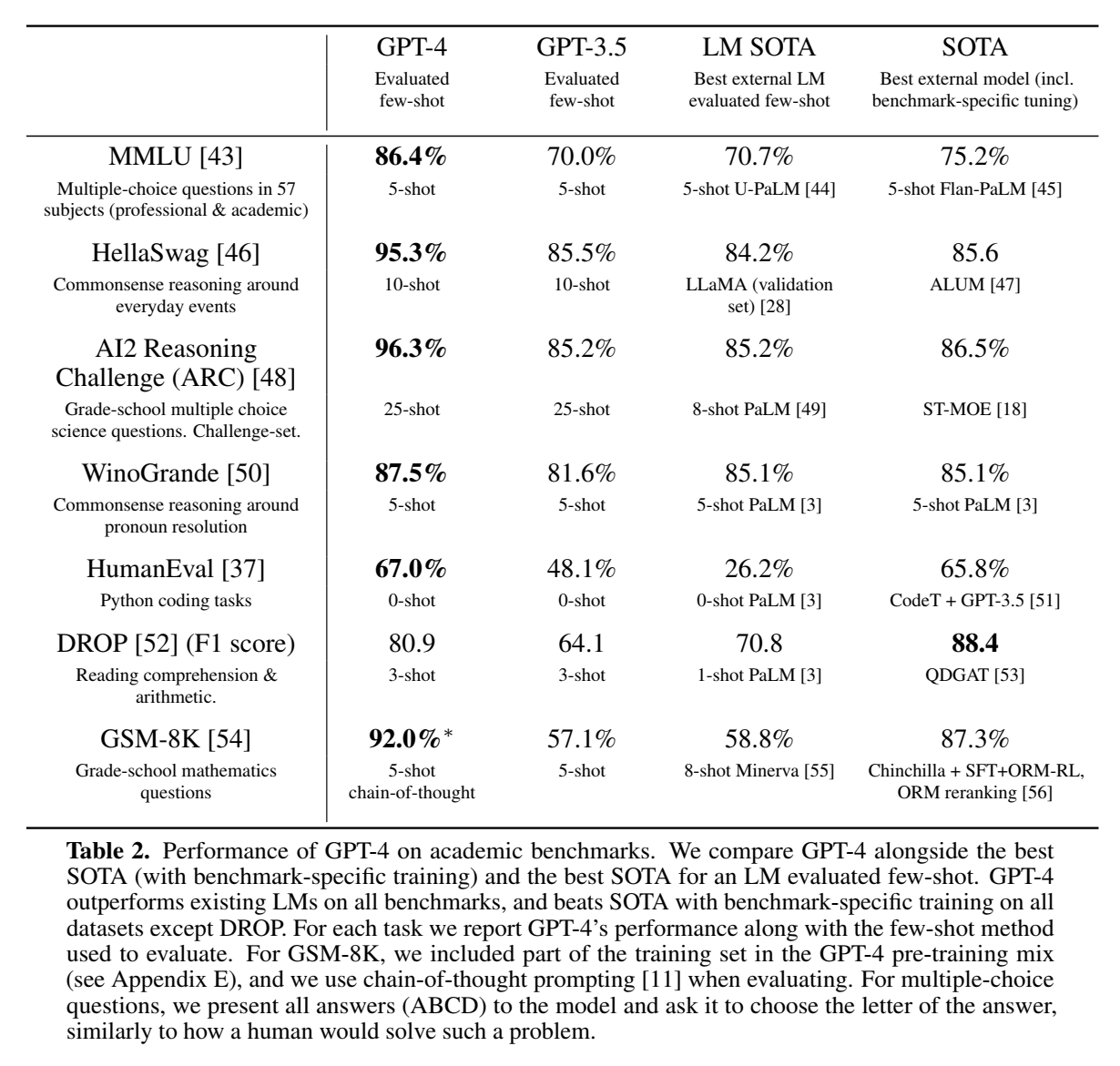
标准LM benchmark:
在用户偏好方面,相比GPT-3.5,人工标注者对GPT-4的回答打分更高。
