一、PPO优化
PPO的简介和实践可以看笔者之前的文章 强化学习_06_pytorch-PPO实践(Pendulum-v1)
针对之前的PPO做了主要以下优化:
| - | 笔者-PPO | 笔者-PPO2 | ref |
|---|---|---|---|
| data collect | one episode | several episode(one batch) | |
| activation | ReLU | Tanh | |
| adv-compute | - | compute adv as one serires | |
| adv-normalize | mini-batch normalize | servel envs-batch normalize | 影响PPO算法性能的10个关键技巧 |
| Value Function Loss Clipping | - | L V = m a x [ ( V θ t − V t a r ) 2 , ( c l i p ( V θ t , V θ t − 1 − ϵ , V θ t − 1 + ϵ ) ) 2 ] L^{V}=max[(V_{\theta_t} - V_{tar})^2, (clip(V_{\theta_t}, V_{\theta_{t-1}}-\epsilon, V_{\theta_{t-1}}+\epsilon))^2] LV=max[(Vθt−Vtar)2,(clip(Vθt,Vθt−1−ϵ,Vθt−1+ϵ))2] | The 37 Implementation Details of Proximal Policy Optimization |
| optimizer | actor-opt & critic-opt | use common opt | |
| loss | actor-loss-backward & critic-loss-backward | loss weight sum | |
| paramate-init | - | 1- hidden layer orthogonal initialization of weights 2 \sqrt{2} 2; 2- The policy output layer weights are initialized with the scale of 0.01; 3- The value output layer weights are initialized with the scale of 1.0 | The 37 Implementation Details of Proximal Policy Optimization |
| training envs | single gym env | SyncVectorEnv |
相比于PPO2_old.py 这次实现了上述的全部优化,
1.1 PPO2 代码
详细可见 Github: PPO2.py
class PPO:
"""
PPO算法, 采用截断方式
"""
def __init__(self,
state_dim: int,
actor_hidden_layers_dim: typ.List,
critic_hidden_layers_dim: typ.List,
action_dim: int,
actor_lr: float,
critic_lr: float,
gamma: float,
PPO_kwargs: typ.Dict,
device: torch.device,
reward_func: typ.Optional[typ.Callable]=None
):
dist_type = PPO_kwargs.get('dist_type', 'beta')
self.dist_type = dist_type
self.actor = policyNet(state_dim, actor_hidden_layers_dim, action_dim, dist_type=dist_type).to(device)
self.critic = valueNet(state_dim, critic_hidden_layers_dim).to(device)
self.actor_lr = actor_lr
self.critic_lr = critic_lr
self.actor_opt = torch.optim.Adam(self.actor.parameters(), lr=actor_lr)
self.critic_opt = torch.optim.Adam(self.critic.parameters(), lr=critic_lr)
