智谱AI批量文章生成工具:Python + PyCharm从安装到实战
在内容创作中,高效、自动化地生成大量高质量原创文章成为了许多内容创作者的追求。本文将手把手教你如何从零开始,利用 Python 和 PyCharm Community Edition,结合 智谱AI GLM-4-Plus 模型,搭建一个批量生成文章的高效工具。
一、工具简介
我们要搭建的工具具备以下功能:
- 批量生成:支持同时生成多个高质量文章,内容符合SEO需求。
- 自动保存:生成的文章按主题保存在本地,文件名即主题名称。
- 实时进度显示:在生成过程中,输出标题名称、线程编号和时间戳。
- 内容去重:避免重复生成内容,确保文件唯一性。
二、注册智谱AI账号并获取API
1. 注册智谱AI账号
- 访问官网:打开 智谱AI官网。
- 注册新账号:
- 点击右上角的
注册按钮。 - 按要求填写注册信息,包括手机号、邮箱和密码。
- 完成后登录账号。
- 点击右上角的
2. 获取API密钥
- 进入开发者中心:
- 登录后,点击右上角的用户名,进入
开发者中心。
- 登录后,点击右上角的用户名,进入
- 生成API Key:
- 点击
API密钥管理,然后点击生成API密钥按钮。 - 系统将生成一个独特的密钥,格式为
{id}.{secret}。
- 点击
- 查看API使用说明:
- 在开发者中心的文档页面,可以查看
API接口文档,了解API参数和调用方式。
- 在开发者中心的文档页面,可以查看
3. API体验与购买
- 新用户体验:
- 注册成功后,新用户通常会获得一定的免费调用额度,可用于体验。
- 免费调用额度用完后,需购买API使用权。
- 实名认证:
- 在购买API之前,需完成实名认证。
- 实名认证步骤:
- 上传身份证信息或企业营业执照(根据个人或企业账户选择)。
- 等待审核,审核通过后即可购买API。
- 推荐使用GLM-4-Plus模型:
- GLM-4-Plus是智谱AI的旗舰模型,对标OpenAI GPT-4,性能优异且价格相对经济。
- 如果需要高质量内容生成,GLM-4-Plus是首选。
三、Python环境安装教程
1. 下载并安装 Python
-
访问官网:打开 Python 官方网站。
-
下载安装包:点击导航栏的
Downloads,选择适合你操作系统(Windows/Mac/Linux)的版本。推荐使用最新的稳定版本(如 3.12+)。 -
安装 Python:
- 双击下载的安装包。
- 勾选 Add Python to PATH(非常重要,确保命令行可以直接调用 Python)。
- 点击
Customize installation,确保勾选pip和Python 3.x。 - 按提示完成安装。
-
验证安装:
- 打开终端(Windows 的 CMD 或 Mac 的 Terminal)。
- 输入命令
python --version或python3 --version,如果出现版本号,则安装成功。
四、安装 PyCharm Community Edition
1. 下载 PyCharm
- 访问官网:打开 JetBrains 官网。
- 选择免费版本:点击
Download按钮,下载 Community Edition(免费版本)。
2. 安装 PyCharm
- 运行安装程序:
- Windows 用户:双击
.exe文件。 - Mac 用户:双击
.dmg文件后,将 PyCharm 拖入Applications文件夹。
