1,数据类型
- 数据类型获取
--类型获取:pg_typeof
select pg_typeof(id) from ...
- 类型转换:
cast或者::
select '5'::int, '2014-09-09'::date;
select int '5', date '2014-09-09';
- 常见操作符:
# + - * / %
3 ^ 3 # 幂
|/36.0 #平方根
||/8.0 #立方根
5! 或 !!5 #阶乘,结果都是120
@-5.0 #绝对值
# & (and) |(or) #(XOR) ~(not) << >>
- 三值逻辑: UNKNOWN
MySQL 、PG 使用三值逻辑 —— TRUE, FALSE 和 UNKNOWN。
任何值与null做比较结果都是Unknow,即select * from a <> 1,不会查出来a is null 的数据。
1)布尔(boolean)
常用操作符:is、and、or、not
| 值 | 表示方法 |
|---|---|
| true | true、'true'、't'、'y'、'1' |
| false | FALSE、'false'、'f'、'no'、'0' |
NULL 或unknown |
2)数值
1>int
| 类型 | 说明 |
|---|---|
| smallint(int2) | 存储有符号或无符号 2 字节整数 |
| int(int4) | 存储有符号或无符号 4 字节整数 |
| bigint(int8) | 存储有符号或无符号 8 字节整数 |
2>decimal(numeric,精确类型的小数)
DECIMAL(p,s) 或 NUMERIC(p,s)
存储精确的数值
精度(p):精度可达1000
刻度(s)
- 适用于货币金额等要求精度的场合。
- 会影响运算速度。
3>float(非精确类型的浮点小数)
| 类型 | 说明 |
|---|---|
| real(float4) | 精度为 8 或更低和 6 个小数位 |
| double(float8) | 精度为 16 或更低和 15 个小数位 |
- 浮点数(float)特殊值:Infinity(正无穷大)、-Infinity、NaN(不是一个数字),sql操作:
update table set x='Infinity' #不区分大小写
另外两个浮点数值做相等性比较时可能不符合预期。
4>money(8字节,货币类型)
完全保证精度,不同国家其输出格式不同。
show lc_monetary; #en_US.UTF-8输出就是$1.22
select '1.22' :: money;
set lc_monetary = 'zh_CN.UTF-8'; #通过这个修改,可输出¥1.22
5>serial(自动递增整数)
| 类型 | 说明 |
|---|---|
| serial(serial4) | 最多 4 字节存储空间 |
| bigserial(serial8) |
pg中的自增字段,通过序列(sequence)来实现的。
create table t (
id serial
);
等价于:
create sequence t_id_seq;
create table t(
id integer not null default nextval('t_id_seq')
);
alter sequence t_id_seq owned by t.id;
6>常用函数
| 函数 | 说明 |
|---|---|
round(1::numeric/4,2) | 第一个参数是数值,第二个参数表示保留小数点几位 |
- 进制转换
-- 平台:mysql
-- 十进制转换为二进制
SELECT BIN(2), conv(2,10,2);
-- 十六进制
SELECT HEX(10), conv(10,10,16);
-- 八进制
SELECT OCT(9);
-- 进制转换 conv(值,值的进制,目标进制)
SELECT conv(0010,2,10);
-- 平台:pg
-- 十进制转换为二进制
SELECT 2::bit(4);
-- 十进制转换为十六进制
SELECT to_hex(10);
-- 十六进制转换为十进制
SELECT x'A'::int;
3)字符( varchar(n)、char(n)、text )
在大多数数据库中,定长char(n)有一定的性能优势;但在pg中,定长变长无区别。建议使用varchar(n)、text。
| 类型 | 最大存储 | 说明 | 备注 |
|---|---|---|---|
varchar(n) | 1GB | 变长; 长度最好为 (2^n)-1 | 在mysql中最大是64kb |
char(n) 或 character(n) | 1GB | 定长,不足补空格; 存储空间为4+n | |
text | 最多 1 GB | 变长,pg自动压缩 TEXT 字符串 |
(2^n)-1是好的磁盘或内存块对齐,对齐块更快。当今“块”的大小更大,内存和磁盘足够快,可以忽略对齐。
1>常用函数说明
- 字符串拼接
--Access和 SQL Server使用 + 号。
--pg、DB2、Oracle、SQLite和Open Office Base 使用 ||。
select 'a' || '_' || 'b'
- 其他
| 功能 | 函数 | 支持平台 | 备注 |
|---|---|---|---|
| 字符串拼接 | CONCAT('My', ' a', 'pp') 或者双竖杠拼接 | mysql、pg | |
| 去空格 | trim(' a bc ') ltrim(' a bc ') | mysql、pg | |
| 去掉多余字符 | select trim('"' from '"测试开发组"'); --测试开发组 | ||
| 字符串长度 | LENGTH('abc') | mysql、pg | |
| 字符串截取 | SUBSTRING('Quadratically',5) SUBSTRING('Quadratically'FROM 5) SUBSTRING('Quadratically',5,LENGTH('Quadratically')-1) 其中第二个参数是其实位置,第三个参数为截取长度(可不填) | mysql、pg | |
| 字符串index获取 | position(',' in 'TO,m') | mysql、pg | |
| 大小写转换 | lower('TOm'),upper('TOm') | mysql、pg | |
| 字符串反转 | reverse('TO,m') | mysql、pg | |
| ASCII转换 | ASCII('2') | mysql、pg | |
| 字符串重复 | REPEAT('a',3) | mysql、pg | 输出aaa |
4)二进制(bytea)
用于存储大型二进制对象(比如图形)的原始二进制数据。
使用的存储空间是 4 字节加上二进制串的长度。
5)位串( bit(n)、bit varying(n) )
0和1组成的字符串。相比二进制类型,在位操作方面更方便。
| 类型 | 说明 |
|---|---|
| bit(n) | 定长 |
bit varying(n) VARBIT(n) | 变长,最大n位。 |
6)日期和时间(date、time、timestamp)
| 类型 | 长度 | 说明 | 举例 |
|---|---|---|---|
| date | 4 | 存储日历日期(年、月、日); 不包含时间和时区 | 2024-01-25 |
| time | 存时区12字节,不存8字节 | 存储天内的时间; 可带时区(也可以不带); 精度:毫秒、微秒、纳秒 | 15:49:23 |
| timestamp | 8字节 | 存储日期和时间; 可带时区(也可以不带); 精度:毫秒、微秒、纳秒 | 2024-01-25 15:51:45 |
| timestamptz | 本地时间,并自动转换为 UTC 时间 | ||
| interval | 存储时间间隔,可以表示两个时间点之间的差值。 |
time、timestamp根据是否包括时区又分为两种类型。interval 表示时间间隔。
- pg中世纪可以精确到毫秒。
1>日期函数
--按照当前事务开始的时间返回数据。在整个事务中值不变。
select current_time; --带时区。current_date,current_time, current_timestamp, current_time,current_timestamp(precision)
select localtime; -- 10:13:42.334327,不带时区。localTimestamp, localTime(precision)...
