今年年初的Depth-Anything和去年刚出的SAM一样让人感觉震撼。
如何获得深度图?
Depth-Anything足够了。
就试试
如果只是想几张图片试着看看,可以直接去这个网址Depth Anything
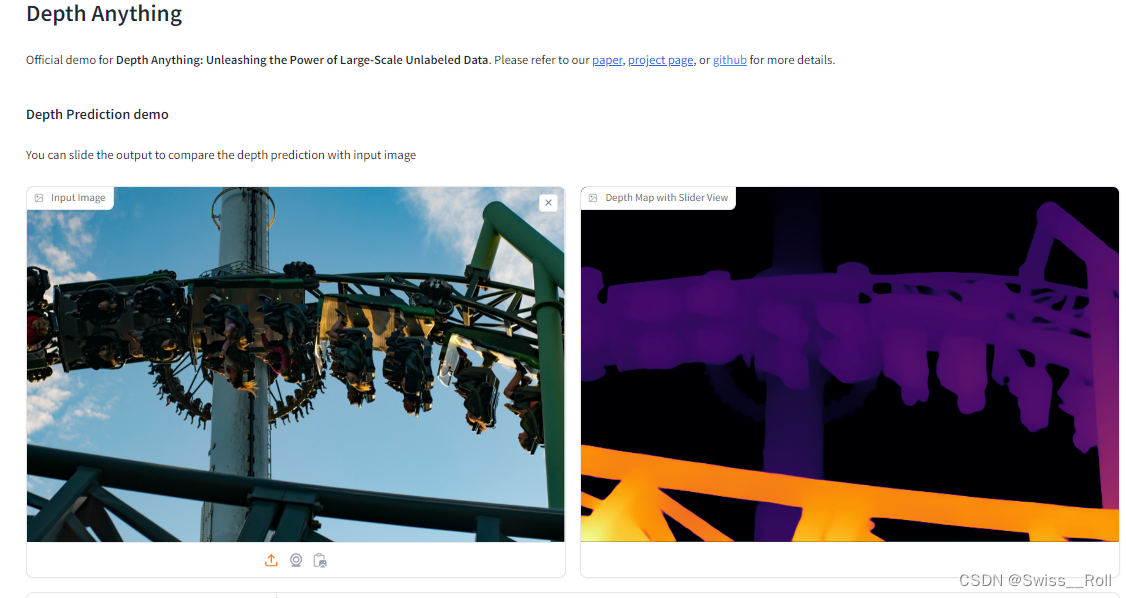
如果像我一样想得到很多图片的深度图,就得本地安装了。
搭环境
参考https://github.com/LiheYoung/Depth-Anything
conda create -n depthanything python=3.8conda activate depthanythinggit clone https://github.com/LiheYoung/Depth-Anything.gitcd Depth-Anythingpip install -r requirements.txt运行
图片
在命令行输入
export HF_ENDPOINT=https://hf-mirror.compython run.py --encoder vitb --img-path /home/xxx/train_329/0a2f2bd294/00000.jpg --outdir output/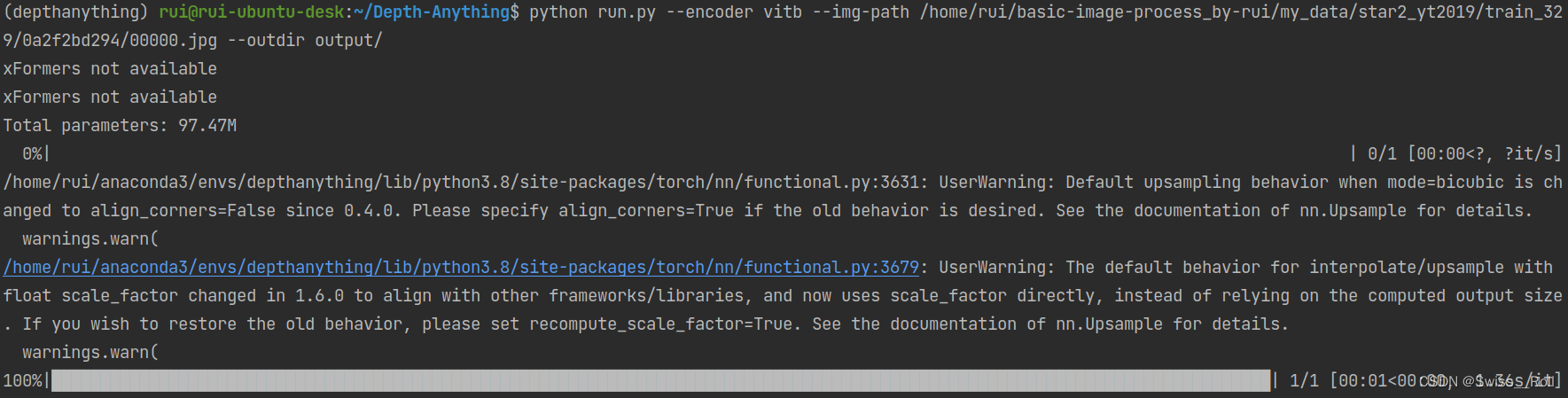


视频
在命令行输入
python run_video.py --encoder vitb --video-path assets/examples_video --outdir output/

davis_rollercoaster_video
批量处理脚本
在run.py的基础上修改
import argparse
import cv2
import numpy as np
import os
import torch
import torch.nn.functional as F
from torchvision.transforms import Compose
from tqdm import tqdm
from depth_anything.dpt import DepthAnything
from depth_anything.util.transform import Resize, NormalizeImage, PrepareForNet
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--img-path', type=str)
parser.add_argument('--outdir', type=str, default='./vis_depth')
parser.add_argument('--encoder', type=str, default='vitb', choices=['vits', 'vitb', 'vitl'])
parser.add_argument('--pred-only', dest='pred_only', action='store_true', help='only display the prediction')
parser.add_argument('--grayscale', dest='grayscale', action='store_true', help='do not apply colorful palette')
args = parser.parse_args()
margin_width = 50
caption_height = 60
font = cv2.FONT_HERSHEY_SIMPLEX
font_scale = 1
font_thickness = 2
DEVICE = 'cuda' if torch.cuda.is_available() else 'cpu'
depth_anything = DepthAnything.from_pretrained('LiheYoung/depth_anything_{}14'.format(args.encoder)).to(
DEVICE).eval()
total_params = sum(param.numel() for param in depth_anything.parameters())
print('Total parameters: {:.2f}M'.format(total_params / 1e6))
transform = Compose([
Resize(
width=518,
height=518,
resize_target=False,
keep_aspect_ratio=True,
ensure_multiple_of=14,
resize_method='lower_bound',
image_interpolation_method=cv2.INTER_CUBIC,
),
NormalizeImage(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
PrepareForNet(),
])
# ---------------------- change start -----------------------
old_dir = "/home/xxxx/JPEGImages/"
new_dir = "/home/xxxx/JPEGImages_dpanything/"
