基于空间注意力的多尺度深度神经网络集成的鼻咽癌肿瘤靶区自动分割
Automatic Segmentation of Gross Target Volume of Nasopharynx Cancer using Ensemble of Multiscale Deep Neural Networks with Spatial Attention
1. 介绍
目的:在各向异性分辨率的CT图像中自动分割鼻咽癌的肿瘤靶区(Gross Target Volume,GTV),同时我们估计分割结果的不确定性
难点:靶区小,分割目标与背景之间存在较大的不平衡。靶区与周围软组织对比度低。GTV边界模糊,会导致训练注释的噪声。通常以较高的面内分辨率和低的面间分辨率获取图像,导致相邻切片的形状发生较大变化。如图一所示:
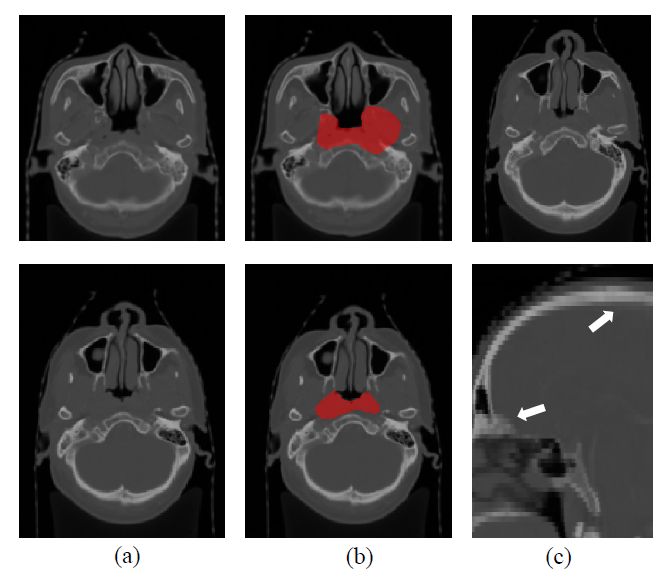
解决方案:提出了一个2.5D的卷积神经网络(CNN)来处理不同的平面内和平面间的分辨率。同时提出了一个空间注意模块,以使网络能够专注于较小的目标,并利用通道注意进一步提高分割性能。
采用多尺度采样方法进行训练,使网络能够学习不同尺度的特征,并结合多模型集成方法提高分割结果的鲁棒性。还对分割结果的进行了不确定性估计
2. 方法
由四部分组成:1)基于HU截断、灰度归一化和图像裁剪的数据处理;2)结合面内注意模块和Project & Excite (PE)块[28]的2.5D CNN进行肿瘤靶区分割;3)基于多尺度信息融合的模型集成方法;4)分割结果的不确定性估计。整体架构如图二所示
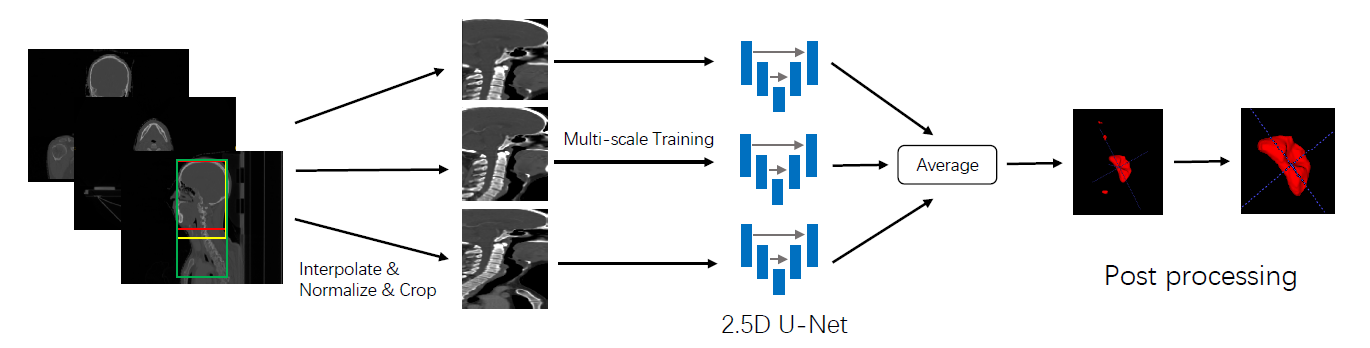
数据预处理
首先将所有图像的强度值截断到[-200,700]HU范围内,增加目标区域的对比度,然后进行归一化。为了保持相同的分辨率,为了得到更好的训练模型,将所有图像在x、y、z方向上的像素间距均匀插值为1 × 1 × 3 mm