select now(); --2021-01-20 10:14:37.50845+08 包括时区,秒也保留到了6位小数
select now()::timestamp(0)without time zone; --2021-01-20 10:22:41
select transaction_timestamp(); --当前事务开始的时间戳
--计算日期差值
select daterange_subdiff(
(select latest_timestamp :: date from user limit 1),
(select latest_timestamp :: date from user limit 1 offset 1)
)
--返回实时时间,不受事务影响:
statement_timestamp() --当前语句开始时的时间戳
clock_timestamp() --实时时间戳,同一条sql中也可能不同
timeofday() --类似clock_timestamp,但返回值为text字符串
select age(timestamp '2011-05-02', timestamp '1980-05-01') ;--31 years 1 day
select age(timestamp '2011-05-02') ;--9 years 8 mons 18 days, 相当于age(current_date, timestamp '2011-05-02')
| 函数 | 函数说明 | 举例 | 备注 |
|---|---|---|---|
| to_char | 日期转为格式化字符串 | to_char(time,'YYYY-MM-DD hh24:mi:ss') as time1 | |
| to_date | text转为日期 | to_date(now()::TEXT,'YYYY-MM-DD') | |
| to_timestamp | 转换为timestamp | to_timestamp('2022-10-25 14:30:00', 'YYYY-MM-DD HH24:MI:SS') |
2>日期运算
- 比较:date、timestamp、long可以通过>=、between and来比较
- 计算
WHERE
create_time BETWEEN (
CURRENT_TIMESTAMP - INTERVAL '3 hour' --日期计算,可以是+或者-
)
AND CURRENT_TIMESTAMP
select date'2020-04-02' + integer'7'; --2020-04-09 date
select date'2020-04-02' + interval'1 hour'; --2020-04-02 01:00:00 timestamp
select date'2020-04-02' + time'3:00'; --2020-04-02 03:00:00 timestamp
select time'3:00' + interval'1 hour'; --04:00:00 time
select to_timestamp('2022-10-25 14:30:00', 'YYYY-MM-DD HH24:MI:SS')- interval'29 days'
select -interval'1 hour'; ---01:00:00 interval
select date'2020-04-02' - date'2020-04-01'; --1
--overlaps 两个时间戳重叠为true
select (date '2020-04-02', date '2021-04-02') overlaps
(date '2020-06-02', date '2022-04-02'); --true
3>日期特殊值
| 字符串 | 使用类型 | 描述 |
|---|---|---|
| epoch | date, timestamp | 1970-01-01 00:00:00+00(UNIX系统零时) |
| infinity | timestamp | 时间戳最大值,比任何时间都晚 |
| -infinity | timestamp | 时间戳min |
| now | date, time, timestamp | 当前事务开始时间 |
| today | date, timestamp | 今日午夜 |
| tomorrow | date, timestamp | 明日午夜 |
| yesterday | date, timestamp | 昨日午夜 |
7)枚举
mysql也有枚举类型,用法稍微不同。
create type week as enum ('sun','mon','wed');
create table lwh_duty(person text, weekday week);
insert into lwh_duty values ('mary','sun');
insert into lwh_duty values ('mary','Sun'); --报错,字符串不在枚举类型内。区分大小写。
select * from lwh_duty where weekday = 'Sun'; --报错
--查看枚举类型的定义
select * from pg_enum;
--常见函数
select enum_first('wed'::week);--sun,返回第一个枚举类型。wed可以是任意枚举值即可。同理还有enum_last
select enum_range('wed'::week); --{sun,mon,wed},wed可以是任意枚举值即可。以有序数组的形式返回所有枚举类型
--删除枚举 删除之前要清除所有依赖
drop type enum_lwh_test;
--枚举创建 表字段类型为枚举名即可
create type enum_lwh_test as enum ('confirmed','unconfirmed');
--枚举重命名 会一并修改相关依赖
alter type enum_lwh_test rename to enum_lwh;
--插入新值
ALTER TYPE enum_lwh ADD VALUE 'orange' AFTER 'unconfirmed';
8)几何(pg特有类型)
包括类型:点(point)、直线(line)、线段(lseg)、路径(path)、多边形(polygon)、圆(cycle)。
9)网络地址(cidr、inet、macaddr,pg特有类型)
| 类型名称 | 存储空间 | 描述 |
|---|---|---|
| cidr | 7或19字节 | ipv4或ipv6的网络地址 (总是显示掩码) |
| inet | 7或19字节 | ipv4或ipv6的网络地址或主机地址 |
| macaddr | 6字节 | mac地址 |
--macaddr支持多种格式
select '00e005664477'::macaddr;
select '00E005:664477'::macaddr;--不区分大小写
select '00-E0-05-66-44-77'::macaddr;
select '00E005-664477'::macaddr;
select '00E0.0566.4477'::macaddr;
--运算
select inet'192.0.0.1' < inet '192.0.0.2';-- true。大于等于、不等于<>
select inet'192.0.0.3' << inet '192.0.0.0/24';-- true。包含于<<、包含>>
select ~inet'0.0.0.255'; --255.255.255.0 位非
select inet'0.0.0.255' & inet'0.0.0.255'; --0.0.0.255 位与&,位或|
select inet'192.0.0.50' + 1; --192.0.0.51 + -
select inet'192.0.0.50' - inet'192.0.0.0'; --50
--其它函数……
host(inet) --取主机地址
hostmask(inet) --主机掩码地址
netmask(inet) --子网掩码
10)数组(pg特有类型)
数组的类型可以是数据库内建的类型、用户自定义的类型、枚举或者组合类型。
1>定义
--数组可以定义长度、也可以不给。也可以定义多维数组。但定义长度和多维数组在实际使用中是无效的。如下面两种定义是等价的。
create table lwh01(id int, col1 int[], col2 text[][]);
create table lwh01(id int, col1 int[10], col2 text[]);
2>插入
--插入
--数组通过单引号+大括号来表示,具体分隔符通过以下sql来查询,大部分情况下使用的是逗号分隔(box通过分号分隔,其它用逗号)。
select typname, typdelim from pg_type where typname in ('int4','box');
insert into lwh01 values(1, '{1,2,3}', '{1,2,3}');
insert into lwh01 values(2, '{{1,2,3},{1,2,3}}', NULL);
--通过ARRAY关键字使用数组构造器也可以输入数组
insert into lwh01 values(3, ARRAY[1,2,3], ARRAY['1','2','3']);
--二维数组 array输入
insert into lwh01 values(4, ARRAY[[1,2],[2,3]], NULL);
--数组下标输入。默认从1开始,可以手动指定以0开始输入。
insert into lwh01 values(5, '[0:2]={1,2,3}', NUll);
3>查询
--pg数组下标从1开始(也可以指定下标开始值)
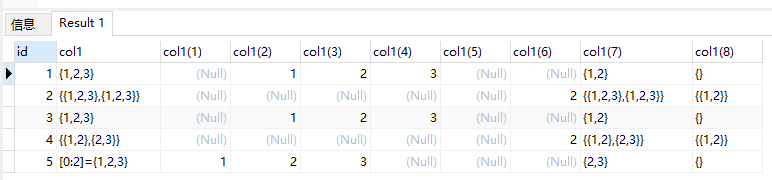
select id, col1, col1[0],col1[1],col1[2],col1[3],col1[4], col1[1][2], col1[1:2], col1[1][1:2] from lwh01;
4>常用操作符
| 操作 | 操作符 | 说明 | 备注 |
|---|---|---|---|
| 等于 | = <> | 两个数组维度、元素个数及值和顺序完全一致为真 | |
| 大于小于 | > < | 按BTree比较函数逐个元素比较 | |
| 包含 | @> | 同理有<@,表示 被包含 | ARRAY[1,2,3] @> ARRAY[1,2] 结果t |
| 重叠 | && | 是否有共同元素。可跨纬度计算。 | ARRAY[1,2,3] && ARRAY[3,4] 结果为t |
| 连接 | ` | ` |
在jpa中,两个数组取交集,即&&运算这样使用:
select ids && '{1}' :: int[] from book_info; --jpa中,sql的::
5>常用函数
| 功能 | 操作 | 备注 |
|---|---|---|
| 数组末尾追加 | array_append(ARRAY[2,3], 3); --{1,2,3} | |
| 数组连接 | array_cat(ARRAY[2,3],ARRAY[2,3]); --{2,3,2,3} | |
| 数组中移除特定值 | array_remove(ARRAY[2,3], 2); --{3} | 只支持一维数组 |
| 数组中替换某个值 | array_replace(ARRAY[2,3],3,5);--{2,5} | 针对所有维度的数据 |
| array2string | array_to_string(ARRAY[2,3],','); --2,3 | |
| string2array | string_to_array('1,2,3', ','); --{1,2,3} | |
| 拼接多个字段 | concat_ws('拼接符号',字段名,more fields) | select concat_ws(',', no, label) from student |
| 拼接多条记录 | string_agg(字段名,'拼接符号') | select string_agg(label,',') from student; |
| 数组拆分 | unnest(arr) | bigint[]类型都可以。unnest(array[10,20,30]) 与array_agg互相转换。 |
| 聚合函数 | array_agg(col) | select id, array_agg(DISTINCT col3) from lwh01 group by id 与unnest互相转换。 通过DISTINCT可去重 |
11)复合类型(用户自定义类型)
类似于C的结构体,
12)xml类型
可以存储xml类型,自动校验是否合法。
13)json/jsonb
postgresql支持两种json数据类型:json和jsonb。与text不同,会自动校验格式是否合法。
1>概念
主要区别在于效率:json类型存储快,使用慢;jsonb类型存储稍慢,使用较快。
json是对输入的完整拷贝,使用时再去解析,所以它会保留输入的空格,重复键以及顺序等。
jsonb是解析输入后保存的二进制,它在解析时会删除不必要的空格和重复的键,顺序和输入可能也不相同。使用时不用再次解析。
json类型和pg类型映射:
| json类型 | pg类型 | 备注 |
|---|---|---|
| string | text | |
| number | numeric | json中没有pg的“NAN”和“infinity”值 |
| boolean | boolean | json仅支持小写的true false |
| null | (none) | sql中NULL表示的意思不同 |
2>常用函数和操作符
json和jsonb的操作与函数基本通用。
①数组操作
注:json和jsonb通用。
| 说明 | 操作符 | 举例 | 备注 |
|---|---|---|---|
| 生成数组 | ARRAY | ARRAY[11] | |
| 生成数组 | json_build_array() | json_build_array(1,2,'3',4,5) | |
| 生成数组 | array_to_json() | array_to_json('{{1,5},{99,100}}'::int[]); --[[1,5],[99,100]] | |
| 数组长度 | jsonb_array_length() | jsonb_array_length('[1,2,3]'); --3 | |
| 取出数组中所有元素 | jsonb_array_elements() | select * from jsonb_array_elements('[1,true, [2,false]]') | json_array_elements_text同理,返回text |
