本系列为《模式识别与机器学习》的读书笔记。
一,概率生成式模型
⾸先考虑⼆分类的情形。类别 C 1 \mathcal{C}_1 C1 的后验概率可以写成
p ( C 1 ∣ x ) = p ( x ∣ C 1 ) p ( C 1 ) p ( x ∣ C 1 ) p ( C 1 ) + p ( x ∣ C 2 ) p ( C 2 ) = 1 1 + exp ( − a ) = σ ( a ) (4.36) \begin{aligned}p(\mathcal{C}_1|\boldsymbol{x})&=\frac{p(\boldsymbol{x}|\mathcal{C}_1)p(\mathcal{C}_1)}{p(\boldsymbol{x}|\mathcal{C}_1)p(\mathcal{C}_1)+p(\boldsymbol{x}|\mathcal{C}_2)p(\mathcal{C}_2)}\\&=\frac{1}{1+\exp(-a)}=\sigma(a)\end{aligned}\tag{4.36} p(C1∣x)=p(x∣C1)p(C1)+p(x∣C2)p(C2)p(x∣C1)p(C1)=1+exp(−a)1=σ(a)(4.36)
其中,
a = ln p ( x ∣ C 1 ) p ( C 1 ) p ( x ∣ C 2 ) p ( C 2 ) a=\ln\frac{p(\boldsymbol{x}|\mathcal{C}_1)p(\mathcal{C}_1)}{p(\boldsymbol{x}|\mathcal{C}_2)p(\mathcal{C}_2)} a=lnp(x∣C2)p(C2)p(x∣C1)p(C1)
σ ( a ) \sigma(a) σ(a) 称之为 logistic sigmoid函数 。
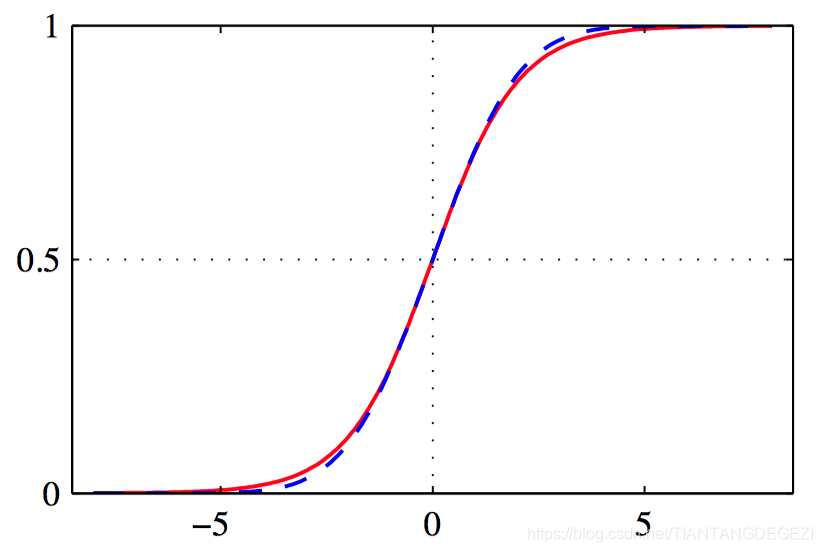
如图4.12,logistic sigmoid函数 σ ( a ) \sigma(a) σ(a) 的图像, ⽤红⾊表⽰,同时给出的是放缩后的逆probit函数 Φ ( λ a ) \Phi(\lambda a) Φ(λa) 的图像, 其中 λ 2 = π 8 \lambda^2=\frac{\pi}{8} λ2=8π , ⽤蓝⾊曲线表⽰。
logistic sigmoid函数 在许多分类算法中都有着重要的作⽤,满⾜下⾯的对称性
σ ( − a ) = 1 − σ ( a ) (4.37) \sigma(-a)=1-\sigma(a)\tag{4.37} σ(−a)=1−σ(a)(4.37)
logistic sigmoid的反函数为
a = ln ( σ 1 − σ ) (4.38) a=\ln\left(\frac{\sigma}{1-\sigma}\right)\tag{4.38} a=ln(1−σσ)(4.38)
被称为 logit函数。它表⽰两类的概率⽐值的对数 ln [ p ( C 1 ∣ x ) p ( C 2 ∣ x ) ] \ln[\frac{p(\mathcal{C}_1|\boldsymbol{x})}{p(\mathcal{C}_2|\boldsymbol{x})}] ln[p(C2∣x)p(C1∣x)] ,也被称为 log odds函数 。
对于 K > 2 K > 2 K>2 个类别的情形,有
p ( C k ∣ x ) = p ( x ∣ C k ) p ( C k ) ∑ j p ( x ∣ C j ) p ( C j ) = exp ( a k ) ∑ j exp ( a j ) (4.39) \begin{aligned}p(\mathcal{C}_k|\boldsymbol{x})&=\frac{p(\boldsymbol{x}|\mathcal{C}_k)p(\mathcal{C}_k)}{\sum_{j}p(\boldsymbol{x}|\mathcal{C}_j)p(\mathcal{C}_j)}\\&=\frac{\exp(a_k)}{\sum_{j}\exp(a_j)}\end{aligned}\tag{4.39} p(Ck∣x)=∑jp(x∣Cj)p(Cj)p(x∣Ck)p(Ck)=∑jexp(aj)exp(ak)(4.39)
