前言:记录了总6w字的面经知识点,文章中的知识点若想深入了解,可以点击链接学习。由于文本太多,按类型分开。这一篇是 算法 常问问题总结,有帮助的可以收藏。
1.十大排序
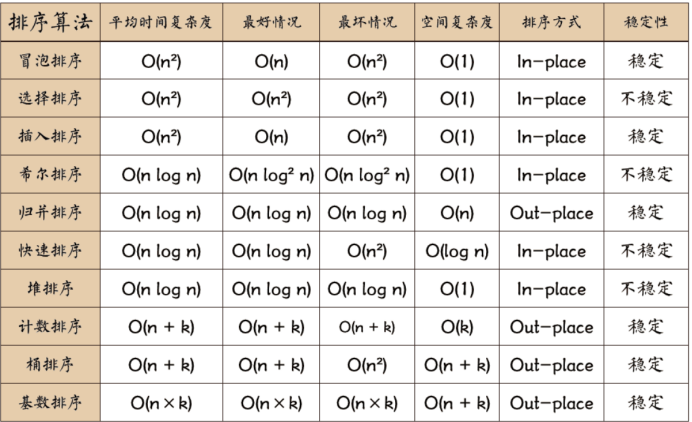
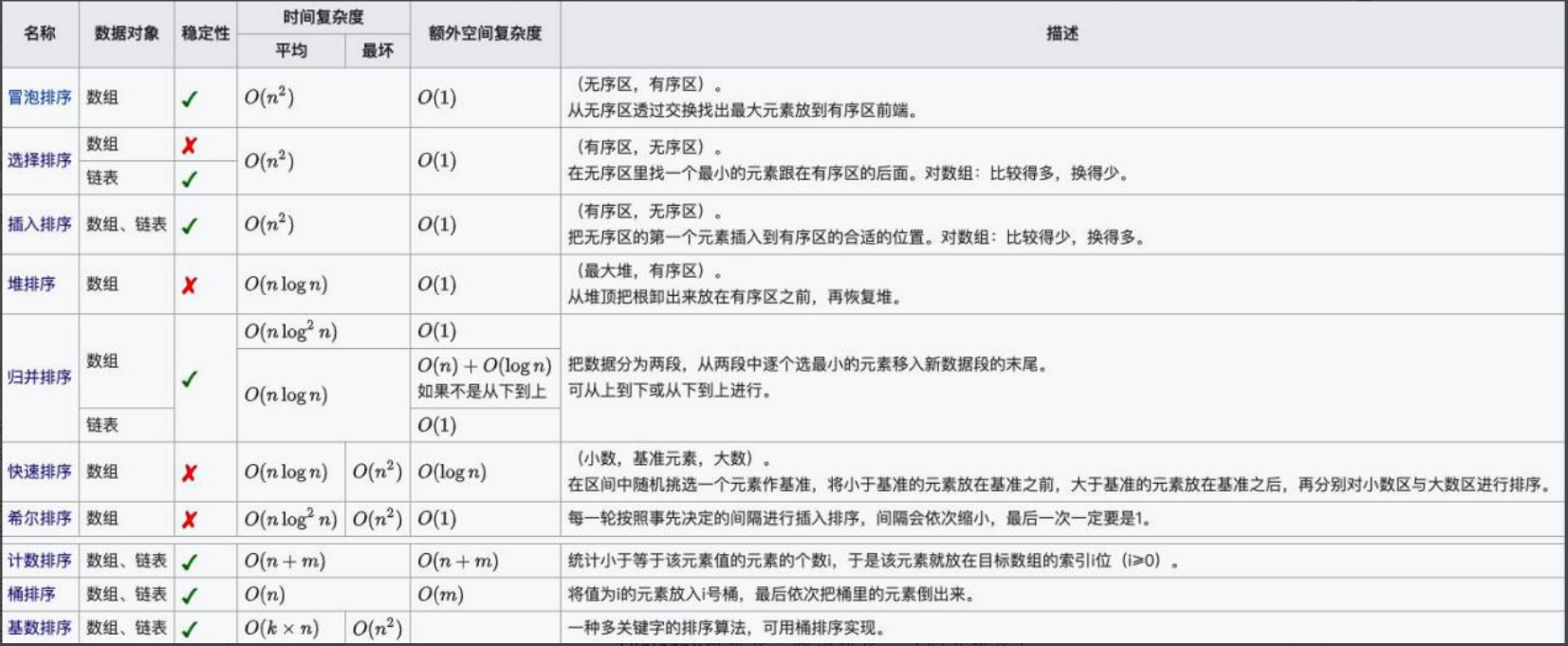
时间复杂度:O(n²) :冒泡排序、选择排序、插入排序
O(nlogn) :堆排序、快速排序、(归并排序)
不稳定的排序:选择排序、快速排序、堆排序、希尔排序。
详细请看: (强烈推荐)https://leetcode.cn/circle/discuss/eBo9UB/#
若基本有序建议用插入排序,不建议用快速排序。
2. 100万的数据选出前1万大的数
利用堆排序、小顶堆实现。
先拿10000个数建堆,然后一次添加剩余元素,如果大于堆顶的数(10000中最小的),将这个数替换堆顶,并调整结构使之仍然是一个最小堆,这样遍历完后,堆中的10000个数就是所需的最大的10000个。建堆时间复杂度是O(mlogm),算法的时间复杂度为O (nmlogm)(n为100,m为10000)。
优化的方法:分治。可以把所有10亿个数据分组存放,比如分别放在1000个文件中。这样处理就可以分别在每个文件的10^6个数据中找出最大的10000个数,合并到一起在再找出1000*10000中的最终的结果。
3. 两个10G 的文件,200m 内存,排序
1.把 10G 大小的文件拆分成 N 个小文件,每个文件 1M 。
2.把每个文件拉倒内存排序,可以并行操作,在内存中直接使用快排,然后写入文件 。
3.对文件做两两合并。
4. A星算法
1.基本原理
避障碍寻路算法有很多,比如:BFS,DFS,Dijkstra等。
对于BFS,它的优点在于可以找到最优的一条路径,缺点是需要遍历整个地图。
对于DFS,它的优点在于不需要遍历整个地图,缺点在于不一定是最优路径。
对于Dijkstar,它的优点在于无差别的遍历当前最短路径,对于查找起始点到任意点的最短路径该算法很有效,缺点是:对于点对点的路径查找很浪费。
对于A*,它能很快的找到一条相对最优的路径,而且搜索的节点比前三个算法都要少。
