
论文代码:https://github.com/metrics-lab/sim
英文是纯手打的!论文原文的summarizing and paraphrasing。可能会出现难以避免的拼写错误和语法错误,若有发现欢迎评论指正!文章偏向于笔记,谨慎食用
目录
1. 心得
(1)还可以,模型比较别致(虽然空间投影这东西比较...难评就是哪哪都能投,它不是一个绝对的这样就好的理论)
(2)看得出来实验非常用心,对实验整体的设计也不错(不知道是自创还是遵循前人)(主要细节很不错,而不是大体)
(3)任务设计也是比较完备的,考虑的方面比较多
(4)读到文尾发现作者在这短短十页单栏里面塞了好多细节信息,属于是没什么废话了。作者,从头到尾感觉没天花乱坠吹自己模型效果,而是更倾向就谈事实一点。挺好的
(5)篇幅较短加上引用是authoryear的情况下其实写不了几句话。作者更多的选择实验表现(表格数据)都放在附录而不是在正文中挡着理论的位置是很明智的选择。这个领域也不是一个SOTA就杀穿顶会的说法。
2. 论文逐段精读
2.1. Abstract
①Limitation: train and test model on the same dataset
②Task: predict movie clips the subjects watch through udio, video, and fMRI
2.2. Introduction
①为什么fMRI和皮层活动可以放在一起说啊,有无大佬解释一下。(ds: 虽然 fMRI 通常覆盖全脑,7T cortical fMRI 特别关注皮层,尤其是浅层皮层的活动。)
②Target: predict cortical activity by stimulus or predict stimulus by cortical activity
③⭐They can predict unseen movie clips of unseen subjects
④Framework of SIM:

2.3. Related works
①⭐This study contains more subjects, rather than repeatly conduct multiple experiments on the same subject
2.4. Methods
①Spatial and temporal cortical fMRI signals: 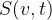
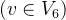
