引言
在机器学习的众多算法中,K 近邻算法(K-Nearest Neighbors,简称 KNN)以其简洁而强大的特性占据着重要地位。它既可以用于分类任务,也能在回归任务中发挥作用。无论是处理简单数据集,还是面对复杂的数据分布,KNN 都展现出独特的魅力。本文将深入探讨 KNN 算法的原理、特点、优缺点、实现步骤以及在分类和回归任务中的具体应用。
KNN 算法的基本原理
KNN 算法属于监督学习范畴,其核心思想质朴而直观。对于一个待分类样本,KNN 通过计算它与训练集中各个样本的距离,从中挑选出距离最近的 K 个样本。然后,依据这 K 个样本的类别(分类问题)或值(回归问题)来预测待分类样本的类别或值。
计算距离
距离度量是 KNN 算法的关键环节之一。常用的距离度量方法包括欧氏距离和曼哈顿距离。欧氏距离是在 n 维空间中两点之间的直线距离,其计算公式为:
\(d(x,y) = \sqrt{\sum_{i=1}^{n}(x_i - y_i)^2}\)
曼哈顿距离则是在网格状空间中两点之间的最短距离,计算方式为:
\(d(x,y) = \sum_{i=1}^{n}|x_i - y_i|\)
选择 K 个最近邻
在计算完待分类样本与所有训练样本的距离后,算法会按照距离从小到大排序,选取前 K 个样本作为最近邻。这 K 个样本将用于后续的预测决策。
投票或平均
- 分类问题:在分类场景下,K 个最近邻中出现次数最多的类别被判定为待分类样本的类别。这种方式类似于民主投票,少数服从多数。
- 回归问题:对于回归任务,K 个最近邻的值的平均值就是待分类样本的预测值。通过求平均,综合考虑了多个近邻样本的信息。
KNN 算法的特点
简单易理解
KNN 算法的原理通俗易懂,不需要复杂的数学推导和高深的理论知识。从原理描述到实际实现,整个过程清晰明了,使得初学者也能快速上手。
无需训练
KNN 属于 “懒惰学习” 算法,它在训练阶段并不对数据进行任何模型构建或参数学习。所有的计算都推迟到预测阶段,当有新的待分类样本出现时,才开始计算与训练集样本的距离等操作。
对数据分布无假设
与许多其他机器学习算法不同,KNN 不对数据的分布做任何先验假设。无论是正态分布、均匀分布,还是其他复杂的分布形式,KNN 都能适用,这大大拓宽了其应用范围。
计算复杂度高
然而,KNN 算法也存在明显的缺点,其中之一就是计算复杂度高。由于在预测时需要计算待分类样本与所有训练集样本的距离,当数据集规模较大时,计算量会呈指数级增长,导致预测效率低下。
KNN 算法的优缺点
优点
- 简单易用:算法原理简单,易于理解和实现,无需复杂的编程技巧和数学知识,降低了使用门槛。
- 无需训练:避免了传统算法繁琐的训练过程,节省了时间和计算资源,尤其适用于数据量动态变化,需要频繁更新模型的场景。
- 适用于多分类问题:在处理多分类任务时,KNN 能够自然地通过投票机制确定样本类别,不需要对算法进行额外的修改或复杂的处理。
缺点
- 计算复杂度高:预测阶段对所有训练样本进行距离计算,在大规模数据集上,计算时间和内存消耗都非常可观。
- 对噪声敏感:噪声数据可能成为离群点,由于 KNN 依赖于近邻样本,噪声点可能会对预测结果产生较大干扰,影响模型的准确性。
- 需要选择合适的 K 值:K 值的选择对模型性能影响巨大。K 值过小,模型容易过拟合,对局部噪声敏感;K 值过大,模型则可能欠拟合,无法捕捉数据的局部特征。如何选择一个最优的 K 值,是使用 KNN 算法时面临的一个挑战。
KNN 算法的实现步骤
导入必要的库
在 Python 中实现 KNN 算法,通常需要导入一些常用的库。numpy 用于高效的数值计算,matplotlib 用于数据可视化,sklearn 则提供了丰富的数据集和机器学习工具,方便我们加载数据集、训练模型以及评估模型性能。
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import accuracy_score加载数据集
