作者:来自 Elastic Annie Hansen, Stef Nestor

在本博客中,我们将介绍如何通过 Elasticsearch 的快照将我们已提交的集群数据备份到 AWS S3 存储桶中。在 Elastic Cloud(企业版)中,Elastic 在其 found-snapshots 存储库下提供内置备份服务。Elasticsearch 还支持云(Cloud)和本地设置的自定义存储库,连接到所有平台类型的数据存储(如 AWS S3、GCP 和 Azure)以及本地文件系统。这些内置和自定义快照存储库为数据备份提供了很好的选择;自定义存储库用于长期存储和开关备份;找到快照用于持续的、最近的备份。用户经常将这两种方法集成到他们的生产集群中。
连接自定义 AWS S3 快照存储库 Elastic Cloud 支持故障排除
创建 AWS S3 存储桶
首先,我们将按照 AWS 指南设置一个 AWS S3 存储桶来存储我们的数据。
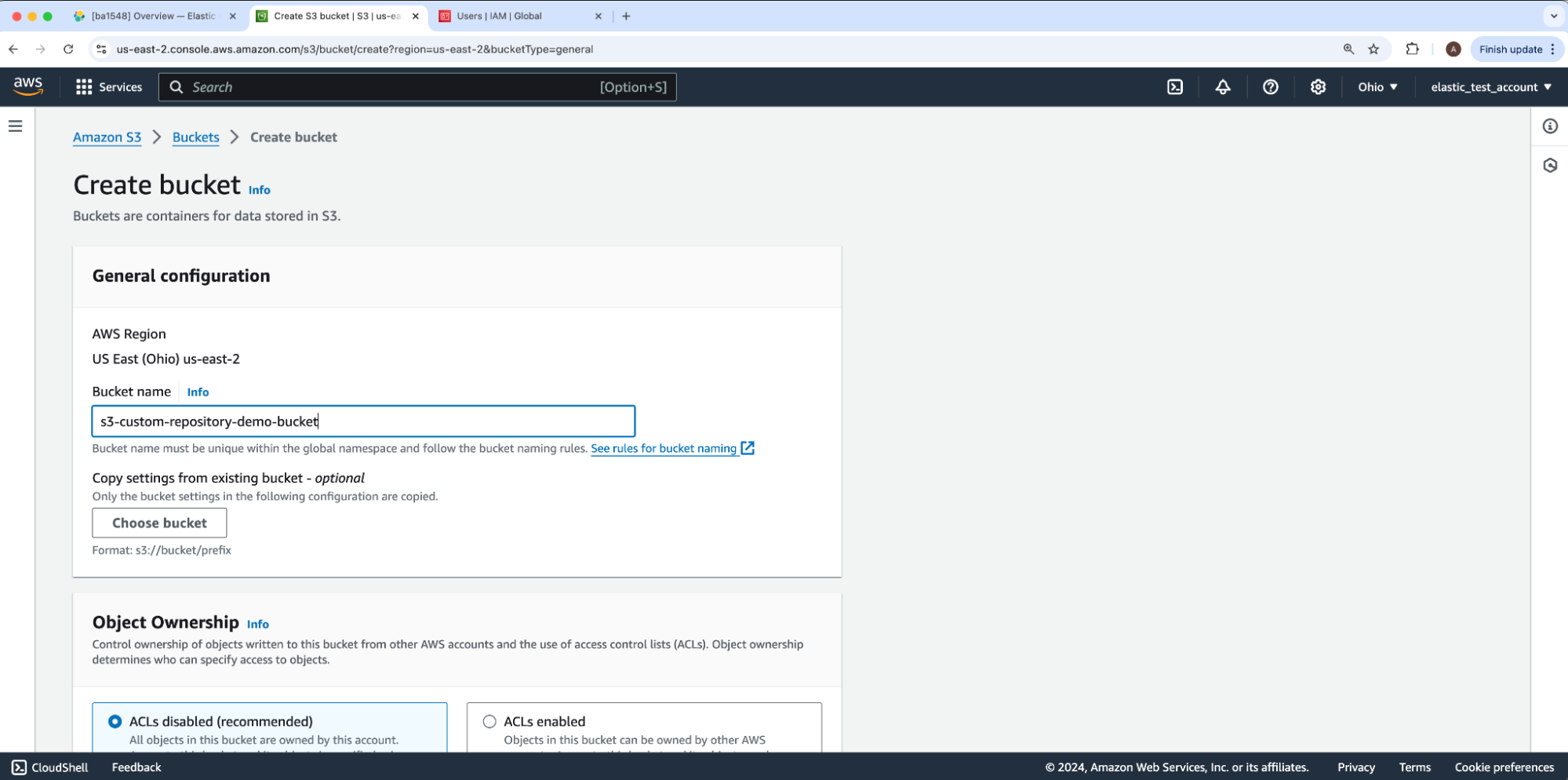
在 Create bucket 下,填写 Bucket name,其他选项保留默认设置。然后,单击 Next 创建此存储桶来保存我们的数据。在我们的示例中,存储桶名称将是 s3-custom-repository-bucket-demo。
