作者:来自 Elastic Gustavo Llermaly

将 Jira 连接到 Elasticsearch 后,我们现在将回顾最佳实践以升级此部署。
在本系列的第一部分中,我们配置了 Jira 连接器并将对象索引到 Elasticsearch 中。在第二部分中,我们将回顾一些最佳实践和高级配置以升级连接器。这些实践是对当前文档的补充,将在索引阶段使用。
运行连接器只是第一步。当你想要索引大量数据时,每个细节都很重要,当你从 Jira 索引文档时,你可以使用许多优化点。
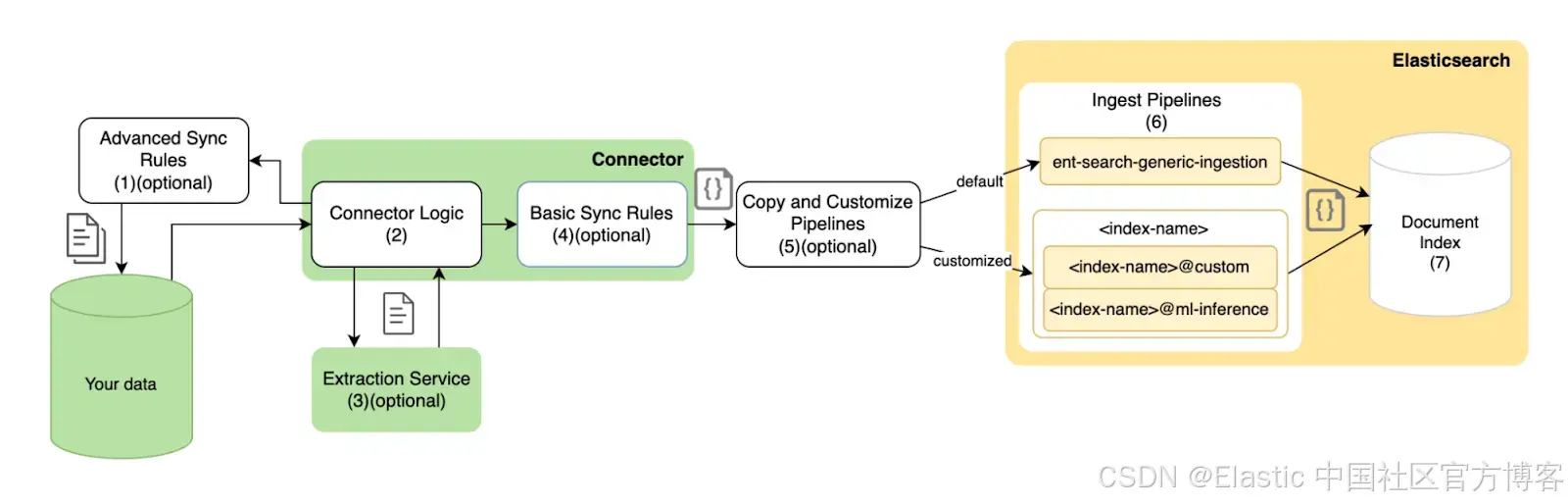
优化点
- 通过应用高级同步过滤器仅索引你需要的文档
- 仅索引你将使用的字段
- 根据你的需求优化映射
- 自动化文档级别安全性
- 卸载附件提取
- 监控连接器的日志
1. 通过应用高级同步过滤器仅索引你需要的文档
默认情况下,Jira 会发送所有项目、问题和附件。如果你只对其中一些感兴趣,或者例如只对 “In Progress - 正在进行” 的问题感兴趣,我们建议不要索引所有内容。
在将文档放入 Elasticsearch 之前,有三个实例可以过滤文档:
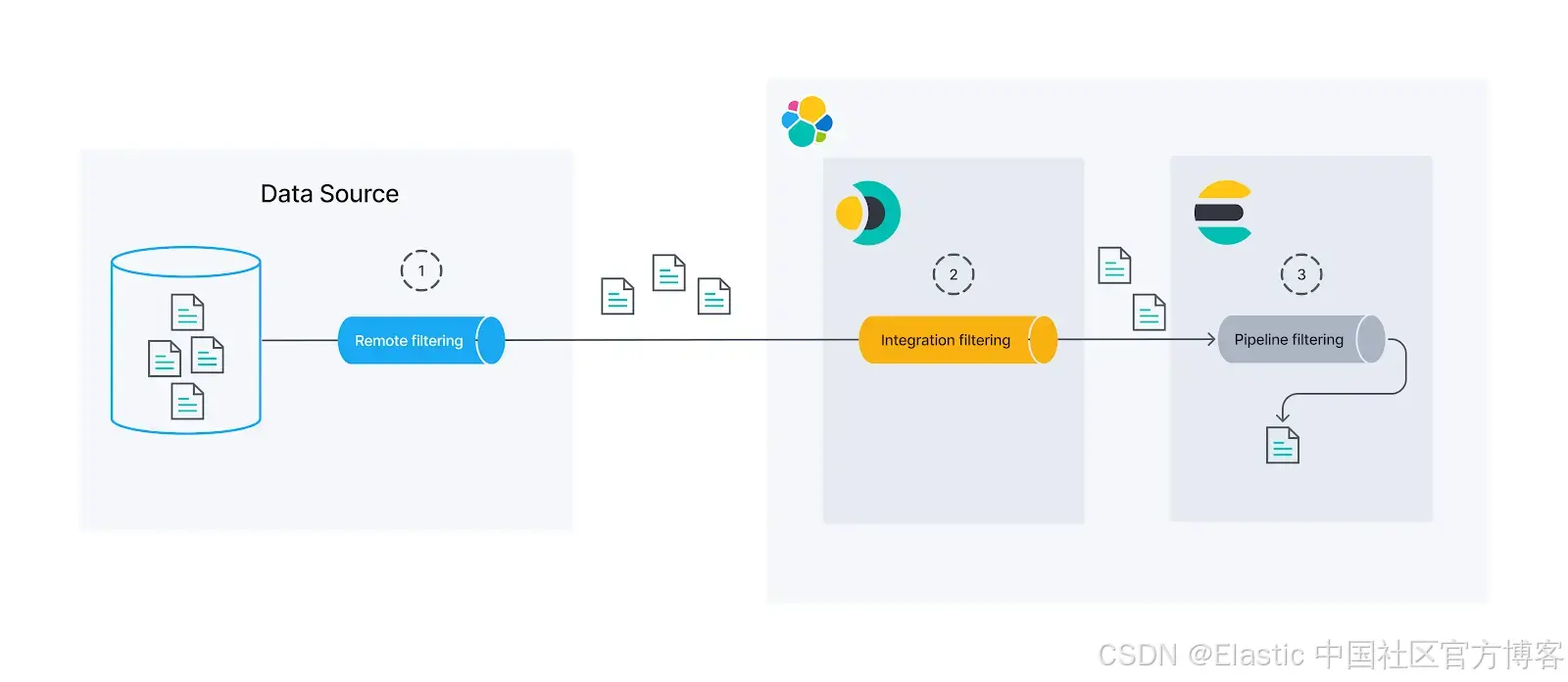
- 远程:我们可以使用原生 Jira 过滤器来获取我们需要的内容。这是最好的选择,你应该尽可能尝试使用此选项,因为这样,文档在进入 Elasticsearch 之前甚至不会从源中出来。我们将为此使用高级同步规则。
- 集成:如果源没有原生过滤器来提供我们需要的内容,我们仍然可以使用基本同步规则在集成级别进行过滤,然后再将其导入 Elasticsearch。
- 摄入管道:在索引数据之前处理数据的最后一个选项是使用 Elasticsearch 摄入管道(ingest pipeline)。通过使用 Painless 脚本,我们可以非常灵活地过滤或操作文档。这样做的缺点是数据已经离开源并通过连接器,因此可能会给系统带来沉重的负担并产生安全问题。
让我们快速回顾一下 Jira 问题:
GET bank/_search
{
"_source": ["Issue.status.name", "Issue.summary"],
"query": {
"exists": {
"field": "Issue.status.name"
}
}
}注意:我们使用 “exists” 查询仅返回具有我们过滤的字段的文档。
你可以看到 “To Do” 中有很多我们不需要的问题:
{
"took": 3,
"timed_out": false,
"_shards": {
"total": 2,
"successful": 2,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 6,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_index": "bank",
"_id": "Marketing Mars-MM-1",
"_score": 1,
"_source": {
"Issue": {
"summary": "Conquer Mars",
"status": {
"name": "To Do"
}
}
}
},
{
"_index": "bank",
"_id": "Marketing Mars-MM-3",
"_score": 1,
"_source": {
"Issue": {
"summary": "Conquering Earth",
"status": {
"name": "In Progress"
}
}
}
},
{
"_index": "bank",
"_id": "Marketing Mars-MM-2",
"_score": 1,
"_source": {
"Issue": {
"summary": "Conquer the moon",
"status": {
"name": "To Do"
}
}
}
},
{
"_index": "bank",
"_id": "Galactic Banking Project-GBP-3",
"_score": 1,
"_source": {
"Issue": {
"summary": "Intergalactic Security and Compliance",
"status": {
"name": "In Progress"
}
}
}
},
{
"_index": "bank",
"_id": "Galactic Banking Project-GBP-2",
"_score": 1,
"_source": {
"Issue": {
"summary": "Bank Application Frontend",
"status": {
"name": "To Do"
}
}
}
},
{
"_index": "bank",
"_id": "Galactic Banking Project-GBP-1",
"_score": 1,
"_source": {
"Issue": {
"summary": "Development of API for International Transfers",
"status": {
"name": "To Do"
}
}
}
}
]
}
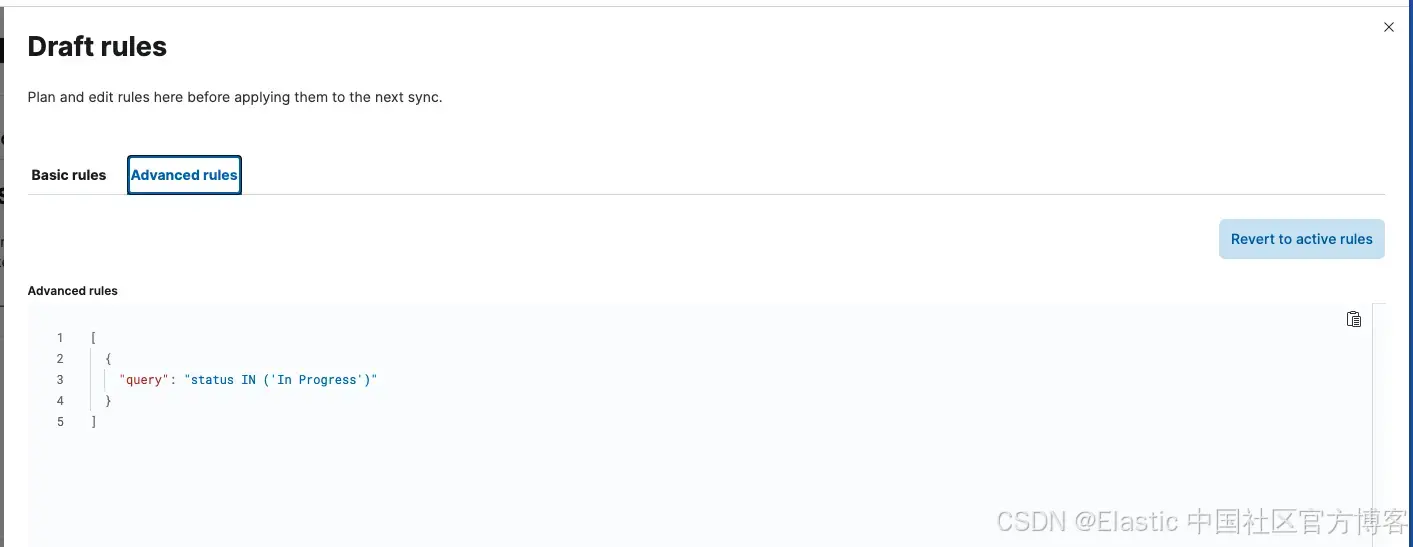
}为了仅获取 “In Progress” 的问题,我们将使用 JQL 查询(Jira 查询语言)创建高级同步规则:
转到连接器并单击 sync rules 选项卡,然后单击 Draft Rules。进入后,转到 Advanced Sync Rules 并添加以下内容:
[
{
"query": "status IN ('In Progress')"
}
]应用规则后,运行 Full Content Sync。

此规则将排除所有非 “In Progress” 的问题。你可以通过再次运行查询来检查:
GET bank/_search
