写在前面
【三年面试五年模拟】旨在整理&挖掘AI算法工程师在实习/校招/社招时所需的干货知识点与面试经验,力求让读者在获得心仪offer的同时,增强技术基本面。
欢迎大家关注Rocky的公众号:WeThinkIn
欢迎大家关注Rocky的知乎:Rocky Ding
AIGC算法工程师面试面经秘籍分享:WeThinkIn/Interview-for-Algorithm-Engineer欢迎大家Star~
获取更多AI行业的前沿资讯与干货资源
WeThinkIn最新福利放送:大家只需关注WeThinkIn公众号,后台回复“简历资源”,即可获取包含Rocky独家简历模版在内的60套精选的简历模板资源,希望能给大家在AIGC时代带来帮助。
Rocky最新发布Stable Diffusion 3和FLUX.1系列模型的深入浅出全维度解析文章,点击链接直达干货知识:https://zhuanlan.zhihu.com/p/684068402
大家好,我是Rocky。
又到了定期学习《三年面试五年模拟》文章的时候了!本周期共更新了60多个AIGC面试高频问答,依旧干货满满!诚意满满!
《三年面试五年模拟》系列文章帮助很多读者获得了心仪的算法岗offer,收到了大家的很多好评,Rocky觉得很开心也很有意义。
在AIGC时代到来后,Rocky对《三年面试五年模拟》整体战略方向进行了重大的优化重构,在秉持着Rocky创办《三年面试五年模拟》项目初心的同时,增加了AIGC时代核心的版块栏目,详细的版本更新内容如下所示:
- 整体架构:分为AIGC知识板块和AI通用知识板块。
- AIGC知识板块:分为AI绘画、AI视频、大模型、AI多模态、数字人这五大AIGC核心方向。
- AI通用知识板块:包含AIGC、传统深度学习、自动驾驶等所有AI核心方向共通的知识点。
Rocky已经将《三年面试五年模拟》项目的完整版构建在Github上:https://github.com/WeThinkIn/Interview-for-Algorithm-Engineer/tree/main,本周期更新的60+AIGC面试高频问答已经全部同步到项目中了,欢迎大家star!
本文是《三年面试五年模拟》项目的第二十九式,考虑到易读性与文章篇幅,Rocky本次只从Github完整版项目中摘选了2024年12月16号-2024年12月29号更新的部分高频&干货面试知识点,并配以相应的参考答案(精简版),供大家学习探讨。
在《三年面试五年模拟》版本更新白皮书,迎接AIGC时代中我们阐述了《三年面试五年模拟》项目在AIGC时代的愿景与规划,也包含了项目共建计划,感兴趣的朋友可以一起参与本项目的共建!
《三年面试五年模拟》系列将陪伴大家度过在AI行业的完整职业生涯,并且让大家能够持续获益。
So,enjoy:
正文开始
目录先行
AI绘画基础:
-
Stable Diffusion 3的图像特征和文本特征在训练前缓存策略有哪些优缺点?
-
什么是人脸解析(Face Parsing)任务?
AI视频基础:
-
介绍一下HunyuanVideo模型的架构
-
HunyuanVideo模型有哪些特点?
深度学习基础:
-
AI模型的池化层包含可学习参数吗?
-
如何设置随机种子让AI模型的推理结果可以复现?
机器学习基础:
-
介绍一下机器学习中的SVD(Singular Value Decomposition)技术
-
介绍一下机器学习中的聚类算法原理
Python编程基础:
-
在AI服务中,python如何加载我们想要指定的库?
-
Python中None代表什么含义?
模型部署基础:
-
AI模型的参数量如何计算?
-
介绍一下模型部署领域自定义算子的概念
计算机基础:
-
介绍一下计算机文件系统的死锁原理
-
解决计算机文件系统死锁的经典方法有哪些?
开放性问题:
-
AI算法工程师如何以AI技术为核心,统筹推动业务的构建与发展?
-
AI公司如何评估和控制各业务部门的成本与效益?
AI绘画基础
【一】Stable Diffusion 3的图像特征和文本特征在训练前缓存策略有哪些优缺点?
SD 3与之前的版本相比,整体的参数量级大幅增加,这无疑也增加了训练成本,所以官方的技术报告中也对SD 3训练时冻结(frozen)部分进行了分析,主要评估了VAE、CLIP-L、CLIP-G以及T5-XXL的显存占用(Mem)、推理耗时(FP)、存储成本(Storage)、训练成本(Delta),如下图所示,T5-XXL的整体成本是最大的:
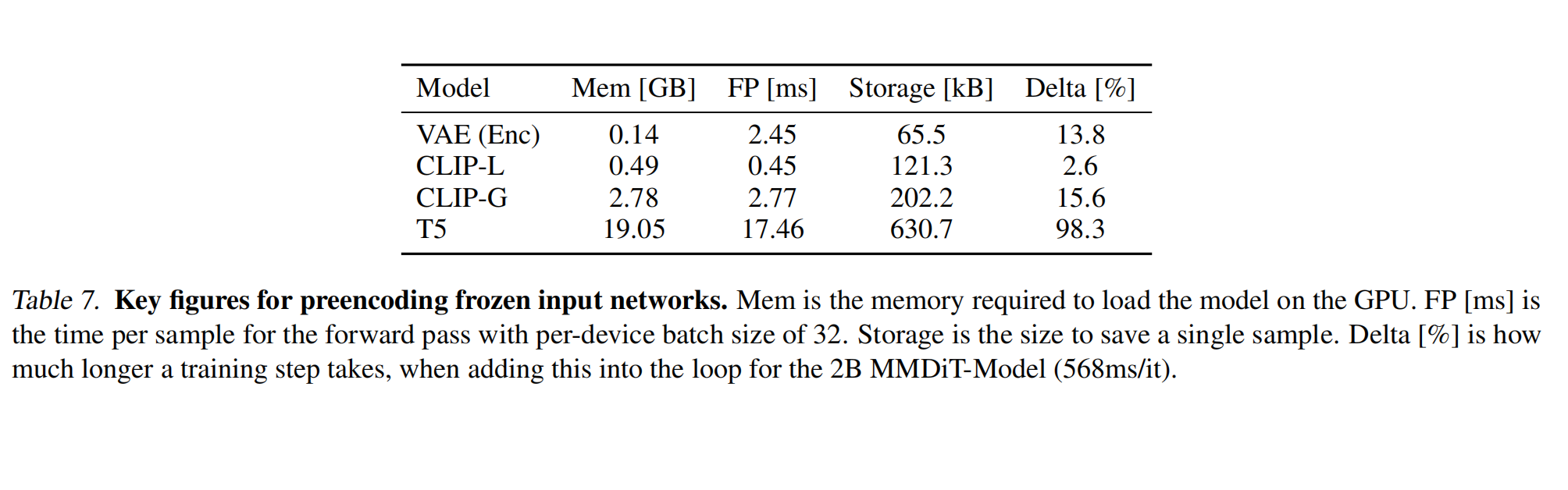
为了减少训练过程中SD 3所需显存和特征处理耗时,SD 3设计了图像特征和文本特征的预计算策略:由于VAE、CLIP-L、CLIP-G、T5-XXL都是预训练好且在SD 3微调过程中权重被冻结的结构,所以在训练前可以将整个数据集预计算一次图像的Latent特征和文本的Text Embeddings,并将这些特征缓存下来,这样在整个SD 3的训练过程中就无需再次计算。同时上述冻结的模型参数也无需加载到显卡中,可以节省约20GB的显存占用。
但是根据机器学习领域经典的“没有免费的午餐”定理,预计算策略虽然为我们大幅减少了SD 3的训练成本,但是也存在其他方面的代价。第一点是训练数据不能在训练过程中做数据增强了,所有的数据增强操作都要在训练前预处理好。第二点是预处理好的图像特征和文本特征需要一定的存储空间。第三点是训练时加载这些预处理好的特征需要一定的时间。
整体上看,其实SD 3的预计算策略是一个空间换时间的技术。
【二】什么是人脸解析(Face Parsing)任务?
