一、绪论
分类 classify 上涨或跌
回归 regression 描述具体数值
分类模型评估
1.混淆(误差)矩阵 confusion matrix
2.ROC曲线 receiver operating characteristic curve 接收者操作特征曲线
3.AUC面积 area under curve ROC曲线下与坐标轴围成的面积,面积越大越好
混淆矩阵
列:预测类别
行:真实归属类别
ACC、FPR、TPR、ENR、F1
DBN:深度信念网络 deep belief network
RBM:restricted Boltzman machine 受限玻尔兹曼机
CNN:卷积神经网络 convolution neural network
SAE:稀疏流自编码 Sparse Auto Encoder
通过计算自编码输出和源输入的误差,不断调节编码器的参数,最终训练出模型。可用于压缩输入信息,提取有的输入特征。【AE通过无监督学习更新参数,使重构误差更小】
算法 algorithm
拟合 fitting
过拟合 overfitting
欠拟合 underfitting

二、
KDD知识发现 knowledge discovery in database
DM data mining
DL deep learning
ML machine learning
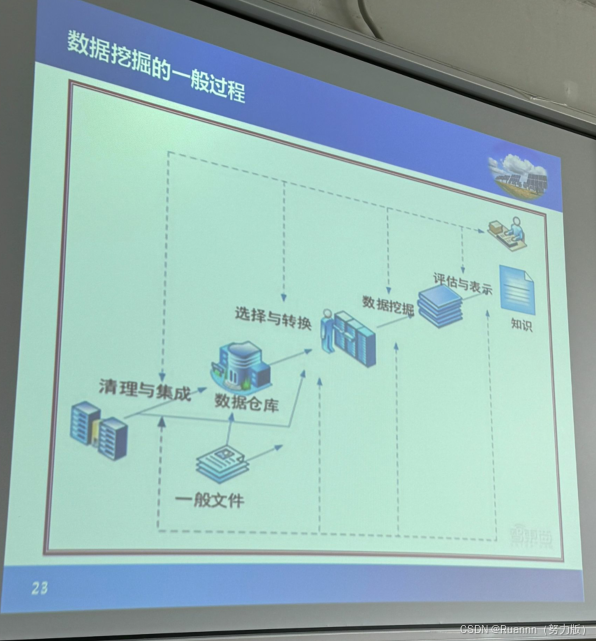