- Windows 用户:双击
- 按提示安装:
- 勾选
Create Desktop Shortcut,方便快速打开。 - 安装完成后运行 PyCharm。
- 勾选
3. 初次配置 PyCharm
- 选择主题:根据喜好选择界面风格(如 Darcula 深色主题)。
- 创建新项目:
- 打开 PyCharm,点击
New Project。 - 在
Location选择项目保存路径。 - 确保右侧
Base Interpreter选择已安装的 Python 版本。
- 打开 PyCharm,点击
- 安装项目依赖:
- 打开
Terminal(位于 PyCharm 窗口底部)。 - 输入以下命令安装必要的库:
pip install zhipuai pip install requests
- 打开
五、实现智谱AI批量文章生成工具
1. 代码结构
项目目录结构如下:
MyArticleGenerator/
├── keyword.txt # 保存关键词列表,每行一个关键词
├── Content/ # 自动生成的文章保存目录
├── main.py # 主程序文件
2. 准备关键词文件
在项目目录下创建 keyword.txt 文件,填写你需要生成文章的主题,每行一个。例如:
如何提升网站SEO排名
简牛2.0是否适合工业应用
内容营销的未来趋势
3. 代码实现
请将以下代码复制到 main.py 文件中运行:
import os
import requests
import threading
from datetime import datetime
# API 认证信息
API_URL = "https://open.bigmodel.cn/api/paas/v4/chat/completions"
API_KEY = "your_api_key_here" # 填写API密钥
# 从本地文件中读取主题关键词
def get_keyword_from_file(file_path='keyword.txt'):
try:
with open(file_path, 'r', encoding='utf-8') as file:
keywords = [line.strip() for line in file if line.strip()]
return keywords
except FileNotFoundError:
print(f"文件 {file_path} 未找到,请检查路径。")
return []
# 检查并创建 Content 目录
def ensure_directory_exists(directory='Content'):
if not os.path.exists(directory):
os.makedirs(directory)
# 定义生成文本的函数并保存到文件
def generate_text(theme, index, total):
headers = {
"Authorization": f"Bearer {API_KEY}",
"Content-Type": "application/json"
}
prompt = f"""
# 角色
你是一名文案创作者,根据指定主题撰写一篇符合SEO需求的原创文章,并且有深度内容质量高。
## 主题:
{theme}
## 技能
### 技能 1:文案创作
1. **开篇核心突出**:开篇段落必须包含核心关键词,简明传达主题要点;第一段即让读者明白文章内容。