设置 AWS IAM 策略
接下来,我们将通过创建 AWS IAM 策略(creating an AWS IAM policy)来设置对新创建的存储桶的访问授权。
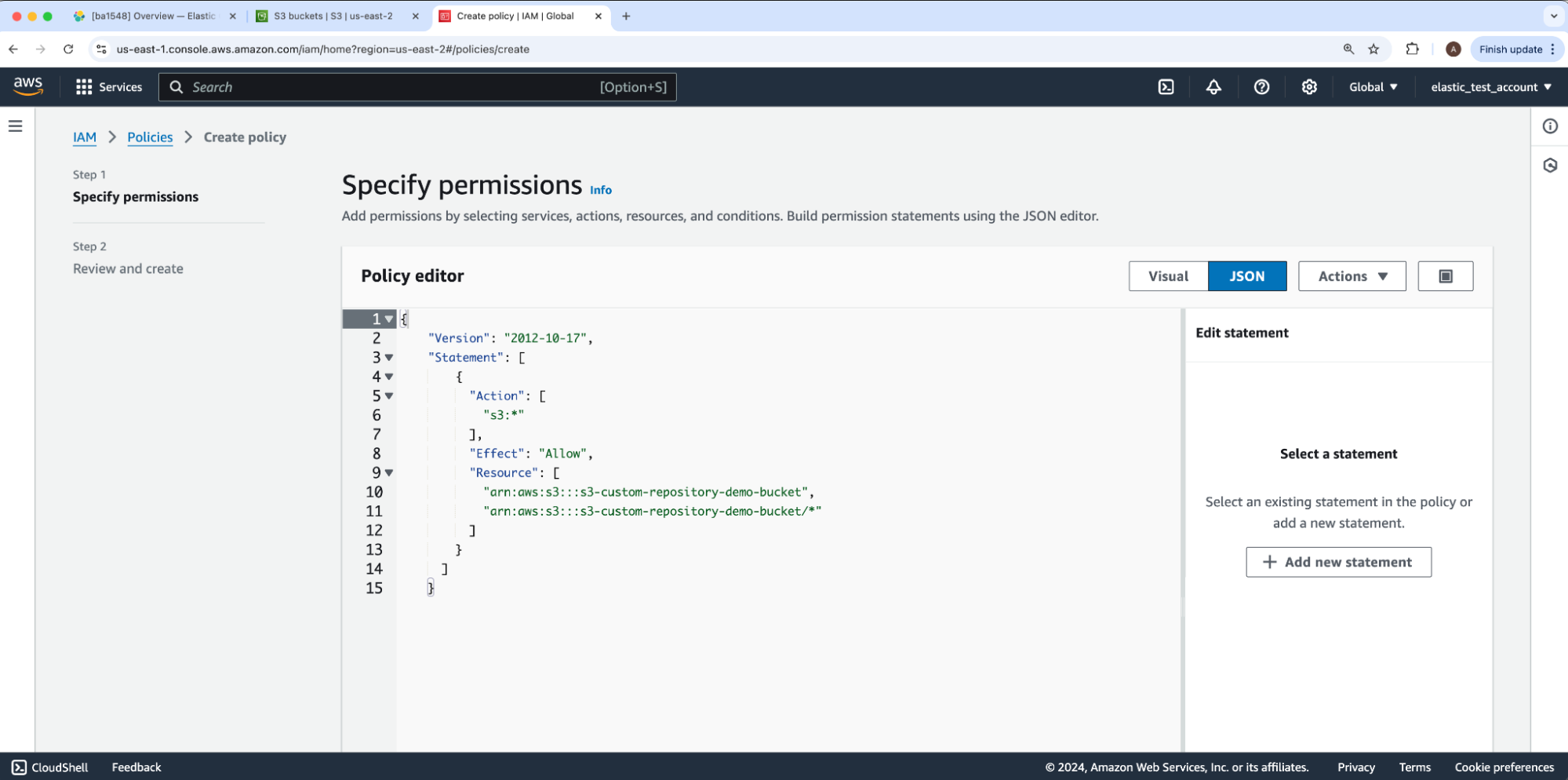
在 Create policy 的第一步(称为 Specify permissions)下,我们将 Elastic Cloud 推荐的 S3 权限复制到 JSON “Policy editor” 中 — 仅保留 AWS 最初为其 “Version” JSON 键设置的值。你可能更喜欢 Elasticsearch 文档中概述的进一步权限限制。我们将用我们的存储桶名称 s3-custom-repository-bucket-demo 替换指南中 Resource 下的 JSON 占位符 bucket-name 。然后,我们将选择 Next 继续执行步骤 2:Review and create。
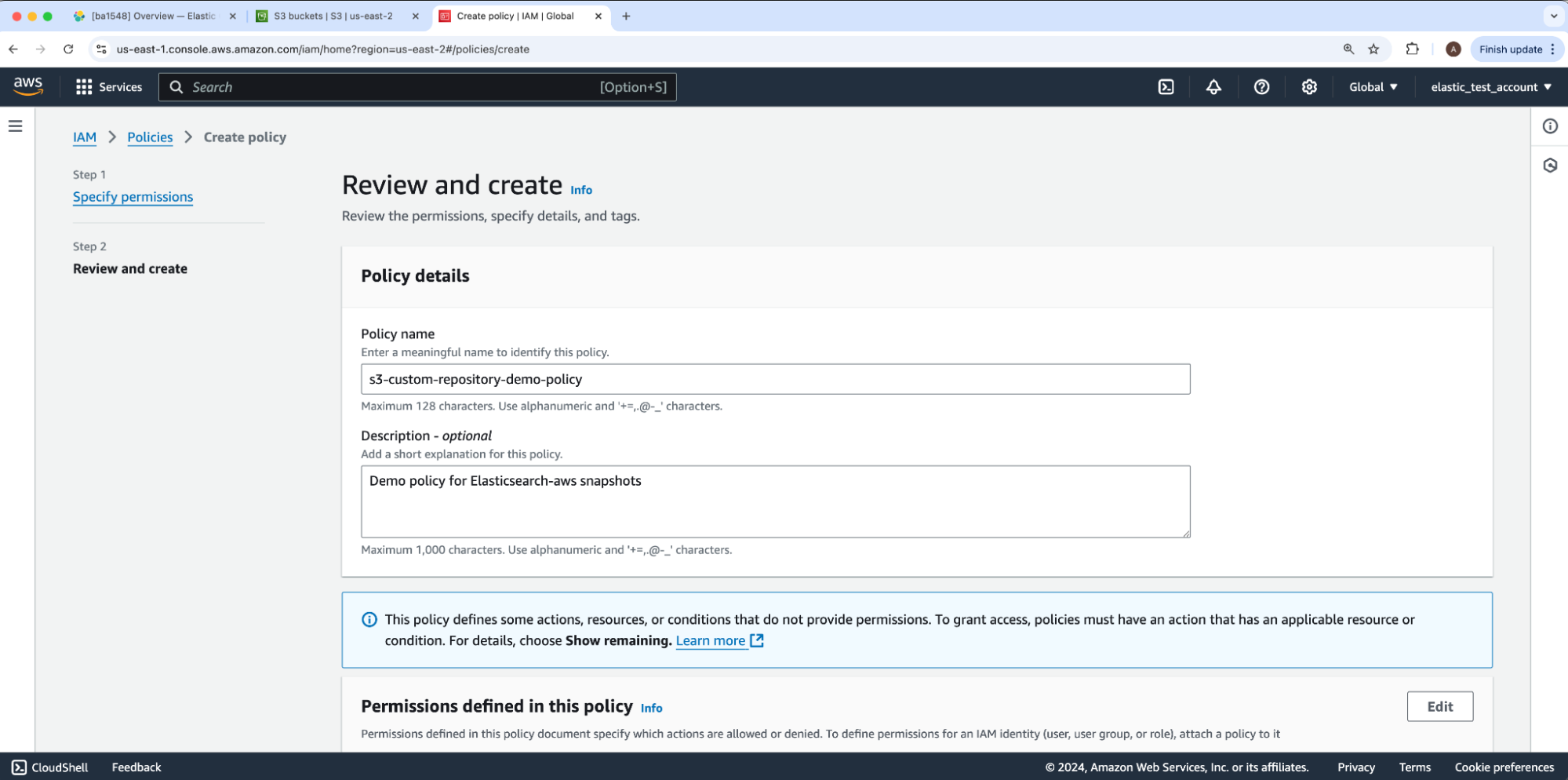
我们将输入 Policy name 和 Description,然后选择 Next。对于我们的示例,策略名称将是 s3-custom-repository-demo-policy。
创建 IAM 用户