分析源数据、确定挖掘目标、系统设计和开发
问题定义、数据抽取、数据预处理、数据挖掘及模式评估
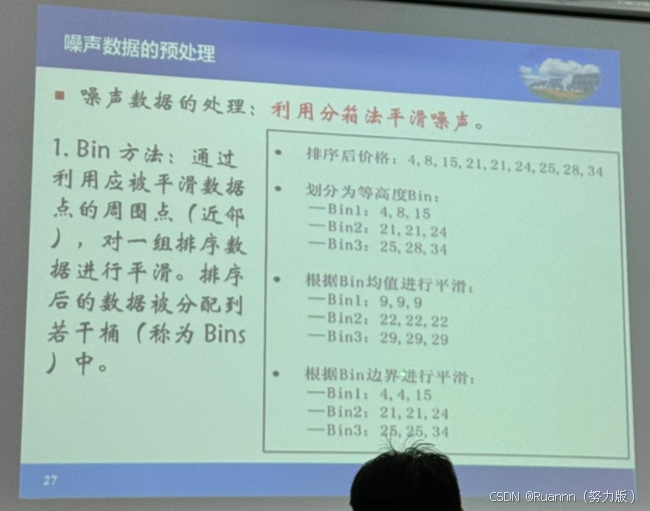
数据预处理:清洗、转换、描述、选择、抽取
冗余redundant
不均衡imbalance
离群值/异常值 outliers
重复 duplicate
数据缺失 incomplete
数据噪声 noisy
数据不一致 inconsistent

中位数 median
众数mode
截尾平均trimmedmean【去首位2%】

主成分分析PCA principal component analysis 降维 投影 特征选择

留出法hold-out
自助法 bootstrap
极差range=max-min
分布的五数概括(five-number summary)中位数Q2 四分位Q1 Q3 Min max
四分位数25 50(median) 75
排序:Min Q1 median Q3 Max
箱线图:盒底Q1 盒顶Q3 中间粗线median 触顶表示数据散布范围 最远1.5IQR(Q3-Q1)【四位数极差、离群点】
强度挖掘 intension Mining
三、关联规则挖掘association rule mining

关联规则挖掘的两步过程:
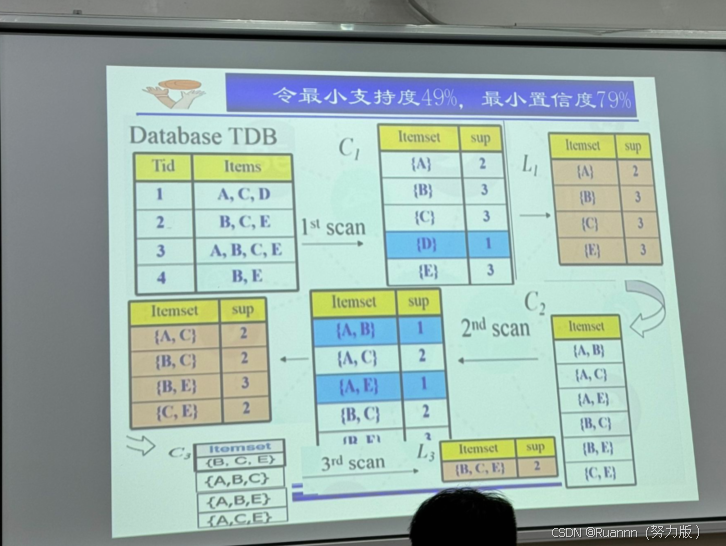