{
"_source": ["Issue.status.name", "Issue.summary"],
"query": {
"exists": {
"field": "Issue.status.name"
}
}
}以下是新的回应:
{
"took": 2,
"timed_out": false,
"_shards": {
"total": 2,
"successful": 2,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_index": "bank",
"_id": "Marketing Mars-MM-3",
"_score": 1,
"_source": {
"Issue": {
"summary": "Conquering Earth",
"status": {
"name": "In Progress"
}
}
}
},
{
"_index": "bank",
"_id": "Galactic Banking Project-GBP-3",
"_score": 1,
"_source": {
"Issue": {
"summary": "Intergalactic Security and Compliance",
"status": {
"name": "In Progress"
}
}
}
}
]
}
}2. 仅索引你将使用的字段
现在我们只有我们想要的文档,你可以看到我们仍然会得到很多我们不需要的字段。我们可以在运行查询时使用 _source 隐藏它们,但最好的选择是不索引它们。
为此,我们将使用摄取管道(ingest pipeline)。我们可以创建一个删除所有我们不会使用的字段的管道。假设我们只想要来自问题的以下信息:
- Assignee
- Title
- Status
我们可以创建一个新的摄取管道,仅使用摄取管道的 Content UI 获取这些字段:
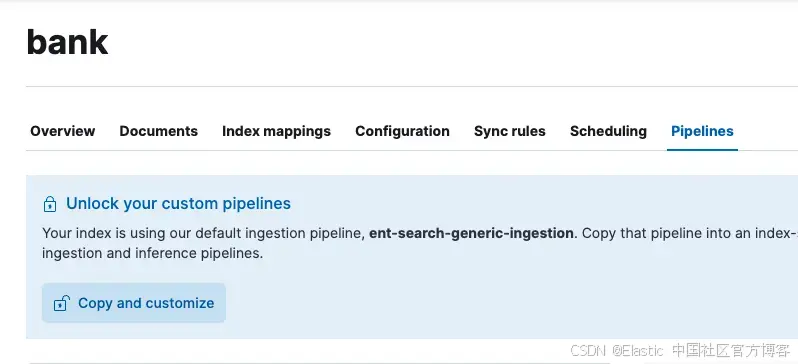
单击复 Copy and customize,然后修改名为 index-name@custom 的管道,该管道应该刚刚创建且为空。我们可以使用 Kibana DevTools 控制台执行此操作,运行以下命令:
PUT _ingest/pipeline/bank@custom
{
"description": "Only keep needed fields for jira issues and move them to root",
"processors": [
{
"remove": {
"keep": [
"Issue.assignee.displayName",
"Issue.summary",
"Issue.status.name"
],
"ignore_missing": true
}
},
{
"rename": {
"field": "Issue.assignee.displayName",
"target_field": "assignee",
"ignore_missing": true
}
},
{
"rename": {
"field": "Issue.summary",
"target_field": "summary",
"ignore_missing": true
}
},
{
"rename": {
"field": "Issue.status.name",
"target_field": "status",
"ignore_missing": true
}
},
{
"remove": {
"field": "Issue"
}
}
]
}让我们删除不需要的字段,并将需要的字段移至文档的根目录。
带有 keep 参数的 remove 处理器将从文档中删除除 keep 数组中的字段之外的所有字段。
我们可以通过运行模拟来检查这是否有效。从索引中添加其中一个文档的内容:
POST /_ingest/pipeline/bank@custom/_simulate
{
"docs": [
{
"_index": "bank",
"_id": "Galactic Banking Project-GBP-3",
"_score": 1,
"_source": {
"Type": "Epic",
"Custom_Fields": {
"Satisfaction": null,
"Approvals": null,
"Change reason": null,
"Epic Link": null,
"Actual end": null,
"Design": null,
"Campaign assets": null,
"Story point estimate": null,
"Approver groups": null,
"[CHART] Date of First Response": null,
"Request Type": null,
"Campaign goals": null,
"Project overview key": null,
"Related projects": null,
"Campaign type": null,
"Impact": null,
"Request participants": [],
"Locked forms": null,
"Time to first response": null,
"Work category": null,
"Audience": null,
"Open forms": null,
"Details": null,
"Sprint": null,
"Stakeholders": null,
"Marketing asset type": null,
"Submitted forms": null,
"Start date": null,
"Actual start": null,
"Category": null,
"Change risk": null,
"Target start": null,
