1.Oracle 数据库正则表达式中的 POSIX 元字符
元字符是具有特殊意义的字符,如通配符字符、重复字符、非匹配字符或一个字符范围。
可以在与函数匹配的模式中使用多个预定义的元字符符号。
| 符号 | 说明 |
* | 匹配零个或多个匹配项 |
| | 用于指定选择性匹配项的选择性运算符 |
^/$
| 匹配行的开头和结尾 |
[] | 用于匹配列表(匹配该列表中的任何表达式)的方括号表达式 |
[^exp] | 如果脱字符位于方括号内部,则对表达式取非。 |
{m} | 精确匹配 m 次 |
{m,n} | 至少匹配 m 次,但不超过 n 次 |
[: :] | 指定一个字符类并匹配该类中的任何字符 |
\ | 可以有四种不同的含义:(1) 表示其自身;(2) 引用下一个字符;(3) 引入一个运算符;(4) 不执行任何操作 |
+ | 匹配一个或多个匹配项 |
| | 匹配零个或一个匹配项 |
. | 匹配所支持字符集中的任何字符(NULL 除外) |
() | 对表达式进行分组(视作一个子表达式) |
\n | 向后引用表达式 |
[==]
| 指定等价类 |
[..]
| 指定一个对照元素(如多字符元素) |
2.Perl 正则表达式扩展
除了 POSIX 标准以外,Oracle 还支持受 Perl 影响的常见元字符。为 Perl 兼容性而添加的元字符包括:
| 运算符 | 说明 |
\d | 匹配数字字符 |
\D | 匹配非数字字符 |
\w | 匹配单词字符 |
\W | 匹配非单词字符 |
\s | 匹配空白字符 |
\S | 匹配非空白字符 |
\A | 仅匹配字符串的开头 |
\Z | 仅匹配字符串的结尾或者行结尾之前 |
\z | 仅匹配字符串的结尾 |
* | 匹配 0 次或更多次(非贪婪) |
+ | 匹配 1 次或更多次(非贪婪) |
? | 匹配 0 次或 1 次(非贪婪) |
{n} | 精确匹配 n 次(非贪婪) |
{n,} | 至少匹配 n 次(非贪婪) |
{n,m} | 至少匹配 n 次,但不超过 m 次(贪婪) |
3、REGEXP_LIKE(x,pattern[,match_option])用于在x中查找正则表达式pattern,该函数还可以提供一个可选的参数match_option字符串说明默认的匹配选项。match_option的取值如下:
‘c’ 说明在进行匹配时区分大小写(缺省值);
'i' 说明在进行匹配时不区分大小写;
'n' 允许使用可以匹配任意字符的操作符;
'm' 将x作为一个包含多行的字符串。
4.Oracle使用正则表达式离不开这4个函数:
1。regexp_like
2。regexp_substr
3。regexp_instr
4。regexp_replace
看函数名称大概就能猜到有什么用了。
regexp_like 只能用于条件表达式,和 like 类似,但是使用的正则表达式进行匹配,语法很简单:

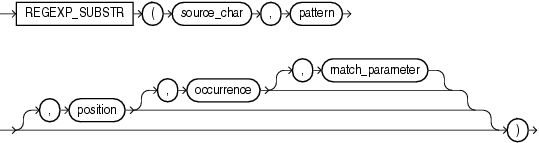
regexp_substr 函数,和 substr 类似,用于拾取合符正则表达式描述的字符子串,语法如下:
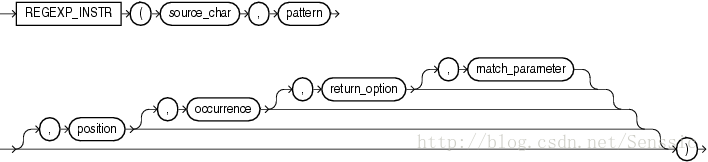
regexp_instr 函数,和 instr 类似,用于标定符合正则表达式的字符子串的开始位置,语法如下:
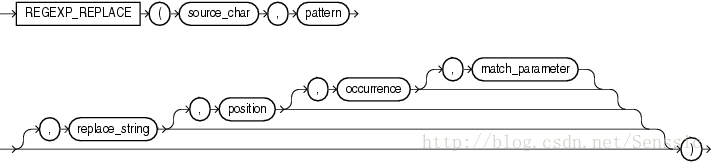
regexp_replace 函数,和 replace 类似,用于替换符合正则表达式的字符串,语法如下:
这里解析一下几个参数的含义:
1。source_char,输入的字符串,可以是列名或者字符串常量、变量。
2。pattern,正则表达式。
3。match_parameter,匹配选项。
取值范围: i:大小写不敏感; c:大小写敏感;n:点号 . 不匹配换行符号;m:多行模式;x:扩展模式,忽略正则表达式中的空白字符。
4。position,标识从第几个字符开始正则表达式匹配。
5。occurrence,标识第几个匹配组。
6。replace_string,替换的字符串。
现在开始实例演练了,在此之前先建好一个表。
create table tmp as
with data as (
select 'like' as id ,'a9999' as str from dual union all
select 'like' ,'a9c' from dual union all
select 'like' ,'A7007' from dual union all
select 'like' ,'123a34cc' from dual union all
select 'substr' ,'123,234,345' from dual union all
select 'substr' ,'12,34.56:78' from dual union all
select 'substr' ,'123456789' from dual union all
select 'instr' ,'192.168.0.1' from dual union all
select 'replace' ,'(020)12345678' from dual union all
select 'replace' ,'001517729C28' from dual
)
select * from data ;
select * from tmp ;
ID STR
------- -------------
like a9999
like a9c
like A7007
like 123a34cc
substr 123,234,345
substr 12,34.56:78
substr 123456789
instr 192.168.0.1
replace (020)12345678
replace 001517729C28
select str from tmp where id='like' and regexp_like(str,'A\d+','i'); -- 'i' 忽略大小写
