在完成了前面章节的学习之后,我们先了解了Qwen2的架构,然后通过动手搭建了RAG,Agent,对于大模型有了深入的了解。在最后一个章节的学习中,我们将学习如何实现对大模型的评测。
前置知识
以下是一些大模型评测常用的指标:
1. 准确性与精确性指标
准确率 (Accuracy):模型正确预测的比例,适用于分类任务,但受数据不平衡影响较大。
精确率 (Precision):在所有预测为正类的样本中,真正是正类的比例,用于衡量预测的精确程度。
召回率 (Recall):真正是正类的样本中,被正确预测为正类的比例,衡量模型发现正类的能力。
F1分数 (F1 Score):精确率和召回率的调和平均值,用于平衡两者的考量,特别是在数据不平衡时更为重要。
2. 模型效能指标
效率 (Efficiency):模型处理速度,如每秒处理样本数(Throughput),以及资源消耗,如内存使用、GPU/TPU小时等。
推理延迟 (Inference Latency):单个请求的处理时间,影响用户体验。
3. 泛化能力与鲁棒性指标
交叉验证得分 (Cross-Validation Scores):使用如K折交叉验证评估模型在未见过数据上的表现。
ROC AUC (Receiver Operating Characteristic Area Under the Curve):衡量二分类模型区分正负例的能力。
Robustness Metrics:评估模型在对抗性攻击或输入噪声下的稳定性。
4. 可解释性指标
LIME (Local Interpretable Model-Agnostic Explanations) 或 SHAP (SHapley Additive exPlanations):提供模型决策的局部解释,帮助理解模型为何做出特定预测。
Attention Maps:对于基于注意力机制的模型,可视化注意力分布,理解模型关注哪些输入特征。
5. 安全性与合规性指标
隐私保护评估:检查模型是否泄露训练数据信息,如通过差分隐私测试。
内容安全:检测模型输出是否存在不良内容、歧视性言论等,确保模型输出符合法律法规和社会伦理。
6. 经济效益与实际应用指标
ROI (Return on Investment):评估模型部署后带来的经济回报。
用户满意度:直接从用户反馈获取,衡量模型在实际应用中的效果。
技术创新指标:衡量模型引入的新技术或改进对行业发展的推动作用。
7. 多模态评估指标
