
本案例将介绍如何爬取豆瓣电影简介,以此帮助读者学习如何通过编写爬虫程序来批量地从互联网中获取信息。本案例中将借助两个第三方库——Requests库和BeautifulSoup库。通过Requests库获取相关的网页信息,通过BeautifulSoup库解析大体框架信息的内容,并且将局部信息中最关键的内容提取出来。通过使用第三方库,读者可以实现定向网络爬取和网页解析的基本目标。
01
确定信息源
首先,需要明确要爬取哪些内容,并精确到需要爬取的网页。在本案例中需要爬取电影的简介,因此选择信息较为全面的豆瓣电影。
进入“豆瓣电影”首页,如图3-1所示,可以看到各种推荐的电影。

■ 图3-1豆瓣电影首页
选择其中任意一部电影,进入电影简介页面,如图3-2所示。可以发现每部电影的简介页面都具有相似的结构,这为编写爬虫程序提供了极大的方便。这意味着只需要以某部电影的电影简介页面为模板编写爬虫程序,此后便可以运用到豆瓣网站中其他所有电影简介的页面。

■ 图3-2豆瓣电影简介页面
02
获取网页信息
确定了需要爬取的网页后,需要如何获取这些信息呢?要知道网页是一个包含HTML标签的纯文本文件。可以通过使用Requests库的request()方法向指定网址发送请求获得的文本文件。注意,在使用Python第三方库前需要在本机上安装第三方库,可以使用pip方式或者其他方式安装。
1. Requests库的两个主要方法
下面先来简单介绍本实验需要用到的Requests库的两个主要方法。
(1) requests.request()方法。该方法的作用是构造一个请求,是支持其他方法的基础方法。
(2) requests.get()方法。该方法是本案例需要用到的一个获取网页的方法,会构造一个向服务器请求资源的Request对象,然后返回一个包含服务器资源的Response对象。其作用是获取HTML网页,对应于HTTP的GET。调用该方法需要一些参数。
① requests.get(url, params=None, **kwargs)。
② url:需要获取页面的URL链接。
③ params:可选参数,URL中的额外参数,字典或字节流格式。
④ kwargs:12个控制访问的参数。
2. Response对象机器属性
Response对象包含服务器放回的所有信息,也包含请求的Request信息。该对象具如下属性。
① status_code:HTTP请求的返回状态,200表示链接成功。只有链接成功的对象内容才是正确有效的,而对于链接失败的行为则产生异常的结果。这里可以使用raise_for_status()方法。该方法会判断status_code是否等于200,如果不等于则产生异常requests.HTTPError。
② text:HTTP相应内容的字符串形式,也即URL对应的页面内容。这部分也是爬虫需要获得的最重要部分。
③ encoding:从HTTP header中猜测的响应内容的编码方式。选择正确的编码方式才能得到可读的正确信息内容。
④ apparent_encoding:从内容中分析出响应内容的编码方式。
学习完上面的基础知识,就可以利用Requests库编写程序来获取“豆瓣电影”首页的信息。获取“豆瓣电影”首页信息的程序如图3-3所示。

■ 图3-3获取“豆瓣电影”首页信息的程序
在控制台里就能够看见“豆瓣电影”首页HTTP相应内容的字符串形式,如图3-4所示。

■ 图3-4控制台输出的部分内容
03
解析信息内容
浏览器通过解析HTML文件,展示丰富的网页内容。HTML是一种标识性的语言。HTML文件是由一组尖括号形成的标签组织起来的,每对括号形成一对标签,标签之间存在一定的关系,形成标签树。可以利用BeautifulSoup库解析、遍历、维护这样的“标签树”。
【注意】对于没有HTML基础的读者,简单学习HTML后将有助于对本书后续内容的理解。
1. BeautifulSoup库中的一些基本元素
Tag:标签,最基本的信息组织单元,用<>标明开头,标明结尾。任何标签都可以用soup.<tag>访问获得,如果HTML文档中存在多个相同<tag>对应内容时,soup.<tag>返回第一个该类型标签的内容。
Name:标签的名字,即尖括号中的字符串。如
…
的name是’p’。每个都有自己的名字,可通过.name获取。
Attributes:标签的属性,字典形式组织。一个 可以有零个或多个属性。可以通过.attrs获取。
NavigableString:标签内非属性字符串,即<>和之间的字符串。可以通过.string调用。
Comment:标签内字符串的注释部分,一种特殊的Comment类型。
2. BeautifulSoup库的三种遍历方式
由于HTML格式是一个树状结构,BeautifulSoup库提供了三种遍历方式,分别为下行遍历、上行遍历和平行遍历。利用下列属性可以轻松地对其进行遍历操作。
(1) 下行遍历。
.contents:子节点的列表,将所有的儿子节点存入列表。
.children:子节点的迭代类型,与.contents相似。
.descendants:子孙节点的迭代类型,包含所有子孙节点。
(2) 上行遍历。
.parent:节点的父亲标签。
.parents:节点先辈标签的迭代类型。
(3) 平行遍历。
.next_sibling:返回按照HTML文本顺序的下一个平行节点标签。
.previous_sibling:返回按照HTML文本顺序的上一个平行节点标签。
.next_siblings:迭代类型,返回按照HTML文本顺序的所有平行节点标签。
.previous_siblings:迭代类型,返回按照HTML文本顺序的前续所有平行节点标签。
3. 查找内容
该如何对所需要的内容进行查找呢?这就需要用到一个方法<>.find_all(name, attrs, recursive, string,kwargs)。其中,name:对标签名称的检索字符串,attrs:对标签属性值的检索字符串,recursive:是否对子孙全部检索,默认为True,string:<>…<>中字符串区域的检索字符串。因此,可以利用该方法对所需要的成员进行特征检索。该方法还有许多拓展方法,在此就不一一介绍了,感兴趣的读者可以自行阅读相关文件。
4. 定位文本内容
如果想定位所需要的文本内容,则要在需要爬取的页面按F12键,便调出开发者界面,即可直接查看该网页的HTML文本。Chrome浏览器开发者模式如图3-5所示。

