文章目录
—

1. Introduction
我们一直听过一句话叫,“如果说我看得比别人更远些,那是因为我站在巨人的肩膀上。(If I have seen further, it is by standing on the shoulders of giants.)”。“站在巨人的肩膀上”,不仅能看得更远,还能看到更多。这也用来表达我们要善于学习先辈的经验, 一个人的成功往往还取决于先辈们累积的知识。这句话, 放在机器学习中, 这就是今天要说的迁移学习(transfer learning)。
2. Development of Machine Learning
现在的机器人视觉已经非常先进了,有些甚至超过了人类,99.99%的识别准确率都不在话下。这样的成功,依赖于强大的机器学习技术,其中,神经网络成为了领军人物。而 CNN 等,像人一样拥有千千万万个神经联结的结构,为这种成功贡献了巨大力量。但是为了更厉害的CNN,我们的神经网络设计,也从简单的几层网络,变得越来越多,越来越多,越来越多… 为什么会越来越多?
因为计算机硬件, 比如GPU变得越来越强大,能够更快速地处理庞大的信息。在同样的时间内,机器能学到更多东西。可是,不是所有人都拥有这么庞大的计算能力,而且有时候面对类似的任务时,我们希望能够借鉴已有的资源。
3. What is transfer learning ?

这就好比,Google 和百度的关系,facebook和人人的关系,KFC和麦当劳的关系, 同一类型的事业,不用自己完全从头做,借鉴对方的经验,往往能节省很多时间。有这样的思路,我们也能偷偷懒,不用花时间重新训练一个无比庞大的神经网络, 借鉴借鉴一个已经训练好的神经网络就行。
迁移学习是深度学习中十分强大的理念之一,有的时候神经网络可以从一个任务中习得知识,并将这些知识应用到另一个独立的任务中。所以例如,也许你已经训练好一个神经网络,能够识别像猫这样的对象,然后使用那些知识,或者部分习得的知识去帮助您更好地阅读 x 射线扫描图,这就是所谓的迁移学习。如果你要做一个计算机视觉的应用,相比于从头训练权重,或者说从随机初始化权重开始,如果你下载别人已经训练好网络结构的权重,你通常能够进展的相当快,用这个作为预训练,然后转换到你感兴趣的任务上。
计算机视觉的研究社区非常喜欢把许多数据集上传到网上,如果你听说过,比如 ImageNet,MS COCO,或者 Pascal 类型的数据集,这些都是不同数据集的名字,它们都是由大家上传到网络的,并且有大量的计算机视觉研究者已经用这些数据集训练过他们的算法了。有时候这些训练过程需要花费好几周,并且需要很多的GPU,其它人已经做过了,并且经历了非常痛苦的寻最优过程,这就意味着你可以下载花费了别人好几周甚至几个月而做出来的开源的权重参数,把它当作一个很好的初始化用在你自己的神经网络上。
4. How to transfer ?
这里举几个栗子来说明如何进行迁移学习。
4.1 Example 1:物体识别
第一个引用莫凡大神的一个例子:

比如这样的一个神经网络, 我花了两天训练完之后, 它已经能正确区分图片中具体描述的是男人, 女人还是眼镜. 说明这个神经网络已经具备对图片信息一定的理解能力. 这些理解能力就以参数的形式存放在每一个神经节点中. 不巧, 领导下达了一个紧急任务,
要求今天之内训练出来一个预测图片里实物价值的模型. 我想这可完蛋了, 上一个图片模型都要花两天, 如果要再搭个模型重新训练, 今天肯定出不来呀. 这时, 迁移学习来拯救我了. 因为这个训练好的模型中已经有了一些对图片的理解能力, 而模型最后输出层的作用是分类之前的图片, 对于现在计算价值的任务是用不到的, 所以我将最后一层替换掉, 变为服务于现在这个任务的输出层. 接着只训练新加的输出层, 让理解力保持始终不变. 前面的神经层庞大的参数不用再训练, 节省了我很多时间, 我也在一天时间内, 将这个任务顺利完成。
但并不是所有时候我们都需要迁移学习. 比如神经网络很简单, 相比起计算机视觉中庞大的 CNN 或者语音识别的 RNN, 训练小的神经网络并不需要特别多的时间, 我们完全可以直接重头开始训练. 从头开始训练也是有好处的。
4.2 Example 2:放射科诊断
假设你已经训练好一个图像识别神经网络,所以你首先用一个神经网络,并在 ( x , y ) (x,y) (x,y)对上训练,其中 x x x是图像, y y y是某些对象,如猫、狗、鸟或其他东西。现在我们把这个神经网络拿来进行迁移到不同任务中,比如说放射科诊断,就是说阅读 X X X射线扫描图。而我们要做的是把神经网络最后的输出层拿走,就把它删掉,还有进入到最后一层的权重删掉,然后为最后一层重新赋予随机权重,然后让它在放射诊断数据上训练。
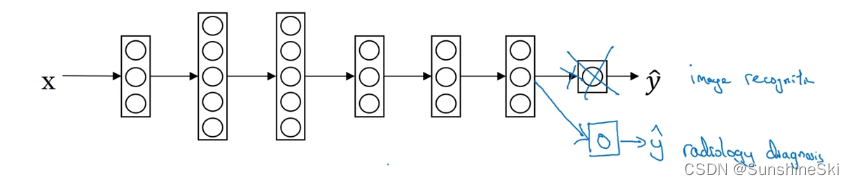
具体来说,在第一阶段训练过程中,当你进行图像识别任务训练时,你可以训练神经网
络的所有常用参数、权重、层,然后你就得到了一个能够做图像识别预测的网络。在训练了这个神经网络后,要实现迁移学习,你现在要做的是,把数据集换成新的
(
x
,
y
)
(x,y)
(x,y)数据对,
x
x
x代表放射科图像,而
y
y
y是预测的诊断,然后初始化最后一层的权重,让我们称之为
w
[
L
]
w^{[L]}
w[L]和
b
[
L
]
b^{[L]}
b[L]随机初始化。
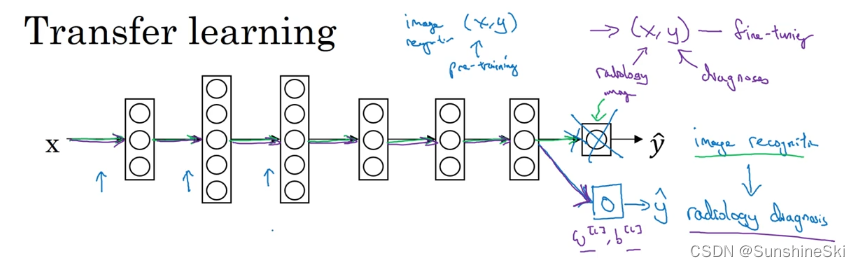
现在,我们在这个新放射科数据集上重新训练网络。要用放射科数据集重新训练神经网络有几种做法:
- 如果你的放射科数据集很小,你可能只需要重新训练最后一层的权重,就是 w [ L ] w^{[L]} w[L]和 b [ L ] b^{[L]} b[L],并保持其他参数不变。
- 如果你有足够多的数据,你可以重新训练神经网络中剩下的所有层。
经验规则是,如果你有一个小数据集,就只训练输出层前的最后一层,或者也许是最后一两层。但是如果你有很多数据,那么也许你可以重新训练网络中的所有参数。
