目的
使用ceph官网的
cephadm无法正常安装,会报错ERROR: Distro openeuler version 22.03 not supported
在openEuler上实现以cephadm安装部署ceph集群。
步骤
规格
所有主机均为openEuler22.03 LTS SP3
| 虚拟机名 | 配置 | IP 地址 | 主机名 | 角色 | 磁盘配置 |
|---|---|---|---|---|---|
| node1 | 2C4G | 192.168.100.81 | node1.example.com | Mon、mgr、osd(引导节点) | 系统盘 20GB, OSD盘 10GB x 3 |
| node2 | 2C4G | 192.168.100.82 | node2.example.com | Mon、mgr、osd | 系统盘 20GB, OSD盘 10GB x 3 |
| node3 | 2C4G | 192.168.100.83 | node3.example.com | Mon、osd(复用客户端) | 系统盘 20GB, OSD盘 10GB x 3 |
| node4 | 2C4G | 192.168.100.84 | node4.example.com | osd 扩容备用节点 | 系统盘 20GB, OSD盘 10GB x 3 |
PS1: 以上虚拟机均需要配置三块硬盘,每块硬盘分别为系统盘(20GB)和三块OSD盘(10GB每块),每个节点共四块硬盘。
PS2: 该实验仅需node1~3 三台主机即可。
步骤
ceph部署前准备工作
- 设置主机名
# 所有主机分别设置
hostnamectl set-hostname node1.example.com
hostnamectl set-hostname node2.example.com
hostnamectl set-hostname node3.example.com
- 设置ip
#node1:
nmcli con de ens33
nmcli con add type ethernet ifname ens33 con-name ens33 ipv4.addresses 192.168.100.81/24 ipv4.gateway 192.168.100.2 ipv4.dns 192.168.100.2 ipv4.method manual autoconnect yes
#node2:
nmcli con de ens33
nmcli con add type ethernet ifname ens33 con-name ens33 ipv4.addresses 192.168.100.82/24 ipv4.gateway 192.168.100.2 ipv4.dns 192.168.100.2 ipv4.method manual autoconnect yes
#node1:
nmcli con de ens33
nmcli con add type ethernet ifname ens33 con-name ens33 ipv4.addresses 192.168.100.83/24 ipv4.gateway 192.168.100.2 ipv4.dns 192.168.100.2 ipv4.method manual autoconnect yes
- 设置hosts文件
# node1:
# 设置hosts文件,将三台主机的ip和主机名加入
cat << EOF >> /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.100.81 node1.example.com
