包含编程籽料、学习路线图、爬虫代码、安装包等!【点击这里】
前言:
在本文中,我们将介绍如何使用Python编写一个简单的网络爬虫,从网站上爬取小说内容并保存到本地文件中。我们将使用requests库来发送HTTP请求,使用BeautifulSoup库来解析HTML内容,并使用正则表达式来提取小说章节内容。
-
准备工作
在开始之前,我们需要安装一些必要的Python库。你可以使用以下命令来安装这些库:
-
分析目标网站
在编写爬虫之前,我们需要先分析目标网站的结构。假设我们要爬取的小说是《斗破苍穹》,并且小说的章节列表页面URL为:https://www.example.com/doupocangqiong。

我们需要找到每个章节的链接,并进入每个章节的页面来提取小说内容。
- 编写爬虫代码
3.1 获取章节链接
首先,我们需要获取所有章节的链接。我们可以通过以下代码来实现:
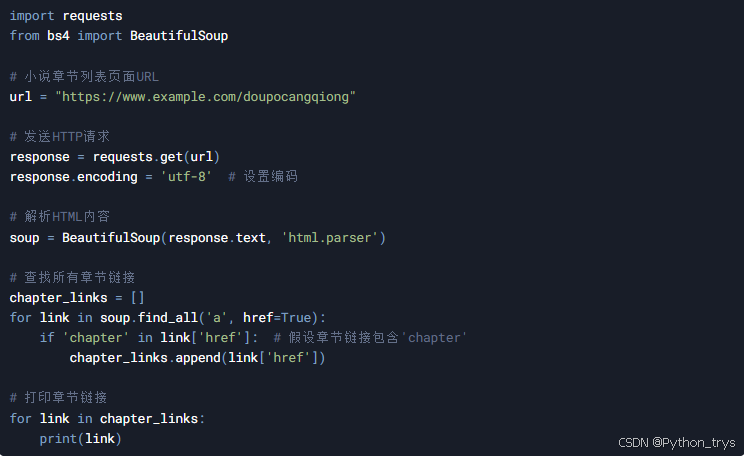
3.2 提取章节内容
接下来,我们需要进入每个章节的页面,提取小说内容并保存到本地文件中。
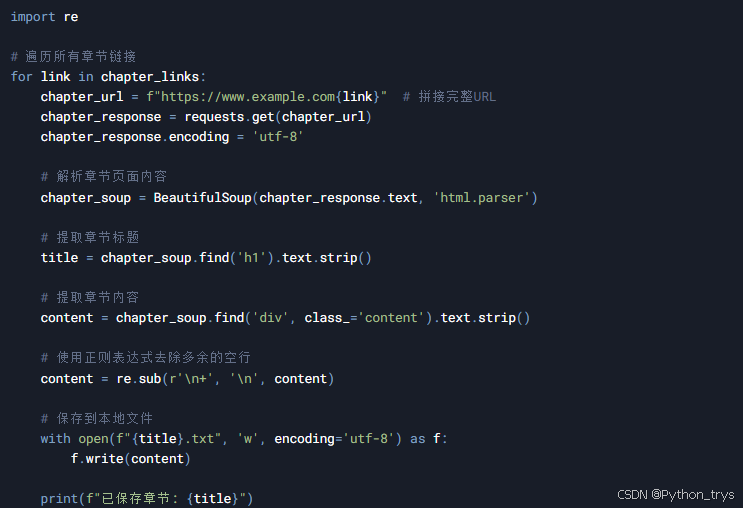
3.3 完整代码
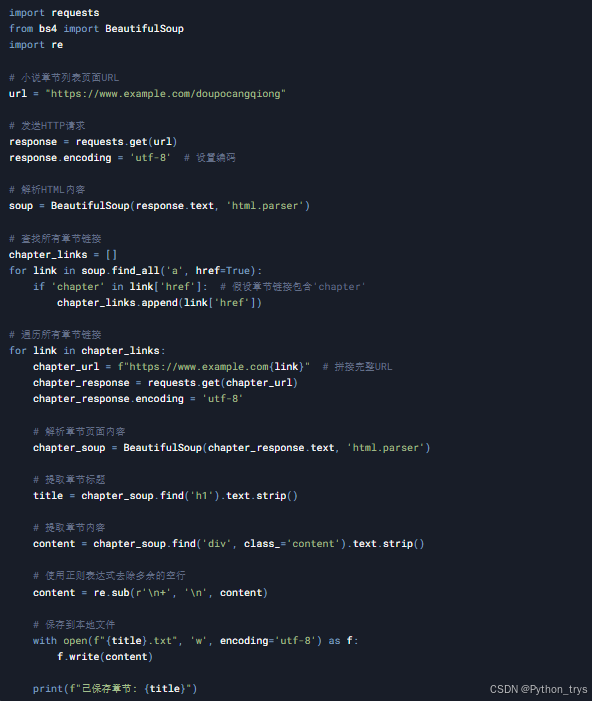
将上述代码整合在一起,完整的爬虫代码如下:
4. 注意事项
合法性:在爬取任何网站内容之前,请确保你遵守该网站的robots.txt文件和相关法律法规。未经授权的爬取行为可能会违反网站的使用条款。
反爬虫机制:一些网站可能会设置反爬虫机制,如IP封禁、验证码等。你可以通过设置请求头、使用代理IP等方式来规避这些机制。
性能优化:如果需要爬取大量数据,建议使用异步请求库(如aiohttp)来提高爬取效率。
- 总结
通过本文的介绍,我们学习了如何使用Python编写一个简单的网络爬虫来爬取小说内容并保存到本地。虽然这个爬虫比较简单,但它涵盖了爬虫的基本流程:发送请求、解析HTML、提取数据、保存数据。希望这篇文章对你有所帮助!
如果你有任何问题或建议,欢迎在评论区留言讨论。
最后:
如果你是准备学习Python或者正在学习(想通过Python兼职),下面这些你应该能用得上:
包括:Python安装包、Python web开发,Python爬虫,Python数据分析,人工智能、自动化办公等学习教程。带你从零基础系统性的学好Python!