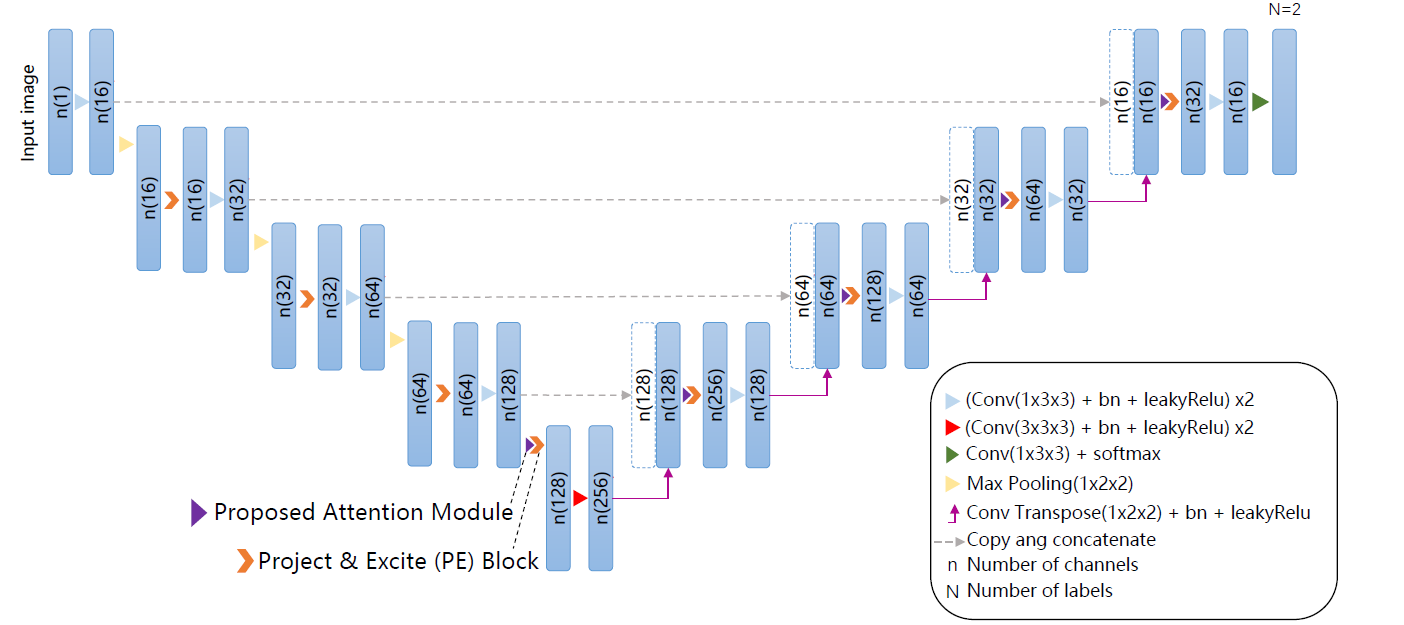
具有平面内空间注意和通道注意的2.5D网络
骨架遵循U-Net 编码-解码器设计,一共有9个卷积块,每个卷积块包含两个卷积层,然后是BN和Leaky ReLU。除第一个卷积块外,每个卷积块前面都有一个PE块,因为第一个卷积块的输入是带一个通道的输入图像,PE块的主要目的是获取通道信息,同时考虑空间信息。注意力模块位于解码器中PE块和底部块的前面,以捕获小GTV区域的空间信息。最后一层由卷积层和提供分割概率的softmax函数组成。
图像输入切片大小和输出切片大小都是16×64×64,即它们具有相同的slice大小
平面内注意力模块
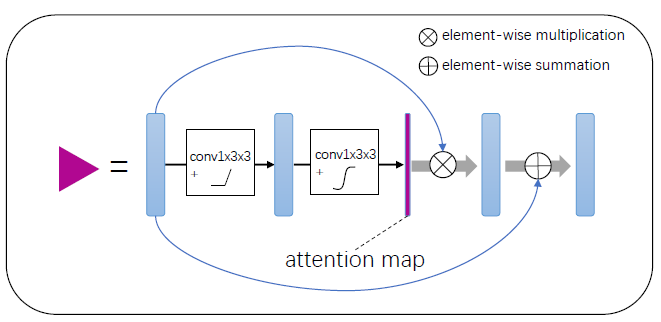
本文提出了一种提高GTV区域分割精度的注意力模块,它可以很好地利用空间信息,使网络能够聚焦于目标区域,如图四所示。注意力模块由两个卷积层组成,核大小为1×3×3。第一个卷积层将通道数量减少到一半,然后是一个ReLU激活函数。第二个卷积层进一步将通道数量减少到1个,然后通过sigmoid激活函数生成空间注意力映射。
空间注意力映射是注意力系数 α i ∈ [ 0 , 1 ] α_i∈[0,1] αi∈[0,1]的单通道特征映射,表示每个空间位置i的相对重要性。然后将空间注意映射与输入特征映射相乘。并添加了残差连接促进更好的收敛。
(PS:感觉是为每层通道乘以一个权重,帮助网络把重要的特征信息学习到,像Squeeze-and-Excitation SE块,两者效果应该差不多)
Project & Excite (PE) Block
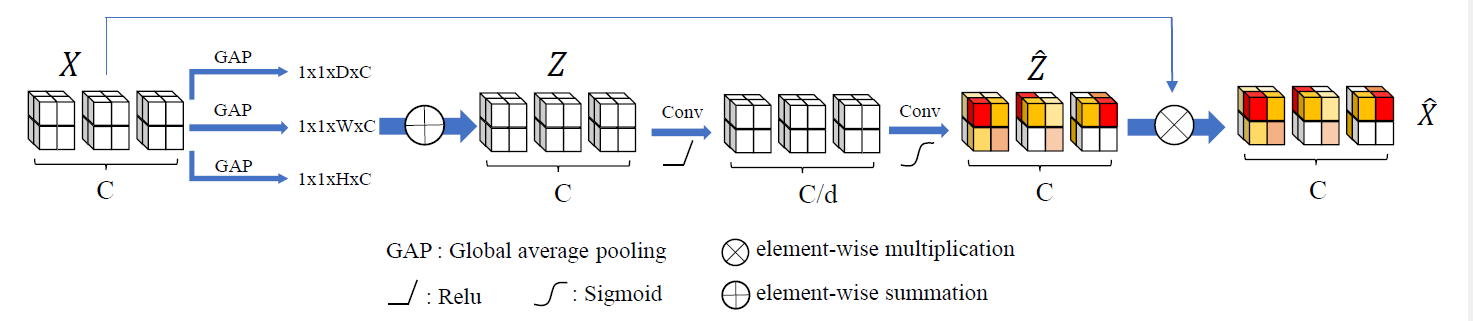