人脸解析是一种精细化的计算机视觉任务,旨在将人脸区域划分为多个语义部分,如皮肤、眼睛、嘴唇、鼻子、眉毛、头发等。与人脸检测和人脸识别不同,人脸解析的目标是为人脸提供像素级的语义分割。这种任务广泛应用于AIGC时代,在美颜、虚拟化妆、换脸、AR/VR 和表情分析等领域都有重要价值。
1. 人脸解析的输入与输出
- 输入:
- 一张包含人脸的 RGB 图像。
- 输出:
- 一张语义分割的图(mask),每个像素值代表对应区域的类别(例如 0 表示背景,1 表示皮肤,2 表示左眼,3 表示右眼等等)。
2. 人脸解析任务的原理
人脸解析的原理主要基于语义分割技术。具体步骤如下:
2.1 预处理阶段
1. 数据收集和标注
- 人脸解析需要有大量已标注的人脸语义分割数据集。
- 数据集中每张图像都有对应的语义分割标签,标签以 mask 的形式存储,每个像素的值对应该像素所属的类别。
- 例如,
0=背景,1=皮肤,2=眼睛,3=嘴巴, 等。
- 例如,
2. 数据增强
- 数据增强可以提高模型的泛化能力,特别是当数据量不足时。
- 常用方法包括:旋转、缩放、剪切、亮度调整、色调变化、镜像翻转等。
3. 人脸检测和对齐
- 为了专注于人脸区域,通常会在训练和推理过程中使用人脸检测器(如 MTCNN 或 RetinaFace)检测并裁剪出人脸区域。
- 人脸对齐确保人脸的关键部分(如眼睛和嘴巴)出现在一致的位置,从而简化模型学习。
2.2 模型架构
人脸解析模型一般基于语义分割网络构建,以下是常用的网络架构:
1. 基础网络
- Fully Convolutional Network (FCN): 最早的语义分割架构,用全卷积层代替全连接层,实现像素级预测。
- U-Net: 通过编码器-解码器架构,结合特征提取与逐步上采样,适合小型数据集。
2. 现代深度学习模型
- DeepLab系列 (DeepLabv3/DeepLabv3+):
- 基于 Atrous Convolution(空洞卷积),能够捕捉多尺度上下文信息。
- 使用 ASPP(空洞空间金字塔池化)模块增强上下文感知能力。
- HRNet(High-Resolution Network):
- 通过多分辨率特征融合保持高分辨率的预测,适合精细分割任务。
- BiSeNet(Bilateral Segmentation Network):
- 专为实时语义分割设计,通过空间路径和上下文路径结合,实现高效分割。
3. 模型输出
- 最终输出是一个大小与输入图像相同的张量,每个像素点的值是一个分类概率分布(通过 Softmax 得到)。
- 最高概率的类别即为该像素的预测类别。
2.3 损失函数
为了优化模型性能,需要选择合适的损失函数:
- 交叉熵损失(Cross-Entropy Loss):
- 计算每个像素预测类别与真实类别之间的交叉熵。
- 加权交叉熵(Weighted Cross-Entropy Loss):
- 用于处理类别不平衡(例如,背景像素远多于其他类别)。
- Dice Loss:
- 用于提高小区域的分割性能(例如眼睛、嘴唇等小部分)。
- 混合损失(Hybrid Loss):
- 结合交叉熵和 Dice 损失,兼顾全局准确性与局部细节。
2.4 后处理阶段
1. 平滑与细化
- 使用条件随机场(CRF)或边缘增强滤波器对分割结果进行平滑,消除噪点。
2. 多尺度融合
- 在不同分辨率下处理图像并融合结果,提高分割的鲁棒性。
3. 类别映射
- 将模型输出的类别值映射为可视化的颜色图,便于人类理解和观察。
3. 常见挑战
-
复杂背景干扰:
- 如果背景和人脸部分的颜色或纹理相似,可能导致误分类。
- 解决方法:添加更多包含复杂背景的数据并增强背景信息。
-
类别不平衡:
- 一些区域(如眼睛和嘴唇)占图像面积的比例较小,可能被忽视。
- 解决方法:使用加权损失或通过数据增强平衡样本。
-
细节区域的分割:
- 对于眉毛、嘴唇等精细区域的分割难度较大。
- 解决方法:使用更高分辨率的模型(如 HRNet)。
-
实时性与性能权衡:
- 部分模型(如 DeepLab)虽然精度高,但推理速度较慢。
- 解决方法:选择轻量级模型(如 BiSeNet)。
4. 应用场景
-
美颜与虚拟化妆:
- 分割出皮肤、眼睛、嘴唇等区域,用于平滑皮肤、调整颜色等。
-
人脸替换(换脸):
- 精确地分割面部区域,方便合成其他脸部特征。
-
表情分析:
- 分析嘴唇、眼睛等区域的形状变化,用于表情识别或情感分析。
-
增强现实(AR):
- 在人脸上叠加虚拟元素(如面具、装饰)。
AI视频基础
【一】介绍一下HunyuanVideo模型的架构
HunyuanVideo是一个基于Latent空间的AI视频扩散模型。它设计了一个3D VAE架构,用于在训练中压缩时间维度和空间维度的特征。同时通过一个大语言模型来对文本Prompts进行编码,作为额外条件输入模型中,来引导模型通过对高斯噪声的多步去噪,输出一个AI视频的Latent空间表示。最后,在HunyuanVideo推理时通过3D VAE解码器将Latent空间表示解码为AI视频。