192.168.100.82 node2.example.com
192.168.100.83 node3.example.com
EOF
# scp传输到另外两台主机
scp /etc/hosts node2.example.com:/etc/
scp /etc/hosts node3.example.com:/etc/
- 关闭防火墙和selinux
# 所有主机
systemctl disable --now firewalld
sed -i 's|enforcing|disabled|g' /etc/sysconfig/selinux
- 设置时间同步
# 所有主机
echo 'server ntp.aliyun.com iburst' >> /etc/chrony.conf
systemctl restart chronyd.service
systemctl enable chronyd --now
- 安装podman
# 所有主机
yum install -y podman
- 重启
安装部署ceph集群
- 安装openeuler专用cephadm
# 引导节点node1
yum install git -y
git clone https://gitee.com/yftyxa/openeuler-cephadm.git
cp openeuler-cephadm/cephadm /usr/sbin && chmod a+x /usr/sbin/cephadm
- 添加ceph源
# 所有主机均需
cat >> /etc/yum.repos.d/ceph.repo <<EOF
[ceph]
name=ceph x86_64
baseurl=https://repo.huaweicloud.com/ceph/rpm-pacific/el8/x86_64
enabled=1
gpgcheck=0
[ceph-noarch]
name=ceph noarch
baseurl=https://repo.huaweicloud.com/ceph/rpm-pacific/el8/noarch
enabled=1
gpgcheck=0
[ceph-source]
name=ceph SRPMS
baseurl=https://repo.huaweicloud.com/ceph/rpm-pacific/el8/SRPMS
enabled=1
gpgcheck=0
EOF
- 初始化ceph集群
# 引导节点node1
# mon-ip即web页面访问IP,user和password就是访问的账户和密码
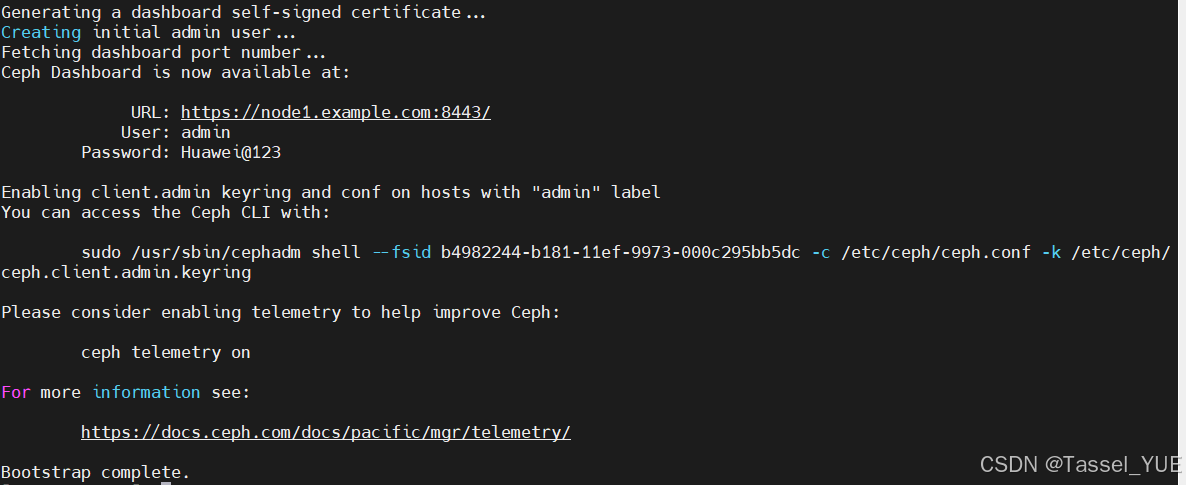
cephadm bootstrap --mon-ip 192.168.100.81 --allow-fqdn-hostname --initial-dashboard-user admin --initial-dashboard-password Huawei@123 --dashboard-password-noupdate
看到下图的url,证明安装成功


ceph集群添加node与osd
- 创建ceph shell(ceph集群的管理容器)
# node1
cephadm shell
# 也可以安装ceph-common (不用每次cephadm shell)
yum install ceph-common
查看状态
[ceph: root@node1 /]# ceph -s
cluster:
id: b4982244-b181-11ef-9973-000c295bb5dc
health: HEALTH_WARN
OSD count 0 < osd_pool_default_size 3
services:
mon: 1 daemons, quorum node1.example.com (age 6m)
mgr: node1.example.com.ehhbco(active, since 2m)
osd: 0 osds: 0 up, 0 in
data:
pools: 0 pools, 0 pgs
objects: 0 objects, 0 B
usage: 0 B used, 0 B / 0 B avail
pgs:
progress:
Updating grafana deployment (+1 -> 1) (0s)
[............................]
- 生成ceph公钥,并给到其他节点
# node1
ceph cephadm get-pub-key > ~/ceph.pub
ssh-copy-id -f -i ~/ceph.pub [email protected]
ssh-copy-id -f -i ~/ceph.pub [email protected]
- 添加节点进入集群
[ceph: root@node1 /]# ceph orch host add node2.example.com
Added host 'node2.example.com' with addr '192.168.100.82'
[ceph: root@node1 /]# ceph orch host add node3.example.com
Added host 'node3.example.com' with addr '192.168.100.83'
4. 查看状态
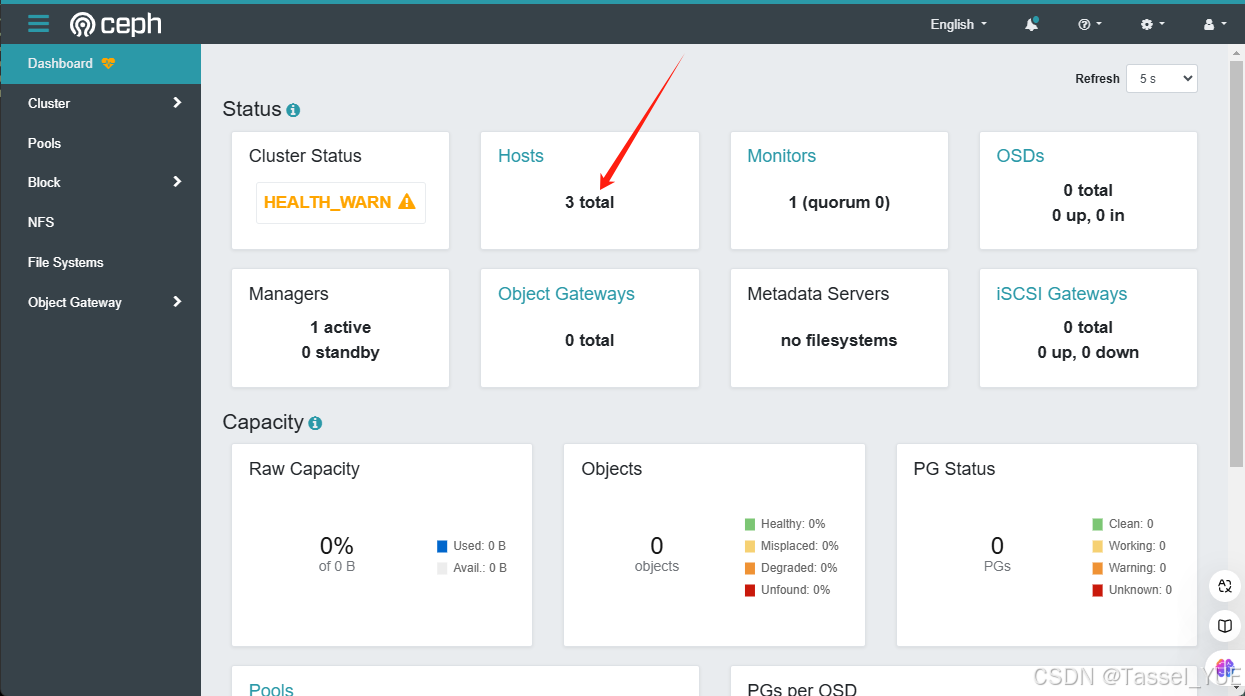
# 查看主机信息
[ceph: root@node1 /]# ceph orch host ls
HOST ADDR LABELS STATUS
主机名 地址 标签 状态(不正常才会有显示)
node1.example.com 192.168.100.81 _admin
node2.example.com 192.168.100.82
node3.example.com 192.168.100.83
3 hosts in cluster
- 给主机打标签
# ceph shell
[ceph: root@node1 /]# ceph orch host label add node2.example.com mgr_test
Added label mgr_test to host node2.example.com
[ceph: root@node1 /]# ceph orch host label add node2.example.com _admin
Added label _admin to host node2.example.com
[ceph: root@node1 /]# ceph orch host label add node3.example.com _admin
Added label _admin to host node3.example.com
# 查看状态
[ceph: root@node1 /]# ceph orch host ls
HOST ADDR LABELS STATUS
node1.example.com 192.168.100.81 _admin
node2.example.com 192.168.100.82 mgr_test _admin
node3.example.com 192.168.100.83 _admin
3 hosts in cluster
- 添加osd
ceph orch daemon add osd <主机名>:/path