| 取出index对应数据(json) | -> | select '[8,10,11]'::json->2 | 数组index从0开始 |
| 取出index对应数据(text) | ->> | select '[8,10,11]'::json->>2 | 数组index从0开始 |
| 数组是否包含某些top-level keys | ?& | '["a", "b"]'::jsonb ?& array['a', 'b']; --true | |
| 数组是否有交集 | ?| | '["a", "b", "c"]'::jsonb ?| array['b', 'd'] | 结果: true |
| 数组求并集 | '["a", "b"]'::jsonb || '["c", "d"]'::jsonb; | ||
| 数组去除某个索引 | - | '["a", "b"]'::jsonb - 1; --["a"] | |
| 数组去除某个路径的键 | #- | '["a", {"b":1}]'::jsonb #- '{1,b}'; --["a", {}] | 备注:1为数组index,b为map的key |
②map操作
注:json和jsonb通用。
| 说明 | 操作符 | 举例 | 备注 |
|---|---|---|---|
| 从map中取值(json) | -> | '{"a": {"b":"foo"}}'::json->'a' 结果: "{"b":"foo"}" | 按key取值 |
| 从map中取值(text) | ->> | '{"a": {"b":"foo"}}'::json->>'a' 结果: {"b":"foo"} | 按key取值 |
| 从map中取值(json) | #> | '{"a": {"b":"foo"}}'::json #>'{a,b}' 结果: "foo" | 按路径取值 |
| 从map中取值(text) | #>> | '{"a": {"b":"foo"}}'::json #>>'{a,b}' 结果: foo | 按路径取值 |
| 从map中取值 | json_extract_path()json_extract_path_text() | 1. json_extract_path('{"f2":{"f3":1},"f4":{"f5":99,"f6":"foo"}}','f4') 2. json_extract_path('{"f2":{"f3":1},"f4":{"f5":99,"f6":"foo"}}','f4','f6') | 按路径取值 |
| map是否包含某个键值对 | @> | '{"a":1, "b":2}'::jsonb @> '{"b":2}'::jsonb结果: true | <@同理 |
| map是否包含某个top-level keys | ? | '{"a":1, "b":2}'::jsonb ? 'b' 结果: true | |
| map key值与数组是否有交集 | ?| | '{"a":1, "b":2, "c":3}'::jsonb ?| array['b', 'd'] | |
| map.remove(key) | - | '{"a": "b"}'::jsonb - 'a' 结果: {} | |
| map.remove(keys) | - | '{"a": "b", "c": "d"}'::jsonb - '{a,c}'::text[] 结果: {} | |
| row转换为map | row_to_json() | 1. row_to_json(row(1,'foo','1')) 结果:{"f1":1,"f2":"foo","f3":"1"} 2. select row_to_json(live_area_info) from live_area_info; 3. select row_to_json(row(area_id,description)) from live_area_info; | |
| 将键值对转换为map | json_build_object() | json_build_object('foo',1,'bar',2) 结果:{"foo" : 1, "bar" : 2} | |
| 将键值对转换为map | json_object() | 1. json_object('{a, 1, b, "def", c, 3.5}') 结果:{"a" : "1", "b" : "def", "c" : "3.5"} 2. json_object('{{a, 1},{b, "def"},{c, 3.5}}') 结果:{"a" : "1", "b" : "def", "c" : "3.5"} 3. json_object('{a, b}', '{1,2}') 结果:{"a" : "1", "b" : "2"} | |
| 将map转换为键值对 | json_each(json, keyName, valueName) | select * from json_each('{"a":"foo", "b":"bar"}') | json_each_text(json, keyName, valueName)同理 |
| 多个map求并集 | || | data::jsonb || '{"uptate_minute": "10"}'::jsonb |
③常用函数
select to_json('Fred said "Hi."'::text); --"Fred said \"Hi.\"" string2json
select json_typeof('-123.4'); --number
--修改jsonb jsonb_set
jsonb_set('[{"f1":1,"f2":null},2,null,3]', '{0,f1}','[2,3,4]', false)
-- attributes为jsonb类型字段(对象转成的json)
-- 第一个参数表示jsonb对象,第二个参数表示路径text[],第三个参数表示value(jsonb对象),第四个值表示无此值是否新建(默认为true)
原值:{"a":"1"}
update user_test set attributes = jsonb_set(attributes,'{a}','"0"'::jsonb, false) where id = '8888';
执行后:{"a":"0"}
3>索引
json类型没办法直接建索引,但是可以建函数索引。
jsonb类型的列上可以建索引,GIN索引可以高效的从jsonb内部的key/value对中搜索数据。(BTree索引效率较低)
根据生成GIN key的方式不同,GIN索引创建方式有2种:
- jsonb_ops
原理:jsonb_ops调用gin_extract_jsonb函数生成key,这样每个字段的json数据中的所有键和值都被转成GIN的key;
场景:可以用于路径查询之外的其他查询
--使用默认的操作符jsonb_ops创建GIN索引:
--每个key和value都作为一个单独的索引项
--如:{“foo”:{“bar”:“baz”}},会创建3个索引项:“foo” “bar” “baz”
create index idx_name on table_name using gin(index_col);
- jsonb_path_ops
原理:jsonb_path_ops使用函数gin_extract_jsonb_path抽取:如果将一个jsonb类型的字段值看做一颗树,叶子节点为具体的值,中间节点为键,则抽取的每个键值实际上时每个从根节点到叶子节点的路径对应的hash值。
场景:用叶子节点的路径做查询条件时会比较快。
--使用jsonb_path_ops操作符建GIN索引:(推荐)
--为每个value创建一个索引项
--如:{“foo”:{“bar”:“baz”}},会创建1个索引项:“foo” “bar” “baz”组合成一个Hash值作为索引项。因为索引相对较小,带来性能的提升。
create index idx_name on table_name using gin(index_col jsonb_path_ops);
14)range(范围类型,pg特有类型)
主要用于范围快速搜索。
直接通过库里的开始值和结束值进行范围搜索效率较低,而使用range类型,通过创建空间索引的方式来执行范围搜索会大大提高效率。
15)对象标识符
16)伪类型
不能作为pg的字段,主要用于声明函数的参数和结果类型。
17)其他类型
| 类型 | 描述 | 备注 |
|---|---|---|
| UUID | 128字节的数字。 | pg核心库没有提供生成UUID的函数 |
| pg_lsn | pg9.4以上版本支持。用于表示LSN的数据类型,64位大整数。 | LSN表示WAL日志的位置 |
2,库操作SQL
--建库
create database children;
--删库
drop database children;
--重命名
ALTER DATABASE old_database_name MODIFY NAME = new_database_name;
--查看数据库
show databases;
--调用数据库
use children;
查询当前数据库:
select current_database();
查询当前用户:
select user; 或者:select current_user;
3,模式SQL
- pg不指定模式的话默认public模式。
--创建
CREATE SCHEMA schema_name;
4,表操作
1)建表
--创建public模式下的表
CREATE TABLE if not exists public.stu_info(
FOREIGN KEY (ID) REFERENCES people_info (ID), --单个外键,一般情况下不建议增加这种强约束
id int8 PRIMARY KEY, --系统会自动为主键创建一个隐含的索引 primary key(Sno,Cno)组合主键
address VARCHAR (255) UNIQUE NOT NULL,
birthday TIMESTAMP NOT NULL,
age int default 15, --默认值,影响后续插入值。但对旧数据没有影响。
CONSTRAINT student2_pkey PRIMARY KEY (id),
CONSTRAINT ck_age CHECK(age<18), --检查约束,约束某些字段需要满足的要求。NULL被认为满足条件。
CONSTRAINT uk_tbl_unique_a_b unique(id ,address) --唯一约束。唯一键中可以写入任意多个NULL!即可以存在多组 1,null
)
WITH (
OIDS=FALSE
);
ALTER TABLE myschema.tb_test
OWNER TO postgres;
--重命名表
alter table tableName RENAME TO newName;--pg
2)表约束
- 主键
不允许null、重复。
--添加主键(有些DBMS不允许在建表之后修改主键)
ALTER TABLE tableName ADD PRIMARY KEY(fieldName) ;
- 外键
允许null。
一般情况下,不建议建立外键这种强约束。 - 检查约束
--添加约束
alter table tableName add check (age<16);--pg 增加检查约束,约束名为:tableName_age_check
--删除约束
--pg 根据约束名删除检查约束、唯一约束
alter table tableName drop constraint IF EXISTS constraintName;
- 唯一约束
--pg 增加唯一约束
--由于add constraint无法和if exists连用,所以先删后加。
alter table tableName add constraint uk_tbl_unique_a_b unique (a,b);
- 非NULL约束。
--pg 增加非空约束
alter table tableName alter column fieldName set NOT NULL;
--pg 删除非空约束(非空约束没有约束名)
alter table tableName alter column fieldName drop NOT NULL;
3)删
4)改
1>属性默认值
--修改默认值
alter table tableName alter column age set DEFAULT 15;--pg
--删除默认值
alter table tableName alter column age drop DEFAULT 15;--pg
2>修改表字段
--增加列\添加一个字段
--column 可加可不加
alter table tableName add column if not exists columnName varchar(30) default 'a' not null;
--删除列(会连同字段上的约束一并删除)
--column 可加可不加
alter table tableName drop column columnName;
--修改列名:
--pg、oracle中
alter table tableName rename column fieldName TO fieldNameNew;
--在sqlserver
exec sp_rename '[表名].[列名]‘,’[表名].[新列名]'
--mysql
ALTER TABLE 表名 CHANGE 列名 新列名 列类型
--修改字段类型或长度:
alter table tableName modify column 字段名 类型;
--pg修改字段数据类型。仅在当前数据都可以隐式转换为新类型时才可以执行成功
alter table tableName alter column fieldName TYPE text;
--将NAME最大列宽增加到10个字符
ALTER TABLE CARD ALTER COLUMN NAME varchar(10)
5)查
pg表也支持TOAST(跨页存储的大字段,需要将行外数据存储到TOAST表)。
--获取数据库中所有表
select * from pg_tables where schemaname='public';
6)表分区SQL
1>概念
表分区是逻辑上把大表分割成物理上几块,如按时区分、按类型分等。
优点
- 删除更快。如按时间分区,删除历史数据直接删除对应分区表。
- 查询更快。如按时间分区,较早时间的表几乎很少查询,各个分区表有各自的索引,使用频率高的分区表的索引就可以完全缓存到内存中。
- 修改更快。访问具体分区表,而不是全表扫描。
- 节省资源。根据访问频率把不常访问的数据存储到不同的物理介质上。
2>表继承分区
注意:通过触发器创建表,主表的唯一索引可以创建但是不起作用!!!