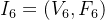
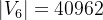
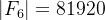
2.4.1. Base architectures
(1)SiT
①fMRI mapping: ribbon-constrained weighted averaging
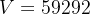
②Sphere resampling: reshape to 

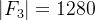
③Triangular patches: 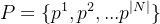
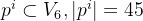
④Feature embedding:
![X^0=\left[X_1^0,...,X_N^0\right]\in\mathbb{R}^{N\times D}](/image/aHR0cHM6Ly9sYXRleC5jc2RuLm5ldC9lcT9YJTVFMCUzRCU1Q2xlZnQlNUJYXzElNUUwJTJDLi4uJTJDWF9OJTVFMCU1Q3JpZ2h0JTVEJTVDaW4lNUNtYXRoYmIlN0JSJTdEJTVFJTdCTiU1Q3RpbWVzJTIwRCU3RA%3D%3D)
⑤Positional embedding:
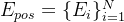
⑥Final sequence:
⑦fMRI feature extraction: 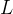
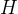
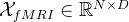
(2)vsMAE
①Original fMRI frames:
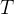
②Masking ratio:
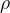
③Encoder: 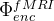
④Mask replacing: replace masked tokens by random embeddings
⑤Reshape sequence and add positional encoding
⑥Decoder: 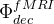

⑦Loss: MSE
2.4.2. Decoding network
①Video and audio input: 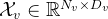
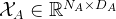
②Embedding model: videoMAE and wav2vec2.0 for the two modalities, respectively
③Multimodal mappers: 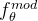
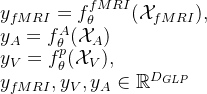
④Positive triplet: fMRI, audio, and video are from the same 3s movie clip
⑤Negative triplet: fMRI, audio, and video are from the different 3s movie clip
⑥Cosine similarity between paired different modalities:
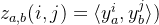
then calculate the probability by:
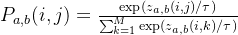
where 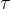
⑦BCE loss:

but they got 3 modalities so they had:

⑧Visual reconstruction:

2.5. Experimental methods
2.5.1. Dataset
①Subjects: 174 with 68 male and 106 female
②Recording sessions: 4 with 15 mins
③Task of subjects: watching movie (1-4.3 mins in length) and having 20s inverval for each
④Participants were told to fixate on a cross on a blank screen
