作者:来自 Elastic Benjamin Trent
Lucene 和 Elasticsearch 中更好的二进制量化 (BBQ)。
嵌入模型输出 float32 向量,通常对于高效处理和实际应用来说太大。Elasticsearch 支持 int8 标量量化,以减小向量大小,同时保持性能。其他方法会降低检索质量,并且不适用于实际使用。在 Elasticsearch 8.16 和 Lucene 中,我们引入了更好的二进制量化 (BBQ),这是一种新方法,从新加坡南洋理工大学的研究人员提出的一项最新技术 “RaBitQ” 中汲取的见解中发展而来。
BBQ 是 Lucene 和 Elasticsearch 在量化方面的一次飞跃,将 float32 维度缩减为位,在保持高排名质量的同时减少约 95% 的内存。BBQ 在索引速度(量化时间减少 20-30 倍)、查询速度(查询速度提高 2-5 倍)方面优于乘积量化 (Product Quantization - PQ) 等传统方法,并且不会额外损失准确性。
在本博客中,我们将探索 Lucene 和 Elasticsearch 中的 BBQ,重点关注召回率、高效的按位运算和优化的存储,以实现快速、准确的向量搜索。
更好的二进制量化中的 “更好” 是什么意思?
在 Elasticsearch 8.16 和 Lucene 中,我们引入了所谓的 “Better Binary Quantization - 更好的二进制量化”。简单的二进制量化具有极高的损耗,要实现足够的召回率,需要收集 10 倍或 100 倍的额外邻居来重新排序。这根本行不通。