BLEU (Bilingual Evaluation Understudy) 或 ROUGE (Recall-Oriented Understudy for Gisting Evaluation):用于评估机器翻译或文本摘要的质量。
mAP (mean Average Precision):在图像识别和目标检测任务中,衡量模型在不同召回率下的平均精确率。
下面我们以F1 Score为例做个详细介绍
示例情境如下:假设我们有一个电子邮件分类器,任务是识别垃圾邮件(正例)和非垃圾邮件(反例)。我们用这个分类器对一个包含100封邮件的数据集进行了预测,其中实际上有20封是垃圾邮件,80封是非垃圾邮件。分类器预测的结果是,它标记了15封邮件为垃圾邮件,其中12封确实是垃圾邮件,而其余3封实际上是正常邮件;另外,它将85封邮件预测为非垃圾邮件,其中78封预测正确,7封实际上是垃圾邮件。
首先,根据预测结果,我们可以构建一个混淆矩阵:

这里,TP(True Positive)表示真正为垃圾邮件且被正确预测为垃圾邮件的数量,FP(False Positive)表示实际不是垃圾邮件但被错误预测为垃圾邮件的数量,FN(False Negative)表示实际是垃圾邮件但被错误预测为非垃圾邮件的数量,TN(True Negative)表示实际不是垃圾邮件且被正确预测为非垃圾邮件的数量。
计算精准率和召回率
- 精确率 (Precision):预测为垃圾邮件中真正是垃圾邮件的比例。

- 召回率 (Recall):真正垃圾邮件中被正确识别的比例。

计算F1 Score
最后,使用精确率和召回率来计算F1 Score。
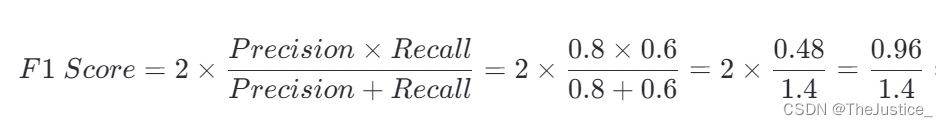
因此,这个电子邮件分类器的F1 Score约为0.686,表明其在垃圾邮件识别任务上的综合性能尚可,但有提升空间,特别是需要提高召回率以减少漏检的垃圾邮件数量,同时保持或优化精确率,以减少误报。
其他的评测指标计算方法各有差异,因为篇幅限制此处不再详细解释。
Eval包含的流程
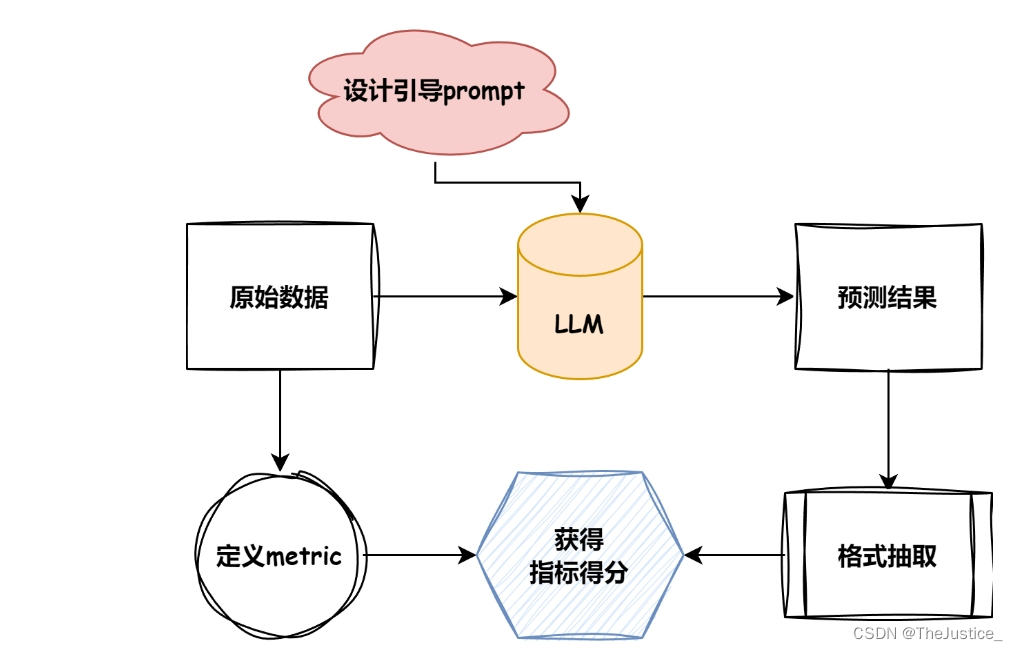
上图是评测任务的简要流程,可以概括如下:
- 首先,根据目标数据集的任务类型指定合理的评测
metric.- 根据目标数据的形式总结模型引导
prompt.- 根据模型初步预测结果采纳合理的抽取方式.
- 对相应的
pred与anwser进行得分计算.