如果DFS就像一个愣头青,一条路摸到黑的话,那么A*就是一个聪明的愣头青,它虽然也是一条路摸到黑,但是它每一步都会更加逼近终点,而不是像DFS每一步都是随机的。可以理解为A*吸收了DFS和BFS的优点,寻找到的路径优劣程度介于BFS和DFS之间。
简单的说,A*算法就是不停的从起点开始遍历周围的点,找出目前来说消耗最小的点作为新的起点,直到找到终点。
2. 如何找到消耗最小的点
1.F(总代价,走到终点消耗得代价)=G(该点离起点距离)+H(该点离终点距离)。
2.G:从起点到达当前点要走的距离,上下左右都是1,斜边用勾股定理算出约为1.4。
3.H:按照曼哈顿距离计算(d(i,j)=|X1-X2|+|Y1-Y2| )。
4.开启列表open:用来存储可以考虑行进的点,同时存放F、G、H、父对象(从哪个点来)的信息。
5.关闭列表close:用来存储不再考虑的点,存放在关闭列表中的点需要从开启列表移除,同时存放F、G、H、父对象(从哪个点来)的信息。
3. 如何确定路径
1.虽然最优点都在关闭列表中,但是并不能直接使用关闭列表中的点作为路径。
2.而是在关闭列表中从终点开始查找父对象,再查找父对象的父对象。
3.死路:当开启列表为空的时候,说明已经找遍了所有可能的点,寻路失败。
4. 详细流程
1、将起点记录为当前点a。
2、将当前点a放入关闭列表close,并设置父对象为空。
3、将当前点a周围所有能行进的格子放入开启列表,如果周围的点已经在开启列表或者关闭列表中再或者是障碍,就不用管它了。
4、记录当前点a周围所有能行进的格子的F值和父对象(父对象为当前点)。
5、重新在open列表中寻找最优点b(F最小值)将其放入关闭列表,同时在开启列表中移除,每次往关闭列表放点时,要判断该点是否为终点,如果是证明路径已经找完了,结束寻路,如果不是则继续
6、将最优点作为起点b
7、重复上述3、4、5、6步骤,直到找到终点。
8、找到终点,寻路结束,根据终点得父节点返回到起点,为最优路径。
原文链接:读书|杂谈|技术分享-我的编程学习笔记一个分享读书笔记,个人杂谈,技术资源的博客网站
A星基础:
 https://blog.csdn.net/cqs123111/article/details/115303885
https://blog.csdn.net/cqs123111/article/details/115303885