STR
-------------
a9999
a9c
A7007
123a34cc
select str from tmp where id='like' and regexp_like(str, 'a\d+');
STR
-------------
a9999
a9c
123a34cc
select str from tmp where id='like' and regexp_like(str,'^a\d+');
STR
-------------
a9999
a9c
select str from tmp where id='like' and regexp_like(str,'^a\d+$');
STR
-------------
a9999regexp_substr 例子:
col str format a15;
select
str,
regexp_substr(str,'[^,]+') str,
regexp_substr(str,'[^,]+',1,1) str,
regexp_substr(str,'[^,]+',1,2) str, -- occurrence 第几个匹配组
regexp_substr(str,'[^,]+',2,1) str -- position 从第几个字符开始匹配
from tmp
where id='substr';
STR STR STR STR STR
--------------- --------------- --------------- --------------- ---------------
123,234,345 123 123 234 23
12,34.56:78 12 12 34.56:78 2
123456789 123456789 123456789 23456789
select
str,
regexp_substr(str,'\d') str,
regexp_substr(str,'\d+' ,1,1) str,
regexp_substr(str,'\d{2}',1,2) str,
regexp_substr(str,'\d{3}',2,1) str
from tmp
where id='substr';
STR STR STR STR STR
--------------- --------------- --------------- --------------- ---------------
123,234,345 1 123 23 234
12,34.56:78 1 12 34
123456789 1 123456789 34 234
select regexp_substr('123456789','\d',1,level) str --取出每位数字,有时这也是行转列的方式
from dual
connect by level<=9
STR
---------------
1
2
3
4
5
6
7
8
9
col ind format 9999;
select
str,
regexp_instr(str,'\.' ) ind ,
regexp_instr(str,'\.',1,2) ind ,
regexp_instr(str,'\.',5,2) ind
from tmp where id='instr';
STR IND IND IND
--------------- ----- ----- -----
192.168.0.1 4 8 10
select
regexp_instr('192.168.0.1','\.',1,level) ind , -- 点号. 所在的位置
regexp_instr('192.168.0.1','\d',1,level) ind -- 每个数字的位置
from dual
connect by level <= 9
IND IND
----- -----
4 1
8 2
10 3
0 5
0 6
0 7
0 9
0 11
0 0
select
str,
regexp_replace(str,'020','GZ') str,
regexp_replace(str,'(\d{3})(\d{3})','<\2\1>') str -- 将第一、第二捕获组交换位置,用尖括号标识出来
from tmp
where id='replace';
STR STR STR
--------------- --------------- ---------------
(020)12345678 (GZ)12345678 (020)<456123>78
001517729C28 001517729C28 <517001>729C28综合应用的例子:
col row_line format a30;
with sudoku as (
select '020000080568179234090000010030040050040205090070080040050000060289634175010000020' as line
from dual
),
tmp as (
select regexp_substr(line,'\d{9}',1,level) row_line,
level col
from sudoku
connect by level<=9
)
select regexp_replace( row_line ,'(\d)(\d)(\d)(\d)(\d)(\d)(\d)(\d)(\d)','\1 \2 \3 \4 \5 \6 \7 \8 \9') row_line
from tmp
ROW_LINE
------------------------------
0 2 0 0 0 0 0 8 0
5 6 8 1 7 9 2 3 4
0 9 0 0 0 0 0 1 0
0 3 0 0 4 0 0 5 0
0 4 0 2 0 5 0 9 0
0 7 0 0 8 0 0 4 0
0 5 0 0 0 0 0 6 0
2 8 9 6 3 4 1 7 5
0 1 0 0 0 0 0 2 0