如果你重新训练神经网络中的所有参数,那么这个在图像识别数据的初期训练阶段,有时称为预训练(pre-training),因为你在用图像识别数据去预先初始化,或者预训练神经网络的权重。然后,如果你以后更新所有权重,然后在放射科数据上训练,有时这个过程叫微调(fine tuning)。如果你在深度学习文献中看到预训练和微调,你就知道它们说的是这个意思,预训练和微调的权重来源于迁移学习。
在这个例子里,我们把图像识别中学到知识应用或迁移到放射科诊断上来。有很多低层次特征,比如说边缘检测、曲线检测、阳性对象检测(positive objects),从非常大的图像识别数据库中习得这些能力可能有助于你的学习算法在放射科诊断中做得更好,算法学到了很多结构信息、图像形状信息,了解了不同图像的组成部分,其中一些知识可能会很有用,也许学到线条、点、曲线这些知识只是对象的一小部分,但这些知识有可能帮助你的放射科诊断网络学习更快一些,或者需要更少的学习数据。
4.3 Example 3:语音识别系统
假设你已经训练出一个语音识别系统,现在 x x x是音频片段输入,而 y y y是听写文本,所以你已经训练了语音识别系统,让它输出听写文本。现在如果想搭建一个“唤醒词”或“触发词”检测系统,所谓唤醒词或触发词就是我们说的一句话,可以唤醒家里的语音控制设备,比如你说“Alexa”可以唤醒一个亚马逊 Echo 设备,或用“OK Google”来唤醒 Google 设备,用"Hey Siri"来唤醒苹果设备,用"你好百度"唤醒一个百度设备。要做到这点,你可能需要去掉神经网络的最后一层,然后加入新的输出节点,但有时你可以不只加入一个新节点,或者甚至往你的神经网络加入几个新层,然后把唤醒词检测问题的标签 y y y喂进去训练。其次,这取决于你有多少数据,你可能只需要重新训练网络的新层,也许你需要重新训练神经网络中更多的层。
5. The meaning of transfer learning
迁移学习起作用的场合是,在迁移来源问题中你有很多数据,但迁移目标问题你没有那么多数据。
例如,假设图像识别任务中你有1百万个样本,所以这里有足够多的数据去学习低层次特征,可以在神经网络的前面几层学到如何识别很多有用的特征。但是对于放射科任务,也许你只有一百个样本,所以你的放射学诊断问题数据很少,也许只有100次 X X X射线扫描,所以你从图像识别训练中学到的很多知识可以迁移,并且真正帮你加强放射科识别任务的性能,即使你的放射科数据很少。
对于语音识别,也许你已经用 10,000 小时数据训练过你的语言识别系统,所以你从这10,000 小时数据学到了很多人类声音的特征,这数据量其实很多了。但对于触发字检测,也许你只有 1 小时数据,所以这数据太小,不能用来拟合很多参数。所以在这种情况下,预先学到很多人类声音的特征人类语言的组成部分等等知识,可以帮你建立一个很好的唤醒字检测器,即使你的数据集相对较小。对于唤醒词任务来说,至少数据集要小得多。
所以在这两种情况下,你从数据量很多的问题迁移到数据量相对小的问题。反过来