1)找出所有的频繁项集:这些项集出现的频繁性要满足最小支持度原则。
2)由频繁项集产生强关联规则:满足最小支持度和最小置信度。
Apriori算法原理(寻找频繁项集)
1)任何一个频繁项集的子集必定是频繁项集;
如,如果{A,B}是频繁项集,则{A}、{B}都是频繁项集。
2)任何非频繁项集的超集都为非频繁项集
如,如果{A}、{B}是非频繁项集,则{A,B}是非频繁项集
Close算法(寻找频繁项集的方法2)
一个频繁闭合项集的所有闭合子集一定是频繁的。一个非频繁闭合项集的所有闭合超集一定是非频繁的。闭合项集:不能在C中存在小于或等于它的支持度的子集。
如何找闭合项集:取交集,修剪
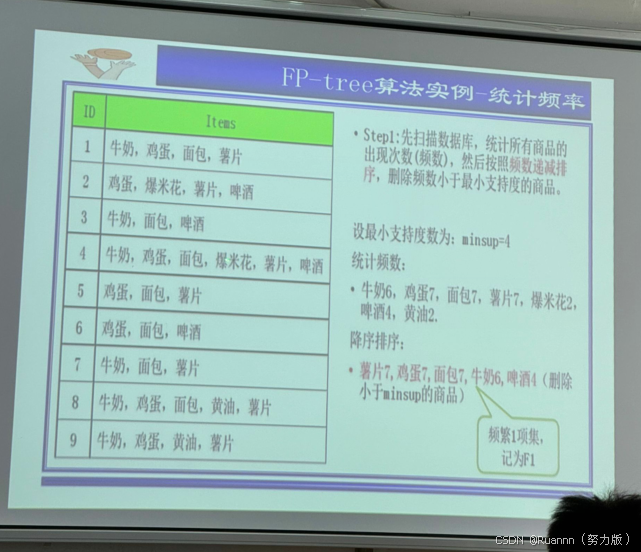
FP-growth(寻找频繁项集方法3)
基于项目系列,只用扫描两次数据库,有顺序。
①频度排序
②信息转变为紧缩内存结构
FP-tree Frequent Pattern Tree
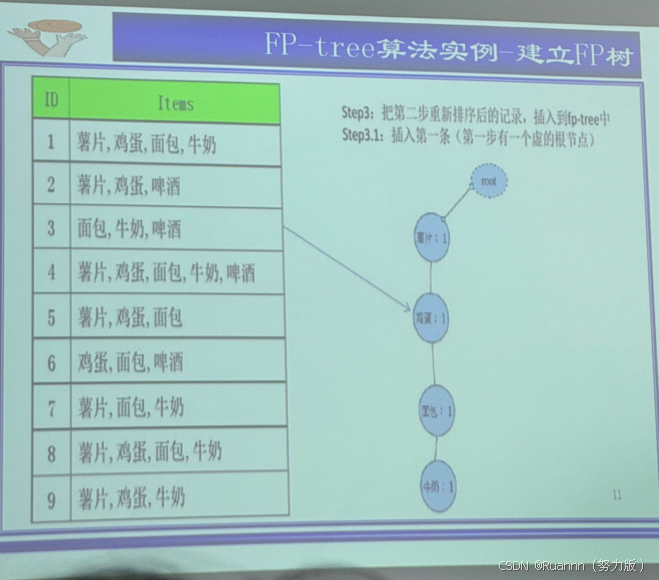
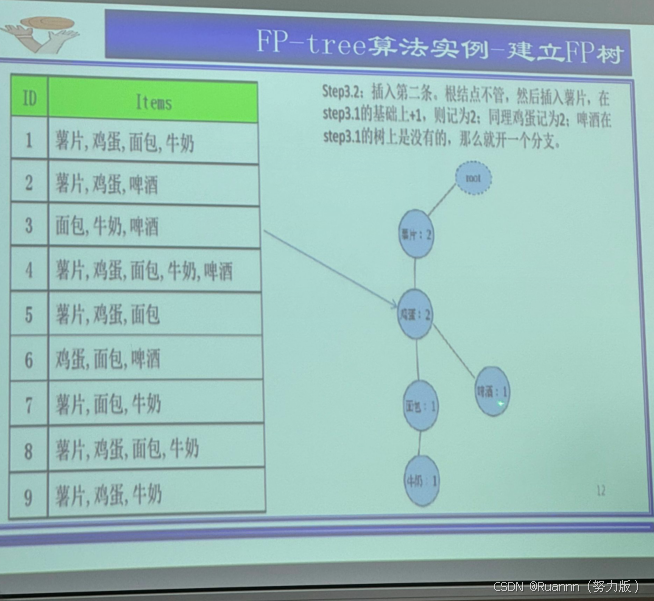
四、分类方法
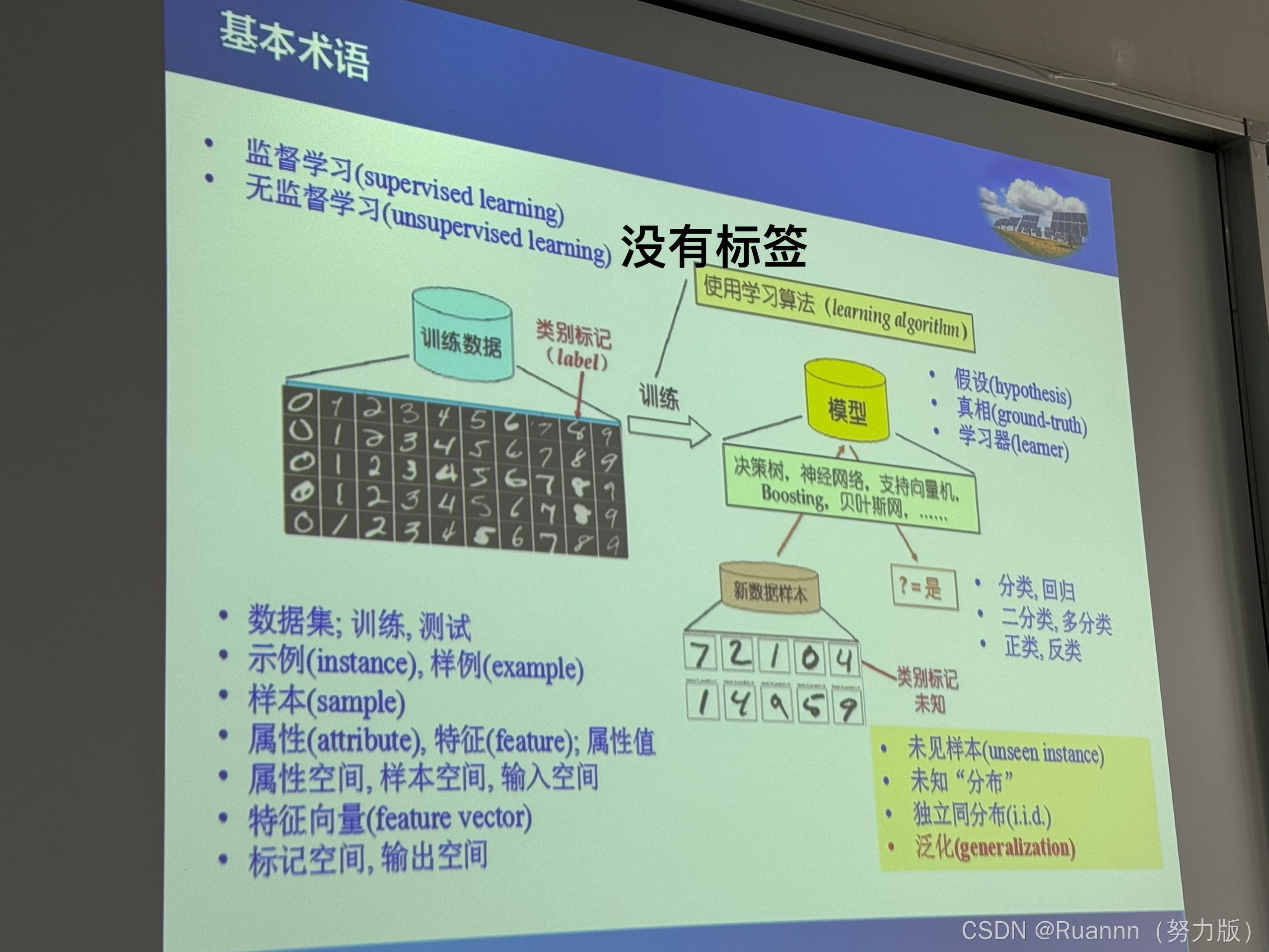
建模 training data
测试 testing data


朴素贝叶斯:假设样本特征彼此独立,没有相关关系。