接下来,我们将创建一个 AWS IAM 用户(create an AWS IAM user),并通过我们新创建的 IAM 策略授予其授权。在 Create user 流程下,我们将从步骤 1 开始:Specify user details。我们将输入s3-custom-repository-demo-user 作为 user name,将页面上的所有其他选项保留为默认值,然后选择 Next 继续执行步骤 2:Set permission。
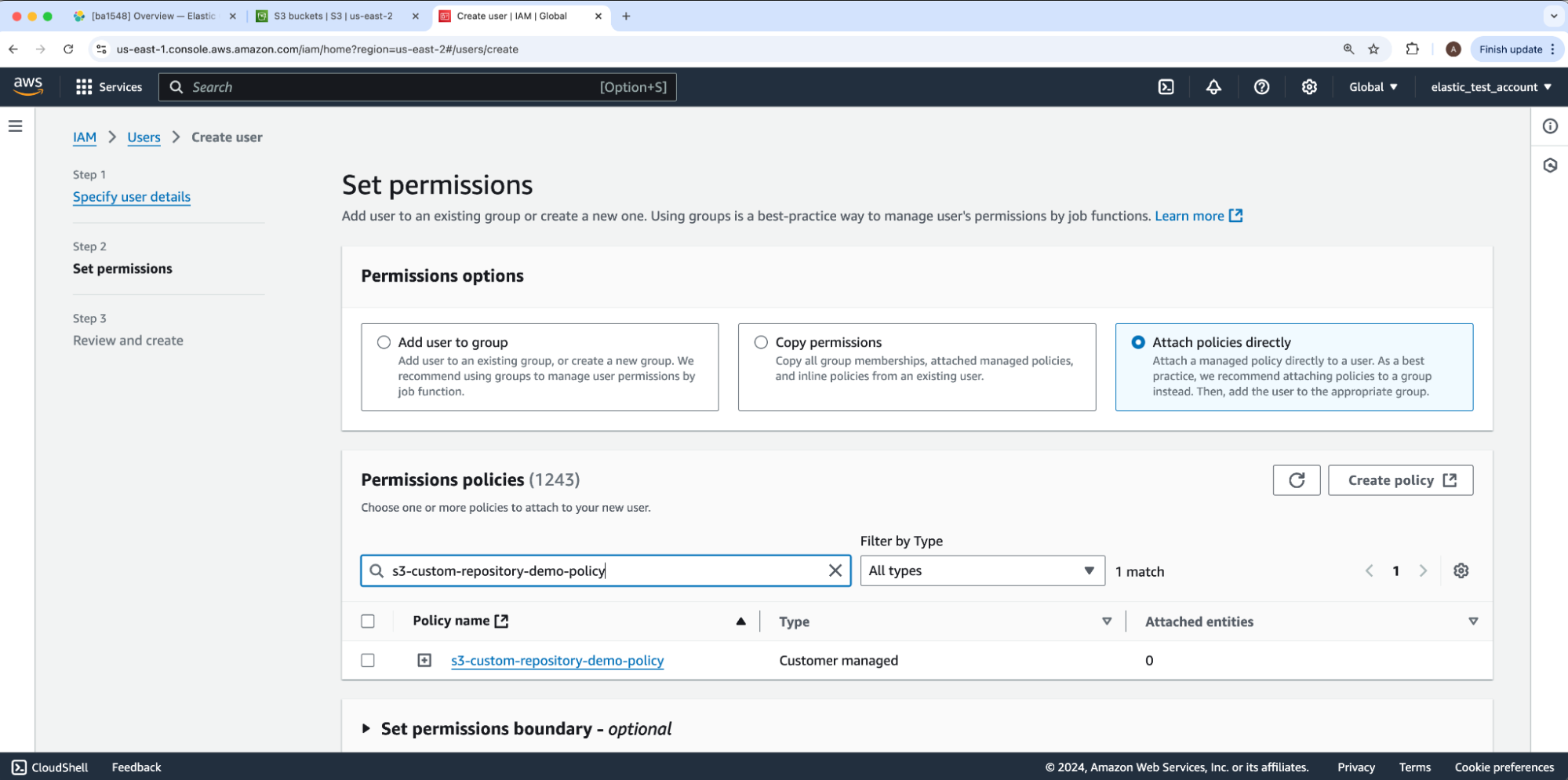
在这里,我们将通过选择 “ Permissions Options” 值及 Attach polices directly 来为用户附加 IAM 策略。接着,在 “Permissions policies” 下,我们将搜索并启用我们的 IAM 策略。完成后,保留其他选项为默认设置,然后单击 “Next” 进入第 3 步:“Review and create”,最后滚动并点击 “Create user”。
设置 IAM 用户访问密钥
Elasticsearch 通过 IAM 用户的 access and secret key(而不是用户名和密码)连接到 AWS S3。为了将存储桶连接到我们的 Elasticsearch 集群,我们将创建一个访问密钥和密钥,以便稍后存储在部署的 Elasticsearch 密钥库中。在我们的 IAM 用户下,我们将选择 Create access key。