被称为归⼀化指数(normalized exponential),也叫 softmax函数 ,可以被当做logistic sigmoid函数对于多类情况的推⼴。其中, a k a_k ak 被定义为
a k = ln p ( x ∣ C k ) p ( C k ) a_k=\ln p(\boldsymbol{x}|\mathcal{C}_k)p(\mathcal{C}_k) ak=lnp(x∣Ck)p(Ck)
如果对于所有的 j ≠ k j\ne k j=k 都有 a k ≫ a j a_k \gg a_j ak≫aj ,那么 p ( C k ∣ x ) ≃ 1 p(\mathcal{C}_k|\boldsymbol{x})\simeq 1 p(Ck∣x)≃1 且 p ( C j ∣ x ) ≃ 0 p(\mathcal{C}_j|\boldsymbol{x}) \simeq 0 p(Cj∣x)≃0。
1,连续输⼊
假设类条件概率密度是⾼斯分布,然后求解后验概率的形式。假定所有的类别的协⽅差矩阵相同,这样类别 C k \mathcal{C}_k Ck 的类条件概率为
p ( x ∣ C k ) = 1 ( 2 π ) D 2 1 ∣ Σ ∣ 1 2 exp { − 1 2 ( x − μ k ) T Σ − 1 ( x − μ k ) } (4.40) p(\boldsymbol{x}|\mathcal{C}_k)=\frac{1}{(2\pi)^{\frac{D}{2}}}\frac{1}{|\boldsymbol{\Sigma}|^{\frac{1}{2}}}\exp\left\{-\frac{1}{2}(\boldsymbol{x}-\boldsymbol{\mu}_k)^{T}\boldsymbol{\Sigma}^{-1}(\boldsymbol{x}-\boldsymbol{\mu}_k)\right\}\tag{4.40} p(x∣Ck)=(2π)2D1∣Σ∣211exp{ −21(x−μk)TΣ−1(x−μk)}(4.40)
⾸先考虑两类的情形。根据公式(4.36),有
p ( C 1 ∣ x ) = σ ( w T x + w 0 ) (4.41) p(\mathcal{C}_1|\boldsymbol{x})=\sigma(\boldsymbol{w}^{T}\boldsymbol{x}+w_0)\tag{4.41} p(C1∣x)=σ(wTx+w0)(4.41)
其中,
w = Σ − 1 ( μ 1 − μ 2 ) w 0 = − 1 2 μ 1 T Σ − 1 μ 1 + 1 2 μ 2 T Σ − 1 μ 2 + ln p ( C 1 ) p ( C 2 ) \boldsymbol{w}=\boldsymbol{\Sigma}^{-1}(\boldsymbol{\mu}_1-\boldsymbol{\mu}_2)\\ w_0=-\frac{1}{2}\boldsymbol{\mu}_{1}^{T}\boldsymbol{\Sigma}^{-1}\boldsymbol{\mu}_{1}+\frac{1}{2}\boldsymbol{\mu}_{2}^{T}\boldsymbol{\Sigma}^{-1}\boldsymbol{\mu}_{2}+\ln\frac{p(\mathcal{C}_1)}{p(\mathcal{C}_2)} w=Σ−1(μ1−μ2)w0=−21μ1TΣ−1μ1+21μ2TΣ−1μ2+lnp(C2)