先验概率prior probability:根据以往经验和分析得到的概率
后验概率 posterior probability:事情已发生,判断事情发生时由哪个原因引起
联合概率joint probability:两个事情共同发生的概率
五、聚类方法 clustering
将对象进行自动分组。是无标签的无监督学习
聚类在数据挖掘中的典型应用有:
1、聚类分析可以作为其它算法的
预处理
步骤
2、聚类分析可以作为一个独立的工具来
获得数据的分布
情况
3、聚类分析可以完成
孤立点挖掘
衡量聚类效果的标准
◼
簇内相似度越高、簇间相似度越低,聚类效果越好

聚类技术:
◼
划分法:k均值、k中心点
◼
层次法:凝聚层次聚类、分裂层次聚类
◼
基于密度的方法:Density-based approach
◼
基于模型的方法:Model-based approach
划分聚类:构造数据k个划分,每一个划分就代表一个簇。每一个簇至少包含一个对象,每一个对象属于且仅属于一个簇。
K-means K平均值【欧氏距离】
把n个对象分为k个簇,以使簇内具有较高的相似度。相似度计算根据一个簇中对象平均值进行。

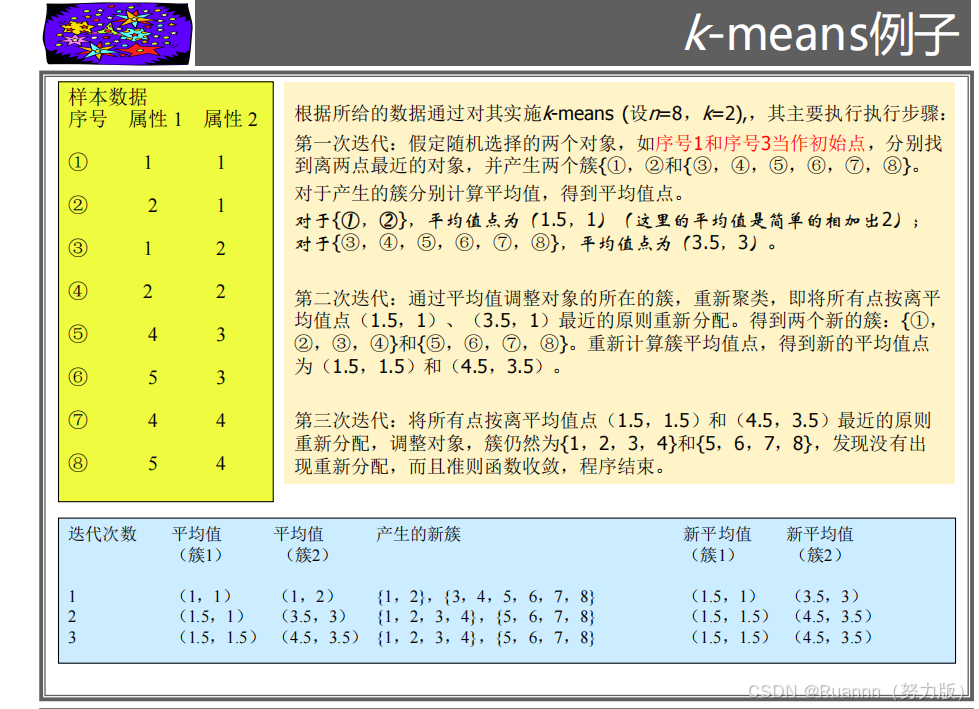 k-中心点
( K-medoids ):算法
k
-means算法对于 孤立点是敏感的。为了解决这个问题,不采用簇 中的平均值作为参照点,可以选用簇
中位置