更好的二进制量化来了!以下是更好的二进制量化和简单的二进制量化之间的一些显著差异:
- 所有向量都围绕质心(centroid)进行归一化。这解锁了量化中的一些良好属性。
- 存储了多个错误校正值。其中一些校正用于质心归一化,一些用于量化。
- 非对称量化。在这里,虽然向量本身存储为单个位值(bit value),但查询仅量化为 int4。这显著提高了搜索质量,而无需额外的存储成本。
- 用于快速搜索的按位操作。查询向量以允许高效按位操作的方式进行量化和转换。
使用更好的二进制量化进行索引
索引很简单。请记住,Lucene 会构建单独的只读段。随着向量进入新的段,质心(centroid)会逐渐计算。然后,一旦段被刷新,每个向量都会围绕质心进行规范化和量化。
这是一个小例子:

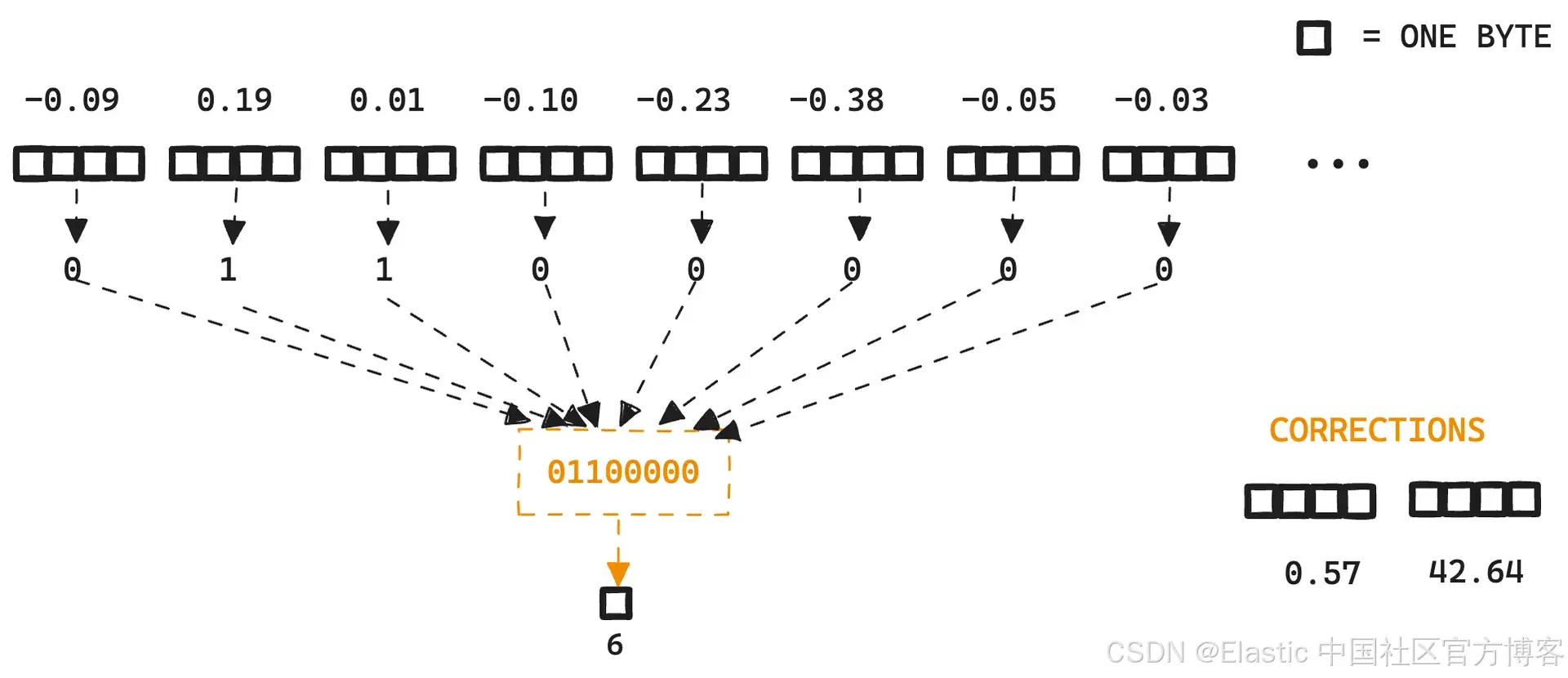
然后,将每个位打包成一个字节,并与所选向量相似性所需的任何错误校正值一起存储在段中。
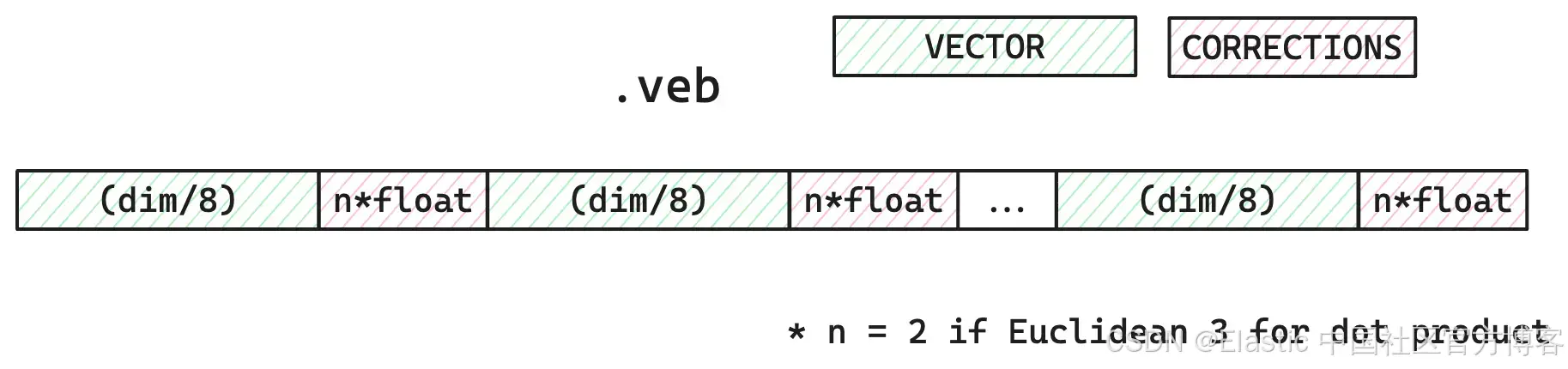
让我们快速讨论一下我们如何处理段合并
当段合并时,我们可以利用先前计算的质心。只需对质心进行加权平均,然后重新量化新质心周围的向量。
棘手的是确保 HNSW 图质量并允许使用量化向量构建图。如果你仍然需要所有内存来构建索引,量化有什么意义?!