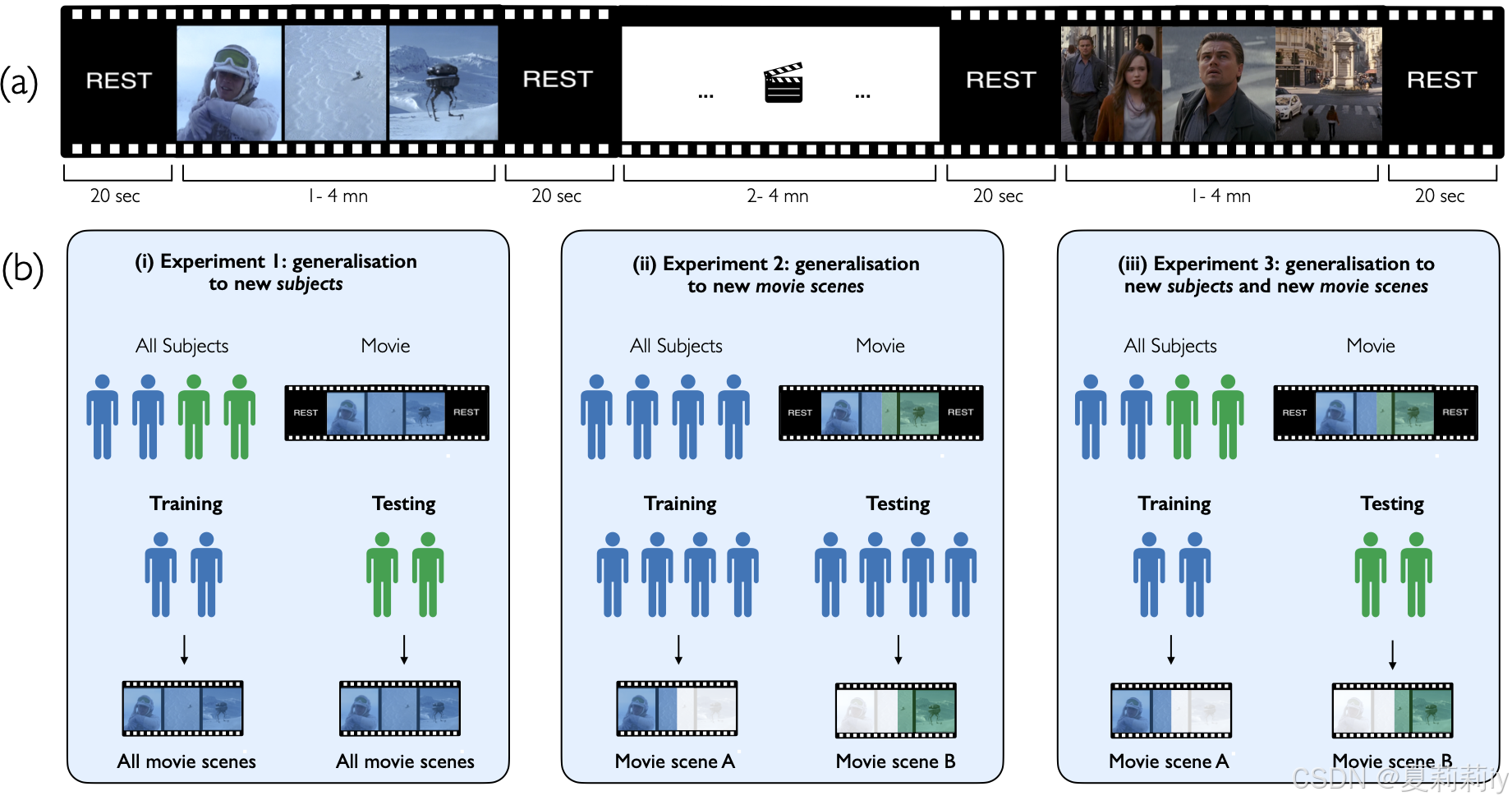
⑤Audio equipment: earbuds
⑥Size of shot: 16:9 with 1024×720
⑦fMRI parameters: TR=1s, TE=22.2ms, spatial resolution=1.6mm^3其他的不说了
⑧Preprocessing: HCP minimal processing surface pipelines
2.5.2. Training
①Data split: 124/25/25 for train/val/test
②Split sex, age, left and right brain hemispheres
③Movie clips: 3s (corresponding to 16 frames of movie stimuli and 3 frames from the cortical fMRI)
④Sampling temporal lag: 6s
⑤SiT backbone: DeiT-small
⑥Experimental settings: AdamW, 3e-4 learning rate, cosine decay, 64 batch size
⑦Training: freeze video and audio encoders and unfreeze multimodal mappers
2.5.3. Inference
①Soft-negative: negative from different movies only; hard negative: negative from the same movies only
2.5.4. Evaluation
①Experimental setting: 上一张图的(b),实验(1)意味着测试集中有新的被试,实验(2)意味着测试集中有新的电影片段,实验(3)意味着测试集中同时有新的被试和新的片段
②Stimulus of movie to brain:
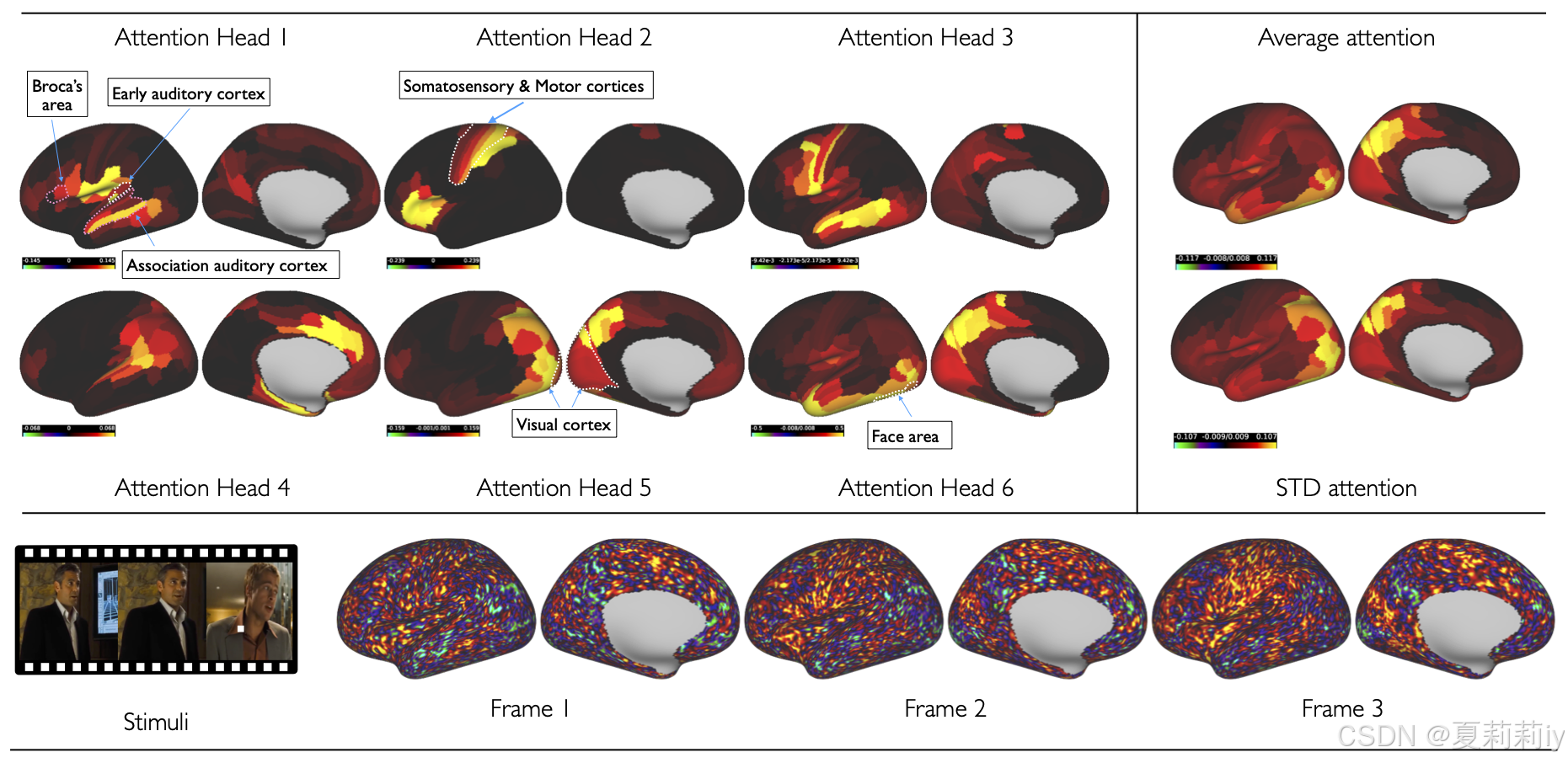
2.6. Results
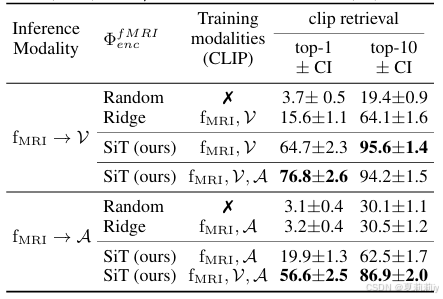
①Performance of experiment 1:
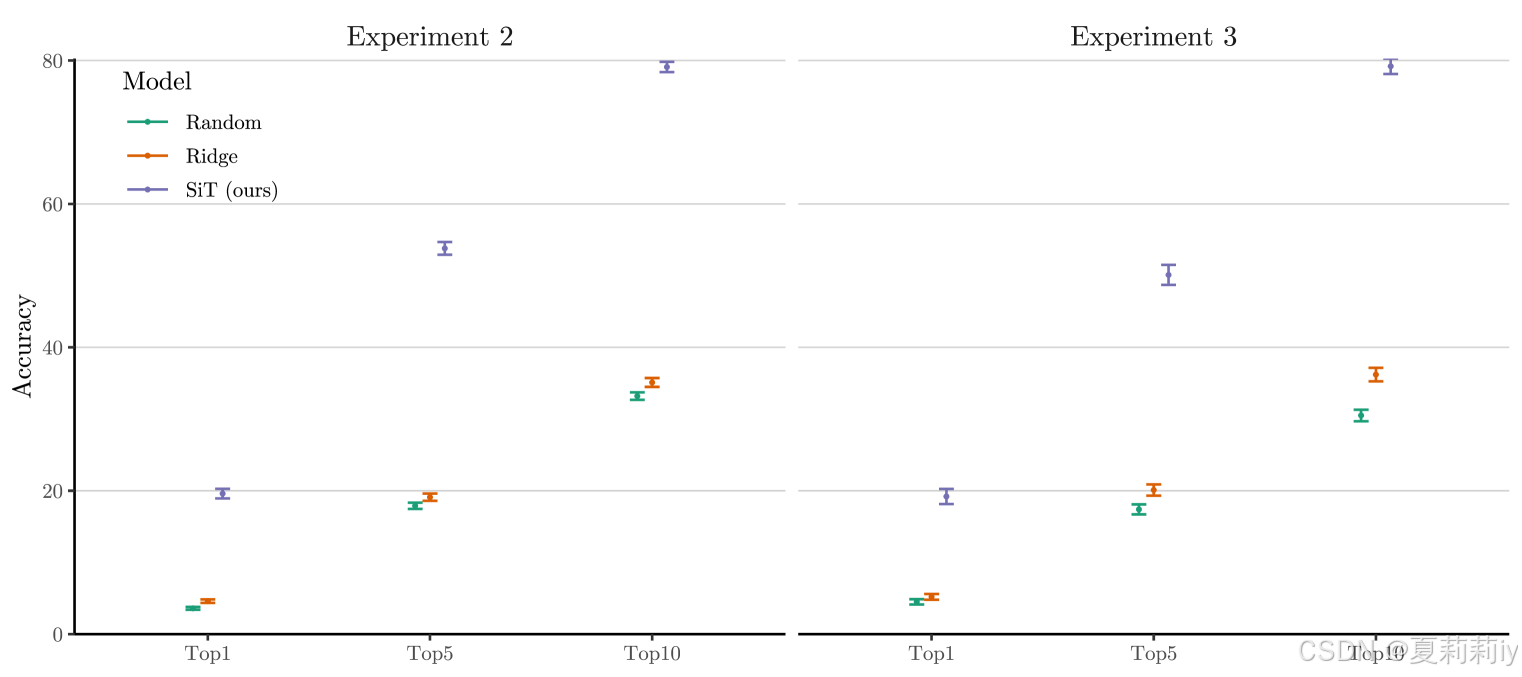
②Soft negative performance:
2.7. Discussion
①Movie clips can be longer
②Types of movie
③Race bias