--表继承
create table sales_detail(...sale_date...);--父表,不存数据
create table sales_detail_y2014m01 (
check (sale_date >= DATE'2014-01-01' and sale < DATE'2014-02-01') --check约束
)INHERITS(sales_detail); --子表继承父表
--在各个分区表的分区键上建立索引
create index sales_detail_y2014m01_sale_date on sales_detail_y2014m01 (sale_date);
--建立规则或触发器,把对主表的数据插入重定向到具体分表。
create RULE sales_detail_insert_y2014m01 AS
ON insert to sales_detail where
(sale_date >= DATE'2014-01-01' and sale < DATE'2014-02-01')
DO INSTEAD
insett into sales_detail_y2014m01 values(NEW.*);
分表通过规则或触发器优缺点对比:
- 相比触发器,规则开销很大。批量插入的情况下,规则效率更高。
- copy插入数据不会触发规则,但会触发触发器。
- 分表之外的数据,再次插入父表时,触发器会报错,但规则会把这些规则之外的数据插入主表。
3>声明式分区
pg内部通过表继承来实现分区表。pg10.x通过声明式分区直接创建分区表,但其内部原理依然是表继承。
相比表继承分区,不需要在父表创建各种触发器(降低维护成本),对父表的DML操作会自动路由到相应分区。
目前仅支持范围分区和列表分区。
--范围分区
--创建主表
1. 创建全局主键必须携带分区字段
2. 不允许全局创建索引,可以在分表上创建索引。
3. 删除主表不会删除子表,通过级联删除可以一起删除。
4. 查询主表时若在where条件中携带分区字段(如日期),可直接去分区表检索,提高检索速度。注意:这个字段不包含运算,否则失效。
create table sales_detail(
...
sale_date date not null,
...
) PARTITION BY RANGE(sale_date); --通过PARTITION BY来支持分区。不能给没有分区表的分区插入数据。
--创建分区表(分区表需要手动进行创建,可以用定时任务一次创建多个)
create table sales_detail_y2014m01 PARTITION OF sales_detail --通过PARTITION OF指定分区表分区。
FOR VALUES FROM ('2014-01-01') TO ('2014-02-01');
--查看所有的分区表
select relname from pg_catalog.pg_class where relispartition = 't';
--列表分区
create table test_list_part(id int, state boolean) PARTITION BY list(state);
create table test_list_part_t partition of test_list_part for values in ('t');
create table test_list_part_f partition of test_list_part for values in ('f');
insert into test_list_part values ('1','t');
insert into test_list_part values ('1','f');
create index on test_list_part_f (state);
create index on test_list_part_t (state);
④优化
1.打开约束排除(postgresql.conf中的constraint_exclusion设置为on)。
sql查询中,where语句的过滤条件与分区表的check条件进行对比,直接跳过不需要扫描的分区表。
注意:分区字段的where语句如果包含计算,可能会扫描全表,需要解释执行确认。
select count(*) from sales_detail where sale_date >= DATE'2014-12-01';--同各个分区表上的check条件进行对比,可知只需要扫描主表和分表sales_detail_y2014m12。
⑤主键
可能我的navicat版本太低了看不见主键,通过以下sql可以查询到主键。
SELECT
pg_attribute.attname AS colname,
pg_type.typname AS typename,
pg_constraint.conname AS pk_name
FROM
pg_constraint
INNER JOIN pg_class ON pg_constraint.conrelid = pg_class.oid
INNER JOIN pg_attribute ON pg_attribute.attrelid = pg_class.oid
AND pg_attribute.attnum = pg_constraint.conkey [ 2 ]
INNER JOIN pg_type ON pg_type.oid = pg_attribute.atttypid
WHERE
pg_class.relname = 'tbl_alarm_judge_conclusion'
AND pg_constraint.contype = 'p';
--pg_constraint.contype : c = 检查约束, f = 外键约束, p = 主键约束, u = 唯一约束 t = 约束触发器 x = 排斥约束
7)序列SQL
序列对象(也叫序列生成器)就是用CREATE SEQUENCE 创建的特殊的单行表。一个序列对象通常用于为行或者表生成唯一的标识符。通常用于表的主键自增。
mysql中的序列有以下两个限制,但pg中的序列没有。
- 自增长只能用于表中的一个字段;
- 自增长只能被分配给固定表的固定的某一个字段,不能被多个表使用。
①创建
1> serial
将id类型设置为:serial,pg会自动创建一个序列,同时将列设置为INT,默认值设置为nextval(‘序列’)。serial8会将列设置为int8(long)
2> sequence(序列)
--[TEMPORARY | TEMP] 临时序列,在会话结束时自动删除;除非用模式修饰,否则同一个会话中同名的非临时序列是不可见的。
create [TEMPORARY | TEMP] sequence seq_name;
--nextval('seq_name') 表示递增序列seq_name并返回新值。字符串会自动转换为regclass类型
--setval('seq_name', bigint) 设置序列当前数值
create table test (id int default nextval('seq_name'), info text);
CREATE SEQUENCE
IF NOT EXISTS PUBLIC .role_id_seq --序列名
START WITH 1 --指定序列的起点,缺省初始值对于递增序列为minvalue, 对于递减序列为maxvalue。
INCREMENT BY 1 --递增量,缺省为1;递减为负数
NO MINVALUE --指定序列的最小值, 如:minvalue 1
NO MAXVALUE --指定序列的最大值,递减序列最大值为-1
CACHE 1 --为快速访问而在内存里预先存储多少个序列号,缺省值为1,表示一次只能生成一个值,也就是说没有缓存。
OWNED BY {table.column | NONE} --将序列关联到一个特定的表字段上,在删除该字段或其所在的表时将自动删除绑定的序列;NONE表示无关联。
CYCLE --默认不添加cycle选项,创建出来的序列满时会报错;添加cycle时,序列会从开始值重新开始。
;
② 给已有的字段创建添加自增,并且自增值从最大的id+1开始
--将下一次的自增值设置成最大id+1
select setval('user_info_id_seq',(select max(id)+1 from user_info));
③修改序列
alter sequence serial
increment by 3
restart with 10; --是一个可选选项,它改变序列的当前值
select nextval('serial');
④删除序列
DROP SEQUENCE [ IF EXISTS ] name [, ...] [ CASCADE | RESTRICT ]
--IF EXISTS 如果指定的序列不存在,那么发出一个 notice 而不是抛出一个错误。
--CASCADE 级联删除依赖序列的对象。
--RESTRICT 如果存在任何依赖的对象,则拒绝删除序列。这个是缺省。
drop sequence serial;
⑤序列和事务
事务回滚不会影响序列。
begin;
select netval('seqtest01'); --3
rollback;
select currval('seqtest01'); --3
⑥cache
如果cache大于1,当序列被用于多会话时,每个会话在每次访问序列对象的过程中都会分配并缓存随后的序列值,会话结束时丢失没有使用的数字,从而导致序列出现空洞。
多个会话的情况下,如果cache大于1,那么只能保证nextval值是唯一的,缺不按顺序生成。比如cache=10,会话A保留了1……10并且返回nextval=1,会话B保留了11……20。会话A返回nextval=1之前会话B可能先返回nextval=11。
8)表继承
表继承是pg特有的。
create table persons_lwh(