"Issue color": "purple",
"Parent Link": {
"hasEpicLinkFieldDependency": false,
"showField": false,
"nonEditableReason": {
"reason": "EPIC_LINK_SHOULD_BE_USED",
"message": "To set an epic as the parent, use the epic link instead"
}
},
"Format": null,
"Target end": null,
"Approvers": null,
"Team": null,
"Change type": null,
"Satisfaction date": null,
"Request language": null,
"Amount": null,
"Rank": "0|i0001b:",
"Affected services": null,
"Type": null,
"Time to resolution": null,
"Total forms": null,
"[CHART] Time in Status": null,
"Organizations": [],
"Flagged": null,
"Project overview status": null
},
"Issue": {
"statuscategorychangedate": "2024-11-07T16:59:54.786-0300",
"issuetype": {
"avatarId": 10307,
"hierarchyLevel": 1,
"name": "Epic",
"self": "https://tomasmurua.atlassian.net/rest/api/2/issuetype/10008",
"description": "Epics track collections of related bugs, stories, and tasks.",
"entityId": "f5637521-ec75-48b8-a1b8-de18520807ca",
"id": "10008",
"iconUrl": "https://tomasmurua.atlassian.net/rest/api/2/universal_avatar/view/type/issuetype/avatar/10307?size=medium",
"subtask": false
},
"components": [],
"timespent": null,
"timeoriginalestimate": null,
"project": {
"simplified": true,
"avatarUrls": {
"48x48": "https://tomasmurua.atlassian.net/rest/api/2/universal_avatar/view/type/project/avatar/10415",
"24x24": "https://tomasmurua.atlassian.net/rest/api/2/universal_avatar/view/type/project/avatar/10415?size=small",
"16x16": "https://tomasmurua.atlassian.net/rest/api/2/universal_avatar/view/type/project/avatar/10415?size=xsmall",
"32x32": "https://tomasmurua.atlassian.net/rest/api/2/universal_avatar/view/type/project/avatar/10415?size=medium"
},
"name": "Galactic Banking Project",
"self": "https://tomasmurua.atlassian.net/rest/api/2/project/10001",
"id": "10001",
"projectTypeKey": "software",
"key": "GBP"
},
"description": null,
"fixVersions": [],
"aggregatetimespent": null,
"resolution": null,
"timetracking": {},
"security": null,
"aggregatetimeestimate": null,
"attachment": [],
"resolutiondate": null,
"workratio": -1,
"summary": "Intergalactic Security and Compliance",
"watches": {
"self": "https://tomasmurua.atlassian.net/rest/api/2/issue/GBP-3/watchers",
"isWatching": true,
"watchCount": 1
},
"issuerestriction": {
"issuerestrictions": {},
"shouldDisplay": true
},
"lastViewed": "2024-11-08T02:04:25.247-0300",
"creator": {
"accountId": "712020:88983800-6c97-469a-9451-79c2dd3732b5",
"emailAddress": "[email protected]",
"avatarUrls": {
"48x48": "https://secure.gravatar.com/avatar/f098101294d1a0da282bb2388df8c257?d=https%3A%2F%2Favatar-management--avatars.us-west-2.prod.public.atl-paas.net%2Finitials%2FTM-3.png",
