深度学习之过拟合
过拟合&欠拟合
过拟合:在训练集上表现很好,但在测试集上表现不佳。
欠拟合:训练集上表现不行,测试集上表现也不行。
导致过拟合的原因
1、模型太复杂:模型过于复杂,以至于可以完全记住训练集上的数据,不需要去学习。
2、数据不够多:数据少,容易被记住。
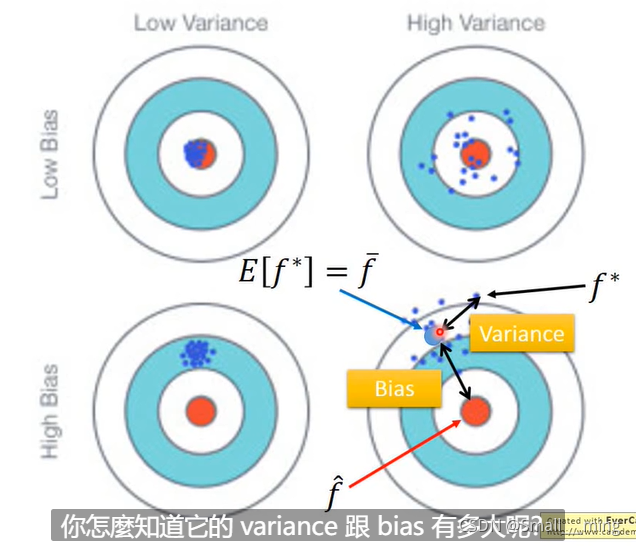
李宏毅老师图:
Bias代指偏差,期望与靶心的差距。
Variance代指误差,实际与期望的差距。
简单的模型Bias大,Variance小。
复杂的模型Bias小,Variance大。
因为简单的模型一根筋,瞄不准。复杂模型瞄的准。所以简单模型Bias大,复杂模型Bias小。
因为简单的模型容易被记住,所以误差小,复杂模型不容易被记住,所以误差大。
Bias的大小可以理解为在训练集上的效果。Variance的大小可以理解为在测试集上的效果。
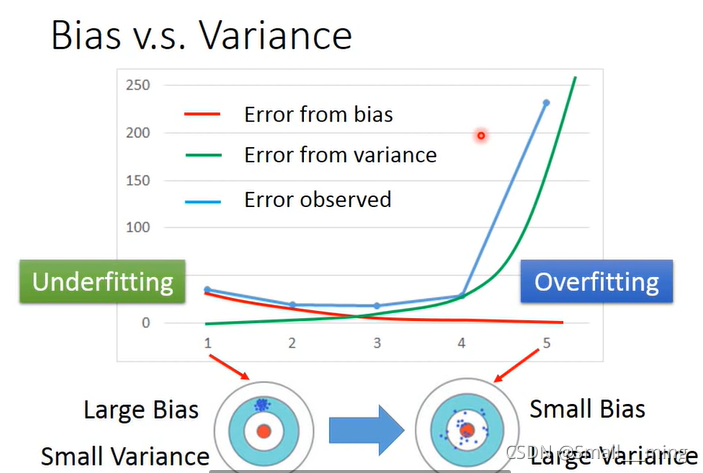
Bias大欠拟合,需要redesign模型,因为你的function set里面可以没有最合适的function。
Variance大过拟合.1、more data 2、Regularization,使曲线变得更平滑。
解决过拟合的方法
正则化
数据增广
增加训练集的数据。
例如:一张图片,可以对其进行反转,加滤镜,裁剪等使其变为多张图片。

加噪声
1、网络权重加噪声:使模型不停的在学习,原本要达到梯度最低点了,给他加一个噪声,使其再次学习。
2、数据标签加噪声。
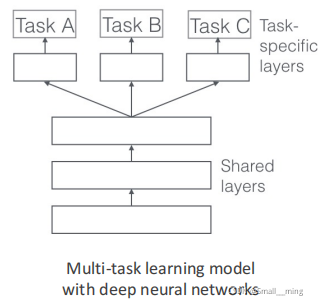
多任务学习
同时做好几件事情,每个任务都不要学太好。
Early Stopping
因为在测试集上的误差不可能是一直增加的,肯定是到达某个点的时候才开始增加。所以我们可以在测试误差最小的时候停止训练。
但是我们不能用测试集来改进模型,用测试集改进模型会导致数据泄露,所以我们就用到了验证集,可以利用验证集来改进模型。
优点:
1、不需要修改数据或者权重等,只需要观察验证误差就可以。
2、可以和其他方法一起用。
缺点:
采用验证集,训练集减小。
两种改进措施:
1、重新训练:通过验证集找到最小误差停止点后,把验证集在丢进训练集重新训练。但这样子有一种刻舟求剑的感觉。因为训练集变大,与原先的最小误差的会有出入。
2、把验证集直接加进去训练:这样的话什么时候停只能靠感觉。
所以这两种改进措施准确度都不敢保证。
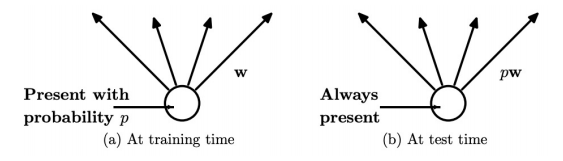
Dropout
训练的时候临时去掉一些神经元。当参数由上层神经元传递到下层时,以P概率激活下层的神经元,随机ban掉一些神经元。这样的话模型就会变得简单,减低模型的复杂度。
如果在预测的时候全部激活所有的神经元,就会有小模型干大模型的事情。所以预测的时候概率p与权重w相乘。
对抗训练
对抗学习就是在训练集上加入对抗样本,加入一些使其产生歧义的样本一起训练。
总结
提示:这里对文章进行总结:
例如:以上就是今天要讲的内容,本文仅仅简单介绍了pandas的使用,而pandas提供了大量能使我们快速便捷地处理数据的函数和方法。