下面是HunyuanVideo模型架构的示意图:

【二】HunyuanVideo模型有哪些特点?
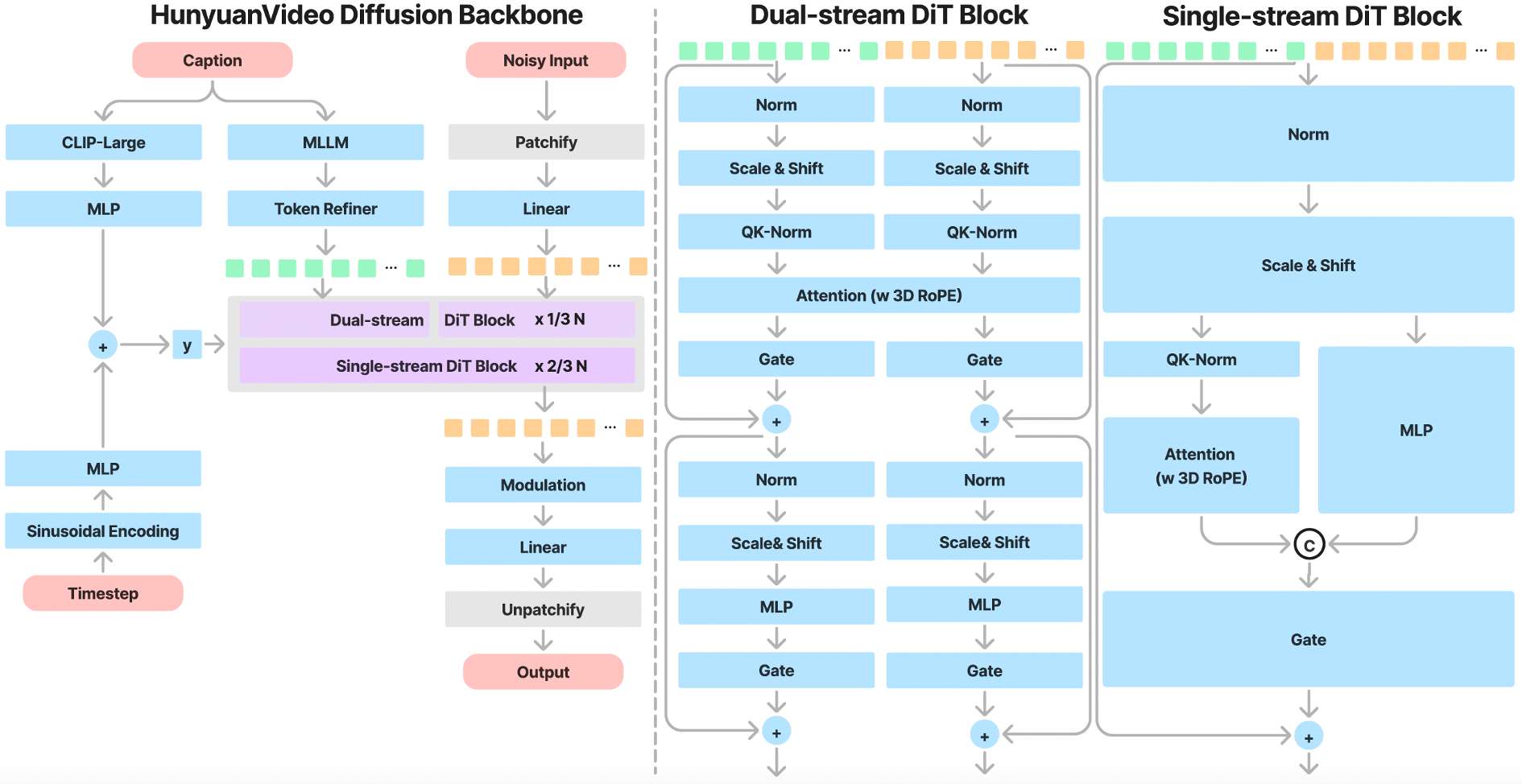
单-双流TransFormer架构
HunyuanVideo模型采用了Transformer架构,设计了一个“双流到单流”的混合模型用于视频生成。在双流阶段,视频特征和文本token通过并行的Transformer Block独立处理,使得每个模态可以学习适合自己的调制机制而不会相互干扰。在单流阶段,再将视频特征和文本token连接起来并将它们输入到后续的Transformer Block中进行有效的多模态信息融合。这种设计和FLUX.1这个AI绘画大模型有异曲同工之妙,捕捉了视觉和语义信息之间的复杂交互,增强了整体模型性能。
下面是HunyuanVideo模型的单-双流TransFormer架构示意图:
使用MLLM文本编码器
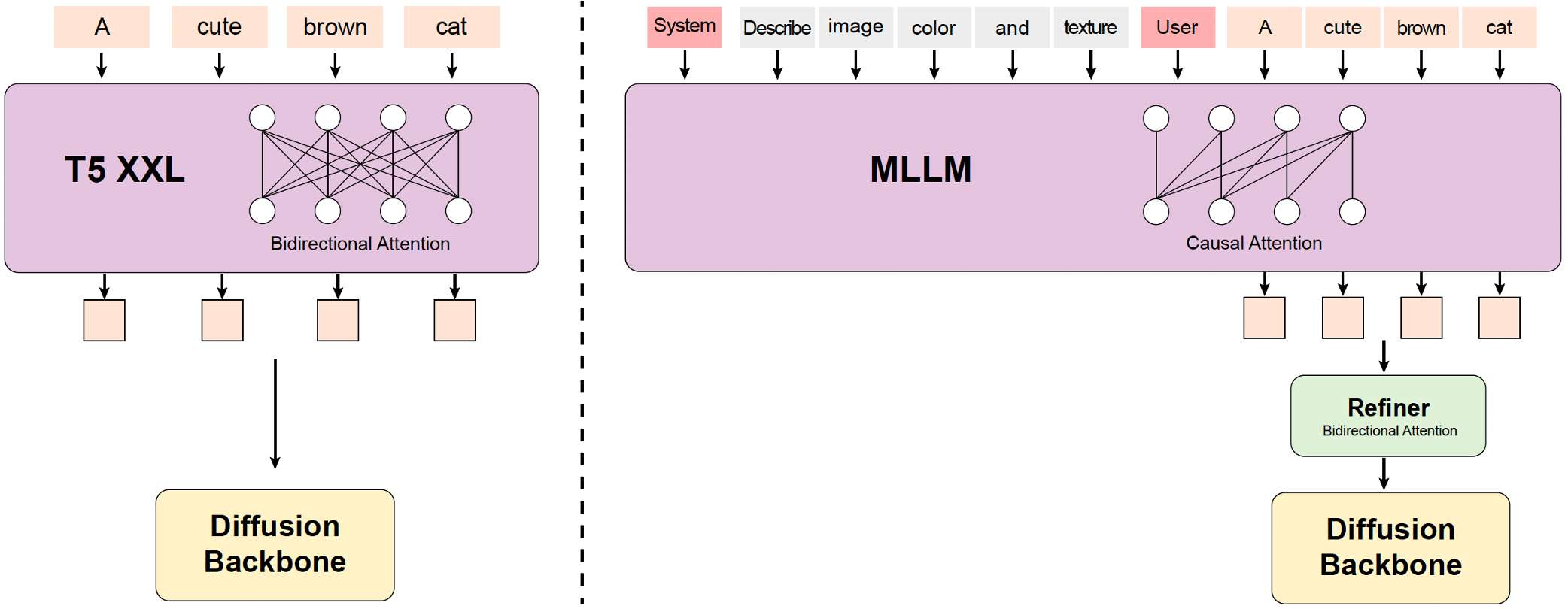
之前的AI视频大模型通常使用预训练的CLIP和T5-XXL作为文本编码器。而HunyuanVideo则是使用了一个预训练的Multimodal Large Language Model (MLLM)作为文本编码器,其具有以下优势:
- 与T5-XXL相比,MLLM模型基于图文数据指令微调后在特征空间中具有更好的图像-文本对齐能力,这就减轻了扩散模型中的图文特征对齐的难度。
- 与CLIP相比,MLLM模型在图像的细节描述和复杂推理方面表现出更强的能力。
- MLLM模型可以通过遵循系统指令实现零样本生成,从而帮助文本特征更多地关注关键信息。
- 由于MLL模型是基于Causal Attention机制的,而T5-XXL使用了Bidirectional Attention机制为扩散模型提供更好的文本引导。因此,HunyuanVideo引入了一个额外的token优化器来增强文本特征的引导。
下面是HunyuanVideo模型中MLLM文本编码器的示意图:
设计了3D VAE
HunyuanVideo的VAE部分采用了CausalConv3D作为AI视频的编码器和解码器,用于压缩视频的时间维度和空间维度,其中时间维度压缩 4 倍,空间维度压缩 8 倍,压缩为 16 channels。这样可以显著减少后续 Transformer 模型的 token 数量,使我们能够在原始分辨率和帧率下训练AI视频大模型。
下面是HunyuanVideo的3D VAE部分的示意图:

对输入Prompt进行改写
为了解决用户输入文本提示的多样性和不一致性的困难,官方微调了Hunyuan-Large model模型作为HunyuanVideo的prompt改写模型,将用户输入的提示词改写为更适合HunyuanVideo模型偏好的写法。
Hunyuan-Large model模型提供了两个改写模式:正常模式和导演模式。正常模式旨在增强视频生成模型对用户意图的理解,从而更准确地解释提供的指令。导演模式增强了诸如构图、光照和摄像机移动等方面的描述,倾向于生成视觉质量更高的视频。注意,这种增强有时可能会导致一些语义细节的丢失。
深度学习基础
【一】AI模型的池化层包含可学习参数吗?
AI模型的池化层(Pooling Layer)不包含可学习的参数。
池化层的作用
池化层的主要功能是对输入特征图进行下采样,减小特征图的尺寸,降低计算复杂度,同时保留重要的特征信息。常见的池化操作包括:
- 最大池化(Max Pooling):取池化窗口中的最大值。
- 平均池化(Average Pooling):计算池化窗口中的平均值。
池化层不包含参数的原因
-
池化层没有权重或偏置参数:
- 与卷积层或全连接层不同,池化层的操作只是固定规则的计算(如取最大值或平均值),不需要学习任何权重或偏置。
- 例如:
- 最大池化:在窗口内取最大值,不涉及任何可学习的参数。
- 平均池化:在窗口内取平均值,同样不需要参数。
-
仅依赖于池化窗口大小和步幅:
- 池化层的行为由超参数决定,如:
- 池化窗口大小(如 2 × 2 2 \times 2 2×2 )
- 步幅(Stride):窗口移动的步长
- 这些超参数是固定的,不需要通过训练学习。
- 池化层的行为由超参数决定,如:
池化层的参数总结
| 层类型 | 是否包含参数 | 说明 |
|---|---|---|
| 卷积层(Conv) | ✅ 是 | 权重(Kernel)和偏置(Bias) |
| 全连接层(FC) | ✅ 是 | 权重矩阵和偏置向量 |
| 最大池化层(Max Pooling) | ❌ 否 | 固定规则:取最大值 |
| 平均池化层(Avg Pooling) | ❌ 否 | 固定规则:取平均值 |
| Dropout 层 | ❌ 否 | 用于随机丢弃神经元,无参数 |
| 批归一化(BatchNorm) | ✅ 是 | 包含可学习的缩放和平移参数 |
【二】如何设置随机种子让AI模型的推理结果可以复现?