的话,迁移学习可能就没有太多意义了。所以总结一下什么时候迁移学习是有意义的。
如果你想从任务A学习并迁移一些知识到任务B,那么当任务A和任务B都有同样的输入 x x x时,迁移学习是有意义的。在第二个例子中,A和B的输入都是图像,在第三个例子中,两者输入都是音频。当任务A的数据比任务B多得多时,迁移学习意义更大。所有这些假设的前提都是,你希望提高任务B的性能,因为任务B每个数据更有价值,对任务B来说通常任务A的数据量必须大得多才有帮助,因为任务A里单个样本的价值没有比任务B单个样本价值大。如果你觉得任务A的低层次特征,可以帮助任务B的学习,那迁移学习更有意义一些。
6. Try to finish transfer learning
这个实例来自https://morvanzhou.github.io/tutorials/machine-learning/tensorflow/5-16-transfer-learning/
个人觉得讲的简单生动,很好理解。
6.1 目标
迁移一个图片分类的 CNN (VGG)(这个 VGG 在1000个类别中训练过),我们提取这个 VGG 前面的 Conv layers, 重新组建后面的 fully connected layers, 让它做一个和分类完全不相干的事:分辨出猫和老虎的长度 (regressor)。
6.2 下载数据
为了达到这次的目的, 我们不需要下载所有的1000个分类的所有图片, 只要找到自己感兴趣的类就好 (老虎和猫)。选老虎和猫的目的就是因为他们是近亲, 还是有点像的, 可以增加点难度。如果是飞机和大象的话, 学习难度就被降低了。
上图是这个网址, 你能在 Download 的那个 tag 中, 找到所有图片的 urls, 我将所有老虎和猫的 urls 文件给大家放在下面:
- 老虎 Tiger: imagenet_tiger.txt
- 猫 Kitty cat: imagenet_kittycat.txt
我们可以编写一个代码逐个下载里面的图片. 这个代码我定义成 download(). 下载好后就会被放在 data 这个文件夹中了。因为有些图片url已经过期了, 所以部分过期的需要手动过滤一遍。
因为现在我们不是预测分类结果了, 所以我伪造了一些体长的数据. 老虎通常要比猫长, 所以它们的 distribution 就差不多是下面这种结构(单位cm):
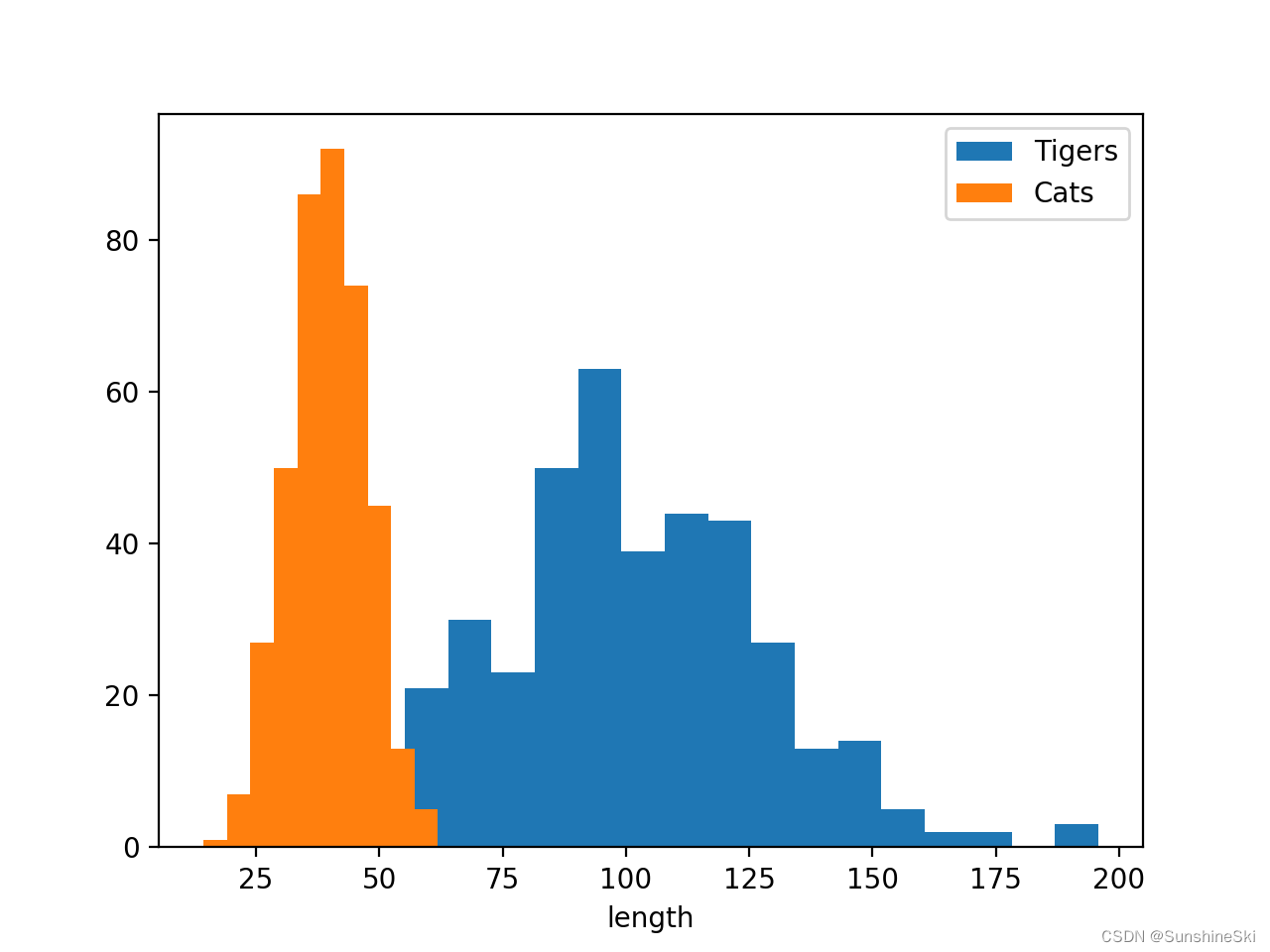
6.3 迁移 VGG
处理好图片后, 我们可以开始弄 VGG 的 pre-trained model. 我使用的是machrisaa 改写的 VGG16 的代码. 和他提供的 VGG16 train 好了的 model parameters, 你可以在这里下载 。
为了做迁移学习, 我对他的 tensorflow VGG16 代码进行了改写. 保留了所有 Conv 和 pooling 层, 将后面的所有 fc 层拆了, 改成可以被 train 的两层, 输出一个数字, 这个数字代表了这只猫或老虎的长度.