self.gamma = gamma
self.lmbda = PPO_kwargs['lmbda']
self.k_epochs = PPO_kwargs['k_epochs'] # 一条序列的数据用来训练的轮次
self.eps = PPO_kwargs['eps'] # PPO中截断范围的参数
self.sgd_batch_size = PPO_kwargs.get('sgd_batch_size', 512)
self.minibatch_size = PPO_kwargs.get('minibatch_size', 128)
self.action_bound = PPO_kwargs.get('action_bound', 1.0)
self.action_low = torch.FloatTensor([-1 * self.action_bound]).to(device)
self.action_high = torch.FloatTensor([self.action_bound]).to(device)
if 'action_space' in PPO_kwargs:
self.action_low = torch.FloatTensor(PPO_kwargs['action_space'].low).to(device)
self.action_high = torch.FloatTensor(PPO_kwargs['action_space'].high).to(device)
self.count = 0
self.device = device
self.reward_func = reward_func
self.min_batch_collate_func = partial(mini_batch, mini_batch_size=self.minibatch_size)
def _action_fix(self, act):
if self.dist_type == 'beta':
# beta 0-1 -> low ~ high
return act * (self.action_high - self.action_low) + self.action_low
return act
def _action_return(self, act):
if self.dist_type == 'beta':
# low ~ high -> 0-1
act_out = (act - self.action_low) / (self.action_high - self.action_low)
return act_out * 1 + 0
return act
def policy(self, state):
state = torch.FloatTensor(np.array([state])).to(self.device)
action_dist = self.actor.get_dist(state, self.action_bound)
action = action_dist.sample()
action = self._action_fix(action)
return action.cpu().detach().numpy()[0]
def update(self, samples: deque):
state, action, reward, next_state, done = zip(*samples)
state = torch.FloatTensor(np.stack(state)).to(self.device)
action = torch.FloatTensor(np.stack(action)).to(self.device)
reward = torch.tensor(np.stack(reward)).view(-1, 1).to(self.device)
if self.reward_func is not None:
reward = self.reward_func(reward)
next_state = torch.FloatTensor(np.stack(next_state)).to(self.device)
done = torch.FloatTensor(np.stack(done)).view(-1, 1).to(self.device)
old_v = self.critic(state)
td_target = reward + self.gamma * self.critic(next_state) * (1 - done)
td_delta = td_target - old_v
