LRU缓存-146
/*
定义双向链表节点,用于存储缓存中的每个键值对。
成员变量:
key和value存储键值对。
preb和next指向前一个和后一个节点,形成双向链表。
构造函数:
默认构造函数:初始化空节点。
参数化构造函数:初始化带有特定键值的节点。
*/
struct LinksNode{
int key,value;
LinksNode* prev;
LinksNode* next;
LinksNode():key(0),value(0),prev(nullptr),next(nullptr){}
LinksNode(int _key,int _value):key(_key),value(_value),prev(nullptr),next(nullptr){}
};
class LRUCache {
private:
/*
定义LRUCache类的成员变量和构造函数
成员变量:
cache:哈希表,键时缓存的key,值是链表节点的指针,用于快速定位节点。
head和tail:伪头部和伪尾部节点,用于简化链表操作。
size:当前缓存的大小。
capacity:缓存的容量。
*/
map<int,LinksNode*> cache;
LinksNode* head;
LinksNode* tail;
int size = 0;
int capacity = 0;
public:
/*
构造函数:
初始化缓存的容量为 _capacity。
创建两个特殊的伪节点head和tail,不存储数据,用于简化链表的插入和删除操作。
head->next指向tail,tail->prev指向head,形成一个空的双向链表。
*/
LRUCache(int _capacity):capacity(_capacity) {
head = new LinksNode();
tail = new LinksNode();
head->next = tail;
tail->prev = head;
}
/*
获取指定键的值
如果键不存在,返回-1.
如果键存在:
使用哈希表cache快速定位节点。
调用moveToHead(node)将节点移动到链表头部,表示最近被访问。
返回节点的值。
*/
int get(int key) {
if(!cache.count(key))return -1;
else{
LinksNode* node = cache[key];
moveToHead(node);
return node->value;
}
}
/*
插入新的键值对或更新已有键值对。
1.键不存在:
创建一个新节点并插入到链表头部。
添加到哈希表。
如果超出容量:
调用removeTail()删除最久未使用的节点。
从哈希表中移除相应的键值对。
2.键已存在
更新对应节点的值。
调用moveToHead()将节点移动到链表头部
*/
void put(int key, int value) {
if(!cache.count(key))
{
LinksNode* node = new LinksNode(key,value);
addToHead(node);
cache[key] = node;
++size;
if(size>capacity)
{
LinksNode* re = removeTail();//返回链表尾部被删除的键
cache.erase(re->key);
delete re;
--size;
}
}
else
{
LinksNode* node = cache[key];
node->value = value;
moveToHead(node);
}
}
/*
将一个节点插入到链表的头部
设置新节点的 prev 为 head,next 为 head->next。
更新原先头部节点的 prev 为新节点。
更新 head->next 为新节点。
*/
void addToHead(LinksNode* node)
{
node->prev = head;
node->next = head->next;
head->next->prev = node;
head->next = node;
}
/*
从链表中删除指定节点:
更新节点前后连接:node->prev->next = node->next和node->next->prev = node->prev。
节点 node 与链表完全断开。
*/
void removeNode(LinksNode* node)
{
node->prev->next = node->next;
node->next->prev = node->prev;
}
/*
将指定节点移动到链表头部:
调用 removeNode(node) 将节点从原位置移除。
调用 addToHead(node) 将节点插入到链表头部。
*/
void moveToHead(LinksNode* node)
{
removeNode(node);
addToHead(node);
}
/*
删除链表的尾部节点(最久未使用的节点)并返回:
找到伪尾部节点之前的节点:tail->prev。
调用 removeNode(node) 将其从链表中移除。
返回该节点,供 put 函数释放资源。
*/
LinksNode* removeTail()
{
LinksNode* node = tail->prev;
removeNode(node);
return node;
}
};每日问题
什么是 C++ 中的智能指针?有哪些类型的智能指针?
C++中的智能指针是一种用于管理动态内存的工具,它封装了裸指针(raw pointer),并通过 RAII(资源获取即初始化)的方式自动管理资源的生命周期,从而避免了内存泄漏和悬空指针问题。
智能指针在头文件 中定义,常见的智能指针有三种:std::unique_ptr、std::shared_ptr 和 std::weak_ptr。
智能指针的特点
1.自动管理资源:
2.避免内存泄漏:无需手动调用 delete,减少资源管理的复杂度和错误风险。
3.指针行为:智能指针提供类似裸指针的操作(如 * 和 ->),使用方便。
智能指针的类型
1. std::unique_ptr
特点:
独占所有权,不能共享。
一个资源只能被一个 std::unique_ptr 管理。
不可复制,但可以通过 std::move 转移所有权。
适用场景:
确保某个资源只需一个所有者。
管理动态分配的内存,避免手动释放。
代码示例
#include <memory>
#include <iostream>
int main() {