# 手动添加某一块硬盘为osd
ceph orch daemon add osd node1.example.com:/dev/sdb
# 添加所有空闲硬盘为osd
ceph orch apply osd --all-available-devices
查看osd
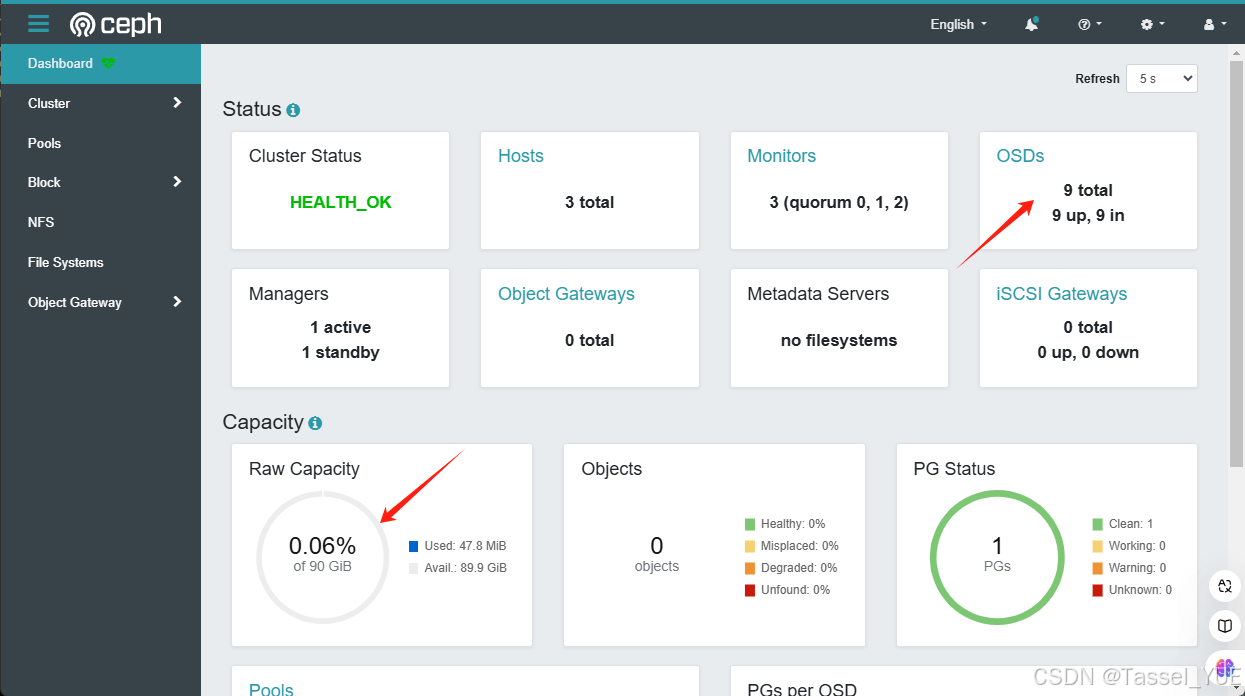
[ceph: root@node1 /]# ceph osd ls
0
1
2
3
4
5
6
7
8
ceph集群一些操作
组件服务操作
- 查询组件服务状态
[ceph: root@node1 /]# ceph orch ls
NAME PORTS RUNNING REFRESHED AGE PLACEMENT
服务名 IP加端口 运行状态/数量 刷新 运行 部署方式
alertmanager ?:9093,9094 1/1 23s ago 17m count:1
crash 3/3 26s ago 17m *
grafana ?:3000 1/1 23s ago 17m count:1
mgr 2/2 26s ago 17m count:2
mon 3/5 26s ago 17m count:5
node-exporter ?:9100 3/3 26s ago 17m *
prometheus ?:9095 1/1 23s ago 17m count:1
count:1 该服务组件只在某一个节点上进行部署
‘*’ : 表示该服务在所有节点上部署
主机名: 表示仅在特定主机上部署
标签名: 表示仅在指定标签主机上部署
- 关闭组件自扩展
为什么加入主机到集群后,ceph的组件会自动部署到主机上???
CEPH集群有节点自扩展能力,会自动部署集群所需要的组件数量
ceph orch apply <组件名> --unmanaged=true
# ceph shell
ceph orch apply mon --unmanaged=true
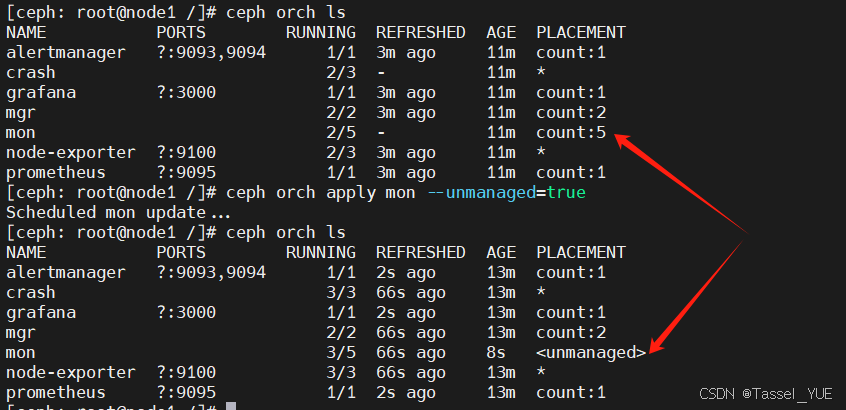
- 部署组件(编排)
ceph orch apply <组件名> xxxxx
# 指定部署3个mgr节点
ceph orch apply mgr --placement=3
# 可以指定标签
[ceph: root@node1 /]# ceph orch apply mon --placement="label:_admin"
Scheduled mon update...
- 部署组件(手动)
ceph orch daemon add <组件名> <主机名>
ceph orch daemon add mgr node3.example.com
集群进程操作
- 查看进程
ceph orch ps
- 启动进程
ceph orch start alertmanager #将所有节点上的服务启动起来
ceph orch daemon start node-exporter.node1 #启动指定节点上的服务进程
- 停止进程
ceph orch stop alertmanager #将所有节点上的进程停止
ceph orch daemon stop node-exporter.node1 #停止指定节点的指定进程
- 重启进程
ceph orch restart alertmanager #重启一组服务
ceph orch daemon restart alertmanager #重启单个进程(服务)
- 删除进程
ceph orch daemon rm node-exporter.node3 #删除指定节点的指定进程
ceph orch rm node-exporter #删除一组服务,在所有节点上删除该服务
# 需要添加回来,请参考上一步的部署服务