为了让AI模型的推理结果可以复现,需要设置随机种子来控制随机过程的行为。
- 设置随机种子是确保 AI 模型推理结果可复现的关键步骤,能够控制所有随机性来源。
- 在 PyTorch、TensorFlow 等框架中,可以通过设置随机种子、固定随机数生成器的状态来保证一致性。
- 对于分布式环境或 GPU 推理,需要额外注意 GPU 随机性的控制。
- 在AIGC模型或需要用户控制结果的场景中,暴露随机种子作为参数是一个常见AI产品做法。
1. PyTorch 中设置随机种子
PyTorch 提供了多个方法来设置随机种子,以控制随机性来源。
关键来源
- CPU 随机性:
torch.manual_seed(seed) - GPU 随机性:
torch.cuda.manual_seed(seed)和torch.cuda.manual_seed_all(seed) - NumPy 随机性:
np.random.seed(seed) - Python 随机性:
random.seed(seed)
完整代码示例
import torch
import numpy as np
import random
def set_seed(seed):
torch.manual_seed(seed) # 控制 PyTorch 的随机性
torch.cuda.manual_seed(seed) # 控制单个 GPU 的随机性
torch.cuda.manual_seed_all(seed) # 控制所有 GPU 的随机性(如果使用多 GPU)
np.random.seed(seed) # 控制 NumPy 的随机性
random.seed(seed) # 控制 Python 的随机性
torch.backends.cudnn.deterministic = True # 确保计算结果的确定性
torch.backends.cudnn.benchmark = False # 禁用动态优化(可能会降低性能)
# 示例:设置随机种子
set_seed(1024)
# 加载模型并进行推理
model = torch.load("WeThinkIn.pth")
model.eval()
# 输入数据
input_data = torch.randn(1, 3, 224, 224) # 示例输入
output = model(input_data) # 推理
print(output)
注意事项
-
CuDNN 性能优化:
- 设置
torch.backends.cudnn.deterministic = True会确保结果的一致性,但可能会牺牲性能。 - 如果对性能要求较高,可不设置该参数,但推理结果可能不完全可复现。
- 设置
-
分布式环境:
- 如果使用分布式训练或推理,还需要在各节点上设置相同的随机种子。
2. NumPy 随机性控制
如果模型依赖 NumPy 的随机性,可以单独控制 NumPy 的随机种子。
示例
import numpy as np
# 设置随机种子
np.random.seed(1024)
# 生成随机数
random_numbers = np.random.rand(5)
print(random_numbers)
3. Scikit-learn 中设置随机种子
Scikit-learn 中许多算法(如 K-Means、Random Forest 等)依赖随机性,可以通过设置 random_state 参数来控制随机性。
示例
from sklearn.cluster import KMeans
# 设置随机种子
kmeans = KMeans(n_clusters=3, random_state=42)
kmeans.fit(data)
4. AIGC通用场景:提供随机种子作为参数
在AIGC模型(如 GPT、DALL-E、Stable Diffusion、Midjourney)中,可以通过显式提供随机种子来控制生成结果。
机器学习基础
【一】介绍一下机器学习中的SVD(Singular Value Decomposition)技术
SVD(Singular Value Decomposition,奇异值分解) 是一种常用的矩阵分解技术,在AIGC、传统深度学习以及自动驾驶中都有广泛的应用。SVD 提供了一种将一个矩阵分解成多个分量的方法,有助于数据降维、特征提取、数据去噪、AI模型轻量化等任务。
1. SVD 的数学原理
对于一个任意矩阵 A A A (大小为 m × n m \times n m×n ),SVD 将其分解为三个矩阵的乘积:
A = U Σ V T A = U \Sigma V^T A=UΣVT
其中:
- U U U (大小 m × m m \times m m×m ):左奇异向量矩阵,列向量是 A A T A A^T AAT 的特征向量。
- Σ \Sigma Σ (大小 m × n m \times n m×n ):对角矩阵,包含 A A A 的奇异值,按降序排列。奇异值是 A A A 的特征值的平方根。
- V T V^T VT (大小 n × n n \times n n×n ):右奇异向量矩阵,行向量是 A T A A^T A ATA 的特征向量的转置。
几何解释:
- SVD 将一个矩阵 A A A 分解成三个部分:先通过 V V V 进行旋转,再通过 Σ \Sigma Σ 进行缩放,最后通过 U U U 进行另一个旋转。
- Σ \Sigma Σ 中的奇异值反映了矩阵 A A A 在不同方向上的重要性。
2. SVD 的应用场景
2.1 数据降维与 PCA
- PCA(主成分分析):PCA 可以通过 SVD 实现,它将高维数据映射到一个低维空间,同时保留尽可能多的数据方差。
- 方法:
- 对数据矩阵 A A A 进行中心化处理(减去均值)。
- 对中心化矩阵执行 SVD 分解 A = U Σ V T A = U \Sigma V^T A=UΣVT 。
- 选取 Σ \Sigma Σ 中最大的 k k k 个奇异值及对应的 U U U 和 V V V 向量,得到降维后的数据。
2.2 推荐系统
- 在推荐系统中,用户-物品评分矩阵通常是稀疏的。SVD 可以分解评分矩阵,提取出用户和物品的隐含特征表示。
- 步骤:
- 对评分矩阵 R R R 进行 SVD 分解。
- 使用分解后的矩阵 U U U , Σ \Sigma Σ , V T V^T VT 预测缺失的评分。
优势:SVD 可以有效提取用户和物品的特征,解决稀疏矩阵的问题。
2.3 去噪与数据压缩
- 图像去噪:SVD 可用于图像的压缩和去噪,通过保留主要的奇异值,丢弃次要的奇异值,实现信息的压缩和噪声的滤除。
- 原理:
- 图像通常被表示为矩阵形式,通过 SVD 分解后,保留前 k k k 个奇异值及对应向量,重构近似图像。
- 较小的奇异值通常对应噪声。
2.4 解决线性系统与伪逆计算
- SVD 可以用于求解奇异或非方矩阵的线性系统。
- 矩阵伪逆:
- 对矩阵
A
A
A 的伪逆可以通过 SVD 求解:
A + = V Σ + U T A^+ = V \Sigma^+ U^T A+=VΣ+UT
其中 $\Sigma^+ $ 是 Σ \Sigma Σ 的伪逆。
- 对矩阵
A
A
A 的伪逆可以通过 SVD 求解:
3. SVD 的优点与缺点
优点:
- 适用性广:适用于任意形状的矩阵(非方矩阵也适用)。
- 数值稳定性:SVD 是一种数值稳定的分解方法。
- 特征提取:可用于数据降维、压缩、去噪等任务。
- 适用于稀疏矩阵:在推荐系统等任务中表现优秀。
缺点:
- 计算复杂度高:SVD 的时间复杂度为 O ( n 3 ) O(n^3) O(n3) (对于 n × n n \times n n×n 的矩阵),在大规模数据上计算成本较高。
- 不易解释:分解后的奇异值和奇异向量可能缺乏直观的物理意义。
4. SVD 与其他分解方法的对比
| 分解方法 | 适用矩阵类型 | 主要应用 | 是否适用于降维 |
|---|---|---|---|
| SVD | 任意矩阵 | 降维、去噪、推荐系统 | 是 |
| PCA | 数据协方差矩阵 | 主成分分析、特征提取 | 是(基于 SVD) |
| LU 分解 | 方阵 | 线性方程求解 | 否 |
| QR 分解 | 方阵 | 正交化与回归分析 | 否 |
| Eigen 分解 | 方阵,且对称正定 | 计算特征值、特征向量 | 否 |
【二】介绍一下机器学习中的聚类算法原理
什么是聚类?
- 聚类是一种无监督学习技术,它的目标是将数据集划分为若干个组(簇,clusters),使得:
- 同一簇中的数据点彼此之间的相似度尽可能高。
- 不同簇之间的数据点相似度尽可能低。
- 聚类广泛应用于AIGC、传统深度学习以及自动驾驶等AI核心领域。
聚类算法的主要类别
根据聚类方法的不同,可以将聚类算法分为以下几类:
- 划分式聚类(Partitioning Clustering)
- 层次聚类(Hierarchical Clustering)
- 基于密度的聚类(Density-Based Clustering)
- 基于网格的聚类(Grid-Based Clustering)
- 基于模型的聚类(Model-Based Clustering)
下面Rocky详细介绍每种类别的代表算法。
1. 划分式聚类
概念
- 将数据集划分为 K K K 个簇,直接对簇进行优化。
- 每个簇由一个中心点(质心)表示,数据点根据距离最近的质心分配到对应的簇。
代表算法:K-Means
-
K-Means 是最常用的划分式聚类算法。
-
工作原理:
- 随机选择 K K K 个点作为初始质心。
- 将每个数据点分配到最近的质心。
- 重新计算每个簇的质心。
- 重复步骤 2 和 3,直到质心不再变化或达到最大迭代次数。
-
优点:
- 简单易实现。
- 计算效率高,适合大规模数据。
-
缺点:
- 需要预先指定 K K K 。
- 对初始值敏感,容易陷入局部最优。
- 不能处理非球形数据和不同大小的簇。
-
改进算法:
- K-Means++:改进初始化步骤,使质心的选择更加合理。
- MiniBatch K-Means:用于大规模数据集,采用小批量数据优化。
2. 层次聚类
概念
- 通过构建层次树状结构(dendrogram)实现聚类。
- 可以分为两种方法:
- 凝聚层次聚类(Agglomerative Clustering):
- 自底向上,每个数据点开始是一个单独的簇,逐步合并簇。
- 分裂层次聚类(Divisive Clustering):
- 自顶向下,所有数据点开始是一个大簇,逐步分裂成多个簇。
- 凝聚层次聚类(Agglomerative Clustering):
代表算法:凝聚层次聚类
-
步骤:
- 计算所有数据点之间的距离矩阵。
- 找到最近的两个簇,合并它们。
- 更新距离矩阵。
- 重复步骤 2 和 3,直到所有数据点合并为一个簇或达到停止条件。
-
链接方法(距离度量方式):
- 单链(Single Linkage):两簇中最近的数据点之间的距离。
- 全链(Complete Linkage):两簇中最远的数据点之间的距离。
- 平均链(Average Linkage):两簇之间所有点的平均距离。
-
优点:
- 不需要预定义簇的数量。
- 适合小数据集,能够生成数据的层次结构。
-
缺点:
- 计算复杂度较高,无法处理大规模数据。
- 对噪声和异常值敏感。
3. 基于密度的聚类
概念
- 通过数据点的密度来定义簇,高密度区域的点归为一个簇,低密度区域被认为是噪声或边界点。
代表算法:DBSCAN
-
工作原理:
- 选择一个点,确定其 ϵ \epsilon ϵ -邻域内的点。
- 如果邻域内的点数大于某个阈值(MinPts),则将这些点归为一个簇。
- 对邻域内的点重复步骤 2,直到没有新的点可以加入。
- 标记低密度区域的点为噪声点。
-
优点:
- 能够自动确定簇的数量。
- 能处理任意形状的簇。
- 对噪声点具有鲁棒性。
-
缺点:
- 对 ϵ \epsilon ϵ 和 MinPts 参数敏感。