name text,
age int,
sex boolean
);
create table students_lwh(
class_no int
)INHERITS(persons_lwh); --继承。
--父表的检查约束、非空约束会被子表继承,但唯一、主键、外键约束子表不会继承。
--一个子表可以继承多个父表,多个相同字段必须类型一致,融合后在子表中只有一个字段。
insert into students_lwh values('Mary',15,true,1); --向子表插入数据,父子表都有数据
insert into persons_lwh values('Bob',15,true);--向父表插入数据,只有父表有数据
select * from persons_lwh;
select * from students_lwh;
select * from only persons_lwh; --添加only,只获取直接插入父表的数据
9)表空间
pg中的表空间就是为表一指定个存储目录,主要用于把表存放到不同的存储目录。
5,表查询
select * from student;
select 1+2;
- 关键字规避
--sqlServer通过加中括号规避关键字
select [select] from 表名;
--pg通过加单引号规避
select 'select' from 表名;
1)条件查询
| 功能 | 表达 | 举例 | 备注 |
|---|---|---|---|
| 等于 | = | ||
| 不等于 | <>或!= | != 不是标准的SQL,<>才是,在pg两者一样 | |
| 空值 | is null is not null | where class is not null; | |
| 确定集合 | in not in | where age not in(21,23); | pg中in的长度限制:32767 |
| 确定范围 | between and not between and | 筛选包含边界值 | |
| 模糊查询 | like not like | where name like '%丽%';’ | %:任意长度字符串;_(下划线):代表任意单个字符,汉字需要2个字符表示;\:转义字符 |
| 多层查询 | EXISTSNOT EXISTS | WHERE EXISTS (SELECT d_name FROM department WHERE d_id=1003); | 逐条将条件下放到判断条件,如果EXISTS 查询记录返回true。 |
1>or、in、exists
- 两三个条件使用or
- 多个使用IN
- 数据量大使用EXISTS(性能最优)
in转exists:
-- IN
SELECT T1.* FROM role_menu T1
WHERE T1.ROLEUUID IN (
SELECT T2.uuid FROM role T2
WHERE T2.UUID = '1'
);
-- EXISTS
SELECT T1.* FROM role_menu T1
WHERE EXISTS (
SELECT T2.* FROM role T2
WHERE T1.ROLEUUID = T2.uuid AND T2.uuid = '1'
);
2)排序
pg:表查询没有指定查询顺序时,按插入顺序进行排序。
#多重排序:
-- 先按字段5排序,再按字段6排序
order by 字段5,字段6 asc
3)分页查询
- limit 和offset后面都要跟整数(单一变量),不涉及计算。
--pg:page从1开始
select * from tbl_
limit size offset (page-1)*size;
limit 100 offset 0和limit 100 offset 100000000比较?
前者远远快于后者,原因:深度分页问题,limit m offset n表示限制查询M个,跳过前n个。
4)group by、having
大部分的where可被having代替,不同的是where过滤行,而having过滤分组,用在group by之后。
select class,avg(age) as age from student
group by class
having avg(age)>23 /*要求平均年龄大于23*/
where肯定在group by 之前
where后的条件表达式里不允许使用聚合函数,而having可以。
5)聚合函数
通过case-when语句可以合并多个聚合查询为一条sql执行。
| 函数 | 说明 | 备注 |
|---|---|---|
| avg(column) | 平均数 | |
| min(column) | ||
| max(column) | ||
| sum(column) | 求和 | |
| count(column) | 数量统计,不统计NULL | |
| count(*) count(1) | 数量统计,统计NULL;性能一样 | |
| distinct(column) | 去重 | count(distinct(class)) |
6)联表查询
luo_persons表:
| id_p | last_name | first_name | address | city |
|---|
luo_orders表:
| id_o | order_no | id_p |
|---|
要求输出:谁订购了产品,并且他们订购了什么产品?
1>嵌套查询
2>关联查询(等值联结)
等值联结明确指定联结类型可转换为inner join。
SELECT
a.last_name, a.first_name, b.order_no
FROM
luo_persons a,
luo_orders b
WHERE
a.id_p = b.id_p
3>join查询
| JSON类型 | 说明 | 备注 |
|---|---|---|
| 内连接 INNER JOIN | 两表取交集 | INNER可省略。mysql会选择数据量(真正参与运算的数据)比较小的表作为驱动表,大表作为被驱动表 |
| LEFT JOIN | 以左表数据为准,连接右表中符合条件的数据 | OUTER已省略,强制指定左表是驱动表。 |
| RIGHT JOIN | 以右表数据为准,连接左表中符合条件的数据 | OUTER已省略,强制指定右表是驱动表。 |
| FULL OUTER JOIN | 两表取并集 | OUTER可省略 |
SELECT
last_name,
first_name,
order_no
FROM
luo_persons
INNER JOIN luo_orders ON luo_persons.id_p = luo_orders.id_p
4>union查询(复合查询、并查询)
用于合并两个或多个 SELECT 语句的结果集。
- UNION 会把两个结果集的所有数据放到临时表中后再进行去重操作。
- UNION ALL 不会再对结果集进行去重操作。
优先使用UNION ALL替代UNION 操作。 - UNION的两个结果集列必须可对应。
相同数量的列、相似的数据类型(可互相转换)、表达式或聚集函数。
列顺序也必须一致。
select id_p from luo_persons
union
SELECT id_p from luo_orders
5>EXCEPT(或MINUS)
检索在第一个表中存在而在第二个表中不存在的行;
select customer_id from customers except select customer_id from orders ;
6>INTERSECT
检索两个表交集,类似inner join。
区别:inner join只能操作表,intersect 可以操作结果集。
select customer_id from customers
intersect
select customer_id from orders
order by customer_id as
7>with as,初步表过滤
适用于pg、mysql,通过with as将表初步过滤一遍再在此基础上进行查询。
with
cr as
(
select CountryRegionCode from person.CountryRegion where Name like 'C%'
)
select * from person.StateProvince where CountryRegionCode in (select * from cr);
8>WITH RECURSIVE 递归查询
主要用于树形结构、层级结构的查询与汇总。
--AllOrgChildren 作为临时表,在初始查询和递归查询中引用
WITH RECURSIVE AllOrgChildren AS (
--第一个select表示初始的查询结果
SELECT id, id as root_id
--tbl_org是一个树型表。
FROM tbl_org
WHERE pid = -1
--UNION 表示将两个查询结果集进行联合,增加ALL表示保留重复
UNION ALL
SELECT o.id, ac.root_id
FROM tbl_org o
--递归查询的终止条件
JOIN AllOrgChildren ac ON o.pid = ac.id
)
--最终返回的查询结果集
select * from AllOrgChildren;
7)判断查询
1>case-when-then
pgsql和mysql都支持。
--简单case函数
case sex
when '1' then '男'
when '2' then '女'
else '其他' end;
--case搜索函数
case when sex = '1' then '男'
when sex = '2' then '女'
else '其他' end
提升:通过case-when合并多个聚合查询为一条sql。
对于一些统计,比如我们要统计家庭地址address分别在a、b、c区的数量,最简单的sql怎么写呢?