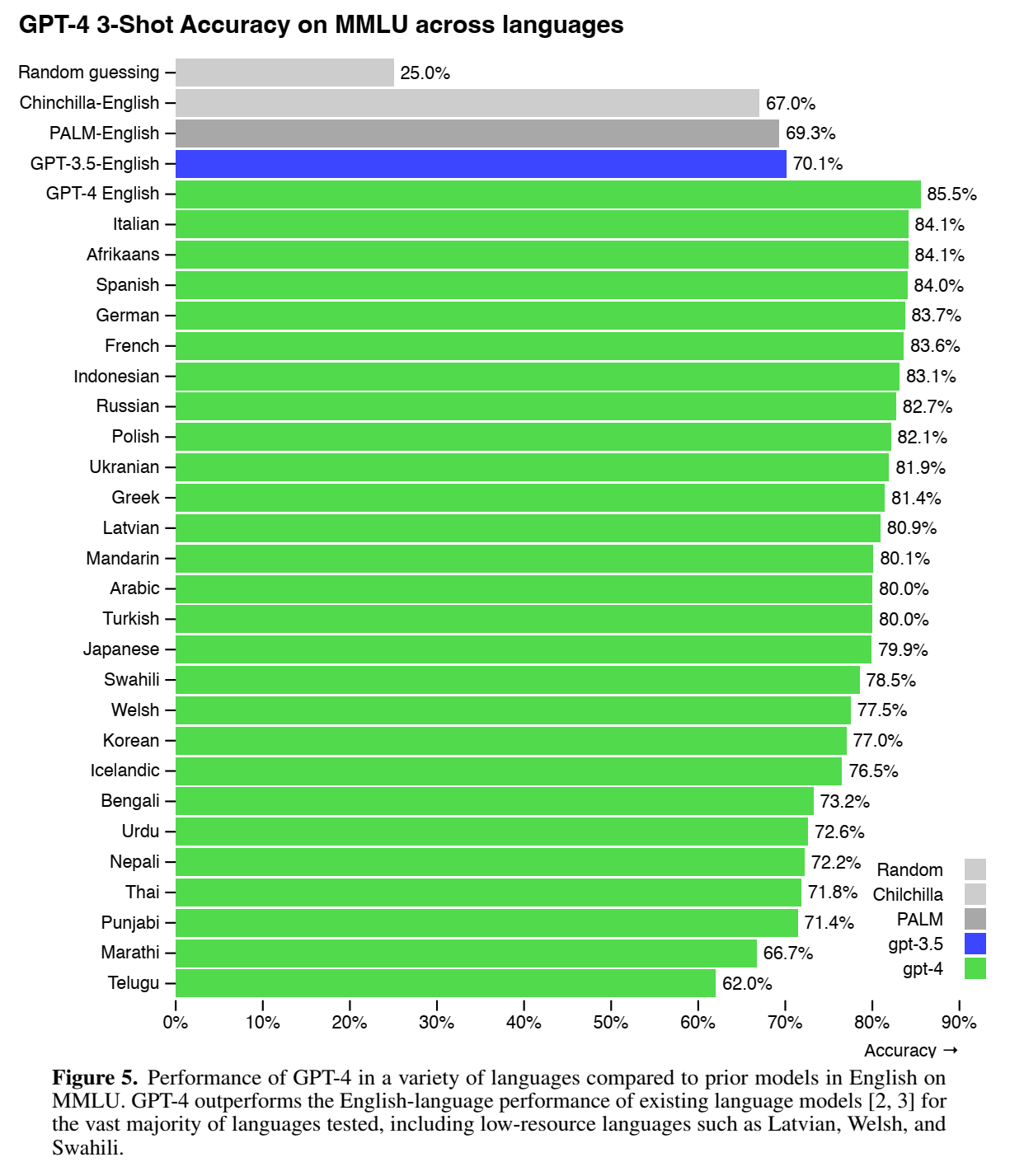
GPT-4的跨语言能力:
多模态示例:

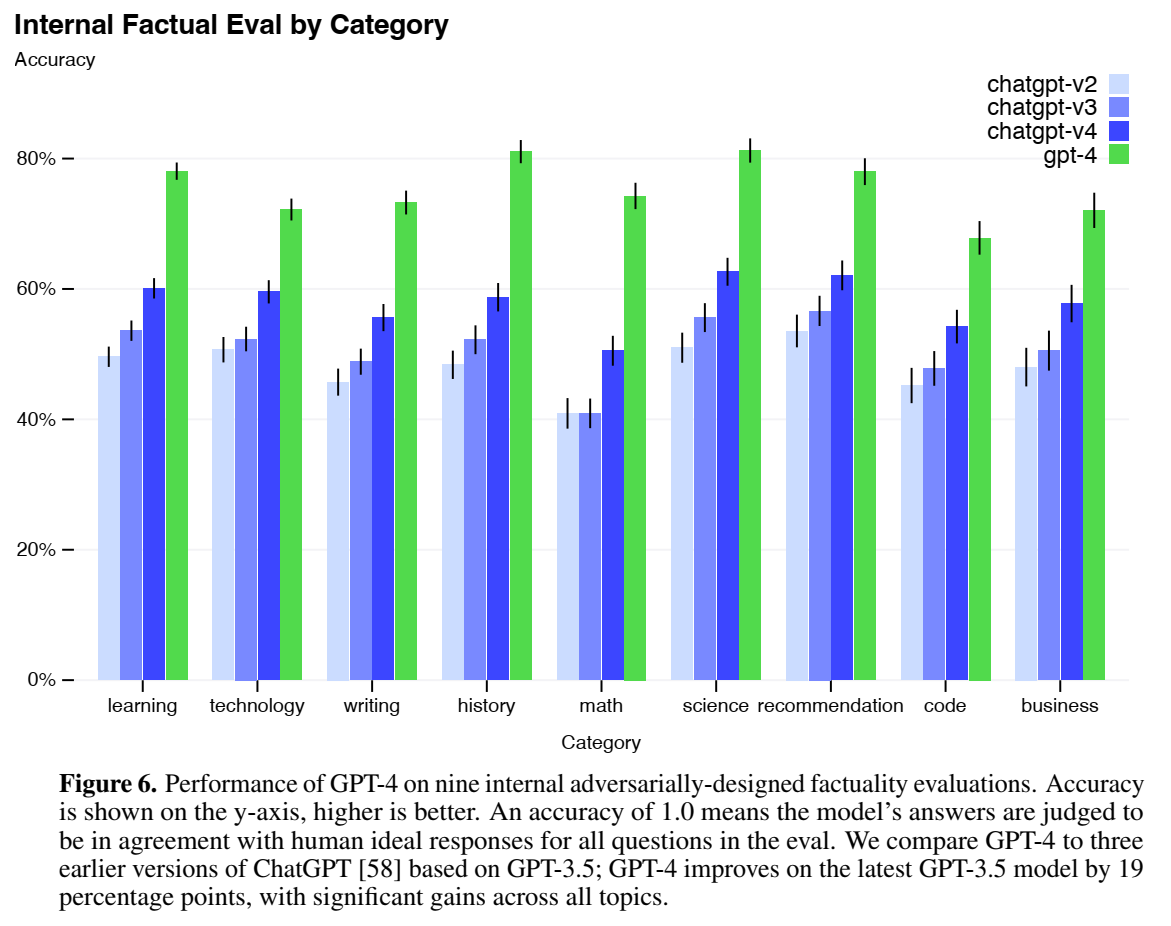
遵从事实的能力得到了提升:
上图任务所用的数据示例:

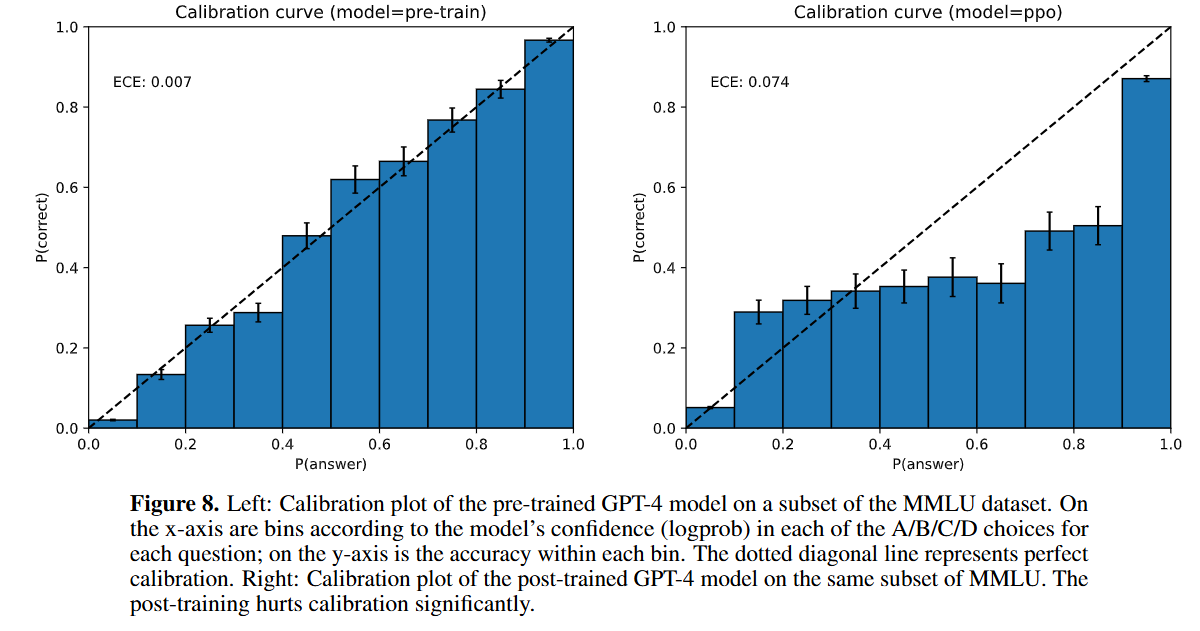