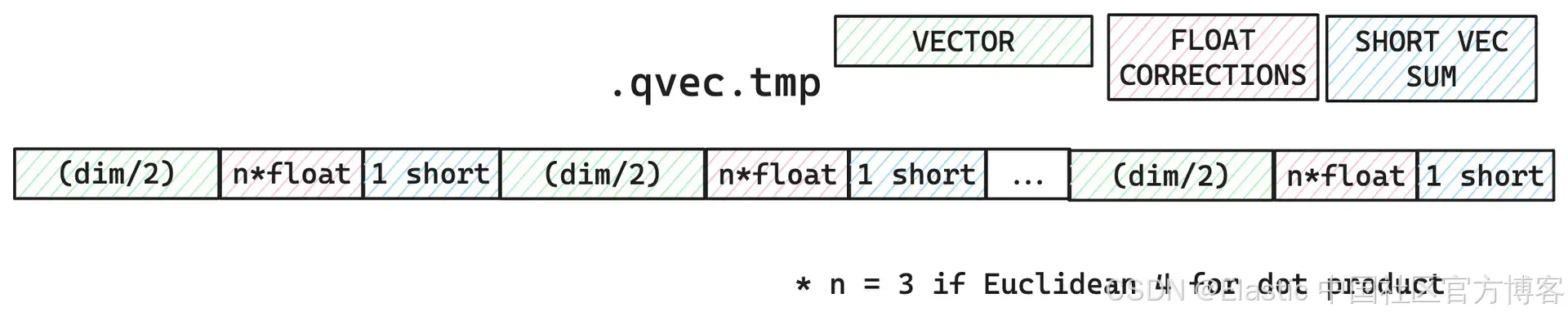
除了将向量附加到现有最大的 HNSW 图之外,我们还需要确保向量评分可以利用非对称量化。HNSW 有多个评分步骤:一个用于初始邻居集合,另一个用于确保只有不同的邻居连接。为了有效地使用非对称量化,我们创建了一个临时文件,其中包含所有量化为 4 位查询向量的向量。
因此,当将向量添加到图中时,我们首先:
- 获取存储在临时文件中的已量化查询向量。
- 使用已经存在的位向量正常搜索图。
- 一旦我们有了邻居,就可以使用先前的 int4 量化值进行多样性和反向链接评分。
合并完成后,临时文件将被删除,仅留下位量化向量。
非对称量化,有趣的部分
我提到了非对称量化以及我们如何布局查询以构建图形。但是,向量实际上是如何转换的?它是如何工作的?
“Asymmetric - 非对称” 部分很简单。我们将查询向量量化为更高的保真度。因此,doc 值是位量化的,查询向量是 int4 量化的。更有趣的是这些量化向量如何转换为快速查询。
以上面的示例向量为例,我们可以将其量化为以质心为中心的 int4。
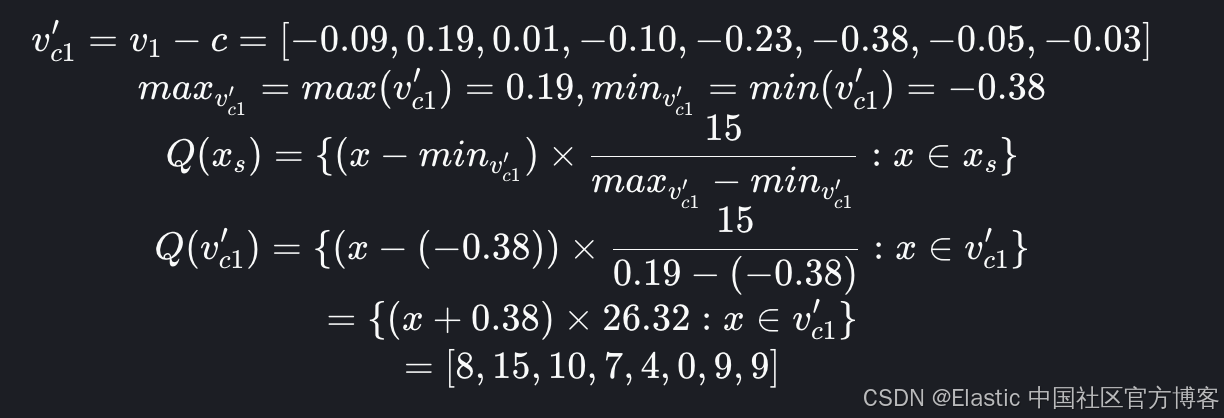
有了量化向量,乐趣就开始了。因此,我们可以将向量比较转换为按位点积,位移位。
最好只是直观地了解正在发生的事情:
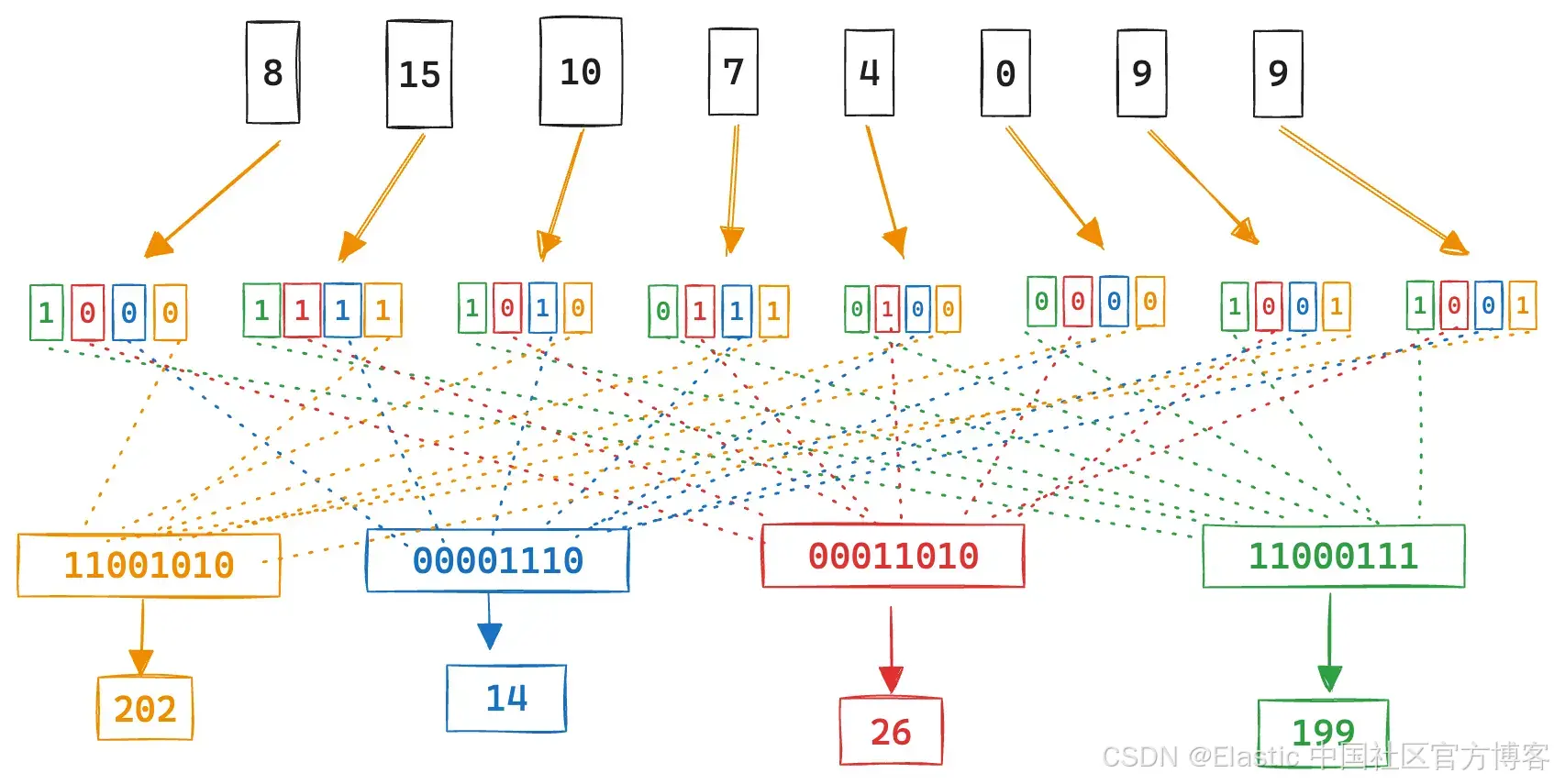
但这实际上如何转化为点积?请记住,点积是组件积的总和。对于上面的例子,让我们完整地写出来:
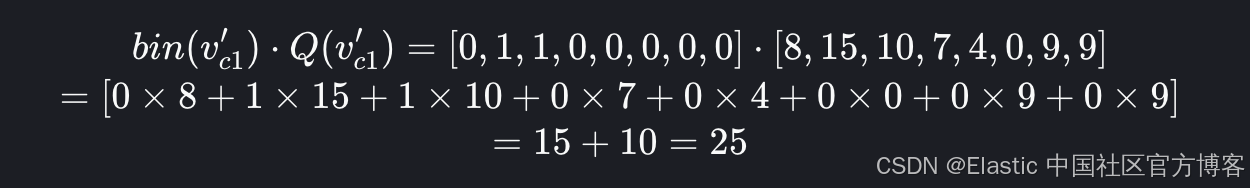
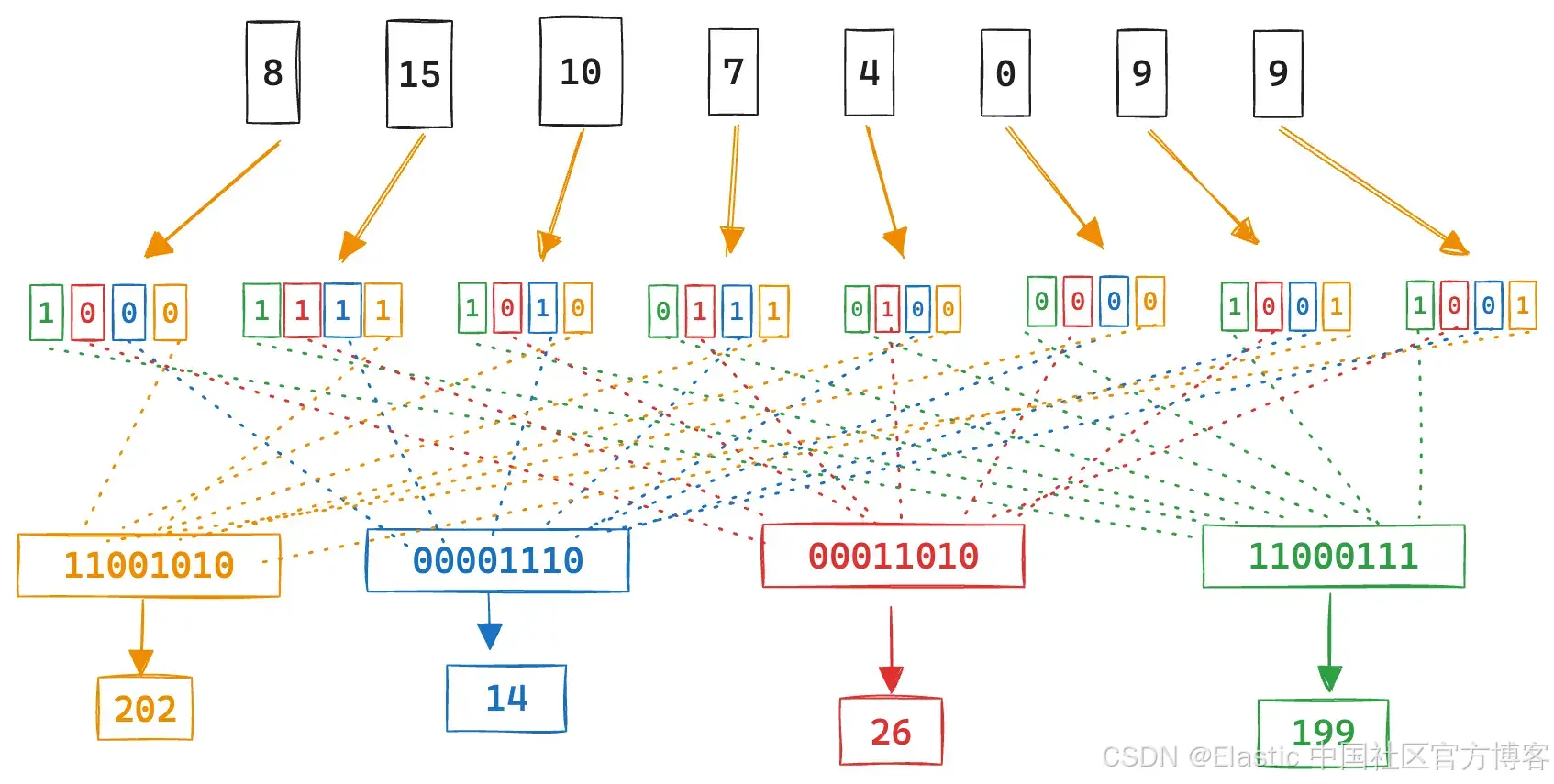
我们可以看到,它只是查询组件的总和,其中存储的向量位为 1。由于所有数字都只是位,因此当使用二进制扩展表示时,我们可以移动一些位置以利用按位运算。