select
sum(case when (address = 'a') then 1 else 0 end) as aTotal,
sum(case when (address = 'b') then 1 else 0 end) as bTotal,
sum(case when (address = 'c') then 1 else 0 end) as cTotal
from user
group by name;
sum可以被max 等替换:
select
tname as '姓名' ,
max(case ttype when '语文' then tscor else 0 end) '语文',
max(case ttype when '数学' then tscor else 0 end) '数学',
max(case ttype when '英语' then tscor else 0 end) '英语'
from testScore
group by tname
2>判空 COALESCE(sql, NULL)
pg函数,判断sql结果,如果sql执行不存则返回null;
--如果status为null,则设置为'默认值'。后续有多个表达式,表示有null值时,按顺序填充后续不为null的值
select status,COALESCE(status,'默认值','使用中','未使用') from test;
返回值:
status | COALESCE
使用中 | 使用中
null | aaaa
null | aaaa
未使用 | 未使用
n)系统属性查询
--查询一个表是否存在
select count(*) from pg_class where relname = 'tablename';
--查询所有的表
SELECT * FROM pg_tables;
--查询所有的视图
SELECT * FROM pg_views;
--查询表结构
SELECT a.attnum,a.attname AS field,t.typname AS type,a.attlen AS length,a.atttypmod AS lengthvar,a.attnotnull AS notnull,b.description AS comment FROM pg_class c,pg_attribute a LEFT OUTER JOIN pg_description b ON a.attrelid=b.objoid AND a.attnum = b.objsubid,pg_type t WHERE c.relname = 'person_wechat_label' and a.attnum > 0 and a.attrelid = c.oid and a.atttypid = t.oid ORDER BY a.attnum;
--从数据库中导出数据到文件
\copy (select * from "user") to '/tmp/1.txt';
a)similar to(pg特色)
类似like的用法,在like的基础上又增加了与POSIX正则表达式相同的模式匹配元字符。
select label FROM classify where label similar to '(36)+%' ;--检索以36开头或3636……开头的数据
select label FROM classify where label like '(36)+%' ; --检索(36)+开头的数据
| 元字符 | 功能 |
|---|---|
() | 表示独立逻辑项目 |
| ` | ` |
* | 重复前面的项0次或更多次 |
+ | 重复前面的项一次或更多次 |
? | 重复前面的项0次或1次 |
{m} | 重复前面的项m次 |
{m, } | 重复前面的项m次或更多次 |
{m,n} | 重复前面的项至少m次,不超过n次 |
[…] |
b)POSIX 正则表达式
pg中有两种正则表达式:
| 区别 | SQL正则表达式 | POSIX 正则表达式 |
|---|---|---|
| 概念 | 遵循sql语句中like、similar to语法 | 脚本语言中的标准正则表达式 |
| 任意一个字符 | _ | . |
| 任意个字符 | % | .* |
POSIX 正则表达式:
| 模式匹配操作符 | 功能 |
|---|---|
~ | 匹配正则表达式,区分大小写 |
~* | 匹配正则表达式,不区分大小写 |
!~ | 不匹配正则表达式,区分大小写 |
!~* | - |
--下面两种语句功能一致:
select 'osdba' ~'a'; --t
select 'osdba' similar to '%a%'; --t
select 'osdba' ~'b|a';--t
c) substring函数(pg特色)
这个函数功能强大,可以使用正则表达式。
6,插入修改删除
1)upsert
更新插入一体
当主键或者unique key发生冲突时,什么都不做(同时也适用于多个字段的唯一性约束):
INSERT INTO test.upsert_test(id, "name")
VALUES(1, 'm'),(2, 'n'),(4, 'c')
ON conflict(id) DO NOTHING;
upsert方法,冲突则更新,否则插入:
insert into "public"."user"
(id, name)
values(1,'a')
ON conflict(id)
DO UPDATE SET
name = 'b';
批量update:
UPDATE test_user
SET age = temp.age
FROM
( VALUES ( 1, '张三', 11 ), ( 3, '王五', 22 ), ( 2, '李四', 33 ) ) AS temp ( id, username, age )
WHERE
test_user.id = temp.id
2)insert
--批量插入
insert into tableName(no,name) values ('1','kate'),('2','kate');
--按表中列的顺序,但如果表结构发生了变化那么对应 sql也要改。不推荐,禁止!!
insert into product values('001','001','N','N');
- 有自增序列可以不插入、插入null或者0,这样mysql、pg会自己填充值;
- 大量数据批量写(CRUD),分批操作。
pg中大量update会导致磁盘告急;
大批量写回造成严重的主从延迟;
Binlog 日志为 row 格式时会产生大量的日志;
大事务容易阻塞;
3) insert select
将select结果插入表中,一般用于可重复执行的sql。
注:
1.insert select语句中,如果select返回多行,那么会insert多行数据。
INSERT INTO "public"."vendors"("vend_name", "vend_id") select 'vend_name1', 1
WHERE NOT EXISTS (select 1 FROM "public"."vendors" WHERE vend_id = 1);
INSERT INTO "public"."classInfo"("studentName", "teacher")
SELECT name, "Ms"
from student;
4)select into
从一个表中选取数据,然后把数据插入另一个表中。
- 场景:创建表的备份复件、对记录进行存档。
- select into 可以从多个表中检索数据,但只能插入到一个表中。
函数里面,把一个查询出来的值存入临时变量:
SELECT LastName,FirstName
INTO _lName,_fName FROM Persons
也可以存入临时表中:
SELECT *
INTO Persons_backup
FROM Persons
5)update
update tableName set name = 'Tom' where name='kate';
update tableName set age = age + 1;
6)数据删除 delete、drop、truncate
1>delete from
删除表中所有行,保留表、不释放空间。所删除的每行记录都会进日志,可以回滚。
DELETE FROM Person WHERE LastName = 'Wilson';
DELETE FROM table_name;
DELETE p1 FROM Person p1,
Person p2
WHERE
p1.Email = p2.Email AND p1.Id > p2.Id
2>drop
删除表:删除内容和定义,释放空间
drop table user;
--可重复执行sql
DROP TABLE IF EXISTS "public"."role_relation";
3>truncate
删除表中所有数据,保留表、同时释放空间(速度比delete快,但是无法撤回,日志里面只记录页释放):
truncate table book;
truncate是DDL语句(Data Definition,数据定义语句),相当于用重新定义一个新表的方法把原表的内容直接丢弃了,所以执行起来很快。delete语句是DML语句(Data Manipulation,数据操作语句),把数据一条一条的删除,所以删除多行数据执行较慢。
7,索引
1)概念
pg采用堆表结构,查询时不需要回表。
2)创建索引
1>普通索引和并发索引
pg创建索引有2种方式:
- 普通方式:
扫表一次,会锁表,阻塞增删改、可查询;
--默认创建类型为BTree类型。desc缺省为asc。NULLS FIRST可缺省,表示空值排在非空值前面,也可以选NULLS LAST.
create [UNIQUE] INDEX indexName on tableName(fieldName desc NULLS FIRST);
--pg中针对array或json、jsonb字段创建索引,指定GIN类型索引。
create INDEX indexName on tableName using gin(fieldName);
- 并发创建:
扫表2次,不会锁表,更耗时。
--pg并发创建索引 启用CONCURRENTLY选项。
--pg中重建索引不支持CONCURRENTLY,要进行并行更新索引一般是先通过CONCURRENTLY创建新索引,然后删除旧索引。
--注意,使用CONCURRENTLY创建索引如果强行取消会残留无效索引,这个索引会引起更新速度变慢、唯一索引还会有唯一约束。需要手动删除这个无效索引。
create index CONCURRENTLY indexName on tableName(fieldName);
2>表达式索引创建
可以实现简单唯一约束无法实现的一些约束,如:
create unique index my_test_idx on tb_test (lower(note)); --禁止向note列插入只是大小写有区别二内容完全两天的数据行
3> 部分索引创建
设置一个部分索引以排除普通数值,能大大提高查询效率:
--场景:内网ip数量少但是访问频率很高,需要统计外网ip的访问
create index access_log_client_ip_ix on access_log(client_ip)
where not(client_ip > inet '192.168.100.0' and
client_ip < inet '192.168.100.255');
4>前缀索引创建
- 对文本的前几个字符建立索引;
- 优点:索引更小,查询效率更快!
- 前缀索引的比较严格按字符比较而不是根据特定于区域设置的排序规则进行比较的。
- 场景:
1)字段长度很长的等式比较。不适用于:<,<=,> 或 >= 比较。
2)字段数据量大且查询频繁。
--平台:pg
--支持类型:text
CREATE INDEX test_index ON test_table (col text_pattern_ops);
--支持类型:varchar
CREATE INDEX test_index ON test_table (col varchar_pattern_ops);
--支持类型:char的B-tree索引
CREATE INDEX test_index ON test_table (col bpchar_pattern_ops);
3)索引 删、改
alter INDEX indexName RENAME TO newName;--索引重命名
alter INDEX indexName set TABLESPACE tableSpaceName;--表空间修改
--[CASCADE | RESTRICT]缺省默认为RESTRICT,表示有依赖会删除失败。CASCADE表示有依赖索引的对象一并删除依赖对象。
drop index if exists indexName [CASCADE | RESTRICT]; --if exists可省略
4)索引查询
select * from pg_indexes where tablename like 'tbl_%' and indexname like 'index_%';
8,函数
- 支持函数重载
pg允许多个函数具有相同的名称,只要参数不同即可。
1)创建
--[OR REPLACE]:是可选的,它允许修改/替换现有函数
CREATE [OR REPLACE] FUNCTION function_name (arguments)
RETURNS return_datatype AS $variable_name$
DECLARE --DECLARE:定义参数(参数名写在前面 类型写在后面)
declaration;
[...]