advantage = compute_advantage(self.gamma, self.lmbda, td_delta, done).to(self.device)
# recompute
td_target = advantage + old_v
# trick1: batch_normalize
advantage = (advantage - torch.mean(advantage)) / (torch.std(advantage) + 1e-5)
action_dists = self.actor.get_dist(state, self.action_bound)
# 动作是正态分布
old_log_probs = action_dists.log_prob(self._action_return(action))
if len(old_log_probs.shape) == 2:
old_log_probs = old_log_probs.sum(dim=1)
d_set = memDataset(state, action, old_log_probs, advantage, td_target)
train_loader = DataLoader(
d_set,
batch_size=self.sgd_batch_size,
shuffle=True,
drop_last=True,
collate_fn=self.min_batch_collate_func
)
for _ in range(self.k_epochs):
for state_, action_, old_log_prob, adv, td_v in train_loader:
action_dists = self.actor.get_dist(state_, self.action_bound)
log_prob = action_dists.log_prob(self._action_return(action_))
if len(log_prob.shape) == 2:
log_prob = log_prob.sum(dim=1)
# e(log(a/b))
ratio = torch.exp(log_prob - old_log_prob.detach())
surr1 = ratio * adv
surr2 = torch.clamp(ratio, 1 - self.eps, 1 + self.eps) * adv
actor_loss = torch.mean(-torch.min(surr1, surr2)).float()
critic_loss = torch.mean(
F.mse_loss(self.critic(state_).float(), td_v.detach().float())
).float()
self.actor_opt.zero_grad()
self.critic_opt.zero_grad()
actor_loss.backward()
critic_loss.backward()
torch.nn.utils.clip_grad_norm_(self.actor.parameters(), 0.5)
torch.nn.utils.clip_grad_norm_(self.critic.parameters(), 0.5)
self.actor_opt.step()
self.critic_opt.step()
return True
def save_model(self, file_path):
if not os.path.exists(file_path):
os.makedirs(file_path)
act_f = os.path.join(file_path, 'PPO_actor.ckpt')
critic_f = os.path.join(file_path, 'PPO_critic.ckpt')
torch.save(self.actor.state_dict(), act_f)
torch.save(self.critic.state_dict(), critic_f)
def load_model(self, file_path):
act_f = os.path.join(file_path, 'PPO_actor.ckpt')
critic_f = os.path.join(file_path, 'PPO_critic.ckpt')
self.actor.load_state_dict(torch.load(act_f, map_location='cpu'))