std::unique_ptr<int> ptr = std::make_unique<int>(42); // 创建并管理资源
std::cout << *ptr << std::endl;
// std::unique_ptr<int> ptr2 = ptr; // 错误:不可复制
std::unique_ptr<int> ptr2 = std::move(ptr); // 转移所有权
if (!ptr) std::cout << "ptr is now null." << std::endl;
}
2. std::shared_ptr
特点:
支持共享所有权。
多个 std::shared_ptr 可以共享一个资源,内部使用引用计数管理资源。
当引用计数变为 0 时,资源被释放。
适用场景:
需要多个对象共享同一个资源。
不明确资源的生命周期,但确保资源在最后一个使用者销毁时释放。
代码示例:
#include <memory>
#include <iostream>
int main() {
std::shared_ptr<int> ptr1 = std::make_shared<int>(42); // 创建并共享资源
std::shared_ptr<int> ptr2 = ptr1; // 共享所有权
std::cout << "Value: " << *ptr1 << ", Ref count: " << ptr1.use_count() << std::endl;
}
3. std::weak_ptr
特点:
弱引用,不影响资源的引用计数。
依赖于 std::shared_ptr,通常用于解决循环引用问题。
需要通过 lock() 方法将 std::weak_ptr 转换为 std::shared_ptr 访问资源。
适用场景:
配合 std::shared_ptr 使用,避免循环引用。
希望访问资源但不影响资源的生命周期。
代码示例:
#include <memory>
#include <iostream>
int main() {
std::shared_ptr<int> sp = std::make_shared<int>(42);
std::weak_ptr<int> wp = sp; // 弱引用,不增加引用计数
std::cout << "Shared count: " << sp.use_count() << std::endl;
if (auto locked = wp.lock()) { // 转换为 std::shared_ptr
std::cout << "Value: " << *locked << std::endl;
} else {
std::cout << "Resource is expired." << std::endl;
}
}

智能指针的注意事项
不要混用裸指针和智能指针:
避免循环引用:使用 std::weak_ptr 打破 std::shared_ptr 的循环引用。
性能问题:std::shared_ptr 和 std::weak_ptr 引入了额外的引用计数开销,使用时需注意性能影响。
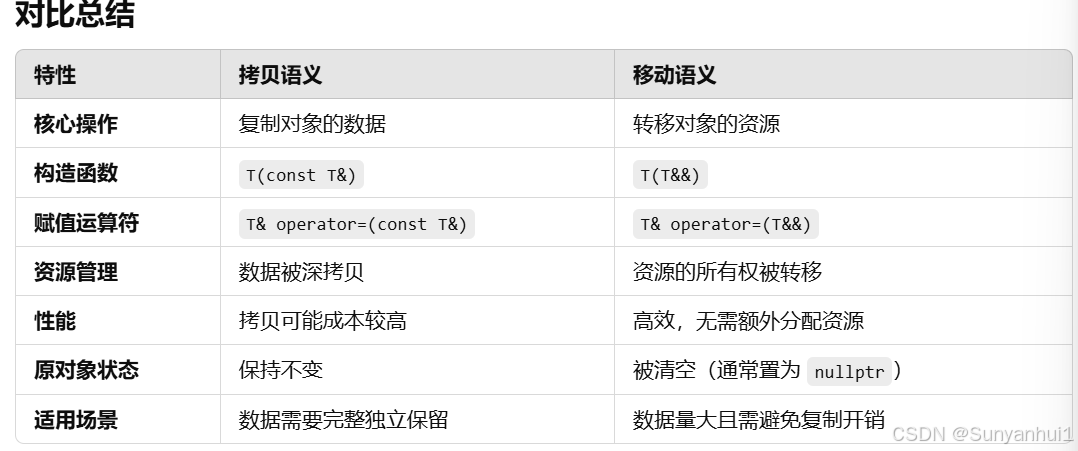
移动语义和拷贝语义有什么区别?
拷贝语义
在 C++ 中,移动语义和拷贝语义是处理对象所有权和资源管理的两种机制。它们的核心区别在于资源的分配方式和所有权转移是否发生。以下是它们的详细对比:
拷贝语义:
1.定义
拷贝语义通过复制对象的数据来创建一个新的对象。拷贝后的两个对象互不影响,拥有各自的资源。
2.实现方式
调用拷贝构造函数T(const T&)。
调用拷贝赋值运算符T& operator=(const T&)。
3.资源处理
资源完全被复制(例如深拷贝)。
每个对象独立管理自己的资源。
拷贝语义不会修改原对象的状态。
4.适用场景
对象的数据需要完整保留。
对象的数据较小,或者深拷贝的成本较低。
5.示例
class MyClass {
private:
int* data;
public:
MyClass(int value) : data(new int(value)) {}
// 拷贝构造函数(深拷贝)
MyClass(const MyClass& other) : data(new int(*other.data)) {}
// 拷贝赋值运算符(深拷贝)
MyClass& operator=(const MyClass& other) {
if (this == &other) return *this;
delete data; // 释放原有资源
data = new int(*other.data); // 复制新资源
return *this;
}
~MyClass() { delete data; }
};
移动语义
1.定义
移动语义通过转移对象的资源来创建一个新对象,而不是复制数据。转移后,原对象的状态变为不可用或空。
2.实现方式
调用移动构造函数T(T&&)。
调用移动赋值运算符T& operator=(T&&)。
3.资源处理
资源被转移到新对象(例如指针的所有权转移)。
避免了资源的深拷贝,提高了性能。
转移后,原对象被置为安全状态(如 nullptr)。
4.适用场景
对象的数据较大,深拷贝成本高。
对象的资源需要高效管理(如动态内存、文件句柄等)。
5.示例
class MyClass {
private:
int* data;
public:
MyClass(int value) : data(new int(value)) {}
// 移动构造函数
MyClass(MyClass&& other) noexcept : data(other.data) {
other.data = nullptr; // 转移后,清空原对象的数据指针
}
// 移动赋值运算符
MyClass& operator=(MyClass&& other) noexcept {
if (this == &other) return *this;
delete data; // 释放原有资源
data = other.data; // 转移资源
other.data = nullptr; // 清空原对象的数据指针
return *this;
}
~MyClass() { delete data; }
};
典型应用场景
1.拷贝语义:
必须要保留多个对象副本时。
数据较小,深拷贝开销可以忽略。
2.移动语义:
临时对象的资源管理(如 std::move)。
对象资源较大,深拷贝开销不可忽略(如容器 std::vector、std::string)。