最中心的对象,即中心点作为参照点。这样划分方法
k-中心点
( K-medoids ):算法
k
-means算法对于 孤立点是敏感的。为了解决这个问题,不采用簇 中的平均值作为参照点,可以选用簇
中位置
最中心的对象,即中心点作为参照点。这样划分方法
仍然是基于最小化所有对象与其参照点之间的相异度之和的原则来执行的。【曼哈顿距离】
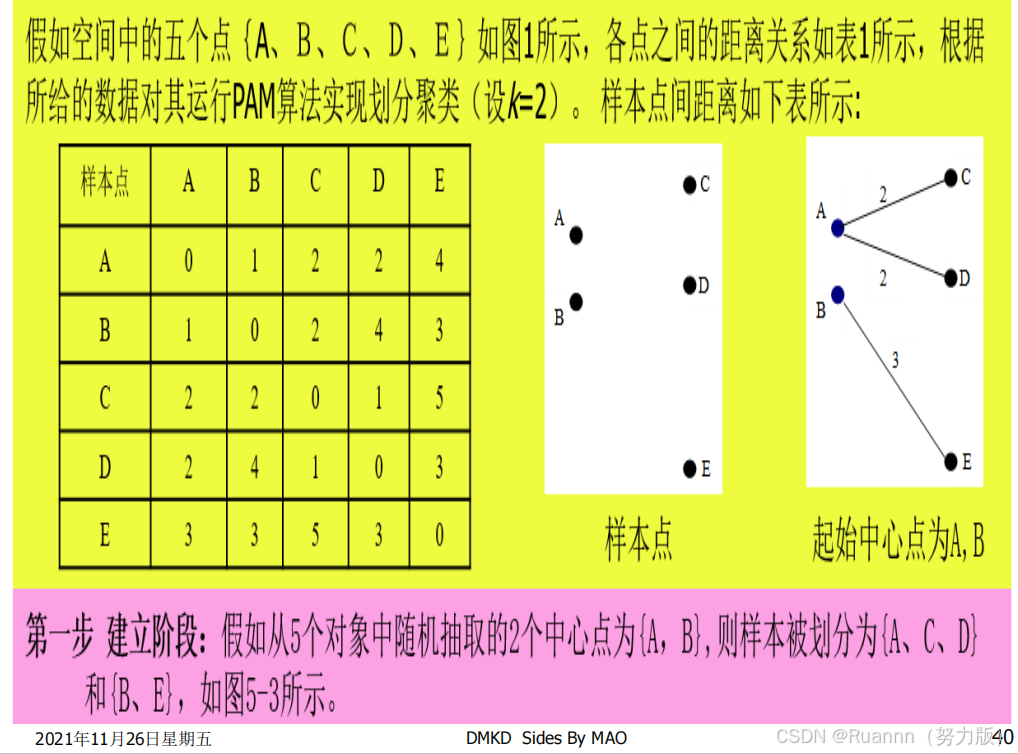
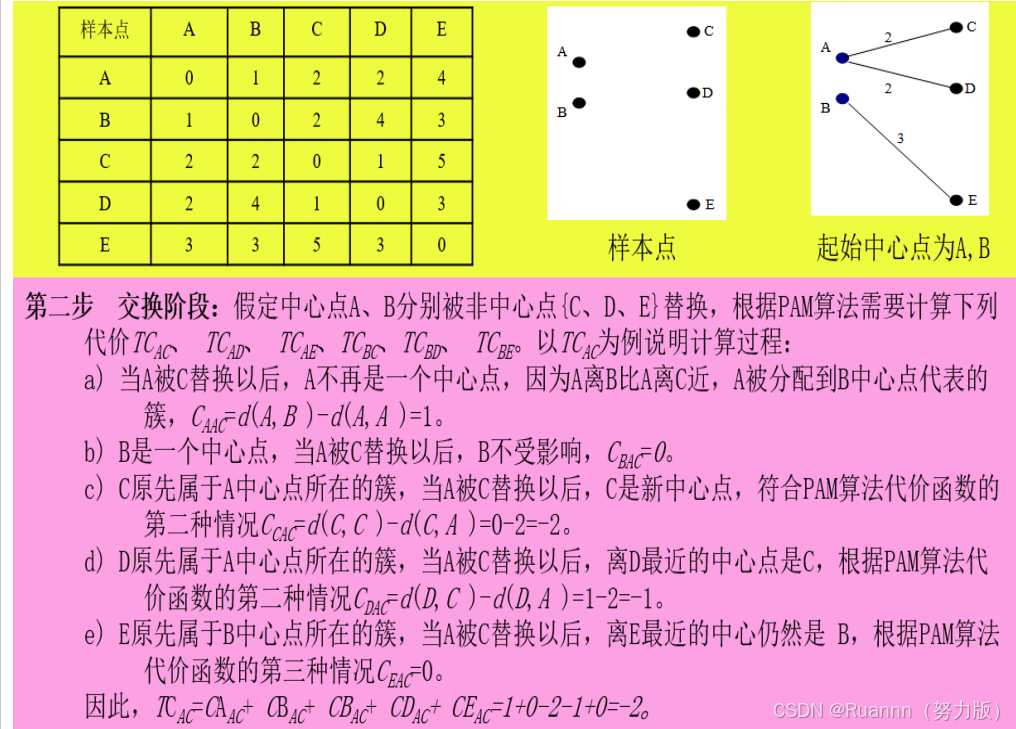
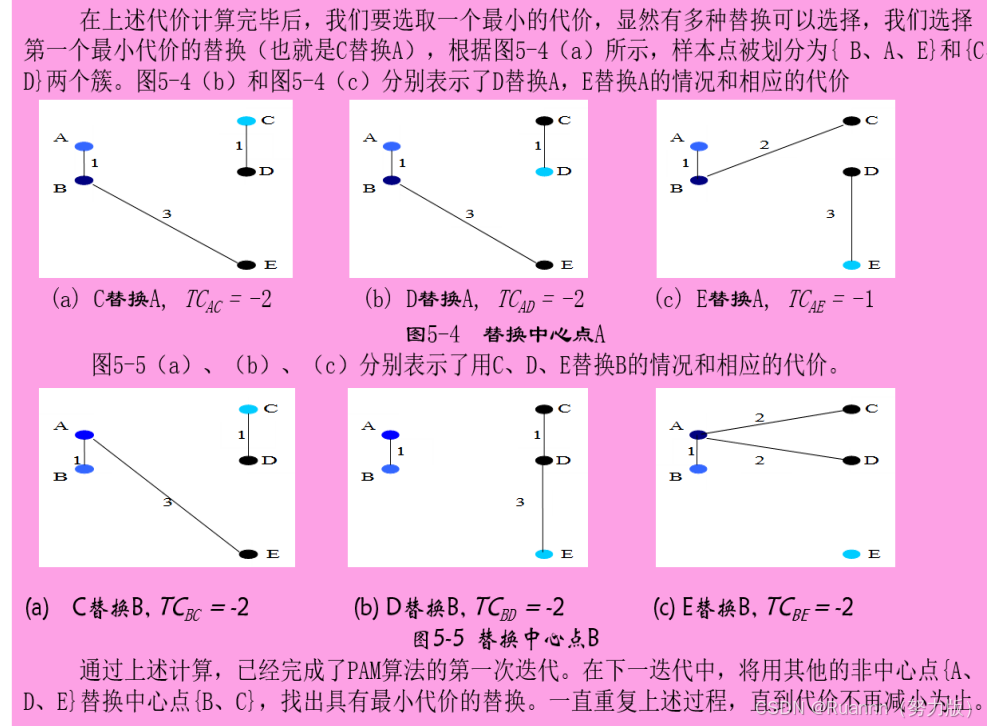
Partitioning Around Medoids (PAM)算法,是一种常见的 k中心点聚类方法,利用
贪婪搜索
,不一定可以找到最优解,但是比穷尽搜索更快。
◼
在 K 中心点算法中,每次迭代后的质点都是从聚类的样本点中选取,k中心点算法不采用簇中对象
的平均值作为簇中心,而选用簇中
离平均值最近的对象作为簇中心
。
层次聚类:对给定的数据集进行层次的分解,直到满足某种条件。
凝聚
的层次聚类:一种
自底向上
的策略,首先将每个对象作为一个簇,然后合并这些原子簇为越来越大的簇, 直到某个终结条件被满足,如AGNES算法。
◼
分裂
的层次聚类:采用
自顶向下
的策略,它首先将所有对象置于一个簇中,然后逐渐细分为越来越小的簇,直到达到了某个终结条件,如DIANA算法