- 在高维数据中效果较差。
改进算法
- HDBSCAN:
- 在 DBSCAN 基础上,自动选择合适的密度阈值,适合更多场景。
4. 基于网格的聚类
概念
- 将数据空间划分为固定大小的网格单元,每个单元根据数据密度分配到簇。
代表算法:CLIQUE
-
工作原理:
- 将数据划分为固定网格。
- 识别高密度网格单元。
- 将相邻的高密度单元合并为一个簇。
-
优点:
- 高效,适合大规模数据。
- 对高维数据有效。
-
缺点:
- 依赖网格划分的大小。
- 可能丢失簇的边界细节。
5. 基于模型的聚类
概念
- 通过假设数据点服从某种分布(例如高斯分布),用概率模型来拟合数据。
代表算法:GMM(Gaussian Mixture Model)
-
工作原理:
- 假设数据点服从多个高斯分布。
- 使用期望最大化算法(EM)优化每个高斯分布的参数(均值、协方差)。
- 根据每个数据点属于各高斯分布的概率分配簇。
-
优点:
- 能够生成概率输出,适合软聚类。
- 能处理不同形状和大小的簇。
-
缺点:
- 对初始值敏感。
- 计算复杂度较高。
聚类算法比较
| 算法 | 适用场景 | 优点 | 缺点 |
|---|---|---|---|
| K-Means | 球形数据、规模较大的数据集 | 简单高效,易实现 | 对初始值敏感,无法处理非球形簇 |
| 层次聚类 | 小规模数据、生成层次结构 | 不需要预定义簇数量,结果直观 | 计算复杂度高,敏感于噪声 |
| DBSCAN | 任意形状的簇,含噪声的数据 | 自动确定簇数,对噪声鲁棒 | 参数敏感,高维数据效果差 |
| GMM | 不同形状和大小的簇 | 能处理软聚类,适合概率建模 | 对初始值敏感,计算复杂度高 |
| CLIQUE | 大规模高维数据 | 高效,适合网格划分的场景 | 依赖网格划分,可能丢失细节 |
如何选择聚类算法?
-
数据规模:
- 小数据集:层次聚类。
- 大规模数据集:K-Means 或 DBSCAN。
-
数据分布:
- 球形数据:K-Means。
- 非球形数据:DBSCAN 或 GMM。
-
是否包含噪声:
- 包含噪声:DBSCAN。
- 不包含噪声:K-Means 或层次聚类。
-
结果要求:
- 精确分组:GMM。
- 快速近似:K-Means。
Python编程基础
【一】在AI服务中,python如何加载我们想要指定的库?
在 AI 服务中,有时需要动态加载指定路径下的库或模块,特别是当需要使用自定义库或者避免与其他版本的库冲突时。Python 提供了多种方法来实现这一目标。
1. 使用 sys.path 动态添加路径
通过将目标库的路径添加到 sys.path,Python 可以在该路径下搜索库并加载。
代码示例
import sys
import os
# 指定库所在的路径
custom_library_path = "/path/to/your/library"
# 将路径加入到 sys.path
if custom_library_path not in sys.path:
sys.path.insert(0, custom_library_path) # 插入到 sys.path 的最前面
# 导入目标库
import your_library
# 使用库中的功能
your_library.some_function()
注意事项
- 如果路径中已经存在版本冲突的库,Python 会优先加载
sys.path中靠前的路径。 - 使用
os.path.abspath()确保提供的是绝对路径。
2. 使用 importlib 动态加载模块
importlib 是 Python 提供的模块,用于动态加载库或模块。
代码示例
import importlib.util
# 指定库文件路径
library_path = "/path/to/your/library/your_library.py"
# 加载模块
spec = importlib.util.spec_from_file_location("your_library", library_path)
your_library = importlib.util.module_from_spec(spec)
spec.loader.exec_module(your_library)
# 使用库中的功能
your_library.some_function()
适用场景
- 当库是一个单独的 Python 文件时,可以使用
importlib动态加载该文件。
3. 设置环境变量 PYTHONPATH
通过设置 PYTHONPATH 环境变量,可以让 Python 自动搜索指定路径下的库。
方法 1:在脚本中动态设置
import os
import sys
# 指定路径
custom_library_path = "/path/to/your/library"
# 动态设置 PYTHONPATH 环境变量
os.environ["PYTHONPATH"] = os.environ.get("PYTHONPATH", "") + ":" + custom_library_path
# 添加到 sys.path
if custom_library_path not in sys.path:
sys.path.append(custom_library_path)
# 导入库
import your_library
方法 2:通过命令行设置
export PYTHONPATH=$PYTHONPATH:/path/to/your/library
python your_script.py
适用场景
- 当需要全局添加路径时,
PYTHONPATH是更方便的方式。
4. 使用 .pth 文件
在 Python 的 site-packages 目录中创建一个 .pth 文件,指定库路径。Python 启动时会自动加载该路径。
步骤
- 找到
site-packages目录:python -m site - 创建
.pth文件:echo "/path/to/your/library" > /path/to/site-packages/custom_library.pth
注意
.pth文件适合用来加载多个库路径,适用于环境配置管理。
5. 加载本地开发库(开发模式安装)
如果需要加载本地开发的库,可以使用 pip install -e 安装为开发模式。
步骤
- 将库代码放到一个目录,例如
/path/to/your/library。 - 进入该目录,运行以下命令:
pip install -e . - Python 会将该库路径注册到系统中,以后可以直接通过
import使用该库。
总结
| 方法 | 适用场景 | 灵活性 | 推荐程度 |
|---|---|---|---|
sys.path 动态加载 | 临时加载单个路径 | 高 | 高 |
importlib 动态加载 | 动态加载单个模块文件 | 中 | 高 |
PYTHONPATH 环境变量 | 全局路径管理 | 中 | 中 |
.pth 文件 | 多路径永久加载 | 中 | 高 |
| 开发模式安装 | 开发环境的库调试或动态加载 | 高 | 高 |
【二】Python中None代表什么含义?
在 Python 中,None 是一个特殊的常量,表示 “没有值” 或 “空值” 。它通常用来表示以下几种场景:
- 一个函数没有显式返回值。
- 一个变量的值尚未被定义。
- 用来表示某种占位符意义的“无”值。
通过合理使用 None,可以提高代码的可读性和鲁棒性。
1. None 是什么?
核心概念
None是一个对象:None是 Python 的内建常量,属于NoneType类型。- 唯一性:在整个程序运行中,
None是全局唯一的对象。 - 不可变性:
None是不可变的,不能修改其值。
代码示例
print(type(None)) # 输出: <class 'NoneType'>
# 比较 `None` 的唯一性
a = None
b = None
print(a is b) # 输出: True (a 和 b 指向同一个 None 对象)
2. None 的常见用法
用法 1:函数无返回值时默认返回 None
- 如果一个函数没有显式
return语句,或return不带值,则该函数默认返回None。
代码示例
def no_return_function():
pass
result = no_return_function()
print(result) # 输出: None
用法 2:表示空值或占位符
- 当一个变量还没有赋予实际的值时,可以用
None表示占位。 - 它在对象初始化或默认参数设置中非常常见。
代码示例
value = None # 表示暂时没有赋值
print(value) # 输出: None
用法 3:函数的默认参数
- 如果函数参数不传递值,可以用
None作为默认值,然后在函数中检测是否需要提供替代值。
代码示例
def process_data(data=None):
if data is None:
data = [] # 如果没有提供 data,初始化为空列表
print(data)
process_data() # 输出: []
process_data([1, 2]) # 输出: [1, 2]
用法 4:表示操作失败或无效
- 在处理异常、查找或数据库查询中,
None可以用来表示未找到结果或操作失败。
代码示例
def find_item(items, target):
for item in items:
if item == target:
return item
return None # 未找到目标,返回 None
result = find_item([1, 2, 3], 4)
print(result) # 输出: None
用法 5:终止循环或递归
- 在递归或循环中,可以用
None来标记终止条件。
代码示例
def countdown(n):
if n == 0:
return None # 递归终止
print(n)
countdown(n - 1)
countdown(5) # 输出: 5, 4, 3, 2, 1
3. 判断 None 的方法
- 判断一个变量是否是
None应使用is运算符,而不是==。 - 原因:
None是一个单例对象,is判断的是两个对象是否是同一个对象,而==判断的是值是否相等。
代码示例
a = None
# 正确判断
if a is None:
print("a 是 None")
# 不推荐,但可行
if a == None:
print("a 等于 None")
4. None 的特性
(1) None 不能用于算术操作
None不能像数字一样参与算术运算。
示例
a = None
# print(a + 1) # 会报错: TypeError: unsupported operand type(s)
(2) None 是假值
- 在布尔上下文中(如条件判断),
None被视为False。
代码示例
a = None
if not a:
print("a 是假值") # 输出: a 是假值
5. None 与其他类型的关系
(1) None 与空字符串、空列表的区别
None表示没有值,而空字符串""和空列表[]表示值是空。
代码示例
a = None
b = ""
c = []
print(a == b) # 输出: False
print(a == c) # 输出: False
print(bool(a), bool(b), bool(c)) # 输出: False, False, False
(2) None 与 False 的区别
None和False都在布尔上下文中表示假,但它们的类型不同。
代码示例
a = None
b = False
print(a == b) # 输出: False
print(type(a), type(b)) # 输出: <class 'NoneType'> <class 'bool'>
模型部署基础
【一】AI模型的参数量如何计算?