这将引导我们进入步骤 1:Access key best practices & alternatives 下的 Create access key 流程。
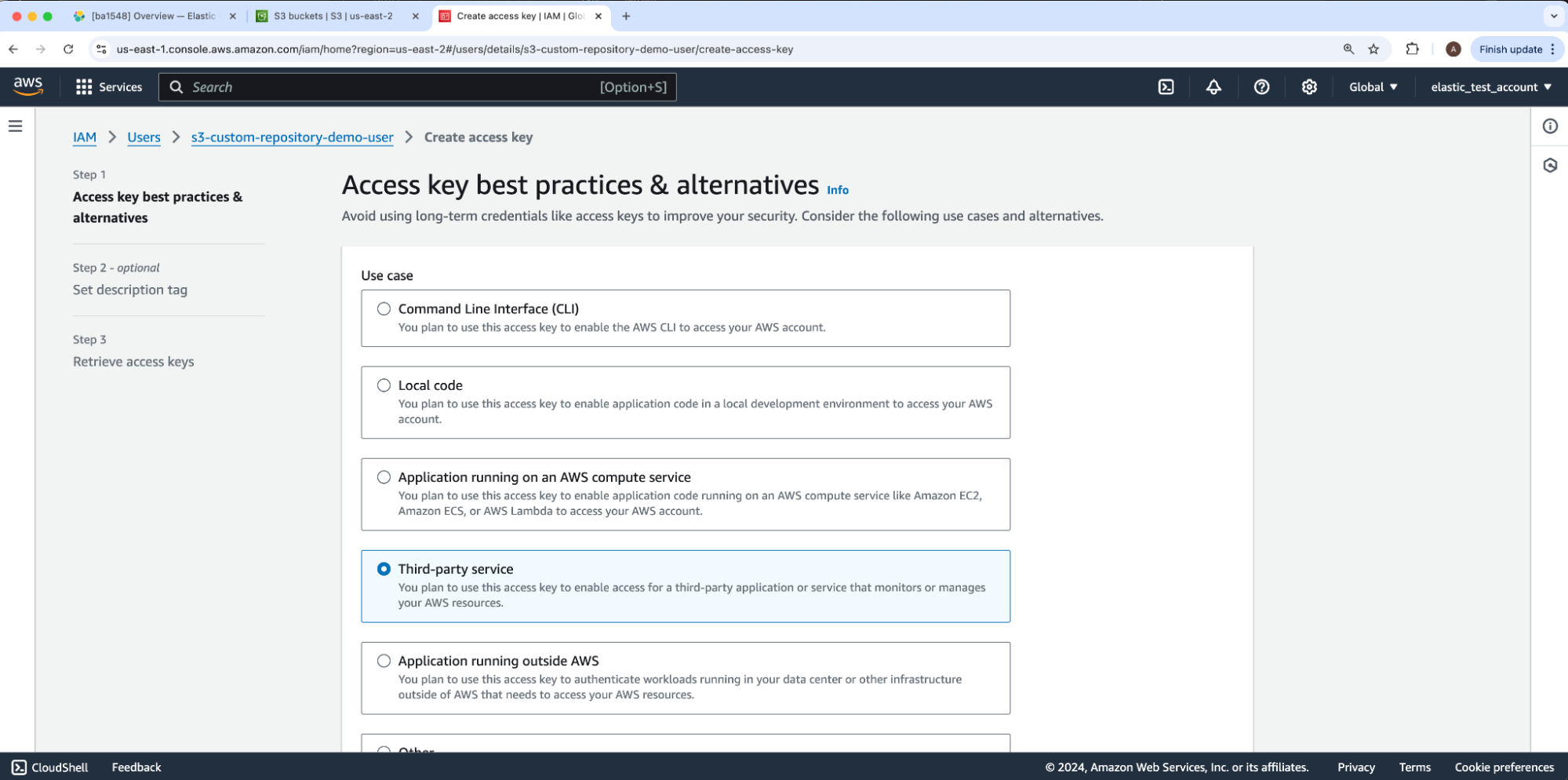
对于 Use case,我们将选择 Third-party service,然后单击 Next。这将带我们进入第 2 步 - 可选:optional: Set description tag,我们将通过再次单击 Next 跳过该步骤,进入第 3 步:Step 3: Retrieve access keys。
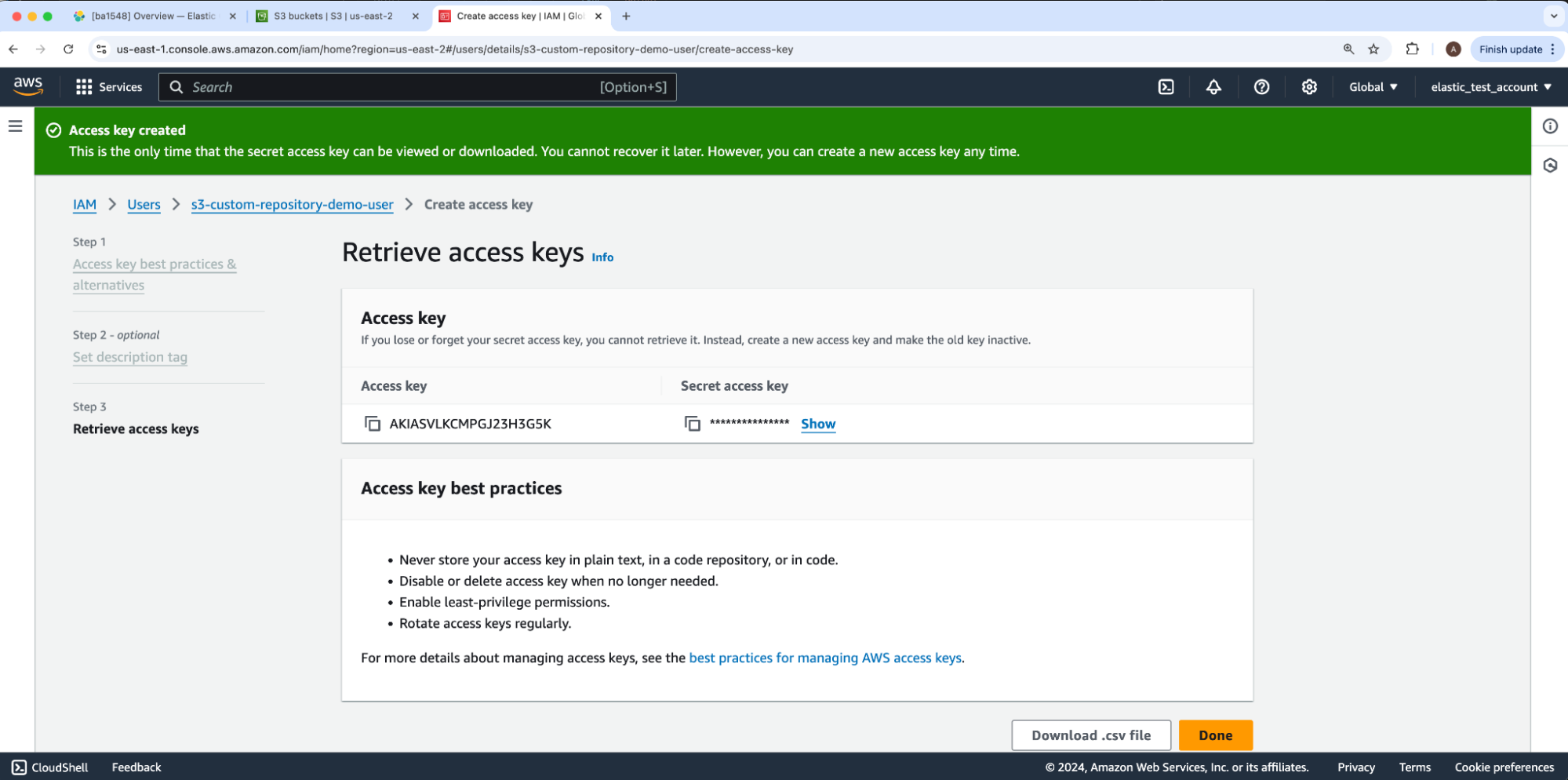
我们将安全地存储我们的 IAM 用户的新访问和密钥。
连接到部署
我们将把这些 IAM 用户访问权限和密钥添加到我们的 Elastic Cloud 部署中。
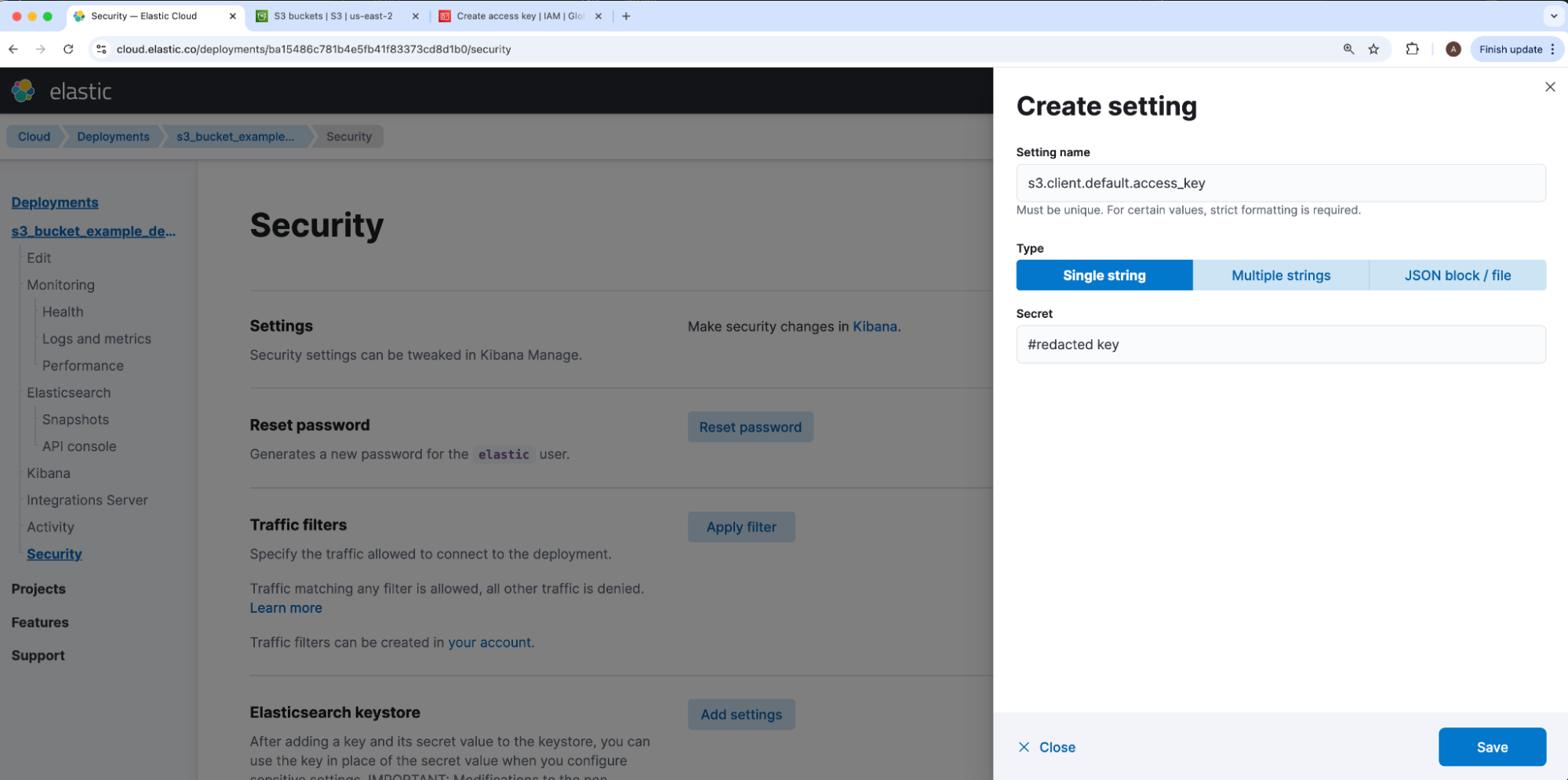