self.critic.load_state_dict(torch.load(critic_f, map_location='cpu'))
self.actor.to(self.device)
self.critic.to(self.device)
self.actor_opt = torch.optim.Adam(self.actor.parameters(), lr=self.actor_lr)
self.critic_opt = torch.optim.Adam(self.critic.parameters(), lr=self.critic_lr)
def train(self):
self.training = True
self.actor.train()
self.critic.train()
def eval(self):
self.training = False
self.actor.eval()
self.critic.eval()
1.2 ppo2_train
其实就是向量环境多个step进行一次ppo update
详细可见 Github: ppo2_train
def ppo2_train(envs, agent, cfg,
wandb_flag=False,
train_without_seed=False,
step_lr_flag=False,
step_lr_kwargs=None,
test_ep_freq=100,
online_collect_nums=1024,
test_episode_count=3,
wandb_project_name="RL-train_on_policy",
add_max_step_reward_flag=False
):
test_env = envs.envs[0]
env_id = str(test_env).split('>')[0].split('<')[-1]
if wandb_flag:
wandb.login()
cfg_dict = cfg.__dict__
if step_lr_flag:
cfg_dict['step_lr_flag'] = step_lr_flag
cfg_dict['step_lr_kwargs'] = step_lr_kwargs
algo = agent.__class__.__name__
now_ = datetime.now().strftime('%Y%m%d__%H%M')
wandb.init(
project=wandb_project_name,
name=f"{algo}__{env_id}__{now_}",
config=cfg_dict,
monitor_gym=True
)
mini_b = cfg.PPO_kwargs.get('minibatch_size', 12)
if step_lr_flag:
opt = agent.actor_opt if hasattr(agent, "actor_opt") else agent.opt
schedule = StepLR(opt, step_size=step_lr_kwargs['step_size'], gamma=step_lr_kwargs['gamma'])
tq_bar = tqdm(range(cfg.num_episode))
rewards_list = []
now_reward = 0
recent_best_reward = -np.inf
update_flag = False
best_ep_reward = -np.inf
buffer_ = replayBuffer(cfg.off_buffer_size)
steps = 0
rand_seed = np.random.randint(0, 9999)
final_seed = rand_seed if train_without_seed else cfg.seed
s, _ = envs.reset(seed=final_seed)
for i in tq_bar:
if update_flag:
buffer_ = replayBuffer(cfg.off_buffer_size)
tq_bar.set_description(f'Episode [ {i+1} / {cfg.num_episode} ](minibatch={mini_b})')
step_rewards = np.zeros(envs.num_envs)
step_reward_mean = 0.0
for step_i in range(cfg.off_buffer_size):
a = agent.policy(s)
n_s, r, terminated, truncated, infos = envs.step(a)