在 & 之后将被翻转的位将是构成点积的数字的各个位。在这种情况下,15 和 10。
记住我们最初存储的向量:

现在我们可以计算位数,移位并求和。我们可以看到剩下的所有位都是 15 和 10 的位置位。

与直接对维度求和的答案相同。
以下是示例,但简化了 Java 代码:
byte[] bits = new byte[]{6};
byte[] queryBits = new byte[]{202, 14, 26, 199};
for (int i = 0; i < 4; i++) {
sum += Integer.bitCount(bits[0] & queryBits[i] & 0xFF) << i;
}好吧,给我看看这些数字
我们已经在 Lucene 和 Elasticsearch 中直接对 BBQ 进行了广泛的测试。以下是一些结果:
Lucene 基准测试
这里的基准测试是在三个数据集上进行的:E5-small、CohereV3 和 CohereV2。这里,每个元素表示召回率@100,过采样率为 [1, 1.5, 2, 3, 4, 5]。
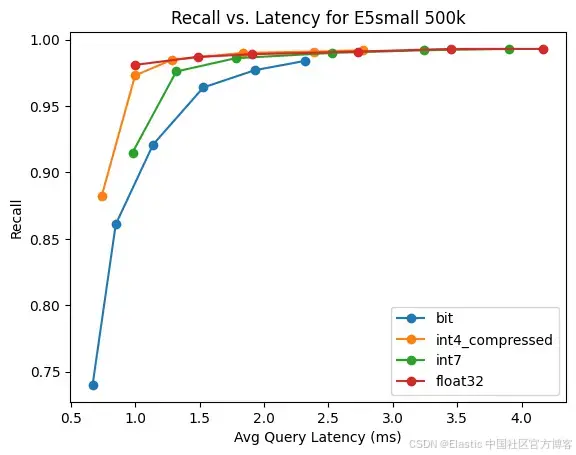
E5-small
这是从 quora 数据集构建的 E5-small 的 500k 个向量。
| quantization | Index Time | Force Merge time | Mem Required |
|---|---|---|---|
| bbq | 161.84 | 42.37 | 57.6MB |
| 4 bit | 215.16 | 59.98 | 123.2MB |
| 7 bit | 267.13 | 89.99 | 219.6MB |
| raw | 249.26 | 77.81 | 793.5MB |
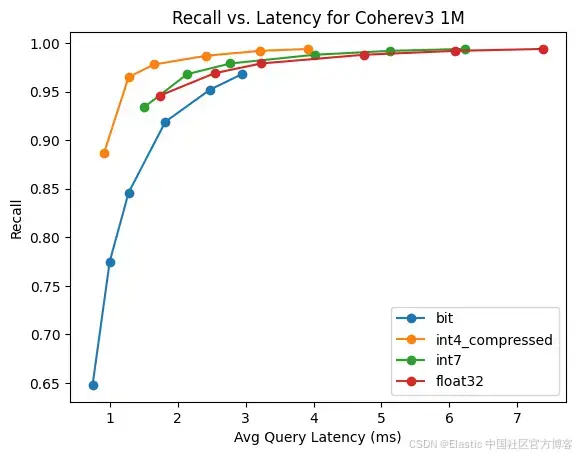
CohereV3
这是 1M 1024 维向量,使用 CohereV3 模型。
| quantization | Index Time | Force Merge time | Mem Required |
|---|---|---|---|
| bbq | 338.97 | 342.61 | 208MB |
| 4 bit | 398.71 | 480.78 | 578MB |
| 7 bit | 437.63 | 744.12 | 1094MB |
| raw | 408.75 | 798.11 | 4162MB |
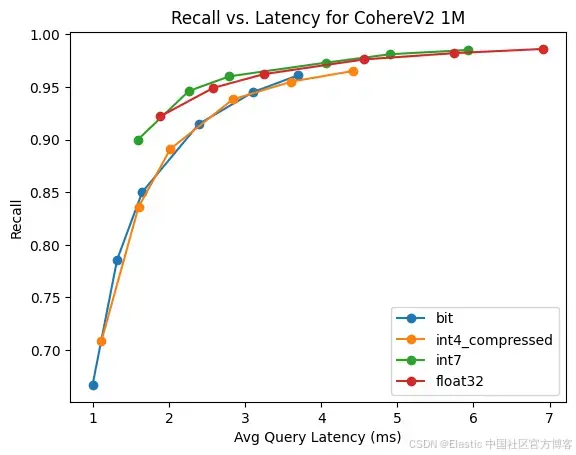
CohereV2
这是 1M 768 维向量,使用 CohereV2 模型和最大内积相似度。
| quantization | Index Time | Force Merge time | Mem Required |
|---|---|---|---|
| bbq | 395.18 | 411.67 | 175.9MB |
| 4 bit | 463.43 | 573.63 | 439.7MB |
| 7 bit | 500.59 | 820.53 | 833.9MB |
| raw | 493.44 | 792.04 | 3132.8MB |
更大规模 Elasticsearch 基准测试
正如我们在更大规模向量搜索博客中提到的,我们有一个用于更大规模向量搜索基准测试的 rally track。
该数据集有 138M 个 1024 维浮点向量。如果没有任何量化,使用 HNSW 需要大约 535 GB 的内存。如果使用更好的二进制量化,估计会下降到大约 19GB。
对于此测试,我们在 Elastic 云中使用了一个 64GB 的节点,具有以下 track 参数:
{
"mapping_type": "vectors-only",
"vector_index_type": "bbq_hnsw",
"number_of_shards": 2,
"initial_indexing_bulk_indexing_clients": 12,
"standalone_search_clients": 8,
"aggressive_merge_policy": true,
"search_ops": [[10, 20, 0], [10, 20, 20], [10, 50, 0], [10, 50, 20], [10, 50, 50], [10, 100, 0], [10, 100, 20], [10, 100, 50], [10, 100, 100], [10, 200, 0], [10, 200, 20], [10, 200, 50], [10, 200, 100], [10, 200, 200], [10, 500, 0], [10, 500, 20], [10, 500, 50],[10, 500, 100],[10, 500, 200],[10, 500, 500],[10, 1000, 0], [10, 1000, 20], [10, 1000, 50], [10, 1000, 100], [10, 1000, 200], [10, 1000, 500], [10, 1000, 1000]]
}重要提示:如果你想要复制,下载所有数据将花费大量时间,并且需要超过 4TB 的磁盘空间。需要所有额外磁盘空间的原因是此数据集还包含文本字段,并且你需要磁盘空间来存储压缩文件及其膨胀大小。
参数如下:
- k 是要搜索的邻居数
- num_candidates 是 HNSW 中每个分片用于探索的候选数
- rerank 是要重新排序的候选数,因此我们将收集每个分片的多个值,收集总重新排序大小,然后使用原始 float32 向量对前 k 个值重新评分。
对于索引时间,大约需要 12 小时。这里不显示所有结果,而是显示三个有趣的结果:
| k-num_candidates-rerank | Avg Nodes Visited | % Of Best NDGC | Recall | Single Query Latency | Multi-Client QPS |
|---|---|---|---|---|---|
| knn-recall-10-100-50 | 36,079.801 | 90% | 70% | 18ms | 451.596 |
| knn-recall-10-20 | 15,915.211 | 78% | 45% | 9ms | 1,134.649 |
| knn-recall-10-1000-200 | 115,598.117 | 97% | 90% | 42.534ms | 167.806 |
这表明了平衡召回率、过采样、重新排序和延迟的重要性。显然,每个都需要针对你的特定用例进行调整,但考虑到这在以前是不可能的,而现在我们在单个节点中拥有 138M 个向量,这非常酷。
结论
感谢你花一点时间阅读有关 Better Binary Quantization 的文章。我来自阿拉巴马州,现在住在南卡罗来纳州,BBQ 在我的生活中已经占据了特殊的地位。现在,我有更多的理由爱上 BBQ!
我们将在 8.16 中将其作为技术预览版发布,或者现在以 serverless 器形式发布。要使用它,只需在 Elasticsearch 中将你的 density_vector.index_type 设置为 bbq_hnsw 或 bbq_flat。
准备好自己尝试一下了吗?开始免费试用。
Elasticsearch 和 Lucene 提供强大的矢量数据库和搜索功能。深入了解我们的示例笔记本以了解更多信息。
原文:Better Binary Quantization (BBQ) in Lucene and Elasticsearch - Search Labs