"24x24": "https://secure.gravatar.com/avatar/f098101294d1a0da282bb2388df8c257?d=https%3A%2F%2Favatar-management--avatars.us-west-2.prod.public.atl-paas.net%2Finitials%2FTM-3.png",
"16x16": "https://secure.gravatar.com/avatar/f098101294d1a0da282bb2388df8c257?d=https%3A%2F%2Favatar-management--avatars.us-west-2.prod.public.atl-paas.net%2Finitials%2FTM-3.png",
"32x32": "https://secure.gravatar.com/avatar/f098101294d1a0da282bb2388df8c257?d=https%3A%2F%2Favatar-management--avatars.us-west-2.prod.public.atl-paas.net%2Finitials%2FTM-3.png"
},
"displayName": "Tomas Murua",
"accountType": "atlassian",
"self": "https://tomasmurua.atlassian.net/rest/api/2/user?accountId=712020%3A88983800-6c97-469a-9451-79c2dd3732b5",
"active": true,
"timeZone": "Chile/Continental"
},
"subtasks": [],
"created": "2024-10-29T15:52:40.306-0300",
"reporter": {
"accountId": "712020:88983800-6c97-469a-9451-79c2dd3732b5",
"emailAddress": "[email protected]",
"avatarUrls": {
"48x48": "https://secure.gravatar.com/avatar/f098101294d1a0da282bb2388df8c257?d=https%3A%2F%2Favatar-management--avatars.us-west-2.prod.public.atl-paas.net%2Finitials%2FTM-3.png",
"24x24": "https://secure.gravatar.com/avatar/f098101294d1a0da282bb2388df8c257?d=https%3A%2F%2Favatar-management--avatars.us-west-2.prod.public.atl-paas.net%2Finitials%2FTM-3.png",
"16x16": "https://secure.gravatar.com/avatar/f098101294d1a0da282bb2388df8c257?d=https%3A%2F%2Favatar-management--avatars.us-west-2.prod.public.atl-paas.net%2Finitials%2FTM-3.png",
"32x32": "https://secure.gravatar.com/avatar/f098101294d1a0da282bb2388df8c257?d=https%3A%2F%2Favatar-management--avatars.us-west-2.prod.public.atl-paas.net%2Finitials%2FTM-3.png"
},
"displayName": "Tomas Murua",
"accountType": "atlassian",
"self": "https://tomasmurua.atlassian.net/rest/api/2/user?accountId=712020%3A88983800-6c97-469a-9451-79c2dd3732b5",
"active": true,
"timeZone": "Chile/Continental"
},
"aggregateprogress": {
"total": 0,
"progress": 0
},
"priority": {
"name": "Medium",
"self": "https://tomasmurua.atlassian.net/rest/api/2/priority/3",
"iconUrl": "https://tomasmurua.atlassian.net/images/icons/priorities/medium.svg",
"id": "3"
},
"labels": [],
"environment": null,
"timeestimate": null,
"aggregatetimeoriginalestimate": null,
"versions": [],
"duedate": null,
"progress": {
"total": 0,
"progress": 0
},
"issuelinks": [],
"votes": {
"hasVoted": false,
"self": "https://tomasmurua.atlassian.net/rest/api/2/issue/GBP-3/votes",
"votes": 0
},
"comment": {
"total": 0,
"comments": [],
"maxResults": 0,
"self": "https://tomasmurua.atlassian.net/rest/api/2/issue/10008/comment",
"startAt": 0
},
"assignee": {
"accountId": "712020:88983800-6c97-469a-9451-79c2dd3732b5",
"emailAddress": "[email protected]",
"avatarUrls": {
"48x48": "https://secure.gravatar.com/avatar/f098101294d1a0da282bb2388df8c257?d=https%3A%2F%2Favatar-management--avatars.us-west-2.prod.public.atl-paas.net%2Finitials%2FTM-3.png",
"24x24": "https://secure.gravatar.com/avatar/f098101294d1a0da282bb2388df8c257?d=https%3A%2F%2Favatar-management--avatars.us-west-2.prod.public.atl-paas.net%2Finitials%2FTM-3.png",
"16x16": "https://secure.gravatar.com/avatar/f098101294d1a0da282bb2388df8c257?d=https%3A%2F%2Favatar-management--avatars.us-west-2.prod.public.atl-paas.net%2Finitials%2FTM-3.png",
"32x32": "https://secure.gravatar.com/avatar/f098101294d1a0da282bb2388df8c257?d=https%3A%2F%2Favatar-management--avatars.us-west-2.prod.public.atl-paas.net%2Finitials%2FTM-3.png"
},
"displayName": "Tomas Murua",
"accountType": "atlassian",
"self": "https://tomasmurua.atlassian.net/rest/api/2/user?accountId=712020%3A88983800-6c97-469a-9451-79c2dd3732b5",
"active": true,
"timeZone": "Chile/Continental"
},
"worklog": {
"total": 0,
"maxResults": 20,
"startAt": 0,
"worklogs": []
},
"updated": "2024-11-07T16:59:54.786-0300",
"status": {
"name": "In Progress",
"self": "https://tomasmurua.atlassian.net/rest/api/2/status/10004",
"description": "",
"iconUrl": "https://tomasmurua.atlassian.net/",
"id": "10004",
"statusCategory": {
"colorName": "yellow",
"name": "In Progress",
"self": "https://tomasmurua.atlassian.net/rest/api/2/statuscategory/4",
"id": 4,
"key": "indeterminate"
}
}
},
"id": "Galactic Banking Project-GBP-3",
"_timestamp": "2024-11-07T16:59:54.786-0300",
"Key": "GBP-3",
"_allow_access_control": [
"account_id:63c04b092341bff4fff6e0cb",
"account_id:712020:88983800-6c97-469a-9451-79c2dd3732b5",
"name:Gustavo",
"name:Tomas-Murua"
]
}
}
]
}响应将是:
{
"docs": [
{
"doc": {
"_index": "bank",
"_version": "-3",
"_id": "Galactic Banking Project-GBP-3",
"_source": {
"summary": "Intergalactic Security and Compliance",
"assignee": "Tomas Murua",
"status": "In Progress"
},
"_ingest": {
"timestamp": "2024-11-10T06:58:25.494057572Z"
}
}
}
]
}这看起来好多了!现在,让我们运行 full content sync 来应用更改。
3. 根据你的需求优化映射
文档很干净。但是,我们可以进一步优化。我们可以进入 “it depends” 的领域。有些映射可以适用于你的用例,而其他映射则不行。找出答案的最佳方法是进行实验。
假设我们测试并得到了这个映射设计:
- assignee:全文搜索和过滤器
- summary:全文搜索
- status:过滤器和排序
默认情况下,连接器将使用 dynamic_templates 创建映射,这些映射将配置所有文本字段以进行全文搜索、过滤和排序,这是一个坚实的基础,但如果我们知道我们想要用我们的字段做什么,它可以进行优化。
这是规则:
{
"all_text_fields": {
"match_mapping_type": "string",
"mapping": {
"analyzer": "iq_text_base",
"fields": {
"delimiter": {
"analyzer": "iq_text_delimiter",
"type": "text",
"index_options": "freqs"
},
"joined": {
"search_analyzer": "q_text_bigram",
"analyzer": "i_text_bigram",
"type": "text",
"index_options": "freqs"
},
"prefix": {
"search_analyzer": "q_prefix",
"analyzer": "i_prefix",
"type": "text",
"index_options": "docs"
},
"enum": {
"ignore_above": 2048,
"type": "keyword"
},
"stem": {
"analyzer": "iq_text_stem",
"type": "text"
}
}
}
}
}让我们为所有文本字段创建用于不同目的的不同子字段。你可以在文档中找到有关分析器的其他信息。
要使用这些映射,你必须:
- 在创建连接器之前创建索引
- 创建连接器时,选择该索引而不是创建新索引
- 创建摄取管道以获取所需的字段
- 运行 Full Content Sync*
*Full Content Sync 会将所有文档发送到 Elasticsearch。Incremental Sync 只会将上次增量或完整内容同步后更改的文档发送到 Elasticsearch。这两种方法都将从数据源获取所有数据。
我们的优化映射如下:
PUT bank-optimal
{
"mappings": {
"properties": {
"assignee": {
"type": "text",
"fields": {
"delimiter": {
"type": "text",
"index_options": "freqs",
"analyzer": "iq_text_delimiter"
},
"enum": {
"type": "keyword",
"ignore_above": 2048
},
"joined": {
"type": "text",
"index_options": "freqs",
"analyzer": "i_text_bigram",
"search_analyzer": "q_text_bigram"
},
"prefix": {
"type": "text",
"index_options": "docs",
"analyzer": "i_prefix",
"search_analyzer": "q_prefix"
},
"stem": {
"type": "text",
"analyzer": "iq_text_stem"
}
},
"analyzer": "iq_text_base"
},
"summary": {
"type": "text",
"fields": {
"delimiter": {
"type": "text",
"index_options": "freqs",
"analyzer": "iq_text_delimiter"
},
"joined": {
"type": "text",
"index_options": "freqs",
"analyzer": "i_text_bigram",
"search_analyzer": "q_text_bigram"
},
"prefix": {
"type": "text",
"index_options": "docs",
"analyzer": "i_prefix",
"search_analyzer": "q_prefix"
},
"stem": {
"type": "text",
"analyzer": "iq_text_stem"
}
},
"analyzer": "iq_text_base"
},
"status": {
"type": "keyword"
}
}
}
}对于 assignee,我们保留了原有的映射,因为我们希望此字段针对搜索和过滤器进行优化。对于 summary,我们删除了 “enum” 关键字字段,因为我们不打算过滤摘要。我们将 status 映射为关键字,因为我们只打算过滤该字段。
注意:如果你不确定如何使用字段,基线分析器应该没问题。
4. 自动化文档级安全性
在第一部分中,我们学习了使用文档级安全性 (Document Level Security - DLS) 为用户手动创建 API 密钥并根据该密钥限制访问权限。但是,如果你想在每次用户访问我们的网站时自动创建具有权限的 API 密钥,则需要创建一个脚本来接收请求,使用用户 ID 生成 API 密钥,然后使用它在 Elasticsearch 中搜索。
这是 Python 中的参考文件:
import os
import requests
class ElasticsearchKeyGenerator:
def __init__(self):
self.es_url = "https://xxxxxxx.es.us-central1.gcp.cloud.es.io" # Your Elasticsearch URL
self.es_user = "" # Your Elasticsearch User
self.es_password = "" # Your Elasticsearch password
# Basic configuration for requests
self.auth = (self.es_user, self.es_password)
self.headers = {'Content-Type': 'application/json'}
def create_api_key(self, user_id, index, expiration='1d', metadata=None):
"""
Create an Elasticsearch API key for a single index with user-specific filters.