done = np.logical_or(terminated, truncated)
steps += 1
mem_done = done
buffer_.add(s, a, r, n_s, mem_done)
s = n_s
step_rewards += r
if (steps % test_ep_freq == 0) and (steps > cfg.off_buffer_size):
freq_ep_reward = play(test_env, agent, cfg, episode_count=test_episode_count, play_without_seed=train_without_seed, render=False, ppo_train=True)
if freq_ep_reward > best_ep_reward:
best_ep_reward = freq_ep_reward
# 模型保存
save_agent_model(agent, cfg, f"[ ep={i+1} ](freqBest) bestTestReward={best_ep_reward:.2f}")
max_step_flag = (step_i == (cfg.off_buffer_size - 1)) and add_max_step_reward_flag
if max_step_flag:
step_reward_mean = step_rewards.mean()
if (("final_info" in infos) or max_step_flag) and step_i >= 5:
info_counts = 0.0001
episode_rewards = 0
for info in infos.get("final_info", dict()):
if info and "episode" in info:
# print(f"global_step={step_i}, episodic_return={info['episode']['r']}")
if isinstance(info["episode"]["r"], np.ndarray):
episode_rewards += info["episode"]["r"][0]
else:
episode_rewards += info["episode"]["r"]
info_counts += 1
# if(steps % cfg.max_episode_steps == 0):
rewards_list.append(max(episode_rewards/info_counts, step_reward_mean))
# print(rewards_list[-10:]) 0: in buffer_size step not get any point
now_reward = np.mean(rewards_list[-10:])
if max_step_flag:
step_reward_mean = 0.0
if (now_reward > recent_best_reward):
# best 时也进行测试
test_ep_reward = play(test_env, agent, cfg, episode_count=test_episode_count, play_without_seed=train_without_seed, render=False, ppo_train=True)
if test_ep_reward > best_ep_reward:
best_ep_reward = test_ep_reward
# 模型保存
save_agent_model(agent, cfg, f"[ ep={i+1} ](recentBest) bestTestReward={best_ep_reward:.2f}")
recent_best_reward = now_reward
tq_bar.set_postfix({
'lastMeanRewards': f'{now_reward:.2f}',
'BEST': f'{recent_best_reward:.2f}',
"bestTestReward": f'{best_ep_reward:.2f}'
})
if wandb_flag:
log_dict = {
'lastMeanRewards': now_reward,
'BEST': recent_best_reward,
"episodeRewards": episode_rewards,