以经典的鸢尾花数据集为例,使用 sklearn 中的 load_iris 函数可以轻松加载。该数据集包含 150 个样本,每个样本有 4 个特征,目标是将样本分为 3 类。为了便于可视化,我们这里只取前两个特征。
# 加载Iris数据集
iris = datasets.load_iris()
X = iris.data[:, :2] # 只取前两个特征,便于可视化
y = iris.target数据预处理
在应用 KNN 算法之前,通常需要对数据进行标准化处理,确保每个特征对距离计算的贡献相同。这里我们使用 train_test_split 函数将数据集拆分为训练集和测试集,测试集占比 30%,并设置随机种子为 42 以保证结果的可重复性。
# 将数据集拆分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)训练 KNN 模型
使用 sklearn 中的 KNeighborsClassifier 类来创建并训练 KNN 模型。这里我们设置 K 值为 3,即选择 3 个最近邻。
# 创建KNN模型,设置K值为3
knn = KNeighborsClassifier(n_neighbors=3)
# 训练模型
knn.fit(X_train, y_train)预测与评估
训练好模型后,使用测试集数据进行预测,并通过 accuracy_score 函数计算模型的准确率。
# 在测试集上进行预测
y_pred = knn.predict(X_test)
# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
print(f"KNN模型的准确率: {accuracy:.4f}")输出结果:
KNN模型的准确率: 0.7556可视化 KNN 分类结果
为了更直观地理解 KNN 的分类效果,我们可以绘制数据点以及决策边界。通过创建一个二维网格表示不同的样本空间,使用训练好的 KNN 模型预测网格中每个点的类别,并绘制决策边界和数据点。
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import accuracy_score
# 加载Iris数据集
iris = datasets.load_iris()
X = iris.data[:, :2] # 只取前两个特征,便于可视化
y = iris.target
# 将数据集拆分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 创建KNN模型,设置K值为3
knn = KNeighborsClassifier(n_neighbors=3)
# 训练模型
knn.fit(X_train, y_train)
# 在测试集上进行预测
y_pred = knn.predict(X_test)
# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
print(f"KNN模型的准确率: {accuracy:.4f}")
# 绘制决策边界和数据点
h =.02 # 网格步长
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
# 创建一个二维网格,表示不同的样本空间
xx, yy = np.meshgrid(np.arange(x_min, x_max, h),
np.arange(y_min, y_max, h))
# 使用KNN模型预测网格中的每个点的类别
Z = knn.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
# 绘制决策边界
plt.contourf(xx, yy, Z, alpha=0.8)
# 绘制训练数据点
plt.scatter(X[:, 0], X[:, 1], c=y, edgecolors='k', marker='o', s=50)