常用的metric与情境:

评测过程介绍
对于F1 Score适用于大模型评测的原因如下:
F1 Score作为分类指标可以来评测大模型,因为它综合考虑了精确率和召回率,能够平衡模型的查准与查全能力。
模型推理
- 首先,对于一个评测数据集,我们首先要构造引导prompt,即引导llm生成我们想要的答案。对于已有的数据集,大部分都提供了相应的prompt,在自己数据集评测时,也可自行设计。以
multifieldqa_zh为例,其引导prompt为:
阅读以下文字并用中文简短回答:\n\n{context}\n\n现在请基于上面的文章回答下面的问题,只告诉我答案,不要输出任何其他字词。\n\n问题:{input}\n回答:
-
之后,再指定模型的输入长度,在此主要是规定每次送进模型多少token数,一般为了追求性能可以设置为模型最大长度,可以在下载好的模型文件里面的
config.json里面的"max_position_embeddings"查询,也可以不设置作为默认最大长度.但本项目设置为了2048,主要为了演示使用~ -
之后就是创建model整体,在此我对模型整体创建了一个class,大家可以参考对其他任意的model进行组装:
class BaseLLM:
def __init__(self, path: str, model_name: str) -> None:
self.path = path
self.model_name = model_name
def build_chat(self, tokenizer: str, prompt: str, model_name: str):
pass
def load_model_and_tokenizer(self, path: str, model_name: str, device):
pass
def post_process(self, response: str, model_name: str):
pass
def get_pred(self, data: list, max_length: int, max_gen: int, prompt_format: str, device, out_path: str):
pass- 参数解读,build_chat为使用模型固有的数据加载形式,以
internlm2为例,其为
def build_chat(self, prompt):
prompt = f'<|im_start|>user\n{prompt}<|im_end|>\n<|im_start|>assistant\n'
return prompt
- model与tokenizer不用多说,后处理根据model的形式选择性判断是否需要,重点讲一下
get_pred函数:
def get_pred(self, data, max_length, max_gen, prompt_format, device, out_path):
model, tokenizer = self.load_model_and_tokenizer(self.path, device)
for json_obj in tqdm(data):
prompt = prompt_format.format(**json_obj)
# 在中间截断,因为两头有关键信息.
tokenized_prompt = tokenizer(prompt, truncation=False, return_tensors="pt").input_ids[0]
if len(tokenized_prompt) > max_length:
half = int(max_length/2)
prompt = tokenizer.decode(tokenized_prompt[:half], skip_special_tokens=True)+tokenizer.decode(tokenized_prompt[-half:], skip_special_tokens=True)
prompt = self.build_chat(prompt)
input = tokenizer(prompt, truncation=False, return_tensors="pt").to(device)
# 表示喂进去的tokens的长度
context_length = input.input_ids.shape[-1]
eos_token_id = [tokenizer.eos_token_id, tokenizer.convert_tokens_to_ids(["<|im_end|>"])[0]]
output = model.generate(
**input,
max_new_tokens=max_gen,
do_sample=False,
temperature=1.0,
eos_token_id=eos_token_id,
)[0]
pred = tokenizer.decode(output[context_length:], skip_special_tokens=True)
pred = self.post_process(pred)
with open(out_path, "a", encoding="utf-8") as f:
json.dump({"pred": pred, "answers": json_obj["answers"], "all_classes": json_obj["all_classes"], "length": json_obj["length"]}, f, ensure_ascii=False)
f.write('\n')此处不使用model.chat()的原因就在于截断策略,对于模型而言,尤其是制定了输入的长度,如果使用阶段命令则其会在输入的末尾进行阶段,但由于引导性prompt的存在,在inputs的两端均有关键信息,故需要对两端的信息进行保留,对中间部位进行截断操作,才能最大限度地保持输出效果。
结果评测
def f1_score(prediction, ground_truth, **kwargs):