PE块首先沿着每条轴线投影特征映射,得到三个形状分别为D×1×1×C、1×H×1×C和1×1×W×C的特征映射,然后将其展开并相加在一起,最后得到一个形状为D×H×W×C的注意力映射。PE块与通道注意更相关,它给每个通道分配一个体素级别的注意力系数。如图五所示
-
project操作
对输入X的各个维度执行全局平均池化操作
-
Excite操作
将三个投影分别扩展到输入特征映射X的原始形状H×W×D×C,将这些扩展张量相加得到Z作为Excite操作的输入,在进行下列操作, F 1 F_1 F1和 F 2 F_2 F2为全连接层, F 1 F_1 F1将通道数量减少到C/d。然后 F 2 F_2 F2将通道数恢复到原来的数量
F e x ( Z ) = s i g m o i d ( F 2 ( R e L U ( F 1 ( Z ) ) ) ) F_{ex}(Z)=sigmoid(F_2(ReLU(F_1(Z)))) Fex(Z)=sigmoid(F2(ReLU(F1(Z))))
PE块最终的输出为 X ⊙ F e x ( Z ) X⊙F_{ex}(Z) X⊙Fex(Z)
多尺度采样
分了三个尺度对图像进行采样。对于局部采样,我们只对头部区域的patch进行采样。中间采样策略从包括头部和颈部的更大区域采样patch。对于全局采样,它从整个图像区域中获取patch。分别采取这三种策略训练分割模型。
模型集成及分割不确定性
对于每个采样策略,我们训练两个模型,最终得到6个集成模型。对输出概率映射进行平均运算。对平均概率映射进行argmax运算得到初始分割结果。最后取最大连通区域进行后处理,得到最终的分割结果。
通过预测得到对于第i个像素一系列的预测标签
y
i
=
{
y
1
i
,
y
2
i
,
y
3
i
,
.
.
.