BEGIN --BEGIN~END: 在中间写方法主体
< function_body >
[...]
--RETURN:指定要从函数返回的数据类型(它可以是基础,复合或域类型,或者也可以引用表列的类型)。
RETURN { variable_name | value }
--LANGUAGE:它指定实现该函数的语言的名称。 可以是SQL,PL/pgSQL,C, Python等。
END; LANGUAGE plpgsql;
1>参数说明
| 参数 | 说明 |
|---|---|
| IN | 可以将 IN 参数传递给函数,但无法从返回结果里再获取到。 |
| OUT | OUT 参数经常用于一个函数需要返回多个值,所以不需要 RETURN 语句。 |
| INOUT | INOUT 参数是 IN 和 OUT 参数的组合。这意味着调用者可以将值传递给函数,函数然后改变参数并且将该值作为结果的一部分传递回去。 |
| VARIADIC | PostgreSQL 函数可以接受可变数量的参数,其中一个条件是所有参数具有相同的数据类型。参数作为数组传递给函数。 |
参数使用例子:
CREATE OR REPLACE FUNCTION hi_lo(
IN a NUMERIC,
IN b NUMERIC,
OUT c NUMERIC,
OUT hi NUMERIC,
INOUT lo NUMERIC)
AS $$
BEGIN
c:= GREATEST(a,b);
hi:= LEAST(a,b);
lo:=GREATEST(a,b);
END; $$
LANGUAGE plpgsql;
2>举例
CREATE FUNCTION getNthHighestSalary(N INT) RETURNS INT
BEGIN
# i 定义变量接收返回值
DECLARE ans INT DEFAULT NULL;
# ii 执行查询语句,并赋值给相应变量
SELECT
DISTINCT salary INTO ans
FROM
(SELECT
salary, @r:=IF(@p=salary, @r, @r+1) AS rnk, @p:= salary
FROM
employee, (SELECT @r:=0, @p:=NULL)init
ORDER BY
salary DESC) tmp
WHERE rnk = N;
# iii 返回查询结果,注意函数名中是 returns,而函数体中是 return
RETURN ans;
END
2)OBJECT_ID
A. 返回指定对象的对象 ID
USE master;
GO
SELECT OBJECT_ID(N'AdventureWorks.Production.WorkOrder') AS 'Object ID';
GO
B. 验证对象是否存在
USE AdventureWorks;
GO
IF OBJECT_ID (N'dbo.AWBuildVersion', N'U') IS NOT NULL
DROP TABLE dbo.AWBuildVersion;
GO
N是显式的将非unicode字符转成unicode字符,它来自 SQL-92 标准中的 National(Unicode)数据类型,用于扩展和标准化,在这里可以不用,写作object_id(PerPersonData)。
CREATE FUNCTION getNthHighestSalary(N INT) RETURNS INT
BEGIN
SET N := N-1;
RETURN (
SELECT salary FROM employee;
);
END
3)块结构
一个 PostgreSQL 函数由块(block)进行组织。
[ DECLARE
声明 ] --可以没有
BEGIN
主体; --必需
...
END;
--声明部分中的每个语句都以分号(;)结尾。 主体部分中的每个语句也以分号(;)结尾。
4)循环
在begin-end中:
--单客户数据量(3万)
FOR num IN 1..30000 LOOP
--客户数量(500)
FOR cust IN 100..600 LOOP
...
end loop;
end loop;
for role in (select * from role where is_delete = false) loop
...
end loop;
9,触发器(Trigger)
- 定义:由事件(增删改操作)自动触发执行的特殊的存储过程。
- 场景:加强数据的完整性约束和业务规则上的约束,不推荐使用。
- 执行顺序:
如果有多个相同类型的触发器定义了相同的事件,他们将被触发名称是按字母顺序排列。
1>创建触发器
语句触发:(修改0行的操作依然会触发。按语句触发,而不管这条语句操作了多少行)
CREATE TRIGGER stu_trigger
AFTER INSERT OR DELETE OR UPDATE ON stu_info --AFTER 可以换成BEFORE,在语句执行前触发。行级别的AFTER触发器在任何语句级别的AFTER触发器之前触发。
FOR STATEMENT EXECUTE PROCEDURE stu_trigger_function ();
针对字段触发:
CREATE TRIGGER stu_trigger
AFTER INSERT OR UPDATE OF birthday OR DELETE ON stu_info
FOR EACH ROW EXECUTE PROCEDURE stu_trigger_function (); --stu_trigger_function 为触发函数
行触发:(如果执行的语句没有更新实际的行,那么不会+触发)
CREATE TRIGGER example_trigger
AFTER INSERT OR DELETE OR UPDATE ON COMPANY
FOR EACH ROW EXECUTE PROCEDURE auditlogfunc();
2>删除
触发器删除不会删除对应的触发函数;但删除表时,表上的触发器会一并删除。
DROP TRIGGER if exists stu_trigger ON stu_info [CASCADE | RESTRRICT]; --中括号中的可省略。CASCADE 级联删除依赖此触发器的对象;RESTRRICT是默认值,有依赖对象存在就拒绝删除。
3>触发函数
触发函数有返回值。
对于BEFORE和INSTEAD OF这类行级触发器来说:
- 返回NULL,表示忽略当前行的操作。也不会触发其它触发器。
- 返回非NULL:对于INSERT和UPDATE操作来说,返回的行将成为被插入的行或者将要更新的行。
- 每个触发器返回的行将成为下一个触发器的输入。
对于AFTER这类行级触发器:返回值会被忽略。
触发函数常用特殊变量:
NEW:
1. INSERT/UPDATE 行级触发器中新的数据行,数据类型是RECORD;
2. 语句级别触发器、DELETE操作触发器 中此变量未分配。
OLD:
3. UPDATE/DELETE 行级触发器中原有的数据行,数据类型是RECORD;
4. 语句级别触发器、INSERT操作触发器 中此变量未分配。
TG_NAME: 触发器名。数据类型:name。
TG_WHEN: 是 BEFORE/AFTER 触发器。
TG_LEVEL:是 ROW/STATEMENT 触发器。
TG_OP:是 INSERT/UPDATE/DELETE/TRUNCATE 之一的字符串,表示DML语句类型。
TG_TABLE_NAME:触发器所在表的名称。同理有TG_TABLE_SCHEMA(模式)。
CREATE
OR REPLACE FUNCTION stu_trigger_function () RETURNS TRIGGER AS
$BODY$
DECLARE
_birthday TIMESTAMP;
_id int;
BEGIN
IF TG_OP = 'INSERT' THEN
SELECT birthday INTO _birthday FROM stu_info WHERE name= NEW .name AND class_id= NEW .class_id;
IF _birthday is NULL THEN
INSERT INTO stu_info ( ID, name, birthday , class_id) VALUES ( NEW . ID, NEW .name, NEW .first_occur_time, NEW .class_id) ;
ELSE IF NEW .birthday < _birthday THEN
UPDATE stu_info SET ID = NEW . ID, birthday = NEW .birthday ;
END IF ;
END IF ;
ELSE IF TG_OP = 'DELETE' THEN
DELETE FROM stu_info A WHERE A . ID = OLD . ID ; RETURN OLD ;
ELSE IF TG_OP = 'UPDATE' THEN
if UPDATE(birthday ) THEN
SELECT ID,birthday INTO _id, _birthday FROM stu_info WHERE class_id= OLD .class_id AND name= OLD .name;
IF ( _id != 0 AND _birthday > OLD .birthday ) THEN
UPDATE stu_info SET ID = _id, birthday = _birthday ;
END IF ;
END IF;
END IF ;
END IF ;
END IF ;
RETURN NEW; --语句级触发函数可以显示的写:RETURN NULL
END ;
$BODY$
LANGUAGE plpgsql;
--删除触发函数
drop FUNCTION add_stu_trigger();
4>事件触发器
pg9.3开始支持Event Trigger,主要用于弥补pg以前版本不支持DDL触发器的不足。
10,存储过程(Stored Procedure)
定义:是一组为了完成特定功能的SQL 语句集,存储在数据库中,经过第一次编译后再次调用不需要再次编译,用户通过指定存储过程的名字并给出参数(如果该存储过程带有参数)来执行它。
1)优点
- 执行效率高
存储过程因为SQL 语句已经预编译过了,因此运行的速度比较快。 - 降低了客户机和服务器之间的通信
调用时传参即可,不需要传送sql语句,提高了io效率。 - 方便实施企业规则(提高了可维护性、安全性)
可以把企业规则的运算程序写成存储过程放入数据库服务器中,由RDBMS管理,既有利于集中控制,又能够方便地进行维护。