后训练(PPO)影响calibration(评估模型对可能性高的答案给出更高的置信度的能力):
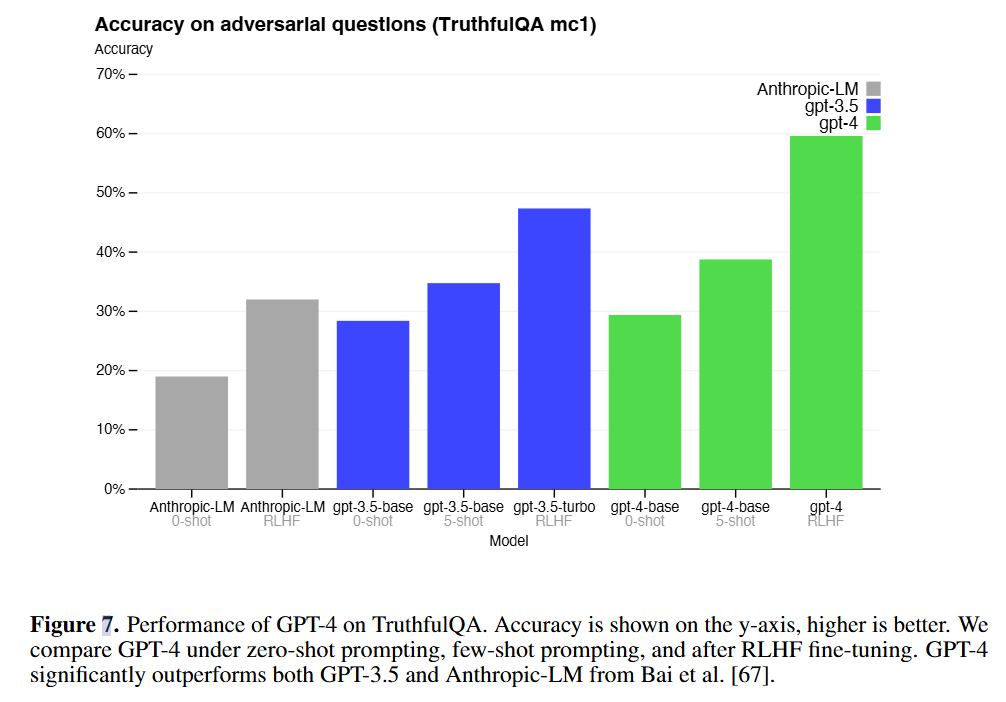