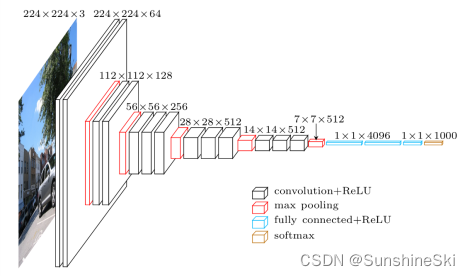
class Vgg16:
def __init__():
# ...前面的层
pool5 = self.max_pool(conv5_3, 'pool5')
# pool5 是最后的 conv 出来的结果
self.flatten = tf.reshape(pool5, [-1, 7*7*512])
self.fc6 = tf.layers.dense(self.flatten, 256, tf.nn.relu, name='fc6')
self.out = tf.layers.dense(self.fc6, 1, name='out')
在 self.flatten 之前的 layers, 都是不能被 train 的. 而 tf.layers.dense() 建立的 layers 是可以被 train 的. 到时候我们 train 好了, 再定义一个 Saver 来保存由 tf.layers.dense() 建立的 parameters.
class Vgg16:
...
def save(self, path='./for_transfer_learning/model/transfer_learn'):
saver = tf.train.Saver()
saver.save(self.sess, path, write_meta_graph=False)
6.4 训练
因为有了训练好了的 VGG16, 你就能将 VGG16 的 Conv 层想象成是一个 feature extractor, 提取或压缩图片中的特征. 和 Autoencoder 中的 encoder 类似. 用这些提取的特征来训练后面的 regressor. 具体代码在这, 下面是简写版:
def train():
xs, ys = ...
vgg = Vgg16(vgg16_npy_path='./for_transfer_learning/vgg16.npy')
print('Net built')
for i in range(100):
b_idx = np.random.randint(0, len(xs), 6)
train_loss = vgg.train(xs[b_idx], ys[b_idx])
print(i, 'train loss: ', train_loss)
vgg.save('./for_transfer_learning/model/transfer_learn')
这里使用的电脑只有CPU,所以只 train 了 100次, 如果是重新开始 train 一个 CNN, 100次绝对少了. 正因为 transfer learning 不用从头 train CNN。否则,用 CPU 估计得一周才能 train 出来这个 VGG 吧。
6.5 测试
我们现在已经迁移好了, train 好了后面的 fc layers, 也保存了后面的 fc 参数. 接着我们提取原始的 VGG16 前半部分参数和 train 好的后半部分参数. 进行测试.
def eval():
vgg = Vgg16(vgg16_npy_path='./for_transfer_learning/vgg16.npy',
restore_from='./for_transfer_learning/model/transfer_learn')
vgg.predict(
['./for_transfer_learning/data/kittycat/000129037.jpg',
'./for_transfer_learning/data/tiger/391412.jpg'])
我输入了一张猫, 一张老虎的图, 这个 VGG 给我预测除了他们的长度:

可以想象, 要让 VGG 达到这个目的, VGG必须懂得区分哪些是猫, 哪些是老虎, 而这个认知, 在原始的 VGG conv 层中就已经学出来了. 所以如果我们拆了后面的层, 将后面的 classifier 变成 regressor, 花费相当少的时间就能训练好。
References:
- https://morvanzhou.github.io/tutorials/machine-learning/ML-intro/2-9-transfer-learning/
- deeplearning.ai