plt.title("KNN Demo")
plt.xlabel("Feature 1")
plt.ylabel("Feature 2")
plt.show()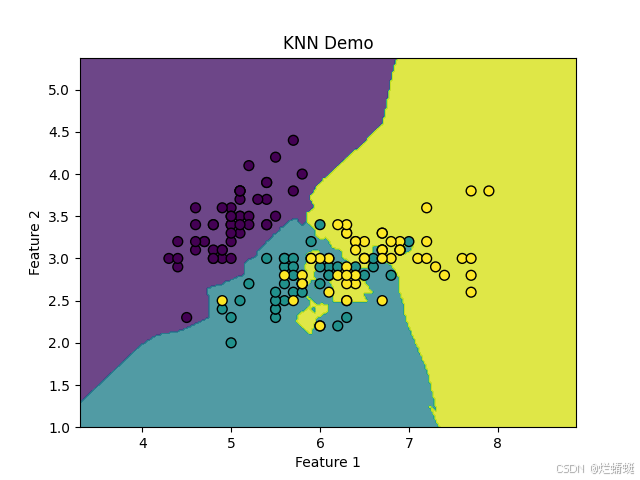
调整 K 值
K 值的选择对模型性能至关重要。我们可以通过交叉验证或可视化方法来寻找最佳 K 值。以下代码通过尝试不同的 K 值,并绘制准确率变化曲线,帮助我们直观地观察 K 值对准确率的影响。
# 尝试不同的K值并绘制准确率变化
k_range = range(1, 21)
accuracies = []
for k in k_range:
knn = KNeighborsClassifier(n_neighbors=k)
knn.fit(X_train, y_train)
y_pred = knn.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
accuracies.append(accuracy)
# 绘制K值与准确率的关系
plt.plot(k_range, accuracies, marker='o')
plt.title("K值与准确率的关系")
plt.xlabel("K值")
plt.ylabel("准确率")
plt.show()使用 KNN 进行回归任务
KNN 同样适用于回归任务(KNN Regression)。在回归任务中,KNN 根据 K 个最近邻的目标值进行平均来预测输出。以下是一个简单的回归任务示例。
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsRegressor
# 生成示例数据
X = np.random.rand(100, 1) * 10
y = np.sin(X).ravel() + 0.1 * np.random.randn(100)
# 拆分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 创建KNN回归模型
knn_reg = KNeighborsRegressor(n_neighbors=5)
# 训练模型
knn_reg.fit(X_train, y_train)
# 在测试集上进行预测
y_pred = knn_reg.predict(X_test)
# 可视化回归结果
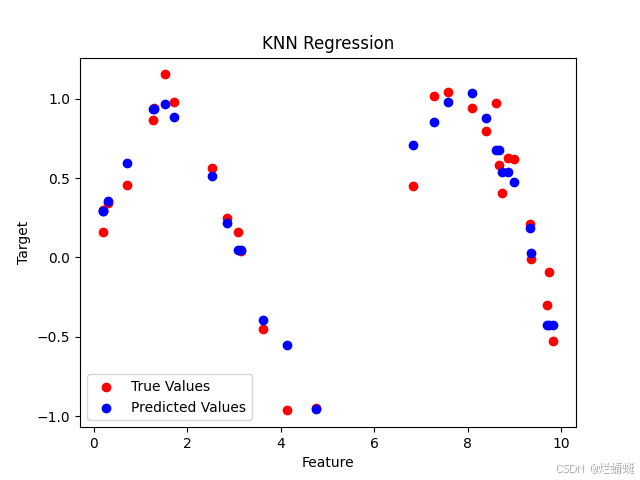
plt.scatter(X_test, y_test, color='red', label='True Values')
plt.scatter(X_test, y_pred, color='blue', label='Predicted Values')
plt.title("KNN Regression")
plt.xlabel("Feature")
plt.ylabel("Target")
plt.legend()
plt.show()在上述代码中,红色点表示真实值,蓝色点表示预测值。通过可视化可以直观地看到 KNN 回归模型对数据的拟合效果。
总结
K 近邻算法作为一种基础而重要的机器学习算法,以其简单易懂、无需训练、对数据分布无假设等优点,在众多领域得到了广泛应用。然而,它也存在计算复杂度高、对噪声敏感以及 K 值选择困难等缺点。在实际应用中,我们需要根据具体的数据集特点和任务需求,权衡 KNN 算法的优缺点,合理调整参数,充分发挥其优势。通过本文对 KNN 算法的原理、特点、实现步骤以及应用案例的详细介绍,希望读者能够对 KNN 算法有更深入的理解,并在实际项目中灵活运用。
无论是在数据挖掘、数据分析,还是在人工智能的其他领域,KNN 算法都将继续发挥其独特的作用,为解决实际问题提供有效的解决方案。希望本文能成为你学习和应用 KNN 算法的有力助手,开启你在机器学习领域探索的新征程。