最近我在捣鼓一个PDF文件,想把它里面的文字和文字颜色给提取出来。后来发现有个叫pymupdf的库能搞定这事儿。操作起来挺简单的,pymupdf的示例文档里就有现成的代码可以参考。
how-to-extract-text-with-color
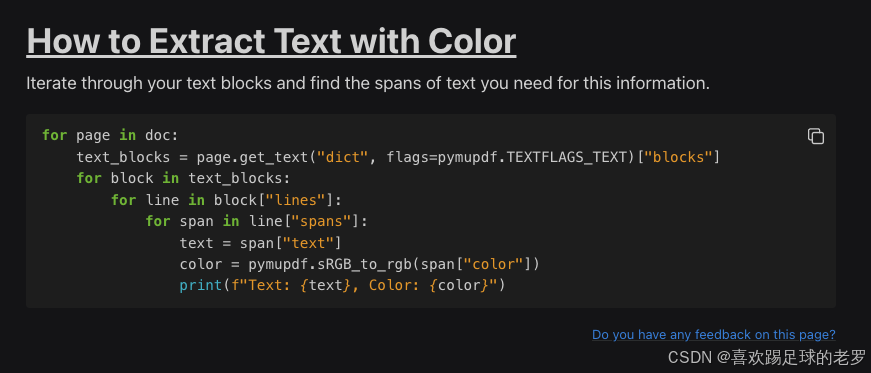
我本地的测试代码如下:
import pymupdf
import sys
# sys.argv[1] 为文件名!
doc = pymupdf.open(sys.argv[1])
page = doc[0]
for page in doc:
text_blocks = page.get_text("dict", flags=pymupdf.TEXTFLAGS_TEXT)["blocks"]
for block in text_blocks:
for line in block["lines"]:
for span in line["spans"]:
text = span["text"]
color = pymupdf.sRGB_to_rgb(span["color"])
print(f"Text: {text}, Color: {color}")
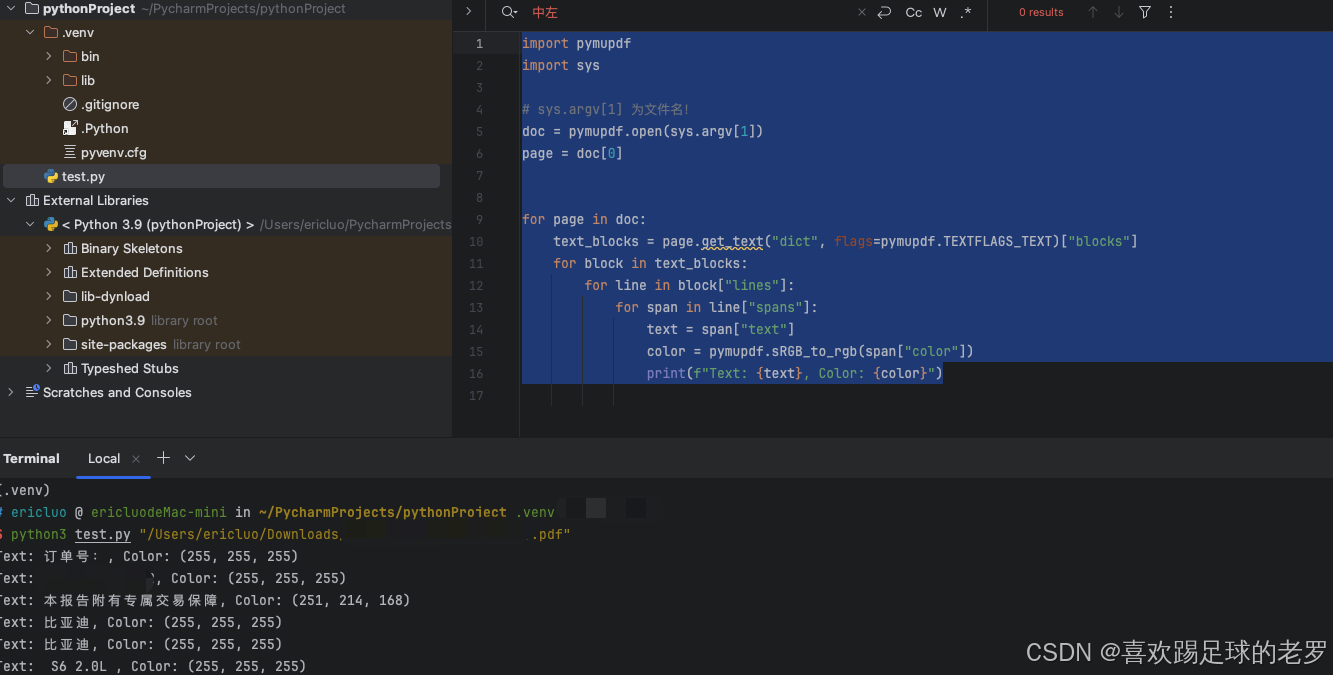
运行效果如下:
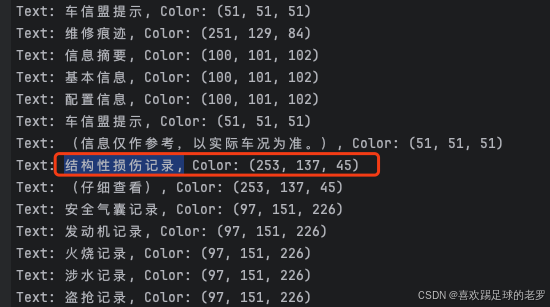
我弄的那个文档里,有一块内容是这样的,项目里的文字被标成橙色,就是那种选中后的样子,所以我特别留意了它的颜色提取。
所以我需要抽取出文字的同时,还需要文字的颜色


推荐相关的文章 PymuPDF4llm:PDF 提取的革命