减少风险
找了专家来进行对抗式提问
示例:


改进误杀的示例:

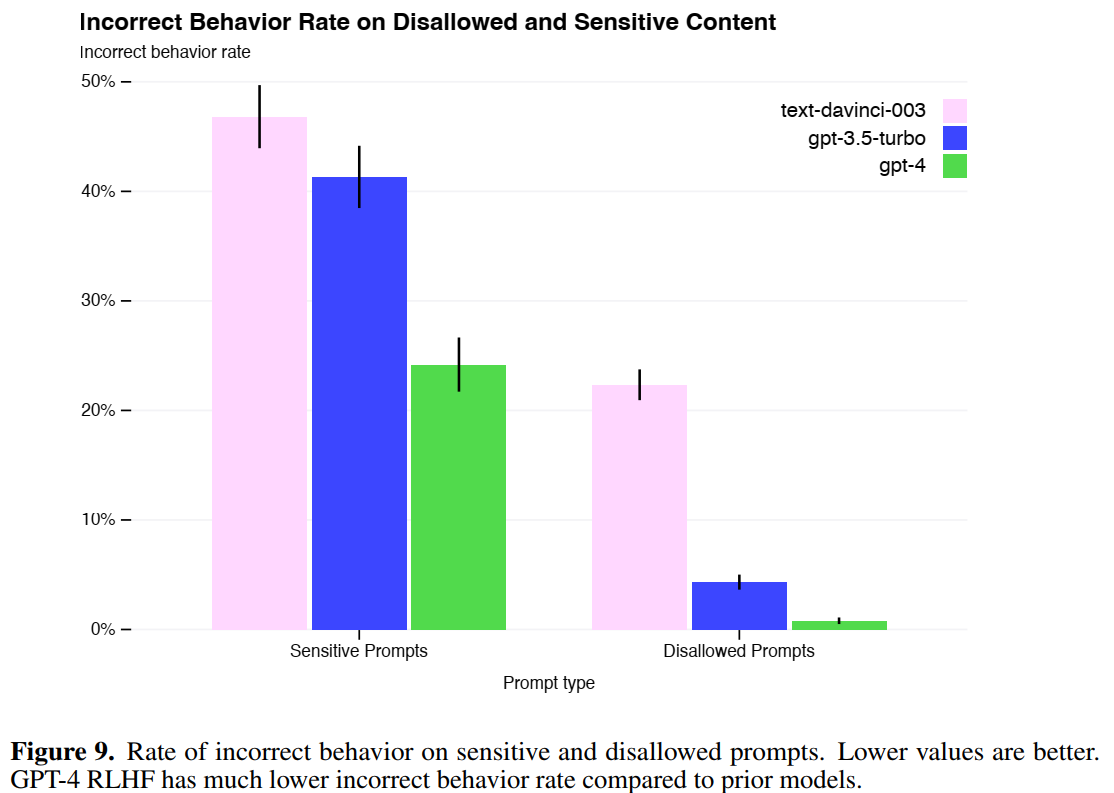
安全性提升效果: