作者:来自 Elastic Sachin Frayne

探索 Elasticsearch 中的热点以及如何使用 AutoOps 解决它。
Elasticsearch 集群中出现热点的方式有很多种。有些我们可以控制,比如吵闹的邻居,有些我们控制得较差,比如 Elasticsearch 中的分片分配算法。好消息是,新的 desire_balance cluster.routing.allocation.type 算法(参见 shards-rebalancing-heuristics)在确定集群中的哪些节点应该获得新分片方面要好得多。如果存在不平衡,它会为我们找出最佳平衡。坏消息是,较旧的 Elasticsearch 集群仍在使用平衡(balanced)分配算法,该算法的计算能力较有限,在选择节点时容易出错,从而导致集群不平衡或出现热点。
在这篇博客中,我们将探讨这种旧算法,它应该如何工作以及何时不起作用,以及我们可以做些什么来解决这个问题。然后,我们将介绍新算法以及它如何解决这个问题,最后,我们将研究如何使用 AutoOps 来针对客户用例突出显示这个问题。然而,我们不会深入探讨热点的所有原因,也不会深入探讨所有具体的解决方案,因为它们太多了。
什么是 AutoOps?
平衡分配
在 Elasticsearch 8.5 及更早版本中,我们使用以下方法来确定在哪个节点放置分片,此方法主要归结为选择分片数量最少的节点:https://github.com/elastic/elasticsearch/blob/8.5/server/src/main/java/org/elasticsearch/cluster/routing/allocation/allocator/BalancedShardsAllocator.java#L242
float weight(Balancer balancer, ModelNode node, String index) {
final float weightShard = node.numShards() - balancer.avgShardsPerNode();
final float weightIndex = node.numShards(index) - balancer.avgShardsPerNode(index);
return theta0 * weightShard + theta1 * weightIndex;
}- node.numShards():分配给集群中特定节点的分片数量
- balancer.avgShardsPerNode():集群中所有节点的分片平均值
- node.numShards(index):分配给集群中特定节点的特定索引的分片数量
- balancer.avgShardsPerNode(index):集群中所有节点的特定索引的分片平均值
- theta0:(cluster.routing.allocation.balance.shard) 分片总数的权重因子,默认为 0.45f,增加该值会增加均衡每个节点分片数量的趋势(请参阅 Shard balancing heuristics settings)
- theta1:(cluster.routing.allocation.balance.index) 每个索引分片总数的权重因子,默认为 0.55f,增加该值会增加均衡每个索引分片数量的趋势每个节点(请参阅 Shard balancing heuristics settings)
该算法在整个集群中的目标值是以这样的方式选择一个节点,使得集群中所有节点的权重回到 0 或最接近 0。
示例
让我们探讨这样一种情况:我们有 2 个节点,其中 1 个索引由 3 个主分片组成,并且假设我们在节点 1 上有 1 个分片,在节点 2 上有 2 个分片。当我们向具有 1 个分片的集群添加新索引时会发生什么?
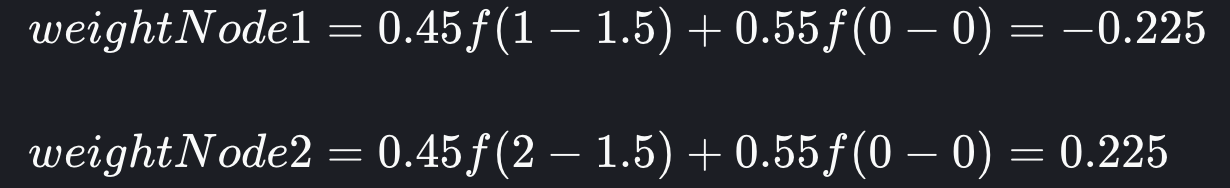
由于新索引在集群中的其他任何地方都没有分片,因此 weightIndex 项减少到 0,我们可以在下一个计算中看到,将分片添加到节点 1 将使余额回到 0,因此我们选择节点 1。
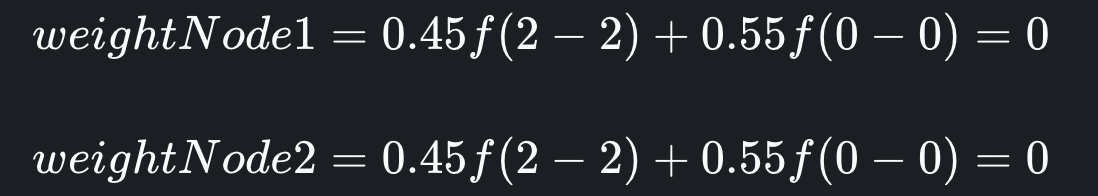
现在让我们添加另一个包含 2 个分片的索引,由于现在已达到平衡,因此第一个分片将随机分配到其中一个节点。假设节点 1 被选为第一个分片,则第二个分片将分配到节点 2。
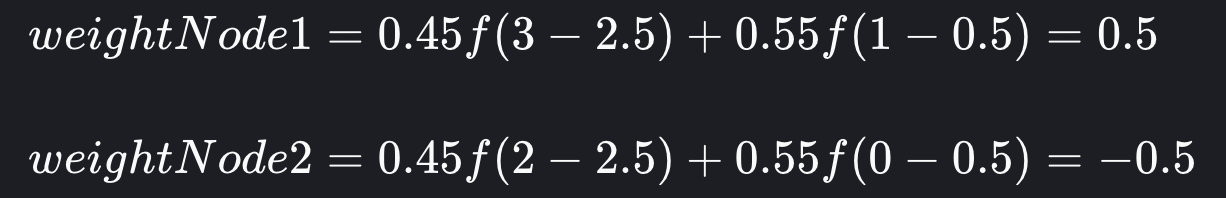
新的平衡最终将是:
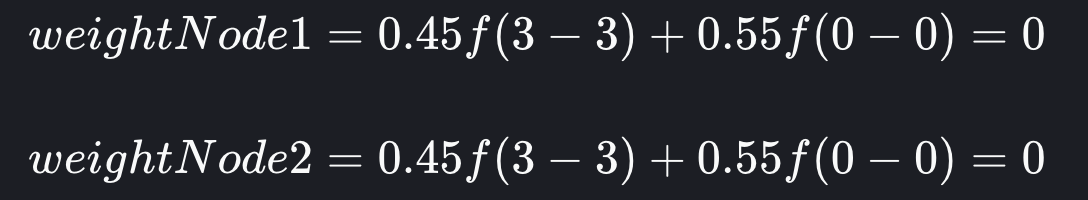
如果集群中的所有索引/分片在采集、搜索和存储要求方面都执行大致相同的工作量,则此算法将很好地发挥作用。实际上,大多数 Elasticsearch 用例并不这么简单,并且分片之间的负载并不总是相同的,请想象以下场景。
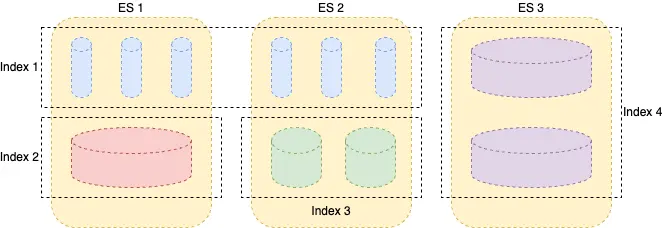
- 索引 1,小型搜索用例,包含几千个文档,分片数量不正确;
- 索引 2,索引非常大,但未被主动写入且偶尔搜索;
- 索引 3,轻量级索引和搜索;
- 索引 4,重度摄取应用程序日志。
假设我们有 3 个节点和 4 个索引,它们只有主分片,并且故意处于不平衡状态。为了直观地了解正在发生的事情,我根据分片的繁忙程度以及繁忙的含义(写入、读取、CPU、RAM 或存储)夸大了分片的大小。即使节点 3 已经拥有最繁忙的索引,新的分片也会路由到该节点。索引生命周期管理 (ILM) 不会为我们解决这种情况,当索引滚动时,新的分片将放置在节点 3 上。我们可以手动缓解这个问题,强制 Elasticsearch 使用集群重新(cluster reroute)路由均匀分布分片,但这无法扩展,因为我们的分布式系统应该处理这个问题。尽管如此,如果没有任何重新平衡或其他干预措施,这种情况将继续存在,并可能变得更糟。此外,虽然这个例子是假的,但这种分布在具有混合用例(即搜索、日志记录、安全)的旧 Elasticsearch 集群中是不可避免的,尤其是当一个或多个用例是重度摄取时,确定何时会发生这种情况并不是一件容易的事。
虽然预测这个问题的时间范围很复杂,但在某些情况下行之有效的一个好的解决方案是保持所有索引的分片密度相同,这是通过在所有索引的分片达到预定大小(以 GB 为单位)时滚动所有索引来实现的(请参阅分片大小 - size your shards)。这并不适用于所有用例,正如我们将在下面 AutoOps 捕获的集群中看到的那样。
所期望的平衡分配
为了解决这个问题和其他一些问题,一种可以同时考虑写入负载和磁盘使用情况的新算法最初在 8.6 中发布,并在 8.7 和 8.8 版本中进行了一些微小但有意义的更改:https://github.com/elastic/elasticsearch/blob/8.8/server/src/main/java/org/elasticsearch/cluster/routing/allocation/allocator/BalancedShardsAllocator.java#L305
float weight(Balancer balancer, ModelNode node, String index) {
final float weightShard = node.numShards() - balancer.avgShardsPerNode();
final float weightIndex = node.numShards(index) - balancer.avgShardsPerNode(index);
final float ingestLoad = (float) (node.writeLoad() - balancer.avgWriteLoadPerNode());
final float diskUsage = (float) (node.diskUsageInBytes() - balancer.avgDiskUsageInBytesPerNode());
return theta0 * weightShard + theta1 * weightIndex + theta2 * ingestLoad + theta3 * diskUsage;
}- node.writeLoad():特定节点的写入或索引负载
- balancer.avgWriteLoadPerNode():整个集群的平均写入负载
- node.diskUsageInBytes():特定节点的磁盘使用情况
- balancer.avgDiskUsageInBytesPerNode():整个集群的平均磁盘使用情况
- theta2:(cluster.routing.allocation.balance.write_load)写入负载的权重因子,默认为 10.0f,增加该值会增加均衡每个节点的写入负载的趋势(请参阅 Shard balancing heuristics settings)
- theta3:(cluster.routing.allocation.balance.disk_usage)磁盘使用情况的权重因子,默认为 2e-11f,增加该值会增加均衡每个节点的磁盘使用情况的趋势(请参阅 Shard balancing heuristics settings)
我不会在本博客中详细介绍此算法所做的计算,但是 Elasticsearch 用于决定分片应位于何处的数据可通过 API 获取:获取所需平衡(Get desired balance)。在调整分片大小时,遵循我们的指导仍然是最佳实践,并且仍然有充分的理由将用例分离到专用的 Elasticsearch 集群中。然而,此算法在平衡 Elasticsearch 方面要好得多,以至于它为我们的客户解决了以下平衡问题。(如果你遇到本博客中描述的问题,我建议你升级到 8.8)。
最后要注意的是,此算法没有考虑搜索负载,这很难衡量,甚至更难预测。6.1 中引入的自适应副本选择(Adaptive replica selection)对解决搜索负载大有帮助。在未来的博客中,我们将深入探讨搜索性能的主题,特别是如何使用 AutoOps 在搜索性能问题发生之前发现它们。
在 AutoOps 中检测热点
上述情况不仅难以预测,而且一旦发生也难以检测,我们需要对 Elasticsearch 有深入的内部了解,并且我们的集群需要满足非常具体的条件才能处于这种状态。
现在,使用 AutoOps 检测这个问题就轻而易举了。让我们看一个真实的例子;
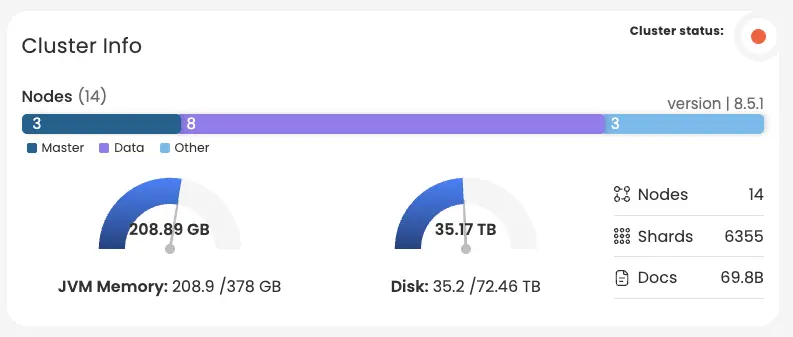
在这个设置中,Elasticsearch 前面有一个排队机制,用于处理数据峰值,但是用例是近实时日志 - 持续的滞后是不可接受的。我们遇到了持续滞后的情况,必须进行故障排除。从集群视图开始,我们获取了一些有用的信息,在下图中我们了解到有 3 个主节点、8 个数据节点(以及 3 个与案例无关的其他节点)。我们还了解到集群是红色的(这可能是网络或性能问题),版本是 8.5.1,有 6355 个分片;最后这两个将在以后变得重要。
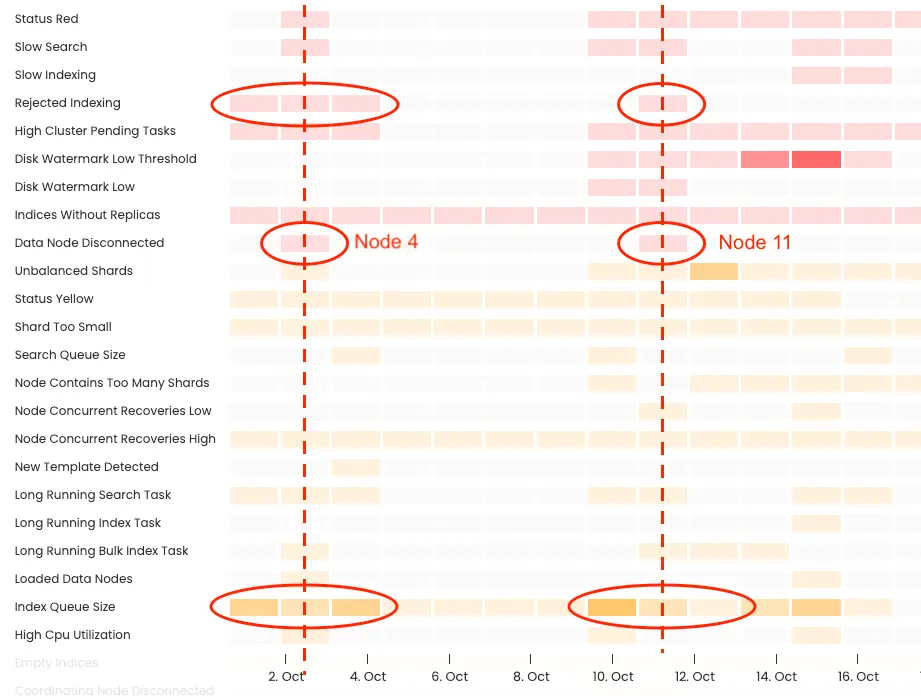
这个集群中发生了很多事情,它经常变成红色,这些都与离开集群的节点有关。节点离开集群的时间大约在我们观察到索引拒绝的时间,并且拒绝发生在索引队列过于频繁地填满后不久,黄色越深,时间块中的高索引事件越多。
转到节点视图并关注最后一个节点断开连接的时间范围,我们可以看到另一个节点(节点 9)的索引率比其他节点高得多,其次是节点 4,该节点在本月早些时候曾出现过一些断开连接的情况。你还会注意到,在同一时间范围内索引率下降幅度相当大,这实际上也与此特定集群中计算资源和存储之间的间歇性延迟有关。
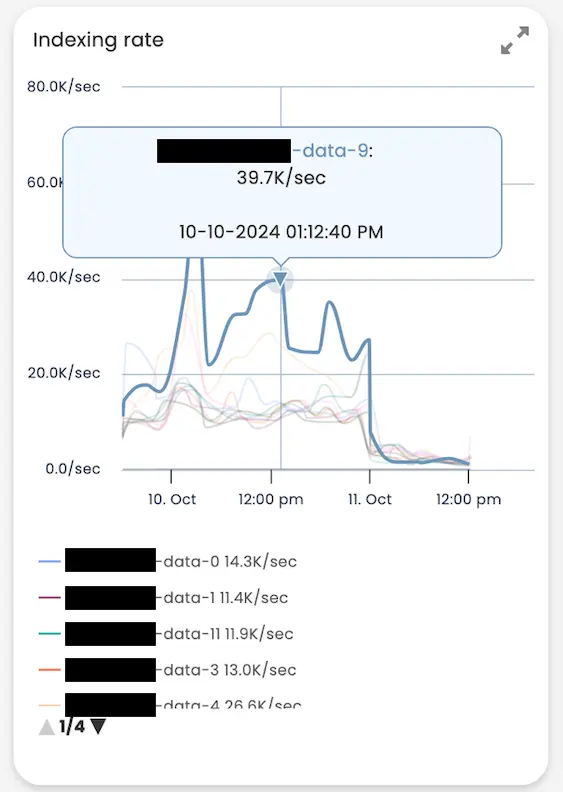