在我们部署的 security tab 下,我们将导航到 elasticsearch-keystore 并单击 Add settings。如果单独的 S3 存储库连接有多个访问和密钥对,Elasticsearch S3 存储库 JSON将通过 client 字符串映射我们的访问和密钥。我们的 IAM 用户的访问密钥将是 s3.client.CLIENT_NAME.access_key 的值,而密钥将是 s3.client.CLIENT_NAME.secret_key 的值,其中 CLIENT_NAME 是该 S3 JSON 映射的 client 值的占位符。由于 client 默认为 default,我们将在示例中使用相同的值,因此我们在 Setting name 下插入的访问和密钥值将分别存储在密钥 s3.client.default.access_key 和 s3.client.default.secret_key 下。
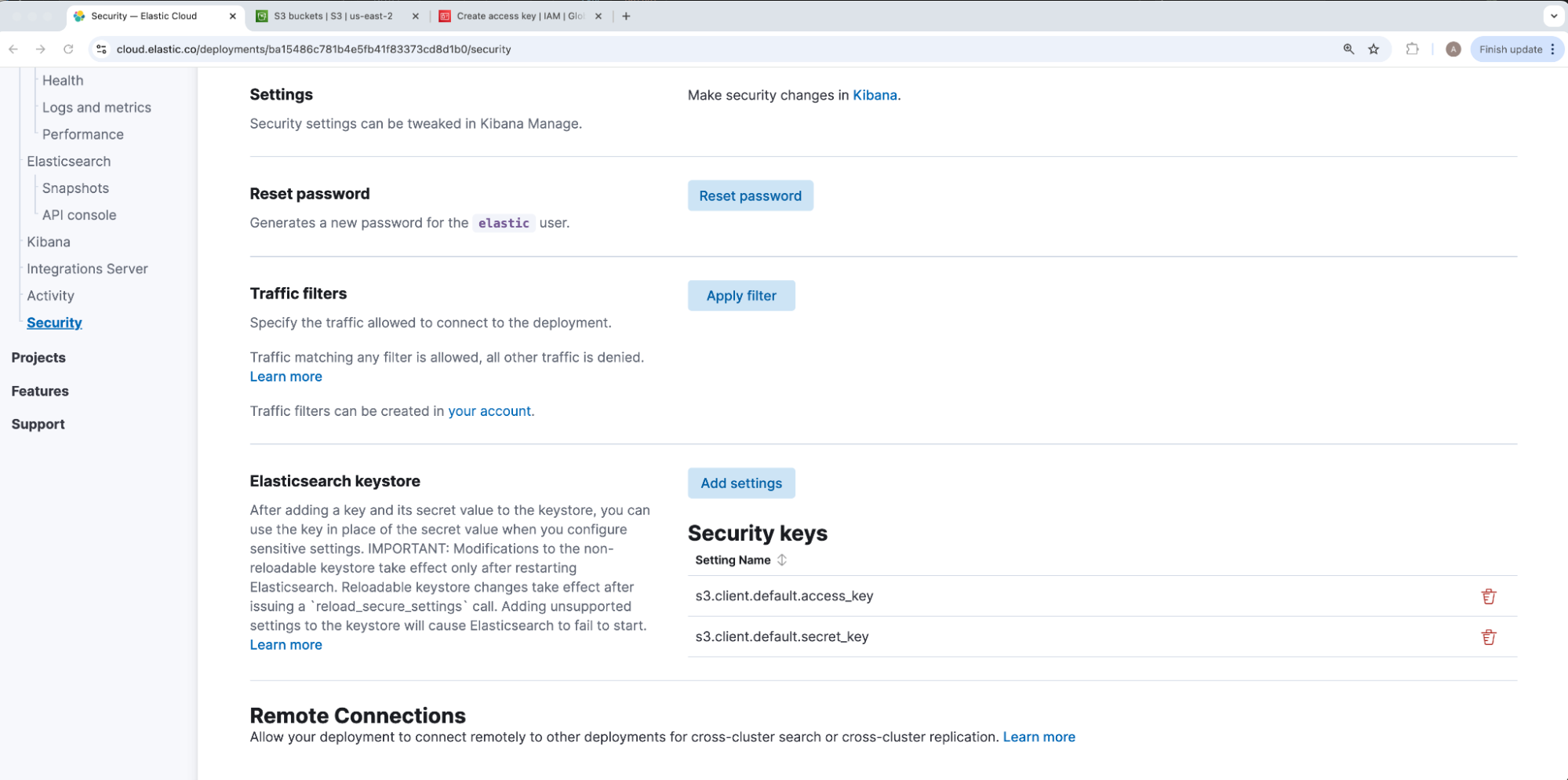
添加后,我们的密钥将显示在 “Security keys”下。出于安全考虑,添加后无法查看或编辑我们的密钥库值 — 只能删除以重新创建。
创建存储库连接
我们现在将通过 Kibana 注册我们的 AWS S3 Elasticsearch 存储库。我们将通过在 Dev Tools 下运行 node reload secure settings 将安全设置加载到集群中。