AGNES (AGglomerative NESting):
自底向上凝聚算法,
先将每个对象作为一个簇,然后这些簇根据某些准则被一步步地合并。两个簇间的相似度由这 两个不同簇
中
距离最近的数据点对
的相似度来确定。 聚类的合并过程反复进行直到所有的对象最终满足 簇数目。
算法
5-3 AGNES
(自底向上凝聚算法)
输入
:
包含
n
个对象的数据库,终止条件簇的数目
k
。
输出
:
k
个簇,达到终止条件规定簇数目。
(1)
将每个对象当成一个初始簇;
(2) REPEAT
(3)
根据两个簇中最近的数据点找到最近的两个簇;
(4)
合并两个簇,生成新的簇的集合;
(5) UNTIL
达到定义的簇的数目;
DIANA
(Divisive ANAlysis)
算法是典型的
分裂聚类方法
。
◼
用户能定义希望得到的簇数目作为一个结束条件。同时,它使用下面两种测度方法:
◼
簇的直径
:在一个簇中的任意两个数据点的距离中的最大值。
◼
平均相异度
(平均距离)

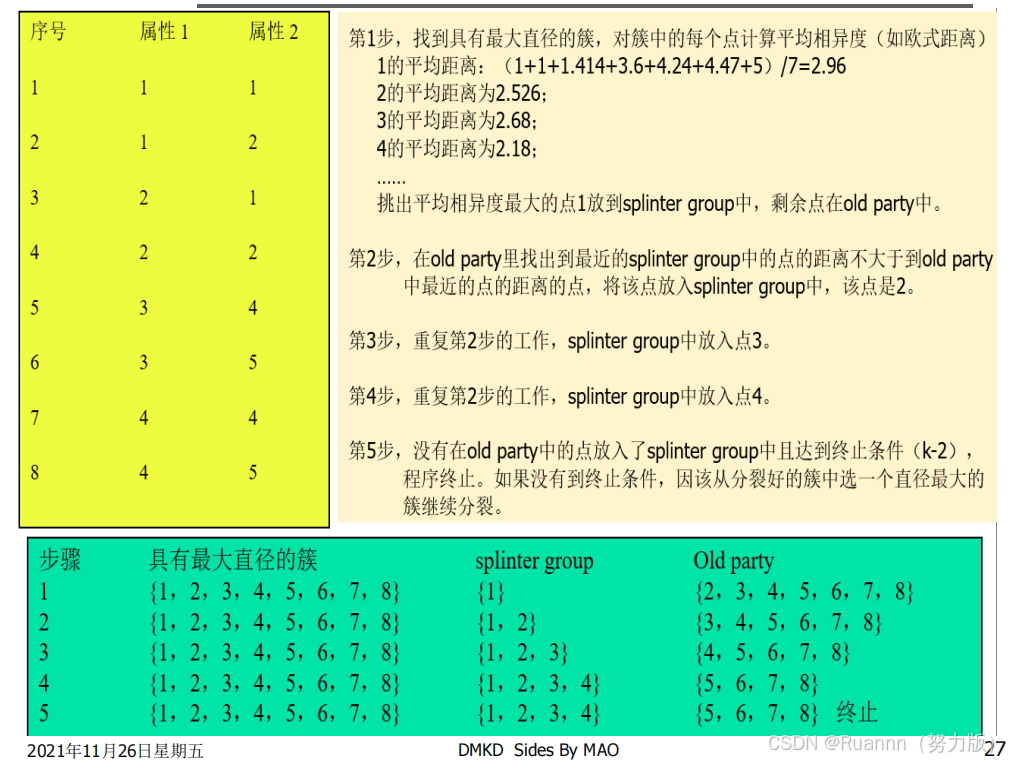
密度聚类方法
的指导思想是,只要一个
区域
中,点的密度大于某个
阈值
,就把它加到与之相连的簇中去。
(1) DBSCAN
:
Density-Based Spatial Clustering of Applications with Noise,噪声环境下的密度聚类算法