不管是AIGC、传统深度学习还是自动驾驶领域,计算 AI 模型的参数量(参数个数)是评估模型复杂度的常用指标。参数量指的是 模型中所有可学习参数(权重和偏置) 的数量。Rocky总结了通用AI模型参数量计算方法,在不同类型的神经网络中,计算参数量的方法略有不同。下面是详细的计算方法:
不同类型神经网络参数量的计算方法:
- 全连接层:输入特征数 × 输出特征数 + 输出特征数。
- 卷积层:卷积核高度 × 卷积核宽度 × 输入通道数 × 输出通道数 + 输出通道数。
- 循环神经网络:需要考虑输入、隐藏单元和门结构。
- Transformer 模型:关注多头自注意力机制和前馈网络。
1. 计算神经网络的参数量的基本原则
- 权重参数:每一层的神经元与下一层的神经元之间的连接权重。
- 偏置参数:每个神经元(节点)对应的偏置值(bias)。
一般公式为:
参数量 = 输入特征数 × 输出特征数 + 输出特征数 \text{参数量} = \text{输入特征数} \times \text{输出特征数} + \text{输出特征数} 参数量=输入特征数×输出特征数+输出特征数
其中:
- 输入特征数:上一层的输出通道或神经元数。
- 输出特征数:当前层的通道或神经元数。
- ( + \text{输出特征数} ):是因为每个输出单元都有一个对应的偏置参数。
2. 不同类型网络的参数量计算
2.1 全连接层(Fully Connected Layer)
全连接层的参数量由输入和输出的神经元数决定。
公式:
参数量 = 输入特征数 × 输出特征数 + 输出特征数 \text{参数量} = \text{输入特征数} \times \text{输出特征数} + \text{输出特征数} 参数量=输入特征数×输出特征数+输出特征数
示例:假设输入特征为 512,输出特征为 256。
参数量 = 512 × 256 + 256 = 131328 \text{参数量} = 512 \times 256 + 256 = 131328 参数量=512×256+256=131328
2.2 卷积层(Convolutional Layer)
卷积层的参数量取决于卷积核的大小、输入通道数和输出通道数。
公式:
参数量 = ( 卷积核高度 × 卷积核宽度 × 输入通道数 + 1 ) × 输出通道数 \text{参数量} = (\text{卷积核高度} \times \text{卷积核宽度} \times \text{输入通道数} + 1) \times \text{输出通道数} 参数量=(卷积核高度×卷积核宽度×输入通道数+1)×输出通道数
- 卷积核高度 × 卷积核宽度:卷积核的尺寸,例如 3 × 3 3 \times 3 3×3 。
- 输入通道数:前一层的特征图通道数。
- 输出通道数:当前层的特征图通道数。
- +1:表示偏置参数。
示例:输入通道数为 3,输出通道数为 64,卷积核大小为 3 × 3 3 \times 3 3×3 。
参数量 = ( 3 × 3 × 3 + 1 ) × 64 = ( 27 + 1 ) × 64 = 1792 \text{参数量} = (3 \times 3 \times 3 + 1) \times 64 = (27 + 1) \times 64 = 1792 参数量=(3×3×3+1)×64=(27+1)×64=1792
2.3 循环神经网络(RNN, LSTM, GRU 等)
循环神经网络的参数量与输入特征、隐藏单元数和门控结构有关。
-
RNN:
参数量 = 输入特征数 × 隐藏单元数 + 隐藏单元数 × 隐藏单元数 + 隐藏单元数 \text{参数量} = \text{输入特征数} \times \text{隐藏单元数} + \text{隐藏单元数} \times \text{隐藏单元数} + \text{隐藏单元数} 参数量=输入特征数×隐藏单元数+隐藏单元数×隐藏单元数+隐藏单元数
-
LSTM/GRU(由于有多个门结构):
参数量 = 4 × ( 输入特征数 × 隐藏单元数 + 隐藏单元数 × 隐藏单元数 + 隐藏单元数 ) \text{参数量} = 4 \times \left( \text{输入特征数} \times \text{隐藏单元数} + \text{隐藏单元数} \times \text{隐藏单元数} + \text{隐藏单元数} \right) 参数量=4×(输入特征数×隐藏单元数+隐藏单元数×隐藏单元数+隐藏单元数)
示例:输入特征数为 128,隐藏单元数为 256。
-
对于 RNN:
参数量 = 128 × 256 + 256 × 256 + 256 = 98304 + 65536 + 256 = 164096 \text{参数量} = 128 \times 256 + 256 \times 256 + 256 = 98304 + 65536 + 256 = 164096 参数量=128×256+256×256+256=98304+65536+256=164096
-
对于 LSTM:
参数量 = 4 × ( 128 × 256 + 256 × 256 + 256 ) = 4 × 164096 = 656384 \text{参数量} = 4 \times (128 \times 256 + 256 \times 256 + 256) = 4 \times 164096 = 656384 参数量=4×(128×256+256×256+256)=4×164096=656384
2.4 Transformer 模型
Transformer 由多个自注意力机制(Multi-Head Attention) 和 前馈网络(Feedforward Layer) 组成。
-
多头自注意力机制:
每个注意力头有 ( Q, K, V ) 三个矩阵,参数量为:参数量 = 3 × ( 输入特征数 × 注意力头的特征数 ) × 注意力头数 \text{参数量} = 3 \times (\text{输入特征数} \times \text{注意力头的特征数}) \times \text{注意力头数} 参数量=3×(输入特征数×注意力头的特征数)×注意力头数
-
前馈网络:
包含两层全连接层,参数量为:参数量 = 2 × ( 输入特征数 × 隐藏特征数 + 隐藏特征数 ) \text{参数量} = 2 \times (\text{输入特征数} \times \text{隐藏特征数} + \text{隐藏特征数}) 参数量=2×(输入特征数×隐藏特征数+隐藏特征数)
3. 参数量的自动计算方法
在实际项目中,可以使用代码自动计算模型的参数量。以下是 PyTorch 的示例:
3.1 PyTorch 示例
import torch
import torch.nn as nn
# 定义一个简单模型
class SimpleCNN(nn.Module):
def __init__(self):
super(SimpleCNN, self).__init__()
self.conv1 = nn.Conv2d(in_channels=3, out_channels=16, kernel_size=3)
self.fc1 = nn.Linear(16 * 6 * 6, 120)
self.fc2 = nn.Linear(120, 10)
def forward(self, x):
x = self.conv1(x)
x = torch.flatten(x, 1)
x = self.fc1(x)
x = self.fc2(x)
return x
model = SimpleCNN()
# 计算参数量
total_params = sum(p.numel() for p in model.parameters())
print(f"模型的参数量: {total_params}")
输出:
模型的参数量: 14366
【二】介绍一下模型部署领域自定义算子的概念
不管是AIGC、传统深度学习还是自动驾驶领域,涉及到AI模型的深入部署和优化,就需要进行自定义算子的研发。自定义算子(Custom Operator) 是指开发者在标准框架(如 PyTorch、TensorFlow、ONNX 等)之外,为实现特殊功能或优化性能而编写的算子(Operator)。这些算子通常用于AI模型推理阶段,解决标准算子无法满足的需求,或对计算逻辑进行更高效的实现。
自定义算子主要用于:
- 实现新的功能(如自定义激活函数)。
- 针对硬件加速进行优化(如 GPU、TensorRT 插件)。
- 支持AI模型的高效部署与跨平台适配。
通过正确实现和注册自定义算子,可以有效提升AI模型部署的灵活性与性能,满足AI实际业务的特殊需求。
1. 什么是自定义算子?