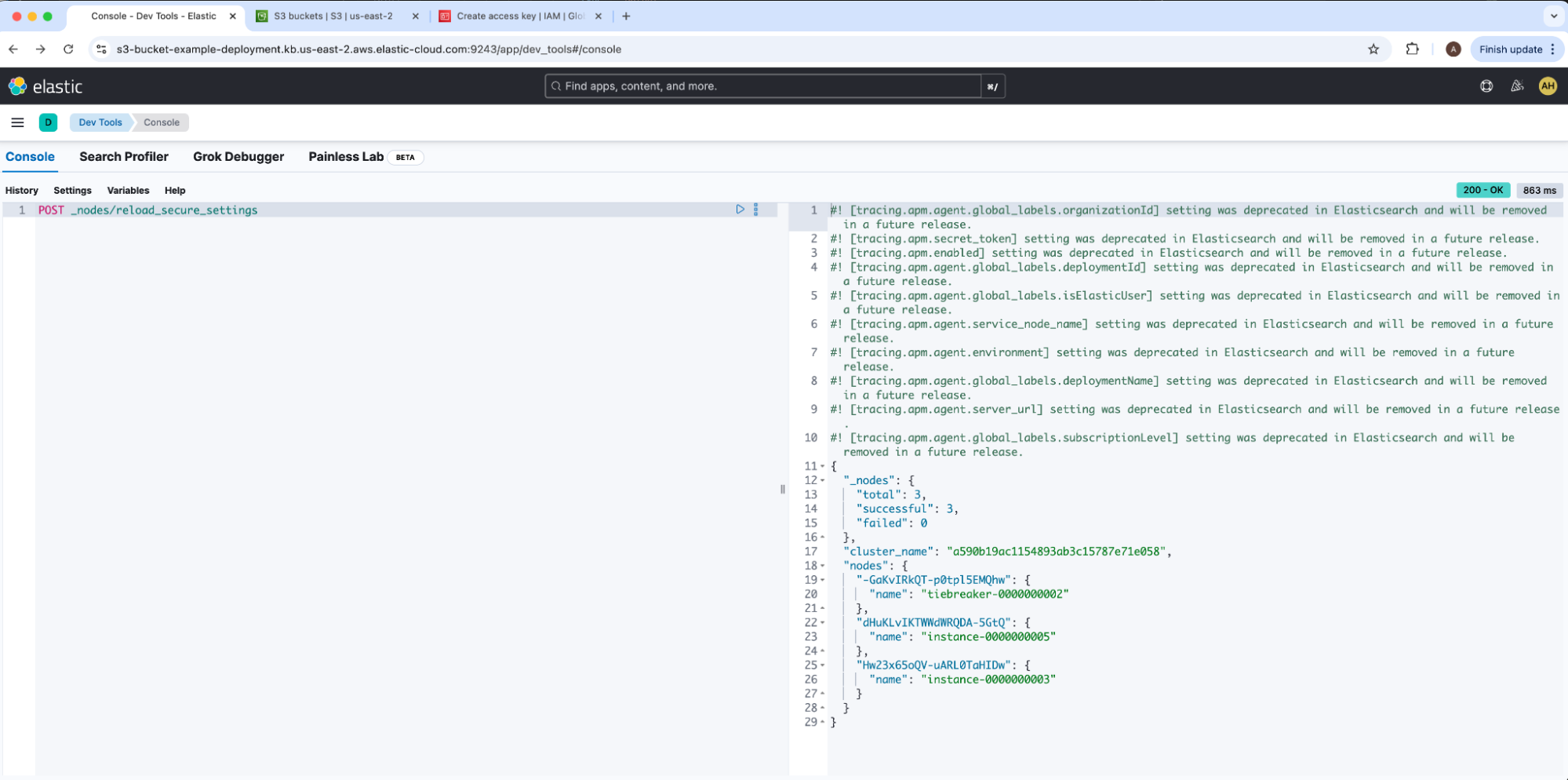
成功响应将发出 _nodes.failed: 0。我们的访问和密钥库对现已添加到 Elasticsearch 中,因此我们现在可以注册我们的 AWS S3 存储库。然后,我们将导航到 “Stack Management ” 下的 “Snapshot and Restore”,单击 “Repositories” 选项卡,然后选择 “Register a Repository”。
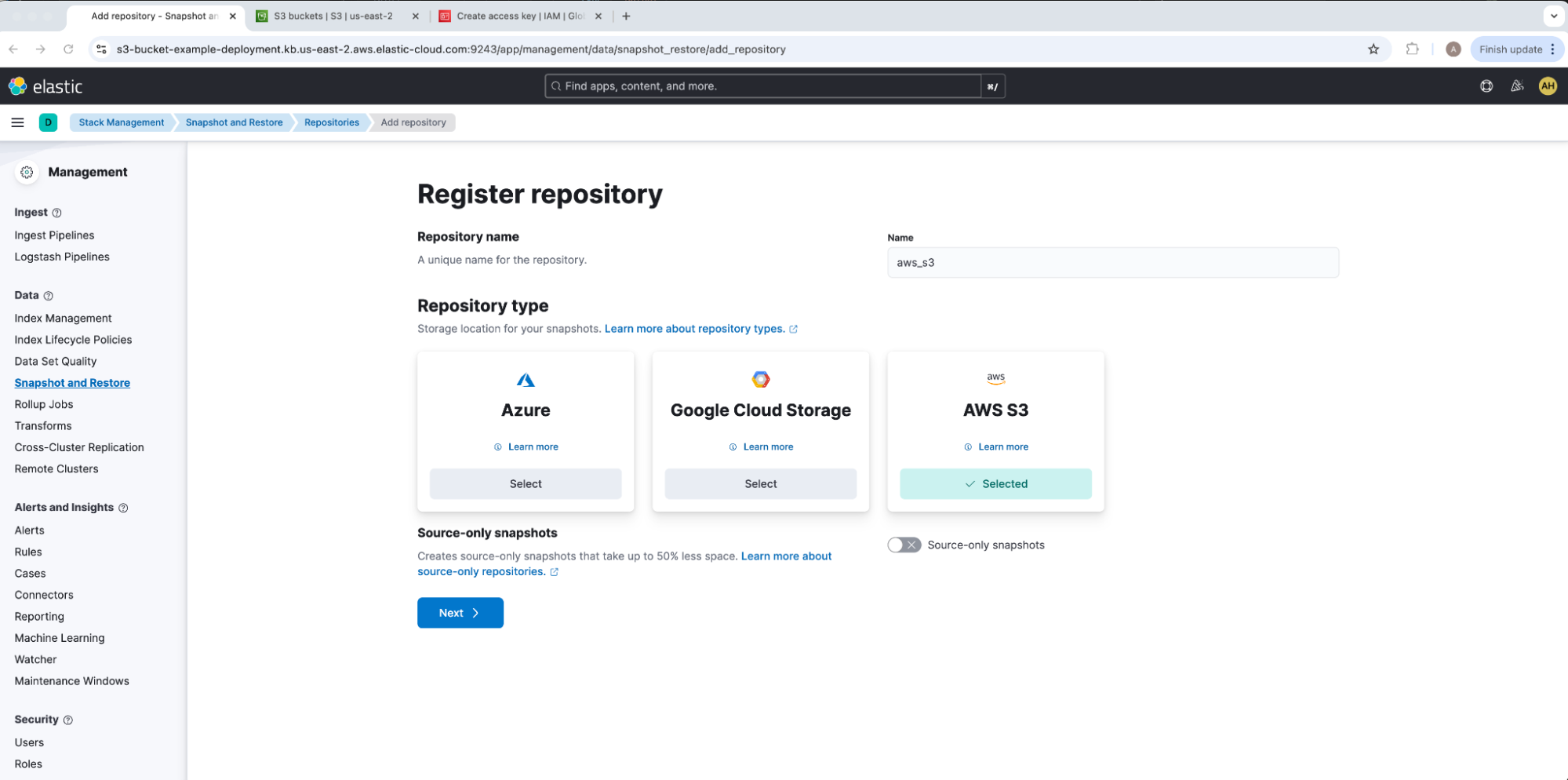
我们将为存储库定义 Name,并选择 AWS S33 作为 Repository Type。在我们的示例中,我们的存储库名称为 aws_s3。请注意,虽然大多数 Elasticsearch 功能(如分配)在最初注册后根据其存储的 uuid 从存储库加载数据,但 ILM 可搜索快照(ILM searchable snapshots)确实使用存储库 name 作为标识符。在迁移可搜索快照(searchable snapshot)数据时,需要在 Elasticsearch 集群之间进行对齐。
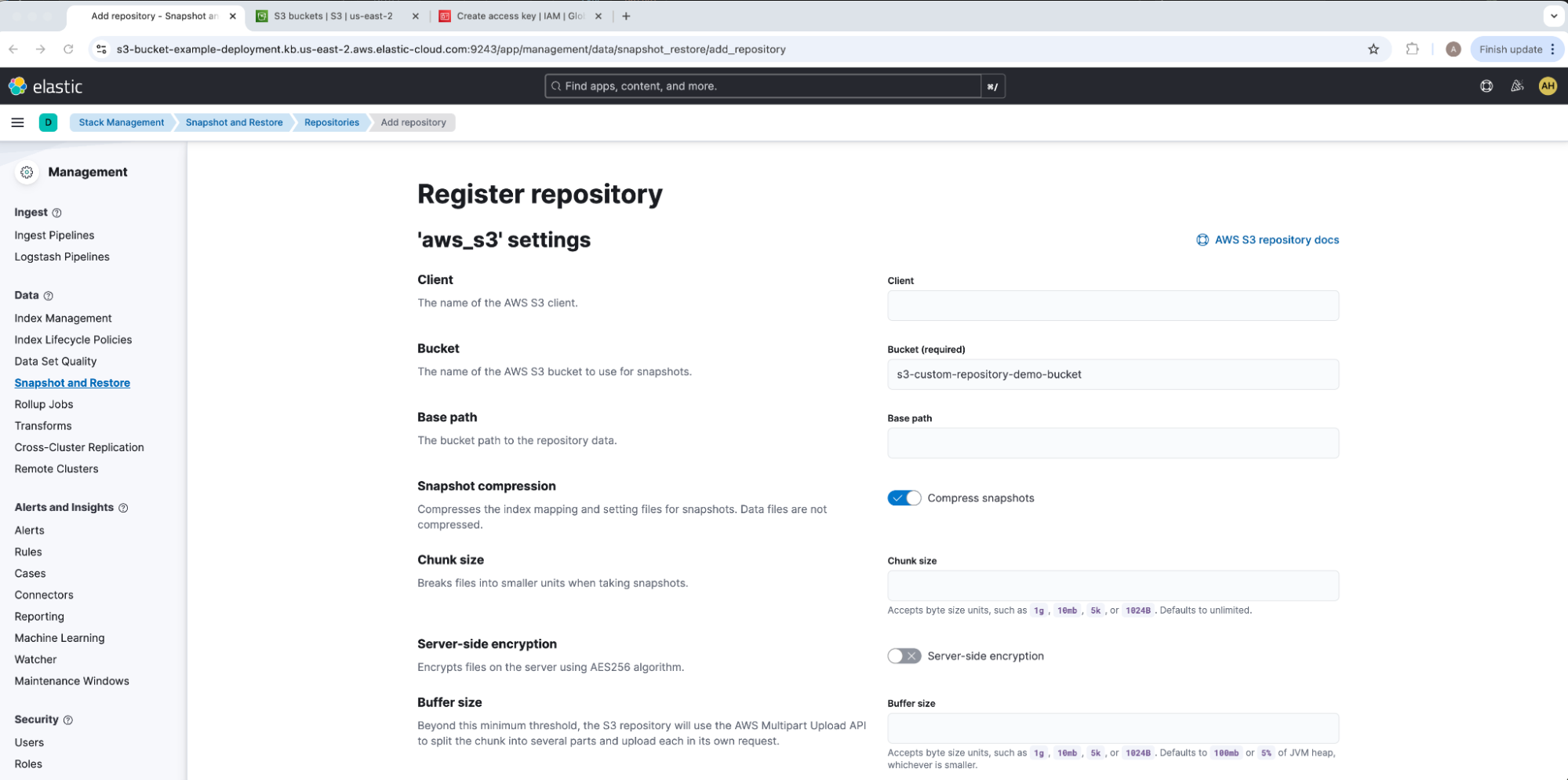
在 Register repository 下,添加我们的 Bucket 名称 s3-custom-repository-demo-bucket,保留所有其他选项的默认值,然后选择 Save。在我们的示例中,我们将 Client 留空,以便默认为 default 以匹配我们的 Elasticsearch 密钥库 CLIENT_NAME。请注意,一个 Elasticsearch 集群中一次只能有一个读写连接对存储库起作用;根据需要,请确保标记为 readonly,以避免意外覆盖或损坏数据。这将带我们进入 aws_s3 存储库概览 UI 抽屉。
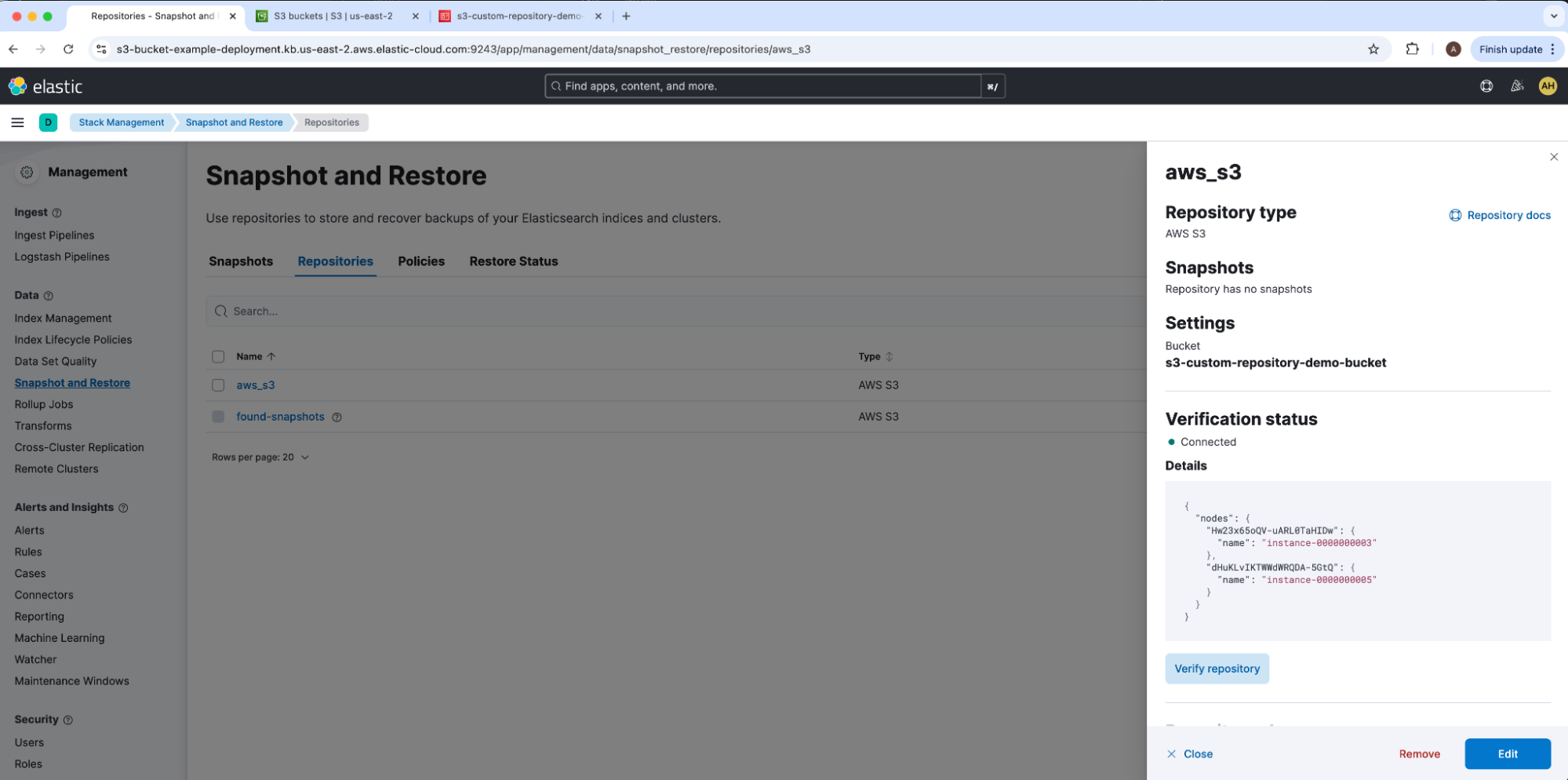
在这里,我们可以选择 Verification status 下的 Verify repository,以确认所有节点都可以连接到我们的 AWS S3 存储桶并通过初始验证检查。我们还可以使用验证快照存储库从 Dev Tools 运行相同的测试。
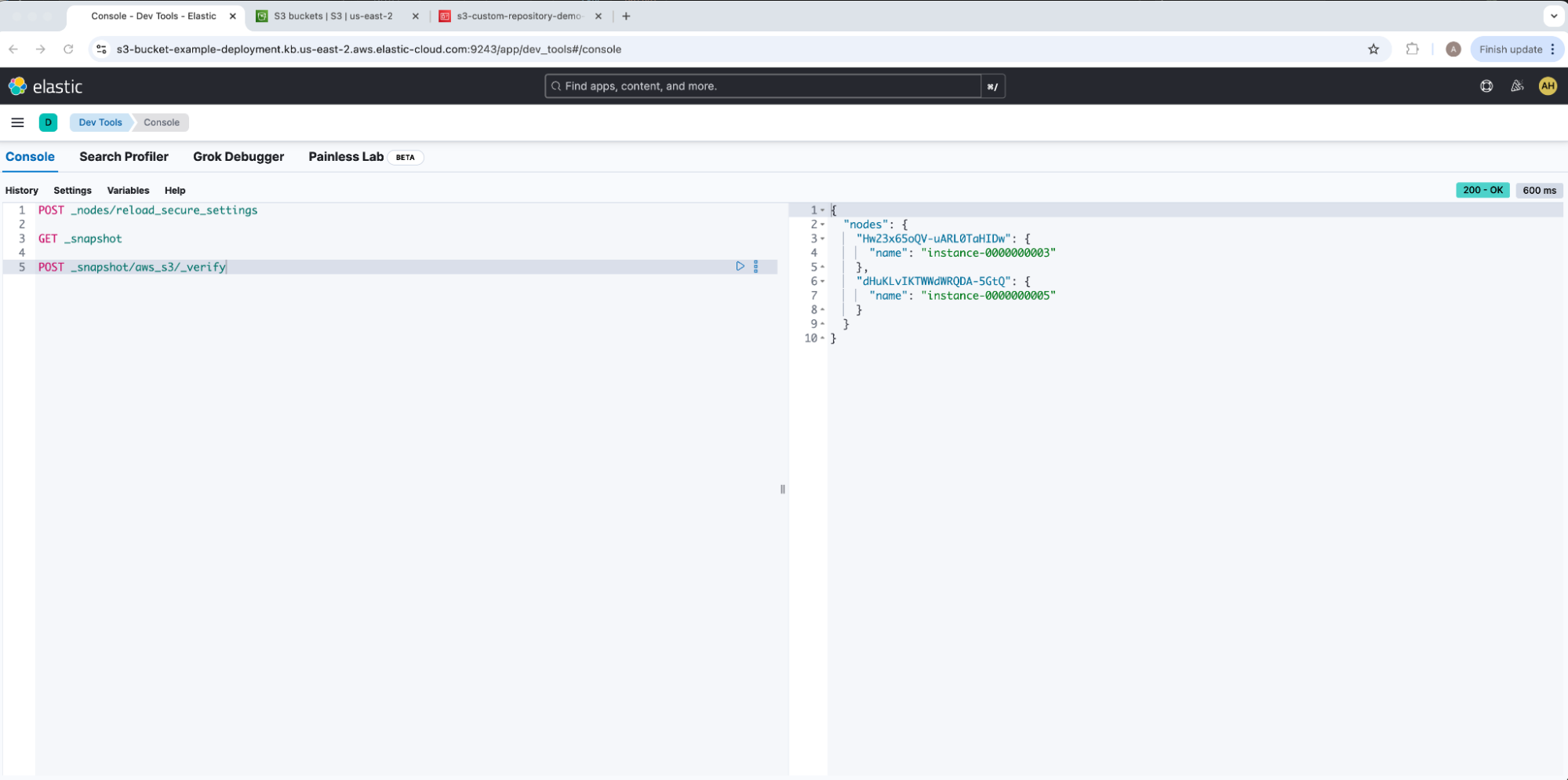
这两个输出都返回成功连接到我们的 AWS S3 存储桶的相同节点列表。
捕获快照