2. **结构分明、逻辑清晰**:使用小标题将文章分段,并使用富含信息的描述性标题。
3. **深度指导**:逐步详细介绍每个操作步骤,确保所有步骤对初学者易懂,并对可能的问题进行指导。
4. **关键词密度与相关性**:控制核心关键词的密度在2-3%,自然分布在文章内,并且结合多个长尾关键词以覆盖更多搜索需求。
5. **多角度拓展**:在主题范围内扩展相关内容,提供背景信息、常见问题和实用技巧,保证内容全面覆盖用户的潜在疑问。
6. **用户体验导向**:文章需提供详实、有用的内容,切忌使用冗长、复杂的表达,保持语言自然流畅。
7. **语言要求**:使用中文撰写,保持风格专业、严谨。
### 技能 2:重要事项与内容优化
1. **关键词分布优化**:确保核心关键词和长尾关键词均匀分布在文章的各段落,自然融入,不堆砌。
2. **原创性和准确性**:所有内容需原创,通过多角度深入分析主题,避免重复;确保内容准确、权威、可信。
3. **增强读者互动**:适当添加问题式的内容或读者可能会提问的问题,以引导读者思考或停留。
## 限制
- 严格遵循上述要求进行创作,不得偏离。
- 保证内容的准确性和流畅性,避免过度营销和低质词句。
- 确保文章适合直接发布,无需编辑即可为读者提供清晰、系统的知识指导。
- 回复信息不要用pre标签,影响复制。
- 文章内不可以出现标题。
- 结尾不要用“总结、总语、总之”之类的词语,要自然收尾,如:“综合以上、通过以上、综上所述”。
"""
payload = {
"model": "glm-4-plus",
"messages": [
{"role": "user", "content": prompt}
],
"stream": False
}
response = requests.post(API_URL, json=payload, headers=headers)
timestamp = datetime.now().strftime("%Y-%m-%d %H:%M:%S")
if response.status_code == 200:
try:
result = response.json()
content = result["choices"][0]["message"]["content"]
# 检查并保存到文件
file_path = os.path.join('Content', f"{theme}.txt")
if os.path.exists(file_path):
with open(file_path, 'r', encoding='utf-8') as existing_file:
if content.strip() == existing_file.read().strip():
print(f"[{timestamp}] 标题:{theme} | 线程 {index + 1}/{total} - 内容重复,跳过。")
return
with open(file_path, 'w', encoding='utf-8') as file:
file.write(content)
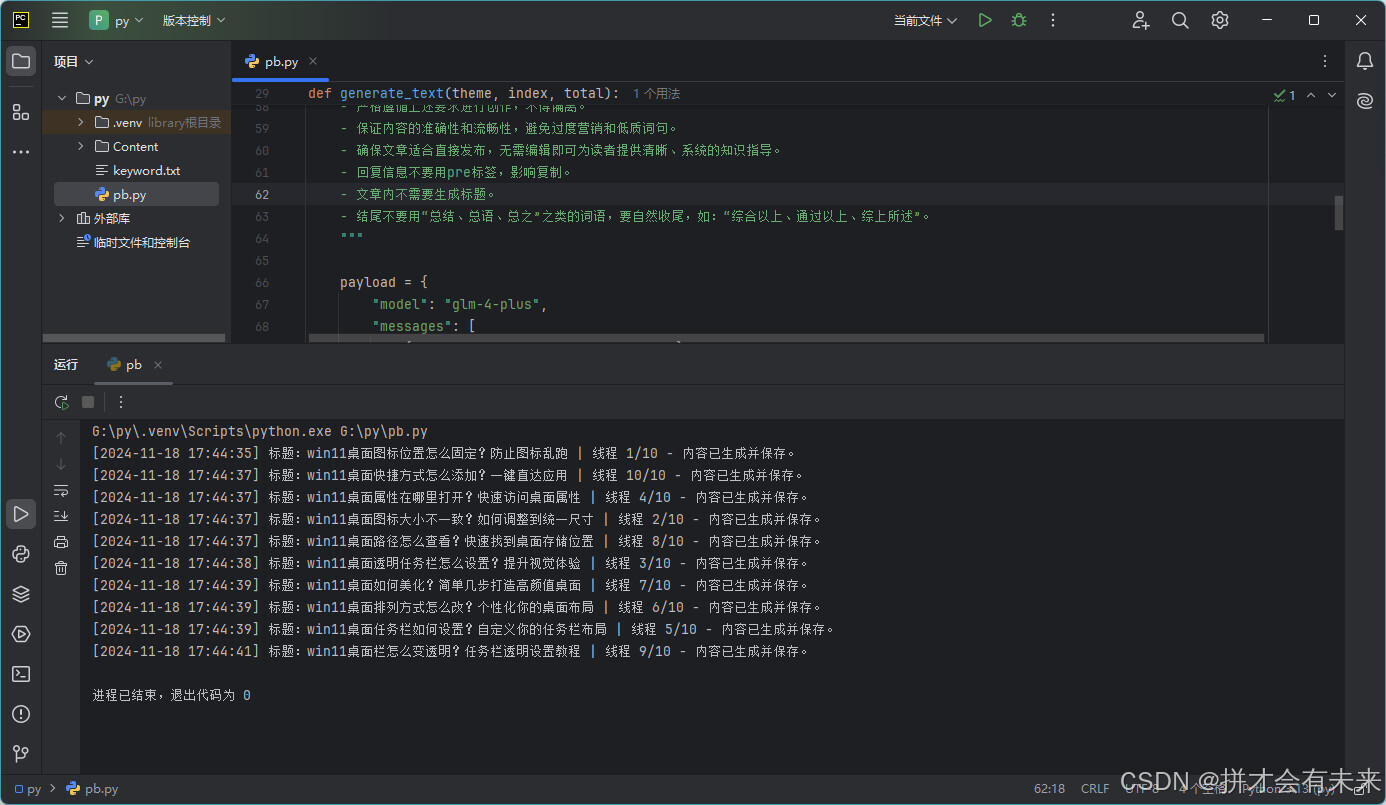
print(f"[{timestamp}] 标题:{theme} | 线程 {index + 1}/{total} - 内容已生成并保存。")