# Counter以dict的形式存储各个句子对应的词与其对应个数,&操作符返回两个Counter中共同的元素的键值对
common = Counter(prediction) & Counter(ground_truth)
# 显示prediction与gt的共同元素的个数
num_same = sum(common.values())
if num_same == 0:
return 0
# 即模型预测正确的样本数量与总预测样本数量的比值
precision = 1.0 * num_same / len(prediction)
# 模型正确预测的样本数量与总实际样本数量的比值
recall = 1.0 * num_same / len(ground_truth)
f1 = (2 * precision * recall) / (precision + recall)
return f1该代码的作用为将预测值和答案的关键值带入,算出共同的元素个数,带入F1 Score的公式计算
最后应该对所有的结果取平均值得到最后答案。
评测指标拓展
1. 多类分类的宏观平均和微观平均
在多分类问题中,除了单一对立面的F1 Score,还可以计算每个类别的F1 Score,然后取平均得到宏观平均F1 Score(不考虑类别不平衡)或微观平均F1 Score(考虑所有类别的TP, FP, FN)。
2. ROC AUC 和 PR曲线
ROC曲线(Receiver Operating Characteristic Curve):通过改变分类阈值,展示真正例率(TPR)与假正例率(FPR)的关系。AUC(Area Under the Curve)是ROC曲线下的面积,AUC值越接近1,表示模型区分正负样本的能力越强。
PR曲线(Precision-Recall Curve):当数据不平衡时,PR曲线比ROC曲线更能体现模型性能。曲线下的面积(AUC-PR)也是常用的评估指标。
3. Log Loss(交叉熵损失)
特别是在概率预测任务中,Log Loss(也称为交叉熵损失)能很好地衡量预测概率与实际标签之间的差距,对于评估模型的不确定性很有帮助。
4. Calibration Error(校准误差)
评估模型预测概率与实际观察到的概率一致性,即模型预测某事件发生的概率应该接近该事件实际发生的频率。常用ECE(Expected Calibration Error)或MCE(Maximum Calibration Error)来量化。
5. Error Analysis(错误分析)
手动或自动审查模型预测错误的实例,理解错误模式,如特定类型的数据导致的错误,这对于定位模型弱点和后续改进至关重要。
6. Counterfactual Fairness(反事实公平性)
在AI道德和公平性评估中,考虑如果某个敏感属性(如性别、种族)改变,模型预测是否会改变。这有助于评估模型是否在决策中存在不公平偏见。
7. Explainability and Interpretability(可解释性和可解释性)
使用如LIME、SHAP、Attention Maps等工具来解释模型的决策过程,确保模型不仅性能好,而且决策过程透明可理解。
8. Stress Testing(压力测试)
通过引入极端情况或对抗性样本,测试模型在非典型或恶意输入下的鲁棒性。
9. Model Complexity and Compute Efficiency(模型复杂度和计算效率)
评估模型的参数量、训练/推理时间、资源消耗等,确保模型在满足性能要求的同时,具有良好的效率和可部署性。
10. Continual Learning Evaluation(持续学习评估)
对于需要不断学习新数据的场景,评估模型的遗忘旧知识的程度(灾难性遗忘)和适应新任务的能力。
下面对ROC AUC和PR曲线,以及Log Loss进行详细地介绍
ROC AUC
概念:
ROC曲线展示了分类器在所有可能的分类阈值下的真正例率(True Positive Rate, TPR)与假正例率(False Positive Rate, FPR)之间的权衡。TPR定义为真正例(TP)占所有实际正例(TP + FN)的比例,而FPR为假正例(FP)占所有实际反例(FP + TN)的比例。AUC是ROC曲线下的面积,取值范围从0.5到1,AUC值越接近1,表示模型区分正负样本的能力越强。
示例:
假设你有一个银行欺诈检测系统,正在评估其在预测交易是否为欺诈交易的能力。ROC曲线会显示,随着我们降低欺诈预测的阈值(即更倾向于认为交易是欺诈的),TPR如何增加(捕获更多真实欺诈交易),同时FPR也增加(更多正常交易被错误地标记为欺诈)。AUC值可以帮助我们量化整个操作范围内系统的整体性能。
PR曲线
概念:
PR曲线展示了精确率(Precision)与召回率(Recall)之间的关系,随着分类阈值的变化。精确率定义为真正例占预测为正例的所有样本的比例(TP / [TP + FP]),而召回率同上定义为真正例占所有实际正例的比例。PR曲线适用于类别不平衡的数据集,因为它更关注正例的分类质量。
示例:
继续上面的欺诈检测系统例子,PR曲线在此场景下特别有用,因为欺诈交易通常是少数。通过绘制PR曲线,我们能更好地了解在提高召回率的同时,精确率是如何变化的。例如,如果模型在低阈值下召回了所有欺诈交易,但同时预测了很多正常交易为欺诈(低精确率),这会在PR曲线上反映出来,帮助我们找到一个平衡点。
Log Loss
概念: Log Loss,或称对数损失,是衡量预测概率与实际标签差异的一种损失函数,广泛应用于逻辑回归和分类问题的评估。对于二分类问题,对数损失定义为:

其中,N 是样本总数,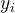
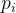
假设模型预测一个样本为正例的概率是0.9,而实际标签为1(正例),那么该样本的对数损失贡献是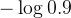
总结:本文对于大模型评测体系的一些基础知识以及F1 Score的具体代码实现进行了讲解,也介绍了一些更为有效的评测指标,希望在今后学习的过程中能掌握更多更有效的评测方法。