一、介绍
TangoFlux是通过流匹配和 Clap-Ranked 首选项优化,实现超快速、忠实的文本到音频生成的模型。
- 本模型由 Stability AI 提供支持
- 🚀 TangoFlux 可以在单个 A40 GPU 上在 ~3 秒内生成长达 34.1kHz 的立体声音频。
二、部署
安装方式非常简单
1.克隆并安装环境
pip install git+https://github.com/declare-lab/TangoFlux
2.推理
TangoFlux 可以生成长达 30 秒的音频。使用 Python API 时,必须将 duration 传递给函数。请注意,持续时间应在 1 到 30 之间。model.generate
Web 界面
运行以下命令以启动 Web 界面。
tangoflux-demo
首次运行web界面的启动命令后,项目会自动下载所需的模型,此时需要保持网络畅通,耐心等待:

出现ip地址即端口号后即可进行访问。
命令行界面
使用 CLI 从文本直接生成音频。
tangoflux "Hammer slowly hitting the wooden table" output.wav --duration 10 --steps 50
Python 接口
import torchaudio
from tangoflux import TangoFluxInference
model = TangoFluxInference(name='declare-lab/TangoFlux')
audio = model.generate('Hammer slowly hitting the wooden table', steps=50, duration=10)
torchaudio.save('output.wav', audio, 44100)
官方评估表明,使用 50 个步骤进行推理会产生最佳结果。CFG 等级为 3.5、4 和 4.5 可产生相似的质量输出。25 步推理以更快的速度产生类似的音频质量。
训练
官方使用 Hugging Face 的包进行多 GPU 训练。Run 以设置您的运行配置。默认的 accelerate 配置位于 文件夹中。请在 中指定训练文件的路径。的样本 和 已提供。将它们替换为您自己的音频。accelerate``accelerate config``configs``configs/tangoflux_config.yaml``train.json``val.json
tangoflux_config.yaml 定义训练文件路径和模型超参数:
CUDA_VISIBLE_DEVICES=0,1 accelerate launch --config_file='configs/accelerator_config.yaml' tangoflux/train.py --checkpointing_steps="best" --save_every=5 --config='configs/tangoflux_config.yaml'
要执行 DPO 训练,请修改训练文件,使每个数据点都包含“chosen”、“reject”、“caption”和“duration”字段。请在 中指定训练文件的路径。中提供了一个示例。将其替换为您自己的音频。configs/tangoflux_config.yaml``train_dpo.json
CUDA_VISIBLE_DEVICES=0,1 accelerate launch --config_file='configs/accelerator_config.yaml' tangoflux/train_dpo.py --checkpointing_steps="best" --save_every=5 --config='configs/tangoflux_config.yaml'
评估脚本
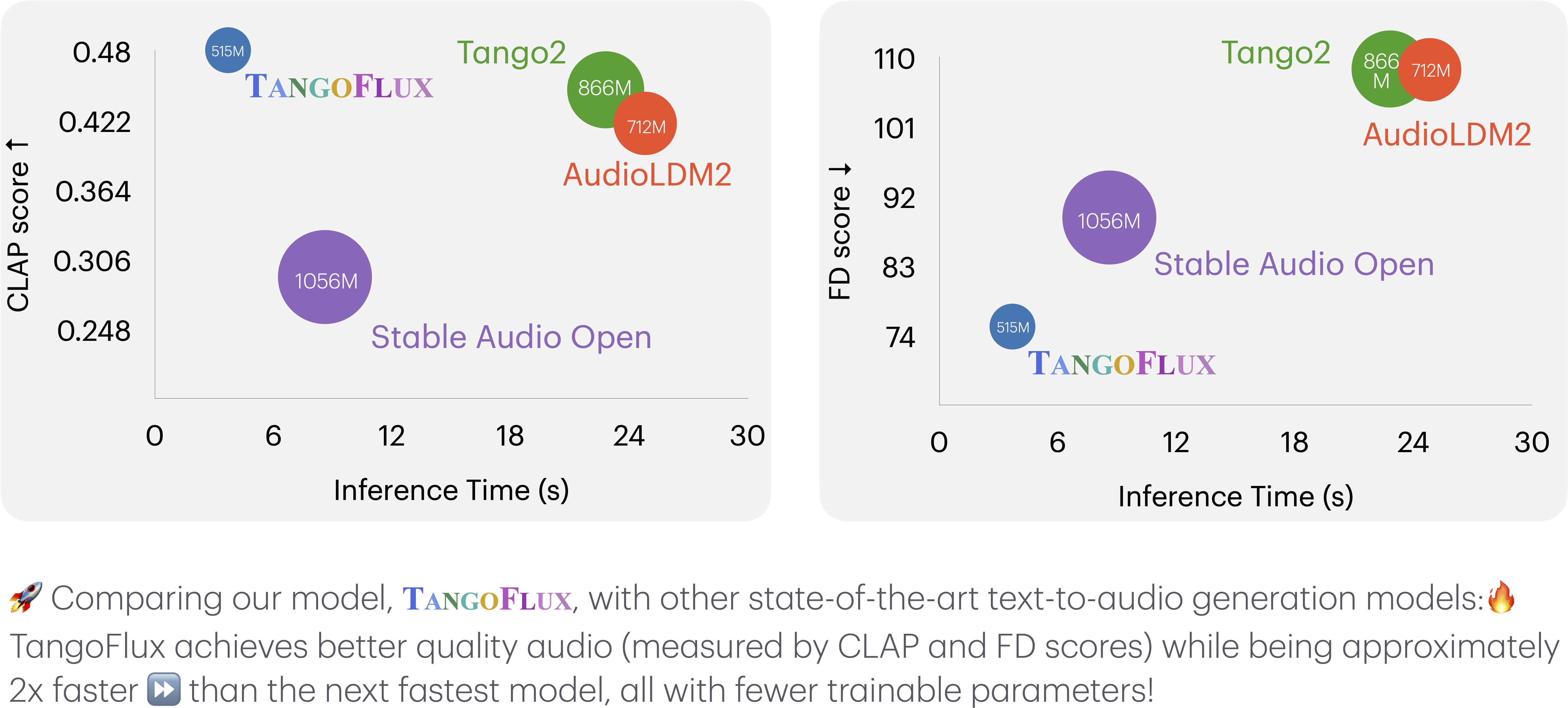
TangoFlux 与其他音频生成模型
这些关键比较指标包括:
- Output Length : Represents the duration of the generated audio.
- FD openl3 : Fréchet Distance.
- KL passt : KL divergence.
- CLAP score : Alignment score.
所有推理时间都在同一个 A40 GPU 上观察到。可训练参数的计数在 #Params 列中报告。
| 型 | 参数 | 期间 | 步骤 | FD 系列openl3 ↓ | 吉隆坡通行证 ↓ | 拍得分 ↑ | 是 ↑ | 推理时间 (s) |
|---|---|---|---|---|---|---|---|---|
| AudioLDM 2 (Large) | 712 米 | 10 秒 | 200 | 108.3 | 1.81 | 0.419 | 7.9 | 24.8 |
| Stable Audio Open | 1056 米 | 47 秒 | 100 | 89.2 | 2.58 | 0.291 | 9.9 | 8.6 |
| Tango 2 | 866 米 | 10 秒 | 200 | 108.4 | 1.11 | 0.447 | 9.0 | 22.8 |
| TangoFlux(基础) | 515 分钟 | 30 秒 | 50 | 80.2 | 1.22 | 0.431 | 11.7 | 3.7 |
| TangoFlux | 515 分钟 | 30 秒 | 50 | 75.1 | 1.15 | 0.480 | 12.2 | 3.7 |