"bestTestReward": best_ep_reward
}
if step_lr_flag:
log_dict['actor_lr'] = opt.param_groups[0]['lr']
wandb.log(log_dict)
update_flag = agent.update(buffer_.buffer, wandb=wandb if wandb_flag else None)
if step_lr_flag:
schedule.step()
envs.close()
if wandb_flag:
wandb.finish()
return agent
二、 Pytorch实践
2.1 智能体构建与训练
PPO2主要是收集n_envs * n_step的结果序列进行训练,针对Humanoid-v4,需要同时对多个环境进行游戏采样(num_envs = 128),同时环境的步数需要进行尝试(笔者尝试了[60, 64, 70, 75, 80, 100, 120, 159, 164)最终采用n_step=80。这里还有一个非常重要的是需要对环境进行NormalizeObservation。
2.1.1 NormalizeObservation
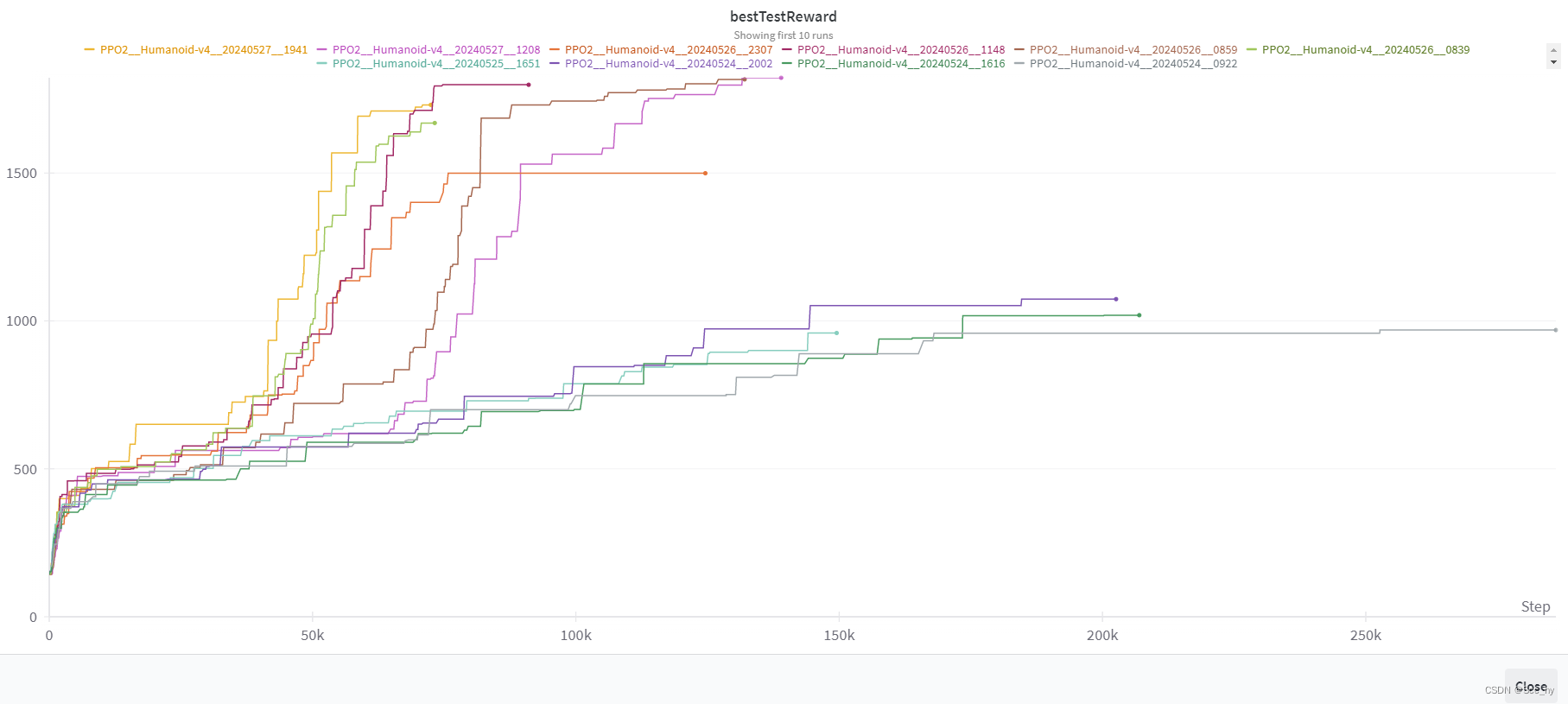
下图是几个训练的比较好的未进行环境Normalize的BestTestReward VS 进行环境Normalize的BestTestReward。 所有1500分以上的均是环境Normalize的。
NormalizeObservation的核心就是RunningMeanStd,每个step都对环境进行迭代
# update_mean_var_count_from_moments
delta = batch_mean - mean
tot_count = count + batch_count
new_mean = mean + delta * batch_count / tot_count
m_a = var * count
m_b = batch_var * batch_count
M2 = m_a + m_b + np.square(delta) * count * batch_count / tot_count
new_var = M2 / tot_count
new_count = tot_count
2.1.2 进行训练
详细可见 Github: test_ppo.Humanoid_v4_ppo2_test
env_name = 'Humanoid-v4'
num_envs = 128 #64
gym_env_desc(env_name)
print("gym.__version__ = ", gym.__version__ )
path_ = os.path.dirname(__file__)
norm_flag = True
reward_flag = False
envs = gym.vector.SyncVectorEnv(
[make_env(env_name, obs_norm_trans_flag=norm_flag, reward_norm_trans_flag=reward_flag) for _ in range(num_envs)]
)
dist_type = 'beta'
cfg = Config(
envs,
# 环境参数
save_path=os.path.join(path_, "test_models" ,f'PPO_Humanoid-v4-{norm_flag}-1'),
seed=202405,
# 网络参数
actor_hidden_layers_dim=[128, 128, 128],
critic_hidden_layers_dim=[128, 128, 128],
# agent参数
actor_lr=4.5e-4,
gamma=0.99,
# 训练参数
num_episode=3000,
off_buffer_size=80, # batch_size = off_buffer_size * num_env
max_episode_steps=80,
PPO_kwargs={
'lmbda': 0.985,
'eps': 0.125,
'k_epochs': 3,
'sgd_batch_size': 2048, # 1024, # 512,
'minibatch_size': 1024, # 512, # 64,
'action_space': envs.single_action_space,
'act_type': 'tanh',
'dist_type': dist_type,
'critic_coef': 1,