except KeyError as e:
print(f"[{timestamp}] 标题:{theme} | 线程 {index + 1}/{total} - 响应中缺少预期字段: {e}")
except requests.exceptions.JSONDecodeError:
print(
f"[{timestamp}] 标题:{theme} | 线程 {index + 1}/{total} - 响应无法解析为 JSON,请检查 API 是否返回了正确格式的数据。")
else:
print(
f"[{timestamp}] 标题:{theme} | 线程 {index + 1}/{total} - 请求失败,状态码:{response.status_code},错误信息:{response.text}")
# 读取关键词并启动线程池
def main():
ensure_directory_exists('Content')
keywords = get_keyword_from_file()
if not keywords:
print("未找到关键词,请检查 'keyword.txt' 文件。")
return
max_threads = 20 # 最大并发线程数
threads = []
total_keywords = len(keywords)
for i, keyword in enumerate(keywords):
thread = threading.Thread(target=generate_text, args=(keyword, i, total_keywords))
threads.append(thread)
# 限制同时运行的线程数量
if len(threads) >= max_threads:
for t in threads:
t.start()
for t in threads:
t.join()
threads = []
# 处理剩余的线程
for t in threads:
t.start()
for t in threads:
t.join()
if __name__ == "__main__":
main()
该程序为v1.0版本,有多少问题需要优化调整。
待优化问题:
- 对于在生成过程中原某些原因导致中断导致已生成过文章的关键词重复生成,需要进行优化过滤已生成过的关键词,避免多次生成。
- 内容输出格式默认为markdown语法,可根据个人需求定制输出格式。
- 还没想到…
后续升级版本请留言博主个人博客网站:http://www.baimahao.com
六、运行工具并查看生成内容
- 运行代码:打开 PyCharm,运行
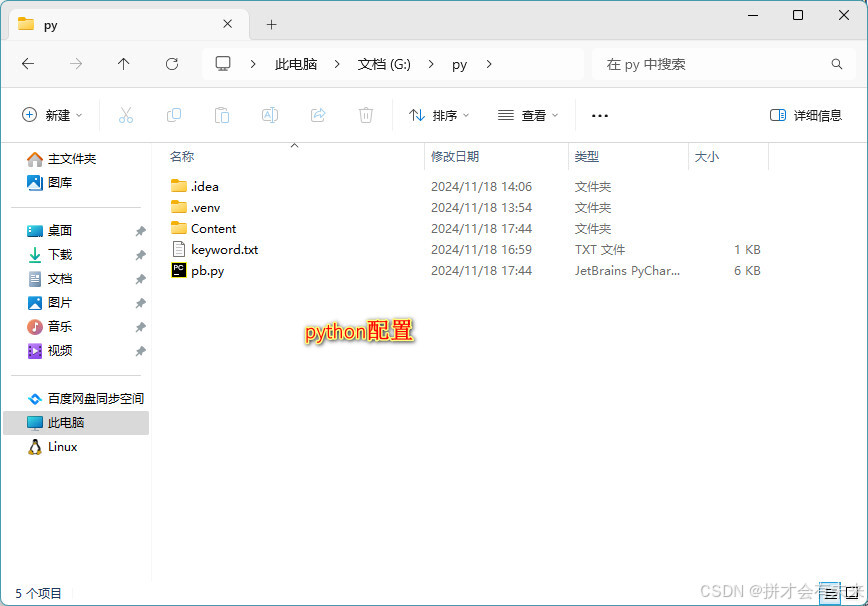
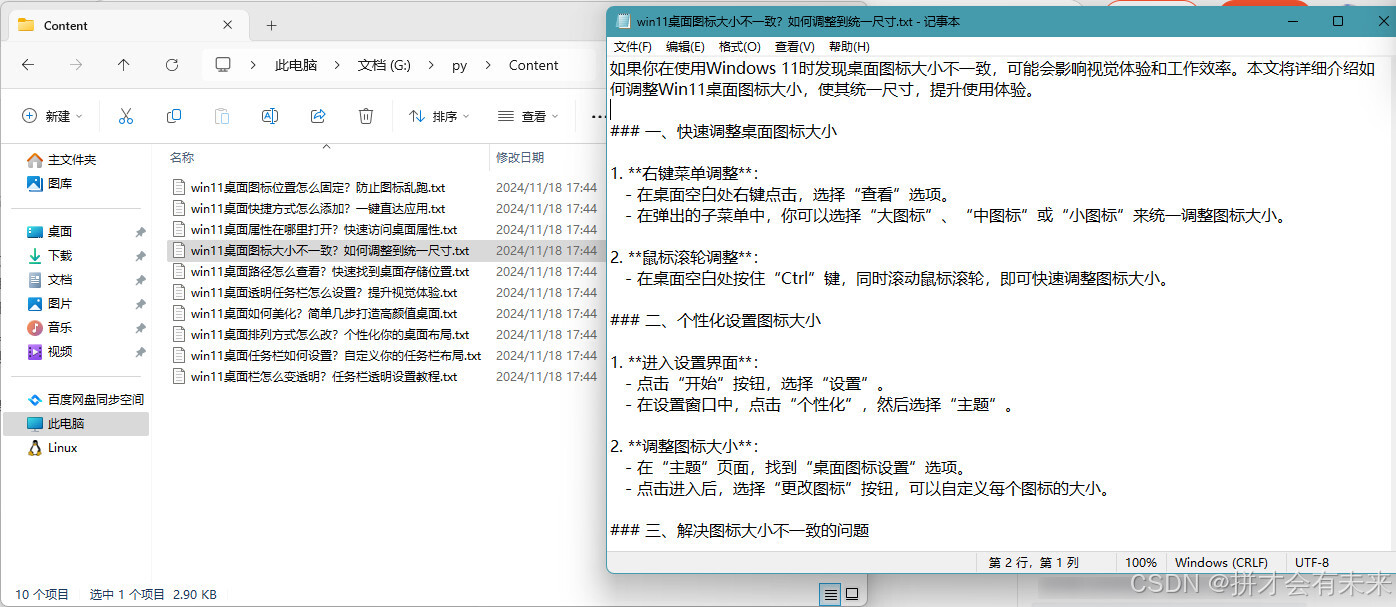
main.py文件。 - 查看内容:生成的文章会保存在
Content目录下,以关键词为文件名保存为.txt文件。
执行效果图
七、总结
本文从安装 Python 和 PyCharm 开始,详细介绍了如何注册智谱AI账号、获取API密钥以及搭建一个结合智谱AI的批量文章生成工具。通过多线程处理、高效保存和实时日志输出,这款工具可以帮助你快速生成高质量内容。如果你是内容创作者或SEO从业者,这无疑是一个提升效率的必备工具!
如果觉得本文对你有帮助,请在博客下方留言分享你的使用体验!