默认情况下,AutoOps 只会报告断开连接时间超过 300 秒的节点,但我们知道包括节点 9 在内的其他节点经常离开集群,如下图所示,节点上的分片数量增长太快,无法移动分片,因此在节点断开连接/重新启动后,它们必须重新初始化。有了这些信息,我们可以放心地得出结论,集群正在经历性能问题,但不仅仅是热点性能问题。由于 Elasticsearch 以集群的形式工作,它只能以最慢的节点的速度运行,而且由于节点 9 被要求比其他节点做更多的工作,它无法跟上,其他节点总是在等待它,偶尔也会断开连接。
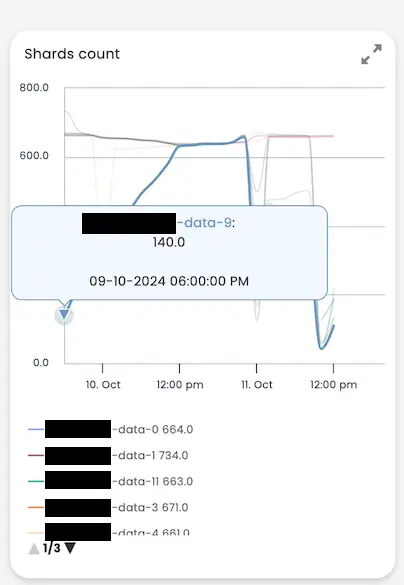
此时我们不需要更多信息,但为了进一步说明 AutoOps 的强大功能,下面是另一张图像,该图像显示了节点 9 比其他节点执行了多少工作,特别是它写入磁盘的数据量。
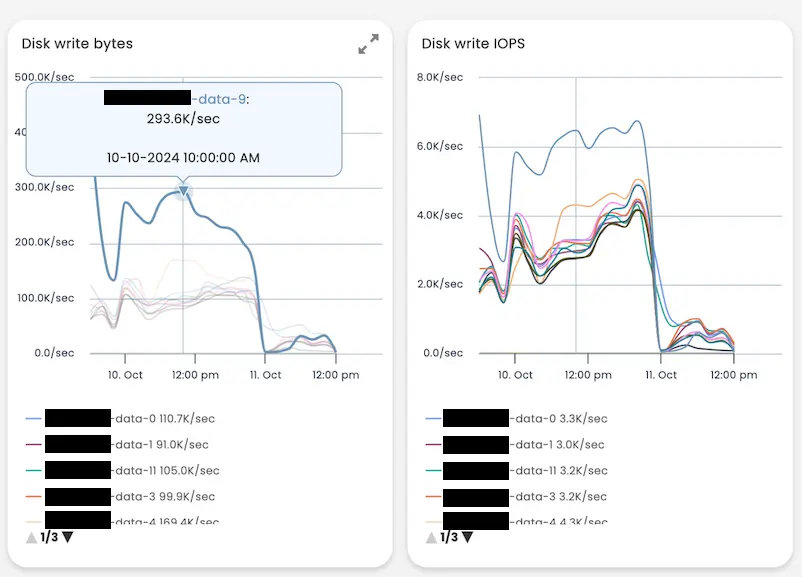
我们决定将所有分片从节点 9 移出,方法是将它们随机发送到集群中的其他节点;这是通过以下命令实现的。此后,整个集群的索引性能得到改善,延迟消失。
PUT /_cluster/settings
{
"transient": {
"cluster.routing.allocation.exclude._name": "****-data-9"
}
}现在我们已经观察、确认并解决了该问题,我们需要找到一个长期的解决方案,这又让我们回到了博客开头的技术分析。我们遵循最佳实践,分片以预定的大小滚动,甚至限制每个节点特定索引的分片数量。我们遇到了算法无法处理的边缘情况,即索引繁重且频繁滚动的索引。
我们考虑过是否可以手动重新平衡集群,但对于由 6355 个分片组成的约 2000 个索引,这并非易事,更不用说,在这种级别的索引下,我们将与 ILM 竞争重新平衡。这正是新算法的设计目的,因此我们的最终建议是升级集群。
最后的想法
本博客总结了一组相当具体但复杂的情况,这些情况可能会导致 Elasticsearch 性能出现问题。你今天甚至可能会在集群中看到其中一些问题,但可能永远不会像这个用户那样严重地影响集群。这个案例强调了跟上 Elasticsearch 最新版本的重要性,以便始终利用最新的创新来更好地管理数据,它有助于展示 AutoOps 在发现/诊断问题并提醒我们注意问题方面的强大功能,以免它们成为全面生产事件。
考虑迁移到至少 8.8 版 https://www.elastic.co/guide/en/elasticsearch/reference/8.8/migrating-8.8.html
Elasticsearch 包含许多新功能,可帮助你为你的用例构建最佳搜索解决方案。深入了解我们的示例笔记本以了解更多信息,开始免费云试用,或立即在你的本地机器上试用 Elastic。
原文:Hotspots in Elasticsearch and how to resolve them with AutoOps - Search Labs