'max_grad_norm': 3.5, # 45.5
'clip_vloss': True,
# 'min_adv_norm': True,
'anneal_lr': False, # not work
'num_episode': 3000
}
)
cfg.test_max_episode_steps = 300
cfg.num_envs = num_envs
minibatch_size = cfg.PPO_kwargs['minibatch_size']
max_grad_norm = cfg.PPO_kwargs['max_grad_norm']
agent = PPO2(
state_dim=cfg.state_dim,
actor_hidden_layers_dim=cfg.actor_hidden_layers_dim,
critic_hidden_layers_dim=cfg.critic_hidden_layers_dim,
action_dim=cfg.action_dim,
actor_lr=cfg.actor_lr,
critic_lr=cfg.critic_lr,
gamma=cfg.gamma,
PPO_kwargs=cfg.PPO_kwargs,
device=cfg.device,
reward_func=None
)
agent.train()
ppo2_train(envs, agent, cfg, wandb_flag=True, wandb_project_name=f"PPO2-{env_name}",
train_without_seed=False, test_ep_freq=cfg.off_buffer_size * 10,
online_collect_nums=cfg.off_buffer_size,
test_episode_count=10)
# save norm env
save_env(envs.envs[0], os.path.join(cfg.save_path, 'norm_env.pkl'))
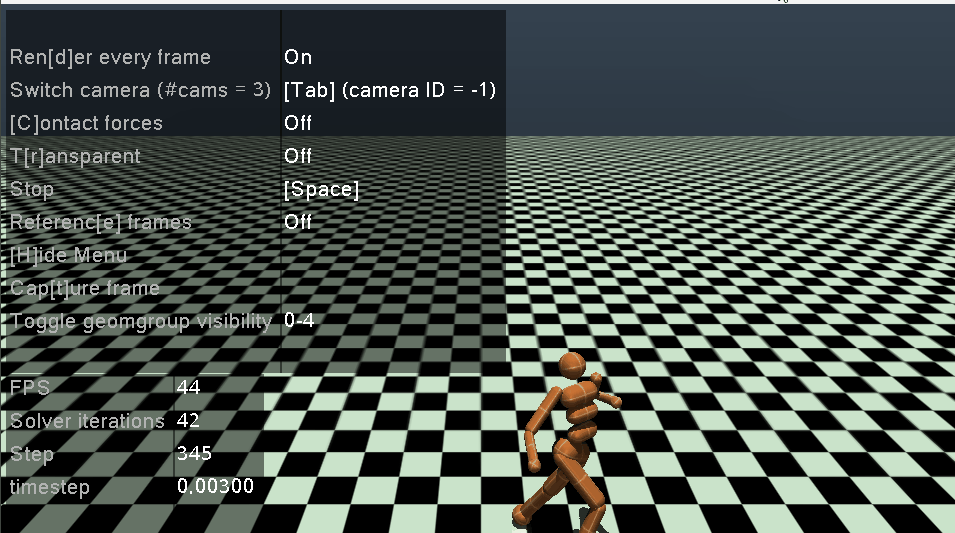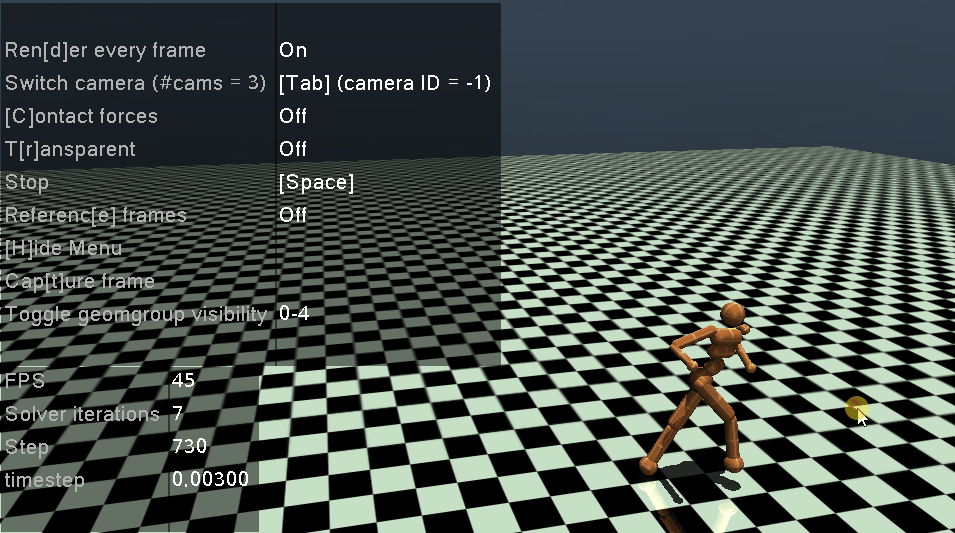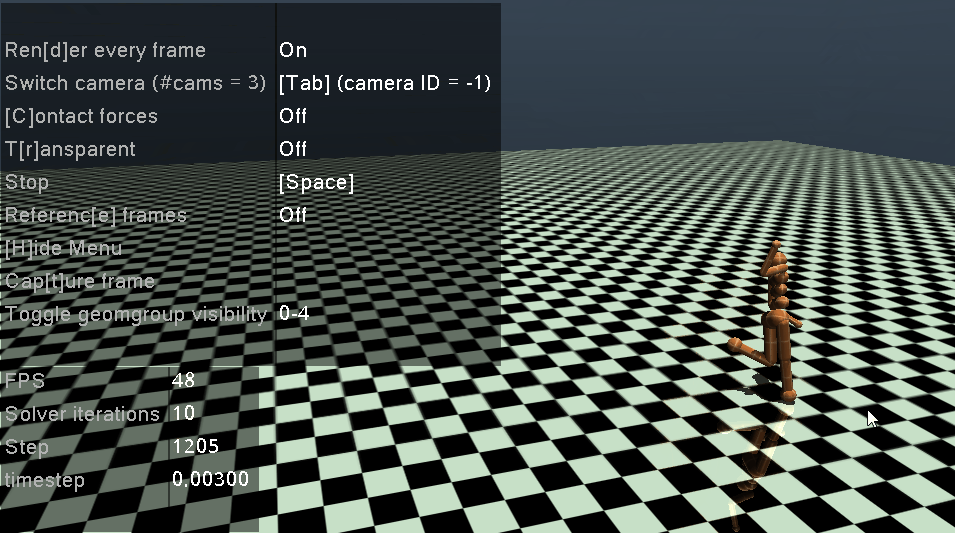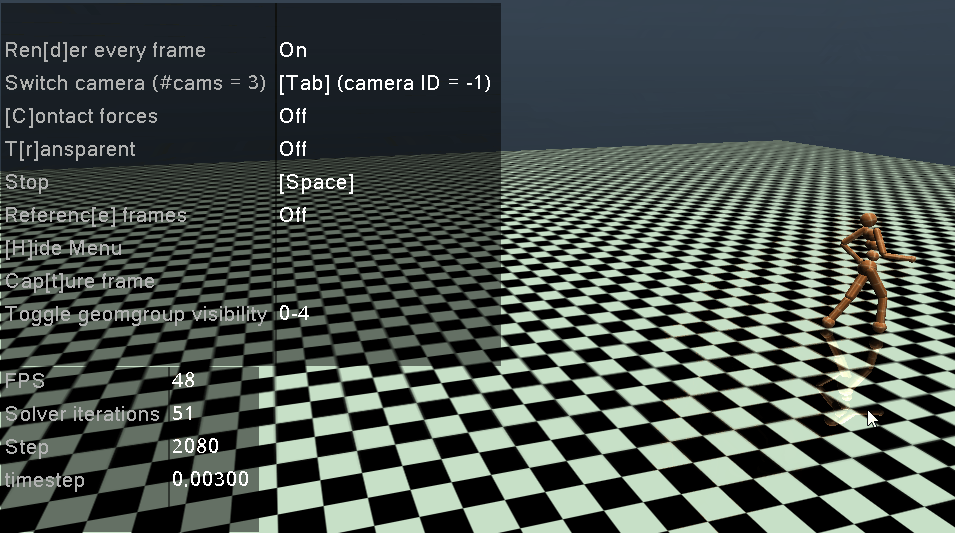
2.2 训练出的智能体观测
最后将训练的最好的网络拿出来进行观察,这里需要注意:我们在训练的时候对环境进行了Normalize,所以在环境初始化的时候,需要将obs_rms (即 RunningMeanStd)中的mean, var, count进行初始化,然后再play
agent.load_model(cfg.save_path)
agent.eval()
with open(os.path.join(cfg.save_path, 'norm_env.pkl'), 'rb') as f:
env = cloudpickle.load(f)
# p = '/home/scc/sccWork/myGitHub/RL/src/test/test_models/PPO_Humanoid-v4-True-2/norm_env.pkl'
# with open(p, 'rb') as f:
# env = cloudpickle.load(f)
obs_rms = env.get_wrapper_attr('env').get_wrapper_attr("obs_rms")
env = make_env(env_name, obs_norm_trans_flag=norm_flag, render_mode='human')()
env.get_wrapper_attr('env').get_wrapper_attr("obs_rms").mean = obs_rms.mean
env.get_wrapper_attr('env').get_wrapper_attr("obs_rms").var = obs_rms.var
env.get_wrapper_attr('env').get_wrapper_attr("obs_rms").count = obs_rms.count
# env = make_env(env_name, obs_norm_trans_flag=norm_flag)()
# cfg.max_episode_steps = 1020
play(env, agent, cfg, episode_count=3, play_without_seed=False, render=True)