(2) OPTICS
:
Ordering Points To Identify the Clustering Structure,基于不同密度的聚类算法
(3) EDNCLUE
:
Density Clustering
,基于一组密度分布函数的聚类算法
DBSCAN算法:
如果一个点
q
的区域内包含多于MinPts 个对象,则创建一个q
作为核心对象的簇。然后,
反复 地寻找
从这些核心对象直接密度可达的对象,把一些密度可达簇进行合并。当没有新的点可以被添加到任何簇时,该过程结束。
STING(Statistaical Information Grid_based method)是一种
基于网格的多分辨率聚类技术
,它将空间区域划分为矩形单元。针对不同级别的分辨率,通常存在多个级别的巨型单元,这些单元形成了一个层次结构:高层的每个单元被划分为多个第一层的单元。高层单元的统计参数可以很容易的从底层单元的计算得到。这些参数包括属性无关的参数count
、属性相关的参数
m
(平均值)、
s
(标准偏差)、
min
(最小值)、
max
(最大值)以及该单元中属性值遵循的分布类型。
◼
STING算法的主要优点是效率高,通过对数据集的一次扫描来计算单元的统计信息,因此产生聚类的时间复杂度是
O
(
n
)。在建立层次结构以后,查询的时间复杂度是
O
(
g
),
g 远小于n
。STING算法采用网格结构,有利于并行处理和增量更新。