,
y
N
i
}
y^i=\{y_1^i,y_2^i,y_3^i,...,y_N^i\}
yi={y1i,y2i,y3i,...,yNi},定义基于熵信息的像素级不确定性为
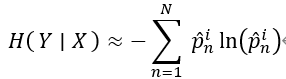
3. 实验结果
使用Dice损失函数对网络进行训练。
评价标准:Dice得分,平均表面距离ASSD,相对volume误差RVE
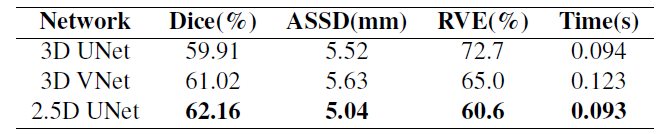
不同网络的比较
对3D UNet、3D VNet、不含PE块和注意力模块的2.5D UNet进行比较。都采用局部采样策略进行训练。表1显示了不同骨架在三种不同评价标准下的性能
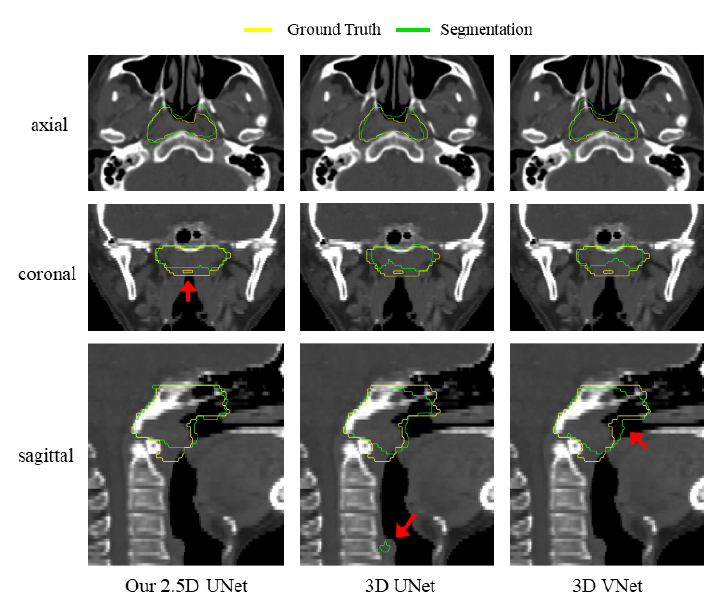
图六显示了三种网络的视觉分割结果
不同模块的效果
探讨了PE块和我们注意力模块(AM)的作用。网络中使用了8个PE块和5个注意力模块。
比较了四种变体:上述我们提出的2.5D UNet,使用PE块的2.5D UNet,使用PE块和AM的2.5D UNet,使用PE块和AG[18]的2.5D UNet,所有变体均采用局部抽样策略进行训练。结果如表二所示
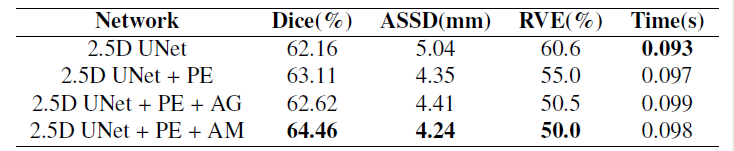
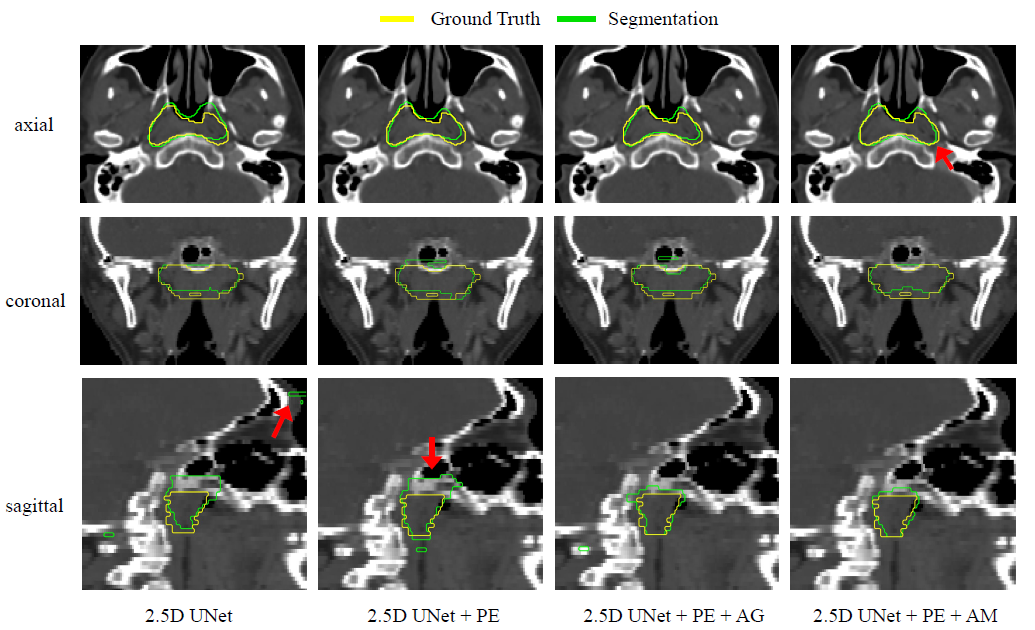
图七显示了三个不同模块的视觉比较。PE块和AM块可以有效地提高分割性能,特别是在GTV的边界处
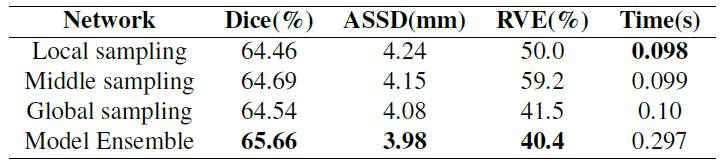
多尺度模型集成的效果
