大家好,我是卢旗。
今天来聊聊GPU。GPU,全称Graphic Processing Unit,即图形处理器。它的并行处理能力非常强大,能够同时处理多个任务和数据,因此被广泛用于图形渲染、视频处理、深度学习、科学计算等领域。
研发团队在负责制定硬件选型策略并设计优化下一代大规模GPU集群的软硬件架构时,我们需要关注GPU技术的最新进展、重点研究问题以及潜在的技术突破。
一、GPU在重点研究的问题
- 算力提升与能效优化:
- 问题:随着人工智能、大数据等技术的快速发展,对计算能力的需求急剧增加。如何在提升GPU算力的同时,保持或降低能耗,成为当前研究的重点。
- 技术突破:新一代GPU如NVIDIA的H100、A100以及更高级的Blackwell系列,通过改进架构和工艺,实现了算力的大幅提升和能效比的优化。例如,H100相比A100在FP16稠密算力上提升了超3倍,同时功耗控制得当。
- 内存与带宽:
- 问题:大规模模型训练需要处理海量数据,这对GPU的内存容量和带宽提出了更高要求。
- 技术突破:采用高带宽内存技术(如HBM2e)和更高效的内存管理系统,可以显著提升GPU的数据处理能力。
- 并行计算与通信优化:
- 问题:在大规模GPU集群中,如何高效地进行数据并行、模型并行和专家并行,以及如何在不同GPU之间实现低延迟、高带宽的通信,是提升集群整体性能的关键。
- 技术突破:NVIDIA的NVLink和NVSwitch技术实现了GPU之间的全面互联,确保了性能的极致释放。同时,优化网络拓扑结构(如3-Tier、Fat-Tree)和采用高速网卡(如Mellanox的ConnectX系列)也可以提升集群的通信效率。
- 容错与可靠性:
- 问题:在大规模训练中,硬件和软件故障难以避免,如何确保训练的连续性和数据的可靠性成为重要问题。
- 技术突破:通过实现高效的容错系统和检查点机制,可以在硬件或软件故障发生时快速恢复训练状态,确保训练的顺利进行。
二、硬件选型策略
- GPU选型:
- 根据应用需求(如训练、推理、科学计算等)和预算情况,选择合适的GPU型号。对于大规模训练任务,优先考虑算力强大、能效比高的GPU,如NVIDIA的H100、A100等。
- 服务器配置:
- 选择高性能的CPU和内存配置,以匹配GPU的计算能力。同时,考虑服务器的扩展性和可维护性,确保能够灵活应对未来需求的变化。
- 存储系统:
- 采用大容量、高速的存储系统(如SSD或NVMe固态硬盘),以确保数据快速读取和处理。同时,考虑数据的安全性和可靠性,实现数据的冗余备份和容灾恢复。
- 网络设备:
- 选择高速、低延迟的网络设备(如高速网卡、交换机、光模块等),以支持GPU集群之间的高效通信。同时,考虑网络的扩展性和可管理性,确保能够满足未来集群规模的增长需求。
三、软硬件架构设计
- 模块化设计:
- 采用模块化设计思想,将GPU集群划分为多个独立的模块(如计算模块、存储模块、网络模块等),以便于管理和维护。同时,支持模块的灵活扩展和升级,以应对未来需求的变化。
- 分布式架构:
- 构建分布式GPU集群架构,通过高效的并行计算和通信机制,实现计算资源的共享和优化利用。同时,考虑集群的负载均衡和容错机制,确保集群的稳定性和可靠性。