八、Web挖掘
Web挖掘依靠它所挖掘的信息来源可以分为:
◼
Web内容挖掘(Web Content Mining)
:
对站点的Web页面的各类信息进行集成、概化、分类等,挖掘某类信息所蕴含的知识模式。
◼
Web访问信息挖掘(Web Usage Mining)
:Web访问信息挖掘是对用户访问Web时在服务器方留下的访问记录进行挖掘。通过分析日志记录中的规律,可以识别用户的忠实度、喜好、满意度,可以 发现潜在用户,增强站点的服务竞争力。
◼
Web结构挖掘(Web Structure Mining):
Web结构挖掘是对Web页 面之间的链接结构进行挖掘。在整个Web空间里,有用的知识不仅包含在Web页面的内容之中,而且也包含在页面的链接结构之中。 对于给定的Web页面集合,通过结构挖掘可以发现页面之间的关联 信息,页面之间的包含、引用或者从属关系等。
信息检索(Information Retrieval,IR)
是搜索的根基,其目的是帮助用户从大规模的文本文档中
找到所需信息的研究领域。
信息检索可能经常被说成是Web挖掘的初级阶段, 是为了强调Web挖掘不是简单的信息索引或关键词匹配技术,而是实现信息浓缩成知识的过程, 它可以支持更高级的商业决策和分析
一些比较有代表性的数据源有:
◼
Web服务器
日志
数据
◼
Web上的
电子商务
数据
◼
Web上的
网页
◼
Web上的网页之间的
链接
◼
Web上的
多媒体
数据