pic_list = os.listdir(old_dir)
# print(pic_list)
for pic_folder in pic_list:
input_dir = old_dir + pic_folder
out_dir = new_dir + pic_folder
if os.path.exists(out_dir):
print("exist")
continue
print("processing: ", input_dir)
if os.path.isfile(args.img_path):
if args.img_path.endswith('txt'):
with open(args.img_path, 'r') as f:
filenames = f.read().splitlines()
else:
filenames = [args.img_path]
else:
args.img_path = input_dir
filenames = os.listdir(args.img_path)
filenames = [os.path.join(args.img_path, filename) for filename in filenames if
not filename.startswith('.')]
filenames.sort()
args.outdir = out_dir
os.makedirs(args.outdir, exist_ok=True)
for filename in tqdm(filenames):
raw_image = cv2.imread(filename)
image = cv2.cvtColor(raw_image, cv2.COLOR_BGR2RGB) / 255.0
h, w = image.shape[:2]
image = transform({'image': image})['image']
image = torch.from_numpy(image).unsqueeze(0).to(DEVICE)
with torch.no_grad():
depth = depth_anything(image)
depth = F.interpolate(depth[None], (h, w), mode='bilinear', align_corners=False)[0, 0]
depth = (depth - depth.min()) / (depth.max() - depth.min()) * 255.0
depth = depth.cpu().numpy().astype(np.uint8)
if args.grayscale:
depth = np.repeat(depth[..., np.newaxis], 3, axis=-1)
else:
depth = cv2.applyColorMap(depth, cv2.COLORMAP_INFERNO)
filename = os.path.basename(filename)
args.pred_only = True
if args.pred_only:
cv2.imwrite(os.path.join(args.outdir, filename[:filename.rfind('.')] + '.jpg'), depth)
else:
split_region = np.ones((raw_image.shape[0], margin_width, 3), dtype=np.uint8) * 255
combined_results = cv2.hconcat([raw_image, split_region, depth])
caption_space = np.ones((caption_height, combined_results.shape[1], 3), dtype=np.uint8) * 255
captions = ['Raw image', 'Depth Anything']
segment_width = w + margin_width
for i, caption in enumerate(captions):
# Calculate text size
text_size = cv2.getTextSize(caption, font, font_scale, font_thickness)[0]
# Calculate x-coordinate to center the text
text_x = int((segment_width * i) + (w - text_size[0]) / 2)
# Add text caption
cv2.putText(caption_space, caption, (text_x, 40), font, font_scale, (0, 0, 0), font_thickness)
final_result = cv2.vconcat([caption_space, combined_results])
cv2.imwrite(os.path.join(args.outdir, filename[:filename.rfind('.')] + '_img_depth.png'), final_result)
# ---------------------- change end -----------------------