■ 图3-5Chrome浏览器开发者模式
可以单击图3-6中的

■ 图3-6按钮
例如,可以在图3-5所示的页面中快速定位该影片导演的信息所在的位置,如图3-7所示。

■ 图3-7导演信息的HTML文本
通过观察可以发现,“ span class=“pl” 导演 / span”标签的平行标签中NavigableString便是需要的导演名字。以此方法,可以快速定位电影编剧、主演、类型等信息。通过比较多个网页发现标签中的共同元素,便可以通过编写程序快速解析出需要的信息,并运用于所有的豆瓣电影简介页面。
下面编写程序来实验一下,如图3-8所示。

■ 图3-8获取电影《1917》导演的爬虫程序
在控制台就可以看到输出的导演名字“萨姆·门德斯”。类似地,根据其他标签的特征,也可以爬取其他信息。
关于Python学习指南
学好 Python 不论是就业还是做副业赚钱都不错,但要学会 Python 还是要有一个学习规划。最后给大家分享一份全套的 Python 学习资料,给那些想学习 Python 的小伙伴们一点帮助!
包括:Python激活码+安装包、Python web开发,Python爬虫,Python数据分析,人工智能、自动化办公等学习教程。带你从零基础系统性的学好Python!
👉Python所有方向的学习路线👈
Python所有方向路线就是把Python常用的技术点做整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。(全套教程文末领取)
👉Python学习视频600合集👈
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。
温馨提示:篇幅有限,已打包文件夹,获取方式在:文末
👉Python70个实战练手案例&源码👈
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉Python大厂面试资料👈
我们学习Python必然是为了找到高薪的工作,下面这些面试题是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有阿里大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。
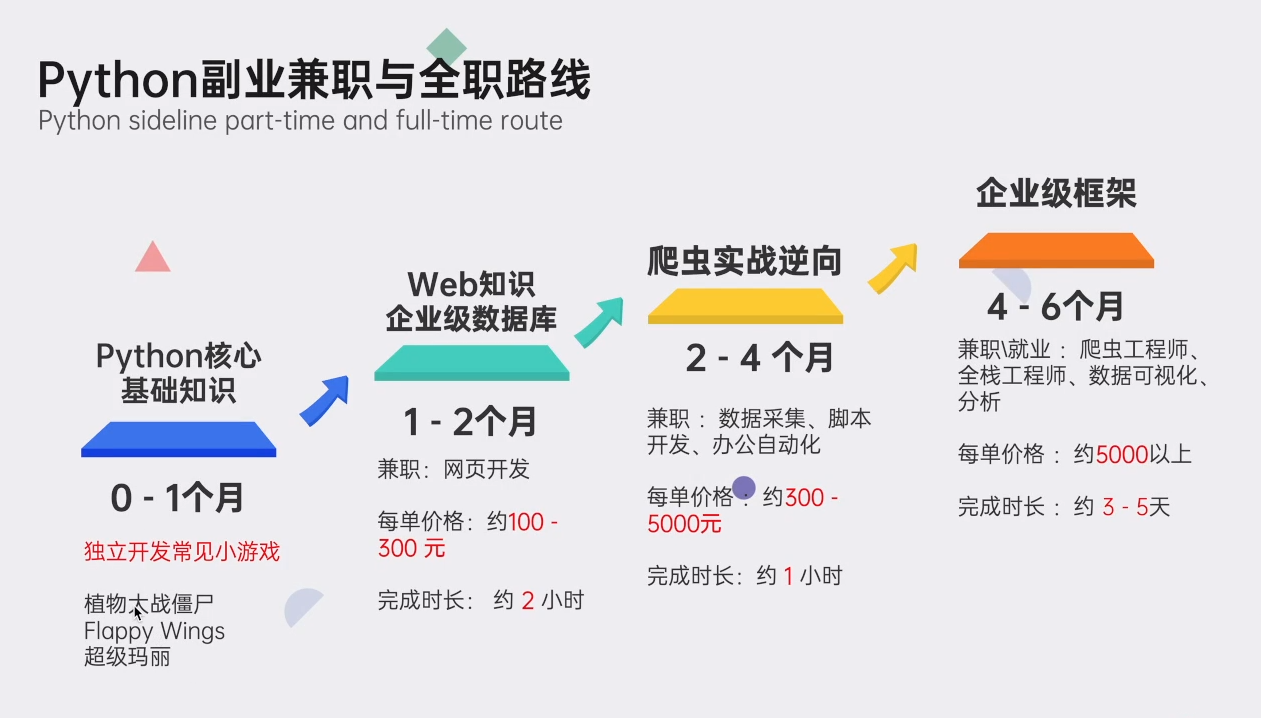
👉Python副业兼职路线&方法👈
学好 Python 不论是就业还是做副业赚钱都不错,但要学会兼职接单还是要有一个学习规划。
👉 这份完整版的Python全套学习资料已经上传,朋友们如果需要可以扫描下方CSDN官方认证二维码或者点击链接免费领取【保证100%免费】