我们现在准备将已提交的 Elasticsearch 集群的快照备份到 AWS S3 存储桶中。请注意,Elastic Cloud 的内置存储库 found-snapshots 也通过 Elasticsearch 的快照生命周期管理 (SLM) 定期执行备份。接下来,我们将运行 create snapshot 命令以创建快照。
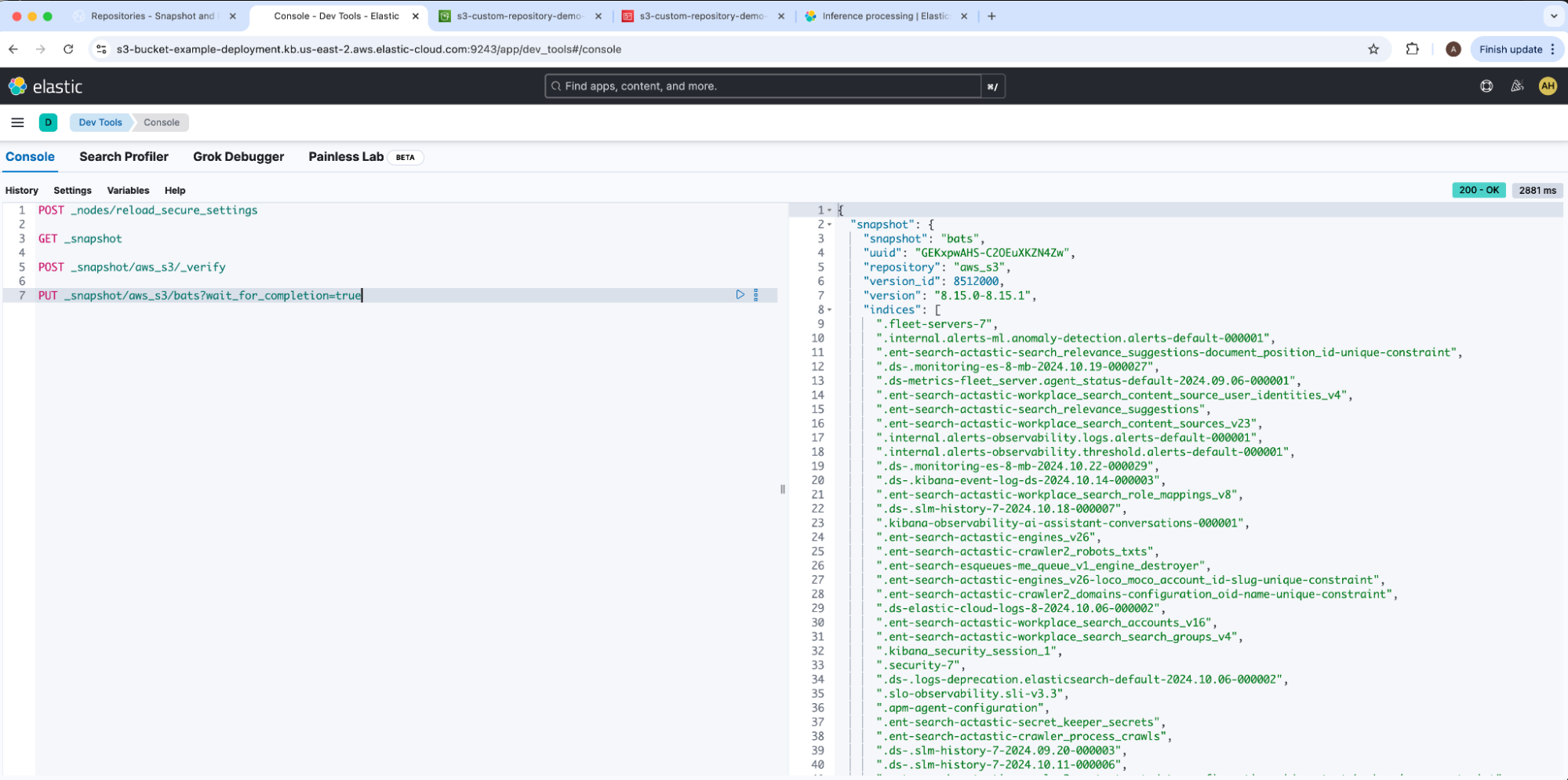
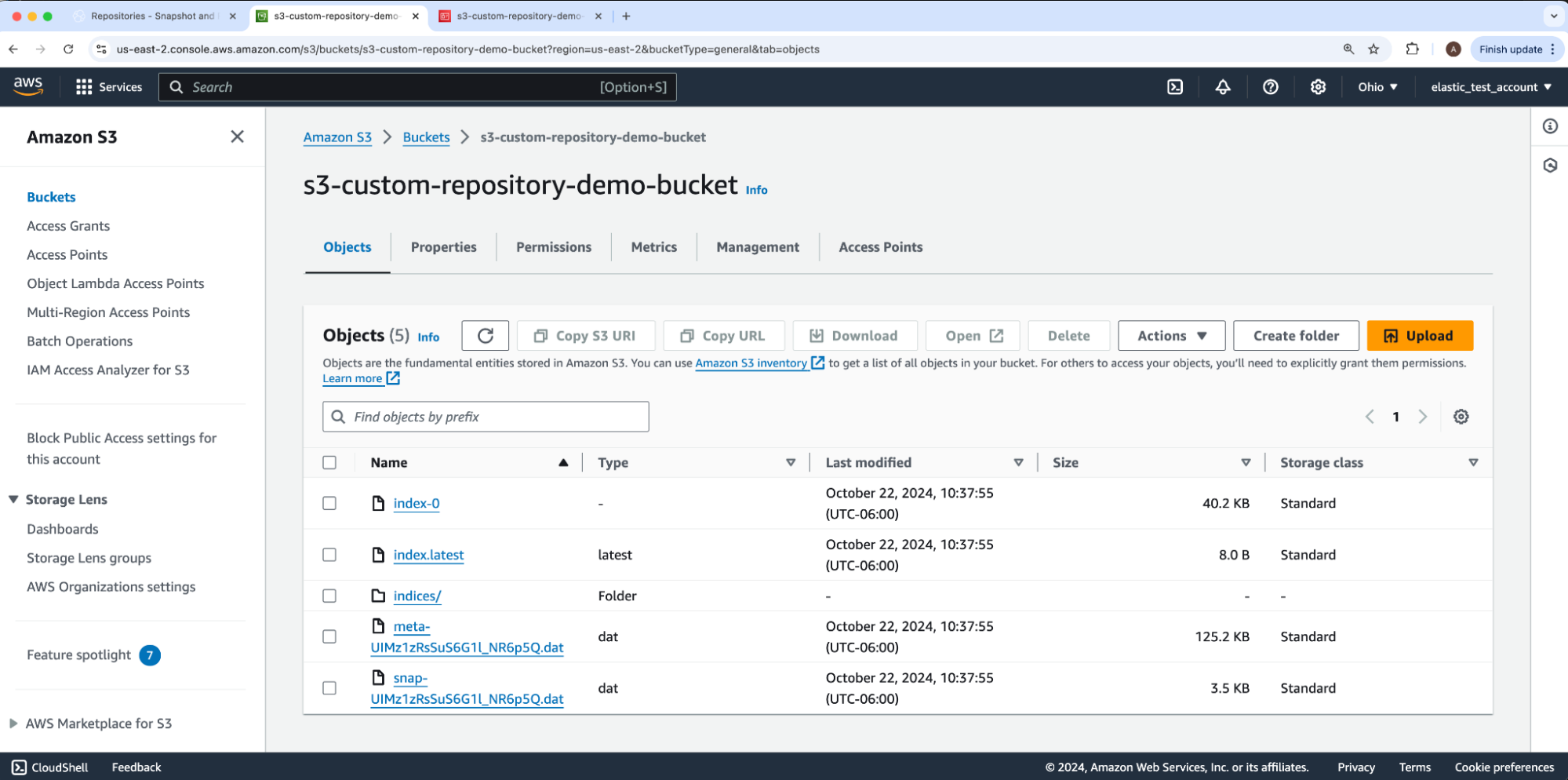
我们的示例快照名称是 bats。生成的快照报告 state: SUCCESS。我们可以通过导航回我们的 AWS S3 存储桶 s3-custom-repository-demo-bucket 来确认结果,它显示 Elasticsearch 已将文件和子文件夹添加到我们的根目录中。
我们做到了!观看此视频,了解上述步骤。
此时,我们可以根据需要设置快照生命周期管理,以拍摄周期快照并管理快照保留。或者,我们可以断开 AWS S3 存储库的连接,将其连接到不同的 Elasticsearch 集群,以迁移此新快照数据。
本文中描述的任何特性或功能的发布和时间均由 Elastic 自行决定。任何当前不可用的特性或功能可能无法按时交付或根本无法交付。
原文:https://www.elastic.co/blog/custom-aws-s3-snapshot-repository-elastic-cloud