- 软件优化:
- 开发或采用高效的编程框架和并行加速库(如CUDA、TensorRT等),以充分利用GPU的并行计算能力。同时,优化软件算法和数据结构,以减少计算复杂度和提高计算效率。
四、优化的思考
在主导超大规模AI异构计算集群的设计与优化过程中,研发者需要付出深入的思考和多方面的努力,以提供训练/推理加速、故障诊断容错等功能。
1、思考维度
- 需求分析:
- 业务需求:明确AI模型的需求,包括模型规模、训练数据量、推理速度等。
- 计算需求:根据业务需求,评估所需的计算资源,包括GPU、CPU、内存、存储等。
- 架构设计:
- 异构计算:结合GPU、CPU、FPGA等多种计算资源,设计高效的异构计算架构。
- 并行计算:采用数据并行、模型并行、流水线并行等多种并行策略,提升计算效率。
- 网络设计:设计高性能、低延迟的网络架构,确保计算节点间的数据通信顺畅。
- 优化策略:
- 算法优化:针对特定模型进行算法优化,如优化神经网络结构、参数初始化等。
- 硬件优化:利用GPU的加速库(如CUDA、TensorRT)和特定硬件特性(如NVLink)进行硬件加速。
- 软件优化:优化集群管理软件、资源调度系统等,提高集群的整体性能和稳定性。
- 故障诊断与容错:
- 监控与日志:建立完善的监控系统和日志记录机制,实时监测集群状态。
- 故障诊断:开发智能故障诊断工具,快速定位并解决问题。
- 容错机制:设计容错机制,如检查点(Checkpoint)和回滚恢复(Rollback Recovery),确保训练过程不因硬件故障而中断。
2、实际案例
以某超大规模AI异构计算集群的设计与优化为例,该集群采用了以下策略来突破难关:
- 架构设计:
- 该集群采用了多层无收敛的CLOS组网结构,确保了集群内互通带宽的充足。每个服务器上的GPU通过高速网卡和交换机相连,形成了多个独立的计算单元。
- 在计算单元内部,采用张量并行策略,充分利用单机内部NVLink的高带宽特性。在计算单元之间,采用流水线并行和数据并行策略,进一步加速模型训练。
- 优化策略:
- 针对特定模型(如大型语言模型),进行了算法优化和硬件加速。利用GPU的加速库进行矩阵运算和神经网络的加速计算。
- 开发了高效的集群管理软件,实现了资源的动态调度和负载均衡。通过智能的调度算法,确保了计算资源的最大化利用。
- 故障诊断与容错:
- 建立了全面的监控系统和日志记录机制,实时监测集群的硬件状态、网络状态、任务进度等信息。
- 开发了智能故障诊断工具,通过机器学习算法对日志数据进行分析和挖掘,快速定位并解决问题。
- 设计了检查点和回滚恢复机制,确保在硬件故障或软件异常时能够迅速恢复训练状态,减少损失。
五、技术栈的应用
为了不断优化迭代,熟悉AI/LLM(大语言模型)训练和推理技术栈对于研发者来说至关重要。这些技术栈包括PyTorch、TensorFlow、vLLM、Triton以及CUDA库(如cuBLAS、cuDNN、TensorRT)等。
以下是这些技术栈的特征、优势以及如何在生产中高效应用的建议:
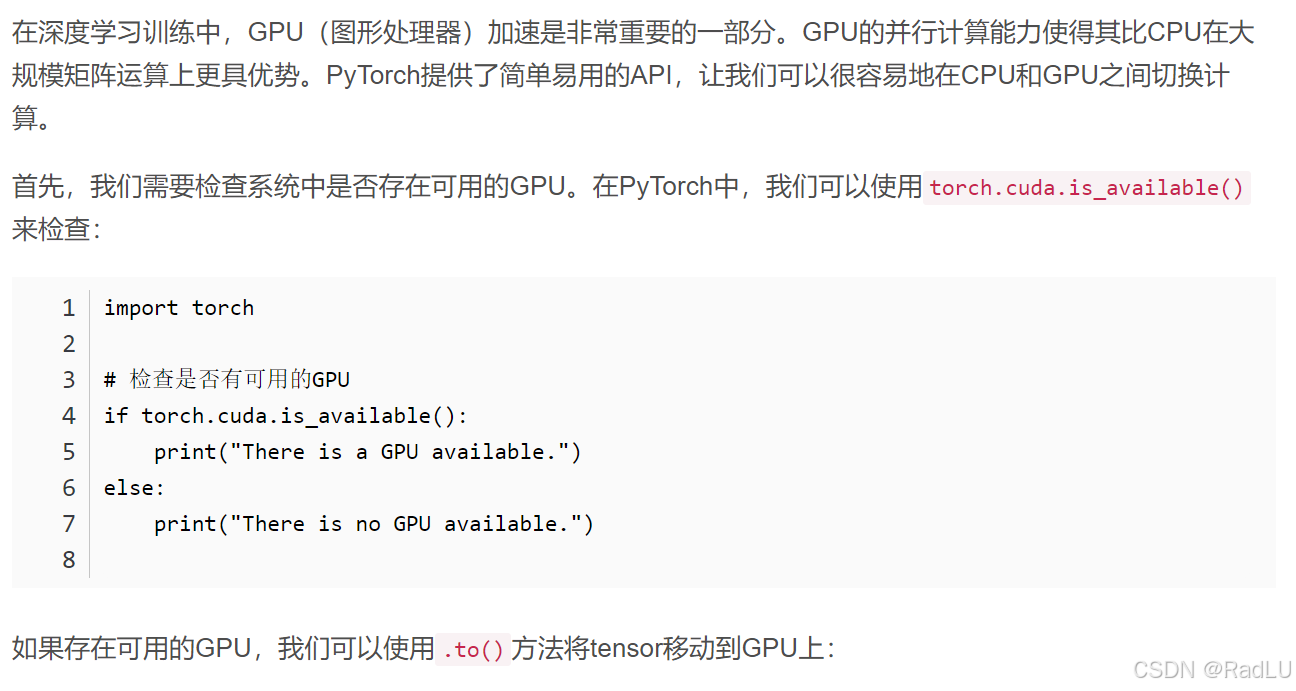
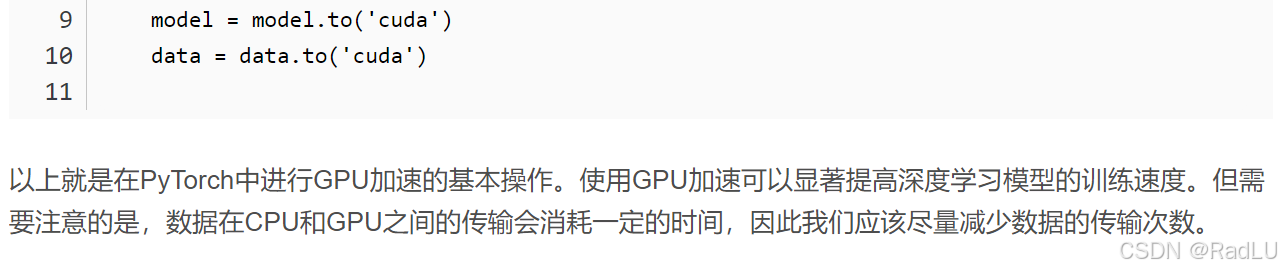
1. PyTorch
特征与优势:
- 动态计算图:PyTorch的计算图是在运行时构建的,支持动态修改和调整,便于实验和调试。
- 灵活性:提供大量的灵活性,允许用户自定义模型和训练流程。
- 易用性:API设计直观,易于学习和使用。
- 支持GPU加速:利用GPU加速深度学习模型的训练。
- 社区支持:拥有活跃的社区,提供丰富的文档、教程和代码示例。
应用建议:
- 适用于需要频繁调整模型结构和参数的实验阶段。
- 利用PyTorch的灵活性,快速迭代和优化模型。

2. TensorFlow
特征与优势:
- 灵活性:支持多种平台和设备,包括移动设备、台式机、服务器和云端环境。
- 高性能:使用计算图优化和并行化,支持GPU加速。
- 易用性:提供丰富的API和工具,支持多种编程语言(如Python、C++、Java)。
- 社区支持:庞大的用户和开发者社区,提供丰富的资源和定期更新。
- 可扩展性:支持自定义操作和扩展,便于实现复杂任务。
应用建议:
- 适用于需要稳定、高性能且易于部署的生产环境。
- 利用TensorFlow的社区支持,快速解决问题和获取最新功能。
3. vLLM
特征与优势:
- 高效内存管理:采用PagedAttention算法,有效管理大语言模型的注意力内存,提升吞吐量和内存使用效率。
- 高吞吐量:相比其他框架,吞吐量显著提升,适合处理大规模NLP任务。
- 易于集成:可与HuggingFace无缝集成,方便使用现有模型。
应用建议:
- 适用于需要处理大量文本数据和高吞吐量的实时场景。
- 利用vLLM的内存优化技术,提升模型推理效率。
4. Triton
特征与优势:
- 高性能:针对深度学习推理场景进行高度优化,支持多种硬件平台。
- 可扩展性:支持横向和纵向扩展,满足高并发需求。
- 易用性:提供简洁的API接口和详细的文档支持,降低学习成本。
应用建议:
- 适用于需要高性能推理和多模型部署的生产环境。
- 利用Triton的扩展性和易用性,快速部署和扩展模型服务。
5. CUDA库(cuBLAS、cuDNN、TensorRT)
特征与优势:
- cuBLAS:提供基本线性代数子程序的GPU加速实现,支持大规模矩阵运算。
- cuDNN:针对深度学习优化的GPU加速库,提供高效的神经网络前向和后向传播。
- TensorRT:用于优化和部署深度学习模型的高性能推理引擎,支持多种硬件平台。
应用建议:
- 利用CUDA库加速深度学习模型的训练和推理过程。
- 在生产环境中,结合cuBLAS、cuDNN和TensorRT等库,优化模型性能和响应速度。
高效应用建议
- 明确需求:在选择技术栈时,首先要明确应用场景和需求,以便选择最合适的技术。
- 持续学习:深度学习领域发展迅速,持续学习新技术和最佳实践对于高效应用至关重要。
- 优化模型:针对特定任务优化模型结构和参数,提升模型性能和效率。
- 利用社区资源:积极参与社区交流和学习,获取最新的技术动态和解决方案。