定义
- 算子(Operator) 是深度学习框架中执行特定计算任务的基本单元,例如卷积算子(
Conv)、矩阵乘法算子(MatMul)等。 - 自定义算子 是指用户自行开发并集成到部署框架中的算子,用于替代或扩展标准框架提供的算子功能。
为什么需要自定义算子?
-
框架内置算子功能有限:
- 标准框架的算子集合有限,无法满足所有业务场景或特殊需求。
- 例如,某些特定的激活函数、归一化方法或复杂的前后处理逻辑可能无法直接用框架内置算子表示。
-
优化性能:
- 在特定硬件(如 GPU、TPU、NPU)上实现针对性优化,提高计算效率。
- 例如,结合 SIMD(单指令多数据)、张量核矩阵加速(Tensor Cores)等硬件特性。
-
自定义功能:
- 实现新的数学运算、复合逻辑或特殊需求的算子。
- 例如:实现新型激活函数或非标准计算图操作。
-
跨平台部署:
- 在不同推理引擎(如 TensorRT、ONNX Runtime、TFLite)上实现统一算子接口,方便模型的跨平台部署。
2. 自定义算子的实现流程
自定义算子的开发一般遵循以下流程:
1. 算子定义
- 确定自定义算子的输入、输出、形状以及具体的计算逻辑。
- 定义数学公式或编程逻辑。
2. 编写算子代码
- 选择底层实现语言(如 C++、CUDA、C)进行编写,以便高效执行。
- 可以使用框架提供的扩展 API 进行开发,例如:
- PyTorch:使用
torch.autograd.Function或torch::RegisterOperators扩展。 - TensorFlow:使用
tf.OperationAPI 编写自定义算子。 - ONNX:实现自定义算子并将其注册到 ONNX Runtime 中。
- TensorRT:通过插件(Plugin)机制扩展算子。
- PyTorch:使用
3. 算子注册
- 将自定义算子注册到框架中,以便模型在推理时可以识别并调用该算子。
- 例如:
- 在 PyTorch 中,通过
torch.ops注册。 - 在 TensorFlow 中,通过
REGISTER_OP注册。
- 在 PyTorch 中,通过
4. 算子验证与测试
- 在框架中测试算子的功能正确性和性能。
- 与标准算子进行结果对比,确保数值精度和稳定性。
5. 集成到部署引擎
- 将算子与推理引擎(如 TensorRT、TFLite、ONNX Runtime)集成,进行实际部署测试。
3. 不同框架中的自定义算子实现
3.1 PyTorch 自定义算子
在 PyTorch 中,可以使用以下两种方法实现自定义算子:
-
Python 级别实现:
- 使用
torch.autograd.Function自定义前向传播和反向传播。
import torch from torch.autograd import Function class CustomRelu(Function): @staticmethod def forward(ctx, input): ctx.save_for_backward(input) return torch.clamp(input, min=0) @staticmethod def backward(ctx, grad_output): input, = ctx.saved_tensors grad_input = grad_output.clone() grad_input[input < 0] = 0 return grad_input x = torch.tensor([-1.0, 2.0, 3.0], requires_grad=True) y = CustomRelu.apply(x) y.backward(torch.ones_like(y)) print(x.grad) - 使用
-
C++/CUDA 扩展:
- 使用 PyTorch 的
torch::RegisterOperatorsAPI 将 C++/CUDA 算子注册到 PyTorch。
- 使用 PyTorch 的
3.2 TensorFlow 自定义算子
TensorFlow 提供了一个灵活的接口,支持开发自定义算子:
-
使用 TensorFlow Custom Op API(C++ 实现):
REGISTER_OP("CustomAdd") .Input("a: float") .Input("b: float") .Output("sum: float") .SetShapeFn([](shape_inference::InferenceContext* c) { c->set_output(0, c->input(0)); return Status::OK(); }); -
Python 层封装:
- 使用
tf.py_function和 TensorFlow 的 Autograph 机制自定义前向传播。
- 使用
3.3 ONNX 自定义算子
- 使用 ONNX Runtime 的扩展机制来实现自定义算子。
- 注册自定义算子并将其打包为动态库供 ONNX 使用。
3.4 TensorRT 自定义算子
- TensorRT 支持通过 Plugin(插件) 扩展算子。
- 使用 C++ 和 CUDA 编写自定义插件,实现算子的高性能加速。
4. 自定义算子的应用场景
-
新激活函数:
- 实现模型框架中未提供的激活函数,例如 Swish、Mish、GELU。
-
非标准操作:
- 实现特殊算子,如自定义的归一化层、复杂损失函数等。
-
硬件加速:
- 利用硬件特性(如 GPU、FPGA、NPU)优化计算逻辑,实现更高性能。
-
模型前后处理:
- 在部署中实现自定义的输入前处理和输出后处理算子。
-
特定算法的优化:
- 针对特定应用场景(如图像处理、时间序列分析)设计高效算子。
5. 自定义算子的优缺点
优点:
- 功能扩展:可以实现框架原生不支持的功能或算子。
- 性能优化:针对硬件特性进行深度优化,提升推理性能。
- 灵活性:根据具体需求设计高度定制的算子。
缺点:
- 开发复杂:需要编写底层代码(如 C++/CUDA),学习成本较高。
- 维护成本:自定义算子需要持续维护,适配框架和硬件更新。
- 跨平台适配难度:不同框架和推理引擎可能需要不同的算子实现。
计算机基础
Rocky从工业界、学术界、竞赛界以及应用界角度出发,总结归纳AI行业所需的计算机基础干货知识。这些干货知识不仅能在面试中帮助我们,还能让我们在AI行业中提高工作效率。
【一】介绍一下计算机文件系统的死锁原理
在计算机领域中,死锁(Deadlock) 是一种进程无法继续执行的状态,通常发生在多个进程竞争有限的资源时。死锁的典型特征是,进程相互等待其他进程释放资源,而没有一个进程能够打破这种等待状态,导致系统陷入停滞。
在文件系统中,死锁通常出现在多个进程试图同时访问文件资源时。如果进程之间的资源请求形成了循环等待,并且没有适当的协调机制来处理这些冲突,就会导致死锁。
死锁的四个必要条件
文件系统中的死锁遵循操作系统中死锁的经典四个必要条件:
-
互斥条件:
- 文件或资源一次只能被一个进程占用。例如,一个进程在写文件时,其他进程不能同时对文件进行写操作。
-
占有且等待条件:
- 一个进程已占用某些资源,同时还在等待其他资源,而这些资源被其他进程占用。例如,进程 A 已经打开了文件 X,并等待文件 Y;进程 B 已经打开了文件 Y,并等待文件 X。
-
不可抢占条件:
- 资源不能被强制抢占,只有占有资源的进程可以主动释放。例如,文件锁定(file lock)机制确保了文件只有当前进程可以访问,其他进程必须等待其释放。
-
循环等待条件:
- 存在一个进程的循环链,每个进程都在等待下一个进程所占有的资源。例如:
- 进程 A 等待进程 B 的资源;
- 进程 B 等待进程 C 的资源;
- 进程 C 又等待进程 A 的资源。
- 存在一个进程的循环链,每个进程都在等待下一个进程所占有的资源。例如:
文件系统死锁的典型场景
-
文件锁死锁
- 当多个进程试图同时获取文件的锁时,可能会导致死锁。
- 示例:
- 进程 A 锁住文件
file1,并试图获取文件file2的锁; - 进程 B 锁住文件
file2,并试图获取文件file1的锁; - 两个进程彼此等待对方释放锁,陷入死锁。
- 进程 A 锁住文件
-
目录操作死锁
- 当进程试图同时访问或修改多个目录时,也可能导致死锁。
- 示例:
- 进程 A 在移动文件时需要锁定源目录和目标目录;
- 进程 B 在目标目录中创建新文件时,需要锁定目标目录;
- 如果两者锁定顺序不同,会产生循环等待。
-
文件访问死锁
- 当多个进程试图同时读取或写入一个文件时,死锁可能发生。
- 示例:
- 进程 A 正在写文件
file1,并等待进程 B 的文件操作完成; - 进程 B 正在读取
file1,并等待进程 A 释放写锁。
- 进程 A 正在写文件
-
网络文件系统(NFS)死锁
- 在分布式系统中,死锁问题更为复杂,因为多个节点可能需要访问同一个文件系统。
- 示例:
- 两个远程节点都需要访问共享文件,并尝试通过网络获取锁,形成循环等待。
【二】解决计算机文件系统死锁的经典方法有哪些?