为了融合三个不同尺度的特征信息,本文采用2.5D UNet + PE + AM结构的6种不同模型的概率映射进行平均。模型集成分割结果如图九所示,全局采样通常会导致欠分割,而局部和中间采样通常会导致一些过分割。通过三种尺度的模型集成,可以得到较好的GTV边界分割结果。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Z5cJ0PUO-1614566911979)(https://cdn.jsdelivr.net/gh/A1ANGithub/cloudimg@main/img/NPCGTV图九.png)]
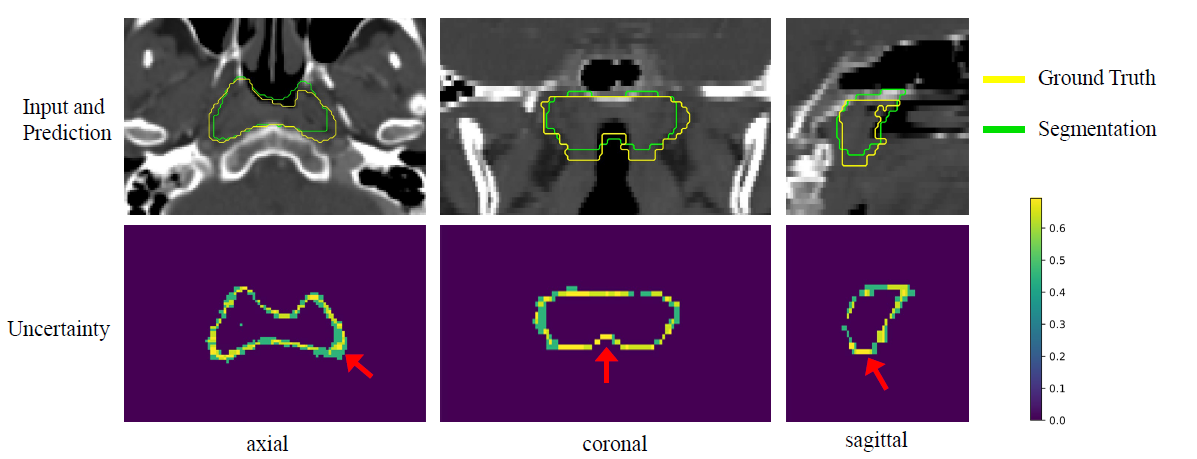
不确定性分割结果
图十为我们的模型集成方法在多尺度训练的CNN下获得的像素级不确定性的可视化。紫色像素的不确定性较低,黄色像素的不确定性较高。不仅在GTV的边界上出现了不确定的分割,在一些难以分割的区域也出现了不确定的分割。随着不确定性的增加,模型的分割错误率也随之增加,这意味着不确定性高的区域通常对应着较高的误分割概率。
参考文献
分割。随着不确定性的增加,模型的分割错误率也随之增加,这意味着不确定性高的区域通常对应着较高的误分割概率。
[外链图片转存中…(img-IwjL9x7z-1614566911980)]
参考文献
[18] O. Oktay, J. Schlemper, L. L. Folgoc, M. Lee, M. Heinrich, K. Misawa, K. Mori, S. McDonagh, N. Y. Hammerla, B. Kainz, et al., Attention u-net: Learning where to look for the pancreas, arXiv preprint arXiv:1804.03999 (2018).