- 性能测试:在生产环境部署前进行充分的性能测试和调优,确保模型性能符合预期。
综上,研发者应根据具体需求和场景选择合适的技术栈,并结合最佳实践和优化策略来高效应用在生产中。
六、先进的产品
目前市场上GPU的先进产品众多,主要由英伟达(NVIDIA)、AMD和英特尔(Intel)等几家大公司主导。
一些先进GPU产品:
英伟达(NVIDIA)
- GeForce系列:面向消费级市场,提供高性能的图形处理能力和游戏特性。最新型号包括RTX 40系列(如RTX 4090、RTX 4080等)和RTX 30系列(如RTX 3090、RTX 3080等)。
- Quadro系列:面向专业级市场,针对商业和专业应用领域进行了优化。常用于图形设计、视频编辑、3D建模和渲染等需要高精度图形处理的任务。
- Tesla系列:面向数据中心和大型计算应用,提供强大的并行计算能力,适用于高性能计算(HPC)、深度学习、大数据分析等任务。
- Jetson系列:面向边缘计算和人工智能应用的嵌入式开发平台,集成了GPU和其他专用硬件,适用于自动驾驶、机器人、无人机等场景。
- DGX系列:面向深度学习和人工智能研究的高性能计算服务器,集成了多个GPU和专用硬件,提供了强大的计算能力和高效的数据处理能力。
英伟达还特别推出了基于Blackwell架构的GPU,如B100和预计推出的GB200,这些产品在算力和能效比上均有显著提升。
AMD
- Radeon RX系列:AMD最受欢迎的GPU系列之一,提供了从入门级到高端的各种型号,广泛应用于游戏、图形设计和多媒体娱乐等领域。
- Radeon Pro系列:面向专业图形市场,专为工作站和服务器设计,提供高性能的图形处理能力。
- Radeon Instinct系列:面向高性能计算和深度学习市场,提供了出色的并行计算能力和能效比。
英特尔(Intel)
- 锐炬® Xe 显卡:提供可切换的GPU和集成显卡,为设计师和创作者带来更丰富的游戏体验和更快的速度。
- Arc系列:英特尔全新的独立显卡系列,如Arc A580 GPU,以及计划推出的代号为“Battlemage”的Xe2系列独立显卡。
七、市场售价
GPU的售价因型号、性能、市场需求和供应情况等因素而异。以下是一些大致的售价范围(请注意,这些价格可能会随时间而变化):
- 英伟达GeForce系列:
- RTX 3060Ti:约4000-5000元人民币
- RTX 3080Ti:约7000-8000元人民币
- RTX 4090等高端型号价格更高
- 英伟达Quadro系列:
- RTX 4000:约10000-12000元人民币
- RTX 6000:约18000-20000元人民币
- 更高端型号价格更高
- 英伟达Tesla系列:
- V100:约25000-30000元人民币
- V200等高端型号价格更高
- 英伟达基于Blackwell的GPU:
- B100及后续型号(如GB200)的售价较高,特别是当它们作为数据中心构建块或服务器的一部分销售时,价格可能达到数万至数十万美元不等。
作为一名先进的研发工程师,应当不断向顶尖的开发者学习。
今天就分享到这里。
感谢阅读。
点个赞再走。