-
预防死锁(Deadlock Prevention)
- 破坏死锁的四个必要条件之一:
- 打破循环等待:
- 给资源(如文件锁)分配一个顺序编号,进程只能按照编号顺序请求资源。
- 示例:如果文件
file1编号为 1,file2编号为 2,所有进程必须先请求文件编号较小的锁。
- 允许抢占:
- 允许高优先级进程强制抢占低优先级进程的文件锁。
- 打破循环等待:
- 破坏死锁的四个必要条件之一:
-
避免死锁(Deadlock Avoidance)
- 银行家算法(Banker’s Algorithm):
- 计算每个进程对资源的需求,确保在分配资源后,系统仍然处于安全状态。
- 在文件系统中,这可以通过模拟文件锁请求,确保不会导致资源循环等待。
- 超时机制:
- 如果进程等待资源的时间超过设定的阈值,释放所有已占用资源,重新尝试操作。
- 银行家算法(Banker’s Algorithm):
-
检测并恢复(Deadlock Detection and Recovery)
- 检测:
- 定期检查系统中的进程与资源状态,检测是否存在循环等待。
- 示例:建立一个资源分配图(Resource Allocation Graph),如果图中存在环,则发生死锁。
- 恢复:
- 通过中止某些进程来打破循环等待。
- 示例:中止优先级最低的进程,释放其占有的文件锁。
- 检测:
-
文件系统设计层面改进
- 锁分离:
- 读写锁分离,允许多个读操作同时进行,减少死锁的可能性。
- 事务机制:
- 在操作多个文件时,使用事务机制确保要么所有操作完成,要么回滚到初始状态。
- 分布式锁管理器(Distributed Lock Manager, DLM):
- 在分布式文件系统中,通过集中管理锁来避免死锁。
- 锁分离:
实际应用中的案例
案例 1:多线程文件操作
- 场景:
- 多个线程同时尝试对同一文件进行读写操作。
- 死锁原因:
- 线程 A 获取写锁后等待线程 B 的读锁释放,而线程 B 等待线程 A 的写锁释放。
- 解决方案:
- 使用读写锁分离,允许多个读线程同时访问文件,但写线程必须独占文件。
案例 2:数据库文件死锁
- 场景:
- 多个进程同时访问一个数据库文件。
- 死锁原因:
- 进程 A 锁定表
users,并尝试锁定表orders; - 进程 B 锁定表
orders,并尝试锁定表users。
- 进程 A 锁定表
- 解决方案:
- 为数据库表定义锁顺序,所有进程必须按照相同的顺序请求锁。
总结
- 文件系统中的死锁通常发生在多个进程竞争文件资源或目录锁时。
- 要解决死锁问题,可以通过预防(打破必要条件)、避免(如超时机制)、检测与恢复(如资源分配图)等方式。
- 从设计角度,事务机制、锁分离和顺序编号是降低死锁发生概率的有效策略。
开放性问题
Rocky从工业界、学术界、竞赛界以及应用界角度出发,总结AI行业的本质思考。这些问题不仅能够用于面试官的提问,也可以用作面试者的提问,在面试的最后阶段让面试双方进入深度的探讨与交流。
与此同时,这些开放性问题也是贯穿我们职业生涯的本质问题,需要我们持续的思考感悟。这些问题没有标准答案,Rocky相信大家心中都有自己对于AI行业的认知与判断,欢迎大家在留言区分享与评论。
【一】AI算法工程师如何以AI技术为核心,统筹推动业务的构建与发展?
Rocky认为这是AI算法工程师要终身思考的本质问题,以AI技术为核心的基础上,我们还需要统筹推动业务的构建与发展。
【二】AI公司如何评估和控制各业务部门的成本与效益?
Rocky认为这个问题非常关键,我们需要从AI行业角度出发,从整体上评估成本,增强效益,才能把握公司下一步的发展趋势。
推荐阅读
1、加入AIGCmagic社区知识星球!
AIGCmagic社区知识星球不同于市面上其他的AI知识星球,AIGCmagic社区知识星球是国内首个以AIGC全栈技术与商业变现为主线的学习交流平台,涉及AI绘画、AI视频、大模型、AI多模态、数字人以及全行业AIGC赋能等100+应用方向。星球内部包含海量学习资源、专业问答、前沿资讯、内推招聘、AI课程、AIGC模型、AIGC数据集和源码等干货。
那该如何加入星球呢?很简单,我们只需要扫下方的二维码即可。知识星球原价:299元/年,前200名限量活动价,终身优惠只需199元/年。大家只需要扫描下面的星球优惠卷即可享受初始居民的最大优惠:

2、Sora等AI视频大模型的核心原理,核心基础知识,网络结构,经典应用场景,从0到1搭建使用AI视频大模型,从0到1训练自己的AI视频大模型,AI视频大模型性能测评,AI视频领域未来发展等全维度解析文章正式发布!
码字不易,欢迎大家多多点赞:
Sora等AI视频大模型文章地址:https://zhuanlan.zhihu.com/p/706722494
3、Stable Diffusion 3和FLUX.1核心原理,核心基础知识,网络结构,从0到1搭建使用Stable Diffusion 3和FLUX.1进行AI绘画,从0到1上手使用Stable Diffusion 3和FLUX.1训练自己的AI绘画模型,Stable Diffusion 3和FLUX.1性能优化等全维度解析文章正式发布!
码字不易,欢迎大家多多点赞:
Stable Diffusion 3和FLUX.1文章地址:https://zhuanlan.zhihu.com/p/684068402
4、Stable Diffusion XL核心基础知识,网络结构,从0到1搭建使用Stable Diffusion XL进行AI绘画,从0到1上手使用Stable Diffusion XL训练自己的AI绘画模型,AI绘画领域的未来发展等全维度解析文章正式发布!
码字不易,欢迎大家多多点赞:
Stable Diffusion XL文章地址:https://zhuanlan.zhihu.com/p/643420260
5、Stable Diffusion 1.x-2.x核心原理,核心基础知识,网络结构,经典应用场景,从0到1搭建使用Stable Diffusion进行AI绘画,从0到1上手使用Stable Diffusion训练自己的AI绘画模型,Stable Diffusion性能优化等全维度解析文章正式发布!
码字不易,欢迎大家多多点赞:
Stable Diffusion文章地址:https://zhuanlan.zhihu.com/p/632809634
6、ControlNet核心基础知识,核心网络结构,从0到1使用ControlNet进行AI绘画,从0到1训练自己的ControlNet模型,从0到1上手构建ControlNet商业变现应用等全维度解析文章正式发布!
码字不易,欢迎大家多多点赞:
ControlNet文章地址:https://zhuanlan.zhihu.com/p/660924126
7、LoRA系列模型核心原理,核心基础知识,从0到1使用LoRA模型进行AI绘画,从0到1上手训练自己的LoRA模型,LoRA变体模型介绍,优质LoRA推荐等全维度解析文章正式发布!
码字不易,欢迎大家多多点赞:
LoRA文章地址:https://zhuanlan.zhihu.com/p/639229126
8、Transformer核心基础知识,核心网络结构,AIGC时代的Transformer新内涵,各AI领域Transformer的应用落地,Transformer未来发展趋势等全维度解析文章正式发布!
码字不易,欢迎大家多多点赞:
Transformer文章地址:https://zhuanlan.zhihu.com/p/709874399
9、最全面的AIGC面经《手把手教你成为AIGC算法工程师,斩获AIGC算法offer!(2024年版)》文章正式发布!
码字不易,欢迎大家多多点赞:
AIGC面经文章地址:https://zhuanlan.zhihu.com/p/651076114
10、50万字大汇总《“三年面试五年模拟”之算法工程师的求职面试“独孤九剑”秘籍》文章正式发布!
码字不易,欢迎大家多多点赞:
算法工程师三年面试五年模拟文章地址:https://zhuanlan.zhihu.com/p/545374303
《三年面试五年模拟》github项目地址(希望大家能多多star):https://github.com/WeThinkIn/Interview-for-Algorithm-Engineer
11、Stable Diffusion WebUI、ComfyUI、Fooocus三大主流AI绘画框架核心知识,从0到1搭建AI绘画框架,从0到1使用AI绘画框架的保姆级教程,深入浅出介绍AI绘画框架的各模块功能,深入浅出介绍AI绘画框架的高阶用法等全维度解析文章正式发布!
码字不易,欢迎大家多多点赞:
AI绘画框架文章地址:https://zhuanlan.zhihu.com/p/673439761
12、GAN网络核心基础知识,网络架构,GAN经典变体模型,经典应用场景,GAN在AIGC时代的商业应用等全维度解析文章正式发布!
码字不易,欢迎大家多多点赞:
GAN网络文章地址:https://zhuanlan.zhihu.com/p/663157306
13、其他
Rocky将YOLOv1-v7全系列大解析文章也制作成相应的pdf版本,大家可以关注公众号WeThinkIn,并在后台 【精华干货】菜单或者回复关键词“YOLO” 进行取用。
Rocky一直在运营技术交流群(WeThinkIn-技术交流群),这个群的初心主要聚焦于技术话题的讨论与学习,包括但不限于算法,开发,竞赛,科研以及工作求职等。群里有很多人工智能行业的大牛,欢迎大家入群一起学习交流~(请添加小助手微信Jarvis8866,拉你进群~)