当用户规则发生变化时,只要修改存储过程,无须修改其他应用程序。
允许模块化程序设计,就是说只需要创建一次过程,以后在程序中就可以调用该过程任意次,类似方法的复用。
增强了使用的安全性,充分利用系统管理员可以对执行的某一个存储过程进行权限限制,从而能够实现对某些数据访问的限制,避免非授权用户对数据的访问,保证数据的安全。程序员直接调用存储过程,根本不知道表结构是什么,有什么字段,没有直接暴露表名以及字段名给程序员。 - 安全性高
可设定只有某些用户才具有对指定存储过程的使用权。
2)缺点
调试麻烦(至少没有像开发程序那样容易),可移植性不灵活(因为存储过程是依赖于具体的数据库)。
3)场景(不推荐使用存储过程)
当一个事务涉及到多个SQL语句时或者涉及到对多个表的操作时就要考虑用存储过程;
过多的使用存储过程会降低系统的移植性。
4)使用
- 创建
use test1
set ansi_nulls on
go
set quoted_identifier on
go
create procedure procedure_student
-- add the parameters for the stored procedure here
@gradeid int,
@gradename varchar(10) --传入的参数
as
begin
--计算内容
end
go
- 执行
exec dbo.procedure_student 1,'g'
11,视图
1)特性
- 虚拟表、临时表,每次调用视图时生成;
- 只读;
- 不能提高检索效率。
- 不支持索引,但视图可以基于索引生成
- 支持规则和触发器,可通过创建触发器或rule实现视图更新;
2)场景
- 重用SQL语句;
- 简化复杂SQL操作(生成视图),重用查询且不需要知道基本查询细节。
- 保护数据。用户有表的部分权限。
- 更改数据格式和表示。视图可返回与底层表不同的表示和格式。
3)操作
--获取数据库中所有view
select * from pg_views where schemaname='public';
--创建视图
CREATE OR REPLACE VIEW view_name(studentName, studentAge) --(studentName, studentAge) 可以去掉,加上是重命名列名
AS
SELECT user_info.name, user_info.age from user_info;
--删除视图
DROP VIEW view_name;
12,物化视图(实体视图)
经笔者测试,物化视图创建比单纯的select语句快接近10倍。
支持平台:mysql、pg9.3、orcle。
1)特性
- 将结果集持久化在表中、支持索引、不支持触发器和rule创建;
占据数据库的物理空间,和基础表一样创建时会注册 “tableoid” 、“cmax”、“xmax”、“cmin”、“xmin”、“ctid”系统字段。 - 一个物化视图对应一个SQL语句,查询时去对应的结果集表查询;
和视图不同,不查询创建实体化视图的基表,而是直接查询对应的结果表。 - 通过定期的刷新机制来更新数据;
2)场景
- 减轻网络负担
通过实体化视图将数据从一个数据库分发到多个不同的数据库上,通过对多个数据库访问来减轻对单个数据库的网络负担。 - 搭建分发环境
通过从一个中央数据库将数据分发到多个节点数据库,达到分发数据的目的。 - 复制数据子集
实体化视图可以进行行级/列级的筛选,这样可以复制需要的那一部分数据。 - 数据汇总、预计算、复制或分发数据
可以提高涉及到的SUM,COUNT,AVG,MIN,MAX等的表的查询的速度。 - 统计数据和下钻列表保持一致。
3)操作
1>创建物化视图
-- pg
CREATE MATERIALIZED VIEW my_view
AS
SELECT PART_ID, MAX(ID) MAX_ID
FROM PART_DETAIL GROUP BY PART_ID;
2>创建索引
-- 如果刷新时不带CONCURRENTLY则无需创建唯一索引
CREATE UNIQUE INDEX my_view_unique ON my_view(PART_ID);
3>数据刷新
- pg: 全量刷新
刷新过程中会对该物化视图的所有的select操作阻塞;
刷新效率快;
REFRESH MATERIALIZED VIEW my_view;
- pg:增量刷新(快速刷新)
必须具备唯一索引;
靠唯一索引对比基表查询的数据,只要有一个字段不同就填充差量数据;所有数据刷新完成后提交事务;
刷新慢,对比全量刷新非常慢,笔者对比了30w数据,全量刷新需要1s,增量筛选要12s。
不会阻塞物化视图的select操作。
-- pgsql命令行操作:利用watch命令每120s刷新一次物化视图
-- sql不支持定时命令,可通过java定时任务去调度
REFRESH MATERIALIZED VIEW CONCURRENTLY my_view; \watch 120;
4>删除
pg:
DROP MATERIALIZED VIEW PUBLIC."my_view" ;
13,用户及权限管理
pg中角色和用户没区别。超级用户为postgres。
14,规则(Rule)
规则系统更准确地说是查询重写规则系统,使用时也可以被函数和触发器替代,但原理和使用场景不同(这在上文讲分表的时候就提到过)。对于批量操作,规则比触发器效率更高。
1>SELECT规则
create RULE "_RETURN" as on select to myview Do instead select * from mytable;
#相当于create table myview (same column list as mytab);
2>更新规则
create [or replace] RULE name as on event #event 值为SELECT/INSERT/UPDATE/DELETE
to tableName [where condition]
do [also | instead] {nothing | command} # also表示执行原操作后还执行一些附加操作 如:also insert into mytab_log...; instead表示把原操作替换为后面的command操作
3>权限
规则从属于表和视图
15,事务
获取当前事务id:
select txid_current();
事务提交:
begin;
--sql语句。单条执行的sql语句也是一个事务。
commit;
事务回滚:
begin;
--sql语句
rollback;
16,Listen/Notify机制
LISTEN在名为channel的通知频道上将当前会话注册为一个监听者。
只要命令NOTIFY channel被调用(不管是在这个会话还是在另一个连接到同一数据库的会话中),所有当前正在该通知频道上监听的会话都会被通知,并且每一个会话将会接着通知连接到它的客户端应用。
LISTEN channel
NOTIFY channel
1)场景
- 实时数据库通知
传统的轮询机制会不断查询数据库以获取更新,这既浪费资源又影响性能。
通过实时接收数据库变更通知,应用程序可以快速响应数据变化。
2)使用
- 创建触发器函数
触发器函数是发送通知的核心,通常在数据变更时调用。
CREATE OR REPLACE FUNCTION notify_channel()
RETURNS TRIGGER AS $$
BEGIN
PERFORM pg_notify('my_channel', 'Data has changed.');
RETURN NEW;
END;
$$ LANGUAGE plpgsql;
- 创建触发器
- 监听通道
应用程序或客户端使用 LISTEN 命令订阅通知。
LISTEN my_channel;
- 接收通知
在客户端应用程序中,实现逻辑以接收并处理通知。
eg:使用psql接收通知
SELECT pg_notify('my_channel', 'notification payload');
eg:使用 Python 和 psycopg2 接收通知
import psycopg2
import select
conn = psycopg2.connect("dbname=mydb user=myuser")
conn.set_isolation_level(psycopg2.extensions.ISOLATION_LEVEL_AUTOCOMMIT)
cur = conn.cursor()
cur.execute("LISTEN my_channel;")
while True:
if select.select([conn], [], [], 5) == ([], [], []):
print("Timeout waiting for notification...")
else:
conn.poll()
while conn.notifies:
notify = conn.notifies.pop(0)
print(f"Got NOTIFY: {notify.pid}, {notify.channel}, {notify.payload}")
3)注意
- 确保客户端库支持异步通知。
- 通过事务commit操作触发NOTIFY 消息发送。
- 消息实时发送没有缓存,宕机后消息通知会丢失。
只有在notity之前允许的listen命令才能触发。A 如果连续发送多个消息,B会一次性收到这些消息。如果没有消息到达,则进入睡眠状态。 - LISTEN 命令在当前事务中有效,如果需要跨事务监听,需要在每个事务中重复该命令。
- 消息是异步发送到B的,即无论B的状态如何,消息都会先到达PG的消息队列(每个PG实例只有一个唯一的存放所有消息的队列)
4)原理
- 消息队列
存放了所有进程的所有通知消息。 - 进程状态数组
状态数组存放了所有执行了Listen命令、准备接收异步消息的进程的状态信息。
状态数组中含有每个进程已经读取到的消息在队列里面的位置指针。如果有了新消息,进程就从此指针往后取,直到读取全部消息。 - 客户端收到消息后,并不立即显示出来,而是需要用API进行获取。例如,psql就是在执行下一个命令时(如begin、commit),会顺便把收到的消息显示出来的。
17,好用工具
1)PgBouncer
为pg提供的一个轻量级连接池工具。
2)Slony-I
基于触发器的两个pg的逻辑同步。
3)Bucardo
双向同步工具,可以实现pg的双(多)master方案。
4)pgpool-II
pg和客户端之间的中间件。
5)Postgres-XC
Postgres-XC是基于pg实现的真正的数据水平拆分的分布式数据库。