Args:
user_id (str): User identifier on the source system
index (str): Index name
expiration (str): Key expiration time (default: '1d')
metadata (dict): Additional metadata for the API key
Returns:
str: Encoded API key if successful, None if failed
"""
try:
# Get user-specific ACL filters
acl_index = f'.search-acl-filter-{index}'
response = requests.get(
f'{self.es_url}/{acl_index}/_doc/{user_id}',
auth=self.auth,
headers=self.headers
)
response.raise_for_status()
# Build the query
query = {
'bool': {
'must': [
{'term': {'_index': index}},
response.json()['_source']['query']
]
}
}
# Set default metadata if none provided
if not metadata:
metadata = {'created_by': 'create-api-key'}
# Prepare API key request body
api_key_body = {
'name': user_id,
'expiration': expiration,
'role_descriptors': {
f'jira-role': {
'index': [{
'names': [index],
'privileges': ['read'],
'query': query
}]
}
},
'metadata': metadata
}
print(api_key_body)
# Create API key
api_key_response = requests.post(
f'{self.es_url}/_security/api_key',
json=api_key_body,
auth=self.auth,
headers=self.headers
)
api_key_response.raise_for_status()
return api_key_response.json()['encoded']
except requests.exceptions.RequestException as e:
print(f"Error creating API key: {str(e)}")
return None
# Example usage
if __name__ == "__main__":
key_generator = ElasticsearchKeyGenerator()
encoded_key = key_generator.create_api_key(
user_id="63c04b092341bff4fff6e0cb", # User id on Jira
index="bank",
expiration="1d",
metadata={
"application": "my-search-app",
"namespace": "dev",
"foo": "bar"
}
)
if encoded_key:
print(f"Generated API key: {encoded_key}")
else:
print("Failed to generate API key")你可以在每个 API 请求上调用此 create_api_key 函数来生成 API 密钥,用户可以在后续请求中使用该密钥查询 Elasticsearch。你可以设置到期时间,还可以设置任意元数据,以防你想要注册有关用户或生成密钥的 API 的一些信息。
5. 卸载附件提取
对于内容提取,例如从 PDF 和 Powerpoint 文件中提取文本,Elastic 提供了一种开箱即用的服务,该服务运行良好,但有大小限制。
默认情况下,本机连接器的提取服务支持每个附件最大 10MB。如果你有更大的附件,例如里面有大图像的 PDF,或者你想要托管提取服务,Elastic 提供了一个工具,可让你部署自己的提取服务。
此选项仅与连接器客户端兼容,因此如果你使用的是本机连接器,则需要将其转换为连接器客户端并将其托管在你自己的基础架构中。
请按照以下步骤操作:
a. 配置自定义提取服务并使用 Docker 运行
docker run \
-p 8090:8090 \
-it \
--name extraction-service \
docker.elastic.co/enterprise-search/data-extraction-service:$EXTRACTION_SERVICE_VERSIONEXTRACTION_SERVICE_VERSION 你应该使用 Elasticsearch 8.15 的 0.3.x。
b. 配置 yaml con 提取服务自定义并运行
转到连接器客户端并将以下内容添加到 config.yml 文件以使用提取服务:
extraction_service:
host: http://localhost:8090c. 按照步骤运行连接器客户端
配置完成后,你可以使用要使用的连接器运行连接器客户端。
docker run \
-v "</absolute/path/to>/connectors-config:/config" \ # NOTE: change absolute path to match where config.yml is located on your machine
--tty \
--rm \
docker.elastic.co/enterprise-search/elastic-connectors:{version}.0 \
/app/bin/elastic-ingest \
-c /config/config.yml # Path to your configuration file in the container你可以参考文档中的完整流程。
6. 监控连接器的日志
在出现问题时,查看连接器的日志非常重要,Elastic 提供了开箱即用的功能。
第一步是在集群中激活日志记录。建议将日志发送到其他集群(监控部署),但在开发环境中,你也可以将日志发送到索引文档的同一集群。
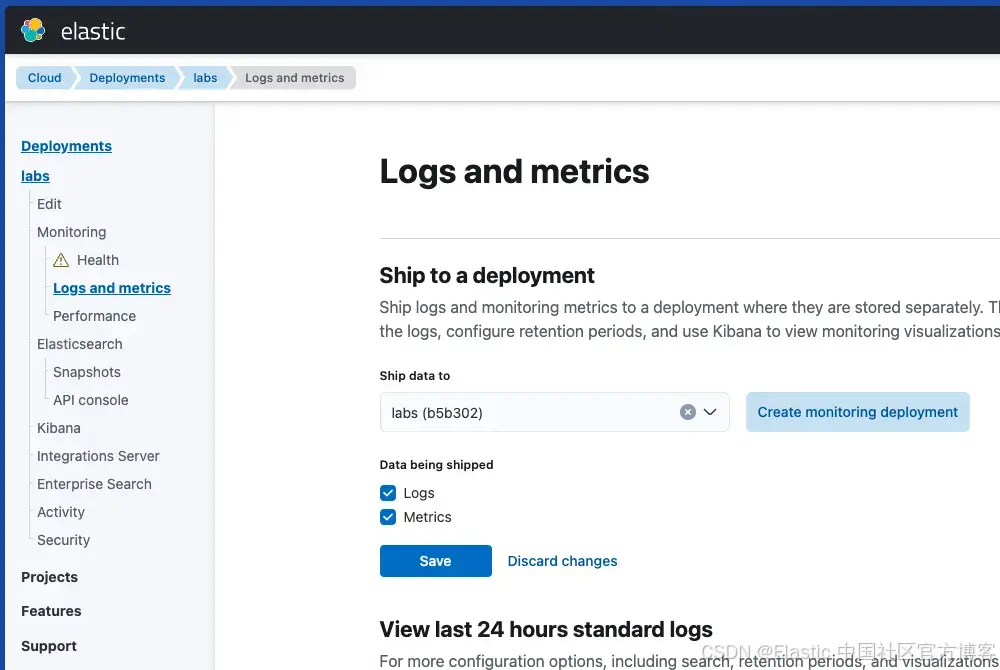
默认情况下,连接器会将日志发送到 elastic-cloud-logs-8 索引。如果你使用的是 Cloud,则可以在新的 Logs Explorer 中检查日志:
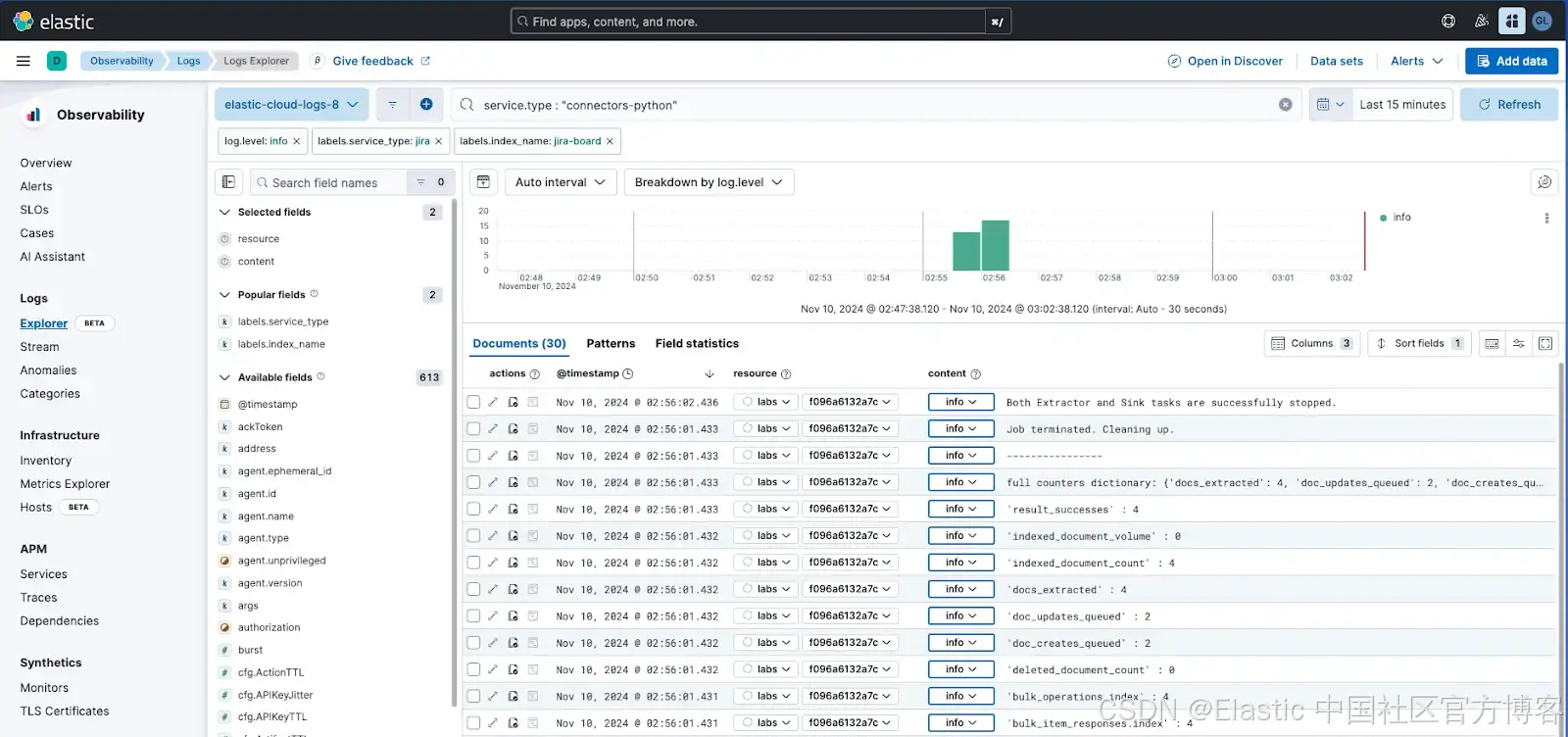
结论
在本文中,我们了解了在生产环境中使用连接器时需要考虑的不同策略。优化资源、自动化安全性和集群监控是正确运行大型系统的关键机制。
想要获得 Elastic 认证?了解下一期 Elasticsearch 工程师培训的时间!
Elasticsearch 包含许多新功能,可帮助你为你的用例构建最佳搜索解决方案。深入了解我们的示例笔记本以了解更多信息,开始免费云试用,或立即在你的本地机器上试用 Elastic。
原文:Jira connector tutorial part II: 6 optimization tips - Elasticsearch Labs